1. Introduction
Despite the rosy outlook surrounding the venture capital industry, most funds are not profitable and may barely break even; the top 2% of venture capital (“VC”) funds receive 95% of the returns in the industry [
1]. Evaluating startups can be largely subjective and earlier stage companies are relatively more unpredictable as there is less historical data. Additionally, venture capital is highly concentrated both geographically and developmentally, and it is arguably very difficult to predict a successful startup let alone determine whether an early-stage company fits a VC firm’s investment thesis. Therefore, VC firms may consider a wide range of quantitative and qualitative factors when evaluating an early-stage startup such as the industry sector, amount of funding, return on investment trends, management team, relevant qualifications of the founders, market potential, and competitive advantage. These considerations can be broken down further into specific indicators that VC firms are looking to invest in based on their investment thesis. Each firm’s investment thesis may be different, and decisions to invest or not invest in a startup will differ based on these theses.
The venture capital scorecard method is one such startup evaluation method of many which consider a diverse range of criteria. Initially motivated by developing a systematic approach for managers to measure the value of intangible assets to improve company performance, Kaplan and Norton introduced the general scorecard method in 1992 [
2,
3]. However, the rudimentary idea of using non-quantitative and non-financial traits to measure company performance traces further back. For example, in the 1950s, GE created a system to measure the performance of its business units using eight criteria, only one of which was financial [
4]. Furthermore, in the 1970s and 1980s, US management experts claimed that US companies were too focused on managing short-term financial performance compared to the long-term health and managerial success of a company [
5]. Kaplan and Norton’s balanced scorecard method prioritizes company strategy and relationships that influence sustainable stakeholder and shareholder value, which align with the general motives of the long-term investments in venture capital. Thus, the balanced scorecard method became commonly adopted across many kinds of companies and management systems including venture capital investment firms.
Past startup evaluation methods have explored predicting the success and failure of certain projects based on criteria [
6,
7,
8,
9]. Some research has used different models and machine learning techniques to analyze which classification methods are most accurate [
10,
11]. These tests are generally based on widely available public data of large companies such as Spotify as a base case [
10]. They primarily use quantitative data based on startup performance such as cash burn rate and common VC metrics such as valuation and market value [
12].
Additional studies include qualitative characteristics of startups such as founder attributes, startup performance, and team dynamics to identify characteristics that may indicate red flags in developing a founding group [
13,
14,
15,
16]. On the other hand, studies may explore the characteristics of successful entrepreneurs [
17], diving into personality traits such as stress tolerance and innovativeness. The results may imply that economic background and openness to change are influential factors in founders [
18]. Some model results ranked the importance of certain traits as well. Qualitative factors focused on social metrics have been increasingly used in startup predictability such as social network schemes of founders [
19] and startup engagement on social media platforms [
20,
21,
22].
Our research employs similar qualitative and quantitative characteristics as prior studies; however, we focus on decisions from a single venture capital firm retrospectively evaluating late-stage companies as a favorable or unfavorable investment. We chose to use common machine learning models to support the evaluation process to discover which characteristics were more influential in decision-making, as well as which models were most accurate in predictability of investment decisions. Machine learning has been increasingly used by firms to support investment decisions and have been found to decrease bias and increase predictability success [
23]. Specifically, models can be more helpful for novice firms and identifying outliers that could be potential “unicorns” [
24].
2. Materials and Methods
The variables employed in this study consist of company characteristics collected by RSC, whose primary investment focus is on e-commerce businesses. Instead of collecting data on early-stage startups, RSC studied late-stage companies because there is more information on the developed companies, both failed and successful. For example, based on the current success of Glossier, the firm decides it would have liked to invest in the company at the time it was in pre-seed funding. Using the vast coverage on Glossier, we can analyze the qualities of the company when it was a startup to collect desired data for the machine learning task. Compared to early-stage companies, focusing on late-stage startups allows the firm to make more educated retrospective investment decisions based on more accurate company characteristics, which is essential in building successful machine learning models.
To facilitate this research, RSC studied 100 known late-stage companies and quantitatively scored various characteristics (
Table 1) that the management team believed to be highly pertinent in making the investment decisions. The 100 companies were carefully selected to constitute an equal number of favorable (i.e., “yes”) and unfavorable (i.e., “no”) instances, and thus engendering a binary classification task in the machine learning domain. The companies were also chosen to encompass a wide variety of industries and sizes. The framework for choosing these companies was that there was enough public information to fill out the balanced scorecard and make an investment decision.
