Abstract
In recent years, different variants of the botnet are targeting government, private organizations and there is a crucial need to develop a robust framework for securing the IoT (Internet of Things) network. In this paper, a Hadoop based framework is proposed to identify the malicious IoT traffic using a modified Tomek-link under-sampling integrated with automated Hyper-parameter tuning of machine learning classifiers. The novelty of this paper is to utilize a big data platform for benchmark IoT datasets to minimize computational time. The IoT benchmark datasets are loaded in the Hadoop Distributed File System (HDFS) environment. Three machine learning approaches namely naive Bayes (NB), K-nearest neighbor (KNN), and support vector machine (SVM) are used for categorizing IoT traffic. Artificial immune network optimization is deployed during cross-validation to obtain the best classifier parameters. Experimental analysis is performed on the Hadoop platform. The average accuracy of 99% and 90% is obtained for BoT_IoT and ToN_IoT datasets. The accuracy difference in ToN-IoT dataset is due to the huge number of data samples captured at the edge layer and fog layer. However, in BoT-IoT dataset only 5% of the training and test samples from the complete dataset are considered for experimental analysis as released by the dataset developers. The overall accuracy is improved by 19% in comparison with state-of-the-art techniques. The computational times for the huge datasets are reduced by 3–4 hours through Map Reduce in HDFS.
1. Introduction
Internets of Things provide internet enabled platform to link heterogeneous devices. Each of these devices are enabled to act smart with the addition of network connection and processing power to them [1]. With the rise of IoT technology, smart home technology has entered the market for controlling the doors, lights, and other appliances in wireless mode. Due to the absence of an administrator [2], various home devices are prone to attacks. Smart home devices were also targeted with information destruction, illegal physical access and privacy violation attacks. These attacks decrease the security level of IoT devices. Hence, it is necessary to develop a robust framework for identifying the IoT attack in an IoT ecosystem in an efficient manner using machine learning models. Traditional classifiers may get biased towards the majority class samples, and this can cause misclassification of the minor but significant class instances. Information loss can be reduced by eliminating such instances using a modified Tomek-linked under-sampling which is detailed in Section 3.
1.1. Attacks in the IoT Network
The various botnet attacks namely Mirai, Bashlite, and Hajime pose huge challenges for IoT security. The different categories of botnet attacks are DDoS, identity theft, leakage of information, keylogging, and pushing [3]. The botmasters perform network mapping to gather the OS information by fingerprinting and port scanning to find vulnerabilities and infect the IoT devices. The major purpose to launch a DDoS attack by a botnet is to render the service inaccessible to authentic users [4]. These attacks are targeted in the network and application layer of the IoT environment. Besides, the application layer also has to handle the security issues. The violations of privacy and data disclosure to the users were the challenges addressed in the research study [5]. Amongst the various fields of study, the most prominent and ever progressing one has been the study of network traffic for attack detection and mitigation. The advancements in the technologies have proportionately increased the network attacks in various environments like IoT, IIoT, etc., and therefore novel enhanced approaches are required to cope with the latest updates. Distributed machine learning with the development of new tools and frameworks like Hadoop provides a colossal scope of development in this direction [6]. Hence, in this paper a distributed machine learning based approach is deployed to identify the presence of malicious behavior in IoT traffic.
The contribution of this proposed work is as follows:
- Hadoop based framework to distribute the processing of huge IoT traffic datasets for minimizing the computational time.
- Class imbalance of IoT datasets is mitigated by deploying a modified Tomek-linked under-sampling technique.
- Tuning the individual machine learning models like SVM, KNN, and NB using artificial immune network for better cross-validation accuracy.
- The proposed model is evaluated with benchmark IoT datasets to show the superiority of the technique over existing baseline approaches.
Superior performance of the modified Tomek-linked under-sampling (MTL) in comparison to the baseline sampling approaches namely, random under-sampling (RUS), condensed nearest neighbor (CNN), and Tomek-linked under-sampling has motivated to adapt in our proposed approach. A hyperparameter tuning using AiNet improves the cross-validation accuracy before predicting the accuracy on BoT-IoT and ToN-IoT datasets. The performance of the MTL under-sampling with various classifiers has been validated in the literature with 10 real life data sets [7]. Few of the datasets which were highly unbalanced, resulted in enhanced performance on various metrics like precision, recall, specificity, fall out, F-measure, Mathews correlation coefficient (MCC), and area under the ROC curve (AUC). Hence, this technique is chosen for performing an under sampling in our proposed model for improved performance.
The remaining of the paper is summarized in the following manner: Section 2 briefs the extensive literature of IoT security models developed in the recent few years. Section 3 discusses the techniques utilized to implement the proposed approach. Section 4 details the proposed Hadoop based framework for botnet traffic identification. Section 5 outlines the experimental analysis. Performance analysis is detailed in Section 6. The conclusion is given in Section 7.
1.2. Intrusion Detection Systems (IDS)
The security threats on the internet and consumer risks are increasing with the invention of IoT. An example is the DoS attack on Dyn [8], which is a DNS provider in the year 2016 and also Mirai botnet attacks on devices by misusing default credentials [9,10]. The major reason for the effectiveness of Mirai Botnet is because of the easy installation of IoT devices, which were developed with minimal or no security concern and reduced cost [11]. A vulnerable IoT device is very risky, irrespective of its level of security [12]. There were nearly 10,263 botnets introduced in 2018 in various IoT devices [13]. There were also 13,000 IoT devices which launched a powerful DDoS attack on IoT devices discovered in 2017 [14]. IoT security would assist measurement platforms to implement innovative user interfaces for home networks to discover and filter botnet traffic [15]. Besides, users can be notified about malicious activities. There is a challenge associated with traffic classification in the IoT domain because there are very few platforms that analyzes this issue [16]. A limited research is done on IDS using ML deployed on IoT networks [17,18]. The primary reasons are the lack of datasets and also real hardware deployed for all datasets consisting of simulated IoT devices [19].
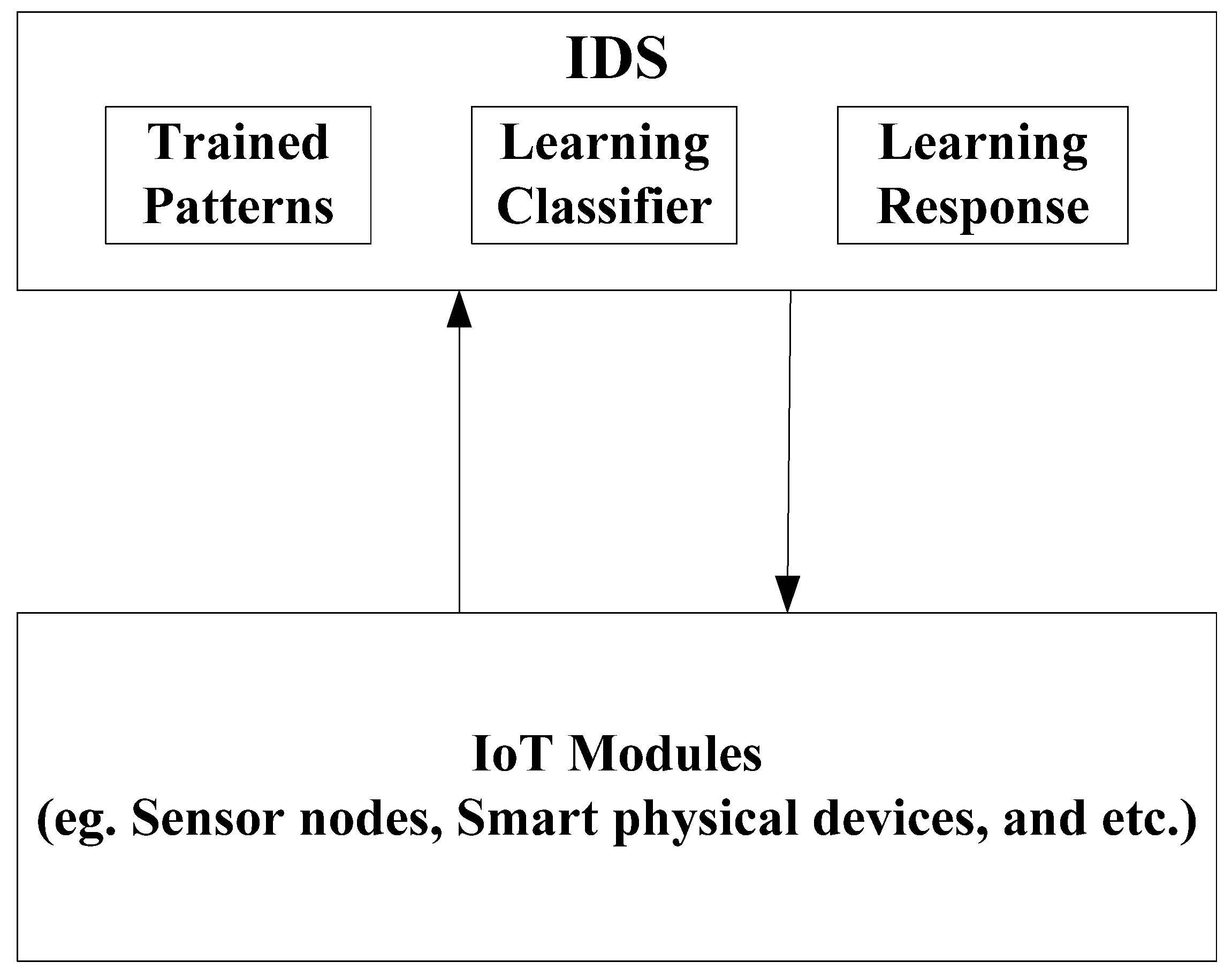
Figure 1 shows typical IDS for IoT environment. The IoT components are monitored by the detection system and the response mechanisms act against the assumed attacks as soon as it is known that the traffic is not a legitimate one. A machine learning technique deploys a learning classifier to train the detection model. Misuse based techniques categorize the incoming traffic by deploying pattern matching algorithms. Traditional IDS cannot be implemented on ordinary IoT devices. Hence, network-based IDS is appropriate to build an IDS for an IoT environment. Huge challenges for Anomaly Detection Systems (ADS) are high false positives but they are effective for novel attacks. The wide diversity of IoT devices is also a challenge for implementing ADS. The storage capacity and computation power require the IDS for IoT to be lightweight.
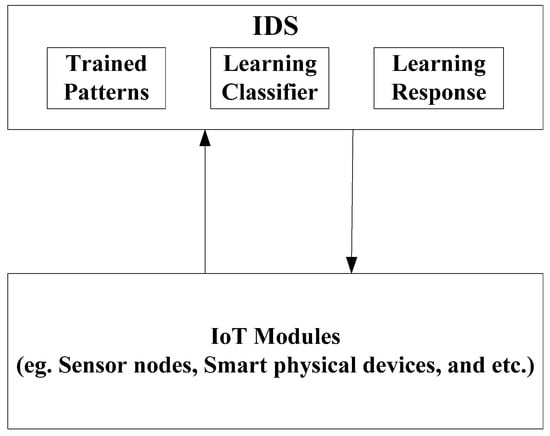
Figure 1.
IDS for IoT environment.
