1. Introduction
With the rapid development of artificial intelligence technologies, the research and application of unmanned platforms, such as robots, has become a research hotspot. The question of how to endow machines with higher autonomy and adaptability is an important goal in current research. The navigation of mobile robots has always been one of the most basic tasks in the field of robotics [
1,
2,
3,
4]. The classic navigation control method used for robots is based on the establishment of an environment map, positioning using sensor (such as GPS and IMU) information, and finally path planning and tracking [
5,
6].
In recent years, with the rise of deep learning (DL), research on using DL to achieve end-to-end autonomous navigation of mobile robots has become a popular topic. However, navigation methods based on DL not only require the robot to accurately position itself but also require a large amount of human prior knowledge. This is not in line with the human way of thinking. Therefore, the question of how to give robots self-learning and self-adaptive capabilities in navigation control, as well as how to teach them to use visual information to control their behavior, is a problem worth studying.
Reinforcement learning (RL) relies on interaction and feedback between agents and the environment, prompting agents to constantly update their own strategies and thereby improving their ability to make decisions and control their own behavior [
7,
8,
9]. The visual navigation method based on RL does not require knowledge of the accurate real-time position of the robot but can realize end-to-end action outputs based on inputting the current observation image. This method is similar to the way of human thinking—using continuous trial and error training in the environment to adjust the strategy and, thereby, improving the navigation control ability.
However, RL is currently facing many problems. The use of constant trial and error causes a low RL data utilization rate, requires a great deal of training time, makes it difficult to properly set the reward function for different tasks, and causes the adaptability and transfer ability of scene changes to be poor. Imitation learning makes use of expert data to provide certain guidance for agents, thereby, improving the training efficiency and adaptability of RL. The common methods of imitation learning include supervised regression [
10] (such as behavioral cloning [
11]), inverse reinforcement learning (IRL) [
12], and direct strategy interaction [
13]. IRL makes use of the reward function from the expert trajectory or expert strategy to guide the update of the strategy.
In previous research, mobile robot navigation based on IRL has been realized. This type of navigation can obtain the reward function from the expert trajectory and provide more accurate feedback for navigation control strategies for robot training, thereby, speeding up the training speed of the algorithm, improving the accuracy of navigation control, and making the navigation path closer to the optimal path [
14,
15,
16]. However, IRL still has certain limitations.
The improvement of the navigation performance is based on the reward function obtained from the target point corresponding to the expert trajectory. For target points without expert trajectories, the navigation effect of the algorithm will be reduced, which means that the generalization ability of the model will not be strong. For a robot navigation algorithm that can be applied in reality, in addition to accurate navigation and control capabilities for trained targets, it also needs to have good migration and generalization capabilities for unknown environments and tasks. Therefore, designing an algorithm that improves the generalization performance while maintaining navigation control accuracy would be an important research development.
To solve this problem, this paper proposes an IRL navigation control method based on a regularized extreme learning machine (RELM-IRL). First, the IRL is used to calculate the reward function from the expert trajectory. Then, the ELM is used to perform regression analysis on the reward function of the expert trajectory in order to obtain a more accurate reward function. Finally, the regularized ELM further improves the generalization ability of the model. The experimental results show that, compared with the traditional RL and IRL, the IRL navigation control method based on a regularized ELM had better generalization and migration capabilities and could navigate to the target point more accurately.
We highlight the main novelty and contribution of this work compared with existing mobile robot navigation methods as follows:
A framework combining extreme learning machine with inverse reinforcement learning is presented. This framework obtains the reward function directly from the image information observed by the agent and improves the generation to the new environment. Moreover, the extreme learning machine is regularized by multi-response sparse regression (MRSR) and leave-one-out (LOO), which can improve further improve the generalization ability.
Simulation experiments show that the proposed approach outperformed previous end-to-end approaches, which demonstrates the effectiveness and efficiency of our approach.
The remainder of the paper is organized as follows: we introduce the related work in
Section 2 and review the research background in
Section 3. Our approach is proposed in
Section 4. Experiments in the AI2-THOR environment are evaluated, and the results are discussed in
Section 5. Finally, our conclusions are drawn in
Section 6.