We evaluated the performance of six established machine learning models and their counterparts with an additional feature selection technique. We performed factor analysis to provide insights on the top predictive features identified by the linear and tree-based machine learning models. Evidenced by a noticeable performance gap between the two classes on a balanced dataset, our experimental results suggest that it is easier to identify attractive investments (i.e., “yes” class) as compared to those unfavorable ones (i.e., “no” class). Furthermore, with the additional feature selection technique, the models are not only capable of delivering improved predictive accuracies but also effective in reducing the performance discrepancy between the two classes for some models. These tailored models can be insightful in providing guidance on what company traits could be weighed more in future investment decisions.
2.1. The Data
The dataset for our study is collected from 100 successful and unsuccessful companies that have passed the early stage and startup phases and range from defunct or struggling companies such as WeWork to successfully exited unicorns such as Facebook. By using data of companies with established reputations, we can generate patterns about retrospective decisions of investing in order to apply a theory to future prospective startups. Specifically, the data consist of 50 companies that resulted in a “yes” for investing and 50 that resulted in a “no” opinion along with other attributes that total 15 characteristics about each company.
The data encompasses a diverse range of later stage companies, varying in size, industry, and age. Each descriptive variable is sorted into the quantitative measurements of scored criteria by the management team of RSC. The team populated the research data by conducting weekly meetings for a duration of approximately one month. Basic research using any publicly available data including news, financing reports, and social media were all included in due diligence. The team produced data on the subjective aspects of the criteria for scoring the companies, in addition to the quantitative characteristics.
Table 1 presents the attribute statistics of the favorable (i.e., “yes”) and unfavorable (i.e., “no”) companies collected for this study.
The attributes are split into qualities that apply to the founding team and qualities that apply to the company itself and the products. For the data of attributes of the team, we observe that in every category the VC firm favors subjectively positive characteristics in founders. Every founder attribute has a higher average of approximately one point among the companies the firm would have liked to invest in. “Years of Relevant Experience”, “Team Management”, and “Planning Strategy” are particularly higher on averages among favorable companies.
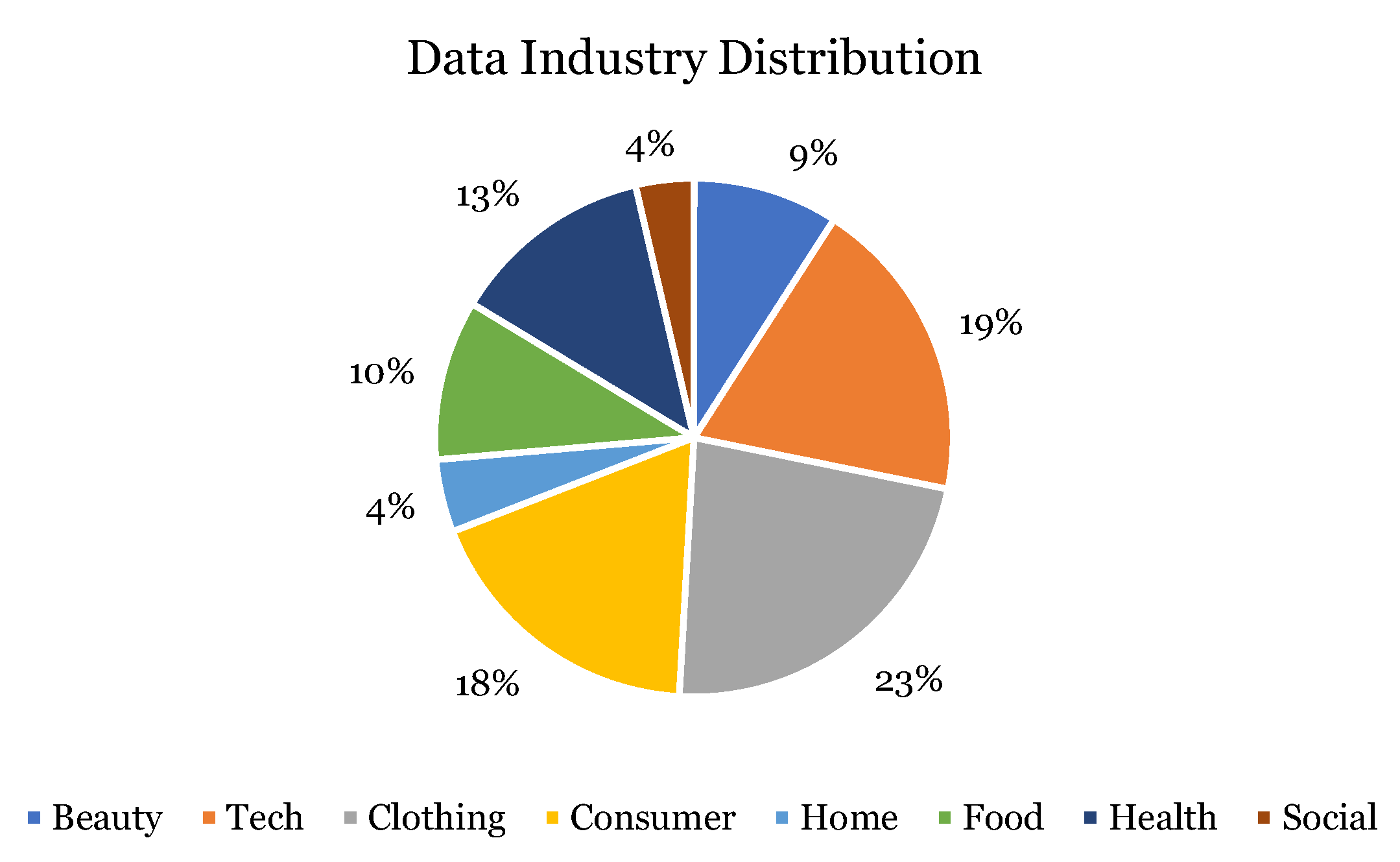
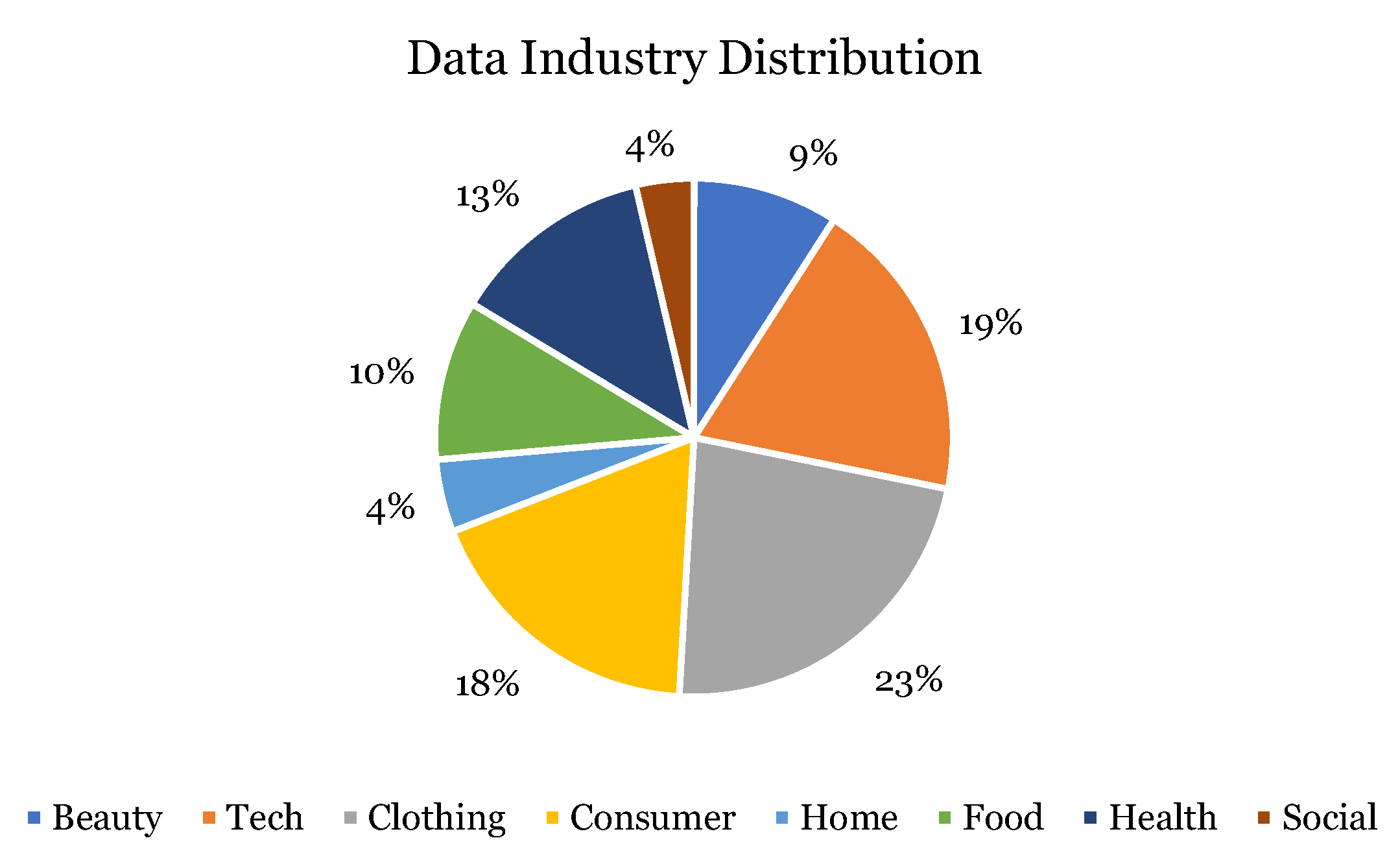
Among all the industries, the most common industries of the companies are technology, clothing, and consumer goods (
Figure 1). Only four of the 100 companies belonged in the social media and entertainment industry. Based on the data, the industries that the firm would most likely have invested in are consumer goods and clothing (
Figure 2). Out of all the companies they would not have invested in, many of them belonged in the technology sector (
Figure 3).
