Trust Perceptions of Metadata in Open-Source Software: The Role of Performance and Reputation

Abstract
:1. Introduction
1.1. Trust and OSS Interactions
1.2. Heuristic-Systematic Processing Model of Trust in Code
2. Method
2.1. Participants
2.2. Measures
2.2.1. Trustworthiness
2.2.2. Remarks
2.2.3. Timing
2.2.4. Click amount
2.2.5. Willingness to Reuse Code
2.3. Stimuli
2.4. Procedure
2.5. Analysis
3. Results
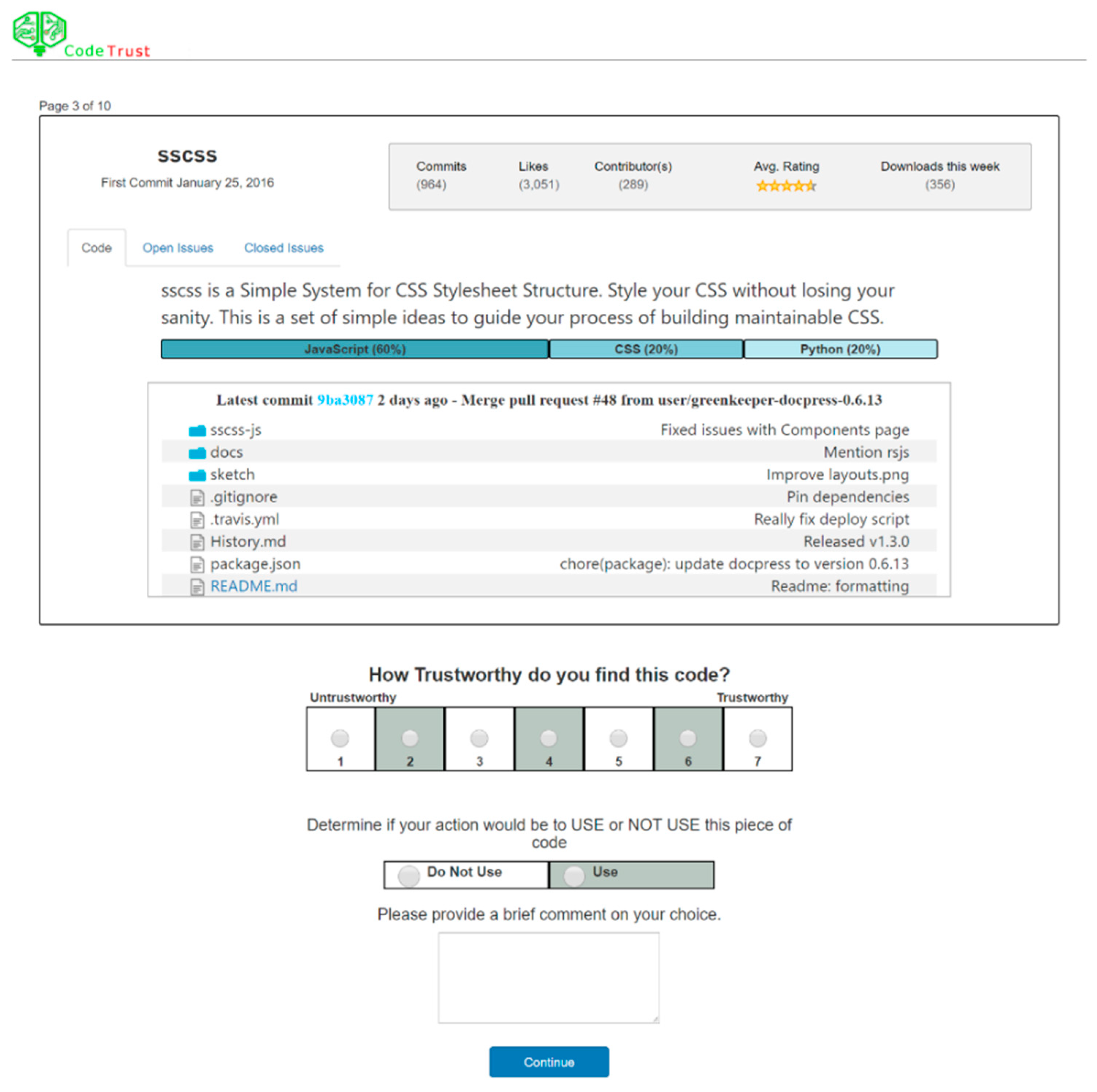
3.1. Time Spent on Code
3.2. Number of Clicks
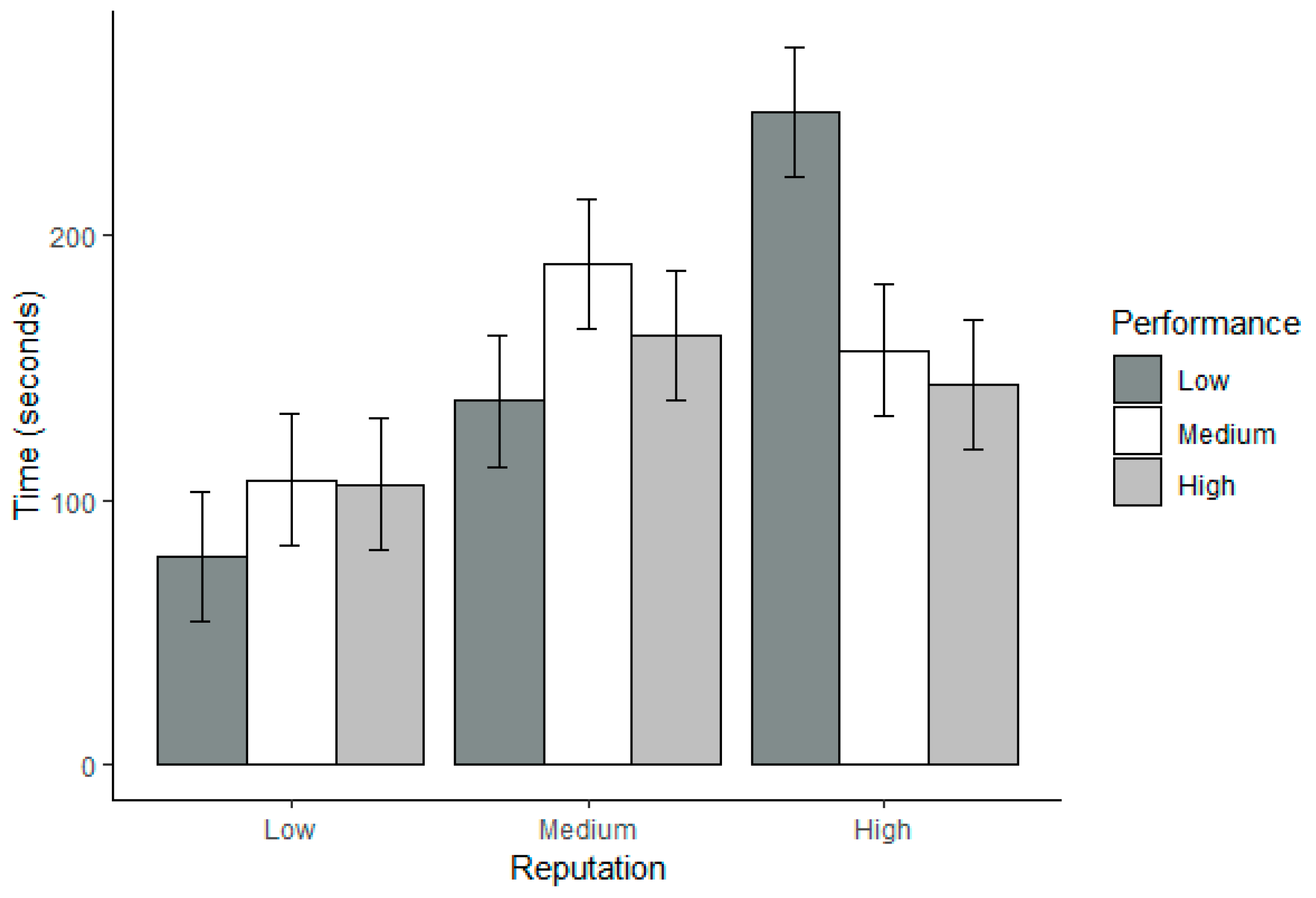
3.3. Trustworthiness
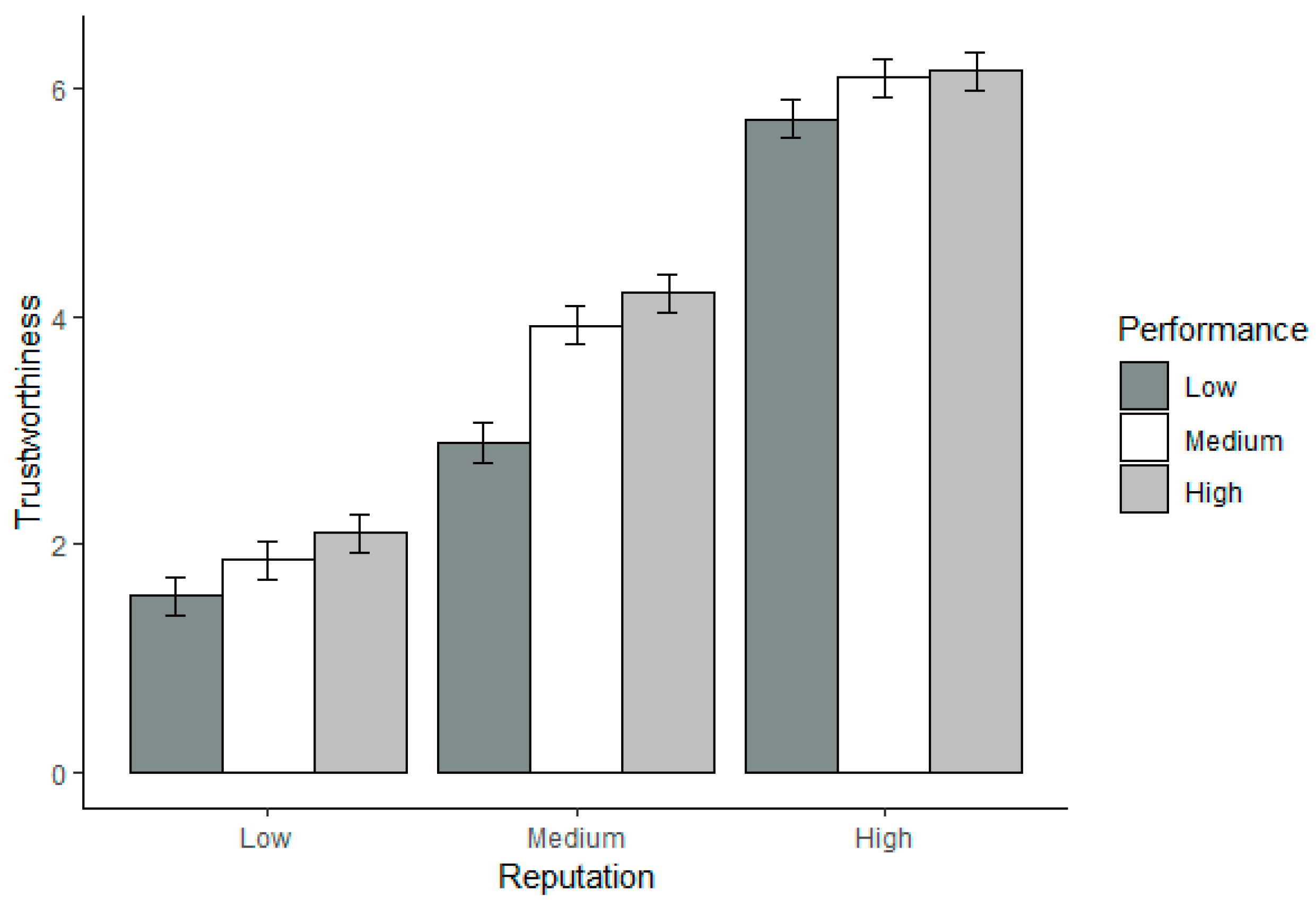
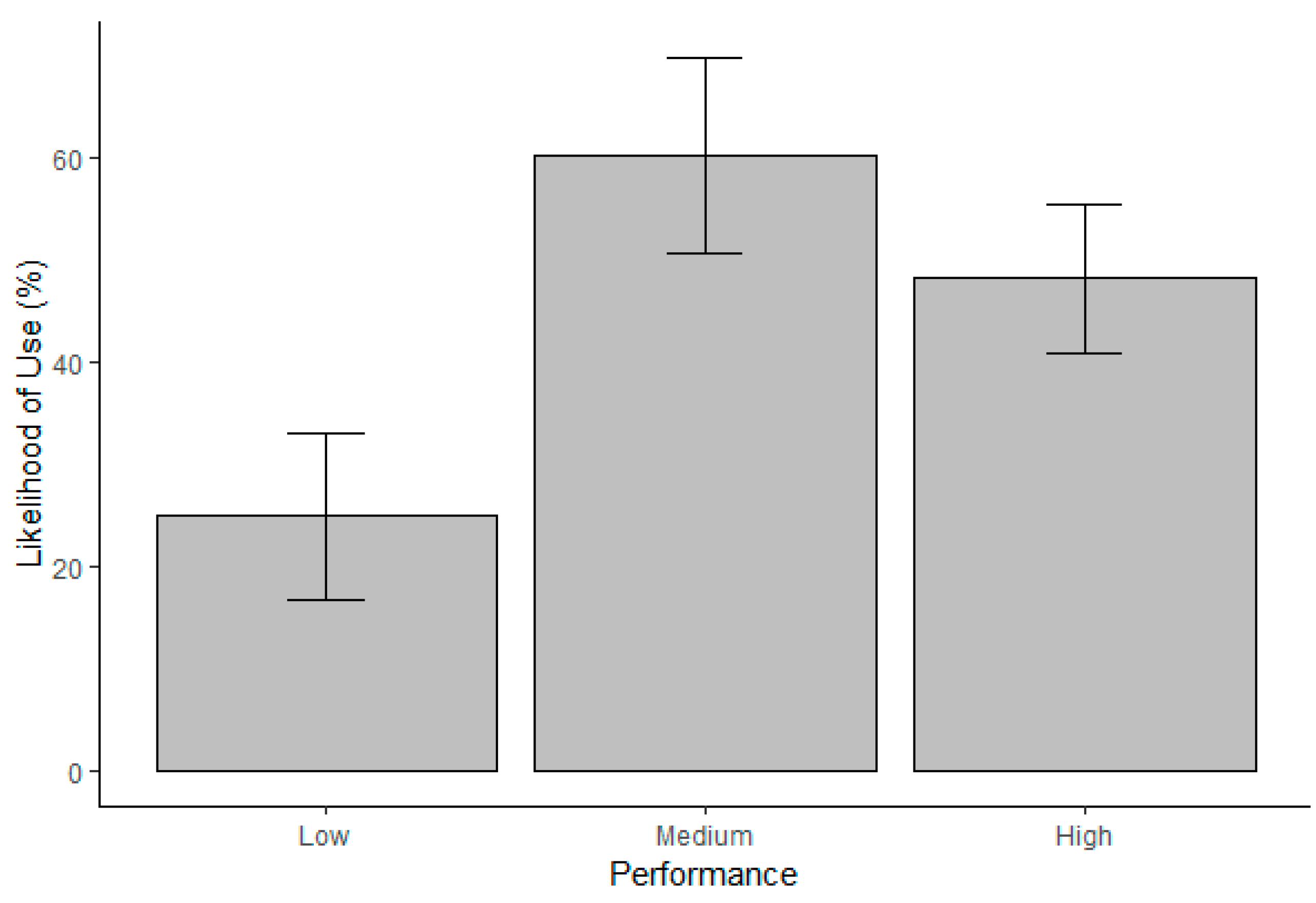
3.4. Willingness to Reuse the Code
4. Discussion
4.1. Reputation
4.2. Performance
4.3. Interactions
4.4. Limitations and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Alarcon, G.M.; Gamble, R.; Jessup, S.A.; Walter, C.; Ryan, T.J.; Wood, D.W.; Calhoun, C.S. Application of the heuristic-systematic model to computer code trustworthiness: The influence of reputation and transparency. Cogent Psychol. 2017, 4, 1389640. [Google Scholar] [CrossRef]
- Alarcon, G.M.; Militello, L.G.; Ryan, P.; Jessup, S.A.; Calhoun, C.S.; Lyons, J.B. A descriptive model of computer code trustworthiness. J. Cogn. Eng. Decis. Mak. 2017, 11, 107–121. [Google Scholar] [CrossRef]
- Li, J.; Conradi, R.; Slyngstad, O.P.N.; Bunse, C.; Torchiano, M.; Morisio, M. An empirical study on decision making in off-the-shelf component-based development. In Proceedings of the 28th International Conference on Software Engineering, Shanghai, China, 20–28 May 2006; pp. 897–900. [Google Scholar]
