
Automatic Categorization of LGBT User Profiles on Twitter with Machine Learning


Abstract
:1. Introduction
- This paper offers a codebook to manually categorize LGBT users.
- The prediction approach is an important step toward categorizing LGBT users by developing a machine learning classifier.
- Methodologically, our approach can be reused in predicting not only LGBT users but also other minorities.
- While this research uses Twitter data, the proposed approach and features can be adopted for other possible social media platforms.
- The approach of this paper can be used to identify and filter out adult content.
- This research can be used by researchers to understand social media activities and concerns (e.g., health issues) of LGBT individuals.
- This study can also be utilized by researchers to explore the social media strategies of LGBT organizations and identify best practices to promote social good for the LGBT population.
2. Materials and Methods
2.1. Data Acquisition
2.2. Data Annotation
- Q1: Is the account useable for this research? This yes/no question excluded the following accounts:
- Non-U.S. accounts where their bio information does not show a location in the U.S.;
- Non-English accounts that posted mostly non-English tweets;
- Inactive accounts that have not been active since 2017;
- Private and suspended accounts;
- Automated accounts that posted an unusual number of tweets, retweets, and likes, had a very low rate of followers to followings, and did not have an image. We also used Botometer (https://botometer.osome.iu.edu/ (accessed on 15 June 2019)) to identify automated accounts [61].
- Q2: What is the category of the account? To address this question, coders used the following definition to assign one of the categories:
- Individual accounts are controlled by a single person.
- Sex Worker/Porn accounts are involved in the production of professional pornography both on and off screen, those engaged in prostitution and escort services, erotic dancers, fetish models, and amateur individuals using webcam sites, amateur porn sites, or pay-gated platforms to profit off of self-made content, and accounts that retweet primarily pornographic material and/or post their own nude photographs or moving images.
- Organization accounts are managed by a group or an organization representing more than one person.
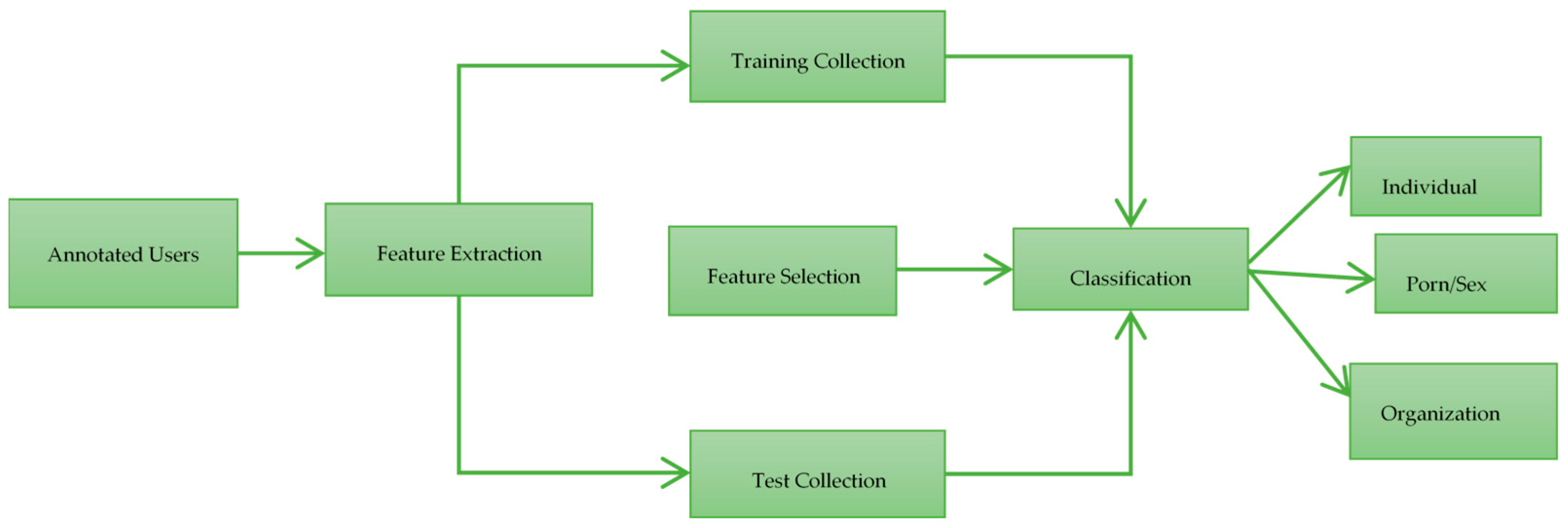
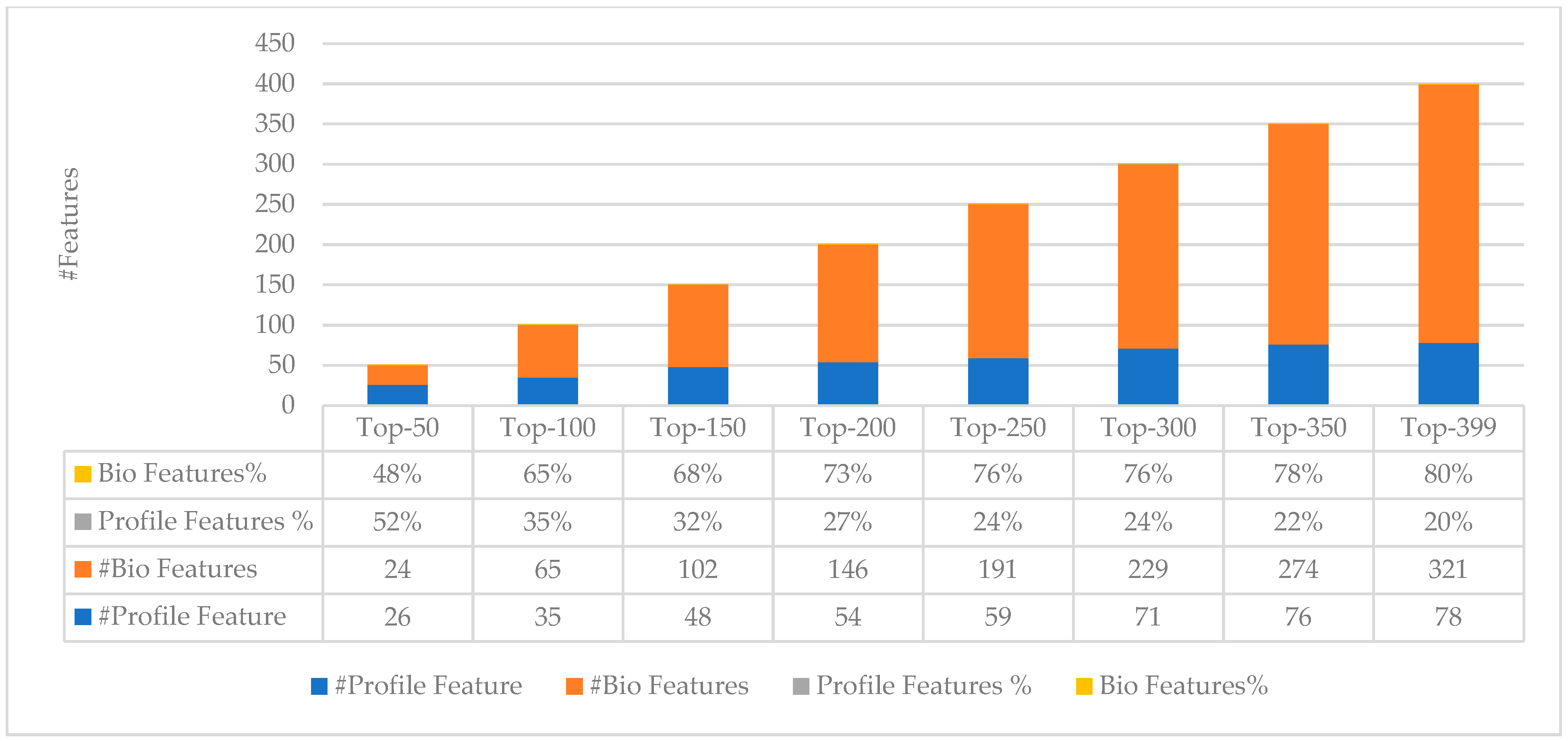
2.3. Classification
- 1288 bio features
- ○
- Frequency of each word in bio
- ○
- The number of words in bio
- 81 profile features
- ○
- The age of each Twitter account (account’s age)
- ○
- Total number of tweets (#tweets)
- ○
- The number of tweets per year (#tweets/year)
- ○
- The number of likes per year (#likes/year)
- ○
- The number of followers (#followers)
- ○
- The number of followings (#followings)
- ○
- The rate of followers to following (#followers/#followers)
- ○
- Frequency of letters (A–Z) and numbers (0–9) in the username
- ○
- Frequency of letters (A–Z) and numbers (0–9) in the screen name
- ○
- The username’s length
- ○
- The screen name’s length
2.4. Evaluation
| Predicted | |||
| Category 1 | Category 2 | ||
