
Aircraft Type Recognition in Remote Sensing Images: Bilinear Discriminative Extreme Learning Machine Framework



Abstract
:
1. Introduction
- (1)
- We propose a novel aircraft recognition framework that not only inherits the characteristics of the ELM’s training speed but also relies on convolution, MRELM-AE, and bilinear pooling to construct a three-level feature extractor, as a result of which the aircraft recognition model exhibits strong discrimination features.
- (2)
- We propose a novel discriminant MRELM-AE, which adds the manifold regularization to the objective of the ELM-AE. The manifold regularization considers the geometric structure and distinguishing information of the data to enhance the feature expression ability of the ELM-AE.
- (3)
- The experimental results on the MTARSI dataset [35] show that the BD-ELMNet outperforms the state-of-the-art deep learning method in terms of its training speed and accuracy.
2. Related Work
2.1. Convolutional Neural Networks
2.2. Pooling Methods
2.3. Data Augmentation Techniques
2.4. Discriminative ELMs
3. Bilinear Discriminative ELM
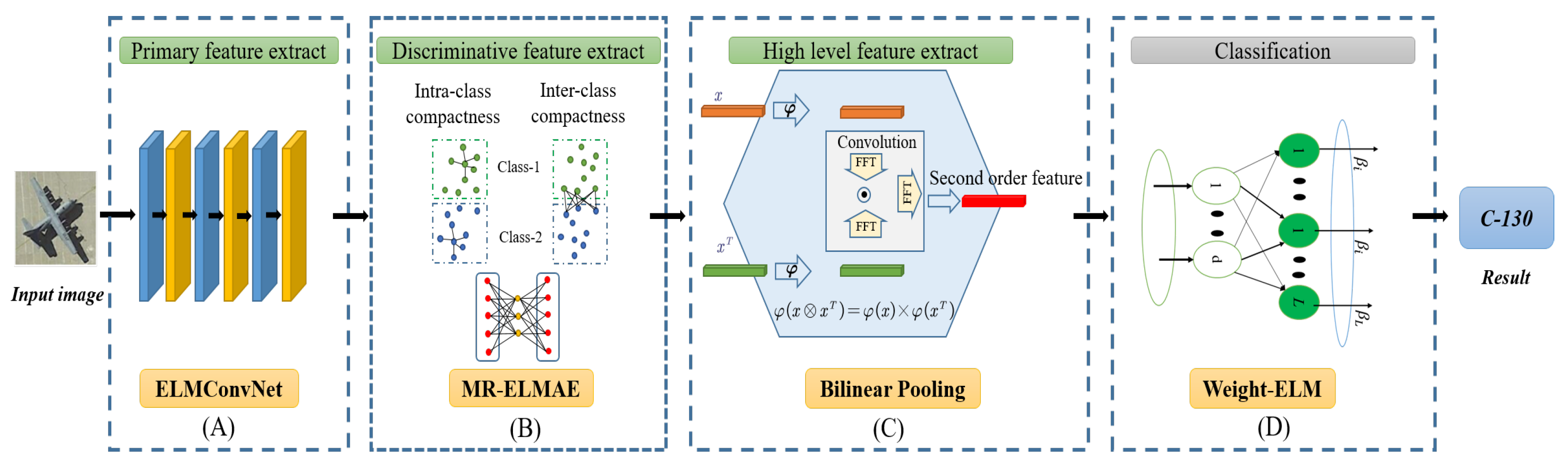
3.1. Overall Framework
3.2. ELMConvNet
3.2.1. Convolutional Layer
3.2.2. Activation Function
3.2.3. Pooling Layer
3.2.4. Feature Learning
3.3. Discriminative Feature Learning by the MRELM-AE
3.4. High-Order Feature Extraction through Compact Bilinear Pooling
3.5. Supervised Learning by Using the Weighted ELM
4. Experiments
4.1. MTARSI Dataset
4.2. Evaluation Metrics
4.3. Implementation Details
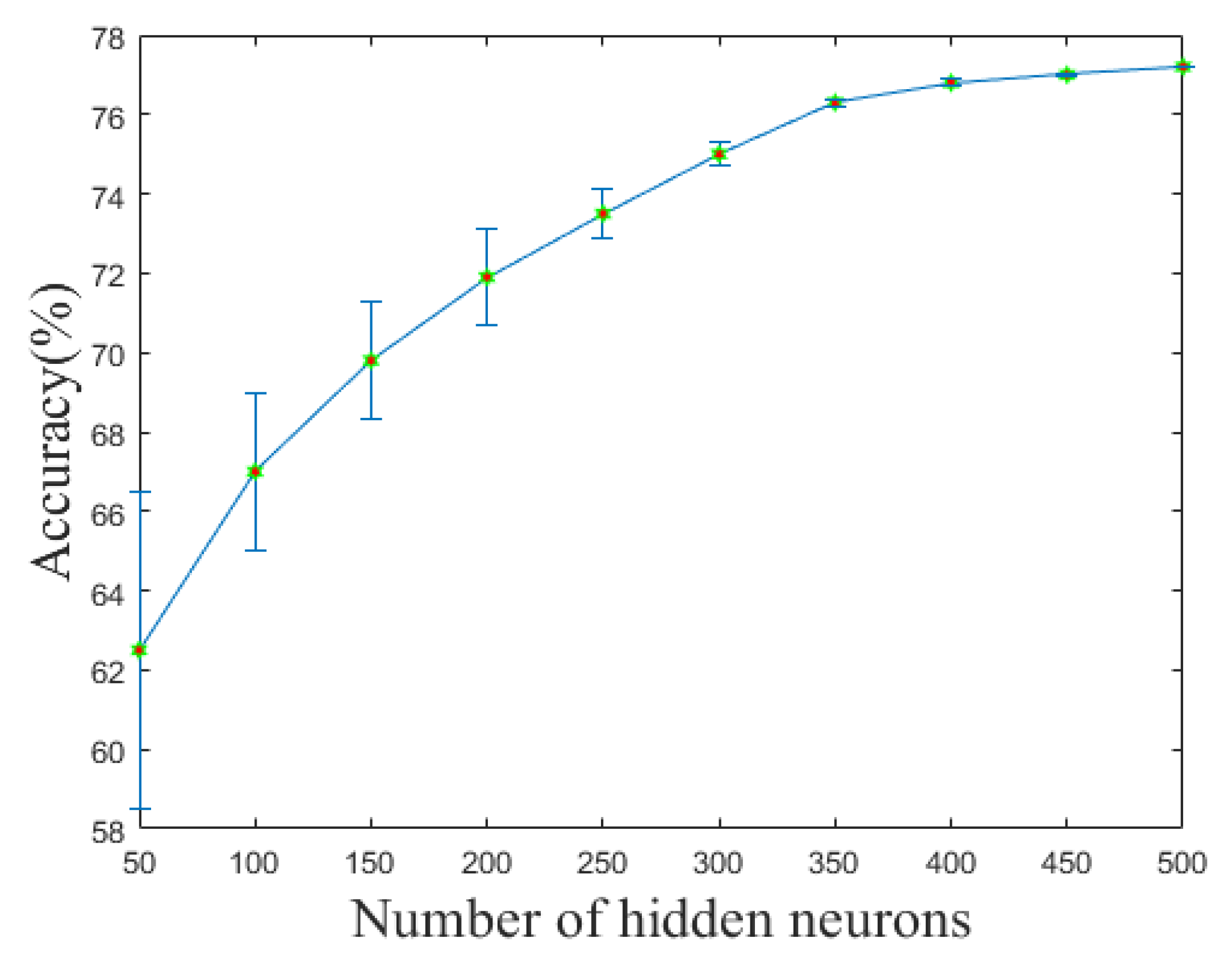
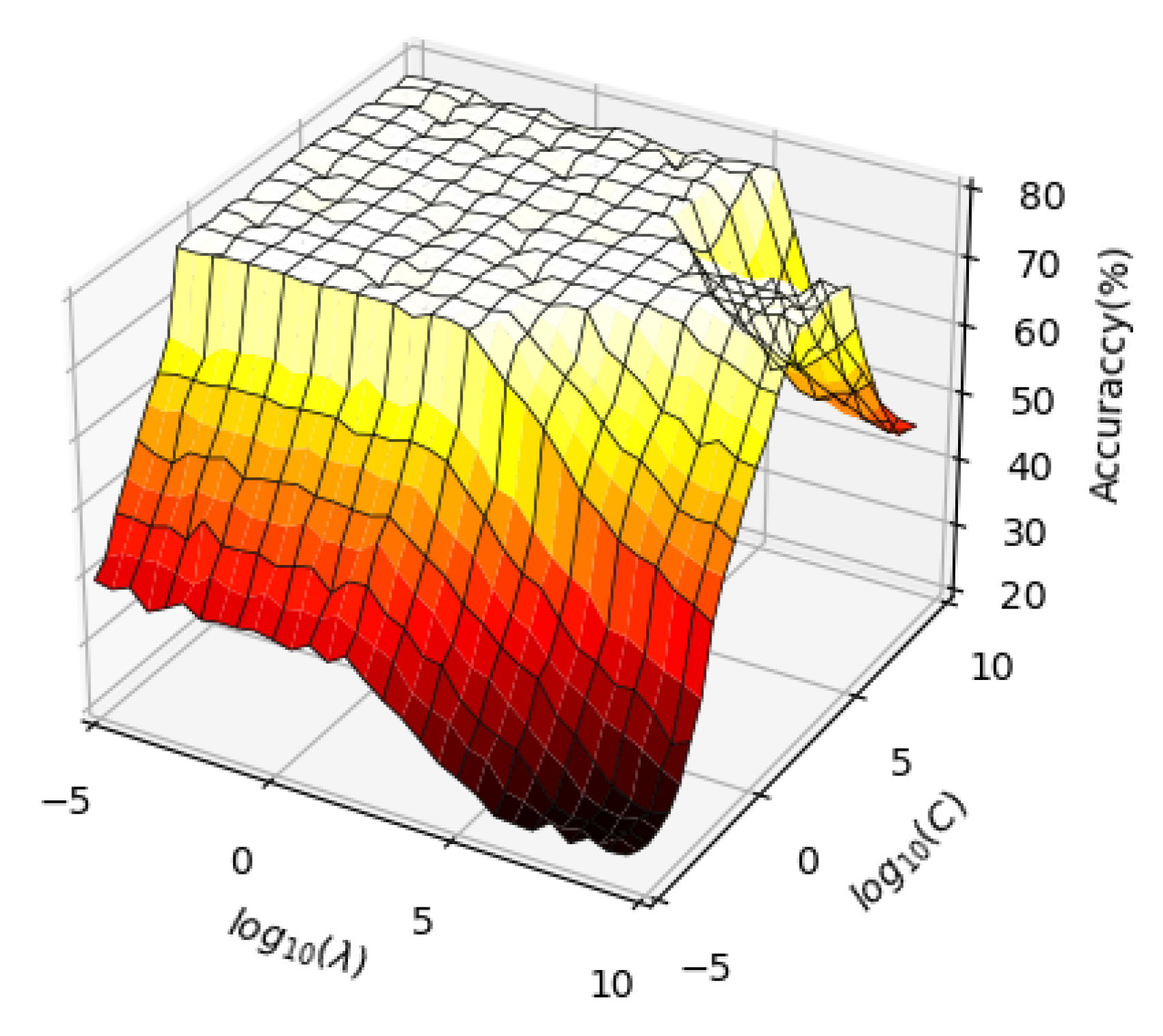
4.4. Hyper-Parameter Study
4.5. Ablation Studies
4.6. Comparison with State-of-the-Art Methods
4.7. Analysis of the Image Features in MTARSI
