
Method of Software Development Project Duration Estimation for Scrum Teams with Differentiated Specializations


Abstract
:1. Introduction
2. Literature Review
3. Results
3.1. Structuring of Software Developer Working Time
3.2. Normalized Development Estimates
3.3. System of Working Time Balance Equations
3.4. Project Duration Estimation Criteria
3.5. Method Algorithm
3.5.1. Step 1. Normalized Development Estimates
3.5.2. Step 2. Release Planning
- 1.
- Define the duration of a sprint, . As a rule, sprint duration is 2 weeks (or 80 working hours). However, it is necessary to take into account state holidays. Given that, on average, there is 1 state holiday per month, an average duration of a sprint is 76 working hours.
- 2.
- Split project implementation into phases. In this context, a project phase is a sequence of adjacent sprints united by certain intermediate goals, the same values of parameters (e.g., GPAC, , where p is an identifier of a phase), and team composition. Typical project phases are as follows: project start, team scaling, performing, stabilization, user acceptance testing, and releasing. It recommended that project phases reflect the team development stages [35].
- 3.
- Specify project scope development flag, . For example, on project start, apart from general project activities (such as setting up project infrastructure), implementation of project scope is planned. In contrast, in the stabilization and the subsequent phases, project scope development does not take phase.
- 4.
- Define number of sprints for each phase including the total number of sprints as well as the number of mandatory sprints (a mandatory sprint is a sprint that takes place regardless of the availability of the project scope to implement). For instance, the project start phase includes two sprints that are mandatory. In turn, the duration of the performing phase (where the main part of development is done) is unknown in the current step—it is found in Step 4.
- 5.
- Provide GPAC, . Values of the coefficient are usually higher in the beginning phases in comparison with the performing phase where the development team is already built and focused rather on project scope development than on general project activities. In the finalization phases, the values of the coefficient are equal to 1 since the team does only general project activities (e.g., fixing defects after regression testing, which is not the development of the project scope).
- 6.
- Specify SDAC, , for each specialization. It is worth noting that the coefficient includes such activities as writing unit tests, fixing defects related to a particular project scope item, as well as team collaboration related to development (e.g., technical meetings). The coefficient is applicable only for phases where development of project scope (i.e., ) takes place. Like , coefficients have the lowest value on the performing phase where productivity of the development team is the highest.
3.5.3. Step 3. Development Team Composition
- 1.
- First of all, it is necessary to define project roles, specializations, and competency levels. From the formal point of view, it means defining such parameters as total number of software developers, n, and CLPC, , that, in turn, for a Scrum team with differentiated specializations satisfy the condition: if is specialization of developer j, then , and for .
- 2.
- Define involvement of the team members on each phase by setting up coefficients and . It is worth noting that it is not recommended to plan a team composition with overtimes (when ) without a valid reason for that (e.g., lack of software developers of a key specialization).
- 3.
- Define non-working time specifying leaves, , and idle, time. Given that a software developer takes one unplanned day off per month (e.g., sick leave), for a sprint of 2 weeks, . As defined above, the idle time might be caused by a lack of project task (when all the scope for a particular specialization is already completed) as well as blocking by unresolved dependencies. In the second case, the risk of being blocked can be included in the estimate by specifying certain values of variable .
