
Early Dropout Prediction in MOOCs through Supervised Learning and Hyperparameter Optimization

 , ,
, ,  , and
, and 
Abstract
:1. Introduction
2. Related Work
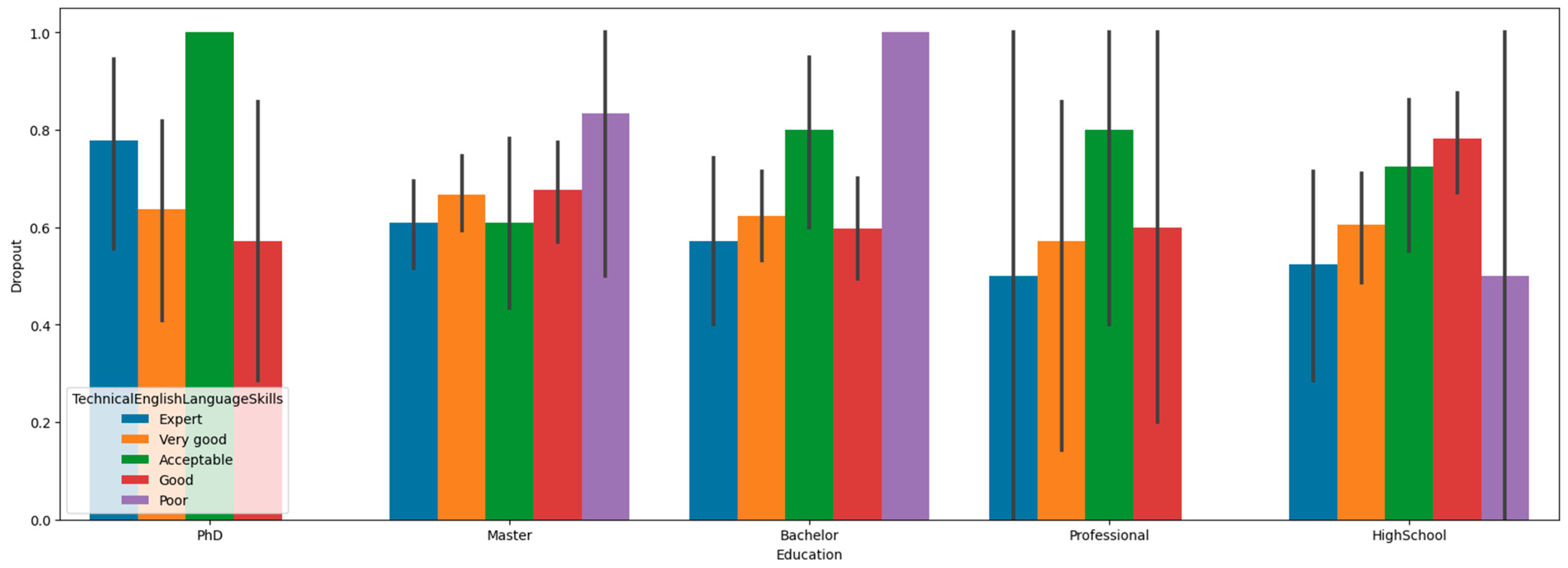
3. Dataset Description
4. Experimental Process and Results
- LightGBM, a gradient boosting decision tree implementation [19];
- Extremely randomized trees (Εxtra) algorithm [20];
- Ridge classification method (Ridge) [21];
- Gradient boosting classifier (GBC) [22];
- Random Forest (RF) ensemble method [23];
- Logistic regression (LR) [24];
- Classification and regression tree (CART) algorithm [25];
- AdaBoost boosting algorithm [26];
- Linear SVM with stochastic gradient descent (SVM-SGD) algorithm [27].
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Dalipi, F.; Imran, A.S.; Kastrati, Z. MOOC dropout prediction using machine learning techniques: Review and research challenges. In Proceedings of the 2018 IEEE Global Engineering Education Conference (EDUCON), Canary Islands, Spain, 18–20 April 2018; pp. 1007–1014. [Google Scholar]
- Cisel, M. Analyzing completion rates in the first French xMOOC. Proc. Eur. MOOC Stakehold. Summit 2014, 26, 51. [Google Scholar]
- Hone, K.S.; El Said, G.R. Exploring the factors affecting MOOC retention: A survey study. Comput. Educ. 2016, 98, 157–168. [Google Scholar] [CrossRef] [Green Version]
- Bote-Lorenzo, M.L.; Gómez-Sánchez, E. Predicting the decrease of engagement indicators in a MOOC. In Proceedings of the Seventh International Learning Analytics & Knowledge Conference, Vancouver, BC, Canada, 13–17 March 2017; pp. 143–147. [Google Scholar]
- Romero, C.; Ventura, S. Educational data mining and learning analytics: An updated survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1355. [Google Scholar] [CrossRef]
- Guo, P.J.; Reinecke, K. Demographic differences in how students navigate through MOOCs. In Proceedings of the First ACM Conference on Learning@ Scale Conference, Atlanta, GA, USA, 4–5 March 2014; pp. 21–30. [Google Scholar]
- Morris, N.P.; Swinnerton, B.J.; Hotchkiss, S. Can demographic information predict MOOC learner outcomes? In Proceedings of the Experience Track: Proceedings of the European MOOC Stakeholder, Mons, Belgium, 18–20 May 2015. [Google Scholar]
- Kizilcec, R.F.; Piech, C.; Schneider, E. Deconstructing disengagement: Analyzing learner subpopulations in massive open online courses. In Proceedings of the Third International Conference on Learning Analytics and Knowledge, Leuven, Belgium, 8–13 April 2013; pp. 170–179. [Google Scholar]
- Kizilcec, R.F.; Halawa, S. Attrition and achievement gaps in online learning. In Proceedings of the Second (2015) ACM Conference on Learning@ Scale, Vancouver, BC, Canada, 14–18 March 2015; pp. 57–66. [Google Scholar]
- Qiu, L.; Liu, Y.; Liu, Y. An integrated framework with feature selection for dropout prediction in massive open online courses. IEEE Access 2018, 6, 71474–71484. [Google Scholar] [CrossRef]
- Feng, W.; Tang, J.; Liu, T.X. Understanding dropouts in MOOCs. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 517–524. [Google Scholar]
- Al-Shabandar, R.; Hussain, A.; Laws, A.; Keight, R.; Lunn, J.; Radi, N. Machine learning approaches to predict learning outcomes in Massive open online courses. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 713–720. [Google Scholar]
- Mourdi, Y.; Sadgal, M.; El Kabtane, H.; Fathi, W.B. A machine learning-based methodology to predict learners’ dropout, success or failure in MOOCs. Int. J. Web Inf. Syst. 2019, 15, 489–509. [Google Scholar] [CrossRef]
- Imran, A.S.; Dalipi, F.; Kastrati, Z. Predicting student dropout in a MOOC: An evaluation of a deep neural network model. In Proceedings of the 2019 5th International Conference on Computing and Artificial Intelligence, Bali, Indonesia, 19–22 April 2019; pp. 190–195. [Google Scholar]