2. Related Work
IRL was originally proposed by Ng.A.Y and Russell, who discussed three aspects: IRL in finite state space, IRL in infinite state space, and IRL sampling trajectory [
17]. In 2004, Abbeel and Ng.A.Y proposed a new method of IRL—apprenticeship learning [
18]. In this method, the reward function is established through the expert example, so that the optimal strategy obtained by the reward function is close to the expert example strategy. The maximum marginal programming (MMP) algorithm is similar to apprenticeship learning using linearized rewards in that it finds a strategy that makes the expert trajectory under this strategy better than the other generated trajectory and minimizes the cost function between observation and prediction [
19].
Ratliff proposed the LEARCH algorithm by extending the maximum marginal planning and applied it to outdoor autonomous navigation. Bayesian IRL uses a Bayesian probability distribution to deal with ill-posed problems [
20]. It samples the state-behavior sequence from the prior distribution of the possible reward function and calculates the posterior of the reward function using Bayes. Similar to Bayesian IRL, maximum entropy IRL uses a Markov decision model to calculate the probability distribution of state behavior [
21]. It focuses on the distribution of trajectories rather than simple actions.
Zhu [
22] proposed a target-driven model based on an actor–critic structure for mobile robot navigation control. It takes the observation image of the camera as the input of the model and the control instructions of the agent as the output, thus, realizing end-to-end navigation indoors. At the same time, the target image and the currently acquired image are combined to improve the generalization ability of the model. In 2019, Mitchell Wortsman designed an improved navigation model using meta-learning and self-supervised learning based on the “object-driven model” [
23]. It can update the network model by providing additional gradients for itself through its internal self-supervised network, which greatly improves the performance of the model and enhances the generalization.
In addition, some researchers have used depth images as inputs to train agents. For example, Li K used depth images to realize the robot’s navigation and obstacle avoidance function [
24]. In terms of images, some researchers combined the attention mechanism and image segmentation technology to provide additional navigation information for the agent. For example, Keyu Li and Yangxin Xu improved the attention RL algorithm by introducing a dynamic local goal setting mechanism and a map-based safe action space to achieve navigation in an indoor environment [
25].
Researchers have explored many ways to improve the generalization performance of mobile robot navigation control. K Cobbe trained an agent using multiple environments with different appearances and layouts, hoping to allow the agent to learn a wider range of strategies by training it on as many environmental tasks as possible [
26]. Experiments showed that, as the number of Markov decision processes used for the training increased, the success rate of the agent in unknown new tasks gradually increased. This shows that the generalization performance of the model was improved.
K Lee used a clever image enhancement method to improve the generalization of a model. By inserting a random convolutional layer between the environmental input image and the policy decision, the input image could be randomly converted into the expression of different features before each batch of training starts. Different but similar inputs can help the model understand subtle changes in the environment and learn more general strategies. In addition, using meta-learning [
27] and transfer learning [
28,
29] to improve the generalization performance of the model is also an important research direction.
3. Background
In this section, we will provide some background to our chosen approach. Since our approach is based on a combination of inverse reinforcement learning (IRL) and extreme learning machines (ELMs), we will briefly introduce the IRL first and then detail the ELM.
3.1. Inverse Reinforcement Learning (IRL)
Inverse reinforcement learning involves learning the reward function from expert data. We assume that when experts complete a task, their decisions are usually optimal or nearly optimal. When the cumulative reward function expectations generated by all the strategies are not greater than the cumulative reward function expectations generated by the expert strategy, the reward function of RL will be the reward function learned from the expert data. Apprenticeship learning [
30,
31] is a type of IRL, which sets the prior basis function as the reward function. This ensures that the optimal strategy obtained from the reward function is near the expert strategy using the given expert data. We suppose the unknown reward function:
where
is the basis function. At this time, the IRL requires the coefficient
w. This is defined by the value function:
Combining Equations (1) and (2), we can obtain:
Among these, represents the cumulative value of a certain dimension mapping feature, and d represents the number of dimensions of w.
According to the definition of the optimal strategy, we know that, in each state, the value function of the optimal strategy
should not be weaker than the value function of other strategies. This means that:
Our ultimate goal is to find the best reward function to maximize the value of the optimal strategy:
where
represents the strategy of taking action a at state s. In addition, we add two constraints to the objective function:
(1) We limit the size of the reward function. For the linear programming problem, we set a restriction on the reward value:
(2) We only consider the differences between the optimal strategy and a sub-optimal strategy. Considering the diversity of strategies and the influence of other strategies on the calculation error, we only consider the gap between the optimal strategy and the sub-optimal strategy:
Among these, we first find the sub-optimal strategy closest to the optimal strategy and then obtain the reward function by maximizing their gap.
