
Different Nonlinear Regression Techniques and Sensitivity Analysis as Tools to Optimize Oil Viscosity Modeling

 , , ,
, , ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental Materials and Methods
2.2. Theory/Calculation
2.2.1. Models
2.2.2. Computational Minimization
2.2.3. Sensitivity Analysis with Respect to Obtained Model Parameters
2.2.4. Sensitivity Analysis with Respect to Given Data
2.2.5. Sensitivity Analysis of Least Squares Method
2.2.6. Sensitivity Analysis of Absolute Value Minimization Problem
2.2.7. Sensitivity Analysis of Squared Relative Errors
3. Results
3.1. Evaluation of the Accuracy of Viscosity Estimation by the Studied Four Methods
3.2. Sensitivity Analysis with Respect to Given Data
3.3. Verification of the Viscosity Prediction Ability of the Four Studied Methods
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| ABP | Average boiling point |
| AIC | Akaike information criterion |
| ARI | Aromatic ring index |
| %AAD | % average absolute deviation |
| BIC | Bayesian information criterion |
| E | Error |
| FCC | Fluid catalytic cracking |
| HAGO | Heavy atmospheric gas oil |
| HCO | Heavy cycle oil |
| HTVGO | Hydrotreated vacuum gas oil |
| HVGO | Heavy vacuum gas oil |
| LAE | Least absolute errors |
| LARE | Least absolute relative errors |
| LCO | Light cycle oil |
| LSAE | Least squares of absolute errors |
| LSRE | Least squares of relative errors |
| LVGO | Light vacuum gas oil |
| MW | Molecular weight |
| NLLSR | Nonlinear least square regression |
| RE | Relative error |
| RI | Refractive index |
| RSE | Relative standard error |
| SA | Sensitivity analysis |
| SE | Standard error |
| SG | Specific gravity |
| SLO | Slurry oil |
| SRHVGO | Straight run heavy vacuum gas oil |
| SRLVGO | Straight run light vacuum gas oil |
| SRVGO | Straight run vacuum gas oil |
| SSE | Sum of square errors |
| VBGO | Visbreaker gas oil |
| VGO | Vacuum gas oil |
| υ | Kinematic viscosity, mm2/s |
References
- Aboul-Seoud, A.L.; Moharam, H.M. A generalized viscosity correlation for undefined petroleum fractions. Chem. Eng. J. 1999, 72, 253–256. [Google Scholar] [CrossRef]
- Abutaqiya, M.I.L.; Alhammadi, A.A.; Sisco, C.J.; Vargas, F.M. Aromatic Ring Index (ARI): A characterization factor for nonpolar hydrocarbons from molecular weight and refractive index. Energy Fuels 2021, 35, 1113–1119. [Google Scholar] [CrossRef]
- Hernández, E.A.; Sánchez-Reyna, G.; Ancheyta, J. Comparison of mixing rules based on binary interaction parameters for calculating viscosity of crude oil blends. Fuel 2019, 249, 198–205. [Google Scholar] [CrossRef]
- Hosseinifar, P.; Jamshidi, S. A new correlative model for viscosity estimation of pure components, bitumens, size-asymmetric mixtures and reservoir fluids. J. Petrol. Sci. Eng. 2016, 147, 624–635. [Google Scholar] [CrossRef]
- Kamel, A.; Alomair, O.; Elsharkawy, A. Measurements and predictions of Middle Eastern heavy crude oil viscosity using compositional data. J. Petrol. Sci. Eng. 2019, 173, 990–1004. [Google Scholar] [CrossRef]
- Kariznovi, M.; Nourozieh, H.; Abedi, J. Measurement and modeling of density and viscosity for mixtures of Athabasca bitumen and heavy n-alkane. Fuel 2013, 112, 83–95. [Google Scholar] [CrossRef]
- Kotzakoulakis, K.; George, S.C. A simple and flexible correlation for predicting the viscosity of crude oils. J. Pet. Sci. Eng. 2017, 158, 416–423. [Google Scholar] [CrossRef]
