Non-Destructive Genotyping of Cultivars and Strains of Sesame through NIR Spectroscopy and Chemometrics

 , ,
, , 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Samples
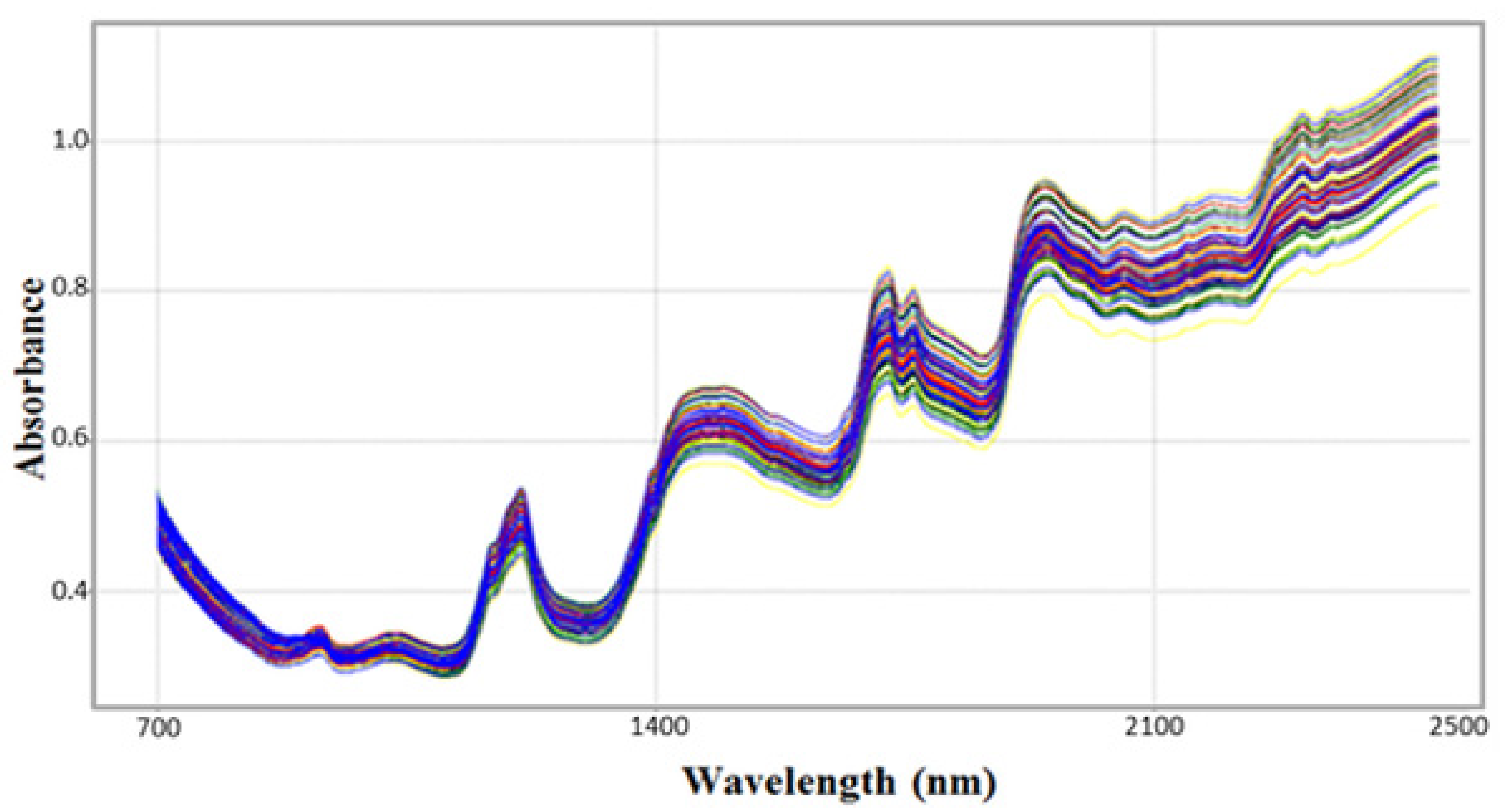
2.2. Near Infrared Spectroscopy
2.3. Data Processing and Statistical Analysis
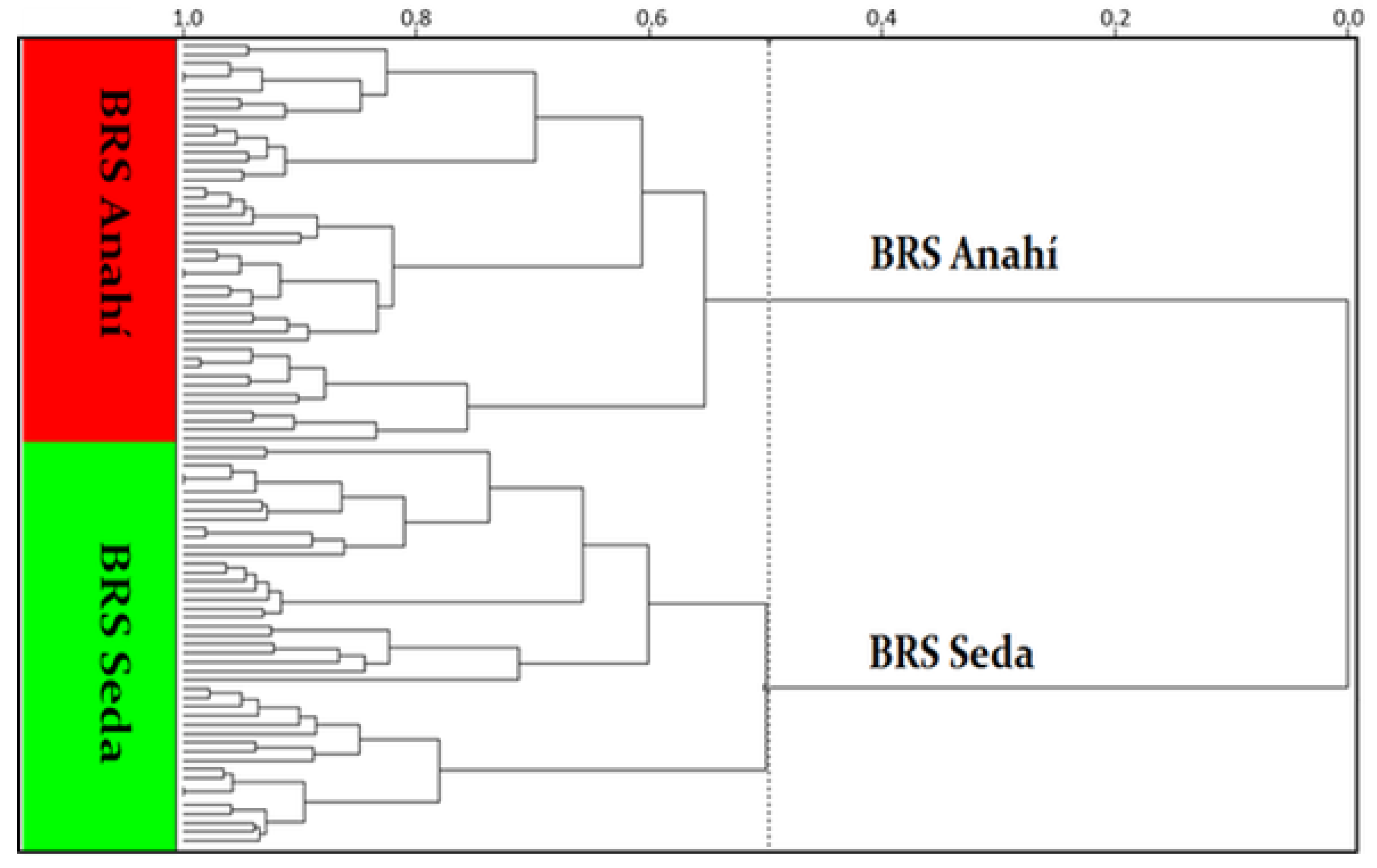
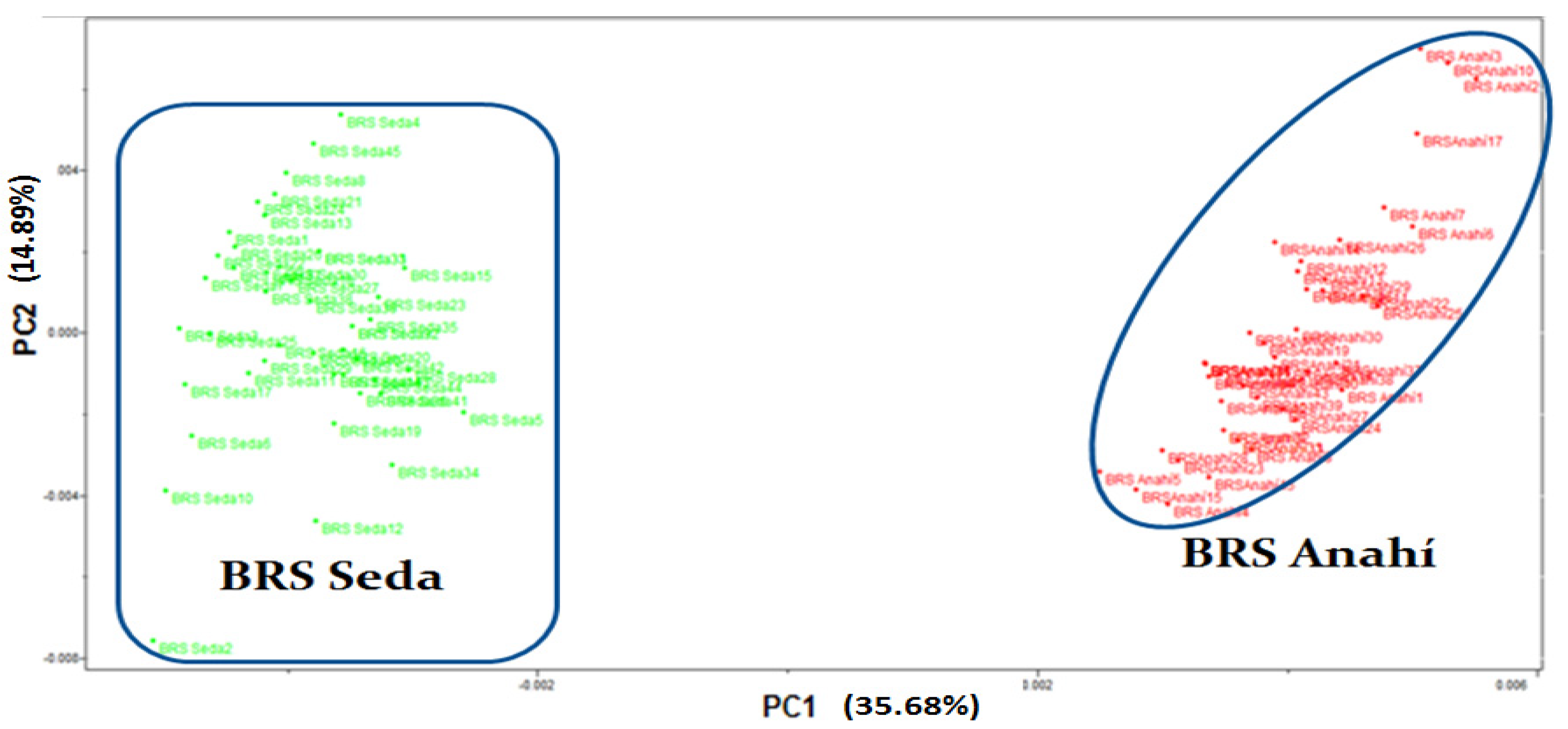
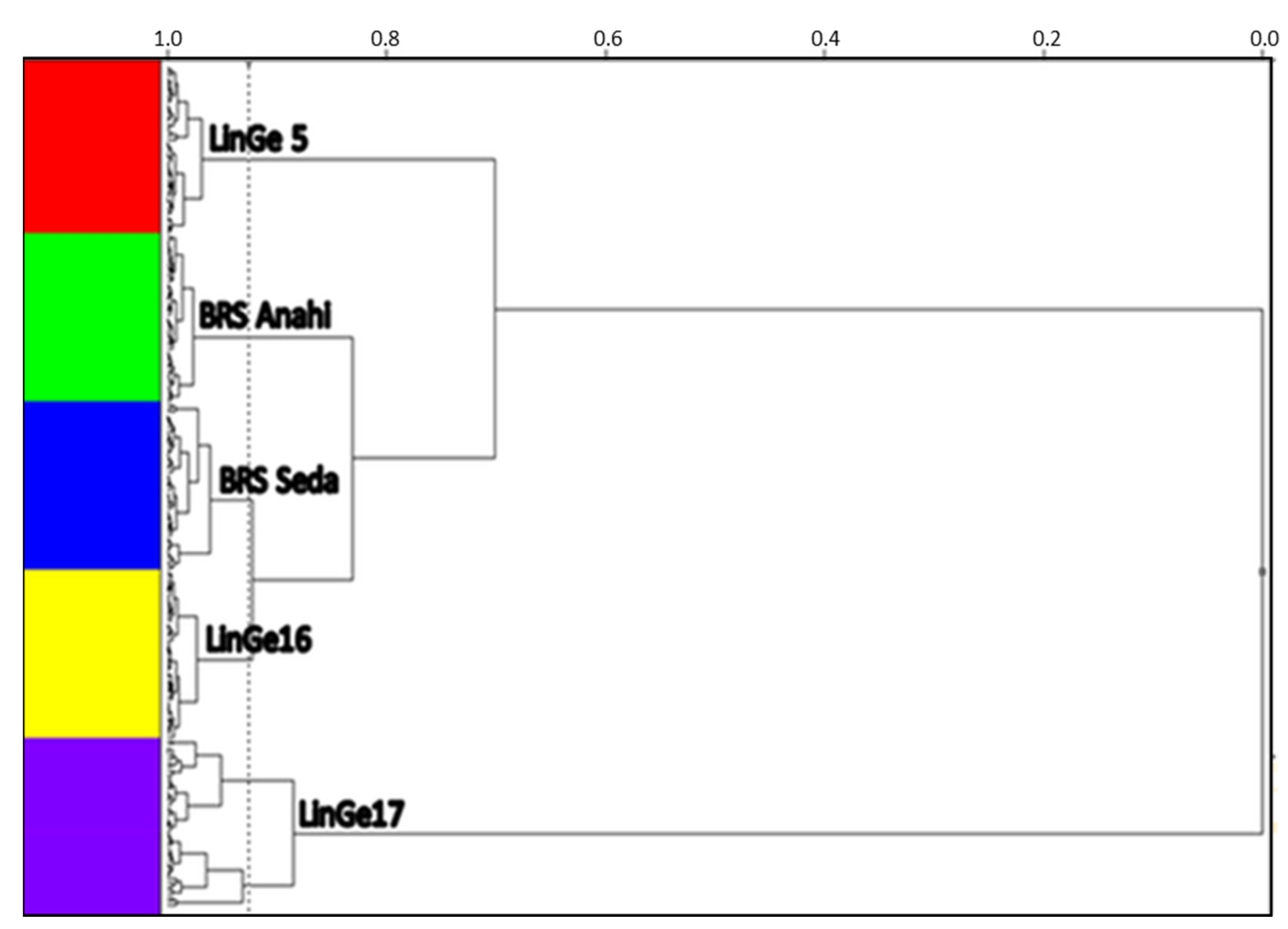
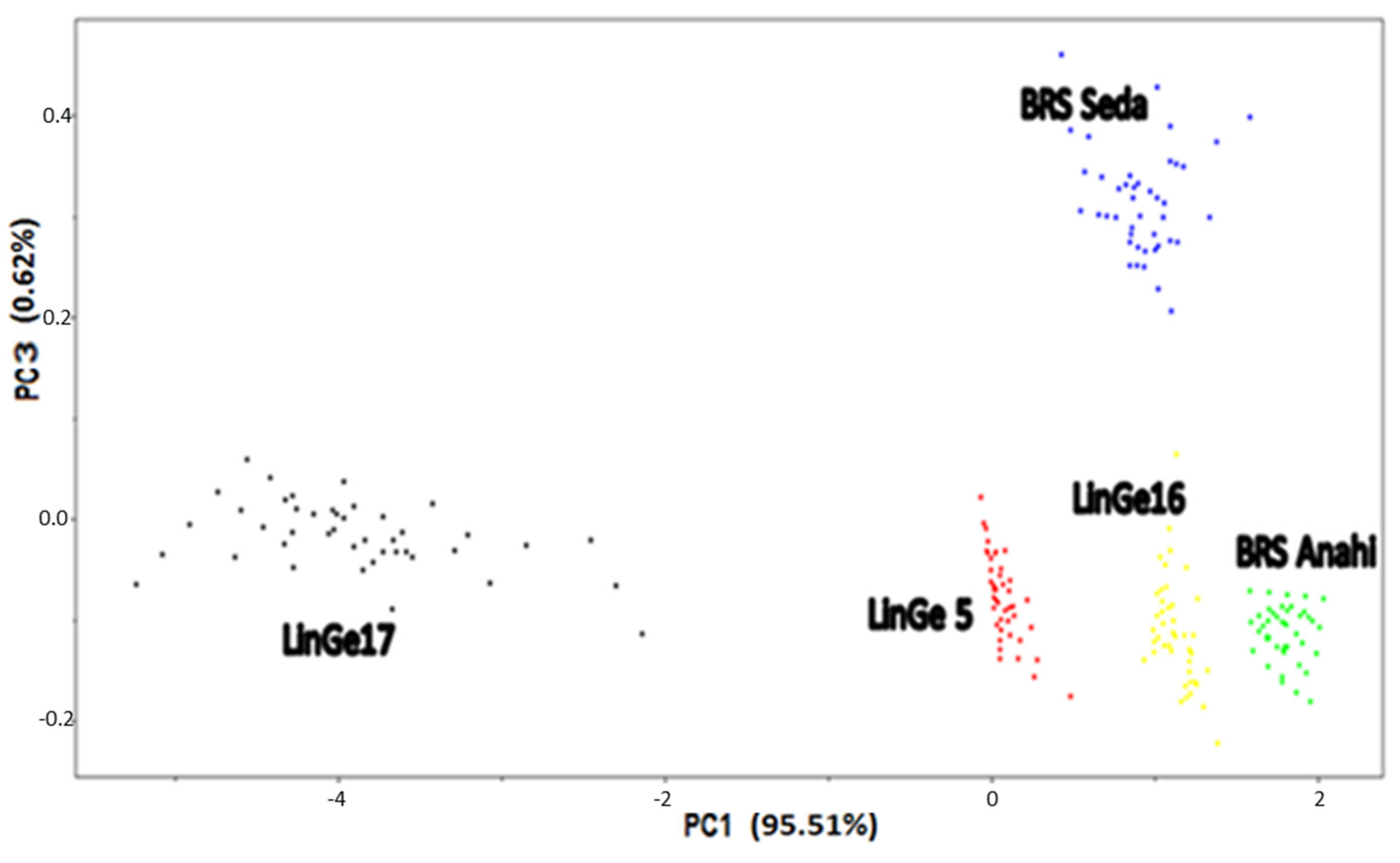
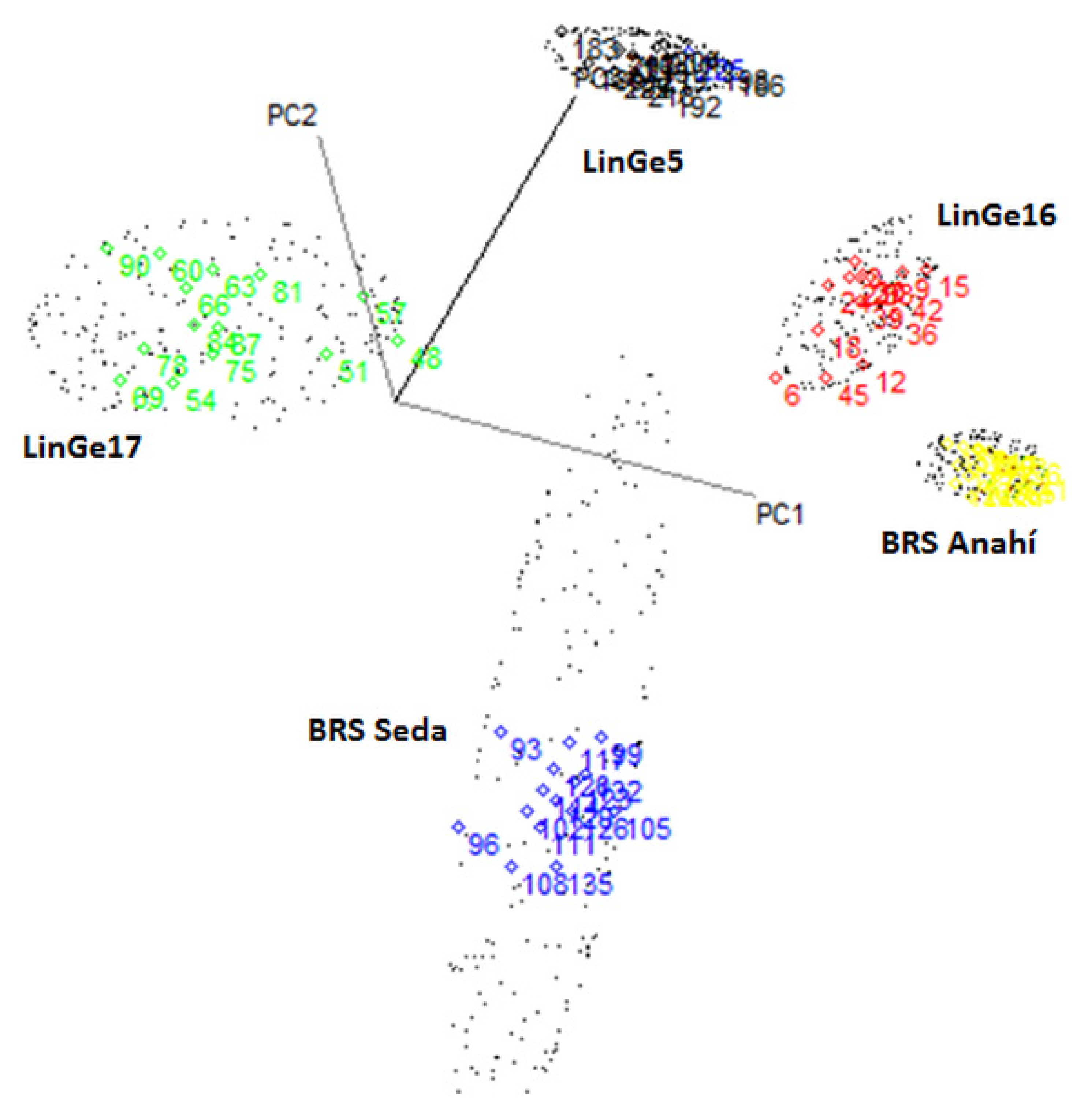
3. Results and Discussion