3.2. Extreme Learning Machine (ELM)
The extreme learning machine (ELM) was proposed by Professor Huang Guangbin from Nanyang Technological University in 2004 [
32]. As shown in the figure, it is the same as a single hidden layer feedforward neural network consisting of an input layer, a hidden layer, and an output layer. However, an innovative point and advantage of the ELM is that it randomly initializes and fixes the weight vector
W and the bias vector
b between the input layer and the hidden layer.
It does not need to be updated according to the gradient in the subsequent training, which greatly reduces the amount of calculation needed. Secondly, it can directly determine the weight vector between the hiddELMen layer and the output layer through the method of least squares or inverse matrix, without iterative update, thus, speeding up the calculation. Research shows that, under the condition of ensuring accuracy, the learning speed and generalization performance of the ELM are better than those of the traditional neural network.
Figure 1 is an ELM with
L hidden neurons. There are
N samples
in the training set, where
is the input and
is the output—that is, the label. For the input Xi, the function output after the hidden layer can be expressed as:
where
w is the weight, representing the strength of the connection between neurons, and
b is the bias, with
w and
b being randomly initialized and fixed before the network training.
is the activation function, and
is the output of
i-th hidden layer neurons. The final output can be expressed as:
The final expected result of the neural network is the minimum error between the output and the label, which is:
This means that there are
,
, and
, such that:
This is expressed as a matrix:
where
is the weight of the output layer and
T is the expected output, which is the label provided by the data set.
H is the output of the hidden layer, which can be expressed as:
The output weight and the desired output can be expressed as:
Traditional gradient descent neural networks usually iterate the network parameters
w and
by minimizing the loss function as follows:
In the ELM, the values of
w and
b are fixed, meaning that the value of
H is also uniquely determined. Therefore, the optimal
value can be obtained by inverting the matrix:
where
is the generalized inverse of matrix
H, and it has been proven that the solution is unique. Compared with the ordinary single hidden layer feedforward neural network, ELM guarantees the accuracy, reduces the amount of calculation by fixing the parameters of the input layer and enables
to be directly obtained in a linear manner. This greatly improves the calculation speed, while also improving the generalization performance of the model.
4. Our Approach
In this section, the design of a navigation algorithm based on IRL and regularized ELM to improve the navigation performance of a mobile robot is described. As shown in
Figure 2, the algorithm structure we designed consists of three parts: the first part is a general feature extraction part, which uses resnet-50 to extract the features of the training scene; the second part is based on regularized ELM-IRL, using regularized ELM-IRL learning expert data rewards, as part of the input of the RL; the third part is an Asynchronous Advantage Actor-Critic (A3C) network [
33]. It uses the fusion features of the fully connected layer and the reward function calculated by the regularized ELM to train the agent’s action strategy.
During training, we first train the IRL part of the algorithm. The reward function is calculated by sampling several expert trajectories in different scenarios. On the other hand, the environment provides the current state image and the target image observed by the agent. These are mixed through the feature extraction network to obtain the state vector. Each time the agent takes an action, the parameters solved by the IRL and the features of the fully connected layer provide reward feedback together as the update source of the policy network and the value network parameters.
4.1. Mobile Robot Navigation Control Based on IRL
After IRL has obtained the reward function parameters w calculated by the expert trajectories of different target points, the RL based on A3C can begin to train the agent action strategy. The A3C algorithm is based on the actor–critic structure and adopts asynchronous multi-threading. At the beginning, multiple training threads are created at the same time. Each training thread corresponds to a task. At the same time, it initializes its own network parameters and assigns them to each sub-thread. After that, all sub-threads are turned on in parallel and the gradient is accumulated in different tasks and environments. When the sub-threads themselves are updated, the gradient accumulation of all the sub-threads is used to update the A3C total parameters.
After a batch of iterations, the total parameters are again assigned to the sub-threads and a new round of iterative training is started. Since the threads are independent of each other and all threads update the global network together, this method can eliminate inter-sample correlation and improve the training speed. Each thread corresponds to a training task—that is, it navigates to a certain target point in the scene. During training, the input is the current state image and target image observed by the camera.