| Actual | Category 1 | True Positive (TP) | False Positive (FP) |
| Category 2 | False Negative (FN) | True Negative (TN) | |
2.5. Statistical Analysis
3. Results
- There was no significant difference between SWP and Org accounts across three features, including #followers/followings, #followers, and #followings. Compared to Org accounts, SWP accounts had a higher #likes/year, #tweets/year, and #tweets and used nsfw (not safe for work) and pornographic words in their bio more. The value of the rest of the features was higher for Org accounts than SWP ones. In sum, we found three NS, five SWP > Org, and twelve SWP < Org comparisons.
- There was no significant difference between Ind and Org accounts across two features, including #followings and nsfw. Compared to Org accounts, Ind accounts had a higher #likes/year, #tweets/year, and #tweets. The value of the rest of the features was higher for Org accounts than Ind ones. In total, this research identified two NS, three Ind > Org, and fifteen Ind < Org comparisons.
- There was no significant difference between Ind and SPW accounts across nine features, including #likes/year, #tweets/year, and the length of the username, and using the words bisexual, transgender, community, organization, and allies in their bio. Compared to SPW accounts, Ind accounts had a higher account age, #tweets, and used the acronym LGBT more. The value of the rest of features was higher for SPW accounts than Ind ones. In total, this research identified nine NS, three Ind > SWP, and eight Ind < SWP comparisons.
- There is a significant difference between the three categories based on the following features: the account’s age; the number of tweets; using porn, LGBT, and men words in the bio; using G in screen name; and the number of words in the bio.
- The effect size analysis illustrates that the 46 significant differences were not trivial, including 6 very small, 18 small, 14 medium, 6 large, and 2 very large effect sizes (Table 5). The maximum difference was between individual and organization accounts with 18 (90%) significant differences, and the minimum difference was between the individual and sexual worker/porn accounts with 11 (55%) significant differences out of 20 comparisons. The effect size analysis also confirmed that the magnitude of significant differences is considerable.
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gallup. LGBT Identification Rises to 5.6% in Latest, U.S. Estimate. 2021. Available online: https://news.gallup.com/poll/329708/lgbt-identification-rises-latest-estimate.aspx (accessed on 1 April 2021).
- Gonzales, G.; Przedworski, J.; Henning-Smith, C. Comparison of health and health risk factors between lesbian, gay, and bi-sexual adults and heterosexual adults in the United States: Results from the National Health Interview Survey. JAMA Intern. Med. 2016, 176, 1344–1351. [Google Scholar] [CrossRef] [Green Version]
- Byron, P.; Rasmussen, S.; Wright, T.D.; Lobo, R.; Robinson, K.H.; Paradise, B. ‘You learn from each other’: LGBTIQ Young People’s Mental Health Help-seeking and the RAD Australia Online Directory. Available online: https://researchdirect.westernsydney.edu.au/islandora/object/uws:38815 (accessed on 1 April 2021).
