1. Introduction
Internet of Things (IoT) devices refer to electronic devices (of any size) that have the capability of connecting to the internet, and collecting and sharing data, as illustrated in
Figure 1a. The aim of IoT devices is to connect and exchange data with other devices and systems over the internet. Electronic devices, such as smartphones, make use of edge systems in the mobile IoT environment [
1]. Smartphones are dominant IoT devices used to access cloud-based services, conveying sensory data related to human tasks.
They are embedded with sensors, including global positioning systems (GPSs), barometers, magnetometers, microphones, gyroscopes, accelerometers, etc. In regard to the internet, end users can perform their daily life activities online with their connected electronic devices. Most of the time, these sensors request end users to provide private information before proceeding with online activities. These sensors, working together, present a fairly complete picture of the end users’ daily activities, which has privacy implications. Another interesting aspect is that smartphones can be connected to other IoT devices, such as smart TVs and smart watches, to share data, as illustrated in
Figure 1b. The main goal of implementing these aforementioned IoT devices is to assist humans in performing their daily life activities with ease and comfort.
However, unfortunately, malicious attackers (or intruders) on the internet tend to write automated malicious applications to attack websites where end users perform their activities. These security threats sometimes put the information stored on connected IoT devices at risk. As a means of combating these malicious attacks, to protect electronic devices or smartphones and the end user’s private data, cyber security practitioners generate CAPTCHAs as a security solution to differentiate machine bots and humans.
Completely Automated Public Turing test to tell Computers and Humans Apart (CAPTCHA) is a universal automatic security program, based on cryptographic protocol; its underlying hardness assumption is centered on the problem of artificial intelligence (AI) [
2]. The main uses of CAPTCHAs are to alleviate the impact of distributed denial of service (DDoS) attacks, prevent automatic registration of free email addresses or spam postings to forums, and to prevent automatic scrapping of web content [
2]. CAPTCHAs are categorized into video, audio, images, and text-based. Among these four CAPTCHA categories, text-based CAPTCHAs are more famous and powerful security mechanisms used against automatic malicious programs. According to Hussain et al. [
2], several approaches have been developed to secure text-based CAPTCHAs, such as text distortion, random lines, and overlapping of characters with foreground and background noise. However, these text-based CAPTCHAs with conventional background and foreground noise, as a form of security, have been compromised due to the advancement of deep learning (DL), and can be solved with high accuracy.
The aforementioned observation was proven by several researchers [
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14]. DL is beneficial in other fields, including target recognition [
15], speech recognition [
16,
17], image recognition [
18,
19,
20], image restoration [
21,
22,
23], audio classification [
24,
25], object detection [
26,
27,
28,
29,
30], scene recognition [
31], etc., but it has been considered “bad news” in text-based CAPTCHAs, by penetrating their security and making them vulnerable.
Adversarial machine learning attacks may be highly necessary and recommended in the area of cyber security. Recently, AML attacks, where the robustness of an image classifier model is exposed to small perturbations, have gained more attention [
32,
33,
34,
35,
36,
37,
38,
39,
40,
41,
42,
43,
44,
45,
46,
47,
48,
49,
50,
51,
52,
53,
54,
55,
56] in the artificial intelligence (AI) research community. An adversarial attack implants adversarial or vector noise in the input image, and is deliberately constructed to fool and deceive image classifier models.
Adversarial attacks can be seen in other fields of artificial intelligence, such as medicine and autonomous driving, threatening deep learning models (for example, when an autonomous vehicle misjudges a stop sign on the road, as a result of the deformation of the sign by malicious attackers through AML attacks). Meanwhile, to the human eye, the stop sign may look normal, but to the deep learning model, it may represent a different image all together due to adversarial perturbations, which may lead to serious accidents and threats to human safety. Moreover, as a result, improving the robustness of deep learning models against adversarial attacks has been a popular topic among researchers.
However, when it comes to the cyber security research community, an adversarial attack can be considered good news, as it can be used as a security mechanism to strengthen CAPTCHAs to deceive deep learning models, to prevent malicious attacks or intrusions, and improve security. The rise of adversarial ML attacks is promising attack measures used to strengthen the security of text-based CAPTCHAs, but there is little research on this when compared to the aforementioned research studies under conventional text-based CAPTCHAs. The most important aspect is that, after generating adversarial text-based CAPTCHAs, it is eminent to verify the strength of their security before they are deployed on a website or web applications, which is a goal to be accomplished in this current work.
The motivations behind this current work can be attributed to the following intrusion detection survey works, based on securing a smart grid from intrusion [
57], network-based intrusion detection [
58], fuzzy signature-based intrusion detection systems [
59], anomaly-based intrusion detection systems [
60], intrusion detection for in-vehicle networks [
61], intrusion detection and prevention systems in digital substations [
62], operational data-based intrusion detection for smart grids [
63], defending network intrusion detection systems against adversarial evasion attacks [
64], generative adversarial attacks against intrusion detection systems [
65], adversarial machine learning in intrusion detection systems [
66]. In addition, the present study work relates well with the work by Radanliev et al. [
67], in terms of using artificial intelligence for IoT risk assessment. According to their studies, AI can be used in cyber risk analytics to enlighten organizational resilience and understand cyber risk. Their work focused on the identification of the role of AI in connected IoT devices to perform IoT risk assessment. Moreover, integration of IoT devices poses an ethical risk related to data security, privacy, reliability and management, data mining, and knowledge exchange [
68].
In terms of performing adversarial CAPTCHA security verification, to the best of our knowledge, most researchers, after fooling their proposed CNN solver models using the adversarial attack algorithms, did not go further in regard to building defense models to test the strength of the generated adversarial text-based CAPTCHAs. Even with the works that built defense models, they did so by utilizing image processing filters, which are sometimes not effective against some adversarial attack algorithms. This current work is significant to the security community, in terms of verifying the security of adversarial text-based CAPTCHA to secure IoT devices, especially smartphones and smart TVs, which are commonly used by humans, to protect their data and privacy. The assumption is that if security mechanism measures are strengthened, the activities by malicious attackers on the internet, through web applications, can also be diminished, thereby securing IoT devices, in terms of protecting data and end users’ privacy. This current study provides practical awareness of cyber risk assessment and proposes AI framework that can be utilized to perform security verification on web applications in which IoT devices are connected through the internet. Even though the focus is on CAPTCHAs for securing low-powered IoT devices, such as smartphones [
1] and smart TVs [
69], with respect to this current study, it can also be beneficial to more native scenarios and sensors, which are connected to web application programming interfaces (APIs).
Therefore, in this current research work, we propose techniques for adversarial text-based CAPTCHA image generation, by utilizing adversarial attack algorithms, including the Fast Gradient Sign Method (FGSM), Iterative Fast Gradient Sign Method (I-FGSM), and Momentum Iterative Fast Gradient Sign Method (MI-FGSM). These techniques will strengthen the security of conventional text-based CAPTCHAs by injecting a small adversarial or vector noise to generate adversarial CAPTCHAs that will retain the human perception, and then fool the Convolutional Neural Network (CNN) model.
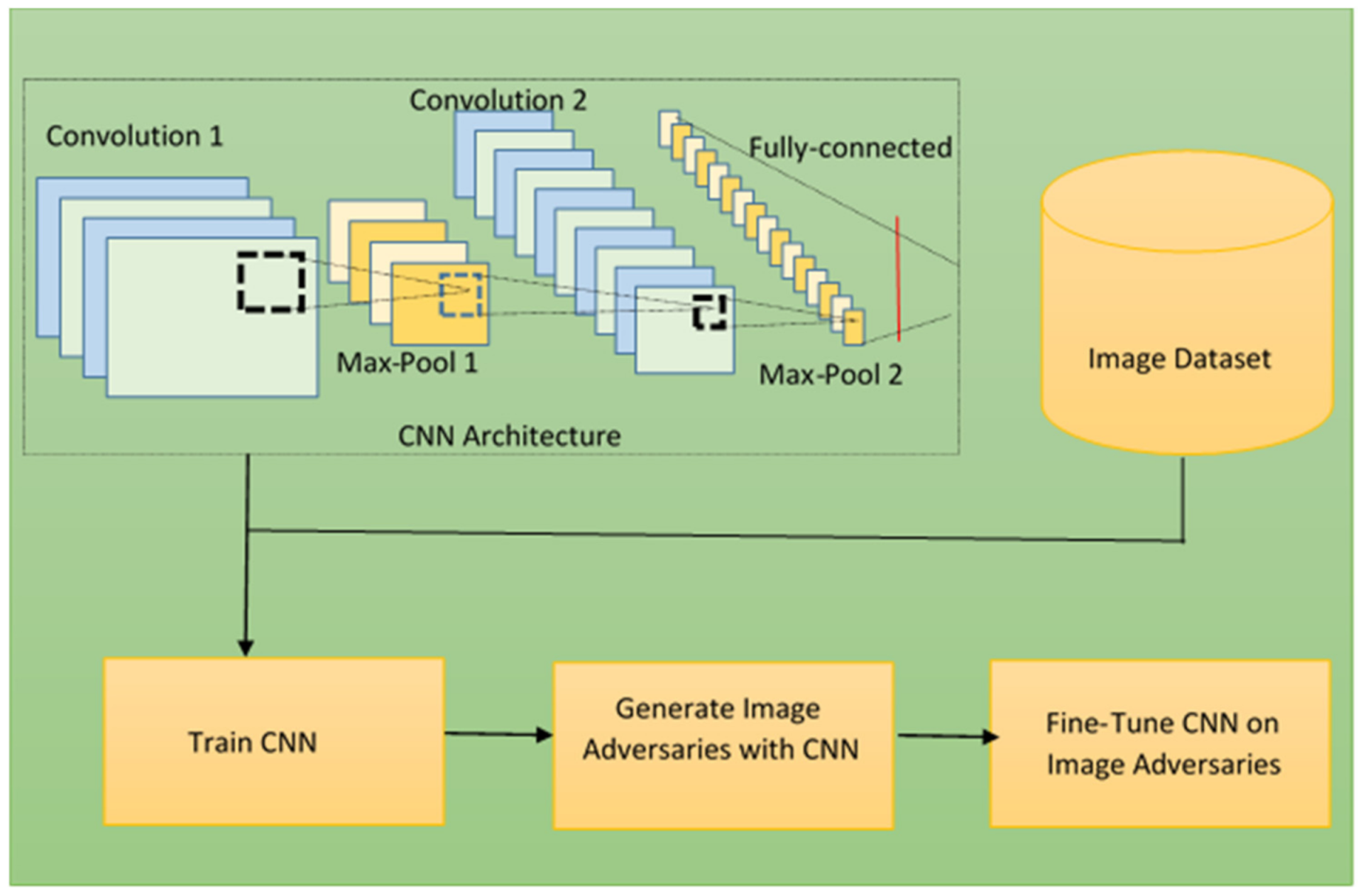
After successfully deceiving the proposed CNN solver model, we proposed two defense models. The first method is a fundamental defense model, which is the CNN with a Denoising Autoencoder (DAE-CNN) to solve adversarial text-based CAPTCHAs. The purpose of the DAE network is to automatically pre-process the adversarial text-based CAPTCHA images, where the encoder will create compressed or latent representation of the CAPTCHA images, and then the decoder will reconstruct the original CAPTCHAs from the latent representation. This will improve the quality of the adversarial CAPTCHA images by removing the noise and, therefore, increase the accuracy of the CNN solver model. This technique is less robust, requires less computation, and cannot perform generalization, it only knows adversarial text-based by forgetting how the original CAPTCHA looks like. This scenario is sometimes referred to as catastrophic forgetting in the context of adversarial attack defense. In order to mitigate this problem, this study proposes a second defense model by introducing the Mixed Batch Adversarial Generation Process (MBAGP). This technique will make the defense model more robust and more computation-efficient, and then improve the model’s capability to solve adversarial text-based CAPTCHAs. In addition, we introduce the optimal learning rate finder algorithm in conjunction with a cyclical learning rate policy to accelerate the defense model’s convergence rate to improve recognition accuracy. The goal of the proposed defense model is, in its robustness, to remove the adversarial noise. This ethical practice will serve as a form of adversarial text-based CAPTCHA security verification system, which will in turn secure the aforementioned IoT devices when connected to web services, and then protect the end user’s privacy as well.