- Liang, J.; Li, C.; Zheng, L. Machine learning application in MOOCs: Dropout prediction. In Proceedings of the 2016 11th International Conference on Computer Science & Education (ICCSE), Nagoya, Japan, 23–25 August 2016; pp. 52–57. [Google Scholar]
- Jin, C. MOOC student dropout prediction model based on learning behavior features and parameter optimization. Interact. Learn. Environ. 2020, 1–19. [Google Scholar] [CrossRef]
- Iatrellis, O.; Panagiotakopoulos, T.; Gerogiannis, V.C.; Fitsilis, P.; Kameas, A. Cloud computing and semantic web technologies for ubiquitous management of smart cities-related competences. Educ. Inf. Technol. 2021, 26, 2143–2164. [Google Scholar] [CrossRef]
- Ali, M. PyCaret: An Open Source, Low-Code Machine Learning Library in Python, PyCaret Version 2.3. Available online: https://www.pycaret.org (accessed on 15 June 2021).
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Grüning, M.; Kropf, S. A ridge classification method for high-dimensional observations. In From Data and Information Analysis to Knowledge Engineering; Springer: Berlin/Heidelberg, Germany, 2006; pp. 684–691. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Ng, A.Y.; Jordan, M.I. On discriminative vs. generative classifiers: A comparison of logistic regression and naive bayes. In Proceedings of the Advances in Neural Information Processing Systems, Burlington, MA, USA; 2002; pp. 841–848. [Google Scholar]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Platt, J. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines. 1998. Available online: https://www.researchgate.net/publication/2624239_Sequential_Minimal_Optimization_A_Fast_Algorithm_for_Training_Support_Vector_Machines (accessed on 15 June 2021).
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Aha, D.W. Lazy Learning; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Emerson, L.C.; Berge, Z.L. Microlearning: Knowledge management applications and competency-based training in the workplace. UMBC Fac. Collect. 2018, 10, 2. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | Accuracy | Recall | Precision | F1-Score | Kappa | MCC |
|---|---|---|---|---|---|---|
| LightGBM | 0.9558 | 0.9507 | 0.9777 | 0.9634 | 0.9076 | 0.9097 |
| Extra | 0.9497 | 0.9434 | 0.9755 | 0.9585 | 0.8946 | 0.8972 |
| Ridge | 0.9497 | 0.9483 | 0.9704 | 0.9587 | 0.8944 | 0.8964 |
| GBC | 0.9450 | 0.9482 | 0.9637 | 0.9551 | 0.8841 | 0.8866 |
| RF | 0.9435 | 0.9434 | 0.9656 | 0.9537 | 0.8812 | 0.8831 |
| LR | 0.9421 | 0.9459 | 0.9614 | 0.9530 | 0.8776 | 0.8793 |
| CART | 0.9405 | 0.9532 | 0.9531 | 0.9522 | 0.8732 | 0.8763 |
| AdaBoost | 0.9298 | 0.9384 | 0.9491 | 0.9429 | 0.8517 | 0.8543 |
| SVM-SGD | 0.9100 | 0.9315 | 0.9376 | 0.9316 | 0.7983 | 0.8097 |
| Classifier | Accuracy | Recall | Precision | F1-Score | Kappa | MCC |
|---|---|---|---|---|---|---|
| Stacking | 0.9604 | 0.9632 | 0.9730 | 0.9677 | 0.9165 | 0.9175 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Panagiotakopoulos, T.; Kotsiantis, S.; Kostopoulos, G.; Iatrellis, O.; Kameas, A. Early Dropout Prediction in MOOCs through Supervised Learning and Hyperparameter Optimization. Electronics 2021, 10, 1701. https://doi.org/10.3390/electronics10141701
Panagiotakopoulos T, Kotsiantis S, Kostopoulos G, Iatrellis O, Kameas A. Early Dropout Prediction in MOOCs through Supervised Learning and Hyperparameter Optimization. Electronics. 2021; 10(14):1701. https://doi.org/10.3390/electronics10141701
Chicago/Turabian StylePanagiotakopoulos, Theodor, Sotiris Kotsiantis, Georgios Kostopoulos, Omiros Iatrellis, and Achilles Kameas. 2021. "Early Dropout Prediction in MOOCs through Supervised Learning and Hyperparameter Optimization" Electronics 10, no. 14: 1701. https://doi.org/10.3390/electronics10141701