2. Related Work
An important step in product development is the security testing of IoT devices before they are introduced in the market. In this section, a comprehensive literature review is provided which analyzes various studies of IoT device susceptibilities, testbeds developed for each IoT device, and various machine learning-based IDS. Security breaches and vulnerabilities of IoT devices have been studied by various researchers [1,13,20,21], for implementing security mechanisms. The major challenges to test IoT devices are their features and limitations [22]. A comprehensive IoT security test bed was developed [23]. Security weakness of IoT devices was evaluated by launching attacks [14,24,25]. The research on the network and firmware analyses, identified the private address of the user from IoT device, monitored traffic and utilized proxy TLS traffic for data extraction. The security of the network protocols due to the DoS attack on VoIP [26] is studied and enhanced. Constrained IoT devices which implement Constrained Application Protocol (CoAP) were examined [27]. Table 1 specifies the analysis of various IoT attacks, tools deployed to initiate the attack, and their effects. It is inferred that different attacks were targeted on IoT devices and there is a need to develop robust frameworks to protect from these attacks.

Table 1.
Analysis of various IoT attacks and results.
2.1. Vulnerability Mitigation Approaches and Security Testbeds
Penetration testing of IoT is performed and architecture was developed [37]. Testing of various IoT devices such as smart home, wireless sensor networks (WSN), and smart wearables is done to identify the security holes. An integrated AI security framework which exploits machine learning approaches to detect new kind of cyber-attacks in IoT is implemented [38]. Tempo-spatial correlation between different sensor data is analyzed for threat identification. In this, knowledge-based and anomaly-based IDS were integrated. Different IDS architectures are developed [39] for IoT devices. A semi-distributed technique results in an accuracy of 99.97% and long CPU time of 186.26 s. However, in a distributed approach, the accuracy obtained is only 97.8% but CPU time is relatively low of about 73.52 s. The constraint of the work is updated datasets on IoT are not available. A cost-effective IDS for IoT was proposed [40], by cooperating between individual sensors and the edge routers. DoS and botnet attacks are effectively identified by correlating events from multiple IoT devices and thereby improve the detection rate and minimizing performance overhead. An IoT dataset for dealing with DDoS attacks is generated [41], and used to build models to prevent DDoS attacks. IDS datasets are limited for evaluation and testing, therefore it is critical to confirm maximum interoperability through various developing technologies. An IDS is developed to detect and minimize ping of death attacks and filter out packets that are more than the required length [42]. A search strategy is used to solve the problem.
2.2. IDS for IoT Using Machine Learning
IDS in the IoT environment have fascinated many researchers and developers due to increase in the real time applicability of IoT devices. Machine learning techniques are implemented for IDS in an IoT environment in many current studies.
An IDS based on LDA and single hidden layer neural network ELM is developed for IoT [43]. A good generalization and detection accuracy of 92.35% is obtained which is superior in comparison to other approaches. An anomaly-based intelligent IDS named Passban is developed to analyze information collected from various IoT sources and identify cyber-attacks which have different flow pattern in comparison to normal events [44]. A real time IoT testbed is deployed on a resource-constrained home automation environment. Malicious traffic is detected with low false positives and high accuracy. Local Outlier Factor (LOF) and isolation Forest are deployed for class predictions which are one-class classification approaches. A supervised three-layer IDS is developed to identify cyber-attacks in IoT networks [45]. The proposed IDS can automatically differentiate between normal and benign network activity with a maximum f-measure of 96.2%.
A detection system was proposed for sinkhole attacks which targeted the routing devices [46]. In another analysis [47], battery exhaustion attacks were prevented on a low energy Bluetooth network. A novel IDS was built using a rule-based architecture for IoT environment [48]. The effort was to predict abnormal activity and identification of malicious IoT nodes. Naive Bayes was used as the classifier and open-source tool Weka was used for performance evaluation. Another study proposed a machine learning-based forensic mechanism for IoT botnets and Weka was used to determine the detection accuracy [49]. A lightweight IDS on Raspberry Pi is implemented using machine learning to protect against attacks in the IoT environment. A feature selection technique was integrated to develop a lightweight system [50]. Ahmad et al. [51], built a machine learning framework with CFS to identify normal behavior in Command-and-Control Communication channels and malicious behavior. Real-world data sets were used for evaluation and various cost-sensitive approaches integrated with various feature combinations to yield a superior result. A Trust aware Collaborative Learning Automata IDS (T-CLAIDS) is developed for VANETs [14]. The abnormal events are detected better using the proposed approach. The scheme outperforms other approaches in terms of false alarm ratio, detection ratio, and overhead. A standard cryptographic technique is used to develop intrusion detection in the distributed vehicular cloud [52]. A 10% of detection rate in improvement is obtained when compared with existing techniques. Figure 2 shows the traffic detection process of BoT-IoT attacks. Lightweight IDS are necessary for IoT whereas existing IDS only target high accuracy with a low false alarm.
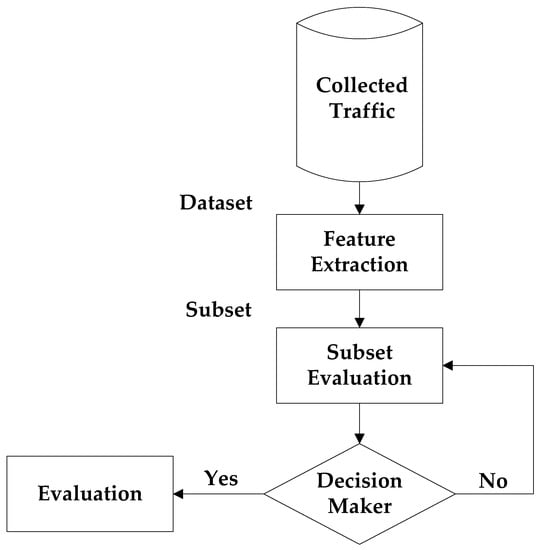
Figure 2.
Traffic detection process of BoT-IoT attacks.
2.3. Enhancements for Upcoming IoT Applications
A standard and a well-built framework for an IoT application are not available. Hence, substantial improvements in the current IoT application are needed to render it trustworthy, robust, and secure. Therefore,
- Severe penetration testing of IoT devices is required to analyze the risk levels in device installation for various applications. A priority list can be made according to the risk involved and appropriately the devices can be deployed.
- Different layers of IoT and protocols are suing encryption techniques. There are different phases in the application such as encrypt, decrypt, and re-encrypt which makes the system susceptible to threats. Hence, a viable solution suggested for preventing various threats is end-to-end encryption.
- An authentication service must be implemented for interaction between devices. Digital certificates can provide seamless authentication that is integrated with cryptographic protocols could be a promising solution
- Encryption approaches like RSA and hashing techniques like SHA256 or hash chains must be deployed for securing the user and environment.
- Cloud services are used by most of the applications for storage and retrieval of data and hence cloud storage risks must be analyzed. Data security can be enhanced by storing the encrypted data in the cloud and the provider cannot decrypt any ciphertext.
- IoT devices can be secured by the use of artificial-intelligence-based approaches.
2.4. Class Imbalance Problem in IoT Datasets
There are two major categories to remove class imbalance problem in datasets.
- Data level solutions
- Algorithmic level
Data level solutions result in a balanced data distribution among the class labels by redistributing the samples in the data space. Sampling is an elementary technique to achieve class distribution balance within a dataset, either by adding examples into the minority class called as oversampling or by removing examples from the majority class. called as under-sampling. Tomek-linked under-sampling is widely preferred to eliminate boundary samples [7]. Algorithmic level approaches result in an optimal solution for class imbalance problem by modifying the classifiers. A cost function is defined against misclassification in cost sensitive approaches and is one of the efficient algorithmic based approaches. Various techniques for improving the class imbalance problem are discussed in detail in the next section. In our proposed approach, the IoT traffic is highly imbalanced—i.e., Minority IoT attack samples—are very less in comparison to normal IoT traffic. Therefore, an algorithmic level under-sampling technique is adopted and deployed in the framework.
3. Methods and Framework Adopted for Proposed Approach
This section discusses the approaches primarily used to implement the proposed scheme in detail.
3.1. Identification of Outlier
A revision is performed on the concept of minority samples related to each Tomek-linked majority samples. An element is considered as an outlier or boundary sample according to the number of minority instances to which a majority sample, is associated by a Tomek-link pair. The majority element is reclined to the data distribution of the minority region and is responsible for deprivation in performance.
3.2. Identification of Redundant and Noisy Samples
The similarity measure between samples is termed as redundancy. The proposed scheme employs three different similarity measures, namely, Euclidean Distance (ED), Cosine Similarity (CS), and City-block Distance (CD). Each of the individual measures is given in equations below:
- (i).
- City-block distance () is represented in Equation (1).and
- (ii).
- Euclidean distance () for two samples and is represented in Equation (3).and
- (iii).
- Cosine similarity is a similarity degree which determines the cosine angle among two samples, and where the result is within the series . Cosine similarity is given in Equation (5).
- (iv).
- Euclidean dot product is defined by
- (v).
- By substituting the value of in (6)
The majority pair samples which contribute to the maximum similarity score are removed.
3.3. Contribution Element, ()
This element specifies the probability mass function which specifies a fixed group of distributions, represented as , where represents model parameter elements and the entire observation set is represented as .
An estimator for predicting the parameter true value, is to be determined by the function . Thus, Equation (8) represents joint density function belonging to a specific category.
In Equation (8), represents the majority class label and where represents the redundant and noisy bulk samples.
The likelihood calculation of each sample, is the objective of . This specifies the possibility to be arranged in the discrete class label set ; if the class label of available in the dataset is true. The likelihood is represented in Equation (9) below
The disadvantage of maximum likelihood of zero estimation is overcome by the log-likelihood function while determining the class label is . A modified log-likelihood function is a combination of each attribute value, (, where is the number of attributes) with the joint density function as given below
Thus, the contribution term is represented as
where, the prior probability of class is represented by and the log-likelihood function is specified as .