The significance of this current study presents a way to minimize the activities of automatic malicious attackers. In addition, it also shows the cyber security research community how to perform adversarial text-based CAPTCHA security verification, using deep learning, based on the attacker–defender scenario in the context of IoT risk assessment. The following sections of this current work are organized as follows. In
Section 2, the work presents related works;
Section 3 presents the materials and the proposed methodologies used in this work;
Section 4 presents the results of the proposed CNN solver model and the attackers;
Section 5 presents the discussions, which includes comparisons with related study works, comparisons among the transfer learning results with the proposed defense models, and implications of the study work. Finally,
Section 6 presents the conclusion and summary of this current work.
2. Related Works
According to Dankwa et al. [
13], CAPTCHA deciphering is an ethical and indispensable form of a vulnerability assessment approach, to assess the strength of security in text-based CAPTCHAs before they are deployed on web applications.
With respect to previous works, Kopp et al. [
70] performed text-based CAPTCHA breaking using the cluster algorithm and CNN, consisting of two steps, character localization and recognition. Their CNN architecture resembled the LeNet-5 architecture. Their localization, CNN, consisted of two (2) convolutional layers with six (6) and sixteen (16) 5 × 5 kernels, each followed by 2 × 2 max pooling layers, and a final fully-connected output layer. They concluded that the use of CNN is superior to multi-layered perceptron (MLP).
In the work by Ondrej et al. [
71], after generating their bubble text-based CAPTCHA images, they then performed a comparative study based on traditional machine learning algorithms, such as Multi-Layered Perceptron (MLP), K-Nearest Neighbor, Support Vector Machines, and Decision Trees. They achieved a success rate of 89% based on all of their analyzed algorithms to solve the CAPTCHAs.
Zhao et al. [
9] used the Python CAPTCHA library to generate both single-letter (e.g., “A”), and multi-letter (e.g., “GCKD”) datasets. They generated 50,000 single-letter images, and 50,000 four-letter text-based CAPTCHA images. They, therefore, developed Support Vector Machines, K-Means algorithm, Convolutional Neural Network, and the VGG-19 pre-trained model with transfer learning. They concluded that, for the single-letter CAPTCHA images, the CNN model was superior to the SVM and K-Means models with an accuracy of 99%. The VGG-19 transfer learning model achieved 95% on the single-letter CAPTCHAs. The interesting aspect of the CNN model was that, as the number of letters increased from one to four, the model’s accuracy reduced to 76%. They stated that, based on their estimation, there was a mistake on judging the location of each letter (that is, splitting for individual letters) in the CAPTCHA images, with distortions, lines, and a noisy and complex background, thereby decreasing their accuracy by 50% per letter.
In the work by Yang et al. [
72], they proposed a CNN model to solve Chinese-character CAPTCHA images. The CNN architecture consisted of standard convolutional layers with 3 × 3 kernels, each followed by a ReLU activation function. They used four (4) max pooling layers, which were designed to subsample the resolution of the feature maps in the previous layer with 2 × 2 kernels. They then added a flattened layer to reduce each vector to one dimension, which was then fed to a fully-connected layer. Lastly, the final layer was fully connected to the previous dense layer with a softmax activation. Their proposed CNN model achieved 99.45% accuracy to solve the Chinese-character CAPTCHA images with noisy backgrounds.
Zahra et al. [
73] proposed a standard CNN model to solve both numerical and alpha–numerical text-based CAPTCHAs with fie characters in each CAPTCHA image. They generated their dataset using the Python CAPTCHA library. Their network started with a convolutional layer with 32 input neurons, ReLU activation function, 5 × 5 kernels. They used max pooling with 2 × 2 kernels, 30% dropout rate, and an output layer with softmax activation. They compiled their network using the Adam optimizer. Their proposed CNN model achieved 98.94% and 98.31% for the numerical and alpha–numerical, respectively.
In the work by Shu et al. [
74], they generated four-character text-based CAPTCHA images with distortions, rotation, and noisy background using the CAPTCHA open source python library tool. They built an end-to-end deep CNN–RNN model, which first constructed a deep Convolutional Neural Network based on residual network architecture to accurately extract the input CAPTCHA image features. In their study, via a constructed variant RNN network, which is a two-layer GRU network, the deep internal features of the text-based CAPTCHA are extracted and the final output sequence becomes the four-character CAPTCHA. Their proposed CNN–RNN model achieved 99% accuracy to solve text-based CAPTCHAs. This kind of architecture sometimes gives good results; however, it is relatively complex to train.
Hu et al. [
14] used the Python script to generate five-character text-based CAPTCHA images. They then proposed a method based on VGG-Net CNN, with a transfer learning approach to solve their generated CAPTCHAs. Their study used an adaptive learning rate technique to accelerate the convergence rate of their model to solve the problem of over-fitting, and obtained local optimal solution. Their model achieved 96.5% to solve five-character text-based CAPTCHAs with background noise and adhesion distortions.
Osadchy et al. [
75] proposed Deep-CAPTCHA using adversarial examples for CAPTCHA generation based on an object classification framework, which involved a large number of classes. They used the Fast Gradient Sign Method algorithm to generate single text-based CAPTCHA characters based on the MNIST digits dataset. Papernot et al. [
76] proofed the limitations of deep learning in an adversarial setting. They exploited forward derivatives, which informed the learned behavior of Deep Neural Networks (DNNs) and generated adversarial saliency maps, allowing efficient exploration of the adversarial sample spaces. They used their algorithm to generate single text-based CAPTCHA characters based on the MNIST digits dataset.
Zhang et al. [
77] showed the effect of adversarial examples on the robustness of CAPTCHAs. They used the VGG16, ResNet101, and the Inception-ResNet-V2 CNNs in conjunction with the Fast Gradient Sign Method and the Universal Adversarial Perturbations method [
78] to generate their adversarial text-based CAPTCHAs. Kwon et al. [
79] generated their adversarial text-based CAPTCHAs using the FGSM, I-FGSM, and the Deep-Fool algorithms. Their experiment results showed a 0% recognition rate with epsilon of 0.15 for FGSM, a 0% recognition rate with alpha of 0.1 with 50 iterations for I-FGSM, and a 45% recognition rate with 150 iterations for the Deep-Fool algorithm. Their CNN architecture consisted of five convolutional layers, five max pooling layers followed each of the convolutional layers, six ReLU activation layers, one fully connected layer, and an output layer with softmax activation.
In the work by Shao [
80], the study proposed adversarial text-based CAPTCHA, named Robust Text CAPTCHA (RTC). The work then defended against their generated adversarial text-based CAPTCHAs using image processing filters with transfer learning techniques. For their CNN architectures, the study used pre-trained models including LeNet, AlexNet, GoogLeNet, VGG19, ResNet50, and DenseNet169. The observation results showed that the image processing filters, together with the pre-trained CNN models, were not able to withstand the generated adversarial text-based CAPTCHAs.
3. Materials and Methods
This section presents the dataset used in this current work, the adversarial attack algorithms, the proposed CNN solver architecture, the proposed fundamental defense DAE–CNN workflow, the cyclical learning rate policy algorithm, and the robust and efficient CNN with the Mixed Batch Adversarial Generation Process (MBAGP) defense workflow.
3.1. Data Acquisition and Description
In this current work, we generated our own text-based CAPTCHA image dataset, as shown in
Figure 2a, using an open source Python library, since there are no publicly available text-based CAPTCHA data to be used. The text-based CAPTCHAs contain both digits (0–9) and uppercase English letters (A–Z), consisting of four characters. We then collected more complex real world text-based CAPTCHAs, as seen in
Figure 2b.
In total, we generated 10,000 original text-based CAPTCHA datasets. We then divided the datasets into training and testing sets, representing 80% and 20%, respectively. Based on the training and testing sets of the original CAPTCHA dataset, we generated the adversarial examples using the FGSM, I-FGSM, and the MI-FGSM attack algorithms with an epsilon of 0.25, iteration of 10, and a decay factor of 1.0. A sample of the adversarial text-based CAPTCHA generated is shown in
Figure 3c. In the perception of the human eye,
Figure 3a,c look identical, but to the CNN solver model, they look like two entirely different images, which may lead to low accuracy for the model to solve. The Python library used in this work is available at (
https://pypi.org/project/captcha/ (accessed on 6 May 2021)).
3.2. Adversarial Attack Algorithms
This section presents the concept behind adversarial attack formulation and the gradient-based attack algorithms used in this current work.
3.2.1. Adversarial Attack Formulation
There is a trained Convolutional Neural Network (CNN) classifier given as
where
is the image,
is a parameter, and
is the probability distribution over the classes. The CNN assigns to
the class
. Therefore, for some, image
finds perturbation
, such that,
where (2) is untargeted adversarial attacking, and (3) is targeted adversarial attacking. Based on either (2) or (3), what we want is to represent
to human as
.
3.2.2. Fast Gradient Sign Method
In the Fast Gradient Sign Method (FGSM) [
36], the gradient descent is changed from the original image
, based on the epsilon
value, and then the adversarial example
is obtained through optimization. It is a simple technique to be used to generate adversarial examples with good performance. FGSM can be formulated as:
3.2.3. Iterative Fast Gradient Sign Method
The Iterative Fast Gradient Sign Method (I-FGSM) [
49] generates adversarial examples based on a given iteration on a target image classifier model. I-FGSM can be formulated as:
3.2.4. Momentum Iterative Fast Gradient Sign Method
In the Momentum Iterative Fast Gradient Sign Method (MI-FGSM) [
50], transferability is improved based on the past updating direction, which is termed as momentum.
