1. Introduction
The rapid influx of populations into urban areas presents many challenges, ranging from resource constraints to heightened traffic and escalating greenhouse gas (GHG) emissions [
1]. Many cities globally are transitioning towards ‘smart cities’ to handle these multifaceted urban issues efficiently [
2]. At its core, a smart city aims to enhance its inhabitants’ efficiency, safety, and living standards [
3]. For example, smart cities tackle GHG emissions by reducing traffic congestion, optimizing energy usage, and incorporating alternatives, such as electric vehicles, energy storage systems (ESSs), and sustainable energy sources [
4]. A significant portion of urban GHG emissions is attributed to building electricity consumption, which powers essential systems and amenities such as heating, domestic hot water (DHW), ventilation, lighting, and various electronic appliances [
5]. Thus, advancing energy efficiency in urban buildings, especially through the integration of energy storage and renewable energy sources, is paramount. Recognizing this, many smart city designs have embraced integrated systems such as building energy management systems (BEMSs) to boost the energy efficiency of existing infrastructure [
6].
A BEMS is a technology-driven tool that harnesses the capabilities of the Internet of Things (IoT) [
7] and big data analytics [
8] to specifically regulate and monitor building electricity consumption. Electricity accounts for a substantial portion of a building’s energy profile, powering everything from lighting and heating to advanced electronic appliances. One of the cardinal functions of a BEMS is short-term load forecasting (STLF) for electricity [
9]. Accurate STLF is essential as it enables facilities to trade surplus electricity, foster economic benefits, and precisely manage power loads, thereby preventing blackouts by moderating peak electrical demands [
10]. However, mastering STLF for electricity consumption is an intricate task. This is because buildings exhibit diverse and complex electricity consumption patterns with a non-linear relationship with several external factors such as weather, occupancy, and time of day [
11]. Additionally, the inherent noise in electricity consumption data further muddles the forecasting process, making accurate predictions challenging [
12]. Given these complexities, many researchers have turned to artificial intelligence (AI) as a promising approach for building electricity consumption forecasting. AI techniques excel in deciphering the recent trends in electricity consumption and processing the intricate, non-linear interactions between various influencing factors and electricity demand [
13].
Recent research underscores the intricate dynamics governing building energy performance. Several factors, both internal, such as building orientation, and external, such as climatic changes, play pivotal roles. These complexities can be unraveled through mathematical modeling, leading to the formulation of more accurate regression models [
14]. Delving into the digital realm, machine learning (ML) stands out as a potent tool. With the support of vast datasets and advanced computing, ML offers groundbreaking solutions for predicting energy demands [
15]. Its potential is evident throughout a building’s lifecycle, impacting both its design and operation phases. However, the journey to its broad acceptance presents numerous challenges. Two notable hurdles include the necessity for extensive labeled data and concerns regarding model transferability. In response to these challenges, innovative strategies have emerged. One notable approach is the introduction of easy-to-install forecast control systems designed for heating. These systems prove especially beneficial for older structures that necessitate detailed documentation [
16]. Such systems not only exemplify technical advancements but also adapt to diverse inputs, considering factors from weather conditions to occupant preferences, ensuring an optimal balance between energy efficiency and occupant comfort.
Building on the promise of ML, as highlighted in recent research, traditional AI techniques, including ML [
13] and deep learning (DL) [
17], have indeed been extensively employed to develop forecasting models. Several ML approaches have been explored, showcasing innovative methodologies to predict hourly or peak energy consumption. Granderson et al. [
18] focused on the versatility of regression models in predicting hourly energy consumption. By emphasizing its applicability in STLF, their model showcased its potential in the broader realm of energy management. Huang et al. [
19] presented a multivariate empirical mode decomposition-based model that harmoniously integrated particle swarm optimization (PSO) and support vector regression for day-ahead peak load forecasting. Li et al. [
20] pioneered a data-driven strategy for STLF by integrating cluster analysis, Cubist regression models, and PSO, presenting an innovative approach that balanced multiple techniques for improved forecasting. Moon et al. [
21] introduced the ranger-based online learning approach, called RABOLA, a testament to adaptive forecasting specially tailored for buildings with intricate power consumption patterns. This model prioritized real-time, multistep-ahead forecasting, demonstrating its potential in dynamic environments.