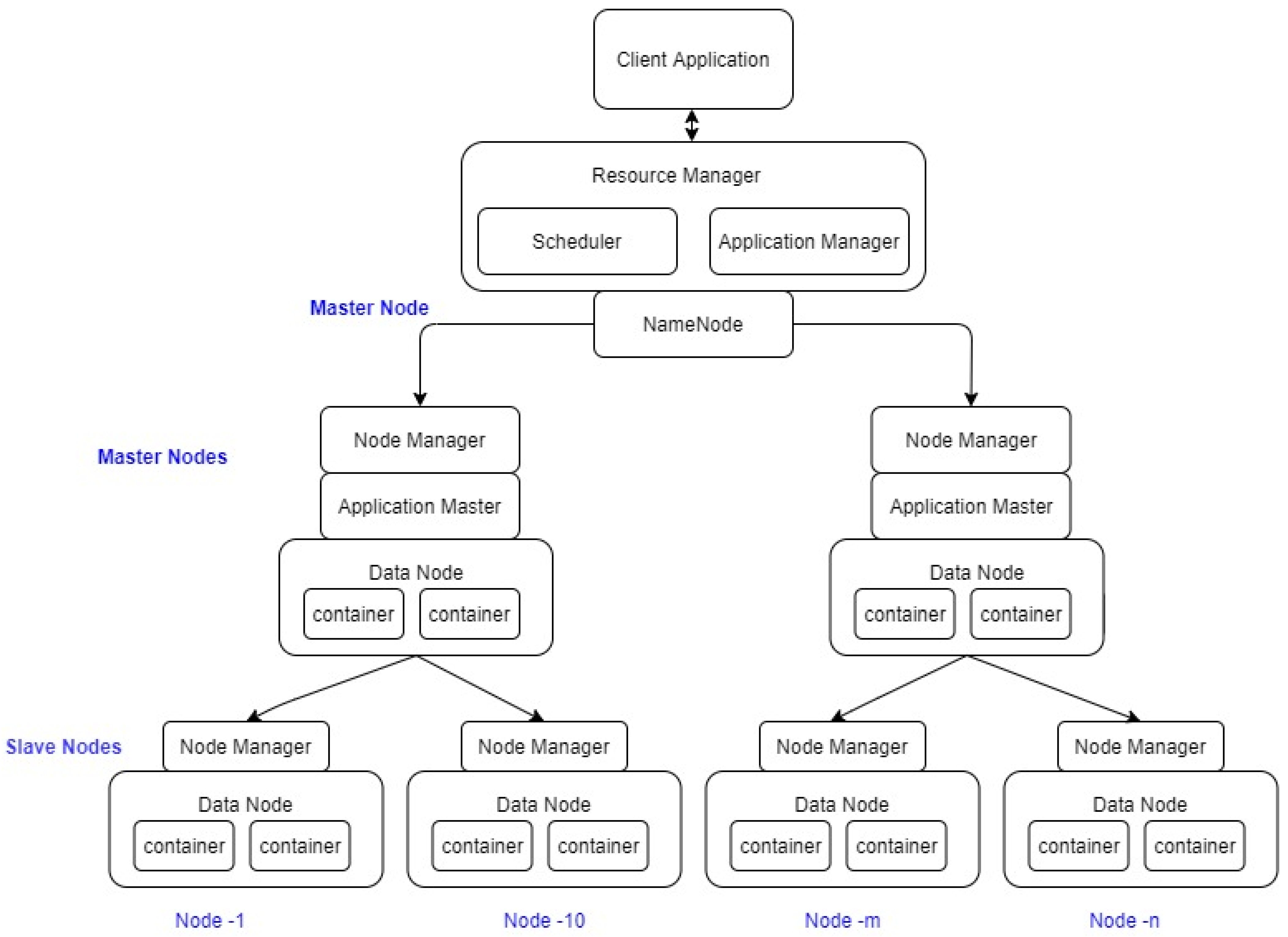
3.4. Hadoop Architecture Overview
Big Data platforms are flexible in terms of data acquisition as it supports structured and unstructured data. In addition, big data platforms like Hadoop are also used for data integration, aggregation, representation, and query processing. Multiple tools are deployed in the Hadoop environment thereby the computational complexity is minimized and readily programmable. Huge volume of IoT network traffic records need to be processed and Hadoop server can send the files to the server and obtain the desirable result. The Hadoop ecosystem utilizes the pig tool to aggregate, MapReduce, join and filter the dataset tuples to produce an optimal result. Figure 3 shows a high-level application architecture design of Hadoop. A master slave approach is followed by Hadoop for storage and data processing. The master node in HDFS is called as the NameNode and the slave nodes manage data storage and complex computations. DataNode is responsible for CPU intensive processes like statistics, machine learning tasks, language, and semantic analysis. In addition, I/O intensive activities like data import, export, clustering, search, decompression, and indexing are also executed by the DataNode. Thus, in our proposed model, Hadoop architecture is implemented for faster and efficient processing of data.
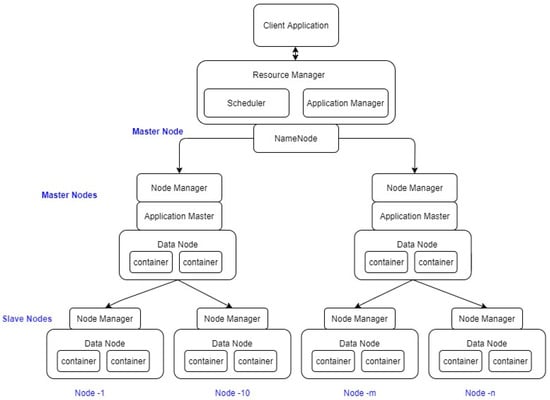
Figure 3.
High level design of Hadoop application architecture.
4. Proposed IoT Intrusion Detection Model
4.1. Machine Learning to Predict IoT Threats
Different IoT attacks listed below can be effectively identified by machine learning techniques.
- DoS Attacks: A serious concern is DoS attacks that originate from IoT devices. Multi-Layer Perceptron (MLP) is one approach that secures networks against such attack. MLP trained by integrating particle swarm optimization with backpropagation technique [53] was proposed which can enhance the security of wireless networks. The detection accuracy will increase by using ML techniques and IoT devices will be secured from the DoS attacks.
- Eavesdropping: ML techniques are used for protecting from eavesdrop on messages during data transmission. ML techniques namely non-parametric Bayesian techniques [54] and Q-learning based offloading strategy [55] can be used.
- Spoofing: Attacks can be avoided using Dyna-Q, Support Vector Machines (SVM) [10], distributed FrankWolfe (DFW) [9], and Deep Neural Network [10], techniques. Classification accuracy increases using these techniques and the false alarm rate and average error rate gets reduced.
- Privacy Leakage: IoT application trust [56] is developed by commodity integrity detection algorithm (CIDA) developed from Chinese remainder theorem (CRT).
- Digital Fingerprinting: IoT systems can be secured by digital fingerprinting and thereby end users will be confident to utilize applications. Smartphones, payments, unlocking car and home doors are implementing fingerprinting. Nontraditional solutions are developed using various machine learning algorithms which are given below.
Machine learning detects undesirable events in IoT devices by training algorithms for data loss prevention and other security concerns. SVM algorithms are widely used in digital fingerprinting and compared their approach with traditional models. SVM is trained using the feature vector obtained based on the fingerprint pixel values. Artificial Neural Network (ANN) provides several benefits such as generalization, adaptive learning, and fault tolerance. A framework for identifying fingerprints digitally by using ANN has been developed [56]. Hence, ML is capable of securing the IoT environment. Liang et al. used machine learning techniques for analyzing the security models for IoT [57]. The authors presented many review techniques using ML for IoT security.
4.2. Secure Model for IoT Traffic
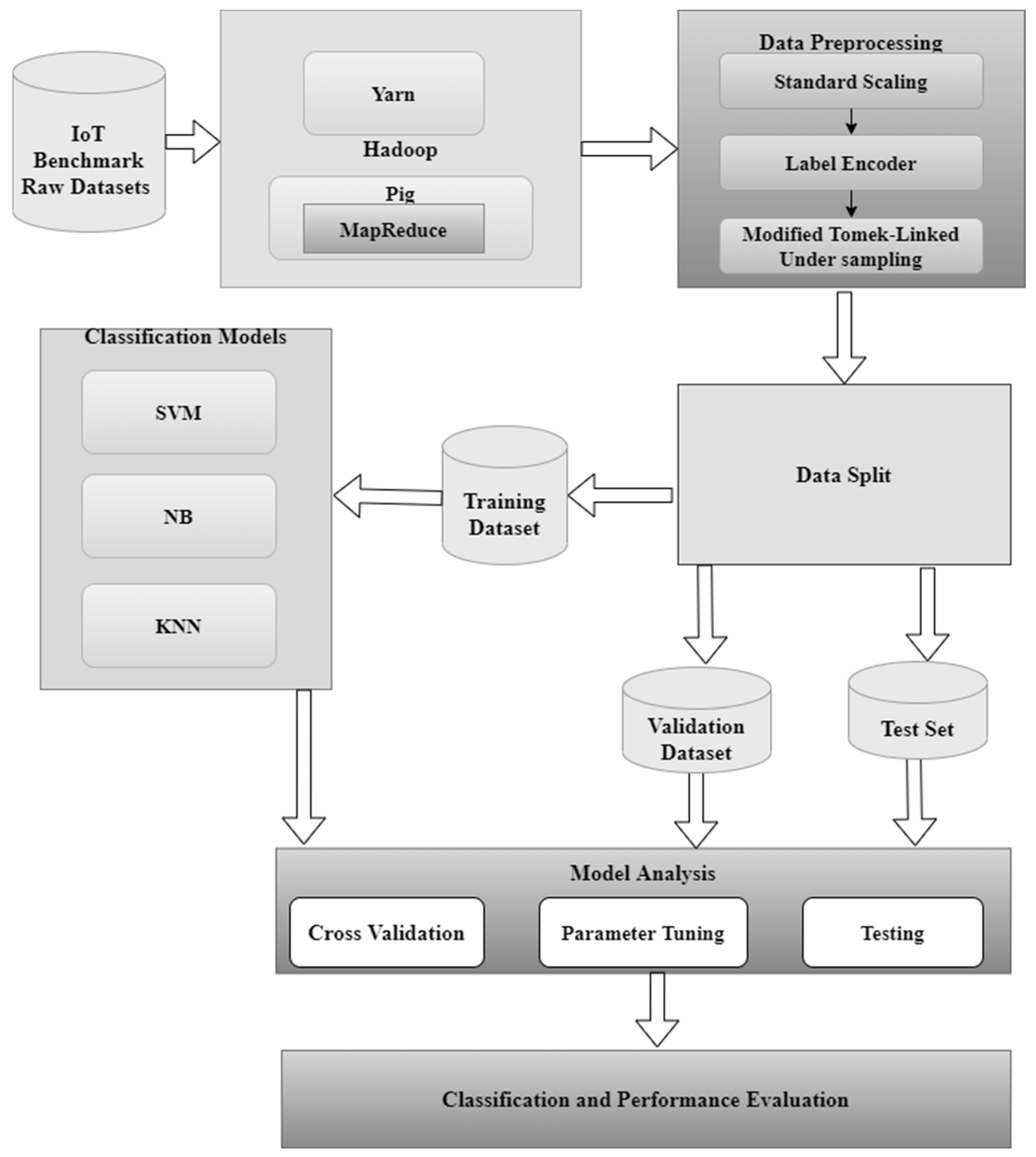
The proposed model is developed in two phases as represented in Figure 4. A multi-level architecture is implemented in the proposed model. In the initial stage, the benchmarks IoT datasets are uploaded into the HDFS. Yarn, which is the resource manager of Hadoop manages the name node, data node and secondary name node of the cluster. The pig script is then executed in the Map Reduce node to implement the Map Reduce functionality. The processed data is saved in the HDFS for further analysis. In the next level, a data pre-processing is performed by standard scaling, label encoder, and under-sampling of majority labeled samples. In the under-sampling technique, the samples with majority class records concerning noise, contribution factor, and redundancy is performed. The final stage is the prediction of the IoT network traffic by deploying three classifiers KNN, SVM, and NB to predict the class labels. This approach improves the accuracy and minimizes the false alarm rate. A hyperparameter optimization is performed using artificial immune network. The desired accuracy is obtained in minimal amount of time because the datasets are processed in Hadoop environment which is discussed in the experimental section. The parameters of SVM, KNN, and naïve Bayes are tuned for optimal accuracy as shown in Table 2 and Table 3. The pseudocode of the various classifier predictions given in Appendix A.
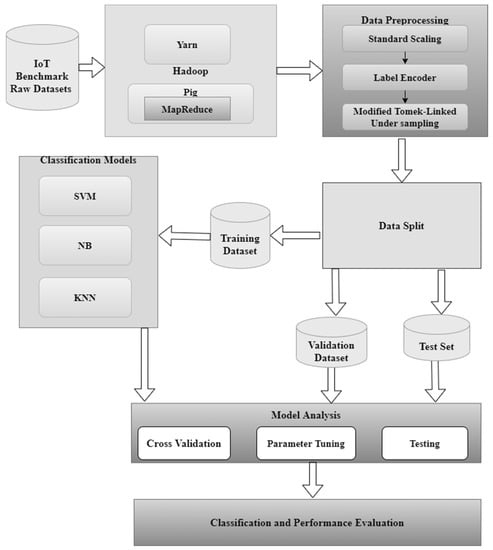
Figure 4.