After the feature extraction part of the network, the mixed state feature is obtained. Then, the value function network and the strategy network generate value estimation and action prediction. After the execution of the action, according to the weight value of w obtained in the IRL part combined with the current input state feature vector to obtain the reward value and feedback to the network, the value network and policy network parameters can be updated. After a certain number of iterations have occurred, the network will reach convergence. The overall algorithm flow is as shown in Algorithm 1.
For each state of the agent, its state value function can be expressed as:
For any action made by the agent, there is also a state–action value function to evaluate the pros and cons of the action:
In training, the value function of each step is estimated by the value network, and there is no need to wait for the end of a test to calculate the value function. This means that the network can be updated in one step, which improves the efficiency. The error of calculating td is:
The policy network update formula is:
The value network update formula is:
| Algorithm 1 Robot navigation algorithm based on IRL |
Initialization parameters:: Global network strategy function, value function parameter
:Threaded network strategy function, value function parameter
- 1:
repeat - 2:
- 3:
- 4:
- 5:
Random initialization starting point - 6:
repeat - 7:
Select action a according to strategy function ; - 8:
Execute a to get the next state ; - 9:
; - 10:
; - 11:
until terminal or - 12:
- 13:
for i do - 14:
Calculate the reward value r of the environment feedback based on ; - 15:
; - 16:
Update value function parameters: - 17:
Update strategy function parameters: - 18:
end for - 19:
until
|
4.2. Reward Function Design Combining ELM and IRL
In order to solve the limitations of the IRL-based robot navigation algorithm in new tasks and new scenarios, it is necessary to improve the generalization performance of the algorithm. We used the state vector obtained from the current image and the target image to train the ELM, meaning that the reward function can be adjusted in real time according to the current state and the change in the target image during training, thus guiding the agent to navigate to the target point.
Traditional neural networks based on gradient descent usually update the network parameters by minimizing the loss function.
where
w is the weight, which represents the strength of the connection between neurons;
b is the bias; and
is the weight of the output layer. In the ELM, since the values of
w and
b are fixed, the output
H of the hidden layer is also uniquely determined. Therefore, the optimal
value can be obtained by inverting the matrix:
Here, is the generalized inverse of matrix H. It has been proven that the obtained by solving is unique. Compared with the ordinary single hidden layer feed-forward neural network, the ELM not only guarantees the accuracy, but also reduces the amount of calculation by fixing the parameters of the input layer and enables to be directly obtained in a linear manner. This greatly improves the calculation speed, while also improving the generalization performance of the model.
Although each expert trajectory is the optimal path from the start point to the end point, each trajectory has its own characteristics. The parameters of the reward function are different for different trajectories. In order to obtain a network that can better calculate the reward function through ELM training, it is necessary to analyze the part of the expert trajectory that has the greatest impact on the performance of the model. However, the parameters obtained from the expert trajectories of different target points only greatly improve their own navigation effect.
For trajectories with the same target point but different starting points, the obtained parameters improve the performance of the model, and the gap between them is very small. Considering the diversity of the intermediate process of the trajectory, we use the starting point and target point of the trajectory as the input of the ELM and the corresponding reward function parameters as the expected output of the ELM. The ELM is trained by sampling multiple expert trajectories with different starting points and target points, meaning that it can more accurately predict the reward function parameters of the new starting point and target point as the feedback of the model. Part of the network structure is shown in
Figure 3, for each training target point several expert trajectories with random starting points are collected, including all state points
s and actions
a on the optimal path from the random starting point to the target point, which are recorded as an action–state pair
. We then use the IRL to solve the corresponding reward function parameter
W, where
W is a high-dimensional vector that is denoted as
.
We extract the image features of the start and end points of each trajectory in the expert trajectory as the input data of the ELM and the corresponding reward function parameter w as the expected output. According to the ELM training method, we train the ELM to obtain the final parameter . After this, the obtained ELM model is saved and, thus, the reward function parameter prediction network model combining the ELM and IRL is obtained. Through the trained ELM model, the starting point and target point of each task can be predicted. A more accurate expert reward function is designed to expand the scope of application of the previous model while at the same time improving the generalization performance of the model.
4.3. Regularized ELM
The ELM is trained with expert data, enabling the model to predict the reward function parameter w according to the current state and the target point state, imitating the process of IRL to solve the parameters from the expert trajectory. However, as mentioned in the previous chapter, due to the high dimensionality of the data that need to be fitted, a large number of expert trajectories are needed to ensure the accuracy of the ELM predictions, which hinders the promotion and application of the model. On the other hand, in the face of large-scale data, ELM has the defect of a weak robustness and is easily affected by some interference data, which will cause large errors in the regression and make the model more complicated.