- Seidenberg, A.B.; Jo, C.L.; Ribisl, K.M.; Lee, J.G.L.; Butchting, F.O.; Kim, Y.; Emery, S.L. A National Study of Social Media, Television, Radio, and Internet Usage of Adults by Sexual Orientation and Smoking Status: Implications for Campaign Design. Int. J. Environ. Res. Public Health 2017, 14, 450. [Google Scholar] [CrossRef] [Green Version]
- Pew Research Center. A Survey of LGBT Americans. In: Pew Research Center’s Social & Demographic Trends Project [Inter-net]. 2013. Available online: https://www.pewresearch.org/social-trends/2013/06/13/a-survey-of-lgbt-americans/ (accessed on 15 April 2021).
- Byron, P.; Albury, K.; Evers, C. It would be weird to have that on Facebook: Young people’s use of social media and the risk of sharing sexual health information. Reprod. Health Matters 2013, 21, 35–44. [Google Scholar] [CrossRef]
- Karami, A.; Lundy, M.; Webb, F.; Dwivedi, Y.K. Twitter and Research: A Systematic Literature Review Through Text Mining. IEEE Access 2020, 8, 67698–67717. [Google Scholar] [CrossRef]
- Karami, A.; Kadari, R.; Panati, L.; Nooli, S.; Bheemreddy, H.; Bozorgi, P. Analysis of Geotagging Behavior: Do Geotagged Users Represent the Twitter Population? ISPRS Int. J. Geo Inf. 2021, 10, 373. [Google Scholar] [CrossRef]
- Karami, A.; Dahl, A.; Shaw, G.; Valappil, S.; Turner-McGrievy, G.; Kharrazi, H.; Bozorgi, P. Analysis of Social Media Discussions on (#)Diet by Blue, Red, and Swing States in the U.S. Healthcare 2021, 9, 518. [Google Scholar] [CrossRef]
- Karami, A.; Anderson, M. Social media and COVID-19, Characterizing anti-quarantine comments on Twitter. In Proceedings of the Association for Information Science and Technology, online, 22 October–1 November 2020; Volume 57, p. e349. [Google Scholar]
- Karami, A.; Dahl, A.A.; Turner-McGrievy, G.; Kharrazi, H.; Shaw, G., Jr. Characterizing diabetes, diet, exercise, and obesity com-ments on Twitter. Int. J. Inf. Manag. 2018, 38, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Money, V.; Karami, A.; Turner-McGrievy, B.; Kharrazi, H. Seasonal characterization of diet discussions on Reddit. In Proceedings of the Proceedings of the Association for Information Science and Technology, online, 22 October–1 November 2020; Volume 57, p. 320. [Google Scholar]
- Kordzadeh, N. Exploring the Use of Twitter by Leading Medical Centers in the United States. In Proceedings of the 52nd Hawaii International Conference on System Sciences, Grand Wailea, HI, USA, 8–11 January 2019. [Google Scholar]
- Li, Z.; Qiao, S.; Jiang, Y.; Li, X. Building a Social Media-Based HIV Risk Behavior Index to Inform the Prediction of HIV New Diagnosis: A Feasibility Study. AIDS 2021, 35, S91–S99. [Google Scholar] [CrossRef]
- Karami, A.; Elkouri, A. Political Popularity Analysis in Social Media. In Proceedings of the International Conference on Information (iConference), Washington, DC, USA, 31 March–3 April 2019. [Google Scholar]
- Karami, A.; Bennett, L.S.; He, X. Mining public opinion about economic issues: Twitter and the us presidential election. Int. J. Strateg. Decis. Sci. 2018, 9, 18–28. [Google Scholar] [CrossRef] [Green Version]
- Najafabadi, M.M.; Domanski, R.J. Hacktivism and distributed hashtag spoiling on Twitter: Tales of the #IranTalks. First Monday 2018, 23. [Google Scholar] [CrossRef]
- Karami, A.; Spinel, M.; White, C.; Ford, K.; Swan, S. A Systematic Literature Review of Sexual Harassment Studies with Text Mining. Sustainability 2021, 13, 6589. [Google Scholar] [CrossRef]
- Karami, A.; Shah, V.; Vaezi, R.; Bansal, A. Twitter speaks: A case of national disaster situational awareness. J. Inf. Sci. 2019, 46, 313–324. [Google Scholar] [CrossRef] [Green Version]
- Turner-McGrievy, G.; Karami, A.; Monroe, C.; Brandt, H.M. Dietary pattern recognition on Twitter: A case example of before, during, and after four natural disasters. Nat. Hazards 2020, 103, 1035–1049. [Google Scholar] [CrossRef]
- Martín, Y.; Cutter, S.L.; Li, Z. Bridging twitter and survey data for evacuation assessment of Hurricane Matthew and Hurri-cane Irma. Nat. Hazards Rev. 2020, 21, 04020003. [Google Scholar] [CrossRef]
- Dzurick, A. Lesbian, Gay, Bisexual, and Transgender Americans at Risk: Problems and Solutions; Praeger: Santa Barbara, CA, USA, 2018; Social media, iPhones, iPads, and identity: Media impact on the coming-out process for LGBT youths. [Google Scholar]
- Haimson, O.L.; Veinot, T.C. Coming Out to Doctors, Coming Out to “Everyone”: Understanding the Average Sequence of Transgender Identity Disclosures Using Social Media Data. Transgender Health 2020, 5, 158–165. [Google Scholar] [CrossRef]