2.2. Methods
We employed six classifiers and six corresponding meta-classifiers with the additional attribute selection technique.
2.2.1. Decision Trees
A decision tree uses nodes that connect data observations to predict a certain outcome of a chosen variable [
25]. Decisions trees can use both quantitative and categorical data to draw patterns that result in a certain concl
, where
Y is the desired outcome variable and
contains the set of features that leads to that outcome. The model uses a tree structure to model the data in which each leaf node corresponds to a decision outcome and the internal nodes are the attributes. Each tree branch represents a potential value of its parent node (i.e., an attribute). The ranking of feature importance follows the order of attributes that the algorithm chooses to split the branches.
2.2.2. Random Forest
Random Forest modeling [
26] employs a collection of decision tree classifiers each of which is trained using a random subset of training instances and data attributes. By pooling predictions from multiple decision trees, a Random Forest model reduces the variance of each individual decision tree and achieves a more robust and superior performance. In our experiment, we utilized 100 decision trees in our Random Forest model.
2.2.3. Naive Bayes
A Bayes classifier belongs to the family of probabilistic generative models [
27]. It is based on Bayes Theorem in that
A can be predicted if
B has happened. In a binary classification task, predictions are set to the larger of
where
are the labels, and
represents the observed attributes. A Naive Bayes classifier further assumes that features are independent of each other given the class label, which simplifies the evaluation of
to
.
2.2.4. Logistic Regression
Logistic regression as a statistical classification system is most commonly used with binary results [
28]. The target
Y variable is first modeled as a linear function of
X, and then the numerical predictions of
Y are transformed into probability scores using a sigmoid function. Thus, the nature of the classification is dichotomous and is based on the basic logistic function that produces scores between 0 and 1. In a binary classification task, the scores indicate a corresponding instance’s likelihood of belonging to the positive (i.e., “yes”) class. A cutoff (default 0.5) can be established to further customize the decision boundary.
2.2.5. Neural Network
The Neural Network model mimics the methods of biological brains to solve predictive problems [
29]. The model structure consists of an input layer, one or more hidden layer(s), and one output layer. The adjacent layers are connected by transferring the values in one layer to a new set of values in the next layer with a set of weights and an activation function. The performance of the model is measured by the consistency between the model outputs and the true class labels of the input instances. “Training” is the process of adjusting the network weights to achieve the highest consistency (i.e., cross entropy) between the model outputs and the true class labels.
2.2.6. Support Vector Machine (SVM)
SVM is also known as maximum margin classifier which aims to maximize the distance between the hyperplane and the data points of both classes [
30]. Maximizing the margin distance reinforces that future data points can be classified with more confidence. SVM is capable of transforming the data into a higher dimensional space using various kernel functions to enhance data separability. In this study, linear SVM is used to facilitate risk factor analysis.
2.2.7. Attribute Selected Classifier
The attribute selected classifier first uses dimensionality reduction to select the most important attributes. The method is a Correlation-based Feature Selection (CFS) algorithm [
31], which applies to the training data and is model independent. Specifically, the dependent variables (i.e., features) are ranked according to their absolute correlations with the target variable (i.e., class labels). A higher absolute correlation implies more feature importance. CFS has been proven to be an efficient and effective technique to reduce noise or bias in dataset with high subjectivity. Our experimental results demonstrate the efficacy of CFS for our machine learning task.