Proposed IoT intrusion detection model.
Table 2.
Optimal aiNet parameters.
Table 3.
Tuned hyper classifier parameters.
4.3. Data Pre-Processing
4.3.1. Identification of Outlier and Tomek-Link Pairs
Input:
- Dataset, using ‘’ samples and the feature space consisting of ‘’ number of attributes.
- , , and threshold () to calculate the majority index samples, .
Every sample is represented as (), where () is the input vector for -th sample, denoted as , where is the total feature set, , and is the selected class labels of the samples with a maximum of c-classes.
Notation:
- —An imbalanced dataset, with ‘’ number of samples and ‘’ represents the number of attributes
- —Minority class set samples, , ‘’ is the sum of minority class samples.
- —Majority class set samples, , ‘’ is the sum of majority class samples.
- —Set of Tomek-linked samples.
- —Total minority samples, to which majority sample, is connected as Tomek-linked pair.
- —Improved subset of , after removing samples, identified to be outliers.
Begin:
- Split the complete dataset, into two subsets, and .
- For every , calculate the k-nearest neighbor using Euclidean measure, , for .
- The nearest neighbor pairs are included in the subset, .
- For each , determine index .
- If index , where h represents threshold; is identified as ‘outlier’, existing in the minority area of the subset, and are removed.
- Updating the subset to as
- Updating the subset to as .
Samples present in the set REM represent the outliers. There is a greater chance of samples creating Tomek-link pair with multiple minority samples to be placed on the incorrect side of the decision boundary. Samples belonging to are represented as Tomek-link paired samples which were sent to the subsequent phase for checking redundancy.
4.3.2. Estimation of Redundancy among Majority Samples
The majority class instances which exist close to the decision margin are identified by redundancy and noise factors and are maximum similar to other majority samples. The similarity measures which has been considered are CB, CS, and ED as detailed in Section 3.2.
Input:
- , r = number of utmost redundant samples which helps to create, . Set .
Begin:
- For every , deploy the various distance measures like ED, CB and CS to calculate the redundant pairs, specified in Equations (1)–(7) and transferred to the subset, as .
- A revised subset, is generated by eliminating the majority samples contributing to redundancy and noise. Thus, the intersection of and , is given as: .
4.3.3. Estimation of the Contribution Factor
The contribution element, is deployed to the majority category samples within the set, . The steps to calculate is detailed in Section 3.3.
4.3.4. Under-Sampling of Majority Samples
The outliers are the initial ones to be removed from the majority samples. These samples are determined based on their redundancy factor and contribution term. Noisy samples which contribute to maximum redundancy and minimum contribution will be identified for removal. Hence, the objective function that can exclude a majority sample, from a pair which is redundant, where is represented by Equation (12) as
, i.e., it is to be noted that the sample with the minimum contribution term will be removed if two noise samples are detected.
4.3.5. Algorithm
The pseudo code of the proposed pre-processing phase is summarized in Algorithm 1 below:
| Algorithm 1. Tomek-linked and redundancy-based under-sampling |
| Input: A dataset, S with “n” samples and the feature space using “h” features. Each sample is represented by () where is the vector input for th-sample, identified as with a sum of h-features and are the chosen category labels from the samples containing the sum of c-classes; where k = total of nearest neighbors with set k = 1 to identify Tomek-link pair. Begin:
|
4.4. Classification
The model deploys three classifiers. Each classifier in this stage is trained with the newly updated training set obtained after under-sampling. The prediction is then computed using the test set. The three classifiers used in the proposed approach are:
- Naive Bayes;
- KNN; and
- SVM
4.4.1. Naive Bayes (NB)
NB belongs to the category of probabilistic algorithm wherein the probability of all the attributes and their outcome. This approach determines the event probability with regard to earlier events occurrence which is called as the posterior probability.
4.4.2. KNN
KNN is the simplest of all the existing models because training will be done only while we classify the data [58,59]. Related data points will be grouped and also it examines the closest data point having the K value. It is most widely used in the intrusion detection. The KNN is used to examine the normal data and attack data.
4.4.3. SVM
Support vector machine (SVM) is a supervised learning approach that practices a hyperplane to classify future predictions and to separate the training data. It splits a dataset into two categories and the decision boundaries which helps to classify the data points. SVM is widely deployed for intrusion detection as observable by the tremendous volume of studies done over the years [57].
The detailed pseudocode of each of the three classifiers for prediction is given in the Algorithm A1 of Appendix A section.
4.5. Artificial Immune Network (aiNet) for Hyperparameter Optimization
An optimization version (Opt-aiNet) which can be used in optimization problems is available in aiNet [60]. A population is grown in Opt-aiNet which consist of a network of antibodies and the population size can be dynamically adjustable.
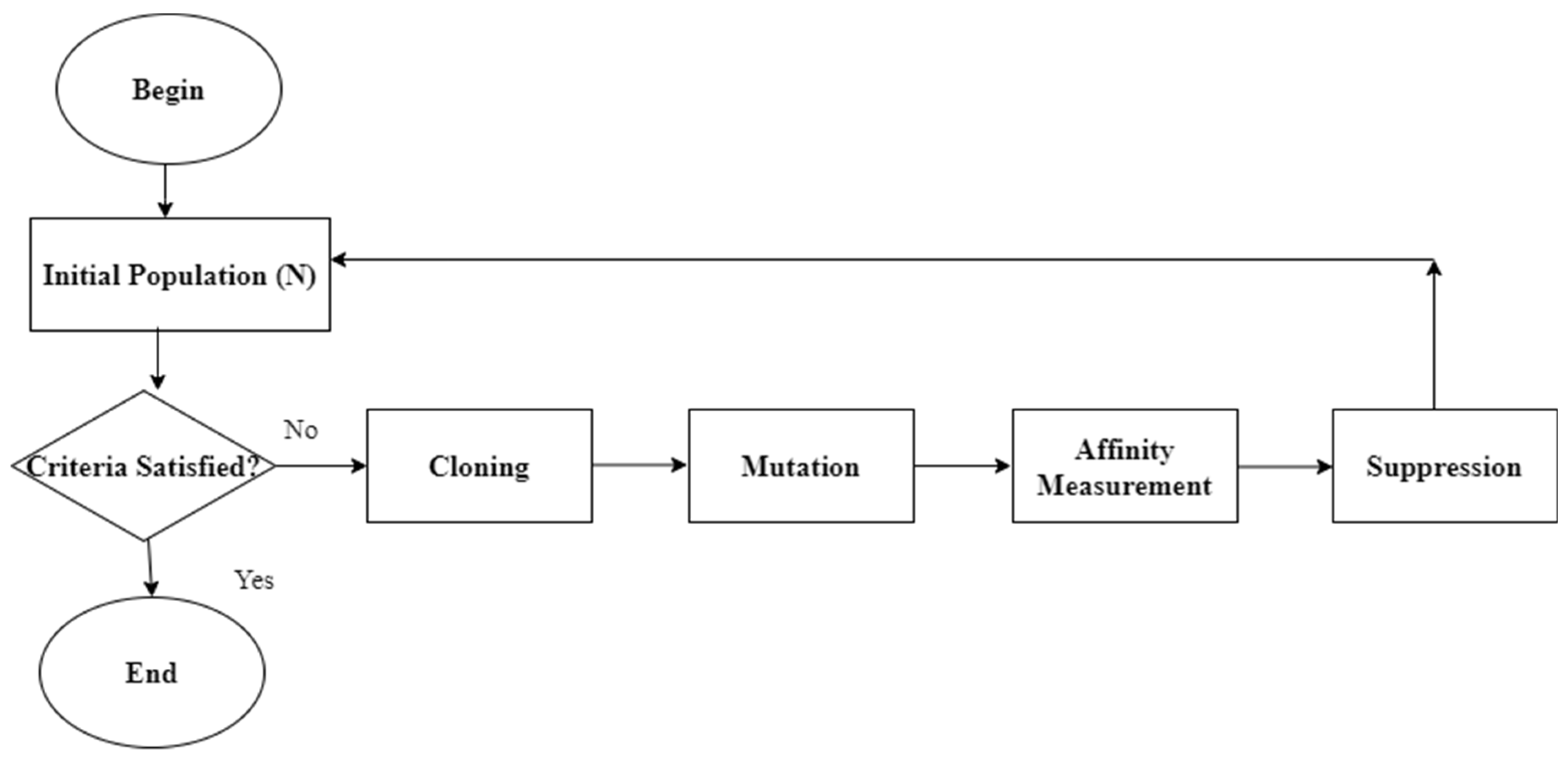
The optimal hyper-parameters of machine learning techniques are determined by Opt-aiNet as shown in Figure 5. SVM consists of the hyper-parameters σ and C. The misclassification cost is represented by ‘C’ which represents the distance from the error and margin. A balance of ‘C’ and σ is very crucial because the model gets overfitted if there is a high value of C and σ. The hyperparameters of KNN are K which represents the number of neighbors and E is Minkowski distance. NB has the hyperparameter namely distribution type which can be normal or kernel density estimation. Table 2 shows the optimal aiNet parameters. Table 3 represents the optimal parameter range of different machine learning techniques obtained from aiNet.
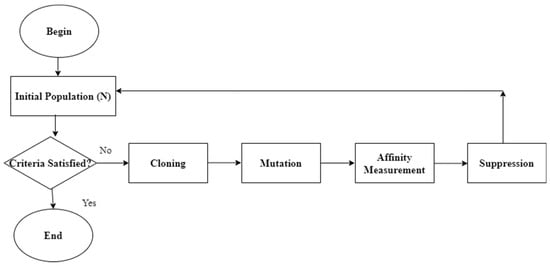
Figure 5.
Flow diagram of opt-aiNet.
An initial population is created randomly with a size of 50. The antigen and antibody values are determined and the similarity between antibody and antigen (Ag) is also determined. The similarity function is calculated as
where Similarity is the association among antibodies and represents the euclidean distance between two antibodies and . The performance obtained by every classifier is determined and the optimization process is iterated till the specified number of generations perform satisfactorily. The similarity mutation is given as
where and represent cell and mutated cell, the Gaussian random value of mean zero and standard deviation is specified by , the control parameter is given by for determining the mutation range and the inverse exponential function decay, is the similarity proportional and is the individual fitness. A mutation is accepted only when the value of ‘c’ lies in the domain range. In the final step, new antibodies replace the old ones. The fitness function process ends when the stopping criteria are reached. Thus, the hyper-parameters are optimized and the optimal accuracy is achieved.
5. Results and Analysis
The model is implemented in the Hadoop and Jupyter platform. The performance of the proposed scheme is evaluated with benchmark IoT datasets.
5.1. Datasets
5.1.1. ToN-IoT Dataset
Data is collected from different heterogeneous data sources such as IIoT sensors, Operating Systems datasets of Windows and Linux from the UNSW Cyber Range and IoT labs. These are the recent new generations of IoT and IIoT datasets for evaluating the models built using machine learning approaches. The attributes of the dataset are different for the edge, fog, and cloud layer captured data samples which are detailed in [7]. Different attacks such as DDoS, DoS, and ransomware were implemented against IoT gateways, web applications and computer systems within the IIoT network. In the proposed approach, only edge layer data samples are used for analysis.
