
A Follow-Up Risk Identification Model Based on Multi-Source Information Fusion

Abstract
:1. Introduction
2. Follow-Up Risk Validation Model
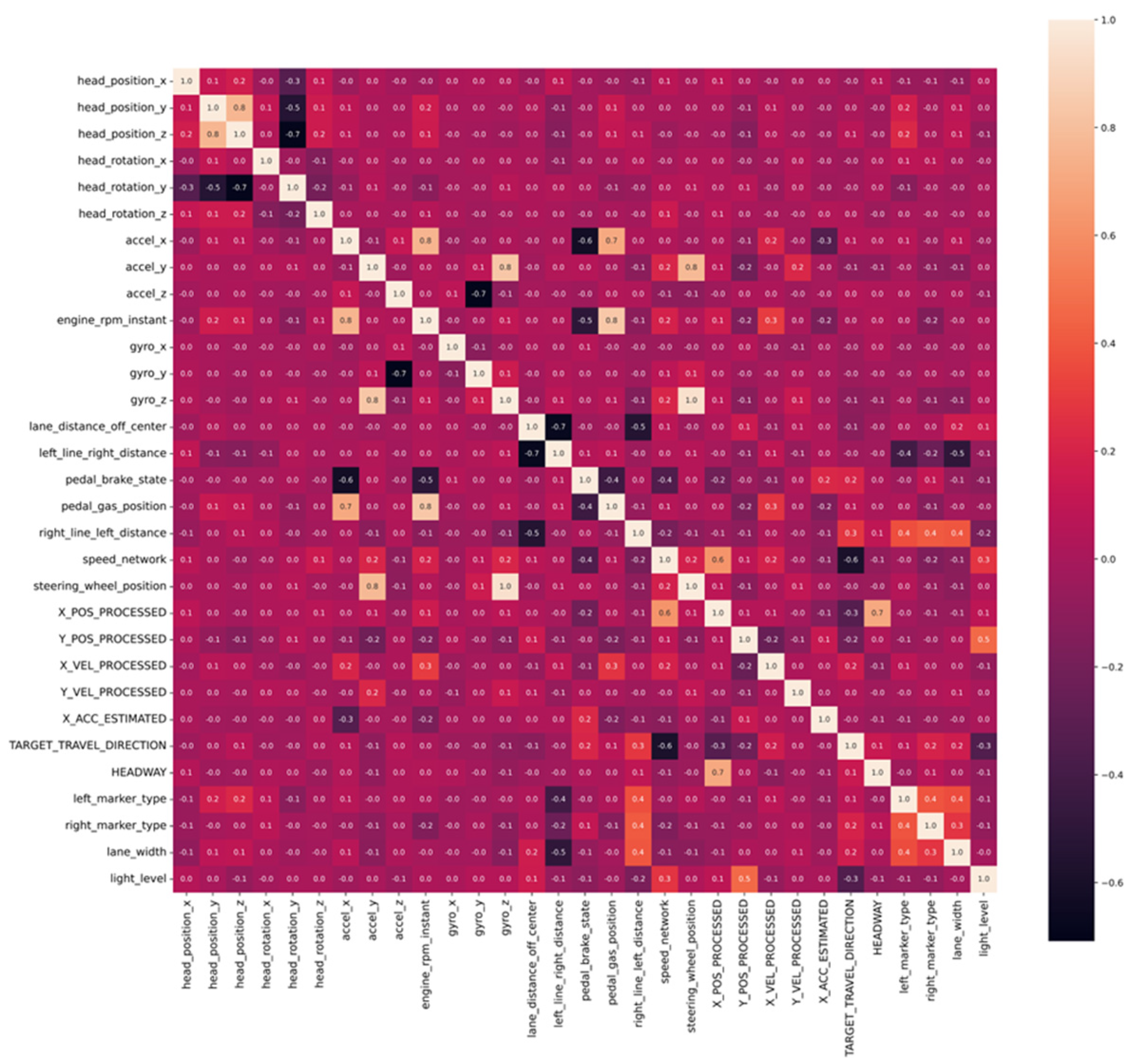
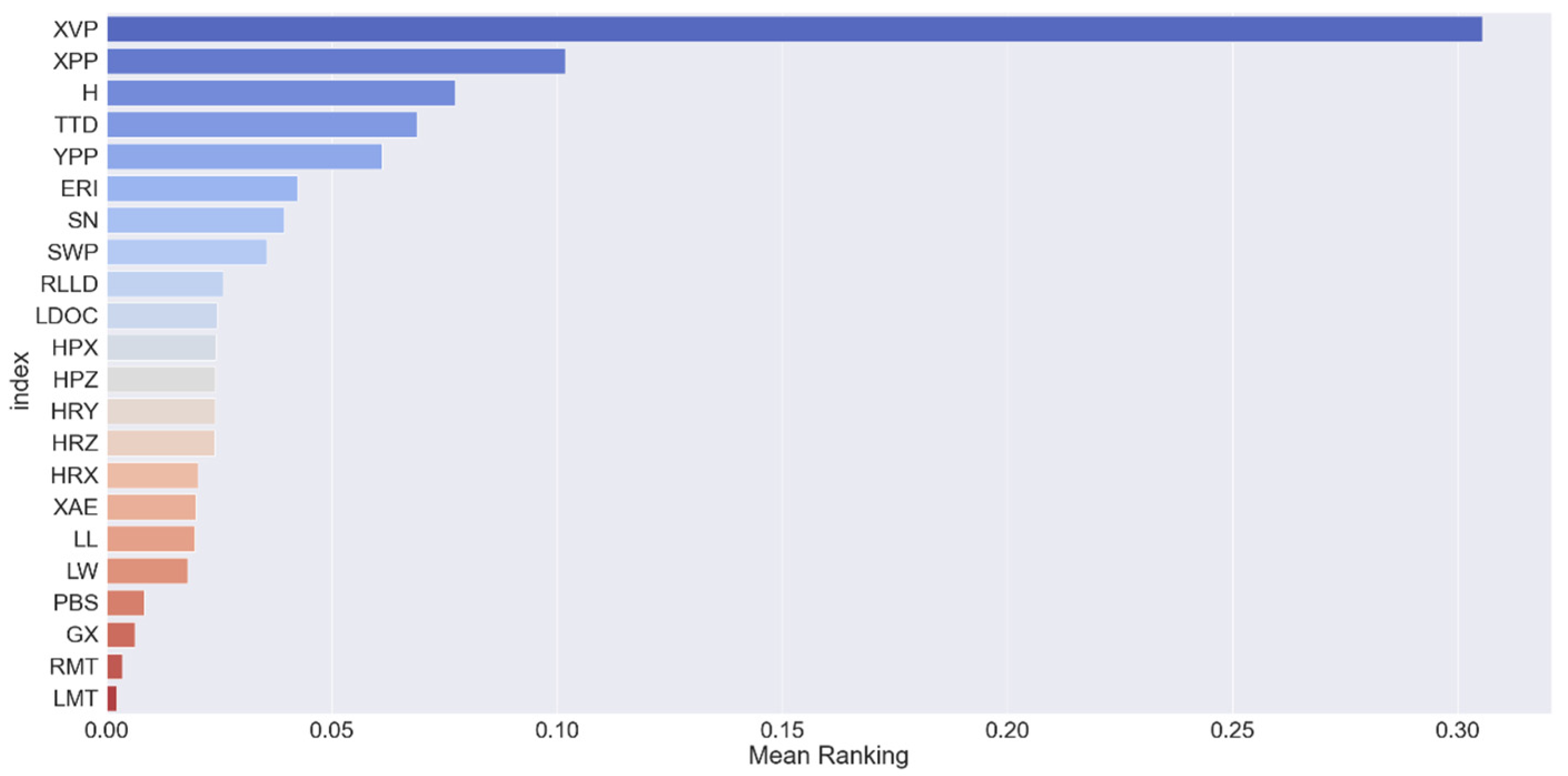
2.1. Indicator Screening and Optimization
- To ensure that both the lead and following vehicles are strictly in the same lane, the absolute value of the lateral distance is limited to 2.2 m.
- To ensure smooth traffic flow, the time distance between the fronts of the vehicles is set to be less than 5 s, the distance between the fronts of the vehicles ranges from 5 to 110 m, and the speed of the following vehicle must exceed 18 km/h.
- To ensure that the vehicle is in a stable following state, the duration of the following clip is required to be no less than 20 s.
2.2. Indicator Screening Results
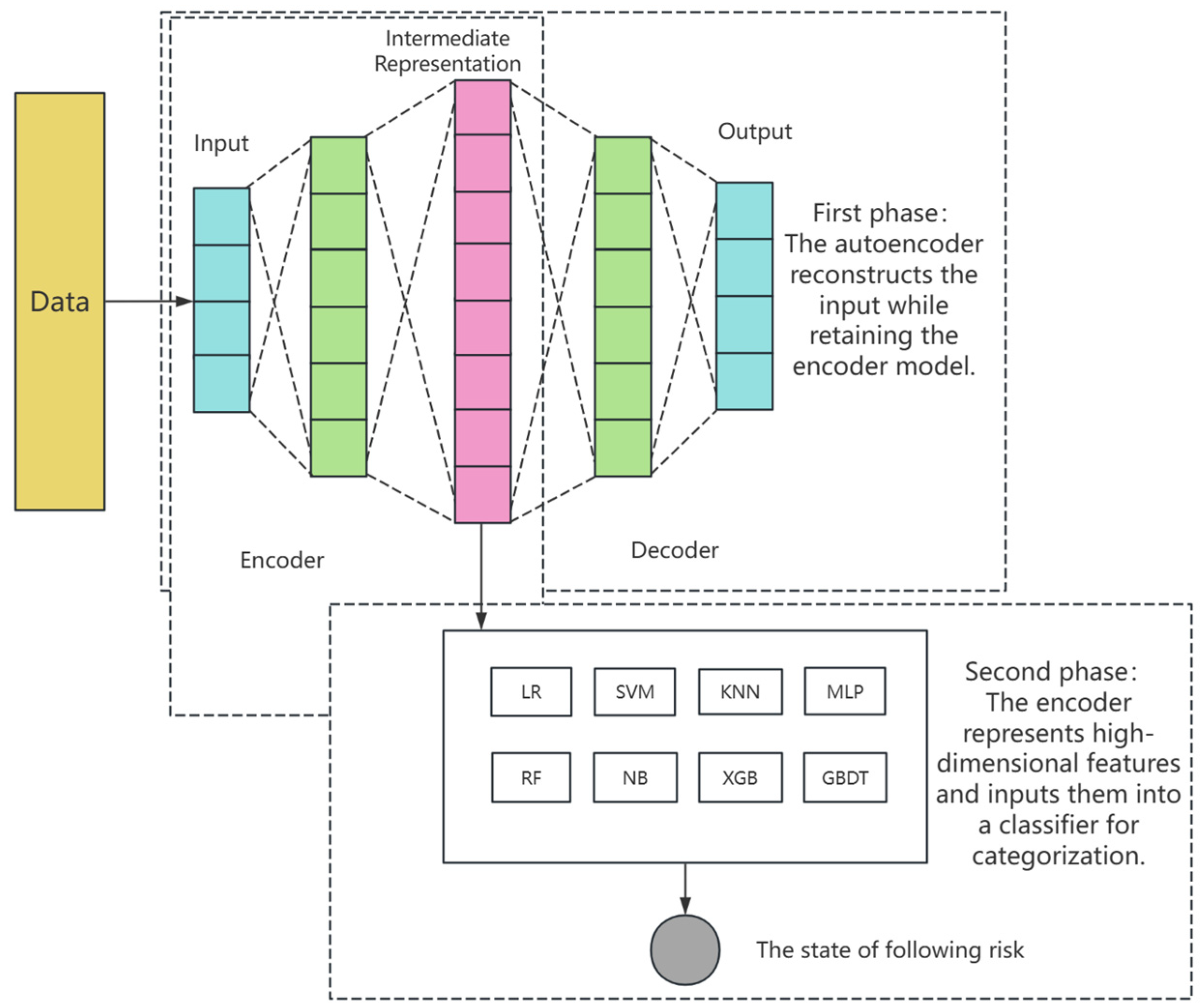
2.3. Construction of Follow-Up Risk Identification Model
