This section describes the proposed method from a software perspective (floating-point description) to a hardware perspective (fixed-point description). It also discusses several aspects of the hardware design phase, which are exploitable to achieve a high processing speed.
5.1. Floating-Point Description
As a starting point, the power-law expressing GC in Equation (
1) can be re-written in terms of exponential and logarithmic functions, as follows.
where
and
denote the exponential and natural logarithmic functions, respectively. As described in
Section 2.2, the exponential function can be accurately approximated by the fourth Taylor polynomial at the proximity around the origin. Therefore, the GC’s approximation can be obtained by letting
and then performing a neat conversion, based on the power to a power rule described in Equation (
5), to ensure that the exponent is extremely small.
where
becomes extremely small for a fairly large value of
m. More specifically, the larger the variable
m is, the closer the exponent
B is pushed to the origin. Consequently, the approximation using the Taylor polynomial in Equation (
3) is more accurate. However, from the hardware designer’s perspective, a higher accuracy comes at the cost of increasing hardware resource utilization. Therefore, this study empirically sets
m to ten (
) to balance this trade-off. Additionally, Equation (
5) is slightly re-arranged to facilitate the subsequent hardware implementation, resulting in the floating-point description in Equation (
6).
Figure 4 provides a first and rough insight into the hardware utilization of the GC’s approximation based on the floating-point description. Because the logarithmic operation drops down the exponent
, the problem that hinders the reconfigurability of GC is remedied. The computation of
is attainable by pre-calculating all input–output pairs and storing the results in the on-chip memory (RAM). This type of implementation is reconfigurable because the memory contents can be updated at the run-time. Concerning the remaining operations, adders and multipliers suffice for a fast and compact implementation. At first glance, the GC’s approximation in
Figure 4 requires a small RAM, four adders, and fifteen multipliers, which is relatively small compared with common operations such as division and square-root.
As mentioned earlier in
Section 1, the floating-point description per se suffices for the hardware implementation. This type of hardware design is typically synthesized using C-like languages, such as C2Verilog [
24] and Handle-C [
25], and the time to market can be shortened significantly. Nevertheless, these high-level languages share two common problems pertinent to concurrency and timing control, as pointed out by Edwards [
26]. As a result, Verilog (IEEE Standard 1364-2005) [
6] and VHDL (IEEE Standard 1076-2019) [
27] are still the main means for realizing signal processing algorithms in reconfigurable devices. Additionally, researchers and practitioners often leverage pipelined architectures and fixed-point representation to gain maximum benefits from Verilog and VHDL hardware description languages. The former refers to a set of processing elements that are connected in series and executed in parallel. This type of data processing scheme optimizes the throughput and thus improves processing speed [
28]. Meanwhile, the latter refers to a particular technique for representing fractional values using binary numbers. This representation style reduces resource utilization and results in a compact hardware design. This study will describe these two relevant techniques in the following subsections.
5.2. Fixed-Point Description
The fixed-point description refers to a particular step in the hardware implementation phase, where each signal within the design is represented by a fixed number of bits (henceforth referred to as the signal’s word length interchangeably). The objective is to minimize the signal’s word length while retaining an acceptable accuracy compared with the floating-point description.
Fixed-point number representation is useful for representing fractional numbers in low-cost embedded
μPs and
μCs, where floating-point processing units are excluded to ensure low power consumption and low market price. Although fixed-point numbers are actually integer numbers, a “virtual” binary point is used to implicitly scale the numbers by a specific factor. For example, the binary number
represents the decimal value
. By adding a virtual binary point in the middle
, the represented decimal value becomes
, as illustrated in
Figure 5. The numbers of bits to the left and the right of the virtual point are called integer bits and fractional bits, respectively. For representing fixed-point numbers with corresponding word length, several notations have been developed. This study adopts the <
> notation of the LabVIEW programming language [
29]. In this format,
s serves as an indicator signifying whether the number is unsigned or 2’s complement signed. Accordingly, it is either + or ±, respectively. The remaining
p denotes the word length, with
i being the integer part. Following this notation, the fixed-point number in
Figure 5 can be expressed as <
>.