- Kumar, R.; Maheshwari, S.; Voolapalli, R.K.; Upadhyayul, S. Investigation of physical parameters of crude oils and their impact on kinematic viscosity of vacuum residue and heavy product blends for crude oil selection. J. Taiwan Inst. Chem. Eng. 2021, 120, 33–42. [Google Scholar] [CrossRef]
- Malta, J.A.M.S.C.; Calabrese, C.; Nguyen, T.B.; Trusler, J.P.M.; Vesovic, V. Measurements and modelling of the viscosity of six synthetic crude oil mixtures. Fluid Phase Equilibria 2020, 505, 112343. [Google Scholar] [CrossRef]
- Mehrotra, A.K. A Simple Equation for Predicting the Viscosity of Crude-Oil Fractions. Chem. Eng. Res. Des. 1995, 73, 87–90. [Google Scholar]
- Pabón, R.E.C.; Filho, C.R.S. Crude oil spectral signatures and empirical models to derive API gravity. Fuel 2019, 237, 1119–1131. [Google Scholar] [CrossRef]
- Raut, B.; Patil, S.L.; Dandekar, A.Y.; Fisk, R.; Maclean, B.; Hice, V. Comparative study of compositional viscosity prediction models for medium-heavy oils. Int. J. Oil Gas Coal Technol. 2008, 1, 229. [Google Scholar] [CrossRef]
- Sánchez-Minero, F.; Sánchez-Reyna, G.; Ancheyta, J.; Marroquin, G. Comparison of correlations based on API gravity for predicting viscosity of crude oils. Fuel 2014, 138, 193–199. [Google Scholar] [CrossRef]
- Stratiev, D.S.; Nenov, S.; Shishkova, I.K.; Dinkov, R.K.; Zlatanov, K.; Yordanov, D.; Sotirov, S.; Sotirova, E.; Atanassova, V.; Atanassov, K.; et al. Comparison of Empirical Models to Predict Viscosity of Secondary Vacuum Gas Oils. Resources 2021, 10, 82. [Google Scholar] [CrossRef]
- Samano, V.; Tirado, A.; F´elix, G.; Ancheyta, J. Revisiting the importance of appropriate parameter estimation based on sensitivity analysis for developing kinetic model. Fuel 2020, 267, 117113. [Google Scholar] [CrossRef]
- Ghorbani, B.; Hamedi, M.; Shirmohammadi, R.; Mehrpooy, M.; Hamedi, M.H. A novel multi-hybrid model for estimating optimal viscosity correlations of Iranian crude oil. J. Petrol. Sci. Eng. 2016, 142, 68–76. [Google Scholar] [CrossRef]
- Khamehchi, E.; Mahdiani, M.R.; Amooie, M.A.A.; Hemmati-Sarapardeh, A. Modeling viscosity of light and intermediate dead oil systems using advanced computational frameworks and artificial neural networks. J. Petrol. Sci. Eng. 2020, 193, 107388. [Google Scholar] [CrossRef]
- Saltelli, A.; Tarantola, S.; Campolongo, F.; Ratto, M. Sensitivity Analysis in Practice; John Wiley & Sons Ltd.: Chichester, UK, 2004. [Google Scholar]
- Parhamifar, E.; Tyllgren, P. Assessment of asphalt binder viscosities with a new approach. In Proceedings of the E&E Congress 2016|6th Eurasphalt & Eurobitume Congress, Prague, Czech Republic, 1–3 June 2016. [Google Scholar]
- Castillo, E.; Hadi, A.S.; Conejo, A.; Fernndez-Canteli, A. A general method for local sensitivity analysis with application to regression models and other optimization problems. Technometrics 2004, 46, 430–444. [Google Scholar] [CrossRef]
- Alcazar, L.A.; Ancheyta, J. Sensitivity analysis based methodology to estimate the best set of parameters for heterogeneous kinetic models. Chem. Eng. J. 2007, 128, 85–93. [Google Scholar] [CrossRef]
- Diarov, I.N.; Batueva, I.U.; Sadikov, A.N.; Colodova, N.L. Chemistry of Crude Oil; Chimia Publishers: St.Peterburg, Russia, 1990; Volume 51. (In Russian) [Google Scholar]
- Fisher, I.P. Effect of feedstock variability on catalytic cracking yields. Appl. Catal. 1990, 65, 189–210. [Google Scholar] [CrossRef]
- Walther, C. Ueber die Auswertung von Viskosit€atsangaben. Erdoel Teer 1931, 7, 382–384. [Google Scholar]