While traditional ML methods have significantly advanced energy forecasting, the advent of DL, especially convolutional neural networks (CNNs) and recurrent neural networks (RNNs), has opened new horizons. These neural networks have set a precedent for understanding intricate data patterns, paving the way for more sophisticated forecasting methodologies [
22]. Compared to traditional ML and mathematical methods, these models stand out due to their learning capabilities and generalization ability [
13]. Understanding the characteristics of building electricity consumption data, including time-based [
23] and spatial features [
24], is essential for efficiently applying these DL models. Despite these sophisticated techniques, the models often deliver unreliable, low forecasts [
25]. They need help with several challenges, such as issues related to short-term memory, overfitting, learning from scratch, and understanding complex variable correlations. Some researchers have investigated hybrid models to overcome these challenges, as single models frequently have difficulties learning time-based and spatial features simultaneously [
13].
Building upon the aforementioned advances in forecasting techniques, a multitude of studies, including those mentioned above, have delved into the realm of STLF. These collective efforts spanning several years are comprehensively summarized in
Table 1. Taking a leaf from hybrid model designs, Aksan et al. [
26] introduced models that combined variational mode decomposition (VMD) with DL models, such as CNN and RNNs. Their models, VMD-CNN-long short-term memory (LSTM) and VMD-CNN-gated recurrent unit (GRU), showcased versatility, adeptly managing seasonal and daily energy consumption variations. Wang et al. [
27], in their recent endeavors, proposed a wavelet transform neural network that uniquely integrates time and frequency-domain information for load forecasting. Their model leveraged three cutting-edge wavelet transform techniques, encompassing VMD, empirical mode decomposition (EMD), and empirical wavelet transform (EWT), presenting a comprehensive approach to forecasting. Zhang et al. [
28] emphasized the indispensable role of STLF in modern power systems. They introduced a hybrid model that combined EWT with bidirectional LSTM. Moreover, their model integrated the Bayesian hyperparameter optimization algorithm, refining the forecasting process. Saoud et al. [
29] ventured into wind speed forecasting and introduced a model that amalgamated the stationary wavelet transform with quaternion-valued neural networks, marking a significant stride in renewable energy forecasting.
Kim et al. [
30] seamlessly merged the strengths of RNN and one-dimensional (1D)-CNN for STLF, targeting the refinement of prediction accuracy. They adjusted the hidden state vector values to suit closely better-occurring prediction times, showing a marked evolution in prediction approaches. Jung et al. [
31] delved into attention mechanisms (Att) with their Att-GRU model for STLF. Their approach was particularly noteworthy for adeptly managing sudden shifts in power consumption patterns. Zhu et al. [
32] showcased an advanced LSTM-based dual-attention model, meticulously considering the myriad of influencing factors and the effects of time nodes on STLF. Liao et al. [
33], with their innovative fusion of LSTM and a time pattern attention mechanism, augmented STLF methodologies, emphasizing feature extraction and model versatility. By incorporating external factors, their comprehensive approach improved feature extraction and demonstrated superior performance compared to existing methods. While effective, their model should have capitalized on the strengths of hybrid DL models, such as GRU and temporal convolutional network (TCN), which could be used to handle both long-term dependencies and varying input sequence lengths [
34].
BiGTA-net is introduced as a novel hybrid DL model that seamlessly integrates the strengths of a bi-directional gated recurrent unit (Bi-GRU), a temporal convolutional network (TCN), and an attention mechanism. These components collectively address the persistent challenges encountered in STLF. The conventional DL models sometimes require assistance in dealing with intricate nonlinear dependencies. However, the amalgamation within the proposed model represents an innovative approach for capturing long-term data dependencies and effectively handling diverse input sequences. Moreover, the incorporation of the attention mechanism within BiGTA-net optimizes the weighting of features, thereby enhancing predictive accuracy. This research establishes its unique contribution within the energy management and load forecasting domains, which can be attributed to the following key contributions:
BiGTA-net emerges as a pioneering hybrid DL model designed to enhance day-ahead forecasting within power system operation, prioritizing accuracy.
The experimental framework employed for testing BiGTA-net’s capabilities is strategically devised, showcasing its adaptability and resilience across different models and configurations.
Utilizing data sourced from a range of building types, the approach employed in this study establishes the widespread applicability and adaptability of BiGTA-net across diverse consumption scenarios.