Based on (4), (5), and (7), , , are the adversarial examples, is the epsilon, is the classifier model, is the original CAPTCHA image, is the target labels, is the loss function, is the momentum factor, is the gradient direction of . In this work, the adversarial text-based CAPTCHA examples were generated using (4), (5), and (7).
3.3. Basic Concepts behind Autoencoders (AEs)
As illustrated in
Figure 4, an autoencoder (AE) is composed of an encoder and decoder. The variable X in the lower layer represents an input value, which is regenerated as an output value via the middle hidden layer. The middle hidden layer serves as a feature extractor. The regenerated value X’ aims to be a value similar to the input value X. The input vector X of the lower layer is calculated by the encoder and compressed to
as an output through the hidden layer, which is formulated as:
In the decoder model, the y value of the hidden layer is remapped to X’, and then reconstructed as an output value, formulated as:
Autoencoders (AEs) study an encoder function from input to representation, and a decoder function, back from representation to the input space, such that the reconstruction, a combination of the encoder and decoder, is good for training examples [
81]. In simple terms, an autoencoder (AE) is a neural network that is trained to attempt to copy its input to its output, as shown in
Figure 4.
3.4. Existing CNN Architectures Used as Transfer Learning
Based on the aforementioned related works, previous researchers generated their adversarial CAPTCHAs by adopting transfer learning techniques in conjunction with adversarial attack algorithms. Therefore, in order to evaluate the strength of the proposed CNN model, we adopted transfer learning methods by using notable state-of-the-art CNN architectures. These famous CNN architectures include GoogLeNet [
82], ResNet [
83], VGG-Net [
84], Xception [
85], and DenseNet [
86].
3.4.1. GoogLeNet
The GoogLeNet architecture starts with two Conv–max pool blocks and continues with a series of inception blocks separated by max pool layers before the final fully-connected layer. In their paper, all of the convolutions in conjunction with those inside the inception modules, used rectified linear activation. The inception block takes the tensor as the input and passes it through four different streams as: a 1 × 1 convolution layer, a 1 × 1 convolution layer followed by a 3 × 3 convolution layer, a 1 × 1 convolution layer followed by a 5 × 5 convolution layer, and a 3 × 3 max pool layer followed a 1 × 1 convolution layer. Then, the output tensors of all four final convolution layers are concatenated to one tensor.
3.4.2. ResNet
ResNet begins with a Conv–BatchNorm–ReLU block and then continues with a series of ResNet blocks before the final average pool and fully-connected layers. The ResNet block comprises of a repetition of blocks. The input tensor goes through three Conv–BatchNorm–ReLU blocks and then the output is added to the input tensor to form a skip connection. The two types of skip connection in ResNet are the identity and projection blocks. The identity block takes a tensor as an input and then passes it through one stream of: a 1 × 1 convolution layer followed by a batch-normalization and a rectified linear unit activation layer, a 3 × 3 convolution layer followed by a batch-normalization and a rectified linear unit activation layer, and a 1 × 1 convolution layer followed by a batch-normalization layer. Then the output is added to the input tensor. The projection block takes a tensor as an input and then passes it through two streams, the left and right streams. The left stream consists of: a 1 × 1 convolution layer followed by a batch-normalization and a rectified linear unit activation layer, a 3 × 3 convolution layer followed by a batch-normalization and a rectified linear unit activation layer, and a 1 × 1 convolution layer followed by a batch-normalization layer. The left consists of a 1 × 1 convolution layer followed by a batch-normalization layer.
3.4.3. VGG-Net
The VGG-Net architecture comprises of five convolutional blocks and three fully-connected layers. Each convolutional block consists of two or more convolutional layers and a max pool layer. All hidden layers are equipped with the rectification non-linearity, and max pooling is performed over a 2 × 2-pixel window, with stride 2. In this current work, we implemented VGG19 architecture.
3.4.4. Xception
With respect to the Xception architecture, all pointwise convolution and depth-wise separable convolution layers are followed by batch-normalization. Moreover, all of the depth-wise separable convolution layers contain a depth multiplier of 1. The Xception network is grouped in three flows, which are entry flow, middle flow with eight repetitions of the same block, and exit flow.
3.4.5. DenseNet
The DenseNet architecture connects each layer to every other layer in a feed-forward manner. The feature maps of all preceding layers are used as inputs, and then its own feature maps are used as inputs into all subsequent layers. Some of the advantages of the DenseNet architecture are to prevent the vanishing-gradient problem, and strengthen feature propagation. In this current work, we used the Dense-121 network, which is easy to implement and train, but effective. The architecture starts with standard convolution-pooling block, and continues with a series of dense block and transition layers. It finally closes with a global average pooling and fully connected layer.
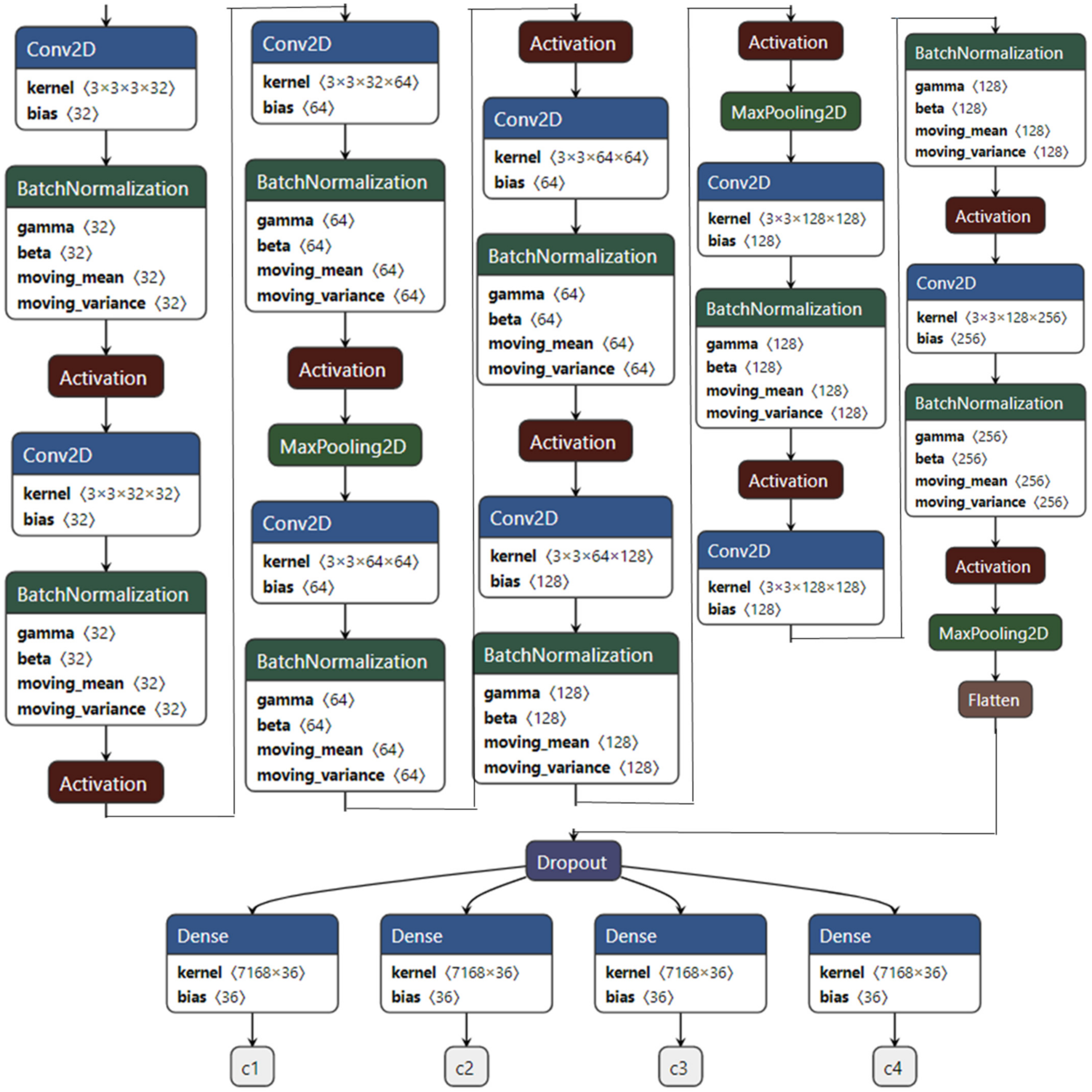
3.5. The Proposed CNN Solver Model without Defense
The architecture of our proposed CNN solver model consists of nine convolutional layers, nine batch-normalization layers, nine rectified linear unit activation layers, three max pooling layers, one flatten layer, one dropout layer, and four fully-connected layers with each output with softmax activation. The network structure starts with Conv=>BatchNorm=>ReLU=>max pool block, and repeat itself for three times. Each block contains three convolutional layers, three batch-normalization layers, three activation ReLU layers, with each of the batch-normalization layers. The network contains three max pooling layers, which follows each of the three blocks. At the end of the max pooling layer, we placed a flatten layer, and a dropout, which connected to four fully-connected layers with output softmax activation layers. This study proposed a custom CNN architecture because, sometimes, the aforementioned transfer learning techniques may take a longer time to train, may sometimes consume a lot of memory and space, especially, the ResNet architecture is very difficult to implement and train.
The network structure of the proposed CNN solver model is illustrated in
Figure 5.
3.6. The Cyclical Learning Rate Policy
Initially, we used an automatic learning rate finder algorithm to find optimal learning rates, which were then used in the CLR algorithms. The idea was to make the defensive model more robust to withstand the adversarial text-based CAPTCHAs, by accelerating the convergence rate of the CNN solver model.
In the experiment, using the cyclical learning rate (CLR) [
87] technique leads to faster convergence and fewer hyper-parameter updates. CLRs oscillate back and forth between two bounds when training, and slowly increase the learning rate after each batch update. By decreasing the learning rate overtime, the CNN model is allowed to descend into lower areas of the loss domain. However, in reality, there is no guarantee that the model will descend into areas of low losses when lowering the learning rate. This is a problem that the CLR method tries to solve.
Therefore, the CLR policy practically eliminates the need to experimentally find the best values and schedule for the global learning rates. Training with CLRs instead of fixed values achieved good performance without the need to tune the model.
The CyclicLR () callback implements a cyclical learning rate policy, as used in this current study. The technique cycles the learning rates between the two boundaries with constant frequency [
87]. The amplitude of the cycle can be scaled on a per-iteration or per-cycle basis. The cyclical callback has three built-in policies, which are: “triangular”: a basic triangular cycle with no amplitude scaling, “triangular2”: a basic triangular cycle that scales the initial amplitude by half each cycle, and “exp_range”: a cycle that scales initial amplitude by gamma at each cyclic iteration. The arguments of the cyclical callback can be seen from
Table 1.
The structure of the CLR policy algorithm is represented as:
where
x is either the iteration or cycle depending on the scale_mode.