- Solodov, M.V.; Svaiter, B.F. A globally convergent inexact Newton method for systems of monotone equations. In Reformulation: Nonsmooth, Piecewise Smooth, Semismooth and Smoothing Methods; Springer: Boston, MA, USA, 1998; pp. 355–369. [Google Scholar]
- Zhou, W.J.; Li, D.H. A globally convergent BFGS method for nonlinear monotone equations without any merit functions. Math. Comput. 2008, 77, 2231–2240. [Google Scholar] [CrossRef]
- Demidenko, E. Is This the Least Squares Estimate? Biometrika 2000, 87, 437–452. [Google Scholar] [CrossRef]
- Takayama, A. Mathematical Economics; Cambridge University Press: New York, NY, USA, 1985; ISBN 0-521-31498-4. [Google Scholar]
- Burnham, K.P.; Anderson, D.R. Model Selection and Multimodel Inference, 2nd ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
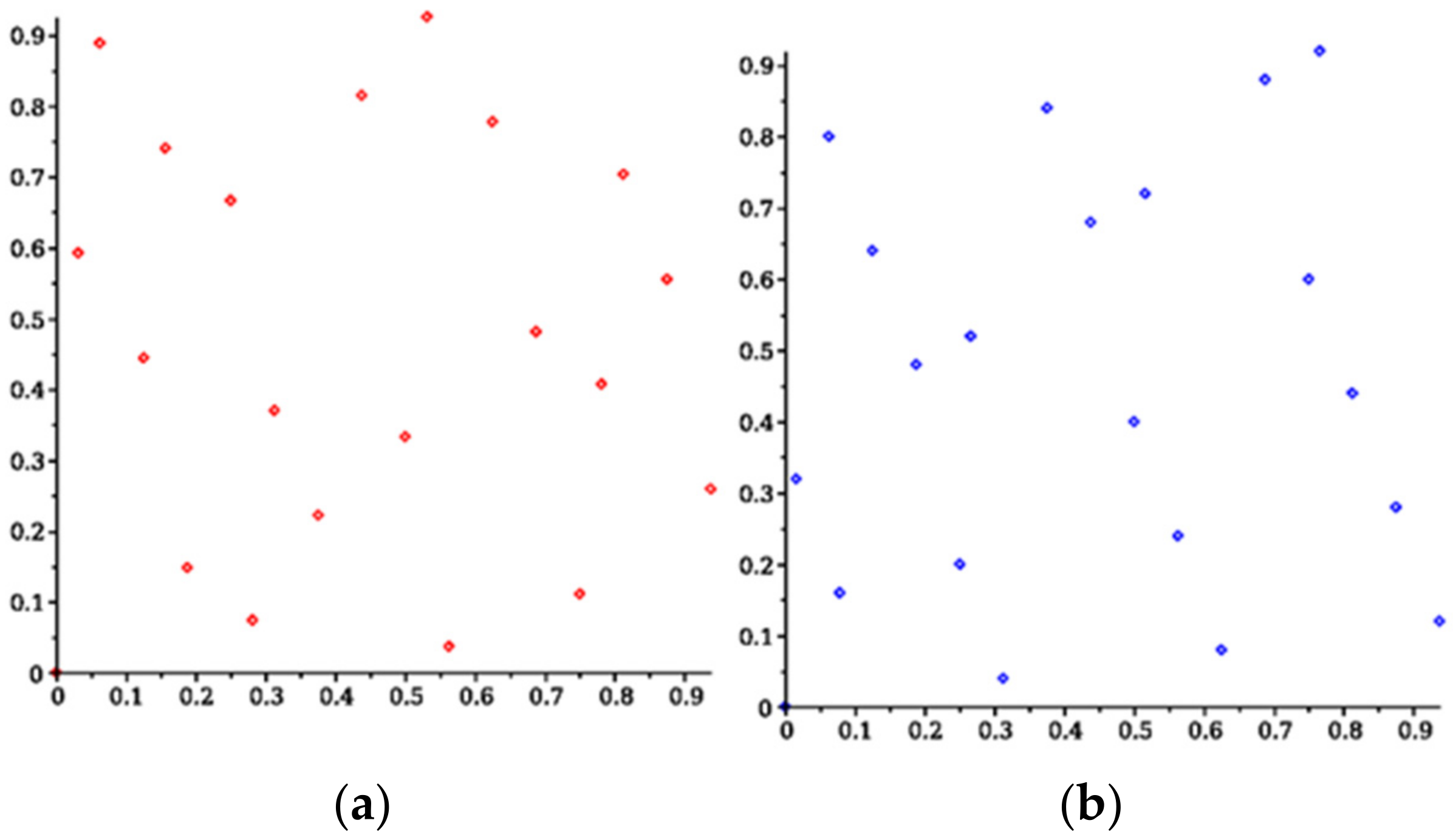






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Nr | Sample | SG | T10% | T50% | T90% | T95% | ABP, °C | Kin. vis. at 80 °C, mm2/s | RI at 20 °C | Kw | MW, g/mol | ARI |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | HAGO-1 | 0.9512 | 343 | 397 | 455 | 476 | 398 | 7.3 | 1.5385 | 11.20 | 342 | 2.2 |
| 2 | LVGO-1 | 0.9715 | 343 | 414 | 493 | 517 | 417 | 12.1 | 1.5509 | 11.07 | 364 | 2.5 |
| 3 | HVGO-1 | 0.9858 | 426 | 491 | 548 | 562 | 488 | 49.9 | 1.5524 | 11.27 | 461 | 3 |
| 4 | HAGO-2 | 0.959 | 335 | 395 | 458 | 480 | 396 | 13.6 | 1.5442 | 11.09 | 339 | 2.3 |
| 5 | LVGO-2 | 0.9856 | 330 | 410 | 488 | 508 | 409 | 15.2 | 1.5612 | 10.86 | 354 | 2.7 |
| 6 | HVGO-2 | 1.0084 | 430 | 489 | 540 | 554 | 486 | 62.1 | 1.5685 | 11.00 | 458 | 3.4 |
| 7 | HAGO-3 | 0.9514 | 323 | 377 | 439 | 461 | 380 | 12.9 | 1.5409 | 11.09 | 322 | 2.1 |
| 8 | LVGO-3 | 0.9768 | 324 | 395 | 482 | 508 | 400 | 16.7 | 1.5567 | 10.91 | 344 | 2.5 |
| 9 | HVGO-3 | 0.997 | 405 | 470 | 534 | 551 | 470 | 34.8 | 1.5626 | 11.05 | 434 | 3.1 |
| 10 | FCC SLO-1 | 0.9871 | 232 | 282 | 412 | 455 | 309 | 3.6 | 1.5763 | 10.29 | 254 | 2.4 |
| 11 | FCC SLO-2 | 1.0549 | 292 | 372 | 475 | 518 | 380 | 9.9 | 1.614 | 10.01 | 319 | 3.3 |
| 12 | FCC SLO-3 | 1.0573 | 329 | 392 | 471 | 493 | 397 | 16.2 | 1.6135 | 10.07 | 337 | 3.5 |
| 13 | FCC SLO-4 | 1.0671 | 337 | 401 | 476 | 498 | 405 | 21.3 | 1.6194 | 10.02 | 346 | 3.6 |
| 14 | FCC SLO-5 | 1.0624 | 324 | 391 | 471 | 494 | 395 | 17.4 | 1.6172 | 10.01 | 335 | 3.5 |
| 15 | FCC SLO-6 | 1.0953 | 331 | 400 | 491 | 525 | 407 | 33.8 | 1.6392 | 9.77 | 346 | 3.9 |
| 16 | FCC SLO-7 | 1.0788 | 326 | 397 | 493 | 531 | 405 | 24.2 | 1.628 | 9.91 | 345 | 3.7 |
| 17 | FCC SLO-8 | 1.063 | 317 | 389 | 484 | 520 | 397 | 18.5 | 1.6178 | 10.01 | 337 | 3.5 |
| 18 | FCC SLO-9 | 1.0835 | 327 | 401 | 480 | 501 | 403 | 28.5 | 1.6309 | 9.85 | 342 | 3.8 |
| 19 | FCC SLO-10 | 1.177 | 371 | 435 | 562 | 634 | 456 | 312.8 | 1.6927 | 9.30 | 395 | 5.1 |
| 20 | FCC SLO-11 | 1.1011 | 332 | 394 | 482 | 530 | 403 | 21.2 | 1.644 | 9.70 | 340 | 3.9 |
| 21 | VGO blend | 0.9165 | 376 | 446 | 525 | 544 | 449 | 14.2 | 1.5088 | 11.91 | 404 | 1.7 |
| 22 | HAGO-4 | 0.905 | 357 | 425 | 489 | 505 | 424 | 8 | 1.5029 | 11.92 | 371 | 1.4 |
| 23 | LVGO-4 | 0.912 | 322 | 417 | 528 | 550 | 422 | 8.6 | 1.5088 | 11.82 | 369 | 1.6 |
| 24 | HVGO-4 | 0.922 | 411 | 486 | 552 | 568 | 483 | 27.2 | 1.5082 | 12.02 | 453 | 1.8 |
| 25 | HAGO-5 | 0.9710 | 338 | 395 | 459 | 480 | 397 | 13.0 | 1.5532 | 10.96 | 341 | 2.5 |
| 26 | LVGO-5 | 0.9860 | 320 | 391 | 470 | 495 | 394 | 13.0 | 1.5642 | 10.78 | 337 | 2.6 |
| 27 | HVGO-5 | 1.0150 | 419 | 477 | 531 | 545 | 476 | 57.5 | 1.5751 | 10.88 | 442 | 3.4 |