- Weber, S.; Luo, J. What makes an open source code popular on github? In Proceedings of the 2014 IEEE International Conference on Data Mining Workshop, Shenzhen, China, 14 December 2014; pp. 851–855. [Google Scholar]
- Mayer, R.C.; Davis, J.H.; Schoorman, F.D. An integrative model of organizational trust. Acad. Manag. Rev. 1995, 20, 709–734. [Google Scholar] [CrossRef]
- Lee, J.D.; See, K.A. Trust in automation: Designing for appropriate reliance. Hum. Factors 2004, 46, 50–80. [Google Scholar] [CrossRef] [PubMed]
- Oleson, K.E.; Billings, D.R.; Kocsis, V.; Chen, J.Y.C.; Hancock, P.A. Antecedents of trust in human-robot collaborations. In Proceedings of the 2011 IEEE International Multi-Disciplinary Conference on Cognitive Methods in Situation Awareness and Decision Support, Miami, FL, USA, 22–24 February 2011; pp. 175–178. [Google Scholar]
- Lyons, J.B.; Ho, N.T.; Koltai, K.S.; Masequesmay, G.; Skoog, M.; Cacanindin, A.; Johnson, W.W. Trust-based analysis of an Air Force collision avoidance system. Ergon. Des. 2016, 24, 9–12. [Google Scholar] [CrossRef]
- Hoff, K.A.; Bashir, M. Trust in automation: Integrating empirical evidence on factors that influence trust. Hum. Factors 2015, 57, 407–434. [Google Scholar] [CrossRef] [PubMed]
- Frakes, W.B.; Kang, K. Software reuse research: Status and future. IEEE Trans. Softw. Eng. 2005, 31, 529–536. [Google Scholar] [CrossRef]
- Hasselbring, W.; Reussner, R. Toward trustworthy software systems. Computer 2006, 39, 91–92. [Google Scholar] [CrossRef]
- Alarcon, G.; Ryan, T. Trustworthiness perceptions of computer code: A heuristic-systematic processing model. In Proceedings of the 51st Hawaii International Conference on System Sciences, Hilton Waikoloa Village, HI, USA, 3–6 January 2018; pp. 5384–5393. [Google Scholar]