3.7. Denoising Autoencoder (DAE) Neural Network
In conventional autoencoders (AEs), the reconstruction of the input at the output is based on the learned underlying manifold of the training dataset’s distribution. Conventionally, autoencoders (AEs) minimize some functions, which is formulated as:
where
is a loss function, which penalizes
as result of being dissimilar from
, such as the
norm of their difference. Based on (13), a Denoising Autoencoder (DAE) neural network minimizes
where
is a copy of
, which has been corrupted by the adversarial or vector noise. The loss function, which we want to minimize for the DAE, is given as:
where
is a factorial distribution,
is an internal representation,
is the adversarial text-based CAPTCHA version of the original text-based CAPTCHA sample
, which is obtained through the given corruption process
, based on the FGSM, I-FGSM, and MI-FGSM adversarial attack algorithms.
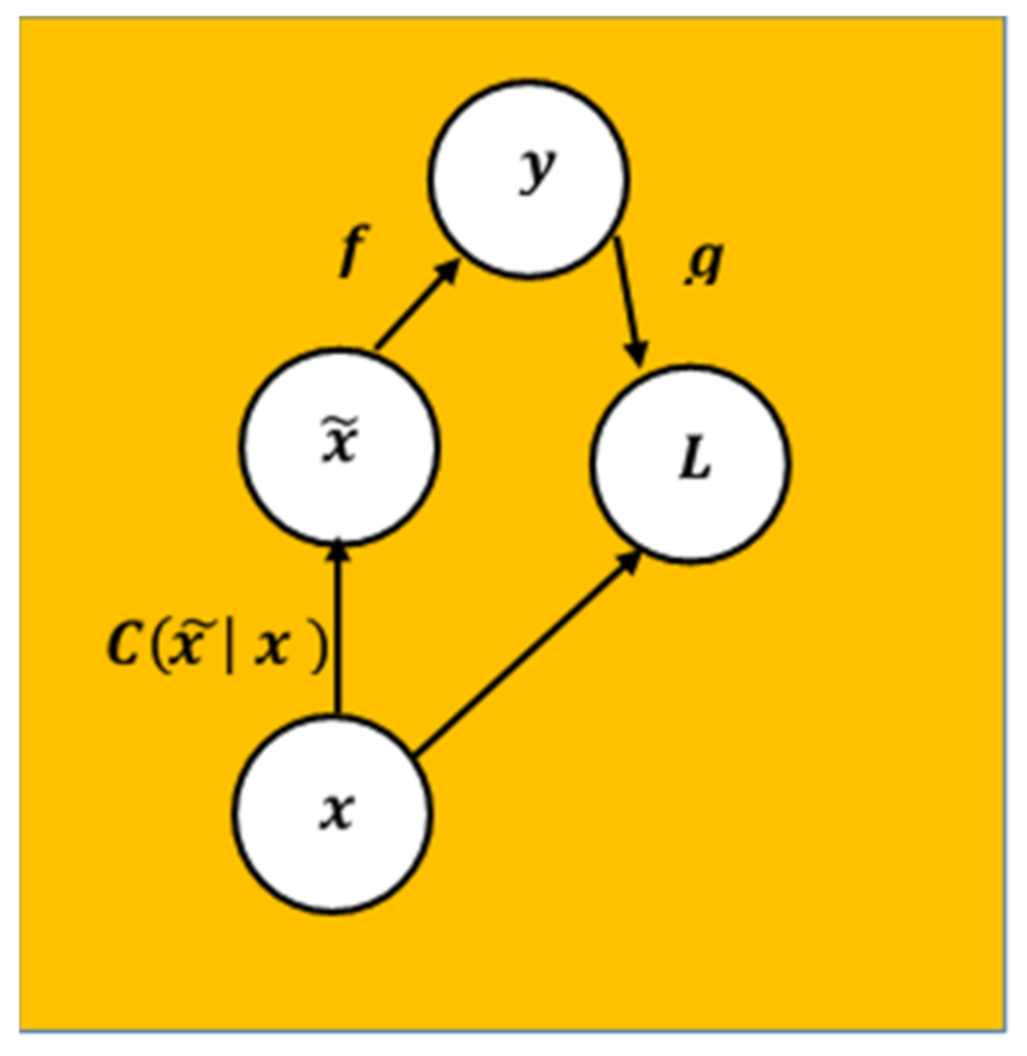
The DAE neural network’s computational graph of the cost function is illustrated in
Figure 6.
3.8. The Proposed Technique of the Baseline Defense Deep Learning Model
Existing defending strategies, including adversarial training [
6], image processing, and manual labelling, have been compromised, and sometimes may not be effective against some adversarial text-based CAPTCHA attacks. A basic workflow, defending against adversarial attacks, is illustrated in
Figure 7. Therefore, with this assumption, this study initially proposes a Convolutional Neural Network with Denoising Autoencoder (DAE-CNN) as a defense model. The workflow of the proposed DAE-CNN model is illustrated in
Figure 8. Given the corrupted process
, which represents a conditional distribution over the generated adversarial text-based CAPTCHA data
from the original text-based CAPTCHA data
, then the DAE neural network will learn a reconstruction distribution
, which is estimated from the training pairs
as follows:
Sample a training example from the original CAPTCHA dataset.
Sample an adversarial CAPTCHA version from .
Use as a training example to estimate the DAE reconstruction distribution with as the output of the encoder and is typically represented as a decoder .
The output of the DAE network is then served as input to the CNN model. We further accelerate the convergence rate of the CNN solver model with an automatic learning rate finder (LRF) algorithm to find optimal learning rates in conjunction with the cyclical learning rate (CLR) policy. The proposed CNN solver model architecture and the CLR algorithm were already explained in the aforementioned section. For the proposed CNN solver architecture, the input shape was 160 × 60, depending on the width and the height of the text-based CAPTCHA, respectively. With vigorous experiments, we trained the CNN model using categorical cross-entropy (CCE), and Adam as the loss function, and optimizer, with a batch size of 32 over 25 epochs, respectively. The learning rate was automatically obtained using the cyclical learning rate policy to improve accuracy.
The structure of the DAE was a bottleneck fully-connected neural network, with the input dimension unit equal to the output dimension unit. The input and output dimension units were obtained through multiplication of 160 × 60 based on the width and the height of the CAPTCHA image. The DAE was then trained with the original CAPTCHA and the adversarial CAPTCHA datasets. Based on the experiment, the mean square error (MSE), and Adam were used as the loss function, and optimizer, to compile the network with a batch size of 256 over 200 epochs, respectively. After training, the DAE network obtained a MSE value of 0.0040, which showed the DAE network’s robust capability to approximate the clean data input of both the original and the adversarial CAPTCHA datasets. The codes in this work were implemented using the Python 3.6 programming language, and were executed and trained on a GPU, based on the Google Colab (
https://colab.research.google.com/ (accessed on 20 February 2021)) environment.
3.9. The Proposed Technique of the Robust Defense Deep Learning with the Mixed Batch Adversarial Generation Process
The robust proposed defense model was inspired by the works [
88,
89]. They provided checklists and recommendations that can be followed to develop a more robust, efficient, and uncompromised defense model. According to their work, a good starting point is a model as equal to the defense model as possible, which this study has already implemented, as illustrated in
Figure 8. The assumption is that, if the defense model would just add some layers to the baseline model, then it would be better to try the baseline model. They further stated that a good proposed defense model should attempt to break the transferability attack.
Therefore, our innovation idea in the second proposed defense model is to introduced a technique called MBAGP, which stands for, Mixed Batch Adversarial Generation Process, to implement a completely new proposed defense model. That is, instead of fine-tuning the CNN model on the adversarial CAPTCHA images, the batch generation training process itself is reconstructed. The second proposed defense model violated the standard protocol of training neural networks in batches by incorporating the adversarial text-based CAPTCHA images into the training process itself, together with the original data. Meaning, the model itself will generate adversarial CAPTCHA images, combine them with the original CAPTCHA training dataset, and then the model is finally trained.
The steps involved in the reconstruction of the standard training procedure to incorporate the adversarial CAPTCHA images are as follows:
The CNN model is initialized;
The total N training samples are selected;
The CNN model is used, together with the adversarial attack algorithm to generate a total of N Adversarial samples;
The original and the adversarial CAPTCHA images are mixed, for a batch size of N × 2;
The defense model on both the original and adversarial CAPTCHA training samples are trained.
The first proposed defense method is less robust and less computation since we will generate only one set of adversarial images, and then fine-tune the model on only the adversarial CAPTCHA images. While the second proposed method, is the MBAGP-CNN model, is more robust and significantly more computation-efficient. The advantage is that it may see both the original CAPTCHA and the adversarial CAPTCHA images through every single batch update throughout the training process. In simple terms, the robust defense model will be used to generate the adversarial CAPTCHA images throughout each batch, as a result, the model will deceive itself, and then learn from its mistakes, so that it can better defend against adversarial CAPTCHA images. In addition, it will learn the patterns of both the original CAPTCHA and the adversarial text-based CAPTCHA images. In addition, the robust MBAGP-CNN model will improve itself based on two factors. For the first factor, the discriminating patterns of the training data will be ideally learned by the model after each batch update. For the second factor, the model will learn to defend against its own generated adversarial text-based CAPTCHAs.
3.10. Performance Evaluation
The proposed deep learning model was evaluated using accuracy and K-fold cross-validation.
3.10.1. Accuracy
The formulas for accuracy is given as:
where
TP is True Positive,
TN is True Negative,
FP is False Positive,
FN is False Negative based on the model’s prediction.