3.5.4. Step 4. Project Duration Estimation
3.6. Example of Applying the Method
3.6.1. Step 1. Normalized Development Estimates
3.6.2. Step 2. Release Planning
3.6.3. Step 3. Development Team Composition
3.6.4. Step 4. Project Duration Estimation
4. Discussion
4.1. Main Findings
4.2. Implications for Software Development Lifecycle
4.3. Threats to Validity
4.4. Potential Software Automation
4.5. Limitations and Future Research
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ASD | “Average” software developer |
| CAEA | Constructive agile estimation algorithm |
| CLPC | Competency level productivity coefficient |
| COCOMO | Constructive cost model |
| CPM | Critical path method |
| DWT | Development working time |
| FPA | Functional point analysis |
| GERT | Graphical evaluation and review technique |
| GPAC | General project activities coefficient |
| IPC | Involvement productivity coefficient |
| NDC | Normalized development capacity |
| NDE | Normalized development estimate |
| NDWT | Normalized development working time |
| PC | Productivity coefficient |
| PERT | Program evaluation and review technique |
| SLIM | Software lifecycle management |
| SNAP | Non-functional assessment process |
| SDAC | Supplementary development activities coefficient |
| SDLC | Software development lifecycle |
| UAT | User acceptance testing |
| UCP | Use case point analysis |
References
- Bureau of Naval Weapons, United States, Special Projects Office. Program Evaluation Research Task PERT Summary Report: Phase 1; Special Projects Office, Bureau of Naval Weapons, Department of the Navy: Monterey, CA, USA, 1958. [Google Scholar]
- Kelley, J.E.; Walker, M.R. Critical-Path Planning and Scheduling. In Proceedings of the Eastern Joint IRE-AIEE-ACM Computer Conference, Boston, MA, USA, 1–3 December 1959; Association for Computing Machinery: New York, NY, USA, 1959; pp. 160–173. [Google Scholar] [CrossRef]
- Albrecht, A.J. Measuring Application Development Productivity. In Proceedings of the IBM Applications Development Symposium, Monterey, CA, USA, 14–17 October 1979; IBM Corporation: White Plains, NY, USA, 1979. [Google Scholar]