- Chaiken, S. Heuristic versus systematic information processing and the use of source versus message cues in persuasion. J. Personal. Soc. Psychol. 1980, 39, 752–766. [Google Scholar] [CrossRef]
- Chen, S.; Duckworth, K.; Chaiken, S. Motivated heuristic and systematic processing. Psychol. Inq. 1999, 10, 44–49. [Google Scholar] [CrossRef]
- Kahneman, D. Thinking, Fast and Slow; Macmillan: New York City, NY, USA, 2011; ISBN 978-0374275631. [Google Scholar]
- Alarcon, G.M.; Gamble, R.F.; Ryan, T.J.; Walter, C.; Jessup, S.A.; Wood, D.W.; Capiola, A. The influence of commenting validity, placement, and style on perceptions of computer code trustworthiness: A heuristic-systematic processing approach. Appl. Ergon. 2018, 70, 182–193. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Li, J.; Ma, J.; Conradi, R.; Ji, J.; Liu, C. An empirical study on software development with open source components in the Chinese software industry. Softw. Process Improv. Pract. 2008, 13, 89–100. [Google Scholar] [CrossRef] [Green Version]
- Gallardo-Valencia, R.E.; Tantikul, P.; Sim, S.E. Searching for reputable source code on the web. In Proceedings of the 16th ACM International Conference on Supporting Group Work, Sanibel Island, FL, USA, 13–16 November 2010; pp. 183–186. [Google Scholar]
- Sim, S.E.; Umarji, M.; Ratanotayanon, S.; Lopes, C.V. How well do internet code search engines support open source reuse strategies. ACM Trans. Softw. Eng. Methodol. 2009, 21, 1–22. [Google Scholar] [CrossRef]