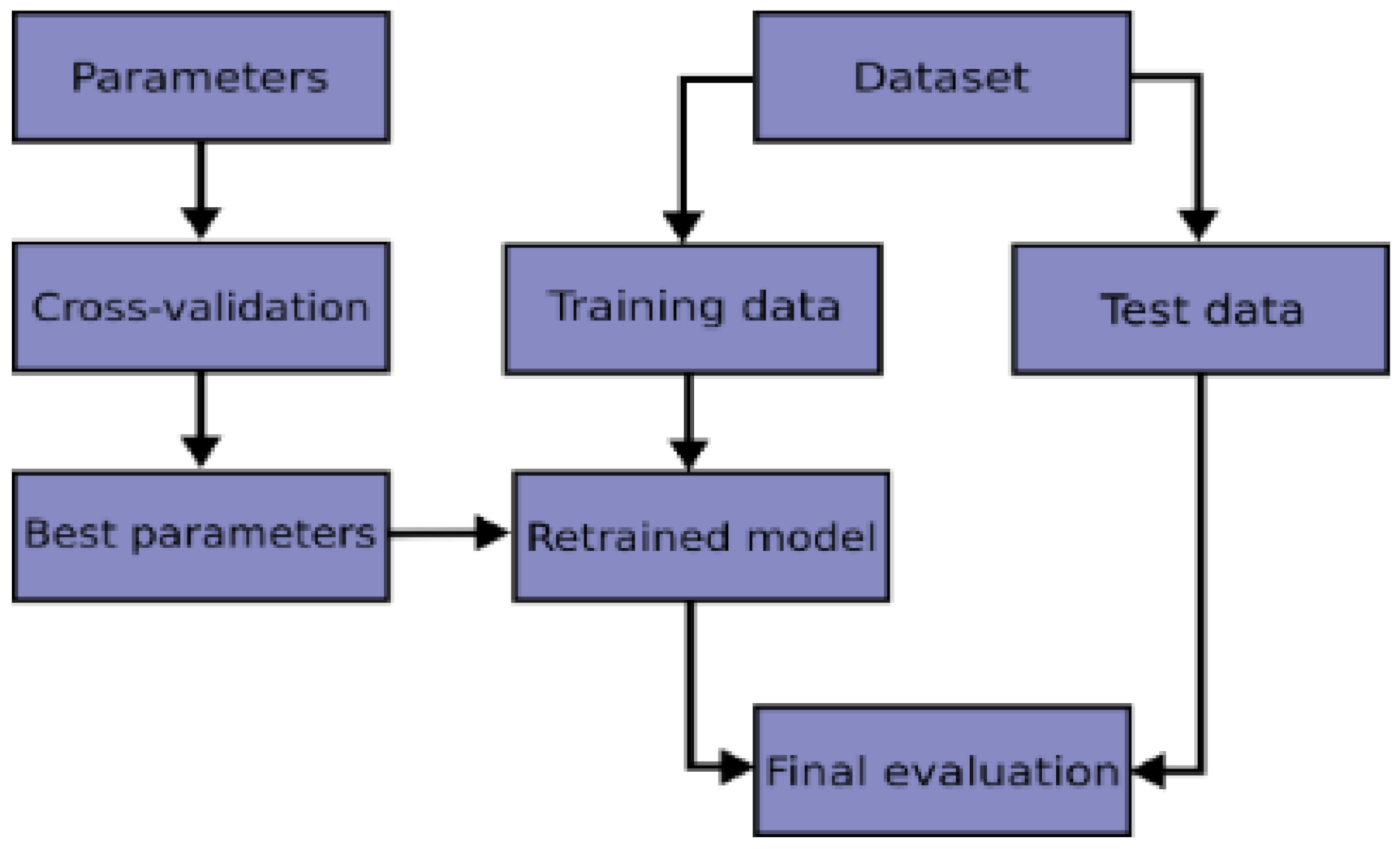
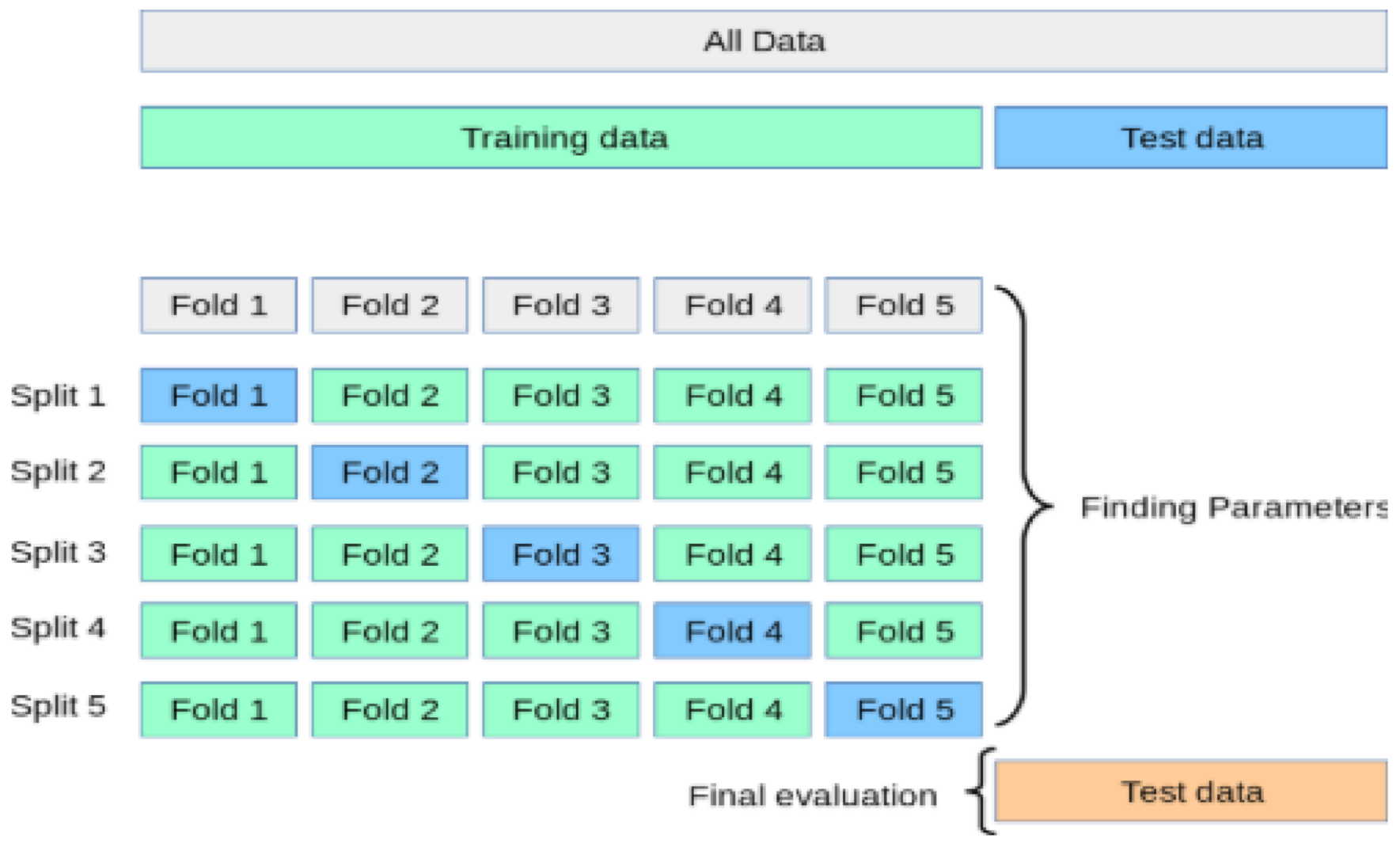
3.10.2. K-Fold Cross-Validation
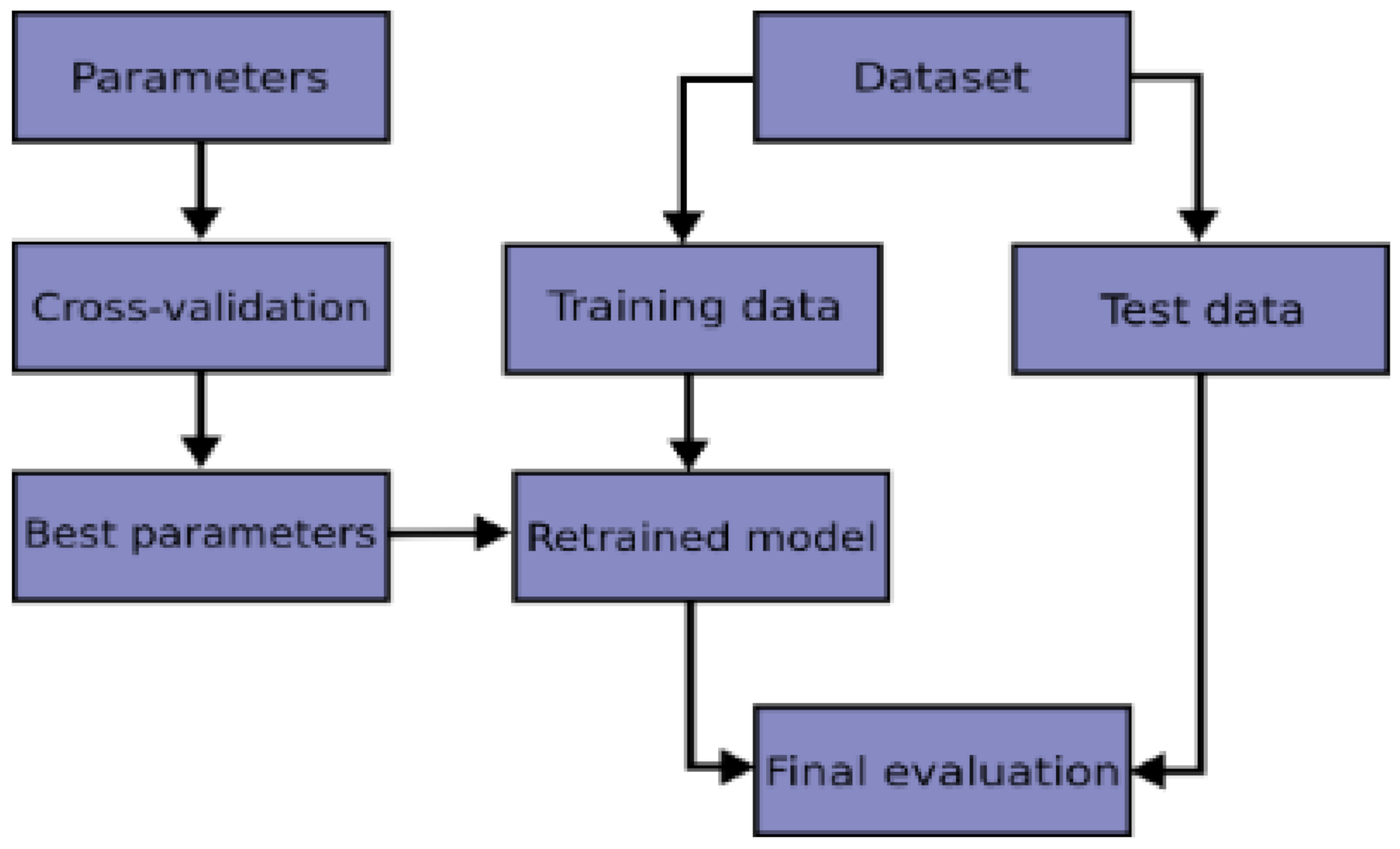
In this current work, we performed K-fold cross-validation to further evaluate the robust performance of the proposed model. A typical cross-validation workflow flowchart is illustrated in
Figure 9.
The process of the K-fold cross-validation is described as [
90]:
- ⮚
Splitting the data into K-folds;
- ⮚
Out of the K-folds, K-1 sets are used to train, whereas the remaining set is used for testing;
- ⮚
The CNN model is trained and tested K times; each time a new set is used as testing, whereas the remaining set is used for training;
- ⮚
The average of the results obtained at each set represents the result of the K-fold cross-validation.
The process of the K-fold cross-validation is illustrated in
Figure 10. In this current work, we performed five-fold cross-validation based on empirical evidence that 5- or 10-fold cross validation should be preferred [
90]. The workflow of the proposed MBAGP-CNN model is illustrated in
Figure 11.