5.1.2. BoT-IoT Dataset
A dataset generated from the UNSW Canberra Cyber Range lab is deployed for the analysis. The dataset encompasses both normal and malicious traffic. The different attacks included in the dataset are Keylogging, DDoS, DoS, OS, service scan, and data exfiltration attacks. The BoT-IoT dataset [6] is extracted using MYSQL by the researchers of that lab and they have utilized only 5% of the original samples as the original dataset is huge. The extracted 5% of data is approximately 1.07 GB of the total size, which is about 3 million records. This is the motivation for adopting Hadoop framework in our proposed work as the dataset is huge and can be processed only in a distributed cluster-based environment. The different attributes in the data are detailed in [61]. Table 4 shows the brief statistics of the various dataset files of BoT-IoT and ToN-IoT utilized for analysis. In this table, the number of samples, features, number of minority samples, majority samples, and imbalance ratio for every dataset is specified. Majority samples are the instances in the dataset containing larger amount of class labels. Minority samples are the instances in the dataset containing minimum amount of class labels. Tomek-linked under-sampling is widely preferred to eliminate boundary samples [7]. For example from Table 4, for the dataset Train_Test_Windows7, the following are Majority samples: Normal—10,000 samples and Minority samples: Backdoor-1780 samples, DDoS-2135, Injection-999, Password-758, Ransomware-83, Scanning-227 and XSS-5. Imbalance ratio is calculated to determine which datasets will require an under sampling based on the minimum difference between minority and majority class labels. Thus, a modified Tomek-linked sampling is deployed to perform under sampling. Similarly, the same procedure is followed for all the datasets specified in Table 4. Imbalance ratio is the number of majority samples to minority samples. Low IR specifies the minimum difference between minority and majority class labels regarding sample count and hence those datasets will be preferred for under-sampling.
Table 4.
Statistics of dataset.
5.2. Comparison with Baseline Approaches
The proposed approach is compared with baseline models for performance. The various baseline approaches for comparative analysis are:
- Random under-dampling (RUS): This is one of the basic techniques for undersampling to eliminate majority samples randomly.
- Condensed nearest neighbor (CNN): This approach eliminates samples randomly concerning nearest neighbor rule.
- Tomek-link: This is a modification of CNN which eliminates interior samples that are in the closeness of the decision boundary.
5.3. Setting Appropriate Values for Parameter ‘t’
In this approach, a parameter ‘t’ is deployed to identify an outlier from the samples of Tomek-link pairs. The main objective is to identify the outliers from the Tomek-associated samples. It is therefore required to select the value of ‘t’ in a medium scale. If the value of ‘t’ is very high, then it can incorrectly identify outlier as potential samples. Similarly, a low value of ‘t’ can delete important majority class samples. Selecting the ‘t’ parameter is influenced by the classifier and similarity type measure for a particular category. The impact of changing ‘t’ values over this proposed approach is evaluated for sensitivity analysis. It is observed that ‘t’ value ranging from 10–15 are appropriate. The ‘t’ value that results in the maximum accuracy for an explicit dataset is identified as the ideal ‘t’ value for a specific dataset. The investigations are accomplished on three classifiers and three distance measures as discussed in Section 3 and Section 4.3. The sensitivity analysis results of BoT-IoT and ToN-IoT dataset is presented in Table 5 and Table 6 respectively. The best train accuracy obtained is highlighted in tables for changing ‘t’ values. Table 7 presents the statistics of various IoT datasets on which under-sampling is executed.
Table 5.
Sensitivity analysis of BoT-IoT dataset.
Table 6.
Sensitivity analysis of ToN-IoT dataset.
Table 7.
Imbalance ratio statistics of IoT datasets.
5.4. Hyper Tuning Parameters Using AiNet
Table 8 and Table 9 presents the different parameter values tuned by aiNet during cross-validation for SVM, KNN, and NB on BoT-IoT and ToN-IoT datasets, respectively. The parameter value which produces minimum training errors and optimum cross-validation accuracy are selected. The parameter setting performed by aiNet with varying parameter values results in the highest average accuracy for further experimental analysis. The proposed approach and the baseline techniques are analyzed by five-fold cross-validation.
Table 8.
Hyper parameter tuning cross-validation results on BoT-IoT dataset.
Table 9.
Hyper parameter tuning cross-validation results on ToN-IoT dataset.
5.5. Results
Table 10, Table 11 and Table 12 shows the graphical illustration of the average test accuracy achieved by the classifiers for all 11 datasets as described in Table 4. It can be observed from Table 10, Table 11 and Table 12, there is a substantial improvement of the proposed work in case of seven datasets which have imbalance ratio less than 1.5. There are four datasets which have imbalance ration more than 1.5. Low IR specifies the minimum difference between minority and majority class labels concerning sample count. The implementation of under-sampling is a good option in these cases because the elimination of a specific amount of potential weak samples creates a balanced dataset. The outliers, noisy, and redundant samples are removed from the common group. The removal of likely weak samples modifies the decision boundary near the minority region, thereby creating a satisfactory state for training the three classifiers, KNN, NB, and SVM.
Table 10.
KNN classifier prediction on all datasets.
Table 11.
NB classifier prediction on all datasets.
Table 12.
SVM classifier prediction on all datasets.
The results are better for the following datasets namely, IoT_Fridge, IoT_garage_door, gps_tracker, IoT_modbus, IoT_Weather, IoT_motion_light, IoT_Windows10, and Final_10_Best_Testing of BoT-IoT dataset. The KNN classifier accomplishes minimum for unbalanced datasets because the majority voting inclines the decision of the classifier. This limitation of KNN is overcome in the implemented proposed work as shown in Table 10. The execution of the proposed scheme with NB and SVM is also illustrated in the results obtained in Table 11 and Table 12. It is observed from the tables that the proposed model achieves good average accuracy in comparison to the Tomek-link technique, for seven datasets which have low imbalance ratio. In the case of naïve Bayes, the approach aims to maintain the prior probability of classes and eliminating boundary samples rather than outliers. The dataset characteristics are represented by imbalance ratio (IR) which is as a statistical parameter. Both prior under-sampling and post oversampling cases are evaluated in context to the scenario and the statistics are shown in Table 7.
The proposed approach comes with an inbuilt under-sampling technique inclusive of three similarity measures to estimate similarity among the samples namely, Euclidean, city-block, and Cosine. It is observed that every dataset performance is influenced by IR. Besides, it is also observed that Euclidean distance produces reasonable results in a substantial number of datasets with all three classifiers. Therefore, Euclidean is considered as the superior similarity measure in the proposed approach. Bold highlighted values in Table 10, Table 11 and Table 12 show the high imbalance datasets resulting in low accuracy and the proposed approach producing better results for all other seven datasets.
6. Performance Analysis
The performance of the proposed model is determined based on the performance measures given in the next subsection.
6.1. Confusion Matrix
The actual and real classification performed by a learner is obtained in the confusion matrix. The various data entries present in a confusion matrix for a binary classifier are following:
- True Positive (TP)—represents the total ‘positive’ samples characterized as positive
- False Positive (FP)—represents the total ‘negative’ samples characterized as positive
- False Negative (FN)—represents the total ‘positive’ samples characterized as negative
- True Negative (TN)—represents the total ‘negative’ samples characterized as negative
The various performance measures for binary categorization retrieved from the confusion matrix values are shown in Table 13. The area-under-curve among two samples is determined by calculating an integral among two separate data samples. An AUC test can be confirmed according to the values given in Table 14.
Table 13.
Performance measure assessment.
Table 14.
Test validation using AUC score.
The advantage of the proposed scheme is shown for derived performance measures. The outliers, noisy and redundant sample of around 5% are removed from the majority group. Thus, only a minor amount of potential weak sample is removed from the dataset to create a balanced one. Table 15 and Table 16 signify the performance measure assessment of edge layer of ToN_IoT dataset and Final_10_Best_Testing of BoT_IoT dataset. Similarly, performance is calculated for remaining datasets also. However, the outcomes of other datasets are not represented because of space restrictions. The bold highlighted values of Table 15 and Table 16 shows the paramount results.
Table 15.
Performance metric values for edge layer of ToN-IoT dataset.
Table 16.
Performance metric values for Final_10_Best_Testing of BoT-IoT dataset.
6.2. Intrusion Detection in Hadoop
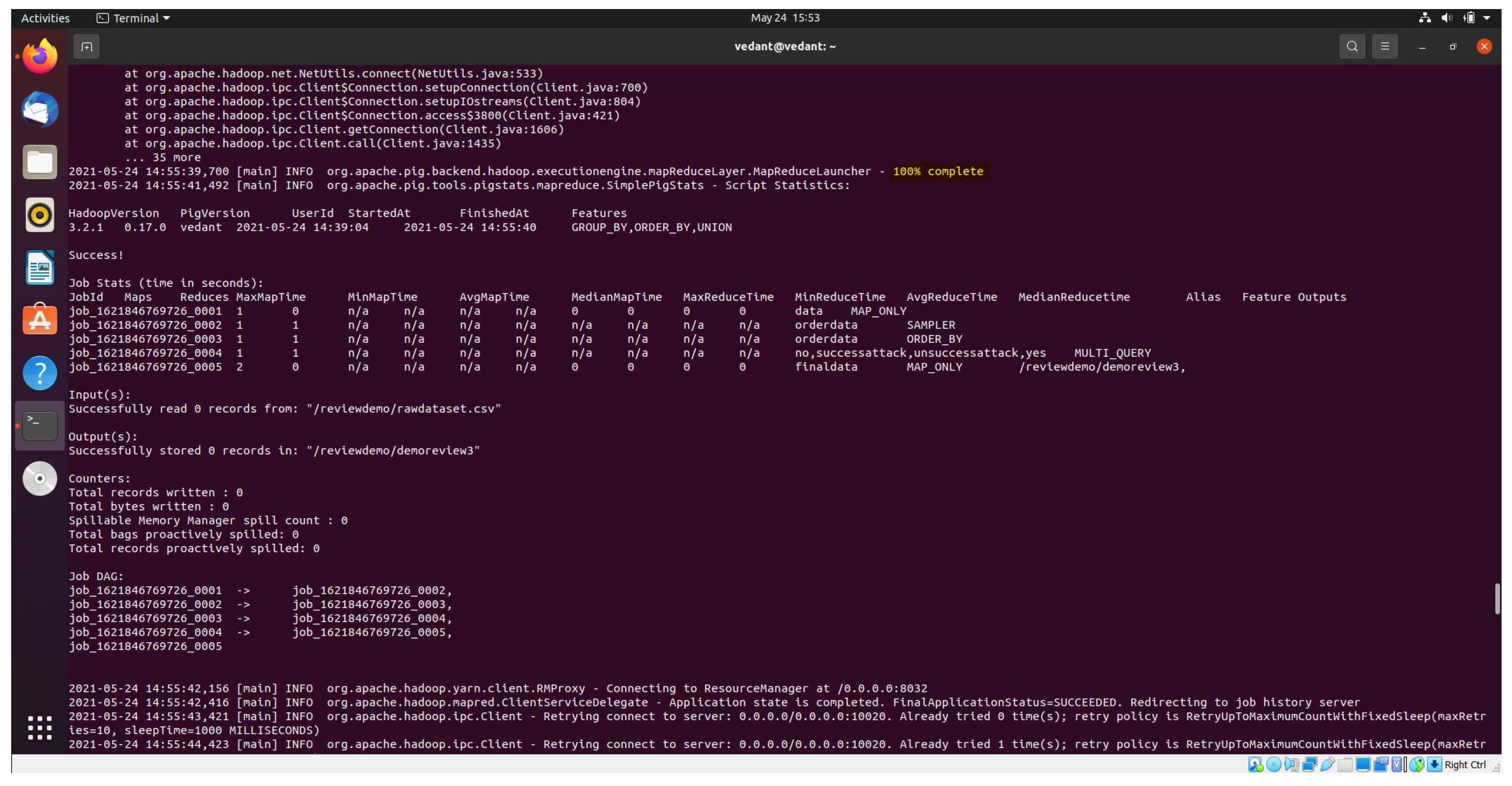
Different sub packages of the org.apache are utilized for various functionality of execution and storage in the Hadoop environment. The various packages used in the Hadoop environment is executed and shown in Figure 6. It is inferred from Figure 6 that the job subclass package present in the org.apache.hadoop is used to allow the user to configure the job, submit, control the execution and query the state. In general, the user creates the application, describes various aspects of the job and submits the job and monitors the progress. The JobSubmitter class can specify access control lists for viewing or modifying a job via the configuration properties mapreduce.job.acl-view-job and mapreduce.job.acl-modify-job respectively. By default, nobody is given access in these properties. In addition, MapReduceLauncher is a main class that launches pig for Map Reduce. The other class namely RMProxy which is a subclass of org.apache.hadoop.yarn.client is utilized for connecting to the Resource Manager and used by the NodeManagers only. This class creates a proxy for the specified protocol. An Inter-process communication is established between client and server by utilizing the following class of org.apache.hadoop.ipc.client. The ClientServiceDelegate class is responsible for monitoring the application state of the process running in various namenode clusters. It returns the FinalApplicationStatus as succeeded and redirects to job history.