- Khatua, A.; Cambria, E.; Ghosh, K.; Chaki, N.; Khatua, A. Tweeting in support of LGBT? A deep learning approach. In Proceedings of the ACM India Joint International Conference on Data Science and Management of Data, Kolkata, India, 3–5 January 2019; pp. 342–345. [Google Scholar]
- Selkie, E.; Adkins, V.; Masters, E.; Bajpai, A.; Shumer, D. Transgender Adolescents’ Uses of Social Media for Social Support. J. Adolesc. Health 2020, 66, 275–280. [Google Scholar] [CrossRef]
- Blackwell, L.; Hardy, J.; Ammari, T.; Veinot, T.; Lampe, C.; Schoenebeck, S. LGBT parents and social media: Advocacy, privacy, and disclosure during shifting social movements. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 7–12 May 2016; pp. 610–622. [Google Scholar]
- Guillory, J.; Wiant, K.F.; Farrelly, M.; Fiacco, L.; Alam, I.; Hoffman, L.; Crankshaw, E.; Delahanty, J.; Alexander, T.N. Recruiting hard-to-reach populations for survey re-search: Using Facebook and Instagram advertisements and in-person intercept in LGBT bars and nightclubs to recruit LGBT young adults. J. Med. Internet Res. 2018, 20, e197. [Google Scholar] [CrossRef]
- Webb, F.; Karami, A.; Kitzie, V.L. Characterizing Diseases and Disorders in Gay Users’ Tweets. In Proceedings of the Southern Association for Information Systems (SAIS), Atlanta, GA, USA, 23 March 2018. [Google Scholar]
- Karami, A.; Webb, F.; Kitzie, V.L. Characterizing transgender health issues in Twitter. In Proceedings of the Association for Information Science and Technology, Vancouver, BC, Canada, 4–9 November 2018; Volume 55, pp. 207–215. [Google Scholar]
- Karami, A.; Webb, F. Analyzing health tweets of LGB and transgender individuals. In Proceedings of the Association for Information Science and Technology, online, 22 October–1 November 2020; Volume 57, p. 264. [Google Scholar]
- Carrasco, M.; Kerne, A. Queer visibility: Supporting LGBT+ selective visibility on social media. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; pp. 1–12. [Google Scholar]
- Escobar-Viera, C.G.; Whitfield, D.L.; Wessel, C.B.; Shensa, A.; E Sidani, J.; Brown, A.L.; Chandler, C.J.; Hoffman, B.L.; Marshal, M.P.; A Primack, B. For better or for worse? A systematic re-view of the evidence on social media use and depression among lesbian, gay, and bisexual minorities. JMIR Ment. Health 2018, 5, e10496. [Google Scholar] [CrossRef] [Green Version]
- Han, X.; Han, W.; Qu, J.; Li, B.; Zhu, Q. What happens online stays online?—Social media dependency, online support behavior and offline effects for LGBT. Comput. Hum. Behav. 2019, 93, 91–98. [Google Scholar] [CrossRef]
- Hswen, Y.; Sewalk, K.C.; Alsentzer, E.; Tuli, G.; Brownstein, J.S.; Hawkins, J.B. Investigating inequities in hospital care among lesbian, gay, bisexual, and transgender (LGBT) individuals using social media. Soc. Sci. Med. 2018, 215, 92–97. [Google Scholar] [CrossRef]
- Haimson, O. Mapping gender transition sentiment patterns via social media data: Toward decreasing transgender mental health disparities. J. Am. Med. Inform. Assoc. 2019, 26, 749–758. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krueger, E.A.; Young, S.D. Twitter: A Novel Tool for Studying the Health and Social Needs of Transgender Communities. JMIR Ment. Health 2015, 2, e16. [Google Scholar] [CrossRef] [Green Version]
- Gold, J.; Pedrana, A.; Stoove, M.; Chang, S.; Howard, S.; Asselin, J.; Ilic, O.; Batrouney, C.; Hellard, M.E. Developing Health Promotion Interventions on Social Networking Sites: Recommendations from The FaceSpace Project. J. Med. Internet Res. 2012, 14, e30. [Google Scholar] [CrossRef] [PubMed]
- Pedrana, A.; Hellard, M.; Gold, J.; Ata, N.; Chang, S.; Howard, S.; Asselin, J.; Ilic, O.; Batrouney, C.; Stoove, M.; et al. Queer as F**k: Reaching and Engaging Gay Men in Sexual Health Promotion through Social Networking Sites. J. Med. Internet Res. 2013, 15, e25. [Google Scholar] [CrossRef] [PubMed]
- McDaid, L.M.; Lorimer, K. P5.044 A Proactive Approach to Online Chlamydia Screening: Qualitative Exploration of Young Men’s Perspectives of the Barriers and Facilitators. Sex. Transm. Infect. 2013, 89, A348. [Google Scholar] [CrossRef] [Green Version]
- Wohlfeiler, D.; Hecht, J.; Volk, J.; Raymond, H.F.; Kennedy, T.; McFarland, W. How can we improve online HIV and STD preven-tion for men who have sex with men? Perspectives of hook-up website owners, website users, and HIV/STD directors. AIDS Behav. 2013, 17, 3024–3033. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Young, S.D.; Harrell, L.; Jaganath, D.; Cohen, A.C.; Shoptaw, S. Feasibility of recruiting peer educators for an online social networking-based health intervention. Health Educ. J. 2013, 72, 276–282. [Google Scholar] [CrossRef] [Green Version]