Authentification of the Cultivars and Sesame Strain
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Beltrão, N.d.M.; Freire, E.C.; Lima, E.F. Gergelim cultura no trópico semi-árido nordestino, Campina Grande: EMBRAPA-CNPA. Circ. Téc. 1994, 18, 52. [Google Scholar]
- Carvalho, R.H.R. Extração Supercrítica de óleo de Sesamum indicum L. e Aplicação Como Inibidor de Corrosão em aço AISI 1020 Através de Sistemas Microemulsionados. Ph.D. Thesis, Universidade Federal do Rio Grande do Norte—UFRN, Natal, Brazil, 2015. [Google Scholar]
- Arriel, N.H.C.; Di Mauro, A.O.; Zingaretti, S.M.; Bakke, O.A.; Trevisoli, S.H.U.; Costa, M.M.; Capeloto, A.; Corrado, A.R. Técnicas multivariadas na determinação da diversidade genética em gergelim usando marcadores RAPD. Pesqui. Agropecu. Bras. 2006, 41, 801–809. [Google Scholar] [CrossRef]
- Santos, M.d.S.; Lima, V.L.A.; Beltrão, N.E.M.; Barros, H.M.M.; Sampaio, M.V.; Martins, E.S.C.S. Produção de gergelim sob irrigação com água residuária tratada e adubação com torta de mamona. Tecnol. Ciênc. Agropecu. 2010, 4, 31–35. [Google Scholar]