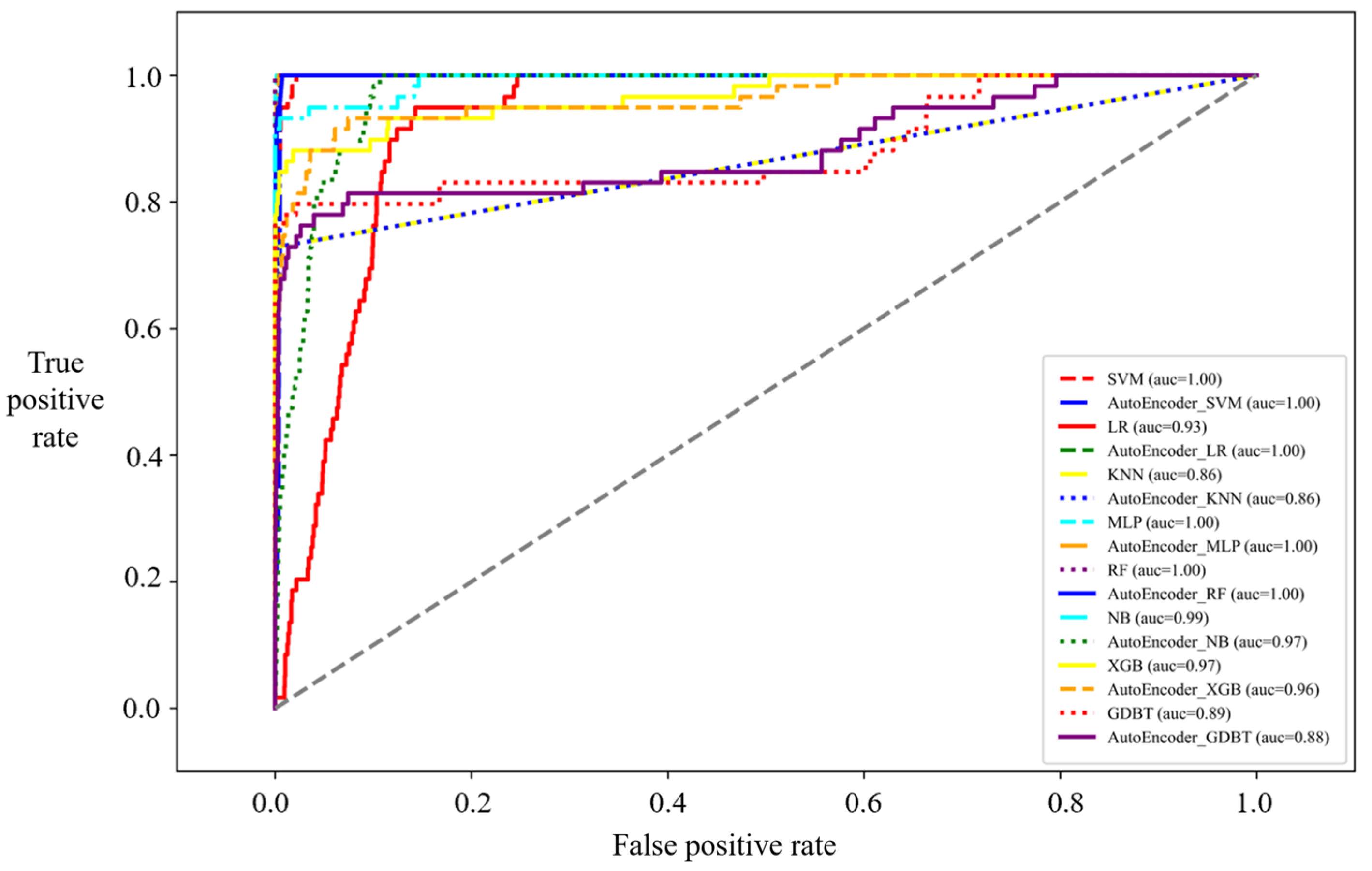
3. Model Training and Validation
3.1. Model Training
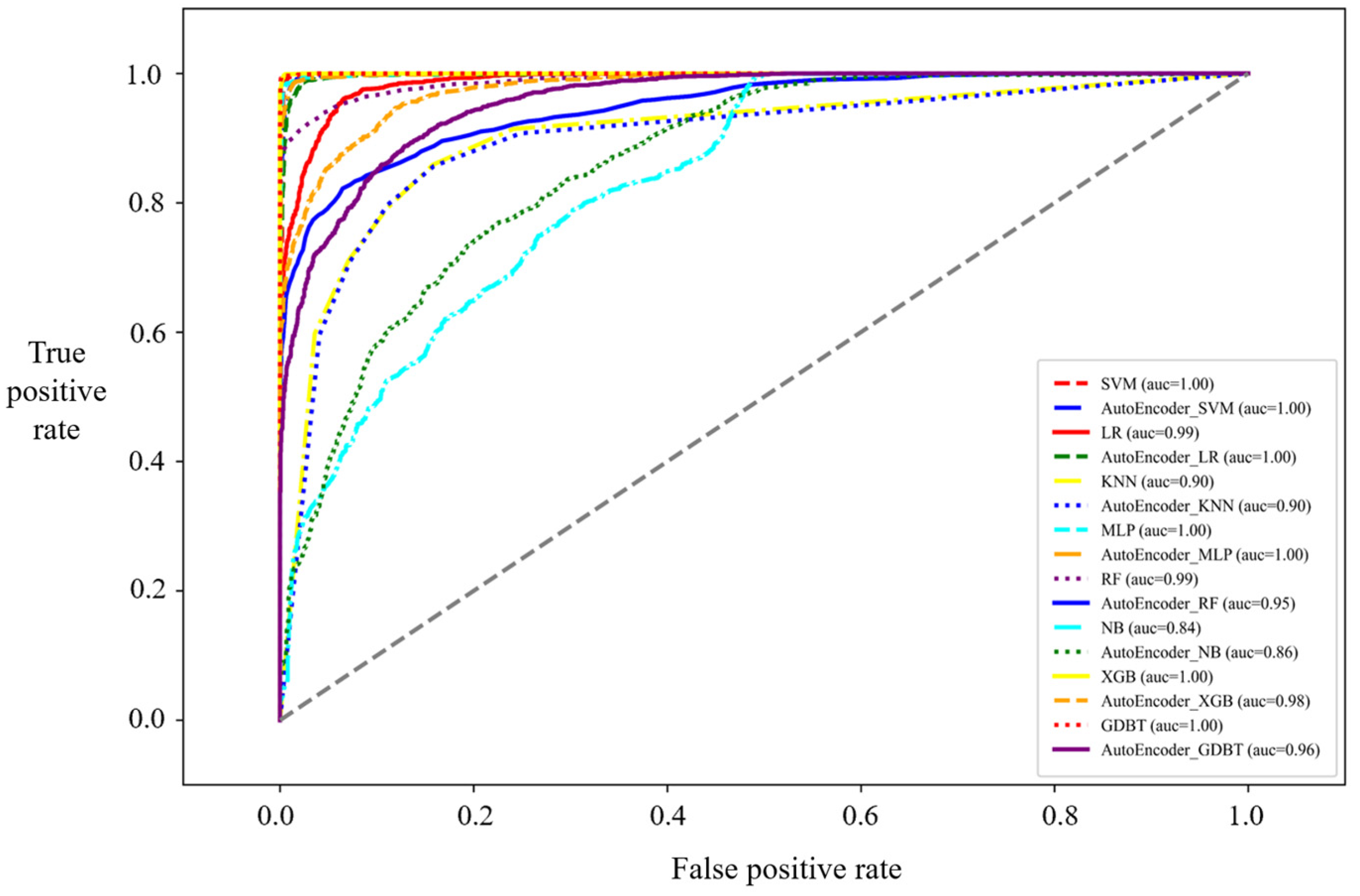
3.2. Training Results
- (1)
- Verification of Follow-up Risk Identification Model Results
- (2)
- Analysis of Validation Model Results for Different Follow-up Risk Levels
3.3. Model Validation
4. Collision Avoidance Grading Early Warning Strategies
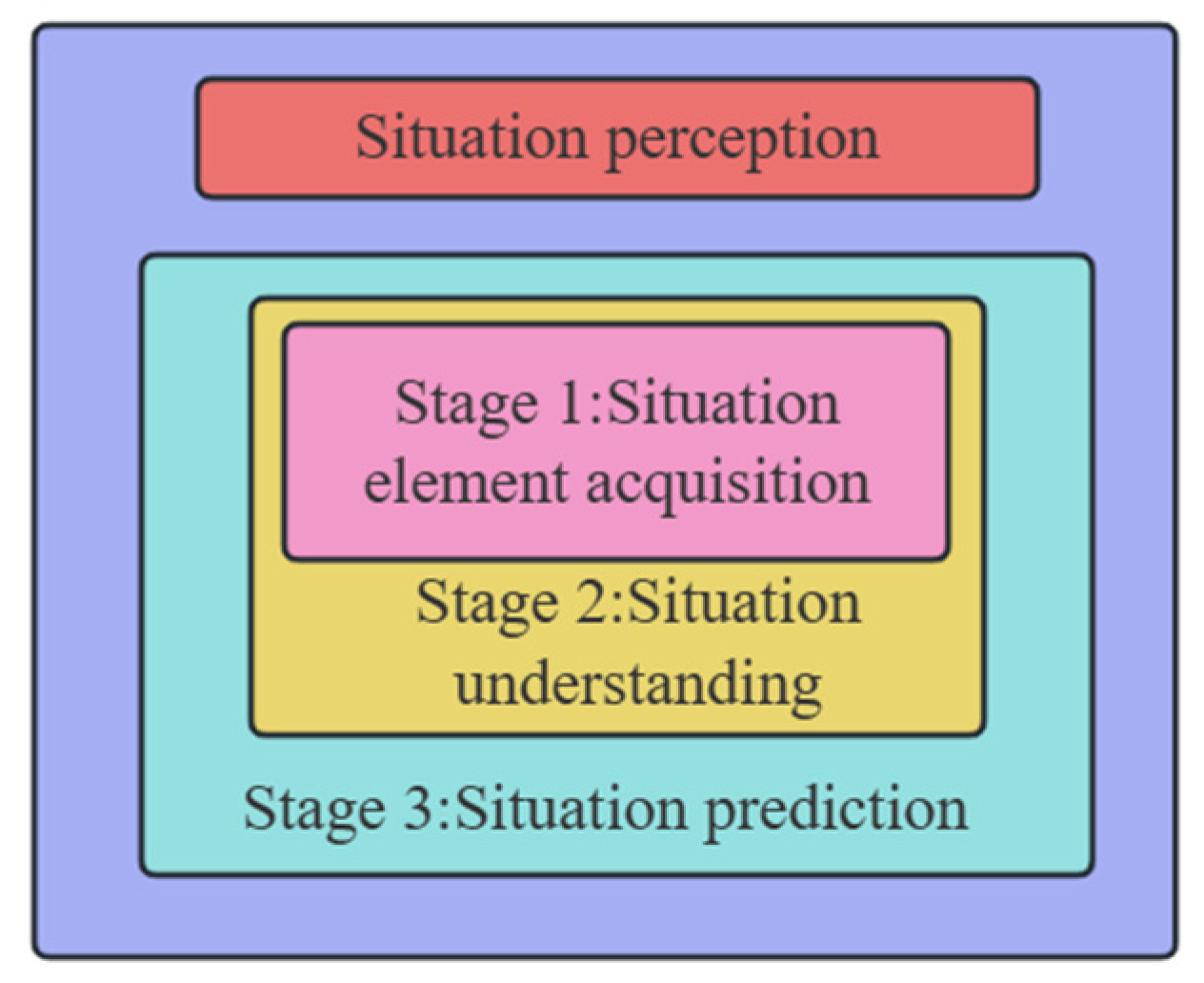
4.1. Situational Awareness Framework
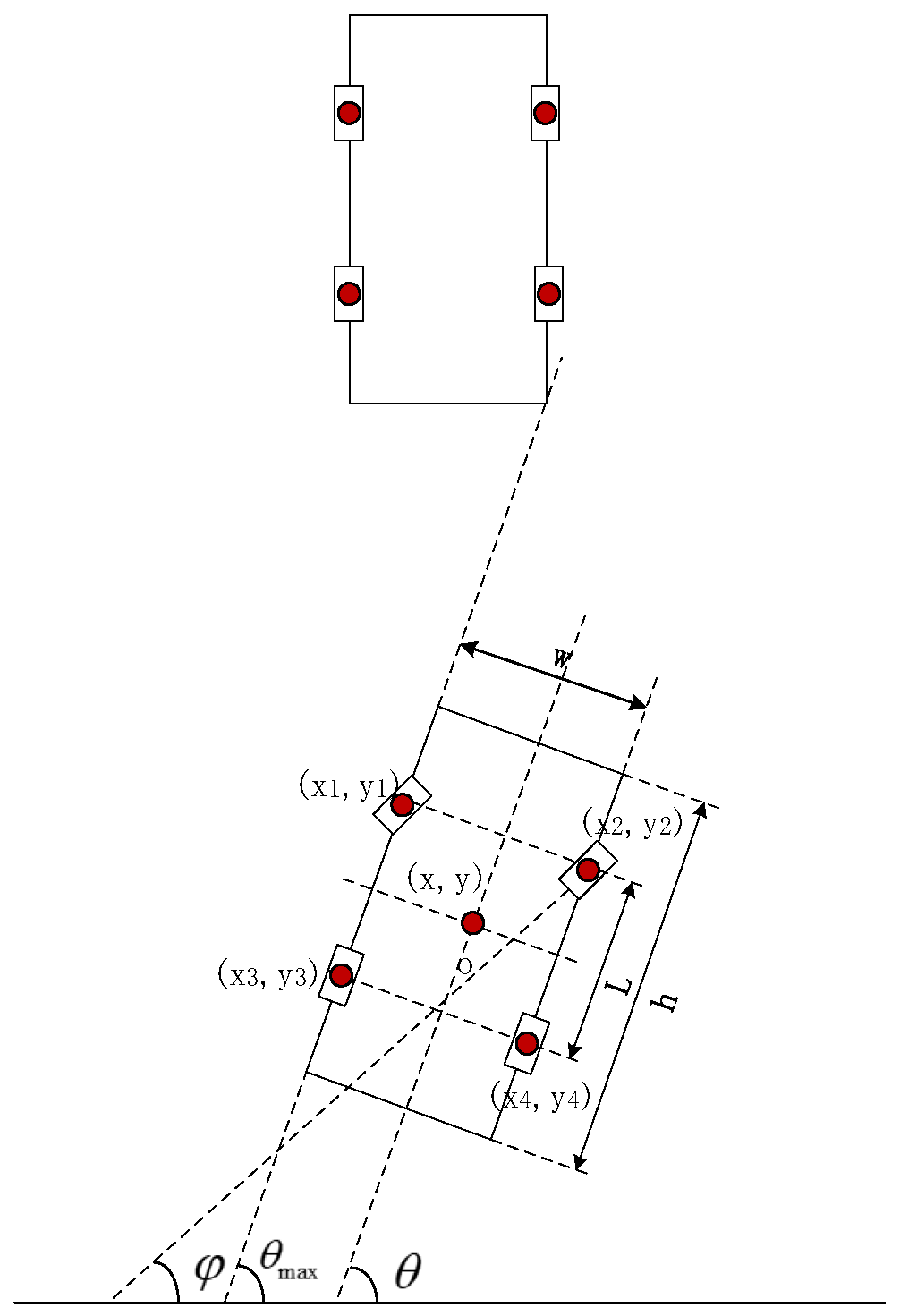
4.2. Vehicle Dynamics Motion Analysis
4.2.1. Vehicle Dynamics Model Construction
4.2.2. Determination of Vehicle Following Status
4.3. Early Warning Grading Information Prompt Design
- When the vehicle is at the lowest risk level, which is the fourth level, a red light warning will be displayed on the screen for 2 s, ensuring that it does not distract or disrupt the driver’s vision. If the vehicle is at the third risk level, both a red