Figure 6.
HDFS dataset partitioning—initial level.
Figure 6 shows the HDFS partitioning of the dataset files at the initial level which will be executed in three different slave nodes. Various commands are executed such as $start-dfs.sh for invoking namenode, datanode, and secondary namenode. The node manager and resource manager are initialized with the command $start-yarn.sh. This is required for distributing the resources and data in HDFS. Thus, from the figure, it is evident that three files are executed in map reduce and shows the percentage of complete as 0%, 7%, and 20% in yellow color in the figure. Figure 7 shows the shows the HDFS partitioning at final level where in the computation is 100% complete after partitioning and executing the computation in a distributed manner. Our input data is the rawdataset.csv which is in HDFS. After executing the store statement, the following output will be obtained. A directory is created with the specified name and the data will be stored in it. The statistics inferred from Figure 7 is there are five Job Ids which have various feature outputs to perform mapping, sampling, ordering, querying, and mapping to the final job status. The complete BoT-IoT dataset is executed in 24 min 39 s in comparison to 6 h in a normal stand-alone environment.
Figure 7.
HDFS execution-completion status.
Table 17 shows the computational time of the benchmark datasets in Hadoop environment. The datasets having less samples do not contribute much in the computational time in a Big Data platform. However, samples of Train_test_network containing 461,043 records and final_10_best_testing samples containing 733,705 records have been executed in less than 30 min whereas in standalone environment, execution time was more than 3 to 4 h.
Table 17.
Computational time of the benchmark datasets in Hadoop environment.
6.3. Discussion
The proposed model implements a Hadoop based framework, effective pre-processing using under-sampling technique to remove outlier, noisy and redundant samples from the majority group. The threshold, for identifying the outlier is considered between 10 and 15. The sensitivity analysis result indicates the impact of the parameter, ‘t’ on the effectiveness of the model and the similarity measure choice is critical for the model. The deployment of three classifiers such as KNN, naïve Bayes, and SVM is used to test the superiority of the baseline schemes with different parameter settings as shown in Table 3. A hyper parameter tuning using AiNet also improves the cross-validation accuracy before prediction on BoT-IoT and ToN-IoT datasets.
The various performance measure results of the proposed approach are shown in Section 6.1 and baseline techniques using three classifiers for all dataset samples of BoT-IoT and ToN-IoT. The classification accuracy increases by detecting outliers for the minority samples, which results in increased recall and precision in maximum cases for the proposed approach. Concerning specificity, the proposed approach outdoes the baseline techniques for both datasets. Table 7 presents a statistics of IR on datasets which demonstrates the efficiency of the proposed approach as it focused on a balanced IoT traffic.
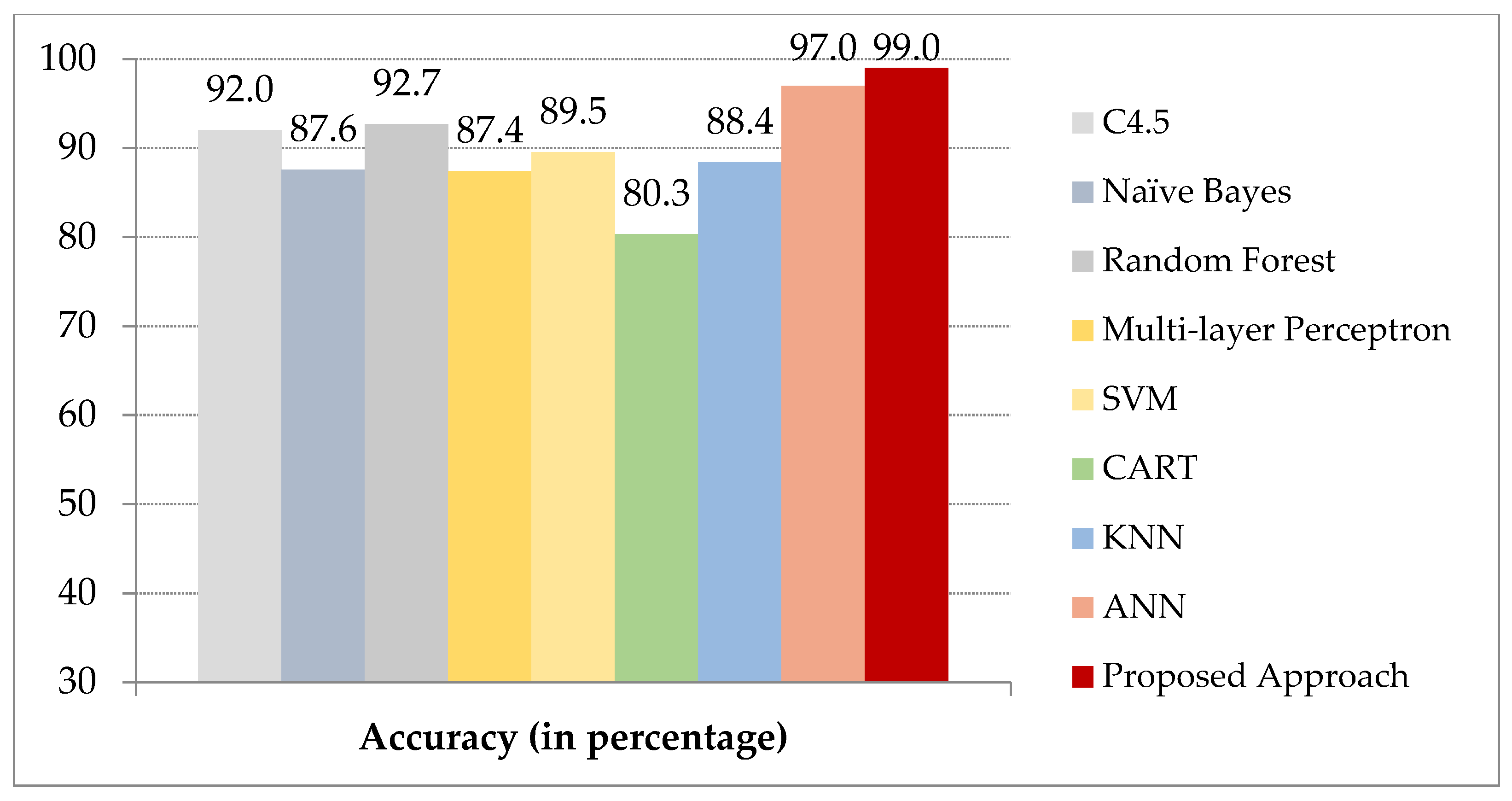
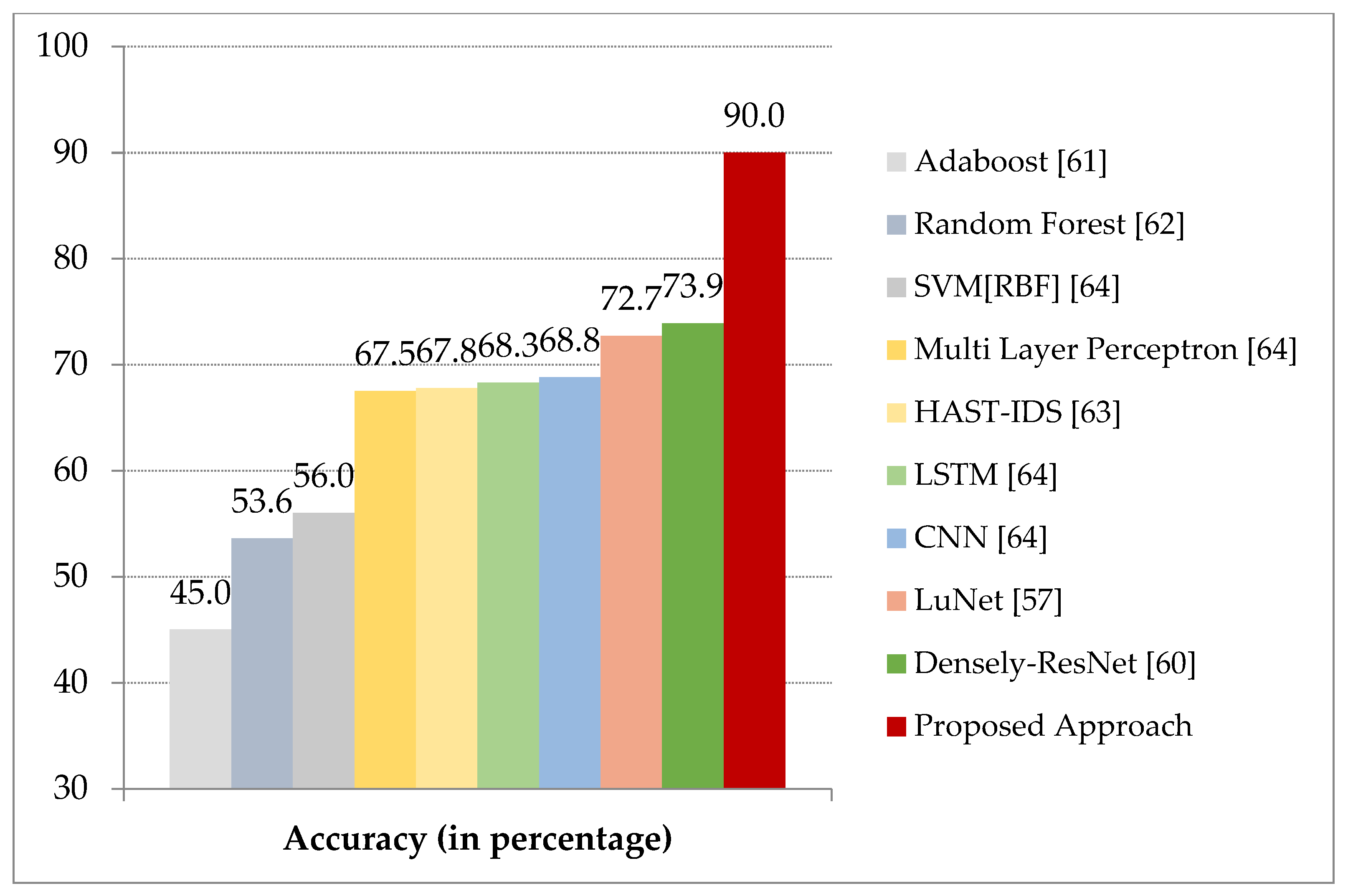
Figure 8 demonstrates the performance of various machine learning approaches [62] on the Bot-IoT dataset. It is evident from the results that the integration of the two phases, namely, modified Tomek link under-sampling and machine learning parameter tuning provides the best performance with an accuracy of 99% for BoT-IoT dataset. The proposed model is also compared with a recent literature [17] which has been verified on BoT-IoT dataset. The proposed model has an overall 19% improvement in accuracy in comparison with the state of the art techniques. Figure 9 signifies the performance comparison of different machine learning approaches on the edge layer of ToN-IoT dataset with the proposed approach [57,60,61,62,63,64]. The proposed model integrates modified Tomek link under-sampling and hyper parameter tuning using AiNet approach for the supervised machine learning classifiers which enhances the overall performance on both the datasets. Conflicting with prevailing works, our analysis shows a broad assessment for the real attack and simulated attack data which were generated by simulating a realistic network at the University of New South Wales where real attacks on IoT networks were recorded.