- Boehm, B.W. Software Engineering Economics; Prentice-Hall: Hoboken, NJ, USA, 1981. [Google Scholar]
- Boehm, B.W. Software Engineering Economics. IEEE Trans. Softw. Eng. 1984, SE-10, 4–21. [Google Scholar] [CrossRef]
- Boehm, B.W.; Abts, C.; Clark, B.K.; Devnani-Chulani, S.; Horowitz, E.; Madachy, R.J.; Reifer, D.J.; Steece, B. COCOMO II Model Definition Manual, Version 2.1; Center for Software Engineering, The University of Southern California: Los Angeles, CA, USA, 1995. [Google Scholar]
- Boehm, B.W.; Abts, C.; Brown, A.W.; Devnani-Chulani, S.; Clark, B.K.; Horowitz, E.; Madachy, R.J.; Reifer, D.J.; Steece, B. Software Cost Estimation with COCOMO II; Prentice-Hall: Hoboken, NJ, USA, 2000. [Google Scholar]
- Grenning, J.W. Planning Poker or How to Avoid Analysis Paralysis While Release Planning. Hawthorn Woods Renaiss. Softw. Consult. 2002, 3, 22–23. [Google Scholar]
- Project Management Institute. Project Management Institute, A Guide To The Project Management Body Of Knowledge (PMBOK-Guide), 6th ed.; PMBOK® Guide; Project Management Institute: Pennsylvania, PA, USA, 2017. [Google Scholar]
- Batyuk, A.; Voityshyn, V. Process Mining-Based Information Technology for Operational Support of Software Projects Estimation. In Proceedings of the XVI International Scientific Conference on Intellectual Systems of Decision-Making and Problems of Computational Intelligence (ISDMCI’2020), Gliwice, Poland, 12–13 May 2020; pp. 9–11. [Google Scholar]
- Pritsker, A.A.B. GERT: Graphical Evaluation and Review Technique; RM-4973-NASA; Rand Corp.: Santa Monica, CA, USA, 1966. [Google Scholar]
- Putnam, L.H. A General Empirical Solution to the Macro Software Sizing and Estimating Problem. IIEEE Trans. Softw. Eng. 1978, SE-4, 345–361. [Google Scholar] [CrossRef]
- Putnam, L.H.; Myers, W. Measures for Excellence: Reliable Software on Time, Within Budget; Yourdon Press: New York, NY, USA, 1992. [Google Scholar]
- Ghafory, H.; Sahnosh, F.A. The Review of Software Cost Estimation Model: SLIM. Int. J. Adv. Acad. Stud. 2020, 2, 511–515. [Google Scholar]