- Were, A.A.; Onkware, A.; Gudu, S.; Welander, M.; Carlsson, A.S. Seed oil content and fatty acid composition in East African sesame (Sesamum indicum L.) accessions evaluated over 3 years. Field Crops Res. 2006, 97, 254–260. [Google Scholar] [CrossRef]
- Barros, M.A.L.; Santos, R.B. Situação do Gergelim nos Mercados Mundial e Nacional, 1995 a 2002; Ministério da Agricultura, Pecuária e Abastecimento: Campina Grande, Brazil, 2002; Circular 67. [Google Scholar]
- Beltrão, N.d.M.; Ferreira, L.L.; Queiroz, N.L.; Tavares, M.d.S.; Rocha, M.S.; Alencar, R.D.; Porto, V.C.N. O Gergelim e Seu Cultivo no Semiárido Brasileiro; Editora IFRN: Natal, Brazil, 2013. [Google Scholar]
- Peske, S.T.; Barros, A.C.S.A. Produção de Sementes. In Sementes: Fundamentos Científicos e Tecnológicos, 3rd ed.; Peske, S.T., Lucca, O.F., Barros, A.C.S.A., Eds.; UFPel: Pelotas, Brazil, 2012; pp. 12–91. [Google Scholar]
- Menezes, M.; Pinho, E.V.R.V.; Pereira, A.M.A.R.; Oliveira, J.A. Identificação de cultivares de milho, feijão, algodão e soja por meio de enzimas e proteínas resistentes ao calor. Rev. Bras. Sementes 2008, 30, 111–122. [Google Scholar] [CrossRef] [Green Version]
- Vasconcelos, M.C. Diferenciação de Cultivares de Girassol por Espectroscopia no Infravermelho Próximo, Utilizando Sementes e óleo. Ph.D. Thesis, Universidade Federal de Lavras—UFLA, Lavras, Minas Gerais, Brazil, 2016. [Google Scholar]
- BRASIL. Lei n° 9.456, de 25 de Abril de 1997. Institui a lei de Proteção de Cultivares. 1997. Available online: http://www.planalto.gov.br/ccivil_03/leis/L9456.htm (accessed on 6 November 2021).
