Ontology-Based Big Data Management

{kind=link}
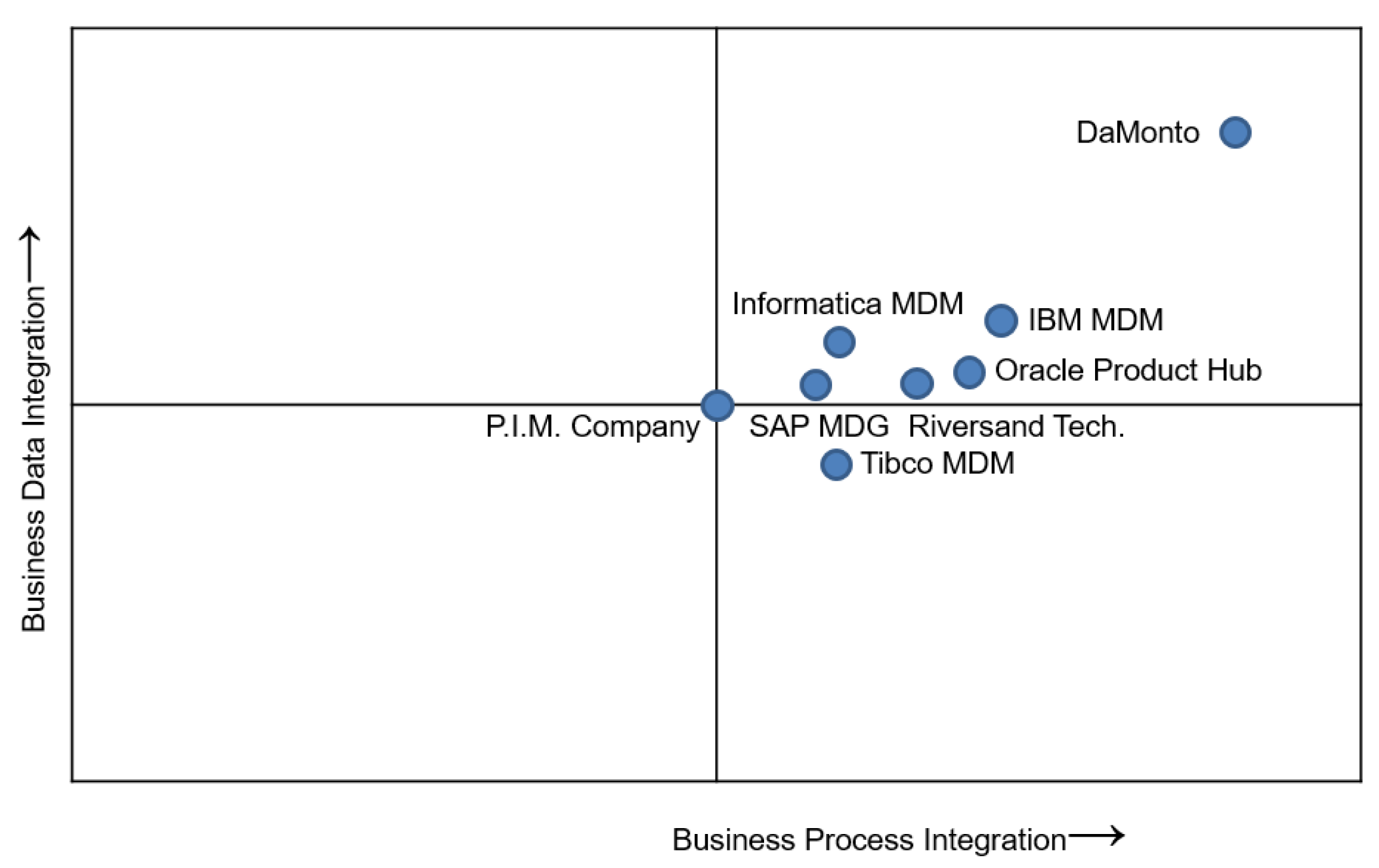{kind=link}
Abstract
:1. Introduction
2. Background & Related Work
2.1. Big Data
2.2. Semantic Technologies
2.2.1. Ontologies
2.2.2. Semantic Web
2.2.3. Semantic Desktop
2.3. Semantic Technologies and Information Systems
3. Use Cases
3.1. Data Integration
3.2. Data Quality
3.3. Business Process Integration
4. Method Comparison
5. Discussion
6. Conclusions
Author Contributions
Conflicts of Interest
References
- O’Brien, J.A.; Marakas, G. Management Information Systems; McGraw-Hill Irwin: New York, NY, USA, 2011. [Google Scholar]
- Manyika, J.; Chui, M.; Brown, B.; Bughin, J.; Dobbs, R.; Roxburgh, C.; Byers, A.H. Big Data: The Next Frontier for Innovation, Competition, and Productivity; The McKinsey Global Institute: New York, NY, USA, 2011. Available online: http://www.mckinsey.com/business-functions/digital-mckinsey/our-insights/big-data-the-next-frontier-for-innovation (accessed on 10 May 2017).