The structure of this paper is outlined as follows:
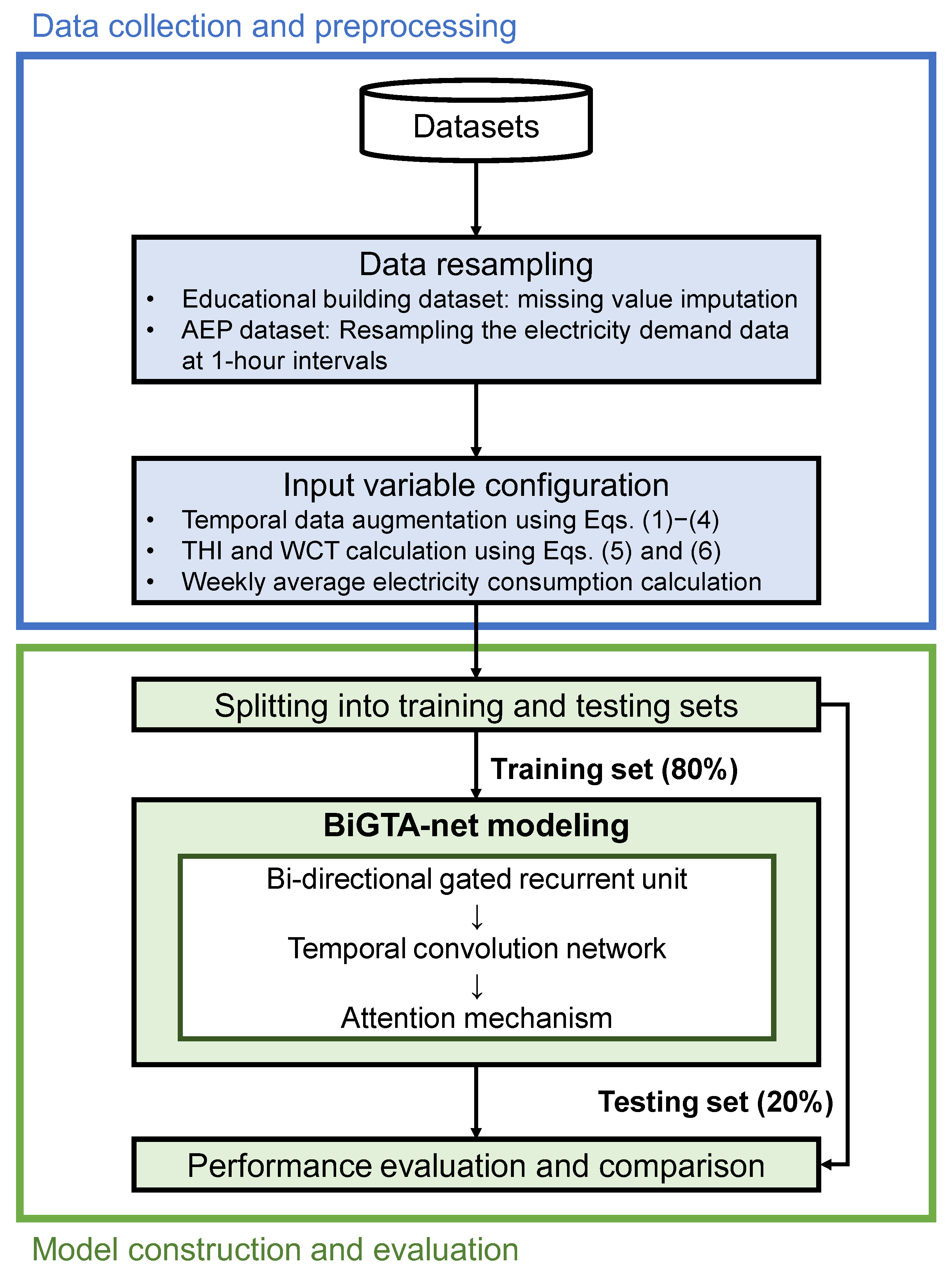
Section 2 elaborates on the configuration of input variables that are crucial to the STLF model and discusses the proposed hybrid deep learning model, BiGTA-net. In
Section 3, the performance of the model is thoroughly examined through extensive experimentation. Finally,
Section 4 encapsulates the findings and provides an overview of the study.