- Vasconcelos, M.C.; Oliveira, A.S.; Granja, J.A.A.; Costa, J.C.; Guimarães, R.M. Diferenciação de cultivares de girassol por espectroscopia no infravermelho próximo e análise multivariada, utilizando sementes e óleo. Rev. Bras. Ciênc. Agrárias 2018, 13, 1–7. [Google Scholar] [CrossRef]
- Milani, M.; Miguel Júnior, S.R.; Sousa, R.L. Documentos, 230: Sub-Espécies de Mamona; Embrapa Algodão: Campina Grande, Brazil, 2009. [Google Scholar]
- Silva, J.L.B. Espectroscopia NIR Aliada a Métodos de Reconhecimento de Padrões para Distinção Entre Sementes de Algodão das Variedades BRS Aroeira e BRS 368 RF. Ph.D. Thesis, Universidade Estadual da Paraíba-UEPB, Campina Grande, Brazil, 2020. [Google Scholar]
- Santos, M.B.H.; Gomes, A.A.; Vilar, W.T.S.; Almeida, P.B.A.; Milani, M.; Nobrega, M.B.M.; Medeiros, E.P.; Galvao, R.K.H.; Araujo, M.C.U. Non-Destructive NIR Spectrometric Cultivar Discrimination of Castor Seeds Resulting from Breeding Programs. J. Braz. Chem. Soc. 2014, 25, 969–974. [Google Scholar] [CrossRef]
- Ozaki, Y. Near-Infrared Spectroscopy—Its Versatility in Analytical Chemistry. Anal. Sci. 2012, 28, 545–563. [Google Scholar] [CrossRef] [Green Version]
- Hacisalihoglu, G.; Larbi, B.; Settles, A.M. Near-infrared reflectance spectroscopy predicts protein, starch, and seed weight in intact seeds of common bean (Phaseolus vulgaris L.). J. Agric. Food Chem. 2010, 58, 702–706. [Google Scholar] [CrossRef]
- Panero, J.S.; da Silva, H.E.B.; Panero, P.S.; Smiderle, O.J.; Panero, F.S.; Faria, F.S.E.D.V.; Rodriguez, A.F.R. Separation of Cultivars of Soybeans by Chemometric Methods Using Near Infrared Spectroscopy. J. Agric. Sci. 2018, 10, 351–360. [Google Scholar] [CrossRef] [Green Version]
- Guangjun, Q.; Enli, L.; Ning, W.; Huazhong, L.; Feiren, W.; Fanguo, Z. Cultivar Classification of Single Sweet Corn Seed Using Fourier Transform Near-Infrared Spectroscopy Combined with Discriminant Analysis. Appl. Sci. 2019, 9, 1530. [Google Scholar]
- Carvalho, L.C.; Morais, C.L.M.; Lima, K.M.G.; Leite, G.W.P.; Oliveira, G.S.; Casagrande, I.P.; Santos Neto, J.P.; Teixeira, G.H.A. Using Intact Nuts and Near Infrared Spectroscopy to Classify Macadamia Cultivars. Food Anal. Methods 2017, 11, 1857–1866. [Google Scholar] [CrossRef] [Green Version]
- Choi, Y.H.; Hong, C.K.; Park, G.Y.; Kim, C.K.; Kim, J.H.; Jung, K.; Kwon, J.H. A Nondestructive Approach for Discrimination of the Origin of Sesame Seeds Using ED-XRF and NIR Spectrometry with Chemometric. Food Sci. Biotechnol. 2016, 25, 433–438. [Google Scholar] [CrossRef]
- Kim, S.Y.; Kim, E.; Shin, B.K.; Seo, J.A.; Kim, Y.S.; Lee, D.Y.; Choi, H.K. NMR-based metabolic profiling discriminates the geographical origin of raw sesame seeds. Food Control 2020, 112, 107–113. [Google Scholar] [CrossRef]
- Roggo, Y.; Chalus, P.; Maurer, L.; Lema-Martinez, C.; Edmond, A.; Jent, N. A review of near infrared spectroscopy and chemometrics in pharmaceutical technologies. J. Pharm. Biomed. Anal. 2007, 44, 683–700. [Google Scholar] [CrossRef] [PubMed]
- Miranda, J.I. Processamento de Imagens Digitais: Métodos Multivariados em Java, 1st ed.; Editora Embrapa: Campinas, Brazil, 2011; Chapter 1; pp. 5–7. [Google Scholar]
- Maquina, A.D.V. Espectrometria no Infravermelho médio e Métodos Quimiométricos PLS-DA e PLS: Classificação e Previsão do teor de Biodiesel na Mistura de Biodiesel/Diesel de Mafurra, Moringa e Algodão. Master’s Thesis, Universidade Federal de Uberlândia, São Paulo, Brazil, 2017. [Google Scholar]
- Pirouettetm. Multivariate Data Analysis. Pirouette User Guide, Version 3.11; Infometrix Inc.: Woodinville, WA, USA, 2003. [Google Scholar]
- Oliveira, V.S. Análise da Autenticidade de Cédulas de Real Utilizando Espectroscopia nir Portátil e Quimiometria. Ph.D. Thesis, Universidade Federal de Pernambuco-UFPE, Recife, Brazil, 2018. [Google Scholar]