3. Results
The data were analyzed through the WEKA machine learning software [
32]. All experiments were conducted using 10-fold cross validation, in which the dataset is partitioned into 10 stratified non-overlapping folds. Each fold was subsequently held out as the test data while the remaining folds form the training data. We report the average model performance of the 10 test folds. In addition to the overall predictive accuracy, we present the separate accuracies on the “yes” (i.e., Sensitivity) and “no” classes (i.e., Specificity), respectively.
3.1. Model Performance Analysis
Table 2 represents the performance results of the models with the highest accuracies based on the WEKA machine learning program. The predictability accuracies for each model are further distinguished into correctly predicted “yes” decisions (i.e., Sensitivity) and “no” decisions (i.e., Specificity).
Out of the six standard machine learning models, the model with the highest overall accuracy is the Neural Network model with an accuracy of 77%. Logistic Regression model achieves similar overall performance (76%). Examining the results in the Sensitivity and Specificity columns, we observe that the Neural Network model was more effective at predicting the “no” decisions, while the Logistic Regression model was more adept in predicting the “yes” companies.
Of the six standard models, the least accurate model is the Naïve Bayes model, which may be due in part to the nature of the algorithm which assumes no dependence or correlation of any of the attributes. This assumption is likely violated since some startup characteristics may indeed be highly correlated to each other. The range of overall accuracies for the top scores is slightly smaller for the meta-classifier used compared to the regular models.
Table 2 further demonstrates that the meta-classifiers improved the overall performance of each corresponding standard model except for Neural Network. Boosted by the feature selection technique, the top overall performing meta-classifiers are the Logistic Regression and SVM models with an overall accuracy of 78%, and an average of 87% and 69% on the “yes” and “no” classes, respectively. We further observe a consistent performance gain over the standard models across both the favorable and unfavorable classes. On average, the meta-classifiers improved the prediction accuracies in the favorable companies more than the unfavorable ones.
In addition to delivering performance gains, the feature selection technique was also effective in reducing the performance gap between the two classes for some models (e.g., Neural Networks and Random Forest). Nevertheless, based on the averages of all the meta-classifiers, the predictability accuracy remains higher for the “yes” class compared to the “no” class, with an average of 0.81 and 0.69, respectively. Since our dataset is balanced, this performance bias suggests that it is easier to identify which companies are more attractive investments to the firm opposed to which companies may not fit into the investment thesis.
3.2. Predictive Factor Analysis
Additionally, we studied the major attributes which affected the decision-making of each model. We extracted the top predictive features for the linear and tree-based algorithms, in which the contribution of each feature to the decision-making process is well-defined.
Table 3 presents the top five predictive attributes for the Random Forest, Logistic Regression, and Decision Tree models. Similar analysis was performed on the meta-classifiers and the results are presented in
Table 4.
In
Table 3, we observe that the ability to plan well is important as it is the highest-weighted attribute for three out of four algorithms. The most weighted attribute for the Random Forest model was whether the company was in the social or entertainment industry, followed by other traits such as the size of the founding team and the likeability of the founders and other attributes that no other algorithm shared the top importance of from the table.
“Technology Sector” is another common predictive factor identified by three out of four algorithms. A closer inspection on the weights of the “Technology Sector” attribute in both the Logistic Regression and SVM models reveals negative signs, which indicate that the attribute is a significant factor contributing to the unfavorable (“No”) predictions. This reinforces RSC’s investment thesis of avoiding SaaS and technology-based companies.
The food and home industries were important attributes for the Decision Tree model. Indeed, three out of five of the top important attributes in the Decision Tree model are industry-specific as opposed to characteristics of the founding team or product. However, since the Decision Tree model had the overall lowest accuracy among all standard algorithms, which may point to the conclusion that focusing on the individual industries are not as important in making investment decisions. This conjecture is confirmed by examining
Table 4 where four out of five principal factors are focusing on the quality of a company’s leadership and product.
Because our feature selection algorithm (CFS) is performed on the training data and is model independent, the top five selected features are the same for all meta-classifiers. Nevertheless, the order of these five features indicates their significance. The results reiterate the importance of planning and aversion to the technology sector. Furthermore, four out of the five principal factors are related to the company’s founding team or product. Given that meta-classifiers exhibit higher model performance and less inter-class bias, we recommend collecting more features capturing the quality and characteristics of a company’s management team and products for future studies.