3. Results and Discussion
3.1. Evaluation Criteria
To evaluate the predictive capabilities of the forecasting model, a variety of performance metrics were utilized, including mean absolute percentage error (MAPE), root mean square error (RMSE), and mean absolute error (MAE). These metrics hold widespread recognition and offer a robust assessment of prediction accuracy [
50].
The MAPE serves as a valuable statistical measure of prediction accuracy, particularly pertinent in the context of trend forecasting. This metric quantifies the error as a percentage, rendering the outcomes intuitively interpretable. While the MAPE may become inflated when actual values approach zero, this circumstance does not apply to the dataset under consideration. The calculation of MAPE is performed using Equation (7).
where Y
t and Ŷ
t represent the actual and predicted values, respectively, and n represents the total number of observations.
The RMSE, or the root mean square deviation, aggregates the residuals to provide a single metric of predictive capability. The RMSE, calculated using Equation (8), is the square root of the average squared differences between the forecast values (Ŷ
t) and the actual values (Y
t). The RMSE equals the standard deviation for an unbiased estimator, indicating the standard error.
The MAE is a statistical measure used to gauge the proximity of predictions or forecasts to the eventual outcomes. This metric is calculated by considering the average of the absolute differences between the predicted and actual values. Equation (9) outlines the calculation for the MAE.
3.2. Experimental Design
The experiments were conducted in an environment that utilized Python (v.3.8) [
51], complemented by machine learning libraries such as scikit-learn (v.1.2.1) [
52] and Keras (v.2.9.0) [
44,
53]. The computational resources included an 11th Gen Intel(R) Core(TM) i9-11900KF CPU operating at 3.50 GHz, an NVIDIA GeForce RTX 3070 GPU, and 64.0GB of RAM. The proposed BiGTA-net model was evaluated against various well-regarded RNN models, such as LSTM, Bi-LSTM, GRU, and GRU-TCN. The hyperparameters were standardized across all models to ensure a fair and balanced comparison. This approach minimized potential bias in the evaluation results due to model-specific preferences or advantageous parameter settings. The common set of hyperparameters for all the models included 25 training epochs, a batch size of 24, and the Adam optimizer with a learning rate of 0.001 [
54]. The MAE was chosen as the key metric for evaluating the performance of the models, providing a standardized measure of comparison.
The training dataset for the BiGTA-net model was constructed by utilizing hourly electrical consumption data from 1 to 7 March 2015, for the educational building dataset, and from 11 to 17 January 2016, for the AEP dataset. In the case of the educational building dataset, the data spanning from 8 March 2015, to 28 February 2019, was allocated for training, while the subsequent period, 1 March 2019, to 29 February 2020, was designated as the testing set. For the AEP dataset, data ranging from 18 January to 30 April 2016, was employed for training purposes, with the timeframe between 1 and 27 May 2016, reserved for testing. The dataset was partitioned into training (in-sample) and testing (out-of-sample) subsets, maintaining an 80:20 ratio. Prior to the division, min–max scaling was applied to the training data, standardizing the raw electricity consumption values within a specific range. This scaling transformation was subsequently extended to the testing data, ensuring uniformity in the range of both training and testing datasets. This process ensured that the original data scale did not influence the model’s performance.
3.3. Experimental Results
In the experimental outcomes, the performances of diverse model configurations were initially investigated, as presented in
Table 4. Specifically, a total of 16 models with varying network architectures, activation functions, and the incorporation of the attention mechanism were evaluated. Among the specifics detailed in
Table 4, the prominent focus is on the Bi-GRU-TCN-I model, alternatively known as BiGTA-net, which was proposed in this study. This particular model embraced the Bi-GRU-TCN architecture, utilized the SELU activation function, and integrated the attention mechanism, setting it apart from the remaining models.
The performance of these models was evaluated using three key metrics: MAPE, RMSE, and MAE, as presented in
Table 5,
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10. The experimental results were divided into two main categories, results obtained from the educational building dataset and the AEP dataset.
In the context of the educational building dataset, the proposed model (Bi-GRU-TCN-I) consistently showcased superior performance in comparison to alternative model configurations. As illustrated in
Table 5, the proposed model achieved the lowest MAPE, underscoring its heightened predictive accuracy. Strong corroboration for its superior performance is also substantiated by the findings presented in
Table 6 and
Table 7, where the proposed model demonstrates the least RMSE and MAE values, respectively, signifying a close alignment between the model’s predictions and actual values.