light warning and an audible “Didi” sound will be utilized for a duration of 2 s. At the second risk level, a red light warning accompanied by a high-frequency “Didi” sound will be employed for 2s. When the vehicle is at the highest risk level, the visual warning method may gradually become ineffective and occupy the driver’s cognitive time. To avoid adverse effects, a high-frequency “Didi” sound and steering wheel vibration will be used for 2 s instead.
- If the vehicle is at the first risk level and maintains a constant speed or continues to accelerate, an auditory-tactile combined warning prompt will be activated, along with a speed suggestion. However, if the vehicle decelerates and reaches a risk-free state within 2 s, no warning prompt will be displayed. If it does not, the corresponding prompt will appear when it slows down to the second, third, or fourth risk levels.
- When the vehicle is at the second risk level and maintains a constant speed or accelerates, a visual-high-frequency “Didi” sound and auditory combined warning prompt will be given, along with a speed suggestion. If the vehicle decelerates and reaches a risk-free state within 2 s, no warning will be issued. If it does not, the corresponding prompt will appear when it slows down to the third or fourth risk levels.
- If the vehicle is at the third risk level and maintains a constant speed or accelerates, a visual and auditory “Didi” combined sound warning prompt will be used to provide speed suggestions. If the vehicle decelerates and reaches a risk-free state within 2 s, no warning prompt will be displayed. If it does not, a corresponding prompt will appear when it slows down to the fourth risk level.
- When the vehicle is at the fourth risk level and maintains a constant speed or accelerates, a red light flashing visual warning prompt will be displayed, along with speed suggestions. If the vehicle decelerates and reaches a risk-free state within 2 s, no warning prompt will be issued. If it does not, a warning corresponding to the fourth risk level will be displayed.
4.4. Potential Effect on User Groups
- (1)
- Positive Behavioral Change:
- (2)
- Trust and Confidence in Technology:
- (3)
- Economic Benefits:
- (4)
- Regulatory Compliance and Standards:
5. Potential Limitations
- (1)
- Data Quality and Accuracy:
- (2)
- Data Privacy and Security:
- (3)
- Model Complexity and Computational Cost:
- (4)
- Model Interpretability and Understandability:
- (5)
- Dependency and Robustness:
- (6)
- Insufficient conditions
6. Discussion
- Ref [19]: A study on traffic conflict prediction model of closed lanes on the outside of expressway involves analyzing various factors that contribute to potential traffic conflicts in scenarios where lanes on the outer side of an expressway are closed.