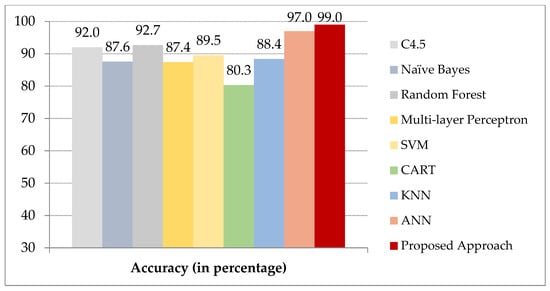
Figure 8.
Comparison of the proposed scheme with existing approaches on BoT-IoT dataset.
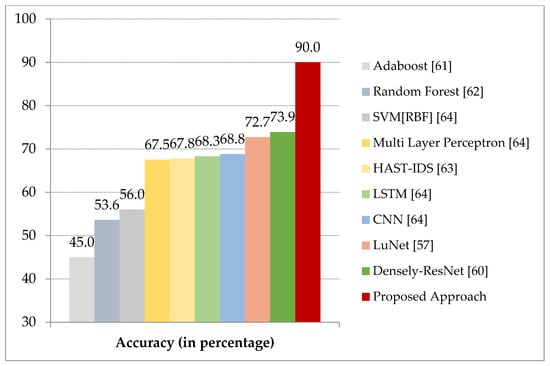
Figure 9.
Comparison of the proposed scheme with existing approaches on ToN-IoT dataset.
7. Conclusions
Autonomous malware attacks are increasing day by day in IoT. This malware affects cross-platform applications and spread between platforms thereby resulting in a devastating effect on connected devices. Numerous researchers have proposed different machine learning techniques for developing a secure framework for IoT. The major contribution of this paper is the usage of a Hadoop based framework integrating an enhanced Tomek-link under-sampling technique for preprocessing and classification using three different supervised classifiers namely NB, SVM, and KNN. The huge volume of IoT traffic datasets increases the computational time in a stand-alone environment. Hence, a HDFS is deployed and all the datasets are loaded inside the Hadoop repository for faster computation. The datasets are hugely imbalanced and hence there is a need to perform under-sampling of majority samples during preprocessing and the classification is performed by machine learning models. A hyper-parameter tuning is performed using Opt-AiNet for tuning the parameters of NB, SVM, and KNN for improved cross-validation accuracy. The performance of BoT-IoT and ToN-IoT datasets on the proposed approach was experimented with various performance metrics like precision, recall, specificity, f-measure, and AUC. The results are compared with traditional approaches to illustrate the supremacy. This is because big data platform is deployed to minimize the computational time and an increase in accuracy is obtained due to the effective data pre-processing and model tuning techniques. There has been a significant increase in average accuracy in BoT-IoT and ToN-IoT datasets in comparison with the contemporary IDS techniques for IoT using machine learning approaches. The computational time is also significantly reduced for the datasets in an HDFS environment.
Author Contributions
Conceptualization, methodology, software, and validation, I.S.T., V.M., and S.R.; Formal analysis, investigation, data curation, and structure of the paper, K.S. and S.-S.Y.; Writing—original draft preparation, I.S.T., V.M., S.R., and K.S.; Writing—review and editing, and supervision, S.-S.Y. All authors have read and agreed to the published version of the manuscript.
Funding
There is no external funding for this research work.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| CFS | Correlation based Feature Selection |
| CST-GR | Correlated-set thresholding on gain-ratio |
| DNS | Domain Name System |
| ELM | Extreme Learning Machine |
| FAR | False Alarm Rate |
| IDS | Intrusion Detection System |
| IoMT | Internet of Medical Things |
| IoT | Internet of Things |
| KNN | K-Nearest Neighbor |
| LDA | Linear Discriminant Analysis |
| LMT | Logistic Model Tree |
| NB | Naïve Bayes |
| PCA-GWO | Principal Component Analysis-Grey Wolf Optimization |
| RF | Random Forest |
| SVM | Support Vector Machine |
| VFDT | Very Fast Decision Tree |
| VoIP | Voice Over Internet Protocol |
| WSN | Wireless Sensor Network |
Appendix A
Pseudocode of machine learning classifiers of the proposed approach:
| Algorithm A1. Proposed Approach |
| Given: Classifier |
Input: Optimal featured dataset D Output: Class label
|
References
- Demiris, G.; Hensel, B.K. Technologies for an aging society: A systematic review of “smart home” applications. Yearb. Med. Inform. 2008, 3, 33–40. [Google Scholar]
- Denning, T.; Tadayoshi, K. Empowering consumer electronic security and privacy choices: Navigating the modern home. In Proceedings of the Symposium on Usable Privacy and Security (SOUPS), Newcastle, UK, 24–26 July 2013. [Google Scholar]
- Amini, P.; Araghizadeh, M.A.; Azmi, R. A survey on Botnet: Classification, detection and defense. In Proceedings of the 2015 International Electronics Symposium (IES), Surabaya, Indonesia, 29–30 September 2015; pp. 233–238. [Google Scholar]
- Koroniotis, N.; Moustafa, N.; Sitnikova, E.; Turnbull, B. Towards the development of realistic botnet dataset in the internet of things for network forensic analytics: Bot-iot dataset. Future Gener. Comput. Syst. 2009, 100, 779–796. [Google Scholar] [CrossRef] [Green Version]
- Hassija, V.; Chamola, V.; Saxena, V.; Jain, D.; Goyal, P.; Sikdar, B. A survey on IoT security: Application areas, security threats, and solution architectures. IEEE Access 2019, 7, 82721–82743. [Google Scholar] [CrossRef]
- Jain, M.; Kaur, G. Distributed anomaly detection using concept drift detection based hybrid ensemble techniques in streamed network data. Clust. Comput. 2021, 2021, 1–16. [Google Scholar]
- Devi, D.; Purkayastha, B. Redundancy-driven modified Tomek-link based undersampling: A solution to class imbalance. Pattern Recognit. Lett. 2017, 93, 3–12. [Google Scholar] [CrossRef]
- Hilton, S. Dyn Analysis Summary of Friday October 21 Attack. Dyn, 2016. Dyn Blog. Available online: https://dyn.com/blog/dyn-analysis-summary-of-friday-october-21-attack (accessed on 2 June 2021).
- Xiao, L.; Xiaoyue, W.; Zhu, H. PHY-layer authentication with multiple landmarks with reduced overhead. IEEE Trans. Wirel. Commun. 2017, 17, 1676–1687. [Google Scholar] [CrossRef]
- Cong, S.; Liu, J.; Liu, H.; Chen, Y. Smart user authentication through actuation of daily activities leveraging WiFi-enabled IoT. In Proceedings of the 18th ACM International Symposium on Mobile Ad Hoc Networking and Computing, Chennai, India, 10–14 July 2017; pp. 1–10. [Google Scholar]
- Jerkins, J.A. Motivating a market or regulatory solution to IoT insecurity with the Mirai botnet code. In Proceedings of the 2017 IEEE 7th annual computing and communication workshop and conference (CCWC), Las Vegas, NV, USA, 9–11 January 2017; pp. 1–5. [Google Scholar]
- Badve, O.; Gupta, B.B.; Gupta, S. Reviewing the security features in contemporary security policies and models for multiple platforms. In Handbook of Research on Modern Cryptographic Solutions for Computer and Cyber Security; IGI Global: Hershey, PA, USA, 2016; pp. 479–504. [Google Scholar]
- Starr, M. Fridge Caught Sending Spam Emails in Botnet Attack. 2014. Available online: https://www.cnet.com/home/kitchen-and-household/fridge-caught-sending-spam-emails-in-botnet-attack/ (accessed on 19 January 2014).