- Karner, G. Resource Estimation for Objectory Projects. Object. Syst. SF AB 1993, 17, 9. [Google Scholar]
- Tichenor, C. A New Software Metric to Complement Function Points: The Software Non-Functional Assessment Process (SNAP). CrossTalk J. 2013, 26, 21–26. [Google Scholar]
- Mallidi, R.K.; Sharma, M. Study on Agile Story Point Estimation Techniques and Challenges. Int. J. Comput. Appl. 2021, 174, 9–14. [Google Scholar] [CrossRef]
- Coelho, E.; Basu, A. Effort Estimation in Agile Software Development Using Story Points. Int. J. Appl. Inf. Syst. 2012, 3, 7–10. [Google Scholar] [CrossRef]
- Munialo, S.W.; Muketha, G.M. A Review of Agile Software Effort Estimation Methods. Int. J. Comput. Appl. Technol. Res. 2016, 5, 612–618. [Google Scholar] [CrossRef]
- Bhalerao, S.; Ingle, M. Incorporating Vital Factors in Agile Estimation through Algorithmic Method. Int. J. Comput. Sci. Appl. 2009, 6, 85–97. [Google Scholar]
- Alshammari, F.H. Cost Estimate in Scrum Project with the Decision-Based Effort Estimation Technique. Soft Comput. 2022. [Google Scholar] [CrossRef]
- Sudarmaningtyas, P.; Mohamed, R. A Review Article on Software Effort Estimation in Agile Methodology. Pertanika J. Sci. Technol. 2021, 29, 837–861. [Google Scholar] [CrossRef]
- Usman, M.; Mendes, E.; Weidt, F.; Britto, R. Effort Estimation in Agile Software Development: A Systematic Literature Review. In Proceedings of the 10th International Conference on Predictive Models in Software Engineering, Turin, Italy, 17 September 2014; pp. 82–91. [Google Scholar] [CrossRef]
- Saeed, A.; Butt, W.H.; Kazmi, F.; Arif, M. Survey of Software Development Effort Estimation Techniques. In Proceedings of the 2018 7th International Conference on Software and Computer Applications (ICSCA 2018), Kuantan, Malaysia, 8–10 February 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 82–86. [Google Scholar] [CrossRef]
- Vyas, M.; Bohra, A.; Lamba, D.C.S.; Vyas, A. A Review on Software Cost and Effort Estimation Techniques for Agile Development Process. Int. J. Recent Res. Asp. 2018, 5, 1–5. [Google Scholar]