- Ryan, T.J.; Walter, C.; Alarcon, G.M.; Gamble, R.F.; Jessup, S.A.; Capiola, A.A. Individual differences in trust in code: The moderating effects of personality on the trustworthiness-trust relationship. In Proceedings of the International Conference on Human-Computer Interaction, Las Vegas, NV, USA, 15–20 July 2018; pp. 370–376. [Google Scholar]
- Walter, C.; Gamble, R.; Alarcon, G.; Jessup, S.; Calhoun, C. Developing a mechanism to study code trustworthiness. In Proceedings of the 50th Hawaii International Conference on System Sciences, Hilton Waikoloa Village, HI, USA, 4–7 January 2017; pp. 5817–5826. [Google Scholar]
- Lingzi, X.; Zhi, L. An Overview of Source Code Audit. In Proceedings of the 2015 International Conference on Industrial Informatics-Computing Technology, Intelligent Technology, Industrial Information Integration, Wuhan, China, 3–4 December 2015; pp. 26–29. [Google Scholar]
- Wanous, J.P.; Reichers, A.E.; Hudy, M.J. Overall job satisfaction: How good are single-item measures? J. Appl. Psychol. 1997, 82, 247–252. [Google Scholar] [CrossRef] [PubMed]
- Faul, F.; Erdfelder, E.; Lang, A.G.; Buchner, A. G* Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behav. Res. Methods 2007, 39, 175–191. [Google Scholar] [CrossRef] [PubMed]
- Jones, S.L.; Shah, P.P. Diagnosing the locus of trust: A temporal perspective for trustor, trustee, and dyadic influences on perceived trustworthiness. J. Appl. Psychol. 2016, 101, 392–414. [Google Scholar] [CrossRef] [PubMed]