5. Discussion
In the work by Zhanyang et al. [
91], they conducted a survey on artificial intelligence (AI) for securing IoT services in edge computing. According to their observations, in the context of security and privacy preservation issues, AI has opened up many possible windows to address security challenges. The main ideas behind text-based CAPTCHAs are: they serve as a means of security to secure user-logins against dictionary or brute force password guessing, prevent automated usage of various web services, prevent machine bots from spamming on forums, prevent downloading large files, etc. As mentioned in the previous related works section, several researchers who performed text-based CAPTCHA security verification used the transfer learning approach to build their CNN models. However, in this current work, the study proposed custom CNN architecture as an inspiration from these notable existing CNN architectures. This is because, sometimes, these existing CNN architectures contain a greater number of parameters, and consume a lot of time and memory, especially VGGNet, and ResNet. As a result, in order to evaluate the strengths and weaknesses of our proposed CNN solver and defense models, we adopted the transfer learning technique based on the famous state-of-the-art CNN architectures, such as GoogLeNet, ResNet, VGGNet, Xception, and DenseNet.
After testing on the original CAPTCHA dataset, the pre-trained models achieved accuracies of 80.47%, 80.78%, 81.45%, 86.79%, and 84.88% based on GoogLeNet, ResNet50, VGG19, Xception, and DenseNet121, respectively, as shown in
Table 4 and
Figure 15. The observed results showed that the Xception and the DenseNet transfer learning models exhibited good results on the original CAPTCHA test set. This work then fine-tuned the transfer learning or pre-trained models on the generated adversarial text-based CAPTCHA test sets. The attacks to the proposed pre-trained solver models were successful at reducing ~50% of the test accuracy, as seen from
Table 4 and
Figure 15. The observation was that the attack algorithms strengthened the security of the conventional text-based CAPTCHAs, and drastically reduced the test accuracies by fooling the pre-trained models and our proposed CNN solver model, as shown in
Figure 15.
However, the goal in this current work is to perform adversarial text-based CAPTCHA security verification, so it means that the security of the CNN solver models need to be strengthened to withstand the attacks. This study initially used the image processing filter, which included, MeanBlur, MedianBlur, GuassianBlur, and RotateFilter techniques, in conjunction with the transfer learning approach, and our proposed CNN, as a form of a feasibility analysis to defend against the adversarial text-based CAPTCHAs. However, the results of the image processing filters, together with CNN models, were less effective on the adversarial text-based CAPTCHAs. Therefore, with inspiration from existing defense techniques and guidelines [
85], we proposed our first Convolutional Neural Network with Denoising Autoencoder (DAE-CNN), as a defense workflow model, as illustrated in
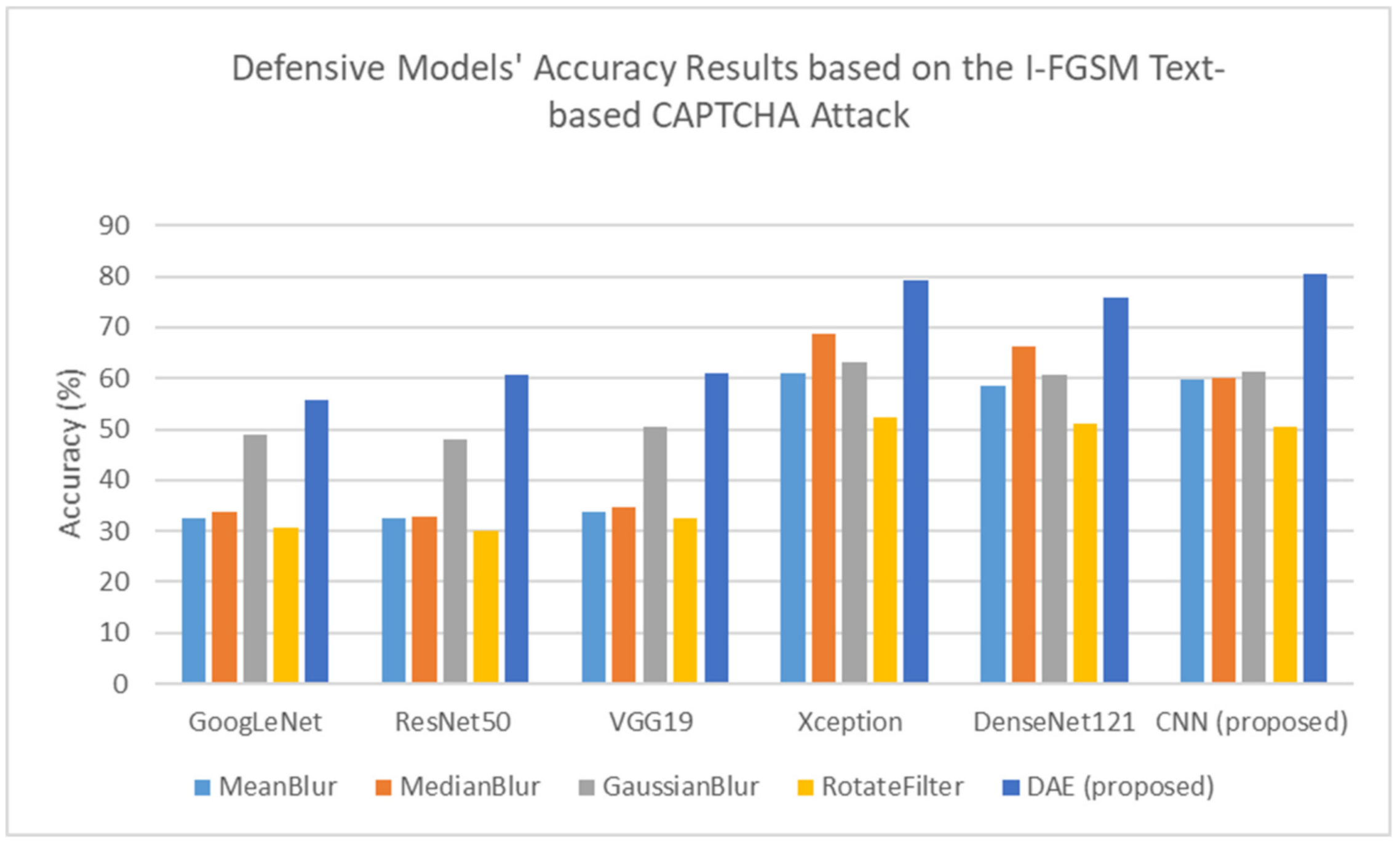
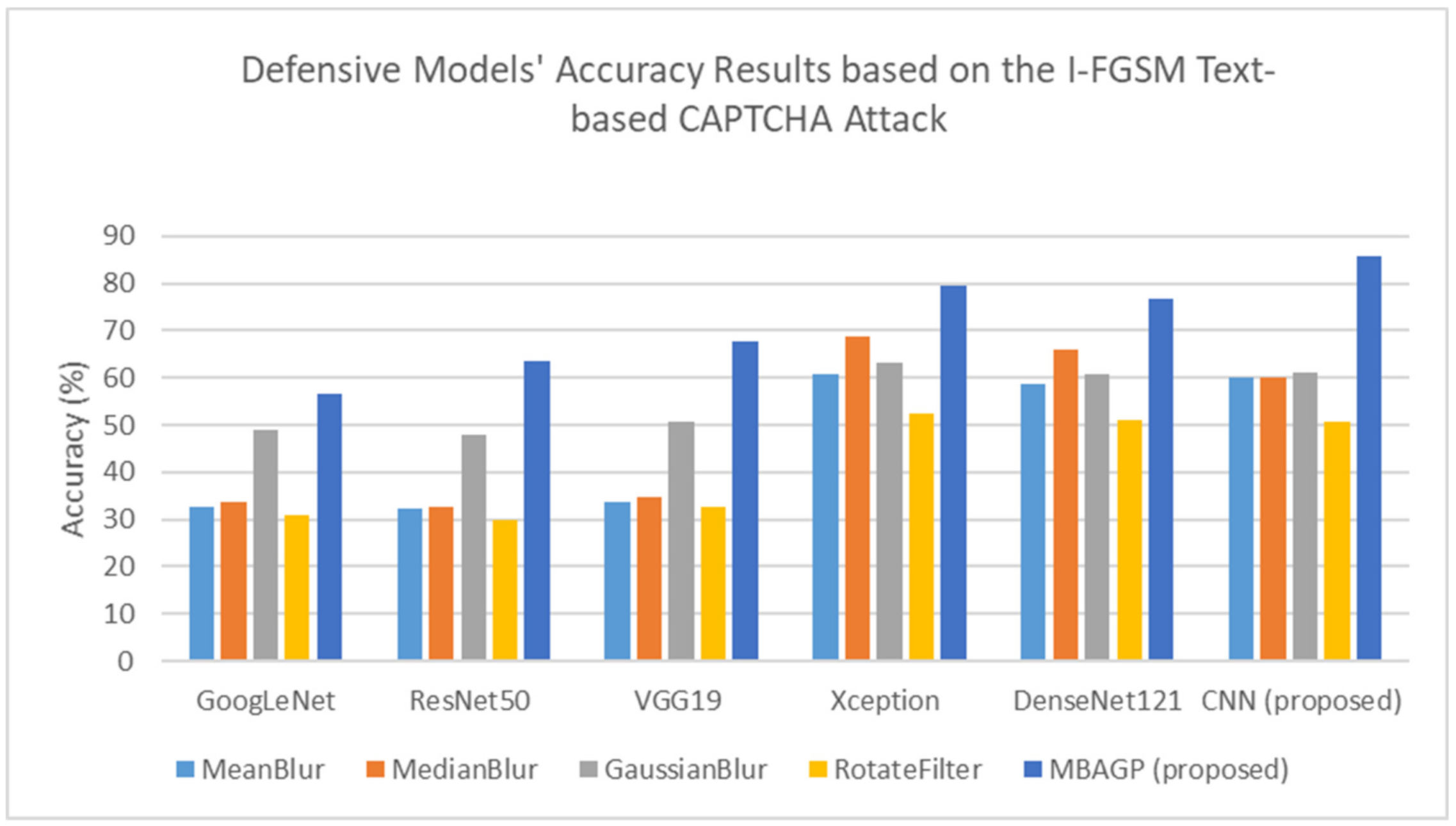
Figure 8. Based on the adversarial test sets, the proposed DAE-CNN model was successful at reducing ~10% of the test accuracy among the three adversarial attack algorithms, FGSM, I-FGSM, and MI-FGSM, as shown in
Figure 16,
Figure 17 and
Figure 18, respectively.
Table 5,
Table 6 and
Table 7 summarize the comparison accuracy results, defending against the FGSM, I-FSGM, and MI-FGSM attacks using the image processing filters with the transfer learning models, compared to the proposed DAE-CNN model based on the testing sets.