- Habibi, F.; Birgani, O.T.; Koppelaar, H.; Radenović, S.N. Using Fuzzy Logic to Improve the Project Time and Cost Estimation Based on Project Evaluation and Review Technique (PERT). J. Proj. Manag. 2018, 3, 183–196. [Google Scholar] [CrossRef]
- Nassif, A.B.; Azzeh, M.; Idri, A.; Abran, A. Software Development Effort Estimation Using Regression Fuzzy Models. Comput. Intell. Neurosci. 2019, 2019, 8367214. [Google Scholar] [CrossRef] [PubMed]
- van Dorp, J.R. A Dependent Project Evaluation and Review Technique: A Bayesian Network Approach. Eur. J. Oper. Res. 2020, 280, 689–706. [Google Scholar] [CrossRef]
- Shabeer, M.K.P.; Krishnan, S.I.U.; Deepa, G. Software Effort Estimation Using Genetic Algorithms with the Variance-Accounted-for (VAF) and the Manhattan Distance. In Ubiquitous Intelligent Systems; Smart Innovation, Systems and Technologies; Karuppusamy, P., Perikos, I., García Márquez, F.P., Eds.; Springer: Singapore, 2021; Volume 243, pp. 421–434. [Google Scholar] [CrossRef]
- Satapathy, S.M.; Acharya, B.P.; Rath, S.K. Early Stage Software Effort Estimation Using Random Forest Technique Based on Use Case Points. Inst. Eng. Technol. Softw. 2016, 10, 10–17. [Google Scholar] [CrossRef]
- Mahmood, Y.; Kama, N.; Azmi, A.; Khan, A.S.; Ali, M. Software Effort Estimation Accuracy Prediction of Machine Learning Techniques: A Systematic Performance Evaluation. J. Softw. Pract. Exp. 2021, 52, 39–65. [Google Scholar] [CrossRef]
- Trendowicz, A.; Jeffery, R. Classification of Effort Estimation Methods. In Software Project Effort Estimation; Springer: Cham, Switzerland, 2014; pp. 155–208. [Google Scholar] [CrossRef]
- Zarour, A.; Zein, S. Software Development Estimation Techniques in Industrial Contexts: An Exploratory Multiple Case-Study. Int. J. Technol. Educ. Sci. 2019, 3, 72–84. [Google Scholar]
- Boehm, B.; Abts, C.; Chulani, S. Software Development Cost Estimation Approaches—A Survey. Ann. Softw. Eng. 2000, 10, 177–205. [Google Scholar] [CrossRef]
- Tuckman, B.W. Developmental Sequence in Small Groups. Psychol. Bull. 1965, 63, 384–399. [Google Scholar] [CrossRef] [PubMed]
- van der Aalst, W.M.P. Process Mining: Data Science in Action, 2nd ed.; Springer: Berlin, Germany, 2016. [Google Scholar] [CrossRef]