Table 5 demonstrates that among all models, the proposed Bi-GRU-TCN-I model boasts the best MAPE performance with an average of 5.37. The Bi-GRU-TCN-II model follows closely with a MAPE of 5.39. When exploring the performance of LSTM-based models, LSTM-TCN-III emerges as a top contender with a MAPE of 5.59, which, although commendable, is still higher than the leading Bi-GRU-TCN-I model. The Bi-LSTM-TCN results, on the other hand, range from 6.90 to 8.53, further emphasizing the efficacy of the BiGTA-net. Traditional GRU-TCN models displayed a wider variation in MAPE values, from 5.68 to 6.50.
In
Table 6, when assessing RMSE values, the proposed BiGTA-net model (Bi-GRU-TCN-I) again leads the pack with a score of 171.3. This result is significantly better than all other models, with the closest competitor being Bi-GRU-TCN-II at 169.5 RMSE. Among the LSTM variants, LSTM-TCN-I holds the most promise, with an RMSE of 134.8. However, the Bi-GRU models are generally superior in predicting values closer to the actual values, underscoring their robustness.
Table 7, although not provided in its entirety, indicates the reliability of BiGTA-net with the lowest MAE of 122.0. Bi-GRU-TCN-II closely follows with an MAE of 122.7. As observed from previous results, other models, potentially including the LSTM and Bi-LSTM series, reported higher MAE scores, ranging between 131.6 and 153.7.
In the context of the AEP dataset, as demonstrated in
Table 8,
Table 9 and
Table 10, the proposed model (Bi-GRU-TCN-I) showcased competitive performance. While marginal differences were observed among the various model configurations, the Bi-GRU-TCN-I model consistently outperformed the alternative models in terms of MAPE, RMSE, and MAE metrics.
In
Table 8, which presents the MAPE comparison for the AEP dataset, the proposed model, Bi-GRU-TCN-I, still manifests the lowest average MAPE of 26.77. This result emphasizes its unparalleled predictive accuracy among all tested models. Delving into the LSTM family, the LSTM-TCN-I achieved an average MAPE of 28.42, while the Bi-LSTM-TCN-I recorded an average MAPE of 29.12. It is notable that while these models exhibit competitive performance, neither managed to outperform the BiGTA-net.
Table 9, focused on the RMSE comparison, depicts the Bi-GRU-TCN-I model registering an RMSE of 375.9 on step 1. This performance, when averaged, proves to be competitive with the other models, especially when considering the range for all the models, which goes as low as 369.1 for Bi-GRU-TCN-III and as high as 622.2 for Bi-LSTM-TCN-III. Looking into the LSTM family, LSTM-TCN-I kicked off with an RMSE of 473.6, whereas Bi-LSTM-TCN-I began with 431.1. This further accentuates the superiority of the BiGTA-net in terms of prediction accuracy.
Finally, in
Table 10, where MAE values are compared, the Bi-GRU-TCN-I model still shines with an MAE of 198.4. This consistently low error rate across different evaluation metrics underscores the robustness of the BiGTA-net across various datasets.
In summary, the proposed model, Bi-GRU-TCN-I, designated as BiGTA-net, exhibited exceptional performance across both datasets, affirming its efficacy and dependability in precise electricity consumption forecasting. These outcomes serve to substantiate the benefits derived from the incorporation of the Bi-GRU-TCN architecture, utilization of the SELU activation function, and integration of the attention mechanism, thereby validating the chosen design approaches.
To evaluate the performance of the BiGTA-net model, a comprehensive comparative analysis was conducted. This analysis included models such as Att-LSTM, Att-Bi-LSTM, Att-GRU, and Att-Bi-GRU, all of which integrate the attention mechanism, a characteristic known for enhancing prediction capabilities. Furthermore, this evaluation also incorporated several state-of-the-art methodologies introduced over the past three years, offering a robust understanding of BiGTA-net’s performance relative to contemporary models:
Park and Hwang [
55] introduced the LGBM-S2S-Att-Bi-LSTM, a two-stage methodology that merges the functionalities of the light gradient boosting machine (LGBM) and sequence-to-sequence Bi-LSTM. By employing LGBM for single-output predictions from recent electricity data, the system transitions to a Bi-LSTM reinforced with an attention mechanism, adeptly addressing multistep-ahead forecasting challenges.