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhao, A.; Fu, K.; Wang, S.; Zuo, J.; Zhang, Y.; Hu, Y.; Wang, H. Aircraft Recognition Based on Landmark Detection in Remote Sensing Images. IEEE Geoence Remote Sens. Lett. 2017, 14, 1413–1417. [Google Scholar] [CrossRef]
- Fu, K.; Dai, W.; Zhang, Y.; Wang, Z.; Yan, M.; Sun, X. MultiCAM: Multiple Class Activation Mapping for Aircraft Recognition in Remote Sensing Images. Remote Sens. 2019, 11, 544. [Google Scholar] [CrossRef] [Green Version]
- Zuo, J.; Xu, G.; Fu, K.; Sun, X.; Sun, H. Aircraft Type Recognition Based on Segmentation with Deep Convolutional Neural Networks. IEEE Geoence Remote Sens. Lett. 2018, 15, 282–286. [Google Scholar] [CrossRef]
- Diao, W.; Sun, X.; Dou, F.; Yan, M.; Wang, H.; Fu, K. Object recognition in remote sensing images using sparse deep belief networks. Remote Sens. Lett. 2015, 6, 745–754. [Google Scholar] [CrossRef]
- Yuhang, Z.; Hao, S.; Jiawei, Z.; Hongqi, W.; Guangluan, X.; Xian, S. Aircraft Type Recognition in Remote Sensing Images Based on Feature Learning with Conditional Generative Adversarial Networks. Remote Sens. 2018, 10, 1123. [Google Scholar]
- Wu, Q.; Sun, H.; Sun, X.; Zhang, D.; Fu, K.; Wang, H. Aircraft Recognition in High-Resolution Optical Satellite Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2014, 12, 112–116. [Google Scholar]
- Rong, H.J.; Jia, Y.X.; Zhao, G.S. Aircraft recognition using modular extreme learning machine. Neurocomputing 2014, 128, 166–174. [Google Scholar] [CrossRef]
- Hsieh, J.W.; Chen, J.M.; Chuang, C.H.; Fan, K.C. Aircraft type recognition in satellite images. IEE Proc. Vision Image Signal Process. 2005, 152, 307–315. [Google Scholar] [CrossRef] [Green Version]
- Xu, C.; Duan, H. Artificial bee colony (ABC) optimized edge potential function (EPF) approach to target recognition for low-altitude aircraft. Pattern Recognit. Lett. 2010, 31, 1759–1772. [Google Scholar] [CrossRef]