| 28 | FCC SLO-12 | 1.0970 | 333 | 395 | 487 | 545 | 405 | 22.2 | 1.6417 | 9.74 | 343 | 3.9 |
| 29 | VBGO-1 | 0.9399 | 376 | 445 | 495 | 505 | 439 | 14.7 | 1.5259 | 11.56 | 391 | 2.1 |
| 30 | VBGO-2 | 0.9449 | 373 | 433 | 486 | 497 | 431 | 13.5 | 1.5307 | 11.45 | 381 | 2.1 |
| 31 | FCC SLO-13 | 1.0529 | 278 | 366 | 459 | 483 | 368 | 14.5 | 1.6139 | 9.96 | 306 | 3.2 |
| 32 | FCC SLO-14 | 1.0765 | 321 | 386 | 469 | 493 | 392 | 16.2 | 1.6283 | 9.86 | 330 | 3.6 |
| 33 | HTVGO-1 | 0.8939 | 364 | 433 | 506 | 521 | 434 | 10.41 | 1.4949 | 12.13 | 383 | 1.3 |
| 34 | HTVGO-2 | 0.8901 | 360 | 429 | 504 | 520 | 431 | 9.57 | 1.4927 | 12.16 | 378 | 1.2 |
| 35 | BG LIGHT | 0.8650 | 306 | 376 | 464 | 514 | 382 | 3.7 | 1.4786 | 12.21 | 319 | 0.8 |
| 36 | PEMBINA | 0.8940 | 340 | 428 | 522 | 629 | 430 | 7.8 | 1.4936 | 12.10 | 378 | 1.2 |
| 37 | EKOFISK | 0.9030 | 342 | 444 | 535 | 577 | 440 | 7.8 | 1.5013 | 12.04 | 391 | 1.4 |
| 38 | BRENT | 0.8940 | 322 | 406 | 502 | 555 | 410 | 8.4 | 1.4990 | 11.98 | 353 | 1.3 |
| 39 | BOW RIVER | 0.9320 | 342 | 421 | 504 | 570 | 422 | 9.5 | 1.5171 | 11.56 | 370 | 1.8 |
| 40 | COKER | 1.009 | 333 | 429 | 514 | 560 | 425 | 20.7 | 1.5761 | 10.70 | 374 | 3.1 |
| 41 | BU ATTIFEL | 0.8380 | 385 | 445 | 512 | 550 | 447 | 8.3 | 1.4541 | 13.01 | 393 | 0.0 |
| Coefficient | Least Squares | Least abs. Errors | Squared rel. Errors | Abs. rel. Errors | ||||
|---|---|---|---|---|---|---|---|---|
| Before SA | After SA | Before SA | After SA | Before SA | After SA | Before SA | After SA | |
| 0.0000972 | 0.0000973 | 0.0888705 | 0.0888705 | 9 × 10−7 | 9 × 10−7 | 0.0841792 | 0.0841793 | |
| 1.5542645 | 1.5542641 | 0.6573309 | 0.657331 | 2.1851235 | 2.1851235 | 0.6533058 | 0.6533059 | |
| 1.0946136 | 1.0946132 | 0.4784847 | 0.4784848 | 1.5193787 | 1.5193787 | 0.5075231 | 0.5075231 | |
| −1.5265719 | −1.5265719 | −5.5717615 | −5.571762 | −0.4953817 | −0.4953818 | −5.0323918 | −5.0323919 | |
| −1.4404829 | −1.4404824 | −2.4403382 | −2.440338 | 1.9089183 | 1.9089184 | 0.0382231 | 0.0382233 | |
| Least Squares (Method 1) | Least abs. Errors (Method 2) | Squared rel. Errors (Method 3) | Abs. rel. Errors (Method 4) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Nr | calc. | Error | rel. Error | calc. | Error | rel. Error | calc. | Error | rel. Error | calc. | Error | rel. Error | |
| 1 | HAGO-1 | 9.79 | −2.52 | 34.7 | 9.74 | −2.47 | 33.9 | 8.48 | −1.21 | 16.7 | 7.99 | −0.72 | 10 |
| 2 | LVGO-1 | 13.25 | −1.17 | 9.7 | 13.09 | −1.01 | 8.4 | 12.34 | −0.26 | 2.1 | 11.6 | 0.48 | 4 |
| 3 | HVGO-1 | 50.96 | −1.05 | 2.1 | 49.76 | 0.15 | 0.3 | 51.55 | −1.64 | 3.3 | 47.02 | 2.89 | 5.8 |
| 4 | HAGO-2 | 9.98 | 3.62 | 26.6 | 9.93 | 3.67 | 27 | 8.69 | 4.91 | 36.1 | 8.22 | 5.38 | 39.5 |
| 5 | LVGO-2 | 13.33 | 1.87 | 12.3 | 13.21 | 1.99 | 13.1 | 12.41 | 2.79 | 18.3 | 11.8 | 3.4 | 22.4 |
| 6 | HVGO-2 | 64.42 | −2.32 | 3.7 | 63.15 | −1.05 | 1.7 | 64.75 | −2.65 | 4.3 | 60.14 | 1.96 | 3.2 |
| 7 | HAGO-3 | 8.25 | 4.65 | 36.1 | 8.27 | 4.63 | 35.9 | 6.71 | 6.19 | 48 | 6.43 | 6.47 | 50.1 |
| 8 | LVGO-3 | 11.22 | 5.48 | 32.8 | 11.14 | 5.56 | 33.3 | 10.08 | 6.62 | 39.7 | 9.58 | 7.12 | 42.6 |
| 9 | HVGO-3 | 38.5 | −3.7 | 10.6 | 37.9 | −3.1 | 8.9 | 38.86 | −4.06 | 11.7 | 36.37 | −1.57 | 4.5 |
| 10 | FCC SLO-1 | 5.72 | −2.16 | 60.8 | 5.95 | −2.39 | 67.2 | 3.72 | −0.16 | 4.5 | 3.93 | −0.37 | 10.3 |
| 11 | FCC SLO-2 | 13.72 | −3.82 | 38.5 | 13.77 | −3.87 | 39.1 | 12.76 | −2.86 | 28.9 | 12.8 | −2.9 | 29.3 |
| 12 | FCC SLO-3 | 17.82 | −1.62 | 10 | 17.89 | −1.69 | 10.4 | 17.19 | −0.99 | 6.1 | 17.27 | −1.07 | 6.6 |