- Young, S.D.; Holloway, I.; Jaganath, D.; Rice, E.; Westmoreland, D.; Coates, T. Project HOPE: Online Social Network Changes in an HIV Prevention Randomized Controlled Trial for African American and Latino Men Who Have Sex With Men. Am. J. Public Health 2014, 104, 1707–1712. [Google Scholar] [CrossRef]
- Mustanski, B.; Greene, G.J.; Ryan, D.; Whitton, S.W. Feasibility, Acceptability, and Initial Efficacy of an Online Sexual Health Promotion Program for LGBT Youth: The Queer Sex Ed Intervention. J. Sex Res. 2014, 52, 220–230. [Google Scholar] [CrossRef]
- Gabarron, E.; Wynn, R. Use of social media for sexual health promotion: A scoping review. Glob. Health Action 2016, 9, 32193. [Google Scholar] [CrossRef]
- Martinez, O.; Wu, E.; Shultz, A.Z.; Capote, J.; Rios, J.L.; Sandfort, T.; Manusov, J.; Ovejero, H.; Carballo-Dieguez, A.; Baray, S.C.; et al. Still a Hard-to-Reach Population? Using Social Media to Recruit Latino Gay Couples for an HIV Intervention Adaptation Study. J. Med. Internet Res. 2014, 16, e113. [Google Scholar] [CrossRef] [PubMed]
- Elliot, E.; Rossi, M.; McCormack, S.; McOwan, A. Identifying undiagnosed HIV in men who have sex with men (MSM) by offering HIV home sampling via online gay social media: A service evaluation. Sex. Transm. Infect. 2016, 92, 470–473. [Google Scholar] [CrossRef]
- Rhodes, S.D.; McCoy, T.P.; Tanner, A.E.; Stowers, J.; Bachmann, L.H.; Nguyen, A.L.; Ross, M. Using Social Media to Increase HIV Testing Among Gay and Bisexual Men, Other Men Who Have Sex With Men, and Transgender Persons: Outcomes From a Randomized Community Trial. Clin. Infect. Dis. 2016, 62, 1450–1453. [Google Scholar] [CrossRef] [PubMed]
- Reiter, P.L.; Katz, M.L.; A Bauermeister, J.; Shoben, A.B.; Paskett, E.D.; McRee, A.-L. Recruiting Young Gay and Bisexual Men for a Human Papillomavirus Vaccination Intervention through Social Media: The Effects of Advertisement Content. JMIR Public Health Surveill. 2017, 3, e33. [Google Scholar] [CrossRef]
- Cao, B.; Liu, C.; Durvasula, M.; Tang, W.; Pan, S.; Saffer, A.J.; Wei, C.; Tucker, J.D.; Jiang, J.; Zhao, H. Social Media Engagement and HIV Testing Among Men Who Have Sex With Men in China: A Nationwide Cross-Sectional Survey. J. Med. Internet Res. 2017, 19, e251. [Google Scholar] [CrossRef] [Green Version]
- Patel, V.V.; Ginsburg, Z.; A Golub, S.; Horvath, K.J.; Rios, N.; Mayer, K.H.; Kim, R.S.; Arnsten, J.H. Empowering With PrEP (E-PrEP), a Peer-Led Social Media–Based Intervention to Facilitate HIV Preexposure Prophylaxis Adoption among Young Black and Latinx Gay and Bisexual Men: Protocol for a Cluster Randomized Controlled Trial. JMIR Res. Protoc. 2018, 7, e11375. [Google Scholar] [CrossRef] [PubMed]
- Qureshi, R.; Zha, P.; Kim, S.; Hindin, P.; Naqvi, Z.; Holly, C.; Dubbs, W.; Ritch, W. Health Care Needs and Care Utilization Among Lesbian, Gay, Bisexual, and Transgender Populations in New Jersey. J. Homosex. 2018, 65, 167–180. [Google Scholar] [CrossRef]
- Tanner, A.E.; Song, E.Y.; Mann-Jackson, L.; Alonzo, J.; Schafer, K.; Ware, S.; Garcia, J.M.; Hall, E.A.; Bell, J.C.; Van Dam, C.N.; et al. Preliminary Impact of the weCare Social Media Intervention to Support Health for Young Men Who Have Sex with Men and Transgender Women with HIV. Aids Patient Care STDs 2018, 32, 450–458. [Google Scholar] [CrossRef] [Green Version]
- Card, K.G.; Lachowsky, N.; Hawkins, B.W.; Jollimore, J.; Baharuddin, F.; Hogg, R.S.; Willoughby, J.; Bauermeister, J.; Zlotorzynska, M.; Kite, J. Predictors of Facebook User Engagement with Health-Related Content for Gay, Bisexual, and Other Men Who Have Sex With Men: Content Analysis. JMIR Public Health Surveill. 2018, 4, e38. [Google Scholar] [CrossRef]
- Verrelli, S.; White, F.; Harvey, L.; Pulciani, M.R. Minority stress, social support, and the mental health of lesbian, gay, and bisexual Australians during the Australian Marriage Law Postal Survey. Aust. Psychol. 2019, 54, 336–346. [Google Scholar] [CrossRef]
- Kruger, S.; Hermann, B. Can an Online Service Predict Gender? On the State-of-the-Art in Gender Identification from Texts. In Proceedings of the 2019 IEEE/ACM 2nd International Workshop on Gender Equality in Software Engineering (GE), Montreal, QC, Canada, 27–29 May 2019. [Google Scholar]
- Rangel, F.; Rosso, P.; Montes-y-Gómez, M.; Potthast, M.; Stein, B. Overview of the 6th Author Profiling Task at Pan 2018, Multi-Modal Gender Identification in Twitter. Available online: http://personales.upv.es/prosso/resources/RangelEtAl_PAN18.pdf (accessed on 15 April 2021).