- Lindeberg, T. Scale Invariant Feature Transform. 2012. Available online: http://https://www.diva-portal.org/smash/record.jsf (accessed on 24 May 2012).
- Wang, X.; Han, T.X.; Yan, S. An HOG-LBP human detector with partial occlusion handling. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 32–39. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Chakraborty, S.; Roy, M. A neural approach under transfer learning for domain adaptation in land-cover classification using two-level cluster mapping. Appl. Soft Comput. 2018, 64, 508–525. [Google Scholar] [CrossRef]
- Dang, L.M.; Hassan, S.I.; Suhyeon, I.; kumar Sangaiah, A.; Mehmood, I.; Rho, S.; Seo, S.; Moon, H. UAV based wilt detection system via convolutional neural networks. Sustain. Comput. Inform. Syst. 2018, 28, 100250. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic Ship Detection of Remote Sensing Images from Google Earth in Complex Scenes Based on Multi-Scale Rotation Dense Feature Pyramid Networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Yang, X.; Zhong, B.; Pan, S.; Chen, D.; Zhang, H. CNNTracker: Online discriminative object tracking via deep convolutional neural network. Appl. Soft Comput. 2016, 38, 1088–1098. [Google Scholar] [CrossRef]
- Han, Y.; Deng, C.; Zhao, B.; Tao, D. State-aware anti-drift object tracking. IEEE Trans. Image Process. 2019, 28, 4075–4086. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Han, Y.; Deng, C.; Zhao, B.; Zhao, B. Spatial-temporal context-aware tracking. IEEE Signal Process. Lett. 2019, 26, 500–504. [Google Scholar] [CrossRef]
- Han, Y.; Deng, C.; Zhang, Z.; Li, J.; Zhao, B. Adaptive feature representation for visual tracking. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 1867–1870. [Google Scholar]