| 13 | FCC SLO-4 | 21.53 | −0.23 | 1.1 | 21.68 | −0.38 | 1.8 | 21.1 | 0.2 | 0.9 | 21.43 | −0.13 | 0.6 |
| 14 | FCC SLO-5 | 17.88 | −0.48 | 2.8 | 17.97 | −0.57 | 3.3 | 17.25 | 0.15 | 0.9 | 17.41 | −0.01 | 0 |
| 15 | FCC SLO-6 | 28.27 | 5.49 | 16.3 | 28.74 | 5.02 | 14.9 | 28.01 | 5.75 | 17 | 29.34 | 4.42 | 13.1 |
| 16 | FCC SLO-7 | 23.89 | 0.32 | 1.3 | 24.15 | 0.06 | 0.2 | 23.54 | 0.67 | 2.8 | 24.21 | 0 | 0 |
| 17 | FCC SLO-8 | 18.38 | 0.09 | 0.5 | 18.48 | −0.01 | 0 | 17.78 | 0.69 | 3.8 | 17.96 | 0.51 | 2.8 |
| 18 | FCC SLO-9 | 23.7 | 4.81 | 16.9 | 23.99 | 4.52 | 15.9 | 23.33 | 5.18 | 18.2 | 24.11 | 4.4 | 15.4 |
| 19 | FCC SLO-10 | 312.7 | 0.1 | 0 | 312.8 | 0 | 0 | 288.07 | 24.73 | 7.9 | 316.69 | −3.89 | 1.2 |
| 20 | FCC SLO-11 | 27.18 | −5.94 | 27.9 | 27.66 | −6.42 | 30.2 | 26.87 | −5.63 | 26.5 | 28.3 | −7.06 | 33.2 |
| 21 | VGO blend | 13.82 | 0.37 | 2.6 | 13.49 | 0.7 | 5 | 13.04 | 1.15 | 8.1 | 11.68 | 2.51 | 17.7 |
| 22 | HAGO-4 | 9.81 | −2.41 | 32.6 | 9.68 | −2.28 | 30.8 | 8.54 | −1.14 | 15.4 | 7.77 | −0.37 | 5.1 |
| 23 | LVGO-4 | 10.25 | −2.65 | 34.8 | 10.1 | −2.5 | 32.9 | 9.03 | −1.43 | 18.8 | 8.25 | −0.65 | 8.5 |
| 24 | HVGO-4 | 23.44 | 8.16 | 25.8 | 22.67 | 8.93 | 28.3 | 23.48 | 8.12 | 25.7 | 20.59 | 11.01 | 34.8 |
| 25 | HAGO-5 | 10.69 | 2.31 | 17.7 | 10.63 | 2.37 | 18.2 | 9.49 | 3.51 | 27 | 9.01 | 3.99 | 30.7 |
| 26 | LVGO-5 | 11.02 | 1.98 | 15.3 | 10.97 | 2.03 | 15.6 | 9.84 | 3.16 | 24.3 | 9.43 | 3.57 | 27.5 |
| 27 | HVGO-5 | 54.1 | 3.4 | 5.9 | 53.38 | 4.12 | 7.2 | 54.46 | 3.04 | 5.3 | 51.49 | 6.01 | 10.4 |
| 28 | FCC SLO-12 | 26.07 | −3.87 | 17.4 | 26.49 | −4.29 | 19.3 | 25.74 | −3.54 | 15.9 | 26.98 | −4.78 | 21.5 |
| 29 | VBGO-1 | 14.48 | 0.22 | 1.5 | 14.19 | 0.51 | 3.5 | 13.75 | 0.95 | 6.5 | 12.53 | 2.17 | 14.8 |
| 30 | VBGO-2 | 13.44 | 0.06 | 0.5 | 13.2 | 0.3 | 2.2 | 12.58 | 0.92 | 6.8 | 11.56 | 1.94 | 14.4 |
| 31 | FCC SLO-13 | 11.5 | 3 | 20.7 | 11.56 | 2.94 | 20.3 | 10.32 | 4.18 | 28.8 | 10.35 | 4.15 | 28.6 |
| 32 | FCC SLO-14 | 18.34 | −2.14 | 13.2 | 18.5 | −2.3 | 14.2 | 17.71 | −1.51 | 9.3 | 18.12 | −1.92 | 11.9 |
| 33 | HTVGO-1 | 10.37 | 0.03 | 0.3 | 10.19 | 0.21 | 2 | 9.19 | 1.21 | 11.7 | 8.27 | 2.13 | 20.5 |
| 34 | HTVGO-2 | 9.86 | −0.26 | 2.7 | 9.7 | −0.1 | 1.1 | 8.6 | 1 | 10.4 | 7.76 | 1.84 | 19.2 |
| 35 | BG LIGHT | 6.19 | −2.49 | 67.4 | 6.32 | −2.62 | 70.8 | 4.32 | −0.62 | 16.7 | 4.2 | −0.5 | 13.5 |
| 36 | PEMBINA | 9.88 | −2.08 | 26.7 | 9.73 | −1.93 | 24.7 | 8.62 | −0.82 | 10.5 | 7.8 | 0 | 0 |
| 37 | EKOFISK | 11.8 | −4 | 51.3 | 11.55 | −3.75 | 48.1 | 10.8 | −3 | 38.5 | 9.67 | −1.87 | 24 |
| 38 | BRENT | 8.28 | 0.12 | 1.4 | 8.25 | 0.15 | 1.8 | 6.78 | 1.62 | 19.3 | 6.28 | 2.12 | 25.3 |
| 39 | BOW RIVER | 11.23 | −1.73 | 18.2 | 11.07 | −1.57 | 16.5 | 10.13 | −0.63 | 6.6 | 9.31 | 0.19 | 2 |
| 40 | COKER | 19.68 | 1.02 | 4.9 | 19.53 | 1.17 | 5.7 | 19.26 | 1.44 | 7 | 18.52 | 2.18 | 10.5 |
| 41 | BU ATTIFEL | 8.75 | −0.45 | 5.4 | 8.61 | −0.31 | 3.7 | 7.35 | 0.95 | 11.4 | 6.5 | 1.8 | 21.7 |
| AARE (%AAD) | 17.3 | 17.5 | 15.2 | 16.0 | |||||||||
| Nr. | Least Squares | Least abs. Errors | Squared rel. Errors | Abs. rel. Errors | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | −0.83 | 0.17 | 0.17 | −0.96 | 0.2 | 0.21 | −1.28 | 0.93 | 0.95 | −1.34 | 0.8 | 0.87 |
| 2 | −0.39 | 0.13 | 0.13 | −0.96 | 0.24 | 0.25 | 0.06 | 0.12 | 0.12 | 0.94 | −0.86 | −0.86 |
| 3 | −0.35 | 0.85 | 0.93 | 1.01 | −0.43 | −0.57 | 0.13 | 0.29 | 0.32 | 0.34 | −1.27 | −1.41 |
| 4 | 1.2 | −0.25 | −0.25 | 1.01 | 0.1 | 0.1 | 1.07 | −1.12 | −1.12 | 0.6 | −0.47 | −0.45 |