- Burger, J.D.; Henderson, J.; Kim, G.; Zarrella, G. Discriminating Gender on Twitter. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; pp. 1301–1309. [Google Scholar]
- Wang, Q.; Ma, S.; Zhang, C. Predicting users’ demographic characteristics in a Chinese social media network. Electron. Libr. 2017, 35, 758–769. [Google Scholar] [CrossRef]
- Schwartz, H.A.; Eichstaedt, J.C.; Kern, M.; Dziurzynski, L.; Ramones, S.M.; Agrawal, M.; Shah, A.; Kosinski, M.; Stillwell, D.; Seligman, M.E.P.; et al. Personality, Gender, and Age in the Language of Social Media: The Open-Vocabulary Approach. PLoS ONE 2013, 8, e73791. [Google Scholar] [CrossRef]
- Peersman, C.; Daelemans, W.; Van Vaerenbergh, L. Predicting age and gender in online social networks. In Proceedings of the 3rd International Workshop on Search and Mining User-Generated Contents, Glasgow, UK, 24–28 October 2011; pp. 37–44. [Google Scholar]
- Yang, K.-C.; Varol, O.; Hui, P.-M.; Menczer, F. Scalable and Generalizable Social Bot Detection through Data Selection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1096–1103. [Google Scholar]
- Kamath, C.N.; Bukhari, S.S.; Dengel, A. Comparative study between traditional machine learning and deep learning approach-es for text classification. In Proceedings of the ACM Symposium on Document Engineering, Halifax, NS, Canada, 28–31 August 2018; pp. 1–11. [Google Scholar]
- Wu, X.; Kumar, V.; Quinlan, J.R.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Liu, C.; Zhang, X.; Almpanidis, G. An up-to-date comparison of state-of-the-art classification algorithms. Expert Syst. Appl. 2017, 82, 128–150. [Google Scholar] [CrossRef]
- Fernández-Delgado, M.; Cernadas, E.; Barro, S.; Amorim, D. Do we need hundreds of classifiers to solve real world classification problems. J. Mach. Learn. Res. 2014, 15, 3133–3181. [Google Scholar]
- Pham, B.T.; Bui, D.T.; Prakash, I. Landslide Susceptibility Assessment Using Bagging Ensemble Based Alternating Decision Trees, Logistic Regression and J48 Decision Trees Methods: A Comparative Study. Geotech. Geol. Eng. 2017, 35, 2597–2611. [Google Scholar] [CrossRef]
- Chimieski, B.F.; Fagundes, R.D.R. Association and classification data mining algorithms comparison over medical datasets. J. Health Inform. 2013, 5, 44–51. [Google Scholar]
- Zhao, Y.; Zhang, Y. Comparison of decision tree methods for finding active objects. Adv. Space Res. 2008, 41, 1955–1959. [Google Scholar] [CrossRef] [Green Version]
- Bassem, B.; Zrigui, M. Gender Identification: A Comparative Study of Deep Learning Architectures. In Proceedings of the Advances in Intelligent Systems and Computing, Vellore, India, 6–8 December 2019. [Google Scholar]
- Sezerer, E.; Polatbilek, O.; Sevgili, Ö.; Tekir, S. Gender prediction from Tweets with convolutional neural networks: Notebook for PAN at CLEF 2018. In Proceedings of the 19th Working Notes of CLEF Conference and Labs of the Evaluation Forum, CLEF CEUR Workshop Proceedings, Avignon, France, 10–14 September 2018. [Google Scholar]
- Wei, F.; Qin, H.; Ye, S.; Zhao, H. Empirical Study of Deep Learning for Text Classification in Legal Document Review. In Proceedings of the 2018 IEEE International Conference on Big Data, Seattle, WA, USA, 10–13 December 2018; pp. 3317–3320. [Google Scholar]
- Karami, A.; Zhou, B. Online Review Spam Detection by New Linguistic Features. In Proceedings of the iConference, Irvine, CA, USA, 24–27 March 2015. [Google Scholar]
- Karami, A.; Zhou, L. Exploiting latent content based features for the detection of static SMS spams. Proc. Am. Soc. Inf. Sci. Technol. 2014, 51, 1–4. [Google Scholar] [CrossRef]
- Karami, A.; Swan, S.; Moraes, M.F. Space identification of sexual harassment reports with text mining. In Proceedings of the Association for Information Science and Technology, online, 22 October–1 November 2020; Volume 57, p. 265. [Google Scholar]
- Yang, Y.; Pedersen, J.O. A Comparative Study on Feature Selection in Text Categorization. In Proceedings of the Fourteenth International Conference on Machine Learning, San Francisco, CA, USA, 8–12 July 1997; pp. 412–420. [Google Scholar]
- Tukey, J.W. Comparing Individual Means in the Analysis of Variance. Biometrics 1949, 5, 99. [Google Scholar] [CrossRef]
- Benjamini, Y.; Hochberg, Y. Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing. J. R. Stat. Soc. Ser. B 1995, 57, 289–300. [Google Scholar] [CrossRef]
- Jafari, M.; Ansari-Pour, N. Why, When and How to Adjust Your P Values? Cell J. 2019, 20, 604–607. [Google Scholar] [PubMed]
- Sawilowsky, S.S.; Salkind, N. Journal of Modern Applied Statistical Methods. Encycl. Meas. Stat. 2013, 26. [Google Scholar] [CrossRef]
- Ollier-Malaterre, A.; Rothbard, N.P. How to Separate the Personal and Professional on Social Media. Harvard Business Re-view. Available online: https://hbr.org/2015/03/how-to-separate-the-personal-and-professional-on-social-media (accessed on 23 July 2021).