- Ryan, T.J.; Walter, C.; Alarcon, G.M.; Gamble, R.; Jessup, S.A. The influence of personality on code reuse. In Proceedings of the 52nd Hawaii International Conference on Systems Sciences, Maui, HI, USA, 7–11 January 2019; pp. 5805–5814. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Manipulation | Features | Levels | ||
|---|---|---|---|---|
| Low | Medium | High | ||
| Reputation | Likes | ≤499 | 500–1999 | ≥2000 |
| Stars | 0–2.5 | 2.5–3.5 | 3.5–5 | |
| Downloads last week | ≤50 | 51–199 | ≥200 | |
| Last Commit Date | ≥16 days | 4–15 days | ≤3 days | |
| General Product Description | >2 spelling or grammar errors | 1–2 spelling or grammar errors | No spelling or grammar errors | |
| Total Commits | ≤200 | 201–499 | ≥500 | |
| Dates of Open Issues | ≤7 days ago | 7–30 days ago | 31–365 days ago | |
| Dates of Closed Issues | 31–365 days ago | 7–30 days ago | ≤7 days ago | |
| File Structure | Few well named files | Some well named files | Well named files | |
| Performance | # of Contributors | 0.5 < # contributors/commits | 0.25 < # contributors/commits < 0.30 | 0.05 < # contributors/commits < 0.10 |
| Ratio of Open to Closed Issues | ≥0.5 | ≤0.49 | ≤0.15 | |
| Description of Open Issues | Mainly functionally related | Some functionally related | Not functionally related | |
| Description of Closed Issues | Not functionally related | Some functionally related | Mainly functionally related | |
| Commit Messages | Very vague | Partially vague | Descriptive | |
| Technical Product Description | Vague or absent ReadMe | Somewhat vague ReadMe | Detailed ReadMe | |
| # of Unique Languages | >5 | 2–3 | 1–2 | |
| Date of First Commit | <3 months ago | 3–12 months ago | >12 months ago | |
| Reputation | Performance | |||||
|---|---|---|---|---|---|---|