This study further went on to propose a second defense model, which is more robust and computationally-efficient when compared to the first method. Based on the innovation idea, this study took the DAE-CNN model, and then introduced a technique called Mixed Batch Adversarial Generation Process (MBAGP). We reconstructed the standard training procedure protocol of the CNN batch training process. The idea was to mitigate the problem of catastrophic forgetting, as already explained and illustrated in detail in
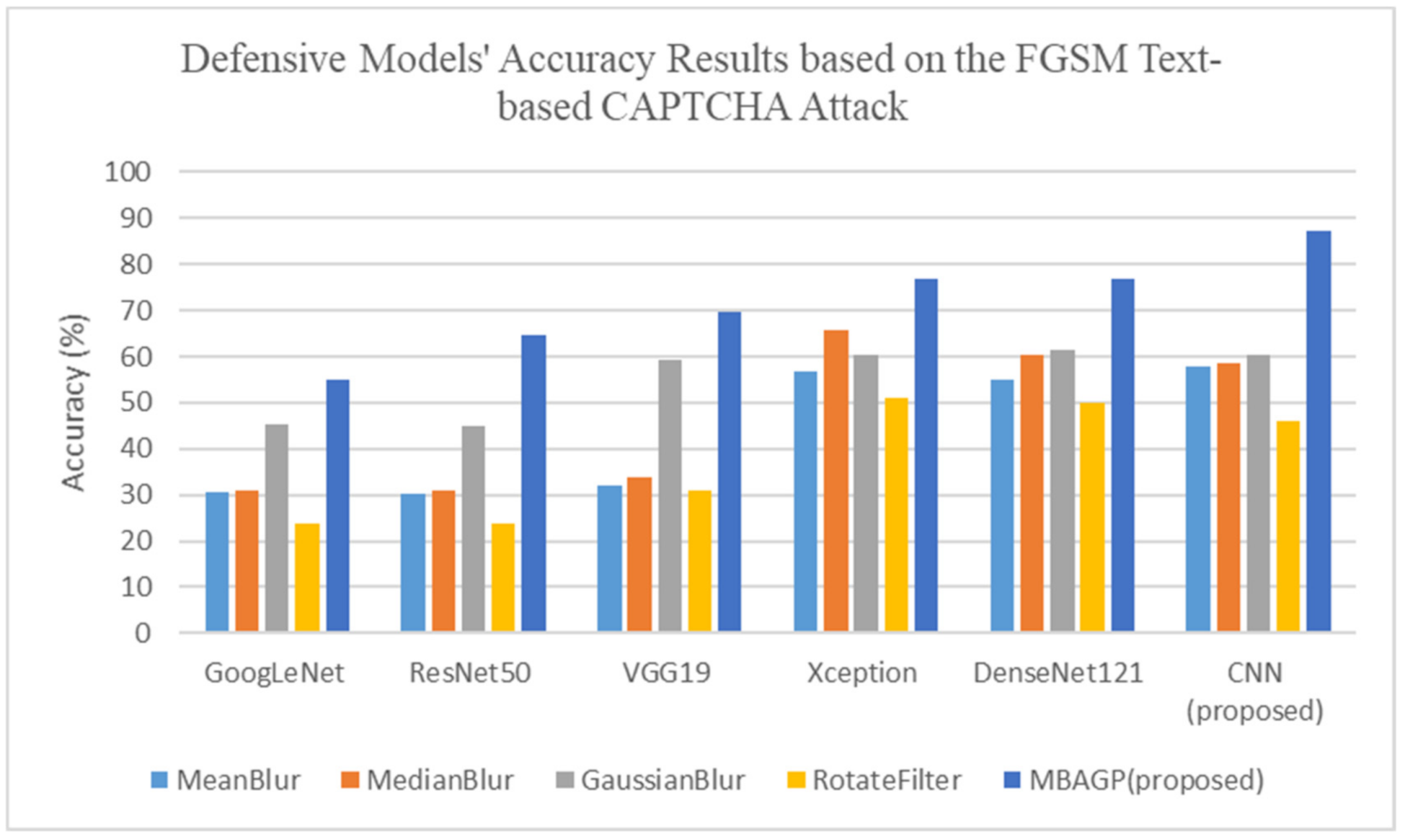
Figure 7. The MBAGP-CNN model is able to generalize and perform better to verify adversarial text-based CAPTCHA security. Based on the adversarial test sets, the proposed DAE-CNN model was successful at reducing ~5% of the test accuracy among the three adversarial attack algorithms, FGSM, I-FGSM, and MI-FGSM, as shown in
Figure 19,
Figure 20 and
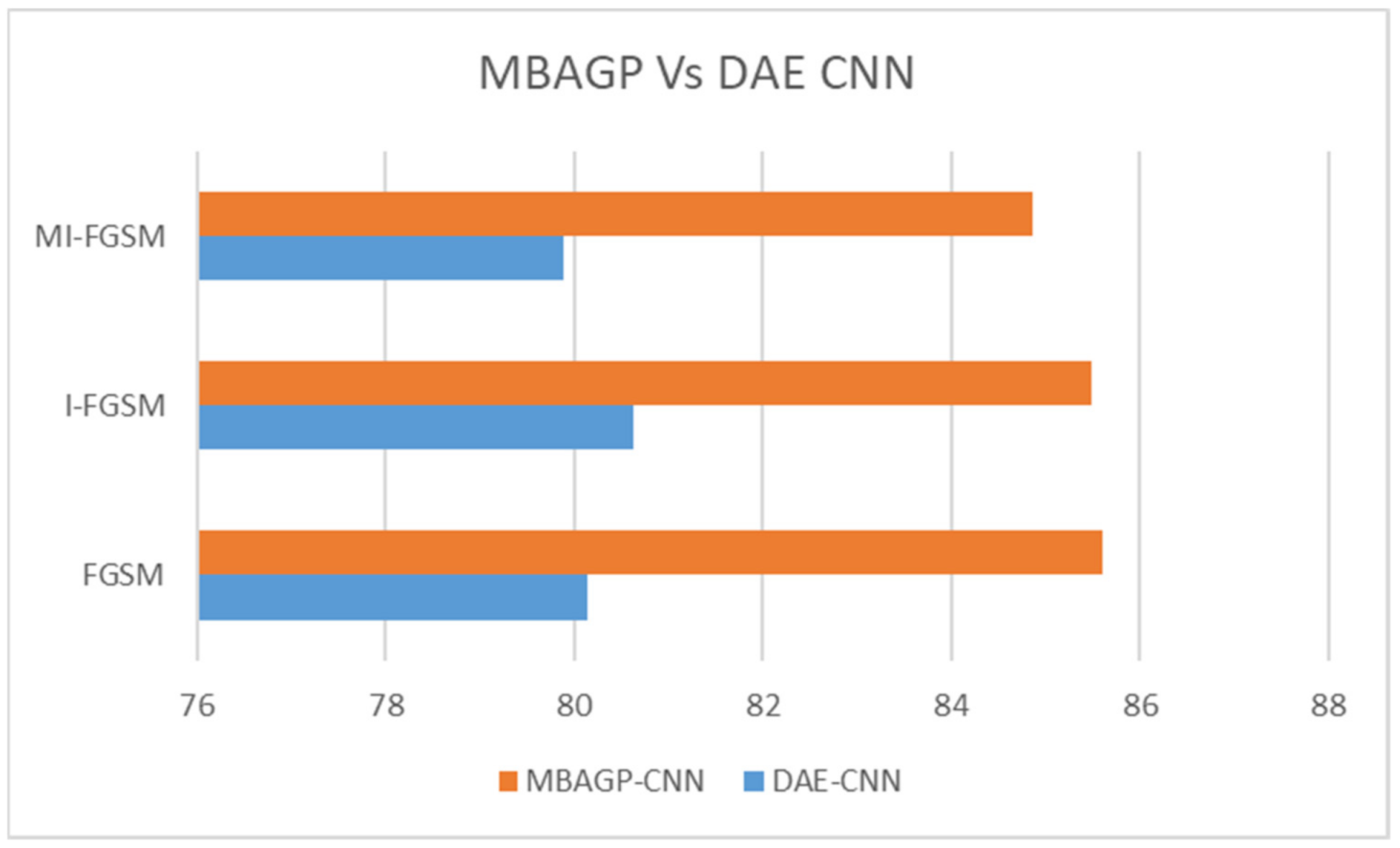
Figure 21, respectively. In comparison, as shown in
Figure 22, the MBAGP-CNN model exhibited good and competitive performance results when compared to the DAE-CNN defense model, to perform a successful adversarial text-based security verification.