- Sumner, M. Enterprise Resource Planning; Prentince Hall: Upper Saddle River, NJ, USA, 2005. [Google Scholar]
- Philpotts, M. An introduction to the concepts, benefits and terminology of product data management. Ind. Manag. Data Syst. 1996, 96, 11–17. [Google Scholar] [CrossRef]
- Ngai, E.W.T. Customer relationship management research (1992–2002): An academic literature review and classification. Market. Intell. Plan. 2005, 23, 582–605. [Google Scholar] [CrossRef]
- Boiko, B. Content Management Bible; John Wiley & Sons, Inc.: New York, NY, USA, 2001. [Google Scholar]
- Eine, B.; Jurisch, M.; Quint, W. Semantic Technologies for Managing Complex Product Information in Enterprise Systems. In Innovations in Enterprise Information Systems Management and Engineering (ERP Future 2015), Lecture Notes in Business Information Processing; Springer: Cham, Switzerland, 2016; Volume 245, pp. 111–118. [Google Scholar]
- Gartner Magic Quadrant for Product Information Management 2007. Available online: ftp://public.dhe.ibm.com/software/emea/de/db2/Gartner_MDM_Magic_Quadrant_PIM.pdf (accessed on 10 May 2017).
- Lucas-Nülle, T. Product Information Management in Deutschland—Marktstudie; Pro Literatur Verlag: Mammendorf, Germany, 2005. [Google Scholar]
- Sheldon, P.; Goetz, M. The Forrester Wave: Product Information Management, Q2 2014. Available online: https://www.informatica.com/resources.asset.84dbaa93b4463fbae96a596b2068676d.pdf (accessed on 10 August 2016).
- Gartner Magic Quadrant for Product Information Management (2005). Available online: ftp://public.dhe.ibm.com/software/data/mdm/pdf/ibmPIMMQ.pdf (accessed on 10 May 2017).
- Dumbill, E. What Is Big Data? Available online: https://www.oreilly.com/ideas/what-is-big-data (accessed on 10 May 2017).
- Labrinidis, A.; Jagadish, H.V. Challenges and Opportunities with Big Data. Proc. VLDB Endow. 2012, 5, 2032–2033. [Google Scholar] [CrossRef]
- Beyer, M. Gartner Says Solving “Big Data” Challenge Involves More Than Just Managing Volumes of Data. 2011. Available online: http://www.gartner.com/newsroom/id/1731916 (accessed on 10 May 2017).
- Zikopoulos, P.C.; deRoos, D.; Parasuraman, K.; Deutsch, T.; Corrigan, D.; Giles, J.; Melnyk, R.B. Harness the Power of Big Data—The IBM Big Data Platform. 2011. Available online: http://www-01.ibm.com/software/data/bigdata (accessed on 10 August 2016).
- Blumauer, A.; Pellegrini, T. Semantic Web und semantische Technologien. Zentrale Begriffe und Unterscheidungen. In Semantic Web. Wege Zur Vernetzten Wissensgesellschaft; Pellegrini, T., Blumauer, A., Eds.; Springer: Heidelberg, Germany, 2006; pp. 9–25. [Google Scholar]
- Dengel, A. Semantische Technologien: Grundlagen-Konzepte-Anwendungen; Springer: Berlin/Heidelberg Germany, 2012. [Google Scholar]
- Pepper, S. The TAO of Topic Map—Finding the Way in the Age of Infoglut. Available online: http://www.ontopia.net/topicmaps/materials/tao.html (accessed on 10 May 2017).
- Gruber, T. Ontology. In Encyclopedia of Database Systems; Ling, L., Tamer Öszu, M., Eds.; Springer Science + Business Media: New York, NY, USA, 2009. [Google Scholar]
- Gruber, T. Toward Principles for the Design of Ontologies Used for Knowledge Sharing. Int. J. Hum. Comp. Stud. 1995, 43, 907–928. [Google Scholar] [CrossRef]
- Berners-Lee, T.; Hendler, J.; Lassila, O. The semantic web. Sci. Am. 2001, 284, 28–37. [Google Scholar] [CrossRef]
- Halpin, H. Sense and references on the web. Minds Mach. 2009, 21, 153–178. [Google Scholar] [CrossRef]
- Bizer, C.; Cyganiak, R.; Heath, T. How to Publish Linked Data on the Web. 2007. Available online: http://www4.wiwiss.fu-berlin.de/bizer/pub/LinkedDataTutorial/ (accessed on 10 May 2017).