4. Discussion
Our research suggests that qualitative startup attributes can play a significant role in VC investment decisions, which is in line with general venture capital sentiment that startup investment decisions are high risk because there is a lack of data-based evaluation methods [
33]. Models based on specific investment theses can help determine which traits may be more influential in decision-making to RSC and which industries are more favorable. Our framework of analyzing 15 unique categories of startups allowed us to compare the impact of the many traits on decision-making, as opposed to a deeper dive on a single feature measured among companies [
34]. However, by comparing multiple characteristics for each company, it becomes clear that many metrics on the scorecard may be influenced by each other. For example, did a low score on “Creativity” for a management team or founder contribute to a low score on “Product Uniqueness”? There seems to be similar positive correlation between multiple traits where intersecting biases are difficult to account for; perhaps in a longer-term cross-sectional study with this VC firm, we could analyze the most influential factors in decision bias [
35].
Our findings align with RSC’s investment thesis in that the company is focused on investing in consumer goods as opposed to technology and software companies. Therefore, based on the sample companies, there would be significant filtering solely by evaluating the startup industry as 26% of the startups that were passed on belonged to the Technology sector, the highest rate of passed investments of all industries in our data. There are many new frameworks for investing in early-stage companies that propose using a considerable amount of criteria and features [
36]. Using the attribute-selected meta-classifier that reduces the number of features used in the algorithm, deciding whether to invest in a startup for the VC firm could be more straightforward than initially perceived. For the attribute insight that was offered by the WEKA program, the characteristics of the founding team and planning strategy may be significantly influential. These industries and attributes that impacted investment decisions the most may be more important to consider on the scorecard, diminishing the justification for some of the other features if the predictability results in similar accuracy.
It is worth noting that the attributes of value are constantly changing and should be reevaluated periodically due to the evolving venture capital environment and the adaptability of a firm’s investment thesis. Venture capital firm values evolve with innovative industries, and when certain qualitative or quantitative traits are more prevalent in certain industries, the heavy emphasis on these features could cause a shift in favored investments. For example, if management teams have more years of relevant career experience in biotechnology startups and this trait is favorable in the venture capital environment, then the favorable quality could cause a higher skew towards venture capital investments in biotechnology companies. This has been seen in the past popularity of investments in SaaS companies with the considerably larger amount of funding this sector received compared to others due to favorable high returns; compared to the relatively difficult environment, SaaS investing has become for venture capital firms looking for good deal flow and discounts [
37,
38].
Our machine learning methods were chosen to their standard and common use for ease of comparison and understanding. There may be more accurate models in predictability and discerning which qualities could be more meaningful. Our models used a relatively small sample size. Nevertheless, considering the practicality of a single firm scoring 100 startups on multiple features, the model results sufficed to satisfy our hypotheses that qualitative features in a startup were significantly impactful in decision-making. WEKA effectively helped reduce the biases in investment decision-making by discerning the attributes that could be worth paying more attention to, which simplifies the process in a relatively customizable manner [
39,
40].
5. Conclusions
There are many ways to approach the evaluation of startups, and every venture capital firm may have a different approach. Our study provides convincing evidence that machine learning models can be adapted to support investment decisions for VC firms. We find that there should be a lower number of influential criteria to make efficient investment decisions that accurately reflect an investment thesis. We also conclude that qualitative features are impactful in investment decision-making and suggest these features should be considered more than most basic quantitative features, depending on the firm. If and when venture capital firms should demonstrate full conviction in the investment thesis, firms should follow relatively strict investment decisions based on these theses according to our findings and discussion due to the high impact of fewer qualities. Our study is limited in that a single VC firm chose the companies, and thus the industry spread may not be neutral. Furthermore, the scoring categories could be biased towards the opinions of the firm and its investment thesis. There may be other important aspects of the companies that may result in more accurate predictability of whether to invest. Although our model is not perfect, our experimental results demonstrate effective predictive models that could serve as a Focus of Attention (FOA) tool for a VC firm. Further research may be conducted with more detailed attributes of the founding team and, thus, provide more insight into what types of people are associated with successful companies. Potential studies could include optimal methods of data discovery for the more subjective information. Examples of data discovery methods include founder interviews, self-reported surveys of startups, and news article sentiment.