Therefore, we propose to use an algorithm based on regularized ELM to obtain a model with fewer parameters that is more concise and has a stronger generalization performance. As shown in
Figure 4, the ELM model can be optimized by the regularization method. First, we complete the training of the ELM. After the training is completed, the MRSR is used to sort the hidden layer neurons. Afterward, in order to determine the optimal number of neurons to retain, LOO is used to verify the optimal model structure, then finally the optimal model structure and the trained model are obtained.
4.3.1. Multi-Response Sparse Regression to Screen Hidden Layer Neurons of ELM
In order to reduce the complexity of the model and improve the generalization performance of the model, the method of multi-response sparse regression (MRSR) is used to sort the hidden layer neurons and the sorting criterion is the degree of influence of neuron output. Suppose a target variable
; the matrix size is
; and the input data
are a matrix of
—that is, the regression variable. The idea of MRSR is to use the following formula to cause
Y to tend toward
T:
where
is the weight coefficient matrix of the
k-th step, with
k non-zero row vectors in the
k-th step, while
is the target variable estimated by
W and the regression variable
X. At each step, MRSR will replace a zero row vector of
W with a non-zero row vector through calculation, which is equivalent to selecting one of the regression variables
X and adding it to the model. When
Y is a row vector—that is, when the model has a single output—the multi-response sparse regression degenerates to the smallest angle regression (LARS), meaning that MRSR can be seen as an extension of LARS.
Initially,
,
and
are set to zero matrices, and we normalize
X and
T. At this time, we define the cumulative correlation between the
j-th regressor
and the current residual:
When it comes to step
k, we first calculate the cumulative correlation
c between all the candidate regression variables and the current residuals. The aim of this is to find the regression variables that are most relevant to the current residuals. We define the maximum cumulative correlation at this time as
, and the set of candidate regressions that satisfy the maximum cumulative correlation is
A. Thus,
We recombine all the regression variables in
A into a matrix
of
and calculate its least squares estimate:
After calculating
, one can update
:
where
is the search step size of the
k-th step. At the same time, according to the above formula, we can obtain:
Combining Formulas (27), (29) and (30), we can obtain:
Among them,
,
. When there is a regressor
of
that makes the above two equations equal, this regressor will be added to the model in step
, and the regression coefficient matrix will be updated as follows:
where
is a sparse matrix of
, its non-zero row order corresponds to
, and the value of non-zero rows is determined by the row vector corresponding to
by the least square estimation. This can sort the regression variables.
4.3.2. Leave-One-Out Is Used to Determine the Optimal Number of Neurons to Retain
Since the MRSR only provides a ranking of the effects of each neuron on the output, it is still uncertain how many neurons are retained to minimize the error and achieve the best model effect. Therefore, LOO is used to make a decision regarding the actual optimal number of neurons in the model:
where
represents the error,
P can be represented as
, and
H is the hidden layer output matrix of the ELM.
represents the output after the
i-th neuron is added, and
and
represent the weight and bias of the ELM input layer, respectively. After obtaining the order of the importance of neurons to the output, the number of neurons suitable for the model can be determined by evaluating the LOO error and the number of neurons used. We continuously add neurons to the model according to their order, test the error
, and choose the lowest
as the number of neurons in the final model.
5. Experimental Results
The main purpose of the visual navigation in this paper is to obtain the best navigation performance for travelling from a random initial location to a goal location. In this section, we will train our model and evaluate the navigation results of our model against those of other baseline models on different tasks.
5.1. Experimental Simulation Environment
To effectively apply our model in different types of environments,, we use The House Of InteRactions (AI2THOR) framework proposed in [
22]. It is a highly realistic indoor simulation environment built by the Allen Institute for Artificial Intelligence, Stanford University, Carnegie Mellon University, University of Washington and University of Southern California, in which agents can complete navigation tasks by interacting with the environment. AI2-THOR provides indoor 3D synthetic scenes, such as the room categories of living room, bedroom, and bathroom.