- Zhao, Z.; Han, Y.; Xu, T.; Li, X.; Song, H.; Luo, J. A Reliable and Real-Time Tracking Method with Color Distribution. Sensors 2017, 17, 2303. [Google Scholar] [CrossRef]
- Gao, X.; Sun, X.; Zhang, Y.; Yan, M.; Xu, G.; Sun, H.; Jiao, J.; Fu, K. An end-to-end neural network for road extraction from remote sensing imagery by multiple feature pyramid network. IEEE Access 2018, 6, 39401–39414. [Google Scholar] [CrossRef]
- Mittal, M.; Goyal, L.M.; Kaur, S.; Kaur, I.; Verma, A.; Hemanth, D.J. Deep learning based enhanced tumor segmentation approach for MR brain images. Appl. Soft Comput. 2019, 78, 346–354. [Google Scholar] [CrossRef]
- Chan, T.H.; Jia, K.; Gao, S.; Lu, J.; Zeng, Z.; Ma, Y. PCANet: A simple deep learning baseline for image classification? IEEE Trans. Image Process. 2015, 24, 5017–5032. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: A new learning scheme of feedforward neural networks. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks (IEEE Cat. No. 04CH37541), Budapest, Hungary, 25–29 July 2004; Volume 2, pp. 985–990. [Google Scholar] [CrossRef]
- Huang, G.B.; Chen, L.; Siew, C.K. Universal approximation using incremental constructive feedforward networks with random hidden nodes. IEEE Trans. Neural Netw. 2006, 17, 879–892. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.B.; Bai, Z.; Kasun, L.L.C.; Vong, C.M. Local receptive fields based extreme learning machine. IEEE Comput. Intell. Mag. 2015, 10, 18–29. [Google Scholar] [CrossRef]
- Zhu, W.; Miao, J.; Qing, L.; Huang, G.B. Hierarchical extreme learning machine for unsupervised representation learning. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–8. [Google Scholar]