- Wood-Doughty, Z.; Mahajan, P.; Dredze, M. Johns Hopkins or johnny-hopkins: Classifying Individuals versus Organizations on Twitter. In Proceedings of the Second Workshop on Computational Modeling of People’s Opinions, Personality, and Emotions in Social Media, New Orleans, LA, USA, 6 June 2018; pp. 56–61. [Google Scholar] [CrossRef]
- Zhao, W. Research on the deep learning of the small sample data based on transfer learning. In Proceedings of the AIP Conference Proceedings, Bydgoszcz, Poland, 9–11 May 2017; p. 020018. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Term | Definition |
|---|---|
| Account’s Age | The length of time that a Twitter account has been created. |
| Bio | A short summary (up to 160 characters) about a user in their profile. |
| Like (Favorite) | Showing appreciation of a tweet by clicking on the like tab. |
| Followers | Twitter accounts that follow updates of a Twitter account. |
| Followings | Twitter accounts that are followed by a Twitter account. |
| Screen Name | The name displayed in the profile to show a personal identifier. |
| Tweet | A status update of a user containing up to 280 characters. |
| Username | The name to help identify a user using @, such as @TheEllenShow. |
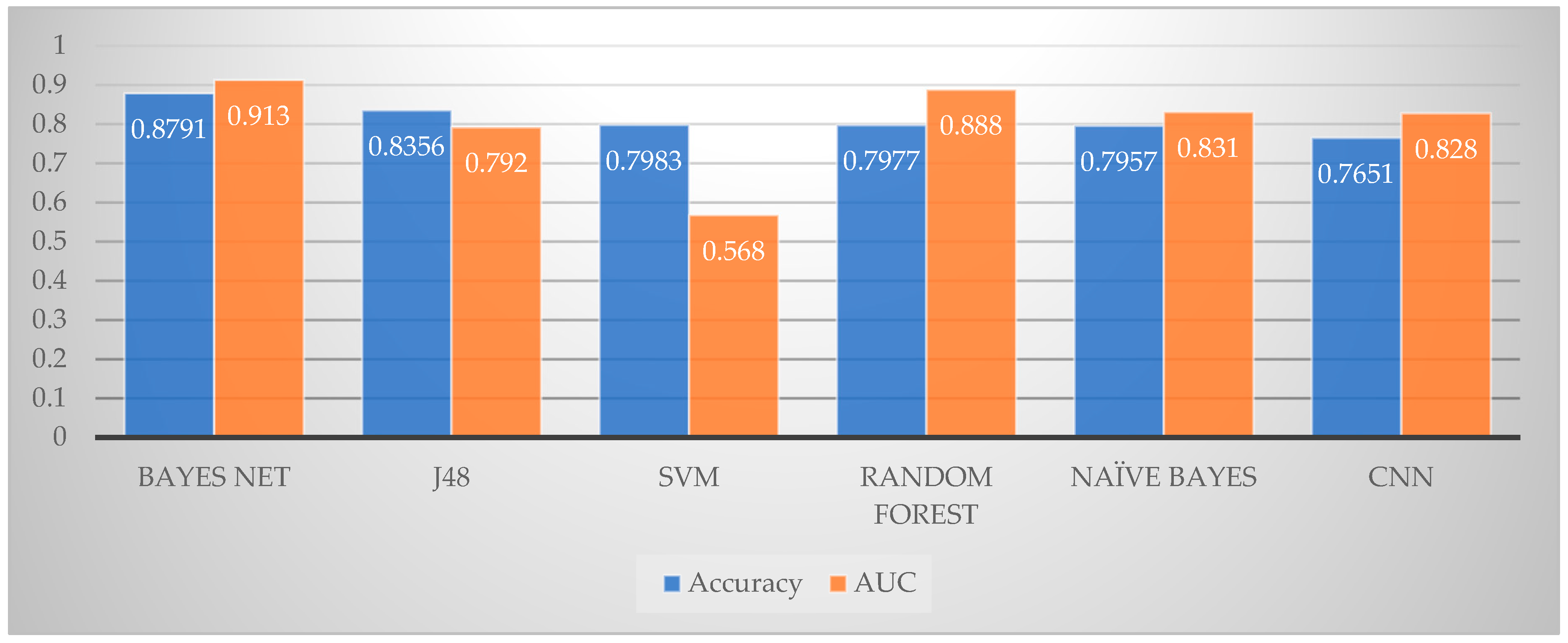
| Model | #Features | Acc | AUC | Precision | Recall |
|---|---|---|---|---|---|
| Profile | 81 | 0.8089 | 0.811 | 0.790 | 0.809 |
| Bio | 1288 | 0.8596 | 0.874 | 0.851 | 0.860 |
| Profile and Bio | 1369 | 0.8791 | 0.913 | 0.873 | 0.879 |
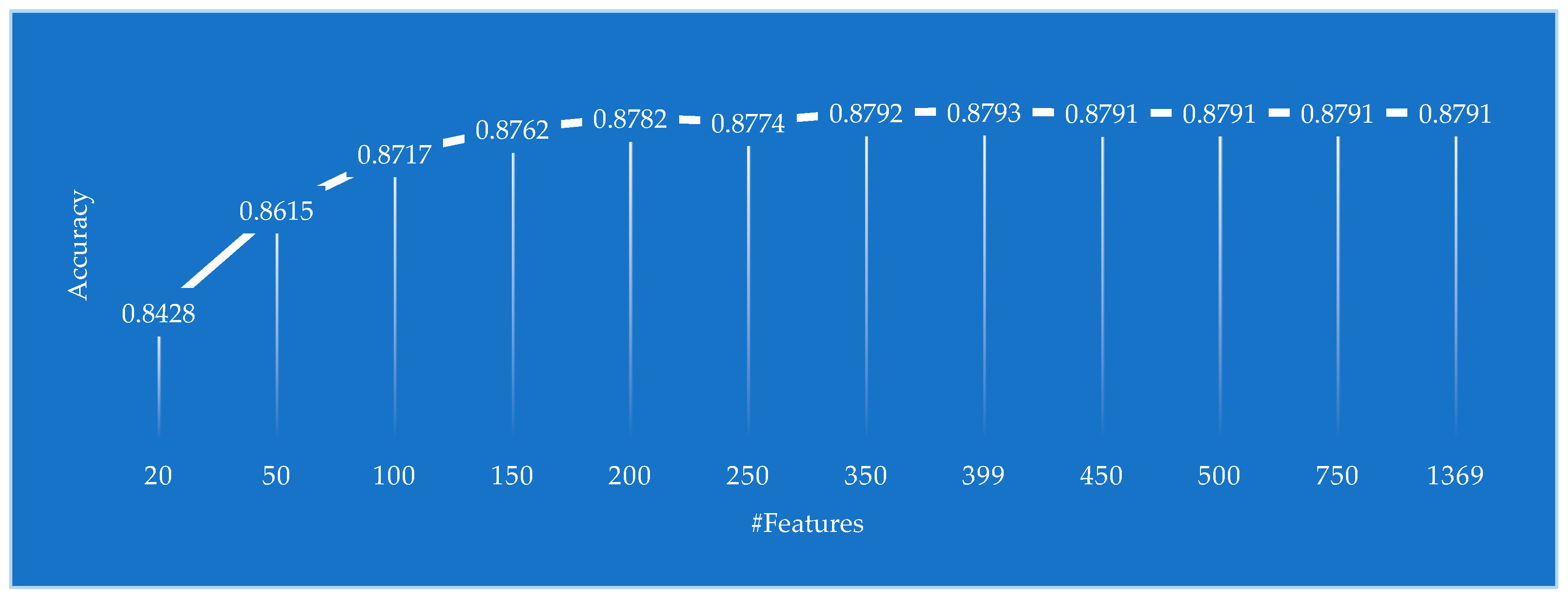
| Profile and Bio | 399 | 0.8793 | 0.913 | 0.873 | 0.879 |
| Metric | Min | Max | Mean | SD | CV |
|---|---|---|---|---|---|
| Accuracy | 0.8750 | 0.8824 | 0.8793 | 0.003 | 0.004 |
| AUC | 0.905 | 0.922 | 0.913 | 0.006 | 0.007 |
| Precision | 0.869 | 0.876 | 0.873 | 0.003 | 0.004 |
| Recall | 0.875 | 0.882 | 0.879 | 0.003 | 0.004 |
| Feature | Category | ANOVA + Tukey Multiple Comparison | ||
|---|---|---|---|---|
| SWP vs. Org | Ind vs. Org | Ind vs. SWP | ||
| #Likes/Year | Profile | * SWP > Org | * Ind > Org | NS |
| Bisexual | Bio | * SWP < Org | * Ind < Org | NS |
| Transgender | Bio | * SWP < Org | * Ind < Org | NS |
| Community | Bio | * SWP < Org | * Ind < Org | NS |
| #Followers/#Followings | Profile | NS | * Ind < Org | * Ind < SWP |
| Nsfw | Bio | * SWP > Org | NS | * Ind < SWP |
| Account’s Age | Profile | * SWP < Org | * Ind < Org | * Ind > SWP |
| #Tweets/Year | Profile | * SWP > Org | * Ind > Org | NS |
| #Tweets | Profile | * SWP > Org | * Ind > Org | * Ind > SWP |
| Porn | Bio | * SWP > Org | * Ind < Org | * Ind < SWP |
| Letter G in Screen Name | Profile | * SWP < Org | * Ind < Org | * Ind < SWP |
| Organization | Bio | * SWP < Org | * Ind < Org | NS |