Author Contributions
Conceptualization, S.B. and Y.Z.; methodology, S.B. and Y.Z.; software, S.B.; validation, S.B. and Y.Z.; formal analysis, S.B. and Y.Z.; investigation, S.B. and Y.Z.; resources, S.B. and Y.Z.; data curation, S.B.; writing—original draft preparation, S.B.; writing—review and editing, Y.Z.; supervision, Y.Z.; project administration, Y.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data will be provided to qualified investigators upon reasonable request.
Acknowledgments
Special thanks to Rose Street Capital for providing the data and Luke Kachersky for academic support.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Is the VC Juice Worth the Squeeze? Available online: https://medium.com/vcdium/white-paper-is-the-vc-juice-worth-the-squeeze-59ed9092ee13 (accessed on 20 July 2021).
- Kaplan, R.S.; Norton, D.P. The balanced scorecard: Measures that drive performance. Harv. Bus. Rev. 2005, 83, 172. [Google Scholar]
- Kaplan, R.S. Conceptual foundations of the balanced scorecard. Handbooks Manag. Account. Res. 2009, 3, 1253–1269. [Google Scholar]
- Lewis, R. Measuring, reporting and appraising results of operations with reference to goals, plans and budgets. In Business Policy: Selected Readings and Editorial Commentaries; Ronald P. Comp.: New York, NY, USA, 1967. [Google Scholar]
- Porter, M.E. Capital disadvantage: America’s failing capital investment system. Harv. Bus. Rev. 1992, 70, 65–82. [Google Scholar]
- Fuertes-Callén, Y.; Cuellar-Fernández, B.; Serrano-Cinca, C. Predicting startup survival using first years financial statements. J. Small Bus. Manag. 2020, 1–37. [Google Scholar] [CrossRef]
- Hunter, D.S.; Saini, A.; Zaman, T. Picking Winners: A Data Driven Approach to Evaluating the Quality of Startup Companies. arXiv 2017, arXiv:1706.04229. [Google Scholar]
- Yeh, J.Y.; Chen, C.H. A machine learning approach to predict the success of crowdfunding fintech project. J. Enterp. Inf. Manag. 2020. [Google Scholar] [CrossRef]
- Ang, Y.Q.; Chia, A.; Saghafian, S. Using Machine Learning to Demystify Startups Funding, Post-Money Valuation, and Success. Post Money Valuat. Success 2020. [Google Scholar] [CrossRef]
- Krishna, A.; Agrawal, A.; Choudhary, A. Predicting the outcome of startups: Less failure, more success. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), Barcelona, Spain, 12–15 December 2016; pp. 798–805. [Google Scholar]
- Arroyo, J.; Corea, F.; Jimenez-Diaz, G.; Recio-Garcia, J.A. Assessment of machine learning performance for decision support in venture capital investments. IEEE Access 2019, 7, 124233–124243. [Google Scholar] [CrossRef]
- Prohorovs, A.; Bistrova, J.; Ten, D. Startup Success Factors in the Capital Attraction Stage: Founders’ Perspective. J. East West Bus. 2019, 25, 26–51. [Google Scholar] [CrossRef]
- Drakopoulos, G.; Kafeza, E.; Mylonas, P.; Al Katheeri, H. Building trusted startup teams from LinkedIn attributes: A higher order probabilistic analysis. In Proceedings of the 2020 IEEE 32nd International Conference on Tools with Artificial Intelligence (ICTAI), Baltimore, MD, USA, 9–11 November 2020; pp. 867–874. [Google Scholar]
- Albourini, F.; Ahmad, A.; Abuhashesh, M.; Nusairat, N. The effect of networking behaviors on the success of entrepreneurial startups. Manag. Sci. Lett. 2020, 10, 2521–2532. [Google Scholar] [CrossRef]
- Canovas-Saiz, L.; March-Chordà, I.; Yagüe-Perales, R.M. A quantitative-based model to assess seed accelerators’ performance. Entrep. Reg. Dev. 2021, 33, 332–352. [Google Scholar] [CrossRef]
- Yin, Y.; Wang, Y.; Evans, J.A.; Wang, D. Quantifying the dynamics of failure across science, startups and security. Nature 2019, 575, 190–194. [Google Scholar] [CrossRef]
- Rauch, A.; Frese, M. Let’s put the person back into entrepreneurship research: A meta-analysis on the relationship between business owners’ personality traits, business creation, and success. Eur. J. Work Organ. Psychol. 2007, 16, 353–385. [Google Scholar] [CrossRef]