- Kasun, L.L.C.; Zhou, H.; Huang, G.B.; Vong, C.M. Representational learning with extreme learning machine for big data. IEEE Intell. Syst. 2013, 28, 31–34. [Google Scholar]
- Zong, W.; Huang, G.B.; Chen, Y. Weighted extreme learning machine for imbalance learning. Neurocomputing 2013, 101, 229–242. [Google Scholar] [CrossRef]
- Zhou, T.; Yao, L.; Zhang, Y. Graph regularized discriminant analysis and its application to face recognition. In Proceedings of the IEEE International Conference on Image Processing, Quebec City, QC, Canada, 27–30 September 2015. [Google Scholar]
- Belkin, M.; Niyogi, P. Laplacian eigenmaps and spectral techniques for embedding and clustering. In Proceedings of the 14th International Conference on Neural Information Processing Systems: Natural and Synthetic (NIPS’01), Vancouver, BC, Canada, 3–8 December 2001; MIT Press: Cambridge, MA, USA, 2001; pp. 585–591. [Google Scholar]
- Sun, K.; Zhang, J.; Zhang, C.; Hu, J. Generalized extreme learning machine autoencoder and a new deep neural network. Neurocomputing 2017, 230, 374–381. [Google Scholar] [CrossRef]
- Ge, H.; Sun, W.; Zhao, M.; Yao, Y. Stacked Denoising Extreme Learning Machine Autoencoder Based on Graph Embedding for Feature Representation. IEEE Access 2019, 7, 13433–13444. [Google Scholar] [CrossRef]
- Wu, Z.Z.; Wan, S.H.; Wang, X.F.; Tan, M.; Zou, L.; Li, X.L.; Chen, Y. A benchmark data set for aircraft type recognition from remote sensing images. Appl. Soft Comput. 2020, 89, 106132. [Google Scholar] [CrossRef]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning PMLR, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Hoiem, D.; Divvala, S.K.; Hays, J.H. The PASCAL Visual Object Classes Challenge 2007 (VOC2007) Development Kit. World Lit. Today. 2009. Available online: http://www.pascal-network.org/challenges/VOC/voc2007/workshop/index.html (accessed on 15 October 2007).