- Di Ciccio, C.; Marrella, A.; Russo, A. Knowledge-Intensive Processes: Characteristics, Requirements and Analysis of Contemporary Approaches. J. Data Semant. 2015, 4, 29–57. [Google Scholar] [CrossRef]
- Kumar, R.; Khan, S.A.; Khan, R.A. Durability Challenges in Software Engineering. J. Def. Softw. Eng. 2016, 42, 29–31. [Google Scholar]
- Khan, S.A.; Alenezi, M.; Agrawal, A.; Kumar, R.; Khan, R.A. Evaluating Performance of Software Durability through an Integrated Fuzzy-Based Symmetrical Method of ANP and TOPSIS. Symmetry 2020, 12, 493. [Google Scholar] [CrossRef]
- Sahu, K.; Shree, R.; Kumar, R. Risk Management Perspective in SDLC. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2014, 4, 1247–1251. [Google Scholar]

{kind=link}
{kind=link}
| No. | Estimation Method | Abbreviation | Category 1 | SDLC Stage 2 | Basic Measure Unit 3 | Usage of Historical Data | Relying on Expert Judgement |
|---|---|---|---|---|---|---|---|
| 1 | Project evaluation and review technique | PERT | Expertise-based | Analysis and design (ending), implementation | Man-hour | No | Yes |
| 2 | Critial path method | CPM | Expertise-based | Analysis and design (ending), implementation | Man-hour | No | Yes |
| 3 | Graphical evaluation and review technique | GERT | Expertise-based | Analysis and design (ending), implementation | Man-hour | No | Yes |
| 4 | Software lifecycle management | SLIM | Model-based | Analysis and design | Effective LOC | Yes | No |
| 5 | Functional point analysis | FPA | Model-based | Analysis and design | Function point | Yes | No |
| 6 | Use case point analysis | UCP | Model-based | Analysis and design | Use case point | Yes | No |
| 7 | Software non-functional assessment process | SNAP | Model-based | Analysis and design | SNAP point | Yes | No |
| 8 | Constructive cost model | COCOMO | Model-based | Analysis and design | LOC | Yes | No |
| 9 | Constructive cost model II | COCOMO II | Composite | Analysis and design | LOC, function point, use case point | Yes | Yes 4 |
| 10 | Planning poker and its modifications | n/a | Expertise-based | Implementation | Story point | No | Yes |