Parts of the scene are shown in
Figure 5. In our experiments, the input includes two parts,
S = <
> and
F, which represent first-person views of the agent, where the resolution of one image is 224 × 224 × 3, and
T represents the goal. Each image is embedded as a 2048D feature vector, which is pretrained on ImageNet with Resnet-50. We consider four discrete actions: ahead, backwards, left, and right. The robot takes 0.5 m as a fixed step length, and its turning angle is 90 degrees in the environment.
5.2. Implementation Details
All of the models were implemented in the Ubuntu16.04 operation system and TensorFlow and trained/tested on an NVIDIA GeForce GTX 2070. For training, the navigation performance was assessed using 20 goals randomly chosen from indoor navigation environments in our dataset. All of the learning models were trained within 5 million frames, and it took about 1.5 h to pass one million training frames across all threads. The test ended when the robot either arrived at the goal location or after it took more than 5000 steps. For the purposes of our evaluation, we performed 1000 different tests for each scene.
In order to verify the effectiveness of our method more comprehensively, we compared the results obtained for the following three tasks:
(1) Task(I): Navigation performance achieved using the trained target points in the trained scene. The trained model was used to verify the capability of a random starting point to the target point trained in the same scene.
(2) Task(II): Navigation performance of new target points in the training scene. The trained model was used to verify the capability of a random starting point to the untrained target point in the same scene.
(3) Task(III): Navigation performance achieved using similar target points in the new scene. The trained model was used to test the capability of a random starting point to the similar target point in the new scene. This helps to verify the generalization ability of the model in a new but similar scene to the training scene. The selected target points and the training target points belong to the same category, such as bookcases, washstands, switches, flower pots, etc.
5.3. Baselines
We compared our models with the following three baseline models:
(1) Random. At each time step, the agent randomly selects an action for navigation using a uniform distribution. Note that since the performance is extremely low for Task II and Task III, in this paper we only show the results obtained for Task I.
(2)
Reinforcement Learning (RL). In this paper, we utilize the method proposed in [
22]. This baseline model updates its own strategy through constant interaction between the agent and the environment. Its reward function is set manually. This is the original target-driven method—it uses deep reinforcement learning and targets use and updates the same Siamese parameters but uses different scene-specific parameters
(3)
Inverse Reinforcement Learning(IRL). In this paper, we utilize the method proposed in [
16]. The baseline architecture is similar to ours, but it requires knowledge of the expert trajectory to generate the reward.
5.4. Evaluation Metrics
In order to evaluate the performance of our proposed method, we applied three typical evaluation indicators—Success Rate (SR), Path Length Error (PLE), and Success weighted by Path Length (SPL) [
23]—as defined by the following:
where
and
are the number of total tests and successful tests;
and
are the best path and actual path;
and
are the best path length and actual path length between the starting point and the target point; and
is a binary indicator—if the agent navigates to the target point successfully, it will be recorded as 1, while otherwise, it will be recorded as 0.
Note that, in the metrics SR and SPL, higher values represent better performance; in contrast, lower values represent better performance in PLE.
5.5. Performance Comparison
In this subsection, we focus on four results: the efficiency during training, the performance of our approach in navigating to the trained targets, the new targets in trained scenes, and the new targets in new scenes. Additionally, the baselines are evaluated for comparison.
5.5.1. Training Efficiency
As we know, training efficiency is important for deep learning-based methods.
Figure 6 shows the error between the actual path length of the agent and the best path during training. Comparison results of training process. The black, blue, and red curves represent the training process of RL, IRL, and RELM-IRL (ours), respectively. It can be seen that our approach and IRL took less time to converge—both required about 3.5 million frames to learn a stable navigation policy, while it took nearly 4 million frames to train in RL.
Moreover, from the perspective of local details, our method maintained good performance after convergence, which is better than RL and IRL, indicating that our approach learns fast to obtain the best navigation policy. The reason for this might be that we used a regularization ELM method to reduce the complexity of the model, thereby, speeding up the training.
5.5.2. Performance on Trained Targets (Task I)
To analyze the navigation performance of our approach, we first analyze the performance on the trained targets to reflect the navigation ability. The experimental results are shown in
Table 1. These are the comparative experimental results of random agents, A3C based on RL, IRL, and our method. We focus on the performance of a random agent. In the bathroom, although the probability of the random agent successfully navigating to the target point is 20% in 1000 tests, its SPL value is very low, and the error with the best path length is large.