The conversion from a real-valued floating-point number
X to its corresponding fixed-point value
is shown in Equation (
7). The
notation denotes the floor function (or round toward minus infinity), the subtraction
denotes the number of fractional bits, and
denotes the sign function–defined in Equation (
8). In the definition of Equation (
7), the round operation implicitly rounds the value
away from zero to the nearest integer with a larger magnitude, conforming with MATLAB R2019a’s definition. This type of rounding allows using MATLAB R2019a for fixed-point conversion, shortening the design time significantly.
The goal of fixed-point design is to determine the word length of all signals in the design so that the output error remains within a pre-determined tolerance. In general, this error tolerance is
LSB for eight-bit image data. However, this study places the virtual point ahead of those eight bits to represent the normalization of image data. Accordingly, the bit position to calculate the error tolerance is at the eighth bit of the output. Given the error tolerance, the range of
is another requisite for evaluating the output error. As discussed in
Section 2.1,
takes on positive real values that can theoretically increase to infinity. However, when
becomes too large, most image data appear too dark to be discernible. In addition, a large number of bits is also required to represent the image data in that case, but current display devices are unable to support such image data. Consequently, this study empirically sets
’s word length to
, signifying that
ranges from zero to
at a step of
.
Figure 6 demonstrates the output error for all
values, and it is easily noticeable that the error varies within the tolerance of
LSB. The detailed information about the word length of internal signals is illustrated in the data path in
Figure 7. This data path serves as a blueprint for designing the hardware implementation.
In
Figure 7, the input data are
and
with the corresponding word lengths of <
> and <
>, while the output data is represented by
, whose word length is <
>. Control signals include the clock, reset, horizontal active video, and vertical active video. They are used to ensure the synchronous operation and are denoted as Clock, Reset, hav, and vav in the bottom-left corner of
Figure 7. At the beginning of the data path, two multiplexers are employed to discard the zero values of
and
because
is undefined and
is meaningless. After that, the data flow is analogous to that depicted in
Figure 4, except that addition, multiplication, division, and square operations are now realized by digital circuits. Notably, although the split multiplier is functionally identical to the multiplier, it is pipelined to ensure a high throughput when multiplying numbers with large word lengths.
5.3. Hardware Implementation
Given the fixed-point description in the form of the data path in
Figure 7, Verilog hardware description language is used to describe the hardware implementation. Because most of the operations are simple, this section solely focuses on the reconfiguration of the logarithmic function, which is realized by RAM, and the split multiplier, which pipelines the multiplication to achieve real-time processing.
Figure 8 depicts the block diagram of the hardware verification, whose top-left portion is the RAM’s content updating scheme. It is noteworthy that the RAM-based implementation of the logarithmic function enables run-time reconfigurability; that is, the RAM’s content can be updated dynamically. However, before describing how to update the RAM’s content in more detail, it is necessary to look quickly at the hardware verification. In
Figure 8, the host computer is the master, which executes the “C platform” to provide the graphical user interface (GUI). Through the GUI, the “C platform” captures user-defined parameters and input data–including the RAM’s content and image data. It then writes that body of data to the DDR4 memory via the universal serial bus (USB) communication. As a result, the quad-core ARM
® Cortex™-A53 processor on the Zynq UltraScale+ MPSoC ZCU106 Evaluation Kit (Xilinx Asia Pacific Pte. Ltd., Singapore, Singapore) (the slave in this hardware verification) can fetch the data. The “controller”, in turn, interacts with the ARM
® Cortex™-A53 processor to obtain user-defined parameters and input data from DDR4 memory. At this time, the “controller” writes the RAM’s content to the on-chip RAM while also writing the image data to the read buffer memories located in the “double buffering interface”. After that, the “user design”, which contains the proposed run-time reconfigurable GC, retrieves the results of the logarithmic function from the on-chip RAM and processes the image data. Finally, the processed data are written back to the write buffer memories in the “double buffering interface” before the “controller” writes them to DDR4 memory. Therefore, the “C platform” can obtain the processed data via USB communication to display to the user.