- Ref [20]: Research on characteristics and trends of traffic flow based on the mixed velocity method and background difference method offers significant potential for improving the understanding of traffic behavior and optimizing road networks.
- Ref [21]: Fusing near-infrared and Raman spectroscopy coupled with deep learning LSTM algorithm represents a powerful tool for analyzing and predicting the properties and behavior of materials. This technique has wide applications in various fields.
- Ref [22]: In the realm of traffic engineering and highway safety, the determination of warning zone lengths on freeways is a critical task. These warning zones play a vital role in alerting drivers to potential hazards or changes in traffic conditions ahead, thereby enabling them to take necessary precautions and avoid accidents.
- Ref [23]: The CNN-LSTM approach combines the feature extraction capabilities of CNNs with the time series modeling capabilities of LSTMs, making it a powerful tool for handling and predicting time series data.
- Ref [24]: Video-based deep learning methods are powerful tools for processing and analyzing video data.
- Ref [25]: The Improved TTC Algorithm represents a significant advancement in traffic conflict detection and prediction. By addressing the limitations of the traditional TTC algorithm and incorporating additional factors and techniques, it provides a more accurate and reliable method for detecting potential rear-end conflicts in complex traffic environments.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Traffic Management Bureau of the Ministry of Public Security. There Are 435 Million Vehicles, 523 Million Drivers, and More than 20 Million New Energy Vehicles in China; Traffic Management Bureau of the Ministry of Public Security: Beijing, China, 2023. [Google Scholar]
- National Bureau of Statistics. China Statistical Yearbook 2023; National Bureau of Statistics: Beijing, China, 2023. [Google Scholar]
- Yang, Z. Research on Causes of Rear-End Collision and Behavior of Avoiding Collision Based on Deep Data Analysis; Northeast Forestry University: Harbin, China, 2021. [Google Scholar]
- Tan, J.H. Impact of risk illusions on traffic flow in fog weather. Physica A Stat. Mech. Appl. 2019, 525, 216–222. [Google Scholar] [CrossRef]
- Liu, Z.H.; Zhang, K.D.; Ni, J. Analysis and Identification of Drivers’ Difference in Car-Following Condition Based on Naturalistic Driving Data. J. Transp. Syst. Eng. Inf. Technol. 2021, 21, 48–55. [Google Scholar]
- Bai, Y.; Ren, M.H. Improving Car Following Model Before the Vehicle Changes Lanes Based on NGSIM Data. Traffic Transp. 2023, 39, 25–29. [Google Scholar]
- Huang, Z.G.; Guo, X.C.; Jia, L. Car-Following Risk Behavior in Rainy Weather Based on Random Forest. J. Transp. Inf. Saf. 2020, 38, 27–34. [Google Scholar]
- Hjelkrem, A.O.; Ryeng, O.E. Chosen risk level during car-following in adverse weather conditions. Accident Anal. Prev. 2016, 95, 268–275. [Google Scholar] [CrossRef]
- Ge, H.; Bo, Y.; Zang, W.; Zhou, L.; Dong, L. Literature review of driving risk identification research based on bibliometric analysis. J. Traffic Transp. Eng. (Engl. Ed.) 2023, 3, 118–130. [Google Scholar] [CrossRef]
- Wang, M.; Tu, H.Z.; Li, H. Prediction of Car-Following Risk Status Based on Car-Following Behavior Spectrum. J. Tongji Univ. (Nat. Sci.) 2021, 49, 843–852. [Google Scholar]
- Transportation Research Board (TRB). Highway Capacity Manual 2010; Highway Research Board: Washington, DC, USA, 2010. [Google Scholar]
- Paker, M. The Effect of Heavy Goods Vehicles and Following Behavior on Capacity at Motorway Roadwork Sites. Traffic Eng. Control 1996, 37, 524–531. [Google Scholar]
- Gartner, N.; Messer, C.J.; Raathi, A.K. Traffic Flow Theory (Update of TRB Special Report 1165); Transportation Research Board: Washington, DC, USA, 1997. [Google Scholar]
- Wang, X.S.; Zhu, M.X. Calibrating and Validating Car-Following Models on Urban Expressways for Chinese Drivers Using Naturalistic Driving Data. China J. Highw. Transp. 2018, 31, 129–138. [Google Scholar]
- Ng, A. Sparse Autoencoder. CS294A Lect. Notes 2011, 72, 1–19. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A.; Bottou, L. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Rifai, S.; Vincent, P.; Muller, X.; Glorot, X.; Bengio, Y. Contractive auto-encoders: Explicit invariance during feature extraction. In Proceedings of the 28th International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; Omnipress: Bellevue, WA, USA, 2011; pp. 833–840. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the International Conference on Learning Representations (ICLR), Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Ge, H.; Huang, M.; Lu, Y.; Yang, Y. Study on Traffic Conflict Prediction Model of Closed Lanes on the Outside of Expressway. Symmetry 2020, 12, 926. [Google Scholar] [CrossRef]