| #Followers | Profile | NS | * Ind < Org | * Ind < SWP |
| LGBT | Bio | * SWP < Org | * Ind < Org | * Ind > SWP |
| Username’s Length | Profile | * SWP < Org | * Ind < Org | NS |
| Allies | Bio | * SWP < Org | * Ind < Org | NS |
| #Words in Bio | Bio | * SWP < Org | * Ind < Org | * Ind < SWP |
| Events | Bio | * SWP < Org | * Ind < Org | NS |
| #Followings | Profile | NS | NS | * Ind < SWP |
| Men | Bio | * SWP < Org | * Ind < Org | * Ind < SWP |
| Feature | Cohen’s d | Effect Size | ||||
|---|---|---|---|---|---|---|
| SWP vs. Org | Ind vs. Org | Ind vs. SWP | SWP vs. Org | Ind vs. Org | Ind vs. SWP | |
| #Likes/Year | 0.58 | 0.43 | NS | Medium | Small | NS |
| Bisexual | 0.89 | 1.66 | NS | Large | Very Large | NS |
| Transgender | 0.86 | 1.58 | NS | Large | Very Large | NS |
| Community | 0.66 | 1.12 | NS | Medium | Large | NS |
| #Followers/#Followings | NS | 0.25 | 0.36 | NS | Small | Small |
| Nsfw | 0.58 | NS | 0.92 | Medium | NS | Large |
| Account’s Age | 1.08 | 0.30 | 0.70 | Large | Small | Medium |
| #Tweets/Year | 0.27 | 0.30 | NS | Small | Small | NS |
| #Tweets | 0.15 | 0.27 | 0.18 | Very Small | Small | Very Small |
| Porn | 0.25 | 0.42 | 0.80 | Small | Small | Medium |
| Letter G in Screen Name | 0.57 | 0.80 | 0.12 | Medium | Large | Very Small |
| Organization | 0.39 | 0.76 | NS | Small | Medium | NS |
| #Followers | NS | 0.32 | 0.33 | NS | Small | Small |
| LGBT | 0.52 | 0.71 | 0.10 | Medium | Medium | Very Small |
| Username’s Length | 0.65 | 0.50 | NS | Medium | Small | NS |
| Allies | 0.34 | 0.65 | NS | Small | Medium | NS |
| #Words in Bio | 0.26 | 0.52 | 0.26 | Small | Medium | Small |
| Events | 0.34 | 0.64 | NS | Small | Medium | NS |
| #Followings | NS | NS | 0.13 | NS | NS | Very Small |
| Men | 0.10 | 0.68 | 0.45 | Very Small | Medium | Small |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karami, A.; Lundy, M.; Webb, F.; Boyajieff, H.R.; Zhu, M.; Lee, D. Automatic Categorization of LGBT User Profiles on Twitter with Machine Learning. Electronics 2021, 10, 1822. https://doi.org/10.3390/electronics10151822
Karami A, Lundy M, Webb F, Boyajieff HR, Zhu M, Lee D. Automatic Categorization of LGBT User Profiles on Twitter with Machine Learning. Electronics. 2021; 10(15):1822. https://doi.org/10.3390/electronics10151822
Chicago/Turabian StyleKarami, Amir, Morgan Lundy, Frank Webb, Hannah R. Boyajieff, Michael Zhu, and Dorathea Lee. 2021. "Automatic Categorization of LGBT User Profiles on Twitter with Machine Learning" Electronics 10, no. 15: 1822. https://doi.org/10.3390/electronics10151822
APA StyleKarami, A., Lundy, M., Webb, F., Boyajieff, H. R., Zhu, M., & Lee, D. (2021). Automatic Categorization of LGBT User Profiles on Twitter with Machine Learning. Electronics, 10(15), 1822. https://doi.org/10.3390/electronics10151822