- Kruse, P.; Wach, D.; Wegge, J. What motivates social entrepreneurs? A meta-analysis on predictors of the intention to found a social enterprise. J. Small Bus. Manag. 2020, 59, 477–508. [Google Scholar] [CrossRef]
- Gloor, P.A.; Dorsaz, P.; Fuehres, H.; Vogel, M. Choosing the right friends–predicting success of startup entrepreneurs and innovators through their online social network structure. Int. J. Organ. Des. Eng. 2013, 3, 67–85. [Google Scholar] [CrossRef]
- Antretter, T.; Blohm, I.; Grichnik, D.; Wincent, J. Predicting new venture survival: A Twitter-based machine learning approach to measuring online legitimacy. J. Bus. Ventur. Insights 2019, 11, e00109. [Google Scholar] [CrossRef]
- Tumasjan, A.; Braun, R.; Stolz, B. Twitter sentiment as a weak signal in venture capital financing. J. Bus. Ventur. 2021, 36, 106062. [Google Scholar] [CrossRef]
- Sharchilev, B.; Roizner, M.; Rumyantsev, A.; Ozornin, D.; Serdyukov, P.; de Rijke, M. Web-based startup success prediction. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Turin, Italy, 22–26 October 2018; pp. 2283–2291. [Google Scholar]
- Blohm, I.; Antretter, T.; Sirén, C.; Grichnik, D.; Wincent, J. It’s a Peoples Game, Isn’t It?! A Comparison between the Investment Returns of Business Angels and Machine Learning Algorithms. Entrep. Theory Pract. 2020. [Google Scholar] [CrossRef]
- Antretter, T.; Blohm, I.; Siren, C.; Grichnik, D.; Malmström, M.; Wincent, J. Do Algorithms Make Better-and Fairer-Investments Than Angel Investors? Available online: https://hbsp.harvard.edu/product/H05Z3X-PDF-ENG (accessed on 20 July 2021).
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Al-Aidaroos, K.M.; Bakar, A.A.; Othman, Z. Naive Bayes variants in classification learning. In Proceedings of the 2010 International Conference on Information Retrieval & Knowledge Management (CAMP), Shah Alam, Malaysia, 16–18 March 2010; pp. 276–281. [Google Scholar]
- Hosmer, D.W., Jr.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression; John Wiley & Sons: Hoboken, NJ, USA, 2013; Volume 398. [Google Scholar]
- Gurney, K. An Introduction to Neural Networks; CRC Press: Boca Raton, FL, USA, 1997. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Duch, W. Feature Extraction: Foundations and Applications (Studies in Fuzziness and Soft Computing); Guyon, I., Gunn, S., Nikravesh, M., Zadeh, L.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; Chapter 3. [Google Scholar]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Yang, H. Venture capital decision based on FPGA and machine learning. Microprocess. Microsyst. 2020, 103457. [Google Scholar] [CrossRef]
- Graves, S.B.; Ringuest, J. Overconfidence and disappointment in venture capital decision-making: An empirical examination. Manag. Decis. Econ. 2018, 39, 592–600. [Google Scholar] [CrossRef]
- Fu, Y.; Ng, S.H. Local bias and performance of venture capital institutions: Evidence from the Chinese venture capital market. J. Asia Bus. Stud. 2020. [Google Scholar] [CrossRef]
- Corea, F.; Bertinetti, G.; Cervellati, E.M. Hacking the venture industry: An Early-stage Startups Investment framework for data-driven investors. Mach. Learn. Appl. 2021, 5, 100062. [Google Scholar]
- Walkinshaw, M. The Venture Capital Model is Losing Relevance in SaaS. Available online: https://timiacapital.com/blog/the-venture-capital-model-is-losing-relevance-in-saas/ (accessed on 20 July 2021).
- Wilhelm, A. SaaS Kicks off 2020 with an Extra Billion in VC Funding as Round Count Halves. Available online: https://techcrunch.com/2020/02/10/saas-kicks-off-2020-with-an-extra-billion-in-vc-funding-as-round-count-halves/ (accessed on 20 July 2021).
- Srivastava, S.K.; Sharma, Y.K.; Kumar, S. Using of WEKA Tool in Machine Learning: A Review. Int. J. Adv. Sci. Technol. 2020, 29, 4456–4466. [Google Scholar]
- Verma, N.K.; Salour, A. Feature selection. In Intelligent Condition Based Monitoring; Springer: Berlin/Heidelberg, Germany, 2020; pp. 175–200. [Google Scholar]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).






{kind=link}
{kind=link}
{kind=link}