| Code # | Reputation | Performance | Positive | Negative | Positive | Negative |
| 7 | High | High | 22 | 1 | 32 | 4 |
| 8 | High | Medium | 0 | 27 | 2 | 29 |
| 5 | High | Low | 0 | 24 | 0 | 33 |
| 1 | Medium | High | 20 | 0 | 28 | 8 |
| 3 | Medium | Medium | 27 | 0 | 32 | 1 |
| 2 | Medium | Low | 1 | 21 | 1 | 33 |
| 4 | Low | High | 3 | 18 | 12 | 27 |
| 6 | Low | Medium | 14 | 8 | 19 | 20 |
| 9 | Low | Low | 0 | 25 | 1 | 33 |
| 10 | Distractor | Distractor | 0 | 25 | 0 | 33 |
| Mean Estimates | IV | df | F | ηp2 | |||
|---|---|---|---|---|---|---|---|
| Performance | |||||||
| Reputation | Low | Medium | High | ||||
| Low | 78.60 (24.80) | 107.60 (24.80) | 105.90 (24.80) | Reputation (A) | 1.75, 64.75 | 13.71 ** | 27 |
| Medium | 137.50 (24.80) | 189.20 (24.80) | 162.00 (24.80) | Performance (B) | 1.60, 59.07 | 0.40 | 0.01 |
| High | 246.60 (24.80) | 156.60 (24.80) | 143.70 (24.80) | A × B | 2.69, 99.59 | 3.35 * | 0.08 |
| Mean Estimates | IV | df | Wald χ2 | |||
|---|---|---|---|---|---|---|
| Performance | ||||||
| Reputation | Low | Medium | High | |||
| Low | 3.56 (0.56) | 3.69 (0.58) | 3.30 (0.52) | Reputation (A) | 2 | 7.04 * |
| Medium | 3.75 (0.58) | 4.50 (0.69) | 3.88 (0.60) | Performance (B) | 2 | 4.40 |
| High | 5.25 (0.79) | 3.45 (0.54) | 3.73 (0.58) | A × B | 4 | 19.55 ** |
| Mean Estimates | IV | df | F | ηp2 | |||
|---|---|---|---|---|---|---|---|
| Performance | |||||||
| Reputation | Low | Medium | High | ||||
| Low | 1.55 (0.17) | 1.87 (0.17) | 2.11 (0.17) | Reputation (A) | 1.92, 71.17 | 331.68 ** | 90 |
| Medium | 2.89 (0.17) | 3.92 (0.17) | 4.21 (0.17) | Performance (B) | 1.69, 62.64 | 20.16 ** | 35 |