| 5 | 0.62 | −0.22 | −0.21 | 1.01 | 0.07 | 0.06 | 0.69 | −0.82 | −0.82 | 0.66 | −0.71 | −0.68 |
| 6 | −0.77 | 2.59 | 2.75 | −0.96 | 0.96 | 1.13 | 0.12 | 0.41 | 0.44 | 0.31 | −1.41 | −1.52 |
| 7 | 1.54 | −0.23 | −0.22 | 1.01 | 0.12 | 0.12 | 1.2 | −1.11 | −1.1 | 0.54 | −0.35 | −0.32 |
| 8 | 1.81 | −0.47 | −0.46 | 1.01 | 0.09 | 0.08 | 0.93 | −1.23 | −1.22 | 0.5 | −0.49 | −0.45 |
| 9 | −1.22 | 2.07 | 2.17 | −0.96 | 0.56 | 0.64 | −0.04 | 1.02 | 1.1 | −0.14 | 1.3 | 1.46 |
| 10 | −0.71 | 0.05 | 0.04 | −0.96 | 0.17 | 0.17 | −0.55 | 0.18 | 0.16 | −2.92 | 0.57 | 0.52 |
| 11 | −1.26 | 0.49 | 0.42 | −0.96 | 0.25 | 0.25 | −1.86 | 2.17 | 1.94 | −1.14 | 1.23 | 1.16 |
| 12 | −0.54 | 0.31 | 0.28 | −0.96 | 0.3 | 0.3 | −0.05 | 0.41 | 0.38 | −0.5 | 1.12 | 1.08 |
| 13 | −0.08 | 0.06 | 0.05 | −0.96 | 0.35 | 0.35 | 0.19 | −0.06 | −0.06 | −0.31 | 1.14 | 1.1 |
| 14 | −0.16 | 0.09 | 0.08 | −0.96 | 0.3 | 0.3 | 0.19 | −0.06 | −0.05 | −0.41 | 1.06 | 1.02 |
| 15 | 1.81 | −2.14 | −1.87 | 1.01 | −0.15 | −0.15 | 0.39 | −1.08 | −0.96 | 0.41 | −1.13 | −1 |
| 16 | 0.1 | −0.1 | −0.08 | 1.01 | −0.08 | −0.08 | 0.22 | −0.19 | −0.17 | −0.25 | 1.19 | 1.13 |
| 17 | 0.03 | −0.02 | −0.02 | −0.96 | 0.31 | 0.31 | 0.27 | −0.24 | −0.21 | 0.68 | −1.08 | −0.96 |
| 18 | 1.59 | −1.45 | −1.27 | 1.01 | −0.08 | −0.08 | 0.44 | −1.06 | −0.96 | 0.45 | −1.04 | −0.92 |
| 19 | 0.03 | −0.85 | −0.74 | 1.01 | −6.15 | −6.09 | 0.17 | −1.06 | −0.94 | 0.12 | 2.22 | 2.06 |
| 20 | −1.96 | 2.19 | 1.89 | −0.96 | 0.44 | 0.43 | −0.68 | 2.53 | 2.24 | −0.47 | 1.68 | 1.55 |
| 21 | 0.12 | −0.04 | −0.05 | 1.01 | 0.07 | 0.05 | 0.44 | −0.4 | −0.45 | 0.73 | −0.71 | −0.78 |
| 22 | −0.8 | 0.15 | 0.17 | −0.96 | 0.2 | 0.21 | −1.12 | 0.82 | 0.91 | −1.25 | 0.72 | 0.86 |
| 23 | −0.87 | 0.19 | 0.2 | −0.96 | 0.2 | 0.21 | −1.41 | 1.05 | 1.16 | −1.26 | 0.77 | 0.91 |
| 24 | 2.7 | −2.16 | −2.48 | 1.01 | −0.04 | −0.09 | 0.49 | −1.22 | −1.44 | 0.36 | −0.68 | −0.78 |
| 25 | 0.76 | −0.18 | −0.18 | 1.01 | 0.1 | 0.09 | 0.97 | −0.99 | −0.98 | 0.69 | −0.57 | −0.54 |
| 26 | 0.65 | −0.17 | −0.16 | 1.01 | 0.09 | 0.09 | 0.92 | −0.94 | −0.92 | 0.71 | −0.61 | −0.57 |
| 27 | 1.12 | −3.04 | −3.15 | 1.01 | −0.5 | −0.62 | 0.21 | −0.44 | −0.47 | 0.31 | −1.26 | −1.33 |
| 28 | −1.28 | 1.34 | 1.16 | −0.96 | 0.42 | 0.42 | −0.28 | 1.37 | 1.22 | −0.39 | 1.51 | 1.4 |
| 29 | 0.07 | −0.03 | −0.03 | 1.01 | 0.06 | 0.04 | 0.38 | −0.33 | −0.36 | 0.73 | −0.76 | −0.81 |
| 30 | 0.02 | −0.01 | −0.01 | 1.01 | 0.07 | 0.05 | 0.41 | −0.34 | −0.37 | 0.79 | −0.75 | −0.78 |
| 31 | 0.99 | −0.29 | −0.24 | 1.01 | 0.08 | 0.08 | 0.92 | −1.12 | −0.98 | 0.64 | −0.65 | −0.55 |
| 32 | −0.71 | 0.44 | 0.38 | −0.96 | 0.31 | 0.31 | −0.18 | 0.67 | 0.59 | −0.53 | 1.22 | 1.14 |
| 33 | 0.01 | 0 | 0 | 1.01 | 0.1 | 0.09 | 0.69 | −0.48 | −0.55 | 0.91 | −0.59 | −0.65 |
| 34 | −0.09 | 0.02 | 0.02 | −0.96 | 0.2 | 0.21 | 0.68 | −0.43 | −0.49 | 0.99 | −0.58 | −0.64 |
| 35 | −0.82 | 0.06 | 0.07 | −0.96 | 0.17 | 0.17 | −2.66 | 0.72 | 0.78 | −2.89 | 0.55 | 0.65 |
| 36 | −0.69 | 0.13 | 0.15 | −0.96 | 0.2 | 0.21 | −0.64 | 0.53 | 0.61 | −1.12 | 0.68 | 0.83 |
| 37 | −1.32 | 0.36 | 0.4 | −0.96 | 0.22 | 0.23 | −3.5 | 2.64 | 3.02 | −1.42 | 0.94 | 1.13 |
| 38 | 0.04 | −0.01 | −0.01 | 1.01 | 0.12 | 0.11 | 1.16 | −0.67 | −0.73 | 1.04 | −0.49 | −0.51 |
| 39 | −0.57 | 0.14 | 0.15 | −0.96 | 0.21 | 0.22 | −0.24 | 0.35 | 0.38 | 1.18 | −0.78 | −0.82 |
| 40 | 0.34 | −0.22 | −0.22 | 1.01 | −0.01 | −0.03 | 0.33 | −0.42 | −0.42 | 0.59 | −0.96 | −0.94 |
| 41 | −0.15 | 0.02 | 0.03 | −0.96 | 0.19 | 0.2 | 0.81 | −0.42 | −0.52 | 1.09 | −0.5 | −0.59 |