- Ge, H.; Sun, H.; Lu, Y. Research on Characteristics and Trends of Traffic Flow Based on Mixed Velocity Method and Background Difference Method. Math. Probl. Eng. 2020, 2020, 1–9. [Google Scholar] [CrossRef]
- Nunekpeku, X.; Zhang, W.; Gao, J.; Adade, S.Y.S.S.; Chen, Q. Gel Strength prediction in ultrasonicated chicken mince: Fusing near-infrared and Raman spectroscopy coupled with deep learning LSTM algorithm. Foods 2024, 14, 168. [Google Scholar] [CrossRef]
- Ge, H.; Yang, Y. Research on Calculation of Warning Zone Length of Freeway Based on Micro-Simulation Model. IEEE Access 2020, 8, 76532–76540. [Google Scholar] [CrossRef]
- Wang, Y.; Li, T.; Chen, T.; Zhang, X.; Taha, M.F.; Yang, N.; Shi, Q. Cucumber Downy Mildew Disease Prediction Using a CNN-LSTM Approach. Agronomy 2024, 14, 1155. [Google Scholar] [CrossRef]
- Chen, C.; Zhu, W.; Steibel, J.; Siegford, J.; Han, J.; Norton, T. Classification of drinking and drinker-playing in pigs by a video-based deep learning method. Animals 2020, 196, 1–14. [Google Scholar] [CrossRef]
- Ge, H.; Xia, R.; Sun, H.; Yang, Y.; Huang, M. Construction and Simulation of Rear-End Conflicts Recognition Model Based on Improved TTC Algorithm. IEEE Access 2019, 7, 134763–134771. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicator Category | Index | Shorthand |
|---|---|---|
| Driver indicators | Y-axis head position X-axis head position | HPY HPX |
| Z-axis head position | HPZ | |
| X-axishead rotation baseline | HRX | |
| Y-axis head rotation baseline | GAMES | |
| Z-axis head rotation baseline | HRZ | |
| Road Parameter Metrics | Lane width | LW |
| The type of left-hand lane sign for the vehicle immediately adjacent to the vehicle being used | LMT | |
| The type of right-hand lane sign for the vehicle immediately adjacent to the vehicle being used | RMT | |
| Environmental indicators | Light level | LL |
| Vehicle operation and performance indicators | X-axis vehicle acceleration | AX |
| Y-axis vehicle acceleration | AY | |
| Z-axis vehicle acceleration | THAT | |
| Instantaneous engine speed | DIFFERENT | |
| X-axis vehicle angular velocity | GX | |
| Y-axis vehicle angular velocity | GY | |
| Z-axis vehicle angular velocity | GZ | |
| Lateral distance | LDOC | |
| The distance from the center line of the vehicle to the inside of the left lane sign | LLRD | |
| The distance from the center line of the vehicle to the inside of the right lane sign | RLLD | |
| Pedal brake status | PBS | |
| Throttle opening | PGP | |
| Speed | SN | |
| Steering wheel position | SWP | |
| The x-axis component of the distance between the front car and the front bumper of the self car | XPP | |
| The y-axis component of the distance between the front car and the front bumper of the self-car | YPP | |
| The rate of change of the distance between the front car and the self is the x-axis component | XVP | |
| The rate of change of the distance between the front and self vehicles is the y-axis component | YVP | |
| The x-axis component of the relative acceleration of the front and self vehicles | XAE | |
| The direction of the vehicle in front | TTD | |
| The distance between the front of the car | H |
| Level 1 Risk (I Risk) | Level 2 Risk (II Risk) | Level 3 Risk (III Risk) | Level 4 Risk (IV Risk) | Risk-Free (No Risk) |
|---|---|---|---|---|
| 0–1.32 s | 1.32–1.90 s | 1.90–2.95 s | 2.95–3.98 s | >3.98 s or <0 s |
| Model | Parameter | Numeric Value |
|---|---|---|
| LR | Regularization intensity Tolerance | 0.93 0.0005 |
| SVM | Regularization intensity Tolerance | 0.95 0.0003 |
| KNN | Number of neighbors Number of leaf nodes | 4 34 |
| MLP | alpha The learning rate is initialized | 0.0002 0.005 |
| RF | Number of weak learners Maximum depth The minimum number of samples required for segmentation Minimum number of samples for leaf nodes Maximum number of leaf nodes | 86 14 10 2 39 |
| NB | Smooth parameters | 2.00 × 10−9 |
| XGB | Learning rate gamma Maximum depth Minimum leaf node sample weights are summed | 0.025 0.06 12 3 |
| GBDT | Learning rate Number of weak learners The minimum number of samples required for segmentation Minimum number of samples for leaf nodes Maximum depth Maximum number of leaf nodes | 0.04 76 2 2 10 42 |
| Model | Evaluation Indicators | ||||
|---|---|---|---|---|---|
| Accuracy | Recall | F1 | Precision | Time (ms) | |
| LR | 0.8969 | 0.8893 | 0.8940 | 0.9123 | 302 |
| AutoEncoder_LR | 0.9133 | 0.9057 | 0.9108 | 0.9304 | 1871 |
| SVM | 0.8802 | 0.8697 | 0.8753 | 0.9082 | 210 |
| AutoEncoder_SVM | 0.9054 | 0.8971 | 0.9024 | 0.9252 | 4524 |
| KNN | 0.8444 | 0.8404 | 0.8404 | 0.8463 | 2980 |
| AutoEncoder_KNN | 0.8442 | 0.8408 | 0.8423 | 0.8451 | 8739 |
| MLP | 0.9016 | 0.8930 | 0.8983 | 0.9225 | 29,464 |
| AutoEncoder_MLP | 0.9149 | 0.9073 | 0.9125 | 0.9318 | 22,498 |
| RF | 0.9066 | 0.8982 | 0.9036 | 0.9263 | 5290 |