| 11 | Constructive Agile Estimation Algorithm | CAEA | Model-based, Expertise-based | Analysis and Design, Implementation | Story point | Yes | Yes |
| 12 | Estimation of project duration for Scrum team with differentiated specializations | n/a | Expertise-based | Analysis and design (beginning) | Man-hour | No | Yes |
| Specialization Identifier, s | Specialization Name | , Man-Hours | , Man-Hours |
|---|---|---|---|
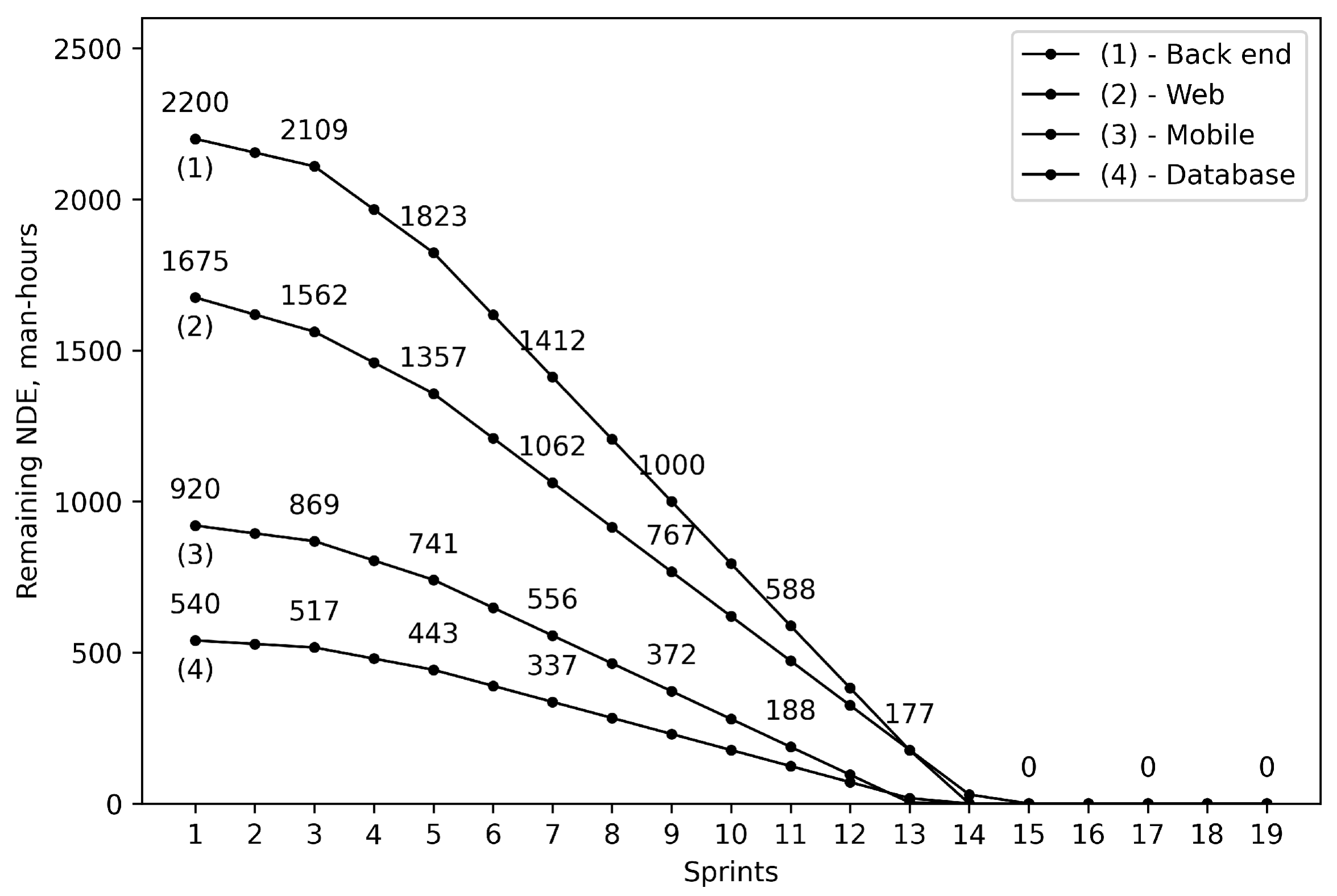
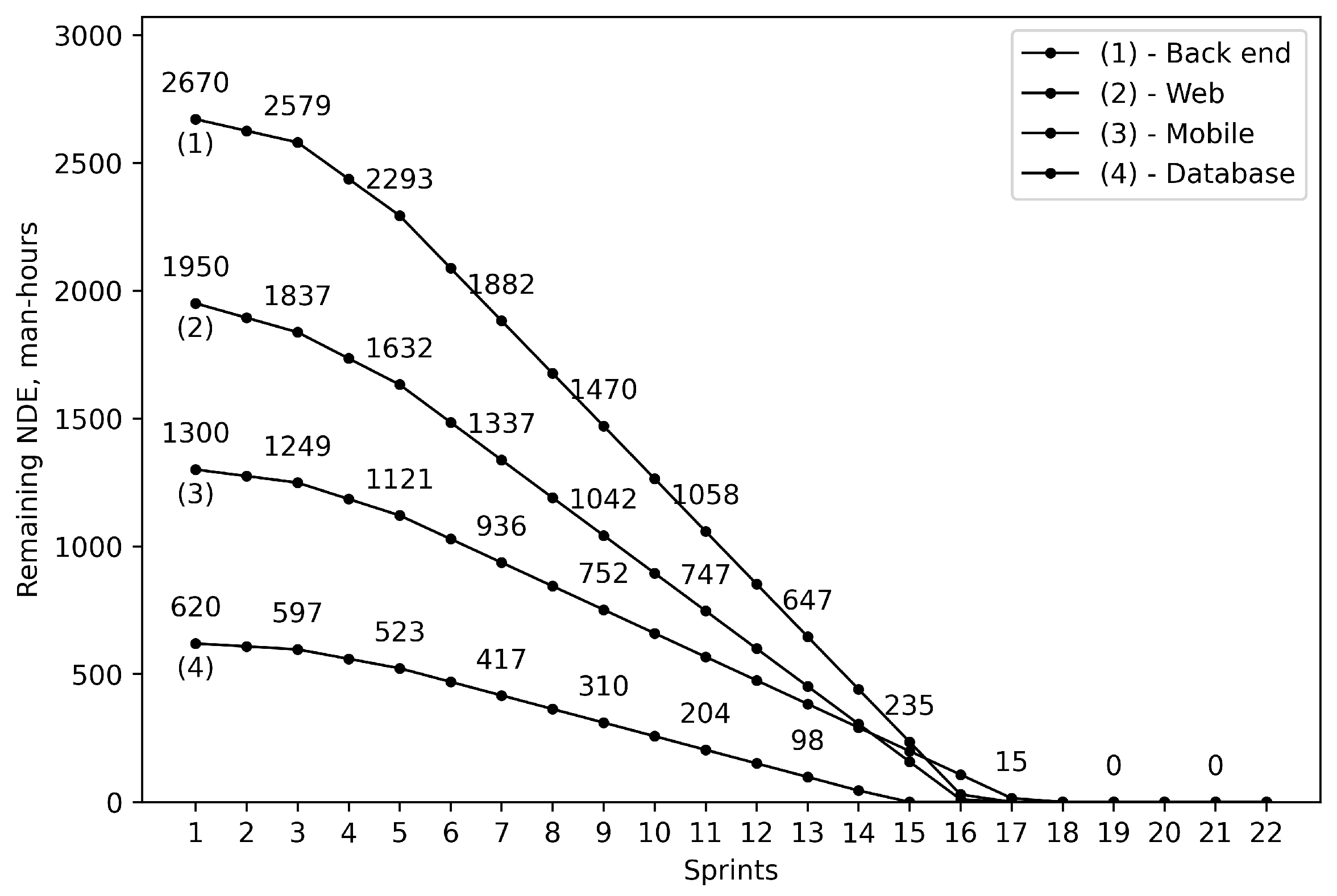
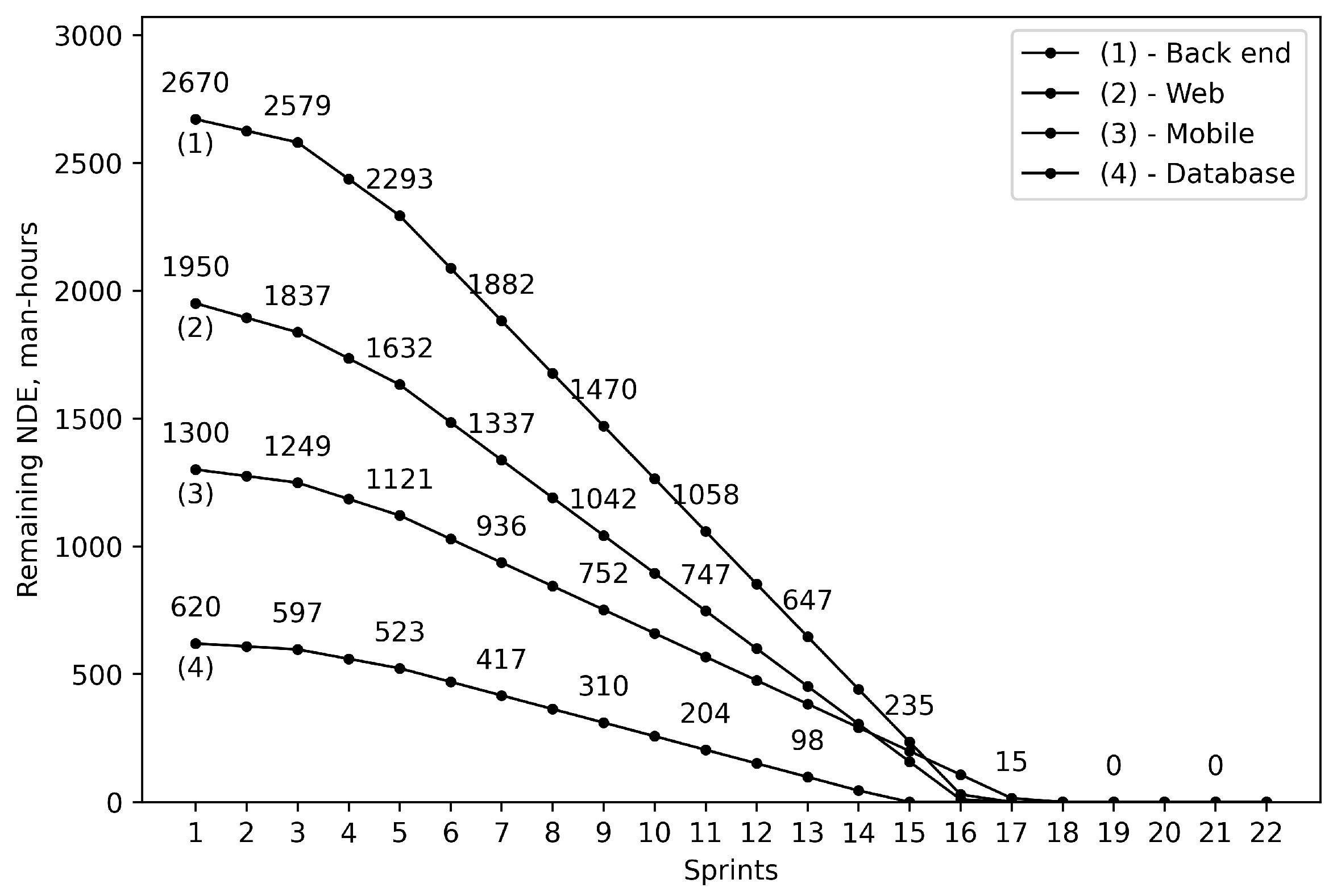
| 1 | Back end | 2200 | 2670 |
| 2 | Web | 1675 | 1950 |
| 3 | Mobile | 920 | 1300 |
| 4 | Database | 540 | 620 |
| Phase Identifier, p | Phase Name | Total Number of Sprints | Number of Mandatory Sprints 1 | , Hours 2 | Development Team | |||
|---|---|---|---|---|---|---|---|---|
| a | Project start | 2 | 2 | 152 | Core team | 0.50 | 0.40 | 1 |
| b | Team scaling | 2 | 0 | 152 | Whole team | 0.40 | 0.35 | 1 |
| c | Performing | 0 | Whole team | 0.20 | 0.25 | 1 | ||
| d | Stabilization | 1 | 1 | 76 | Whole team | 1.00 | n/a | 0 |
| e | UAT | 2 | 2 | 152 | Reduced team | 1.00 | n/a | 0 |
| f | Releasing | 2 | 2 | 152 | Reduced team | 1.00 | n/a | 0 |
| Software Developer Identifier, j | Project Role | Competency Level | s | 1 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Technical leader and back-end engineer | Senior | 1 | 1.2 | 0.5 | 0.5 | 0.50 | 0.50 | 0.5 | 0.5 |
| 2 | Back-end engineer | Senior | 1 | 1.2 | 1 | 1 | 1 | 1 | 0 | 0 |
| 3 | Back-end engineer | Middle | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 4 | Back-end engineer | Middle | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| 5 | Back-end engineer | Junior | 1 | 0.7 | 1 | 1 | 1 | 1 | 1 | 1 |
| 6 | Front-end engineer | Senior | 2 | 1.2 | 1 | 1 | 1 | 1 | 0 | 0 |
| 7 | Front-end engineer | Middle | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 8 | Front-end engineer | Middle | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 9 | Mobile engineer | Middle | 3 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 10 | Mobile engineer | Middle | 3 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| 11 | Database engineer | Senior | 4 | 1.2 | 0.5 | 0.5 | 0.50 | 0.50 | 0.5 | 0.5 |