In the bedroom and living room scenes, as the scene becomes larger, the effect of the random agent drops sharply, making it difficult to accurately navigate to the target point. This proves that it is difficult to navigate through random selection in this simulation environment, and this also illustrates the validity of the experimental verification settings. In terms of the navigation success rate, it can be seen that when the model tends to be stable, A3C based on RL, IRL, and our method accurately navigated to the target point in each test regardless of whether this is in a small range of scenes or in a large range of scenes.
However, according to the results shown in
Figure 5, it can be proven that our method can be stabilized faster. The navigation accuracy is also higher under the same number of training steps, which proves the effectiveness of our method. Combining PLE and SPL, our method performed better than IRL. This is consistent with the expected results, due to the simplified model resulting in a loss of information.
5.5.3. Generalization across New Targets in the Same Scenes (Task II)
To analyze the generalization performance of our approach, we first analyze the performance on the new targets in the same scenes (task II) to reflect the navigation ability. The experimental results are shown in
Table 2. These are the experimental results of sampling the location around the training target point in several scenes during the training of the model or the results of using the position of the obvious object in the scene as the target point.
This sampling method takes into account that there are some extremely unclear target points in the scene, such as walls, glass, or other unique environments. At these target points, no matter which model is used, it is difficult to accurately navigate to the target point. It can be seen from the table that, compared with A3C and IRL, our method can greatly improve the navigation accuracy, shorten the average path length, and increase the SPL value. For scenes, such as living rooms, the navigation effect is slightly reduced. However, overall the generalization performance of our method in training scenarios has been greatly improved. SR, PLE, and SPL have all improved. Compared with RL and IRL, the average SR navigation accuracy of our method is improved by 9% and 11%, respectively.
5.5.4. Generalization across Similar Targets in New Scences (Task III)
Moreover, in order to analyze the generalization performance of our approach, we additionally analyzed the performance on similar targets in the new scenes (task III) to reflect the navigation ability. This was conducted in order to verify the generalization ability of the model in a new but similar scene to the training scene. The selected target points and training target points belong to the same category, such as bookcases, washstands, switches, or flower pots, and the results are shown in
Table 3.
Similar to the results for Task 2, this shows that the our method can improve the generalization ability to a certain extent by reducing the complexity of the model. Compared with RL, the average SR and SPL of our method are improved by 6% and 4%, respectively. For IRL, the average SR and SPL of our method are improved by 5% and 5%, respectively. The above results demonstrate the effectiveness and efficiency of our approach.
5.6. Ablation Study
In this section, we perform ablation on our method to gain further insight into our result. The results are as follows.
5.6.1. Effect of Different Numbers of Hiddden Layer Units in ELM