- Knowledge Processing with Big Data and Semantic Web Technologies. Available online: https://www.insight-centre.org/sites/default/files/publications/kcap_2015_copy_.pdf (accessed on 11 May 2017).
- Ashburner, M.; Ball, C.A.; Blake, J.A.; Botstein, D.; Butler, H.; Cherry, J.M.; Davis, A.P.; Dolinski, K.; Dwight, S.S.; Eppig, J.T.; et al. Gene Ontology: Tool for the unification of biology. Nat. Gen. 2000, 25, 25–29. [Google Scholar] [CrossRef] [PubMed]
- Hepp, M. GoodRelations: An ontology For Describing Products and Services Offers on the Web. In Knowledge Engineering: Practice and Patterns. Proceedings of the 16th International Conference (EKAW), Acitrezza, Italy, 29 September–2 October 2008; Springer: Berlin/Heidelberg, Germany; New York, NY, USA, 2008; pp. 329–346. [Google Scholar]
- Staab, S.; Schnurr, H.-P.; Franz, T.; Hansch, D. Semantische Technologien und Auswirkungen auf Informations und Wissensmanagementsysteme. Available online: http://userpages.unikoblenz.de/~staab/Research/Publications/2008/SemantischeSysteme_Artikel_I_M-preprint.pdf (accessed on 17 June 2016).
- Gams, E. Semantische Content Management Systeme. In Social Semantic Web; Blumauer, A., Ed.; Springer: Berlin, Germany, 2009; pp. 207–226. [Google Scholar]
- Mantsch, M.-T. Anwendungsintegration für den Social Semantic Desktop mittels Publish/Subscribe. Ph.D. Thesis, Universität Koblenz-Landau, Koblenz, German, 2009. [Google Scholar]
- Hepp, M. eClassOWL: A Fully-Fledged Products and Services Ontology in OWL. In Proceedings of the 4th International Semantic Web Conference (ISWC), Galway, Ireland, 6–10 November 2005. [Google Scholar]
- Brunner, J.S.; Ma, L.; Wang, C.; Zhang, L.; Wolfson, D.C.; Pan, Y.; Srinivas, K. Explorations in the use of semantic web technologies for product information management. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 747–756. [Google Scholar]
- Wauer, M.; Schuster, D.; Meinecke, J. Aletheia: An architecture for semantic federation of product information from structured and unstructured sources. In Proceedings of the 12th International Conference on Information Integration and Web-based Applications & Services, Paris, France, 8–10 November 2010; pp. 325–332. [Google Scholar]
- Stolz, A.; Rodriguez-Castro, B.; Hepp, M. Using BMEcat catalogs as a lever for product master data on the semantic web. In Proceedings of the Extended Semantic Web Conference, Montpellier, France, 26–30 May 2013; pp. 623–638. [Google Scholar]
- Fitzpatrick, D.; Coallier, F.; Ratté, S. A holistic approach for the architecture and design of an ontology-based data integration capability in product master data management. In Proceedings of the Product Lifecycle Management: Towards Knowledge-Rich Enterprises—IFIP WG 5.1 International Conference, Montreal, QC, Canada, 9–11 July 2012; Volume 388, pp. 559–568. [Google Scholar]
- Shvaiko, P.; Euzenat, J. Ontology Matching: State of the Art and Future Challenges. IEEE Trans. Knowl. Data Eng. 2011, 25, 158–176. [Google Scholar] [CrossRef]
- Otero-Cerdeira, F.J. Rodriguez-Martinez, A. Gomez-Rodriguez: Ontology matching: A literature review. Expert Syst. Appl. 2015, 42, 949–971. [Google Scholar] [CrossRef]
- Euzenat, J.; Shvaiko, P. Ontology Matching; Springer: Heidelberg Germany, 2013. [Google Scholar]
- Otero-Cerdeira, L.; Rodriguez-Martinez, F.J.; Gomez-Rodriguez, A. Ontology matching: A literature review. Expert Syst. Appl. 2015, 42, 946–971. [Google Scholar] [CrossRef]
- Delone, W.H.; McLean, E.R. The DeLone and McLean Model of Information Systems Success: A Ten-Year Update. J. Manag. Inf. Syst. 2003, 19, 9–30. [Google Scholar]
- Wang, R.Y.; Strong, D.M. Beyond Accuracy: What Data Quality Means to Data Consumers. J. Manag. Inf. Syst. 1996, 12, 5–33. [Google Scholar] [CrossRef]
- Delone, W.H.; McLean, E.R. Measuring e-Commerce Success: Applying the DeLone & McLean Information Systems Success Model. Int. J. Electron. Commer. 2004, 9, 31–47. [Google Scholar]