| AutoEncoder_RF | 0.8780 | 0.8724 | 0.8755 | 0.8849 | 34,673 |
| NB | 0.7149 | 0.7247 | 0.7139 | 0.7328 | 60 |
| AutoEncoder_NB | 0.7476 | 0.7542 | 0.7475 | 0.7562 | 398 |
| XGB | 0.9063 | 0.8980 | 0.9034 | 0.9262 | 2823 |
| AutoEncoder_XGB | 0.8969 | 0.8897 | 0.8941 | 0.9106 | 44,874 |
| GDBT | 0.9090 | 0.9009 | 0.9062 | 0.9280 | 9197 |
| AutoEncoder_GDBT | 0.8780 | 0.8721 | 0.8754 | 0.8858 | 247,200 |
| Model | Evaluation Indicators | ||||
|---|---|---|---|---|---|
| Accuracy | Recall | F1 | Precision | Time (ms) | |
| LR | 0.5765 | 0.3471 | 0.3412 | 0.3886 | 1049 |
| AutoEncoder_LR | 0.7014 | 0.5497 | 0.5986 | 0.7402 | 3232 |
| SVM | 0.6232 | 0.4144 | 0.4096 | 0.4303 | 523 |
| AutoEncoder_SVM | 0.6781 | 0.4809 | 0.5114 | 0.7108 | 21,011 |
| KNN | 0.6735 | 0.5046 | 0.5467 | 0.7019 | 1500 |
| AutoEncoder_KNN | 0.6735 | 0.5045 | 0.5480 | 0.7141 | 7318 |
| MLP | 0.7101 | 0.5176 | 0.5520 | 0.7421 | 20,396 |
| AutoEncoder_MLP | 0.6891 | 0.5492 | 0.5999 | 0.7315 | 36,435 |
| RF | 0.6781 | 0.4972 | 0.5375 | 0.7153 | 3936 |
| AutoEncoder_RF | 0.6787 | 0.4916 | 0.5288 | 0.7156 | 24,601 |
| NB | 0.5934 | 0.4654 | 0.4802 | 0.6299 | 58 |
| AutoEncoder_NB | 0.5809 | 0.4970 | 0.4484 | 0.4361 | 409 |
| XGB | 0.6923 | 0.5320 | 0.5789 | 0.7302 | 8505 |
| AutoEncoder_XGB | 0.6806 | 0.5083 | 0.5515 | 0.7169 | 111,974 |
| GDBT | 0.6883 | 0.5054 | 0.5447 | 0.7224 | 30,786 |
| AutoEncoder_GDBT | 0.6732 | 0.5324 | 0.5773 | 0.7032 | 755,456 |
| Model | Evaluation Indicators | ||||
|---|---|---|---|---|---|
| Accuracy | Recall | F1 | Precision | Time (ms) | |
| LR | 0.8986 | 0.9044 | 0.8984 | 0.9109 | 1280 |
| AutoEncoder_LR | 0.9576 | 0.9583 | 0.9575 | 0.9570 | 3223 |
| SVM | 0.9009 | 0.9066 | 0.9008 | 0.9126 | 686 |
| AutoEncoder_SVM | 0.9370 | 0.9406 | 0.9370 | 0.9405 | 11,688 |
| KNN | 0.8610 | 0.8638 | 0.8609 | 0.8631 | 14,292 |
| AutoEncoder_KNN | 0.8589 | 0.8616 | 0.8589 | 0.8609 | 33,733 |
| MLP | 0.9008 | 0.9065 | 0.9007 | 0.9126 | 54,108 |
| AutoEncoder_MLP | 0.9505 | 0.9534 | 0.9505 | 0.9522 | 116,309 |
| RF | 0.9012 | 0.9069 | 0.9011 | 0.9129 | 18,794 |
| AutoEncoder_RF | 0.8809 | 0.8845 | 0.8809 | 0.8848 | 136,306 |
| NB | 0.7942 | 0.7888 | 0.7903 | 0.8009 | 77 |
| AutoEncoder_NB | 0.8409 | 0.8343 | 0.8368 | 0.8562 | 1000 |
| XGB | 0.8951 | 0.9012 | 0.8949 | 0.9086 | 3455 |
| AutoEncoder_XGB | 0.8897 | 0.8948 | 0.8896 | 0.8987 | 64,089 |
| GDBT | 0.9188 | 0.9235 | 0.9187 | 0.9262 | 37,384 |
| AutoEncoder_GDBT | 0.9007 | 0.9023 | 0.9006 | 0.9008 | 796,193 |
| Model | Evaluation Indicators | ||||
|---|---|---|---|---|---|
| Accuracy | Recall | F1 | Precision | Time (ms) | |
| LR | 0.5967 | 0.3677 | 0.3617 | 0.4087 | 2174 |
| AutoEncoder_LR | 0.7153 | 0.5822 | 0.6334 | 0.7564 | 5899 |
| SVM | 0.5919 | 0.3879 | 0.3755 | 0.4015 | 1185 |
| AutoEncoder_SVM | 0.6709 | 0.5775 | 0.6169 | 0.6883 | 60,323 |
| KNN | 0.6832 | 0.5502 | 0.5979 | 0.7138 | 3236 |
| AutoEncoder_KNN | 0.6787 | 0.5453 | 0.5941 | 0.7190 | 27,326 |
| MLP | 0.6978 | 0.6059 | 0.6513 | 0.7472 | 43,833 |
| AutoEncoder_MLP | 0.7381 | 0.7290 | 0.7616 | 0.8077 | 45,797 |
| RF | 0.7145 | 0.6079 | 0.6587 | 0.7605 | 7803 |
| AutoEncoder_RF | 0.6966 | 0.5888 | 0.6392 | 0.7453 | 54,599 |
| NB | 0.6045 | 0.4811 | 0.5028 | 0.6449 | 94 |
| AutoEncoder_NB | 0.5872 | 0.4967 | 0.4920 | 0.5220 | 769 |
| XGB | 0.7138 | 0.6369 | 0.6854 | 0.7695 | 14,916 |
| AutoEncoder_XGB | 0.6911 | 0.5780 | 0.6284 | 0.7393 | 185,558 |
| GDBT | 0.6605 | 0.5540 | 0.6044 | 0.7217 | 56,182 |
| AutoEncoder_GDBT | 0.6443 | 0.4966 | 0.5430 | 0.6913 | 2,168,225 |
| Risk Level | Level 1 Risk | Level 2 Risk | Level 3 Risk | Level 4 Risk |
|---|---|---|---|---|
| Urgency | Particularly urgent | Highly urgent | Moderately urgent | Low-severity emergency |
| Visual warning | - | red light | red light | Red light or flashing |
| Auditory warning | High-frequency “drip” sound | High-frequency “drip” sound | “Didi” sound | - |
| Tactile warning | The steering wheel vibrates | - | - | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, S.; Bo, Y.; Chen, J.; Liu, Y.; Chen, J.; Ge, H. A Follow-Up Risk Identification Model Based on Multi-Source Information Fusion. Systems 2025, 13, 41. https://doi.org/10.3390/systems13010041
Guo S, Bo Y, Chen J, Liu Y, Chen J, Ge H. A Follow-Up Risk Identification Model Based on Multi-Source Information Fusion. Systems. 2025; 13(1):41. https://doi.org/10.3390/systems13010041
Chicago/Turabian StyleGuo, Shuwei, Yunyu Bo, Jie Chen, Yanan Liu, Jiajia Chen, and Huimin Ge. 2025. "A Follow-Up Risk Identification Model Based on Multi-Source Information Fusion" Systems 13, no. 1: 41. https://doi.org/10.3390/systems13010041
APA StyleGuo, S., Bo, Y., Chen, J., Liu, Y., Chen, J., & Ge, H. (2025). A Follow-Up Risk Identification Model Based on Multi-Source Information Fusion. Systems, 13(1), 41. https://doi.org/10.3390/systems13010041