Moon et al. [
21] presented RABOLA, previously touched upon in the Introduction section. This model is an innovative ranger-based online learning strategy for electricity consumption forecasts in intricate building structures. At its core, RABOLA utilizes ensemble learning strategies, specifically bagging, boosting, and stacking. It employs tools, namely, the random forest, gradient boosting machine, and extreme gradient boosting, for STLF while integrating external variables such as temperature and timestamps for improved accuracy.
Khan et al. [
56] unveiled the ResCNN-LSTM, a segmented framework targeting STLF. The primary phase is data driven, ensuring data quality and cleanliness. The next phase combines a deep residual CNN with stacked LSTM. This model has shown commendable performance on the Individual Household Electricity Power Consumption (IHEPC) and Pennsylvania, Jersey, and Maryland (PJM) datasets.
Khan et al. [
57] also introduced the Att-CNN-GRU, blending CNN and GRU and enriching with a self-attention mechanism. This model specializes in analyzing refined electricity consumption data, extracting pivotal features via CNN, and subsequently transitioning the output through GRU layers to grasp the temporal dynamics of the data.
Table 11 elucidates the comparative performance of several attention-incorporated models on the educational building dataset, with the BiGTA-net model’s performance distinctly superior. Specifically, BiGTA-net records a MAPE of 5.37 (±0.44%), RMSE of 171.3 (±15.0 kWh), and MAE of 122.0 (±10.5 kWh). The Att-LSTM model, a unidirectional approach, records a MAPE of 8.38 (±1.57%), RMSE of 242.1 (±48.2 kWh), and MAE of 188.8 (±39.5 kWh). Its bidirectional sibling, the Att-Bi-LSTM, delivers a slightly better MAPE at 7.85 (±0.70%) but comparable RMSE and MAE values. Interestingly, GRU-based models, such as Att-GRU and Att-Bi-GRU, lag with higher error metrics, the former recording a MAPE of 13.42 (±3.39%). The 2023 Att-CNN-GRU model reports a MAPE of 6.35 (±0.23%), an RMSE of 189.6 (±5.3 kWh), still falling short compared to the BiGTA-net. The RAVOLA model from 2022 registers an impressive MAPE of 7.17 (±0.63%), but again, BiGTA-net outperforms it. In essence, these results demonstrate the BiGTA-net’s unparalleled efficiency when measured against traditional unidirectional models and newer advanced techniques.
Table 12 unveils the comparative performance metrics of various attention-incorporated models using the AEP dataset. Distinctly, the BiGTA-net model consistently outperforms its peers, equipped with a sophisticated blend of the attention mechanism and SELU activation within its bidirectional framework. This model impressively returns a MAPE of 26.77 (±0.90%), RMSE of 386.5 (±6.3 Wh), and MAE of 198.4 (±3.2 Wh). The Att-LSTM model offers a MAPE of 30.91 (±1.03%), RMSE of 447.4 (±5.3 Wh), and MAE of 239.8 (±5.3 Wh). Its bidirectional counterpart, the Att-Bi-LSTM, shows a modest enhancement, delivering a MAPE of 30.54 (±2.58%), RMSE of 402.7 (±8.9 Wh), and MAE of 214.0 (±7.3 Wh). The GRU-based models present a close-knit performance. For instance, the Att-GRU model achieves a MAPE of 30.03 (±0.25%), RMSE of 443.5 (±3.9 Wh), and MAE of 234.5 (±2.4 Wh), while the Att-Bi-GRU mirrors this with slightly varied figures. The 2023 model, Att-CNN-GRU, logs a MAPE of 29.94 (±1.73%), RMSE of 405.1 (±9.7 Wh), yet its precision remains overshadowed by BiGTA-net. RAVOLA, a 2022 entrant, exhibits metrics such as a MAPE of 35.89 (±5.78%), emphasizing the continual advancements in the domain. The disparities in performance underscore BiGTA-net’s superiority. Models that lack the refined structure of BiGTA-net falter in their forecast accuracy, thereby underscoring the merits of the introduced architecture.