- Davis, F.D.; Bagozzi, R.P.; Warshaw, P.R. User acceptance of computer technology: A comparison of two theoretical models. Manag. Sci. 1989, 35, 982–1003. [Google Scholar] [CrossRef]
- Wang, Y. Assessing E-Commerce Systems Success: A Respecification and Validation of the DeLone and McLean Model of IS Success. Inf. Syst. J. 2008, 18, 529–557. [Google Scholar] [CrossRef]
- Esswein, S.; Goasguen, S.; Post, C.; Hallstrom, J.; White, D.; Eidson, G. Towards ontology-based data quality inference in large-scale sensor networks. In Proceedings of the 2012 12th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (ccgrid), Ottawa, ON, Canada, 13–16 May 2012; pp. 898–903. [Google Scholar]
- Martin, N. A Methodology and Architecture Embedding Quality Assessment in Data Integration. J. Data Inf. Qual. 2014, 4, 1–40. [Google Scholar] [CrossRef]
- Fürber, C.; Hepp, M. Towards a Vocabulary for Data Quality Management in Semantic Web Architectures. In Proceedings of the 1st International Workshop on Linked Web Data Management (LWDM), Uppsala, Sweden, 21–24 March 2011; pp. 1–8. [Google Scholar]
- Garijo, D.; Rey, M. A New Approach for Publishing Workflows: Abstractions, Standards, and Linked Data. In Proceedings of the 6th Workshop on Workflows in Support of Large-Scale Science, Seattle, WA, USA, 12–18 November 2011; pp. 47–56. [Google Scholar]
- Rospocher, M.; Ghidini, C.; Serafini, L. An ontology for the Business Process Modelling Notation. Front. Artif. Intell. Appl. 2014, 267, 133–146. [Google Scholar]
- Gartner Magic Quadrant for Business Intelligence and Analytics Platforms (2016). Available online: https://www.gartner.com/doc/reprints?id=1-2XXET8P&ct=160204 (accessed on 10 August 2016).
- Sheldon, P.; Goetz, M. The Forrester Wave: Product Information Management (PIM), Q2 2014. Available online: http://www.hybris.com/medias/sys_master/formsCollaterals/formsCollaterals/hec/h36/8808347926558/Hybris-Forrester-PIM-2014.pdf (accessed on 10 May 2017).
- Nigel, M.; Poulovassilis, A.; Wang, J. A methodology and architecture embedding quality assessment in data integration. J. Data Inf. Qual. 2014, 4, 17. [Google Scholar]
- Batista, M.D.C.M.; Salgado, A.C. Information Quality Measurement in Data Integration Schemas. In Proceedings of the 5th International Workshop on Quality in Databases at VLDB, Vienna, Austria, 23 September 2007; pp. 61–72. [Google Scholar]
- Gabler Wirtschaftslexikon Datenintegration. Available online: http://wirtschaftslexikon.gabler.de/Archiv/74965/datenintegration-v8.html (accessed on 10 May 2017).
- Conrad, S.; Hasselbring, W.; Koschel, A.; Tritsch, R. Enterprise Application Integration–Grundlagen. Konzepte, Entwurfsmuster, Praxisbeispiele; Spektrum: München, Germany, 2005. [Google Scholar]
- Heinrich, M.; Boehm-Peters, A.; Knechtel, M. A platform to automatically generate and incorporate documents into an ontology-based content repository. In Proceedings of the 9th ACM Symposium on Document Engineering, Munich, Germany, 16–18 September 2009; pp. 43–46. [Google Scholar]
- Oberle, D. How ontologies benefit enterprise applications. Semant. Web 2014, 5, 473–491. [Google Scholar]
- Otero-Cerdeira, L.; Rodríguez-Martínez, F.J.; Gómez-Rodríguez, A. Ontology matching: A literature review. Expert Syst. Appl. 2015, 42, 949–971. [Google Scholar] [CrossRef]


© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eine, B.; Jurisch, M.; Quint, W. Ontology-Based Big Data Management. Systems 2017, 5, 45. https://doi.org/10.3390/systems5030045
Eine B, Jurisch M, Quint W. Ontology-Based Big Data Management. Systems. 2017; 5(3):45. https://doi.org/10.3390/systems5030045
Chicago/Turabian StyleEine, Bastian, Matthias Jurisch, and Werner Quint. 2017. "Ontology-Based Big Data Management" Systems 5, no. 3: 45. https://doi.org/10.3390/systems5030045
APA StyleEine, B., Jurisch, M., & Quint, W. (2017). Ontology-Based Big Data Management. Systems, 5(3), 45. https://doi.org/10.3390/systems5030045