- Kumar, N.; Naveen, C. Collaborative trust aware intelligent intrusion detection in VANETs. Comput. Electr. Eng. 2014, 40, 1981–1996. [Google Scholar] [CrossRef]
- Bailey, M.; Evan, C.; Farnam, J.; Yunjing, X.; Manish, K. A survey of botnet technology and defenses. In Proceedings of the 2009 Cybersecurity Applications & Technology Conference for Homeland Security, Institute of Electrical and Electronics Engineers (IEEE), Washington, DC, USA, 3–4 March 2009; pp. 299–304. [Google Scholar]
- Tahaei, H.; Afifi, F.; Asemi, A.; Zaki, F.; Anuar, N.B. The rise of traffic classification in IoT networks: A survey. J. Netw. Comput. Appl. 2020, 154, 25–38. [Google Scholar] [CrossRef]
- Churcher, A.; Ullah, R.; Ahmad, J.; Rehman, S.U.; Masood, F.; Gogate, M.; Alqahtani, F.; Nour, B.; Buchanan, W. An Experimental Analysis of Attack Classification Using Machine Learning in IoT Networks. Sensors 2021, 21, 446. [Google Scholar] [CrossRef]
- Hussain, F.; Hussain, R.; Hassan, S.A.; Hossain, E. Machine Learning in IoT Security: Current Solutions and Future Challenges. IEEE Commun. Surv. Tutor. 2020, 22, 1686–1721. [Google Scholar] [CrossRef] [Green Version]
- Alsamiri, J.; AlSubhi, K. Internet of Things Cyber Attacks Detection using Machine Learning. Int. J. Adv. Comput. Sci. Appl. 2019, 2019, 10. [Google Scholar] [CrossRef] [Green Version]
- Wurm, J.; Hoang, K.; Arias, O.; Sadeghi, A.; Jin, Y. Security analysis on consumer and industrial IoT devices. In Proceedings of the 21st Asia and South Pacific Design Automation Conference (ASP-DAC), Macau, China, 25–28 January 2016; pp. 519–524. [Google Scholar]
- Khraisat, A.; Gondal, I.; Vamplew, P.; Kamruzzaman, J.; Alazab, A. A novel ensemble of hybrid intrusion detection system for detecting internet of things attacks. Electronics 2019, 8, 1210. [Google Scholar] [CrossRef] [Green Version]
- Murad, G.; Badarneh, A.; Quscf, A.; Almasalha, F. Software Testing Techniques in IoT. In Proceedings of the 8th International Conference on Computer Science and Information Technology (CSIT), Amman, Jordan, 11–12 July 2018; pp. 17–21. [Google Scholar]
- Siboni, S.; Shabtai, A.; Elovici, Y. Leaking data from enterprise networks using a compromised smartwatch device. In Proceedings of the 33rd Annual ACM Symposium on Applied Computing, Pau, France, 9–13 April 2018; pp. 741–750. [Google Scholar]
- Moody, M.; Hunter, A. Exploiting known vulnerabilities of a smart thermostat. In Proceedings of the 14th IEEE Annual Conference on Privacy, Security and Trust (PST), Auckland, New Zealand, 12–14 December 2016; pp. 50–53. [Google Scholar]
- Ronen, E.; Shamir, A. Ronen, Eyal; Adi Shamir. Extended functionality attacks on IoT devices: The case of smart lights. In Proceedings of the IEEE European Symposium on Security and Privacy (EuroS&P), Saarbrucken, Germany, 21–24 March 2016; pp. 3–12. [Google Scholar]
- Fernandez, E.; Pelaez, J.; Larrondo-Petrie, M. Attack patterns: A new forensic and design tool. In Proceedings of the IFIP International Conference on Digital Forensics, Orlando, FL, USA, 28–31 January 2021; Springer: New York, NY, USA, 2007; pp. 345–357. [Google Scholar]
- Alghamdi, T.A.; Lasebae, A.; Aiash, M. Security analysis of the constrained application protocol in the Internet of Things. In Proceedings of the Second International Conference on Future Generation Communication Technology, London, UK, 12–14 November 2013; pp. 163–168. [Google Scholar]
- Arias, O.; Wurm, J.; Hoang, K.; Jin, Y. Privacy and Security in Internet of Things and Wearable Devices. IEEE Trans. Multi-Scale Comput. Syst. 2015, 1, 99–109. [Google Scholar] [CrossRef]
- Bachy, Y.; Basse, F.; Nicomette, V.; Alata, E.; Kaaniche, M.; Courrege, J.-C.; Lukjanenko, P. Smart-TV Security Analysis: Practical Experiments. In Proceedings of the 45th Annual IEEE/IFIP International Conference on Dependable Systems and Networks, Rio de Janeiro, Brazil, 22–25 June 2015; pp. 497–504. [Google Scholar]
- Sivaraman, V.; Chan, D.; Earl, D.; Boreli, R. Smart-Phones Attacking Smart-Homes. In Proceedings of the 9th ACM Conference on Creativity & Cognition, Sydney, Australia, 17–20 June 2013; pp. 195–200. [Google Scholar]
- Ling, Z.; Liu, K.; Xu, Y.; Jin, Y.; Fu, X. An end-to-end view of iot security and privacy. In Proceedings of the GLOBECOM 2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–7. [Google Scholar]
- Ling, Z.; Luo, J.; Xu, Y.; Gao, C.; Wu, K.; Fu, X. Security Vulnerabilities of Internet of Things: A Case Study of the Smart Plug System. IEEE Internet Things J. 2017, 4, 1899–1909. [Google Scholar] [CrossRef]
- Seralathan, Y.; Oh, T.T.; Jadhav, S.; Myers, J.; Jeong, J.P.; Kim, Y.H.; Kim, J.N. IoT security vulnerability: A case study of a Web camera. In Proceedings of the 20th International Conference on Advanced Communication Technology (ICACT), Chuncheon-si, Korea, 11–14 February 2018; pp. 172–177. [Google Scholar]
- Xu, H.; Xu, F.; Chen, B. Internet protocol cameras with no password protection: An empirical investigation. In Proceedings of the International Conference on Passive and Active Network Measurement, Berlin, Germany, 27–28 March 2018; pp. 47–59. [Google Scholar]
- Classen, J.; Wegemer, D.; Patras, P.; Spink, T.; Hollick, M. Anatomy of a vulnerable fitness tracking system: Dissecting the fitbit cloud, app, and firmware. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Willingham, T.; Henderson, C.; Kiel, B.; Haque, S.; Atkison, T. Testing vulnerabilities in bluetooth low energy. In Proceedings of the ACMSE 2018 Conference, Richmond, KY, USA, 29–31 March 2018; pp. 1–7. [Google Scholar]
- Sachidananda, V.; Siboni, S.; Shabtai, A.; Toh, J.; Bhairav, S.; Elovici, Y. Let the cat out of the bag: A holistic approach towards security analysis of the internet of things. In Proceedings of the 3rd ACM International Workshop on IoT Privacy, Trust, and Security, Abu Dhabi, United Arab Emirates, 2 April 2017; pp. 3–10. [Google Scholar]
- Bagaa, M.; Taleb, T.; Bernabe, J.B.; Skarmeta, A. A Machine Learning Security Framework for Iot Systems. IEEE Access 2020, 8, 114066–114077. [Google Scholar] [CrossRef]
- Rahman, A.; Asyharia, A.T.; Leong, L.S.; Satrya, G.B.; Tao, M.H.; Zolkipli, M.F. Scalable Machine Learning-Based Intrusion Detection System for IoT-Enabled Smart Cities. Sustain. Cities Soc. 2020, 61, 10–23. [Google Scholar] [CrossRef]
- Arshad, J.; Azad, M.A.; Abdeltaif, M.M.; Salah, K. An intrusion detection framework for energy constrained IoT devices. Mech. Syst. Signal Process. 2020, 136, 106436. [Google Scholar] [CrossRef]
- Al-Hadhrami, Y.; Hussain, F.K. Real time dataset generation framework for intrusion detection systems in IoT. Future Gener. Comput. Syst. 2020, 108, 414–423. [Google Scholar] [CrossRef]
- Abdollahi, A.; Fathi, M. An Intrusion Detection System on Ping of Death Attacks in IoT Networks. Wirel. Pers. Commun. 2020, 112, 2057–2070. [Google Scholar] [CrossRef]
- Zheng, D.; Hong, Z.; Wang, N.; Chen, P. An Improved LDA-Based ELM Classification for Intrusion Detection Algorithm in IoT Application. Sensors 2020, 20, 1706. [Google Scholar] [CrossRef] [Green Version]
- Eskandari, M.; Janjua, Z.H.; Vecchio, M.; Antonelli, F. Passban IDS: An Intelligent Anomaly-Based Intrusion Detection System for IoT Edge Devices. IEEE Internet Things J. 2020, 7, 6882–6897. [Google Scholar] [CrossRef]
- Anthi, E.; Williams, L.; Slowinska, M.; Theodorakopoulos, G.; Burnap, P. A Supervised Intrusion Detection System for Smart Home IoT Devices. IEEE Internet Things J. 2019, 6, 9042–9053. [Google Scholar] [CrossRef]
- Cervantes, C.; Poplade, D.; Nogueira, M.; Santos, A. Detection of sinkhole attacks for supporting secure routing on 6LoWPAN for Internet of Things. In Proceedings of the IFIP/IEEE International Symposium on Integrated Network Management (IM), Ottawa, ON, Canada, 11–15 May 2015; pp. 606–611. [Google Scholar]
- Anthi, E.; Williams, L.; Burnap, P. Pulse: An adaptive intrusion detection for the internet of things. Living Internet Things Cybersecur. IoT 2018, 2018, 35–40. [Google Scholar]
- Nobakht, M.; Sivaraman, V.; Boreli, R. A host-based intrusion detection and mitigation framework for smart home IoT using OpenFlow. In Proceedings of the 11th International conference on availability, reliability and security (ARES), Salzburg, Austria, 31 August–2 September 2016; pp. 147–156. [Google Scholar]
- Fu, Y.; Yan, Z.; Cao, J.; Koné, O.; Cao, X. An Automata Based Intrusion Detection Method for Internet of Things. Mob. Inf. Syst. 2017, 2017, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Soe, Y.N.; Feng, Y.; Santosa, P.I.; Hartanto, R.; Sakurai, K. Towards a Lightweight Detection System for Cyber Attacks in the IoT Environment Using Corresponding Features. Electronics 2020, 9, 144. [Google Scholar] [CrossRef] [Green Version]
- Azab, A.; Alazab, M.; Aiash, M. Machine Learning Based Botnet Identification Traffic. In Proceedings of the 2016 IEEE Trustcom/BigDataSE/ISPA, Tianjin, China, 23–26 August 2016; pp. 1788–1794. [Google Scholar]
- Kumar, N.; Singh, J.P.; Bali, R.S.; Misra, S.; Ullah, S. An intelligent clustering scheme for distributed intrusion detection in vehicular cloud computing. Clust. Comput. 2015, 18, 1263–1283. [Google Scholar] [CrossRef]
- Xiao, L.; Li, Y.; Han, G.; Liu, G.; Zhuang, W. PHY-layer spoofing detection with reinforcement learning in wireless networks. IEEE Trans. Veh. Technol. 2016, 16, 10037–10047. [Google Scholar] [CrossRef]
- Xiao, L.; Yan, Q.; Lou, W.; Chen, G.; Hou, Y.T. Proximity-based security techniques for mobile users in wireless networks. IEEE Trans. Inf. Forensics Secur. 2013, 8, 2089–2100. [Google Scholar] [CrossRef] [Green Version]
- Xiao, L.; Xie, C.; Chen, T.; Dai, H.; Poor, H.V. A mobile offloading game against smart attacks. IEEE Access 2016, 4, 2281–2291. [Google Scholar] [CrossRef]
- Oulhiq, R.; Ibntahir, S.; Sebgui, M.; Guennoun, Z. A fingerprint recognition framework using Artificial Neural Network. In Proceedings of the 10th International Conference on Intelligent Systems: Theories and Applications (SITA), Rabat, Morocco, 20–21 October 2015; pp. 1–6. [Google Scholar]
- Ly, K.; Jin, Y. Security studies on wearable fitness trackers. In Proceedings of the 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Orlando, FL, USA, 16–20 August 2016. [Google Scholar]
- Ali, N.; Neagu, D.; Trundle, P. Evaluation of k-nearest neighbour classifier performance for heterogeneous data sets. SN Appl. Sci. 2019, 1, 1559. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Wang, G. A light-weight commodity integrity detection algorithm based on Chinese remainder theorem. In Proceedings of the IEEE 11th International Conference on Trust, Security and Privacy in Computing and Communications, Liverpool, UK, 25–27 June 2012; pp. 1018–1023. [Google Scholar]
- Khan, F.; Kanwal, S.; Alamri, S.; Mumtaz, B. Hyper-Parameter Optimization of Classifiers, Using an Artificial Immune Network and Its Application to Software Bug Prediction. IEEE Access 2020, 8, 20954–20964. [Google Scholar] [CrossRef]
- UNSW Canberra Website. Available online: https://www.unsw.adfa.edu.au/unsw-canberra-cyber/cybersecurity/ADFA-NB15-Datasets/bot_iot.php (accessed on 2 June 2021).
- Foley, J.; Moradpoor, N.; Ochenyi, H. Employing a Machine Learning Approach to Detect Combined Internet of Things Attacks against Two Objective Functions Using a Novel Dataset. Secur. Commun. Netw. 2020, 2020, 1–17. [Google Scholar] [CrossRef]
- Wang, W.; Sheng, Y.; Wang, J.; Zeng, X.; Ye, X.; Huang, Y.; Zhu, M. HAST-IDS: Learning hierarchical spatial-temporal features using deep neural networks to improve intrusion detection. IEEE Access 2017, 6, 1792–1806. [Google Scholar] [CrossRef]
- Alsaedi, A.; Moustafa, N.; Tari, Z.; Mahmood, A.; Anwar, A. TON_IoT telemetry dataset: A new generation dataset of IoT and IIoT for data-driven intrusion detection systems. IEEE Access 2020, 8, 165130–165150. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).