The combination of Bi-GRU and TCN, along with the integration of attention mechanisms and the adoption of the SELU activation function, synergistically reinforced BiGTA-net as a robust model. The experimental results consistently demonstrated BiGTA-net’s exceptional performance across diverse datasets and metrics, highlighting the model’s efficacy and flexibility in different forecasting contexts. These results decisively endorsed the effectiveness of the hybrid approach utilized in this study.
3.4. Discussion
To highlight the effectiveness of the BiGTA-net model, rigorous statistical analysis was employed, utilizing both the Wilcoxon signed-rank [
58] and the Friedman [
59] tests.
Wilcoxon Signed-Rank Test: The Wilcoxon signed-rank test [
58], a non-parametric counterpart for the paired t-test, is formulated to gauge differences between two paired samples. Mathematically, given two paired sets of observations, x and y, the differences d
i = y
i – x
i are computed. Ranks are then assigned to the absolute values of these differences, and subsequently, these ranks are attributed either positive or negative signs depending on the sign of the original difference. The test statistic W is essentially the sum of these signed ranks. Under the null hypothesis, it is assumed that W follows a specific symmetric distribution. Suppose the computed p-value from the test is less than the chosen significance level (often 0.05). We have grounds to reject the null hypothesis in that case, implying a statistically significant difference between the paired samples.
Friedman Test: The Friedman test [
59] is a non-parametric alternative to the repeated measures ANOVA. At its core, this test ranks each row (block) of data separately. The differences among the columns (treatments) are evaluated using the ranks. This expression is mathematically captured in the following expression, referred to as Equation (10).
where
is the number of blocks,
is the number of treatments, and
is the sum of the ranks for the jth treatment. The observed value of
is then compared with the critical value from the
distribution with
degrees of freedom.
The meticulous validation, as demonstrated in
Table 13 and
Table 14, underscores the proficiency of BiGTA-net in the context of energy management. To fortify the conclusions drawn from the analyses, the approach was anchored on three crucial metrics: MAPE, RMSE, and MAE. The data were aggregated across all deep learning models, focusing on 24 h forecasts at hourly intervals. Comprehensive results stemming from the Wilcoxon and Friedman tests, each grounded in the metrics, are presented in
Table 13 and
Table 14. A perusal of the table illustrates the distinct advantage of BiGTA-net, with p-values consistently falling below the 0.05 significance threshold across varied scenarios and metrics.
Delving deeper into the tables, the BiGTA-net consistently outperforms other models in both datasets. The exceptionally low
p-values from the Wilcoxon and Friedman tests indicate significant differences between the BiGTA-net and its competitors. In almost every instance, other models were lacking when juxtaposed against the BiGTA-net’s results. This empirical evidence is vital in understanding the superior capabilities of the BiGTA-net in energy forecasting. Furthermore, the fact that the
p-values consistently fell below the conventional significance threshold of 0.05 only emphasizes the robustness and reliability of BiGTA-net. The variations in metrics, namely, MAPE, RMSE, and MAE, across
Table 13 and
Table 14 vividly portray the margin by which BiGTA-net leads in accuracy and precision. The unique architecture and methodology behind BiGTA-net have positioned it as a front-runner in this domain.
In the intricate realm of BEMS, the gravity of data-driven decisions cannot be overstated; they bear a twofold onus of economic viability and environmental stewardship. The need for precise and decipherable modeling is, therefore, undeniably paramount. BiGTA-net envisaged as an advanced hybrid model, sought to meet these exacting standards. Its unique amalgamation of Bi-GRU and TCN accentuates its proficiency in parsing intricate temporal patterns, which remain at the heart of energy forecasting.
In the complex BEMS landscape, BiGTA-net’s hybrid design brings a distinctive strength in capturing intricate temporal dynamics. However, this prowess has its challenges. Particularly in industrial environments or regions heavily dependent on unpredictable renewable energy sources, the model may find it challenging to adapt to abrupt shifts in energy consumption patterns swiftly. This adaptability issue is further accentuated when considering the sheer volume of data that the energy sector typically handles. Given the influx of granular data from many sensors and IoT devices, BiGTA-net’s intricate architecture could face scalability issues, especially when implemented across vast energy distribution networks or grids. Furthermore, the predictive nature of energy management demands an acute sense of foresight, especially with the increasing reliance on renewable energy sources. In this context, the TCN’s inherent limitations in accounting for prospective data pose challenges, especially when energy matrices constantly change, demanding agile and forward-looking predictions.