| 12 | Database engineer | Junior | 4 | 0.7 | 1 | 1 | 1 | 1 | 0 | 0 |
| No. | Estimation Stage | Estimation Goals | Estimate Accuracy 1 | Using Estimates for Commitments | SDLC Stage |
|---|---|---|---|---|---|
| 1 | Preliminary estimation | Roughly understand the required resources and timeline | Very low accuracy | Strictly not recommended | Ideation |
| 2 | Intermediate estimation | Provide more accurate estimates than on the previous stage | Low accuracy | Not recommended | Analysis and design (beginning) |
| 3 | Precise estimation and release planning | Prepare definite estimates [9] and detailed release plan | Acceptable accuracy | Can be recommended | Analysis and design (ending) |
| 4 | Implementation monitoring | Compare estimates with actually spent efforts and clarify remaining estimates | Continuously adjusting accuracy | Can be recommended | Implementation |
| 5 | Finalizing feedback on estimates | Finalize feedback on estimates | n/a | n/a | Finalization |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Teslyuk, V.; Batyuk, A.; Voityshyn, V. Method of Software Development Project Duration Estimation for Scrum Teams with Differentiated Specializations. Systems 2022, 10, 123. https://doi.org/10.3390/systems10040123
Teslyuk V, Batyuk A, Voityshyn V. Method of Software Development Project Duration Estimation for Scrum Teams with Differentiated Specializations. Systems. 2022; 10(4):123. https://doi.org/10.3390/systems10040123
Chicago/Turabian StyleTeslyuk, Vasyl, Anatoliy Batyuk, and Volodymyr Voityshyn. 2022. "Method of Software Development Project Duration Estimation for Scrum Teams with Differentiated Specializations" Systems 10, no. 4: 123. https://doi.org/10.3390/systems10040123
APA StyleTeslyuk, V., Batyuk, A., & Voityshyn, V. (2022). Method of Software Development Project Duration Estimation for Scrum Teams with Differentiated Specializations. Systems, 10(4), 123. https://doi.org/10.3390/systems10040123