| Least Squares | Least abs. Errors | Squared rel. Errors | Absl. rel. Errors | |||||
|---|---|---|---|---|---|---|---|---|
| 0 | 6.06 | −0.02 | −0.02 | 0 | 0.04 | −0.01 | 0.1 | |
| 0 | 2.81 | −0.28 | −0.28 | 0 | 0 | 0 | 0.02 | |
| 0.16 | 1409.28 | −129.95 | 848.78 | 0 | 2.54 | −0.16 | 8.36 | |
| Calculated Viscosity, mm2/s | Abs. Relative Error, % | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Nr | VGO and Light Gas Oils | Kin. vis. at 80 °C, mm2/s | ABP | SG | Method 1 | Method 2 | Method 3 | Method 4 | Method 1 | Method 2 | Method 3 | Method 4 |
| 1 | HYDRA | 9.9 | 439 | 0.8861 | 10.4 | 10.2 | 9.2 | 8.3 | 5.0 | 3.0 | 6.9 | 16.0 |
| 2 | EL BUNDUQ | 11.6 | 434 | 0.9240 | 12.3 | 12.0 | 11.3 | 10.3 | 5.6 | 3.5 | 2.8 | 11.1 |
| 3 | SUNNILAND | 13.3 | 444 | 0.9420 | 15.7 | 15.3 | 15.0 | 13.7 | 17.5 | 14.9 | 12.7 | 3.1 |
| 4 | Urals | 14.4 | 445 | 0.9235 | 14.0 | 13.6 | 13.2 | 11.9 | 3.1 | 5.4 | 8.5 | 17.1 |
| 5 | INNES | 10.5 | 435 | 0.8793 | 9.7 | 9.6 | 8.5 | 7.7 | 7.3 | 8.8 | 19.4 | 27.0 |
| 6 | LOKELE | 15.4 | 441 | 0.9581 | 16.7 | 16.4 | 16.1 | 14.9 | 8.4 | 6.3 | 4.7 | 3.1 |
| 7 | Cold Lake | 8.0 | 407 | 0.9291 | 9.6 | 9.6 | 8.3 | 7.8 | 20.6 | 19.5 | 4.0 | 2.3 |
| 8 | CANMET | 5.4 | 376 | 0.9446 | 7.9 | 7.9 | 6.3 | 6.1 | 45.5 | 46.3 | 15.8 | 12.8 |
| 9 | VISBROKEN | 5.0 | 382 | 0.9696 | 9.2 | 9.2 | 7.8 | 7.6 | 84.3 | 84.1 | 56.1 | 51.3 |
| 10 | CHAMPION EXPORT | 14.0 | 426 | 0.9721 | 15.1 | 14.9 | 14.4 | 13.5 | 8.1 | 6.5 | 2.9 | 3.2 |
| 11 | UDANG | 9.3 | 455 | 0.8460 | 9.7 | 9.5 | 8.5 | 7.5 | 4.8 | 2.4 | 8.6 | 19.2 |
| 12 | KAKAP | 4.8 | 424 | 0.8570 | 8.0 | 7.9 | 6.5 | 6.0 | 66.6 | 65.4 | 34.5 | 24.0 |
| 13 | DAQUING | 8.2 | 446 | 0.8651 | 10.0 | 9.7 | 8.7 | 7.8 | 21.4 | 18.9 | 6.4 | 4.9 |
| 14 | SERGIPANO PLATFORMA | 9.2 | 437 | 0.8715 | 9.5 | 9.3 | 8.2 | 7.4 | 3.2 | 1.5 | 11.0 | 19.5 |
| 15 | LAKE ARTHUR | 8.6 | 420 | 0.8766 | 8.4 | 8.4 | 7.0 | 6.4 | 1.9 | 2.7 | 19.0 | 25.2 |
| 16 | MARGHAM LIGHT | 6.3 | 415 | 0.8691 | 7.9 | 7.9 | 6.3 | 5.9 | 24.8 | 24.3 | 0.1 | 6.8 |
| 17 | SYNTHETIC OSA STREAM | 9.3 | 411 | 0.9434 | 10.7 | 10.6 | 9.6 | 9.0 | 15.4 | 14.1 | 2.7 | 3.6 |
| 18 | COLD LAKE BLEND | 28.1 | 463 | 0.9655 | 25.0 | 24.4 | 25.0 | 22.9 | 11.1 | 13.1 | 11.2 | 18.4 |
| 19 | DULANG | 4.8 | 409 | 0.8504 | 7.0 | 7.0 | 5.3 | 5.0 | 44.6 | 45.3 | 9.3 | 3.4 |
| 20 | HARRIET | 5.6 | 422 | 0.8902 | 9.1 | 9.0 | 7.7 | 7.1 | 63.3 | 61.4 | 38.6 | 27.7 |
| 21 | TIA JUANA P | 26.1 | 461 | 0.9673 | 24.4 | 23.9 | 24.4 | 22.5 | 6.4 | 8.4 | 6.6 | 14.0 |
| 22 | TIA JUANA M | 19.7 | 450 | 0.9373 | 16.2 | 15.8 | 15.7 | 14.2 | 17.6 | 19.6 | 20.5 | 27.7 |
| 23 | SOUEDIE | 20.3 | 454 | 0.9529 | 19.4 | 19.0 | 19.1 | 17.4 | 4.3 | 6.4 | 6.0 | 13.9 |
| 24 | ARAB HEAVY | 11.7 | 450 | 0.9285 | 15.3 | 15.0 | 14.7 | 13.3 | 30.8 | 27.5 | 25.2 | 13.3 |
| 25 | ARAB MEDIUM | 8.2 | 445 | 0.9183 | 13.5 | 13.2 | 12.7 | 11.5 | 65.4 | 61.5 | 55.3 | 40.4 |
| 26 | ARAB LIGHT | 10.2 | 449 | 0.9196 | 14.3 | 14.0 | 13.6 | 12.2 | 40.2 | 36.6 | 32.9 | 19.9 |
| 27 | MAGNUS | 13.1 | 451 | 0.8995 | 12.8 | 12.5 | 11.9 | 10.6 | 2.2 | 4.7 | 9.0 | 18.6 |
| 28 | GULLFAKS | 16.4 | 453 | 0.9204 | 15.1 | 14.7 | 14.5 | 13.0 | 7.7 | 10.1 | 11.7 | 20.6 |
| 29 | FLOTTA BLEND | 16.4 | 458 | 0.9168 | 15.6 | 15.2 | 15.0 | 13.4 | 4.6 | 7.2 | 8.3 | 17.9 |
| 30 | EKOFISK | 10.6 | 444 | 0.8963 | 11.7 | 11.4 | 10.6 | 9.6 | 10.0 | 7.5 | 0.4 | 9.8 |
| 31 | HT Kerosene | 0.8 | 205 | 0.8053 | 3.4 | 3.9 | 0.8 | 1.6 | 323.5 | 389.2 | 1.9 | 101.8 |