Concerning the RAM’s content updating scheme, the “controller” uses the retrieved RAM’s content from DDR4 memory as “write data”. Meanwhile, it leverages a counter to generate the “write address” and enables the “write enable”. It then routes the “write address” to the address port of the on-chip RAM via the “select” signal. Most importantly, the “controller” utilizes the vertical active video signal to ensure that the write operation occurs during the vertical blank period—the time between the end of a frame and the beginning of the next frame—to avoid data corruption. For the read operation, the “controller” now disables the “write enable”, while the “logic circuits” uses the image data as the “read address”. The “controller” then routes the “read address” to the address port of the on-chip RAM via the “select” signal. Therefore, the “logic circuits” can retrieve the requisite results of the logarithmic function for processing the image data. Hence, this RAM’s content updating scheme, coupled with the Taylor-series-based approximation of the exponential function, results in the full reconfigurability of the proposed design at the run-time.
Another aspect to consider is the real-time processing capability. As depicted in
Figure 7, timing violation is highly likely to occur in multipliers owing to the large word length of operands. In this study, the multiplication is pipelined, as depicted in
Figure 9. Firstly, the
M-bit multiplicand and
N-bit multiplier are arbitrarily split into halves. The distributive and associative laws are then applied to break the original multiplication into four smaller parts. This process is demonstrated in Equation (
9), where
Q,
A, and
B denote the product, multiplicand, and multiplier, respectively. The multiplicand is separated into
-bit
and
-bit
parts in that equation, and so is the multiplier whose two parts are
-bit
and
-bit
. The derived addition operations (for example,
) are then performed judiciously so that the hardware synthesis tool does not infer unnecessarily large adders. In the previous example,
is equal to
padded with
zeros to the rear. Therefore, the corresponding
LSBs of
can be wired directly to the register containing the sum. It is only necessary to add the remaining bits of
to
and store the result in the corresponding location in the sum register.
In practice, real-time systems in real-world applications typically handle RGB image data. Therefore, this paper first presents two “user design” architectures—illustrated in
Figure 10—to seek out the most efficient design that facilitates the integration into existing real-time systems. After that, it presents a comparative evaluation that assesses this chosen design against two conventional approaches discussed in
Section 4. In
Figure 10a, the proposed run-time reconfigurable GC is applied to the red, green, and blue image channels separately; hence, this design is named RGB-GC. By contrast, the architecture in
Figure 10b first converts the input image to the YCbCr color space and then applies GC to the luminance channel only; therein lies the name YCbCr-GC. This architecture also leverages the chrominance subsampling [
30] to convert the standard 4:4:4 YCbCr data into 4:2:2 format, reducing the hardware resource utilization for chrominance processing/storage. At first glance, the YCbCr-GC appears to be more compact and efficient than the RGB-GC. However, a detailed discussion on this issue will be presented at the end of this section to avoid rambling.
5.4. Implementation Results
The implementation results are summarized in
Table 1, where slice registers, LUTs, and RAM36X1Ss are referred to as primitives—the simplest design elements in the Xilinx libraries. More precisely, slice registers and LUTs denote the logic area, while RAM36X1Ss denote the memory area. These quantities represent the area that the design will occupy on the target device. As demonstrated in
Table 1, the two designs in
Figure 10 are relatively compact and fast, as witnessed by a small hardware utilization and high operating frequency. More specifically, the RGB-GC utilizes, respectively,
,
, and
of slice registers, LUTs, and RAM36X1Ss, while the corresponding percentages of the YCbCr-GC are
,
, and
. Moreover, the fractional numbers of RAM36X1Ss utilized in the two design are worth an explanation. RAM36X1S is a 36 KB block RAM that can be configured as a total 36 KB RAM or two 18 KB RAMs [
31]. In the proposed run-time reconfigurable GC, the RAM’s content is the pre-calculated values of
—which have a word length of 14 bits; thus, it requires
KB. Consequently, the RAM-based implementation of
is mapped to an 18 KB RAM of RAM36X1S. In other words, it occupies half of RAM36X1S or
RAM36X1Ss. Therefore, the RGB-GC instantiates three GCs for red, green, and blue channels; hence, it utilizes
RAM36X1Ss. In contrast, the YCbCr-GC utilizes
RAM36X1Ss because it only instantiates one GC for the luminance channel. So, from the implementation results, it can be concluded that the YCbCr-GC is faster and more compact than the RGB-GC. It is also observed that the YCbCr-GC consumes less power than the RGB-GC, as demonstrated by the worst-case power consumption—which is a sum of static and dynamic power reported by Xilinx Vivado v2019.1 for worst-case operating conditions.