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Boureau, Y.L.; Ponce, J.; LeCun, Y. A theoretical analysis of feature pooling in visual recognition. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 111–118. [Google Scholar]
- Yu, D.; Wang, H.; Chen, P.; Wei, Z. Mixed pooling for convolutional neural networks. In Proceedings of the International Conference on Rough Sets and Knowledge Technology, Shanghai, China, 24–26 October 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 364–375. [Google Scholar]
- Lee, C.Y.; Gallagher, P.W.; Tu, Z. Generalizing pooling functions in convolutional neural networks: Mixed, gated, and tree. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Cadiz, Spain, 9–11 May 2016; pp. 464–472. [Google Scholar]
- Gulcehre, C.; Cho, K.; Pascanu, R.; Bengio, Y. Learned-norm pooling for deep feedforward and recurrent neural networks. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Nancy, France, 15–19 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 530–546. [Google Scholar]
- Tenenbaum, J.B.; Freeman, W.T. Separating style and content with bilinear models. Neural Comput. 2000, 12, 1247–1283. [Google Scholar] [CrossRef]
- Fukui, A.; Park, D.H.; Yang, D.; Rohrbach, A.; Darrell, T.; Rohrbach, M. Multimodal compact bilinear pooling for visual question answering and visual grounding. arXiv 2016, arXiv:1606.01847. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A Review on Deep Learning Techniques Applied to Semantic Segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Hussain, Z.; Gimenez, F.; Yi, D.; Rubin, D. Differential Data Augmentation Techniques for Medical Imaging Classification Tasks. AMIA Annu. Symp. Proc. 2017, 2017, 979–984. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning augmentation strategies from data. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Liang, D.; Yang, F.; Zhang, T.; Yang, P. Understanding mixup training methods. IEEE Access 2018, 6, 58774–58783. [Google Scholar] [CrossRef]
- Wong, S.C.; Gatt, A.; Stamatescu, V.; McDonnell, M.D. Understanding data augmentation for classification: When to warp? In Proceedings of the 2016 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Gold Coast, Australia, 30 November–2 December 2016; pp. 1–6. [Google Scholar]
- Inoue, H. Data augmentation by pairing samples for images classification. arXiv 2018, arXiv:1801.02929. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27. Available online: http://dl.acm.org/doi/10.5555/2969033.2969125 (accessed on 8 December 2014).
- Leng, B.; Yu, K.; Jingyan, Q. Data augmentation for unbalanced face recognition training sets. Neurocomputing 2017, 235, 10–14. [Google Scholar] [CrossRef]
- Zhu, X.; Liu, Y.; Li, J.; Wan, T.; Qin, Z. Emotion classification with data augmentation using generative adversarial networks. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Melbourne, VIC, Australia, 3–6 June; Springer: Berlin/Heidelberg, Germany, 2018; pp. 349–360. [Google Scholar]
- Frid-Adar, M.; Diamant, I.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. GAN-based synthetic medical image augmentation for increased CNN performance in liver lesion classification. Neurocomputing 2018, 321, 321–331. [Google Scholar] [CrossRef] [Green Version]
- Fawzi, A.; Samulowitz, H.; Turaga, D.; Frossard, P. Adaptive data augmentation for image classification. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3688–3692. [Google Scholar]
- Lemley, J.; Bazrafkan, S.; Corcoran, P. Smart augmentation learning an optimal data augmentation strategy. IEEE Access 2017, 5, 5858–5869. [Google Scholar] [CrossRef]
- Ratner, A.J.; Ehrenberg, H.R.; Hussain, Z.; Dunnmon, J.; Ré, C. Learning to compose domain-specific transformations for data augmentation. Adv. Neural Inf. Process. Syst. 2017, 30, 3239. [Google Scholar]