Within the multifaceted environment of the BEMS domain, the continuous evolution and refinement of models, i.e., BiGTA-net are essential. One avenue of amplification lies in broadening its scope to account for external determinants. By incorporating influential factors such as climatic fluctuations and scheduled maintenance events directly into the model’s input parameters, BiGTA-net could enhance responsiveness to unpredictable energy consumption variances. Further bolstering its real-time applicability, introducing an adaptive learning mechanism designed to self-tune based on the influx of recent data could ensure that the model remains abreast of the ever-changing energy dynamics. Additionally, enhancing the model’s interpretability is vital in a sector where transparency and clarity are paramount. Integrating principles from the “explainable AI” domain into BiGTA-net can provide a deeper understanding of its decision-making process, enabling stakeholders to discern the rationale behind specific energy consumption predictions and insights.
As the forward trajectory of BiGTA-net within the energy sector is contemplated, several avenues of research come into focus. Foremost is the potential enhancement of the model’s attention mechanism, tailored explicitly to the intricacies of energy consumption dynamics. The model’s ability to discern and emphasize critical energy patterns could be substantially elevated by tailoring attention strategies to highlight domain-specific energy patterns. Furthermore, while BiGTA-net showcases an intricate architecture, the ongoing challenge resides in seamlessly integrating its inherent complexity with optimal predictive accuracy. By addressing this balance, models could be engineered to be more streamlined and suitable for decentralized or modular BEMS frameworks, all while retaining their predictive capabilities. Lastly, a compelling proposition emerges for integrating BiGTA-net’s forecasting prowess with existing BEMS decision-making platforms. Such integration holds the promise of a future where real-time predictive insights seamlessly inform energy management strategies, thereby advancing both energy utilization efficiency and a tangible reduction in waste.
While BiGTA-net has demonstrated commendable forecasting capabilities in its initial stages, a thorough exploration of its limitations in conjunction with potential improvements and future directions can contribute to the enhancement of its role within the BEMS domain. By incorporating these insights, the relevance and adaptability of BiGTA-net can be advanced, thus positioning it as a frontrunner in the continuously evolving energy sector landscape.
4. Conclusions
Our study presents the BiGTA-net, a transformative deep-learning model tailored for urban energy management in smart cities, enhancing the accuracy and efficiency of STLF. This model harmoniously integrates the capabilities of Bi-GRU, TCN, and an attention mechanism, capturing both recurrent and convolutional data patterns effectively. A thorough examination of the BiGTA-net against other models on the educational building dataset showcased its distinct superiority. Specifically, BiGTA-net excelled with a MAPE of 5.37, RMSE of 171.3, and MAE of 122.0. Notably, the closest competitor, Bi-GRU-TCN-II, lagged slightly with metrics such as MAPE of 5.39 and MAE of 122.7. This superiority was mirrored in the AEP dataset, where BiGTA-net again led with a MAPE of 26.77, RMSE of 386.5, and MAE of 198.4. Such consistent outperformance underscores the model’s capability, especially when juxtaposed with other configurations.
Furthermore, the integration of the attention mechanism serves to enhance the performance of BiGTA-net, reinforcing its effectiveness in forecasting tasks. The distinct bidirectional architecture of BiGTA-net demonstrated superior performance, further establishing its supremacy. This performance advantage becomes notably apparent when contrasted with models, i.e., Att-LSTM, which exhibited higher errors across pivotal metrics, highlighting the resilience and dependability of the proposed model. The evident strength of BiGTA-net lies in its innovative amalgamation of Bi-GRU and TCN, harmonized with the attention mechanism and bolstered by the SELU activation function. Its consistent dominance across diverse datasets and metrics robustly validates the efficacy of this hybrid approach.
Despite its promising results, it is important to explore the BiGTA-net’s capabilities further and identify areas for improvement. Its generalizability has yet to be extensively tested beyond the datasets used in this study, which presents a limitation. Future research should apply the model across various consumption domains, such as residential or industrial sectors, and compare its effectiveness with a wider range of advanced machine learning models. By doing so, researchers can further refine the model for specific scenarios and delve deeper into hyperparameter optimizations.





 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}