Furthermore, the maximum processing speeds (
MPSs)—calculated using Equation (
10) and tabulated in
Table 2—demonstrate that these two designs can, respectively, process DCI 4K video at
and
fps. These results satisfy the real-time processing requirement of 30 fps for both PAL and NTSC color encoding systems [
32]. In Equation (
10),
denotes the maximum operating frequency,
denotes the image’s height and width, and
denotes the vertical and horizontal blanks. It is worth noting that Xilinx Vivado v2019.1 does not provide the maximum operating frequency in the implementation report. Instead, this information was derived from the target clock period (
T) and worst negative slack (
), as shown in Equation (11). In this study, both hardware designs can operate properly with
of at least one image line and one image pixel. Thus, the implementation results presented herein demonstrate that those two designs are highly appropriate for high-speed and high-quality image processing applications, both in standalone operation and in cooperation with other systems.
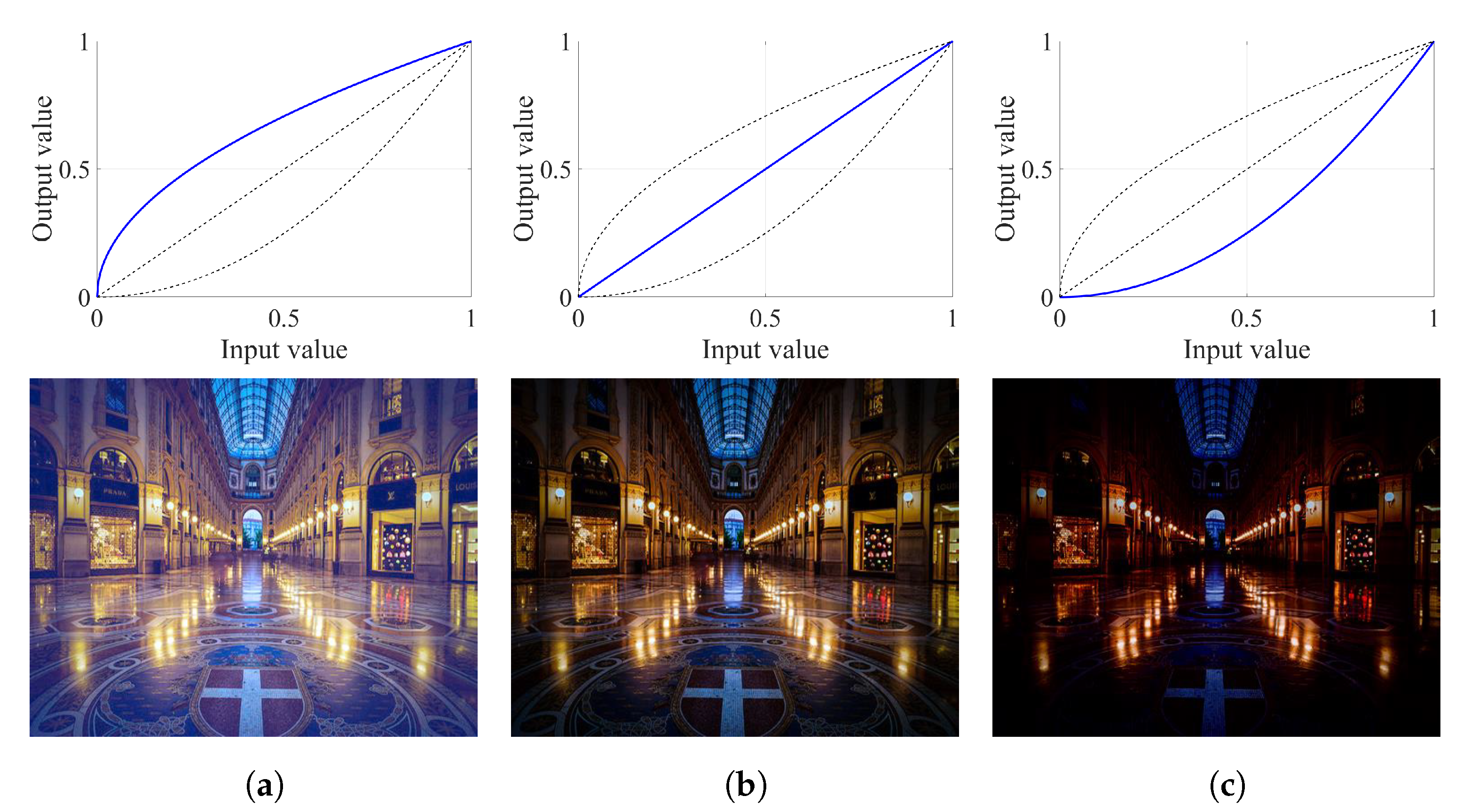
Figure 11 demonstrates a qualitative comparison between these two designs and the reference floating-point versions. As illustrated in
Figure 11, the results of RGB-GC and YCbCr-GC are slightly different. However, this difference is insignificant because the
parameter can be freely adjusted using the proposed architecture. Therefore, users can fine-tune the
parameter to obtain the desired results. In addition, the hardware implementations are designed based on the fixed-point descriptions, which in turn are derived from the floating-point references with the error tolerance of
LSB. Hence, the difference between the results of RGB-GC and YCbCr-GC and their corresponding floating-point references (denoted as RGB-GC ref. and YCbCr-ref.) is indiscernible. This qualitative comparison, coupled with the implementation results, demonstrates the efficacy of the YCbCr-GC design.
Finally, the YCbCr-GC is compared against two conventional designs of GC—which employ LUTs and piecewise linear polynomial approximation.
Table 3 summarizes the implementation results of these three designs in two cases where the gamma parameter is fixed and freely adjustable. The designs that employ LUTs and piecewise linear polynomial approximation are denoted as LUT-based GC and PLPA-based GC, respectively. In addition, because Lee et al. [