| High | 5.74 (0.17) | 6.11 (0.17) | 6.16 (0.17) | A × B | 3.52, 130.36 | 3.86 ** | 09 |
| Mean Estimates | IV | df | Wald χ2 | |||
|---|---|---|---|---|---|---|
| Performance | ||||||
| Reputation | Low | Medium | High | |||
| Low | 2.62 (2.59) | 10.49 (4.99) | 7.86 (4.38) | Reputation (A) | 2 | 6.99 * |
| Medium | 10.49 (4.99) | 44.72 (8.18) | 52.64 (8.22) | Performance (B) | 2 | 84.78 ** |
| High | 92.14 (4.38) | 97.38 (2.59) | 89.51 (4.99) | A × B | 4 | 6.99 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alarcon, G.M.; Gibson, A.M.; Walter, C.; Gamble, R.F.; Ryan, T.J.; Jessup, S.A.; Boyd, B.E.; Capiola, A. Trust Perceptions of Metadata in Open-Source Software: The Role of Performance and Reputation. Systems 2020, 8, 28. https://doi.org/10.3390/systems8030028
Alarcon GM, Gibson AM, Walter C, Gamble RF, Ryan TJ, Jessup SA, Boyd BE, Capiola A. Trust Perceptions of Metadata in Open-Source Software: The Role of Performance and Reputation. Systems. 2020; 8(3):28. https://doi.org/10.3390/systems8030028
Chicago/Turabian StyleAlarcon, Gene M., Anthony M. Gibson, Charles Walter, Rose F. Gamble, Tyler J. Ryan, Sarah A. Jessup, Brian E. Boyd, and August Capiola. 2020. "Trust Perceptions of Metadata in Open-Source Software: The Role of Performance and Reputation" Systems 8, no. 3: 28. https://doi.org/10.3390/systems8030028
APA StyleAlarcon, G. M., Gibson, A. M., Walter, C., Gamble, R. F., Ryan, T. J., Jessup, S. A., Boyd, B. E., & Capiola, A. (2020). Trust Perceptions of Metadata in Open-Source Software: The Role of Performance and Reputation. Systems, 8(3), 28. https://doi.org/10.3390/systems8030028