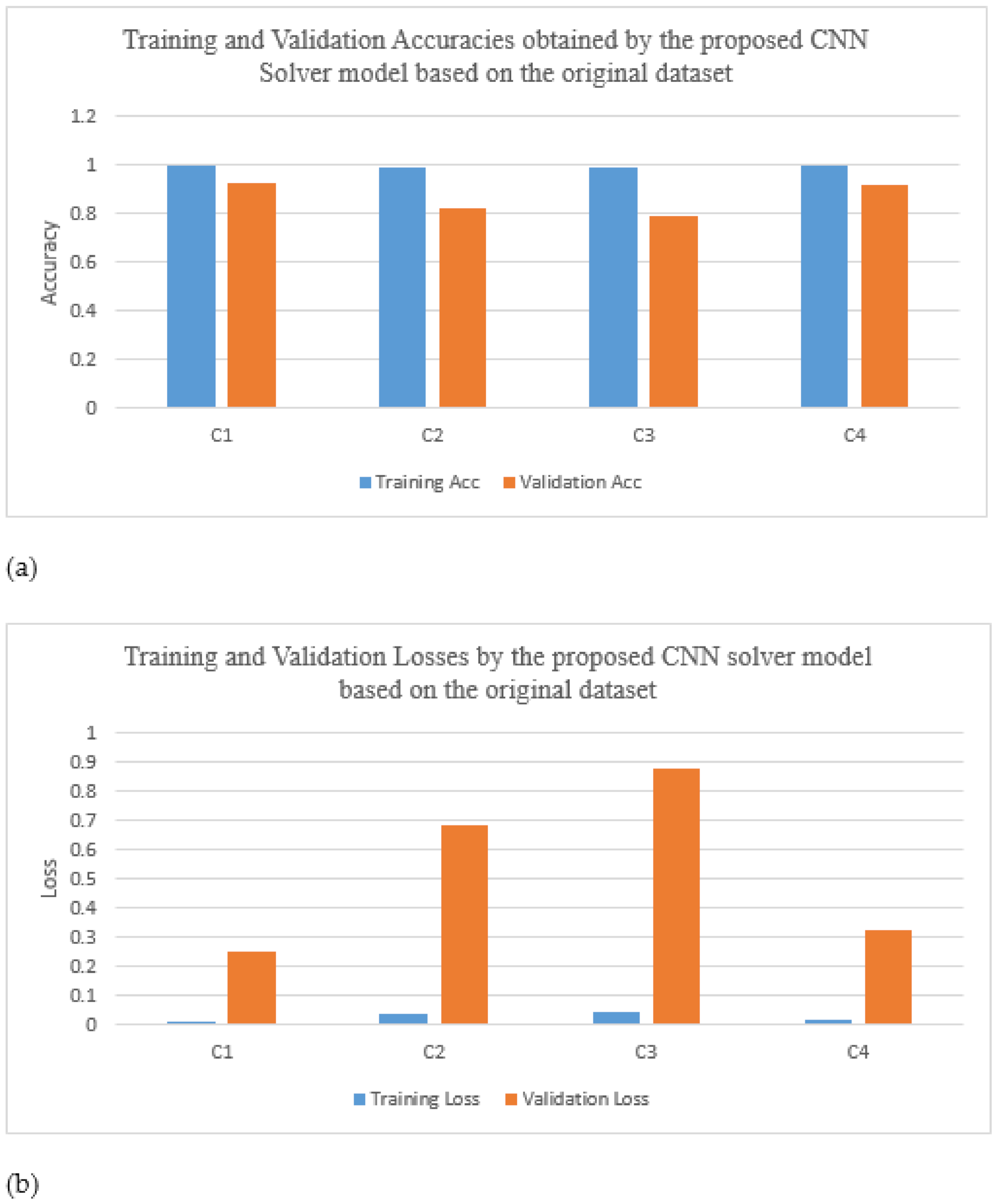
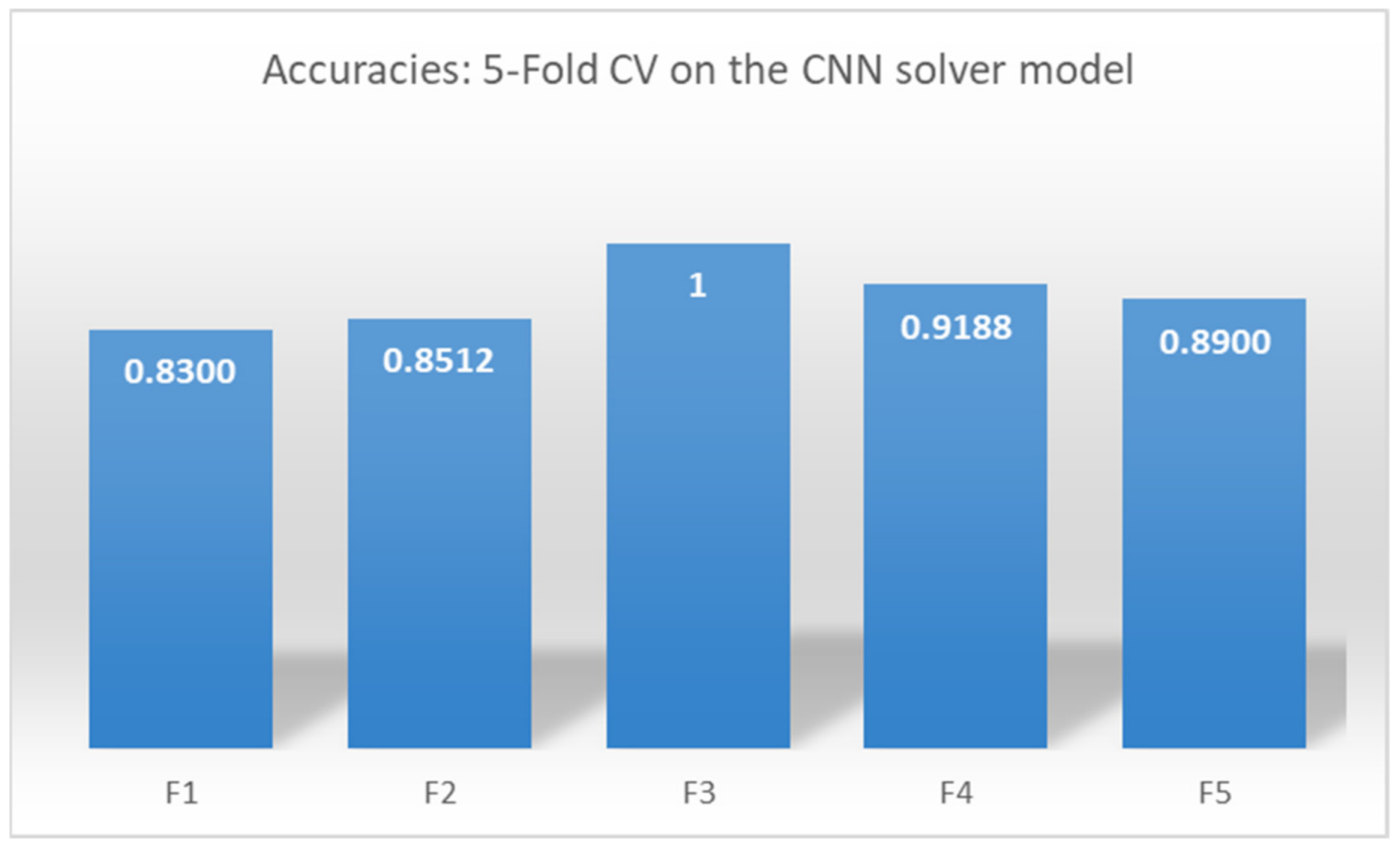
The study further performed five-fold cross-validation on the proposed MBAGP-CNN model based on the FGSM, I-FGSM, and MI-FGSM attacks.
Figure 23 presents the accuracies obtained at the various K-folds. Based on the FGSM attack, the highest accuracy was detected at fold 3, which was 0.8858, as shown in
Figure 23. The MBAGP-CNN defense model therefore achieved a mean accuracy of 84.30%, and a standard deviation of 0.0251 based on the FGSM attack. Based on the I-FGSM attack, the highest accuracy was detected at fold 2, which was 0.8531, as shown in
Figure 23. The MBAGP-CNN defense model, therefore, achieved a mean accuracy of 83.44%, and a standard deviation of 0.0161 based on the I-FGSM attack. Based on the MI-FGSM attack, the highest accuracy was detected at fold 4, which was 0.8588, as shown in
Figure 23. The MBAGP-CNN defense model therefore achieved a mean accuracy of 82.20% and a standard deviation of 0.0260 based on the MI-FGSM attack.
The implications of this current study are:
With observations on websites, it seems that text-based CAPTCHAs will remain in the system for a very longer time, and for that matter, this current study suggests that cyber security researchers take advantage of adversarial attacks to strengthen the security of their generated text-based CAPTCHAs. This can be achieved by implementing robust attack algorithms to strengthen the generated CAPTCHAs to withstand automatic malicious attacks in order to secure IoT devices and end users’ privacy.
Implementing robust adversarial text-based attack algorithms can assist in minimizing the activities of automatic malicious attacks.
Defending against adversarial CAPTCHA attacks is tedious and usually involves a lot of effort, which frustrates hackers. It may also remain and will continue to be an active research area.
It is necessary to perform vulnerability assessments on the generated adversarial CAPTCHAs before they are used on websites for public use, for example, this study recommends taking advantage of the MBAGP technique.
Among the three gradient-based adversarial attacks, MI-FSGM showed highly defensive security measures against the CNN solver models, relative to this study, as compared to FSGM and I-FSGM.
If cybersecurity practitioners want to perform vulnerability assessments on adversarial CAPTCHAs, using transfer learning approaches without building their own CNN models, then they should consider Xception and DenseNet architectures.
In the context of IoT risk assessment, the proposed AI framework technology can be used to perform adversarial text-based CAPTCHA security verification using deep learning. This will help minimize malicious attacks through effective CAPTCHA generating algorithms to secure smartphones and smart TVs, which are connected to websites from spamming.
In addition, the proposed technology will assist in the evaluation of ethical risks based on data protection and privacy on IoT devices, especially smartphones.
Another dimension of the proposed technology can be seen in more native scenarios and sensors, which are connected to web application programming interfaces (APIs). Home security cameras are accessible from mobile IoT devices, such as smartphones. A user authentication system comprising of adversarial images can be generated to verify users who use their smartphones to access home security cameras.
6. Conclusions
Text-based CAPTCHA is still widely used and will remain, for a longer time, as a security mechanism to differentiate machine bots from humans. In this current work, we proposed a technique to generate adversarial text-based CAPTCHAs using the Fast Gradient Sign Method (FGSM), Iterative Fast Gradient Sign Method (I-FGSM), and the Momentum Iterative Fast Gradient Sign Method (MI-FGSM) algorithms. We proposed a more robust and computation-efficient deep learning defense model—a Convolutional Neural Network with a Mixed Batch Adversarial Generation Process (MBAGP-CNN) to perform adversarial text-based CAPTCHA security vulnerability verification.
Based on the experiment’s results, the proposed CNN solver model achieved a competitive result to solve the original text-based CAPTCHAs with about 90% accuracy based on the test set. The adversarial attacks to the proposed CNN solver model were successful at reducing ~60% of the test accuracy, with an epsilon of 0.25, iteration of 10, and a decay factor of 1.0. Therefore, this study initially proposed a fundamental defense vulnerability verification model based on the Convolutional Neural Network (CNN) with a Denoising Autoencoder (DAE-CNN). The number of dimensions occupied by the input data were reduced by the hidden layer representation of the DAE neural network and, hence, increased recognition accuracy of the CNN classifier against adversarial text-based CAPTCHA attacks. The experiment results showed that the proposed DAE-CNN model was successful at reducing ~10% of the test accuracy among the three gradient-based adversarial attacks. However, this study observed that the DAE-CNN model was less robust and less computational, and could be improved to exhibit good performance. Therefore, this study proposed a more robust and more computation-efficient defense model by introducing the Mixed Batch Adversarial Generation Process (MBAGP). The novel proposed MBAGP-CNN model attempted to break the transferability attack, and mitigate the problem of catastrophic forgetting in the context of an adversarial attack defense. Ideally, the MBAGP-CNN model generated image batches of both the original and the adversarial CAPTCHA images by reconstructing the training process of the DAE-CNN model, which improved the model’s capability to generalized denoising on both original and adversarial images to defend against adversarial text-based CAPTCHAs. Competitive experiment results showed that the proposed defense and robust MBAGP-CNN model was successful at reducing ~5% of the test accuracy among the three gradient-based adversarial attacks. This study further introduced the learning rate finder algorithm to find optimal learning rates in conjunction with the cyclical learning rate policy to accelerate the convergence rate of the defense models to improve accuracy.
This study further performed K-fold cross-validation to evaluate the robustness of the proposed MBAGP-CNN model. The proposed defense model then achieved mean accuracies of 84.30%, 83.44%, and 82.20% based on the FGSM, I-FGSM, and the MI-FGSM attack datasets, respectively. The study emphasizes that the result figures are the key contribution outcomes of the experiments conducted in this work. Adversarial text-based CAPTCHA attacks were shown to withstand against automatic malicious attackers or intruders. However, there is still a security risk after performing vulnerability assessment, as our proposed robust defense model obtained accuracy more than 80% among the three adversarial attack algorithms based on five-fold cross validation. Therefore, there is still a need to improve upon adversarial text-based CAPTCHA-generating algorithms to defend against automatic malicious attacks. This current work is useful to the cyber security community and in performing IoT risk assessment. In future works, we can attempt other adversarial attack algorithms, see their results, and propose a defense model to perform security vulnerability assessment.


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}