23] provided the implementation results of these two benchmark designs in case the gamma parameter was fixed, this study reuses those data. In case the gamma parameter is freely adjustable, this study employs the reported data by Lee et al. [
23] to calculate the corresponding memory utilization. In this case, for a fair comparison, the adjustable range of the gamma parameter is from zero to
at a step of
. As the gamma value of zero does not require any calculation, this range includes 255 different gamma values. Therefore, the LUT-based GC must be equipped with additional 255 LUTs to support adjusting the gamma parameter. Meanwhile, Lee et al. [
23] have to add another 255 polynomial coefficient tables to their PLPA-based GC. Hence, these two designs suffer from a heavy memory burden as they require approximately 1 MB and 25 KB. By contrast, the proposed YCbCr-GC can handle both cases without any additional modifications.
A correction step is necessary for slice utilization because the YCbCr-GC and two benchmark designs are implemented on two different FPGA devices. Lee et al. [
23] implemented the LUT-based and PLPA-based GC on a Xilinx Virtex-4 XC4VLX100-12 device, whereas this paper presents the implementation results of the YCbCr-GC for the Xilinx UltraScale XCZU7EV-2FFVC1156 device. According to the data sheets [
33,
34], a slice of the former device consists of eight LUTs and eight registers, while a slice of the latter device comprises eight LUTs and sixteen registers. As a result, 2686 slice registers and 9887 slice LUTs in
Table 1 are converted into 1236 slices in
Table 3. For two benchmark designs, they require a great number of LUTs and registers to handle the case where the gamma parameter is freely adjustable. Those added resources are primarily for routing the internal data according to the gamma parameter. However, because it is impossible to calculate the exact numbers without re-implementing benchmark designs by hand,
Table 3 represents them as not available (NA). Therefore, in case the gamma parameter is fixed, the PLPA-based GC is the best design. Conversely, in case the gamma parameter is freely adjustable, the proposed YCbCr-GC is the most efficient. Additionally, because fixing the gamma parameter severely limits the practicality, it can be concluded that the proposed YCbCr-GC is superior to the two benchmark designs.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}