- Pereira, L.S.A. Análise Multivariada e Espectroscopia no Infravermelho Aplicadas em Análises Forenses: Drogas e Medicamentos. Master’s Thesis, Universidade Federal de Minas Gerais-UFMG, Belo Horizonte, Brazil, 2018. [Google Scholar]
- Kim, K.S.; Park, S.H.; Choung, M.G. Nondestructive Determination of Lignans and Lignan Glycosides in Sesame Seeds by Near Infrared Reflectance Spectroscopy. J. Agric. Food Chem. 2006, 54, 4544–4550. [Google Scholar] [CrossRef]
- Panero, P.S.; Panero, F.S.; Panero, J.S.; Silva, H.E.B. Application of Extended Multiplicative Signal Correction to Short-Wavelength near Infrared Spectra of Moisture in Marzipan. J. Data Anal. Inf. Process. 2013, 1, 30–34. [Google Scholar]
- Morgano, M.A.; Faria, C.G.; Ferrao, M.F.; Ferreira, M.M.C. Determination of total sugar in raw coffee using near infrared spectroscopy and pls regression. Quím. Nova 2007, 30, 346–350. [Google Scholar] [CrossRef] [Green Version]
- Souza, A.M.; Breitkreitz, M.C.; Filgueiras, P.R.; Rohwedder, J.J.R.; Poppi, R.J. Teaching experiment of chemometrics for multivariate calibration in determination of paracetamol in commercial tablets using near-infrared spectroscopy: A tutorial, part II. Quím. Nova 2013, 36, 1057–1065. [Google Scholar] [CrossRef] [Green Version]
- Correia, P.R.M.; Ferreira, M.M.C. Non-supervised pattern recognition methods: Exploring chemometrical procedures for evaluating analytical data. Quím. Nova 2007, 30, 481–487. [Google Scholar] [CrossRef]
- Kangas, M.J.; Burks, R.M.; Atwater, J.; Lukowicz, R.M.; Garver, B.; Holmes, A.E. Comparative Chemometric Analysis for Classification of Acids and Bases via a Colorimetric Sensor Array. J. Chemom. 2018, 32, 1–13. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| KNN | Calibration Set (150 Samples) | Validation Set (75 Samples) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| C1 | C2 | C3 | C4 | C5 | C1 | C2 | C3 | C4 | C5 | |
| 1 | 30 | 0 | 0 | 0 | 0 | 15 | 0 | 0 | 0 | 0 |
| 2 | 0 | 30 | 0 | 0 | 0 | 0 | 15 | 0 | 0 | 0 |
| 3 | 0 | 0 | 30 | 0 | 0 | 0 | 0 | 15 | 0 | 0 |
| 4 | 0 | 0 | 0 | 30 | 0 | 0 | 0 | 0 | 15 | 0 |
| 5 | 0 | 0 | 0 | 0 | 30 | 0 | 0 | 0 | 0 | 15 |
| SIMCA | Calibration Set (150 Samples) | Validation Set (75 Samples) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| C1 | C2 | C3 | C4 | C5 | C1 | C2 | C3 | C4 | C5 | |
| 1 | 30 | 0 | 0 | 0 | 0 | 15 | 0 | 0 | 0 | 0 |
| 2 | 0 | 29 | 0 | 1 | 0 | 1 | 14 | 0 | 0 | 0 |
| 3 | 0 | 0 | 30 | 0 | 0 | 0 | 0 | 15 | 0 | 0 |
| 4 | 0 | 0 | 0 | 30 | 0 | 0 | 0 | 0 | 15 | 0 |
| 5 | 0 | 0 | 0 | 0 | 30 | 0 | 0 | 0 | 0 | 15 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Panero, F.d.S.; Smiderle, O.; Panero, J.S.; Faria, F.S.D.V.; Panero, P.d.S.; Rodriguez, A.F.R. Non-Destructive Genotyping of Cultivars and Strains of Sesame through NIR Spectroscopy and Chemometrics. Biosensors 2022, 12, 69. https://doi.org/10.3390/bios12020069
Panero FdS, Smiderle O, Panero JS, Faria FSDV, Panero PdS, Rodriguez AFR. Non-Destructive Genotyping of Cultivars and Strains of Sesame through NIR Spectroscopy and Chemometrics. Biosensors. 2022; 12(2):69. https://doi.org/10.3390/bios12020069
Chicago/Turabian StylePanero, Francisco dos Santos, Oscar Smiderle, João S. Panero, Fernando S. D. V. Faria, Pedro dos S. Panero, and Anselmo F. R. Rodriguez. 2022. "Non-Destructive Genotyping of Cultivars and Strains of Sesame through NIR Spectroscopy and Chemometrics" Biosensors 12, no. 2: 69. https://doi.org/10.3390/bios12020069
APA StylePanero, F. d. S., Smiderle, O., Panero, J. S., Faria, F. S. D. V., Panero, P. d. S., & Rodriguez, A. F. R. (2022). Non-Destructive Genotyping of Cultivars and Strains of Sesame through NIR Spectroscopy and Chemometrics. Biosensors, 12(2), 69. https://doi.org/10.3390/bios12020069