| 32 | HTDiesel-2 | 1.2 | 251 | 0.8310 | 3.7 | 4.2 | 1.3 | 1.9 | 211.2 | 249.1 | 5.5 | 61.0 |
| 33 | HTDiesel-3 | 2.1 | 310 | 0.8576 | 4.5 | 4.8 | 2.2 | 2.7 | 114.0 | 129.7 | 6.2 | 26.2 |
| 34 | FCC LCO | 1.1 | 250 | 0.9461 | 4.2 | 4.6 | 1.8 | 2.4 | 281.6 | 317.0 | 68.1 | 119.8 |
| 35 | FCC HCO-1 | 2.2 | 309 | 0.9960 | 5.9 | 6.1 | 3.9 | 4.2 | 166.7 | 176.7 | 76.9 | 89.3 |
| 36 | FCC HCO-2 | 3.4 | 325 | 0.9950 | 6.4 | 6.6 | 4.6 | 4.7 | 89.1 | 94.2 | 34.1 | 39.7 |
| 37 | FCC HCO-3 | 4.4 | 340 | 1.0064 | 7.4 | 7.6 | 5.7 | 5.8 | 69.0 | 71.7 | 30.4 | 32.7 |
| 38 | SRLVGO | 2.4 | 314 | 0.8800 | 4.7 | 5.0 | 2.5 | 2.9 | 97.3 | 109.9 | 5.4 | 20.7 |
| 39 | SRVGO-1 | 1.1 | 246 | 0.8345 | 3.7 | 4.2 | 1.2 | 1.9 | 236.9 | 278.7 | 11.8 | 73.4 |
| 40 | SRVGO-2 | 1.37 | 269 | 0.8456 | 3.9 | 4.4 | 1.5 | 2.1 | 187.3 | 217.8 | 11.3 | 54.9 |
| 41 | VBGO-3 | 1.7 | 295 | 0.8618 | 4.3 | 4.7 | 2.0 | 2.5 | 153.4 | 174.5 | 17.4 | 45.7 |
| 42 | SRHVGO-1 | 7.75 | 442 | 0.9230 | 13.3 | 13.0 | 12.5 | 11.3 | 72.1 | 68.3 | 61.1 | 46.4 |
| 43 | SRHVGO-1 | 12.39 | 440 | 0.9227 | 13.1 | 12.8 | 12.2 | 11.1 | 5.4 | 3.1 | 1.7 | 10.6 |
| %AAD | 61.8 | 67.8 | 18.2 | 28.3 | ||||||||
| Method 1 | Method 2 | Method 3 | Method 4 | |
|---|---|---|---|---|
| Min E | −67.3 | −70.8 | −38.5 | −33.3 |
| Max E | 36.0 | 35.9 | 48.0 | 50.2 |
| RE | −232.4 | −217.0 | 149.8 | 296.5 |
| SE | 3.1 | 3.1 | 5.1 | 3.7 |
| RSE | 12.0 | 12.2 | 20.0 | 14.5 |
| SSE | 2.4 | 2.5 | 1.5 | 1.7 |
| %AAD | 17.3 | 17.5 | 15.2 | 16.0 |
| R2 | 0.996 | 0.9959 | 0.9948 | 0.9953 |
| Slope | 0.996 | 0.9954 | 0.9244 | 1.0118 |
| Intercept | 0.1023 | 0.0095 | 0.5351 | −1.6381 |
| AIC | 211 | 175 | −14 | 190 |
| BIC | 220 | 184 | −5 | 198 |
| Method 1 | Method 2 | Method 3 | Method 4 | Aboul Seoud and Moharam | Kotzakoulakis and George | |
|---|---|---|---|---|---|---|
| Min E | −323.5 | −389.2 | −76.8 | −112.8 | −94.2 | −729.9 |
| Max E | 17.6 | 19.6 | 20.5 | 28.1 | 35.2 | 57.2 |
| RE | −2526.6 | −2743.7 | −480.1 | −517.2 | 30.5 | −291151 |
| SE | 2.6 | 2.7 | 1.8 | 2.2 | 2.7 | 7.1 |
| RSE | 28.3 | 29 | 19.9 | 23.6 | 28.9 | 77.3 |
| SSE | 44.1 | 57.6 | 3 | 5.7 | 3.7 | 141.1 |
| %AAD | 61.8 | 67.8 | 18.2 | 27.1 | 21.8 | 89 |
| R2 | 0.9324 | 0.9323 | 0.9294 | 0.9281 | 0.9038 | 0.4352 |
| Slope | 0.771 | 0.7311 | 0.8669 | 0.7603 | 0.7209 | 0.8797 |
| Intercept | 3.66 | 3.93 | 1.48 | 1.75 | 1.5 | 3.45 |
| AIC | 192 | 159 | 9 | 153 | 204 | 316 |
| BIC | 201 | 168 | 18 | 162 | 215 | 326 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stratiev, D.; Nenov, S.; Nedanovski, D.; Shishkova, I.; Dinkov, R.; Stratiev, D.D.; Stratiev, D.D.; Sotirov, S.; Sotirova, E.; Atanassova, V.; et al. Different Nonlinear Regression Techniques and Sensitivity Analysis as Tools to Optimize Oil Viscosity Modeling. Resources 2021, 10, 99. https://doi.org/10.3390/resources10100099
Stratiev D, Nenov S, Nedanovski D, Shishkova I, Dinkov R, Stratiev DD, Stratiev DD, Sotirov S, Sotirova E, Atanassova V, et al. Different Nonlinear Regression Techniques and Sensitivity Analysis as Tools to Optimize Oil Viscosity Modeling. Resources. 2021; 10(10):99. https://doi.org/10.3390/resources10100099
Chicago/Turabian StyleStratiev, Dicho, Svetoslav Nenov, Dimitar Nedanovski, Ivelina Shishkova, Rosen Dinkov, Danail D. Stratiev, Denis D. Stratiev, Sotir Sotirov, Evdokia Sotirova, Vassia Atanassova, and et al. 2021. "Different Nonlinear Regression Techniques and Sensitivity Analysis as Tools to Optimize Oil Viscosity Modeling" Resources 10, no. 10: 99. https://doi.org/10.3390/resources10100099