Before training the ELM, we first had to determine the number of hidden layer neurons. This number is related to the speed and accuracy of the ELM. Meanwhile, when the input and output dimensions are too high, it is difficult to use a small amount of hidden neuron layer units to obtain better results; thus, the number of hidden layer units was set from low to high. As shown in
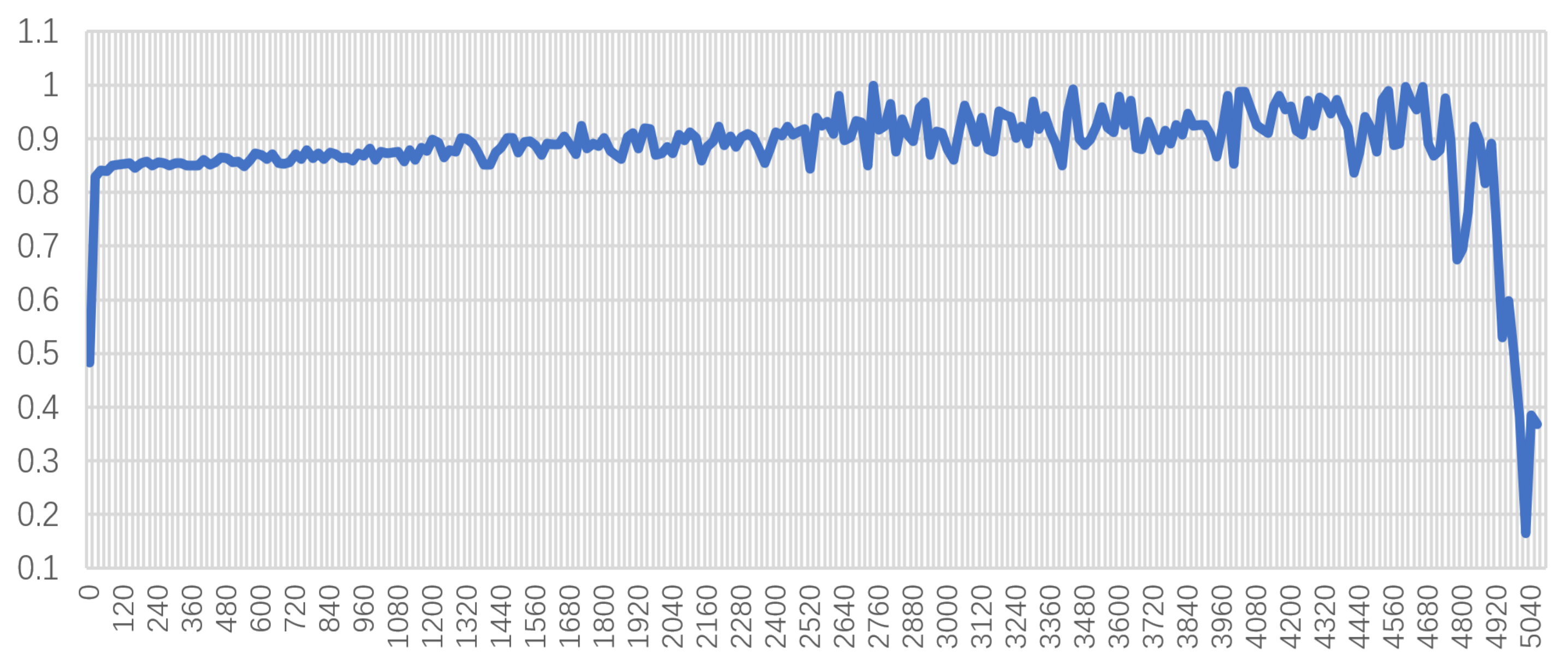
Figure 7, the number of hidden layer neurons was set from 1 to 8000. It can be seen that as the number of ELM hidden neurons increases, the test accuracy of the ELM gradually improves. When the number of neurons exceeds 1800, the accuracy fluctuates between 0.9 and 1. However, when the number of neurons exceeds 4700, the model will have large errors, and its performance will drop sharply.
Considering the complexity and computing speed obtained for the model in training, we chose to use 1950 hidden layer neurons for the experiment. The experimental results are shown in
Figure 8. The blue data points are the predicted values of the model, and the red points are the real data of the test set itself. It can be seen that the difference between the prediction of the ELM and the real data is small, which shows that after sampling training ELM can output more accurate reward function parameters according to the image, indicating the effectiveness of ELM-IRL.
5.6.2. Effect of Regularization in ELM
In the regularized ELM experiment, the hidden layer neurons are sorted by the MRSR, the sorted neurons are gradually added using LOO, and the loss function is calculated to determine the optimal number of hidden layer neurons. Since the previous regularization method MRSR only provides a ranking of the effects of each neuron on the output, it is still uncertain how many neurons should we use to achieve the good model effect under limited neurons. Therefore, LOO is used to make a decision regarding the actual optimal number of neurons in the model. Once the importance of neurons to the output has been sorted, LOO can determine the number of neurons to use according to the loss of training, continuously add neurons to the model according to the order, test the error, and choose the smallest error for the number of neurons in the final model. The experimental results are shown in
Figure 9. It can be seen that the LOO loss reaches the minimum when the number of hidden layers is 593; thus, the ELM was set to take the first 593 hidden layer units of the multi-response sparse regression to form the hidden layer.
Figure 10 shows the test results of the ELM with 593 hidden layer neurons. The blue data points in the figure are the predictions of the model, while the red points are the true data of the test set. The gap between the prediction of the ELM and the real data obtained for the sample is extremely small. Compared with the model without regularization, the prediction error is further reduced, and the change trend and amplitude are basically the same, which proves the effectiveness of the regularized ELM.
5.6.3. Navigation Performance Using ELM-IRL and RELM-IRL
In order to illustrate the generalization performance of the regularized ELM-IRL, we conducted an experiment under task III and selected SPL as the evaluation metric. The results are shown in
Figure 11. It can be seen that the performance of the ELM-IRL after regularization is better than that of ELM-IRL, which proves that the generalization ability of the model was effectively improved after regularization.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}