- Tran, T.; Pham, T.; Carneiro, G.; Palmer, L.; Reid, I. A bayesian data augmentation approach for learning deep models. arXiv 2017, arXiv:1710.10564. [Google Scholar]
- Yan, D.; Chu, Y.; Zhang, H.; Liu, D. Information discriminative extreme learning machine. Soft Comput. A Fusion Found. Methodol. Appl. 2018, 22, 677–689. [Google Scholar] [CrossRef]
- Peng, Y.; Lu, B.L. Discriminative extreme learning machine with supervised sparsity preserving for image classification. Neurocomputing 2017, 261, 242–252. [Google Scholar] [CrossRef]
- Yan, S.; Xu, D.; Zhang, B.; Zhang, H.; Yang, Q.; Lin, S. Graph Embedding and Extensions: A General Framework for Dimensionality Reduction. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 40–51. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pedagadi, S.; Orwell, J.; Velastin, S.; Boghossian, B. Local fisher discriminant analysis for pedestrian re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3318–3325. [Google Scholar]
- Atmane, K.; Hongbin, M.; Qing, F. Convolutional Neural Network Based on Extreme Learning Machine for Maritime Ships Recognition in Infrared Images. Sensors 2018, 18, 1490. [Google Scholar]
- Lin, T.Y.; RoyChowdhury, A.; Maji, S. Bilinear cnn models for fine-grained visual recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1449–1457. [Google Scholar]
- Charikar, M.; Chen, K.; Farach-Colton, M. Finding frequent items in data streams. In Proceedings of the International Colloquium on Automata, Languages, and Programming, Malaga, Spain, 8–13 July 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 693–703. [Google Scholar]
- Csurka, G.; Dance, C.; Fan, L.; Willamowski, J.; Bray, C. Visual categorization with bags of keypoints. In Proceedings of the Workshop on Statistical Learning in Computer Vision, ECCV, Prague, Czech Republic, 16 May 2004; Volume 1, pp. 1–2. [Google Scholar]
- Heikkilä, M.; Pietikäinen, M.; Schmid, C. Description of interest regions with local binary patterns. Pattern Recognit. 2009, 42, 425–436. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types | Images | Types | Images | Types | Images |
|---|---|---|---|---|---|
| B-1 | 513 | C-130 | 763 | F-16 | 372 |
| B-2 | 619 | E-3 | 452 | F-22 | 846 |
| B-52 | 548 | C-135 | 526 | KC-10 | 554 |
| B-29 | 321 | C-5 | 499 | C-21 | 491 |
| Boeing | 605 | C-17 | 480 | U-2 | 362 |
| A-10 | 345 | T-6 | 248 | A-26 | 230 |
| P63 | 305 | T-43 | 306 | - | - |
| Layer | Layer Name | Size/Stride | Output |
|---|---|---|---|
| L0 | Input layer | , 3 channels | - |
| L1 | Convolutional layer | /32, s = 1 | |
| L2 | Combined pooling layer | /s = 2 | |
| L3 | Convolutional layer | /64, s = 2 | |
| L4 | Combined pooling layer | /s = 2 | |
| L5 | Convolutional layer | /128, s = 2 | |
| L6 | Combined pooling layer | /s = 2 |
| Hyperparameter | Range |
|---|---|
| Number of hidden neurons | 100 to 5000 |
| C | 1.0 × 10 to 1.0 × 10 |
| 1.0 × 10 to 1.0 × 10 |
| Baseline (ELM-LRF) | Conv-Pool Layer | MRELM-AE | Compact Bilinear Pooling | W-ELM | Accuracy | Training Time (s) |
|---|---|---|---|---|---|---|
| + | − | − | − | − | 0.517 | 187 |
| + | + | − | − | − | 0.566 | 205 |
| + | + | + | − | − | 0.628 | 438 |
| + | + | + | + | − | 0.717 | 789 |
| + | + | + | + | + | 0.781 | 889 |
| Method | Accuracy |
|---|---|
| LBP–SVM [79] | 0.457 |
| ELM-LRF [27] | 0.517 |
| PCANet [24] | 0.595 |
| SIFT + BOVW [78] | 0.609 |
| ELM-CNN [75] | 0.715 |
| AlexNet [12] | 0.753 |
| SqueezeNet [47] | 0.765 |
| MobileNet [48] | 0.776 |
| BD-ELMNet (Our method) | 0.781 |
| Method | Training Time (s) |
|---|---|
| PCANet [24] | 392 |
| MobileNet [48] | 6480 |
| SqueezeNet [47] | 4979 |
| AlexNet [12] | 3654 |
| ELM-LRF [27] | 187 |
| ELM-CNN [75] | 498 |
| BD-ELMNet (Our method) | 889 |
| Methods | Accuracy |
|---|---|
| AlexNet_scratch | 0.594 |
| AlexNet_pre-train | 0.753 |
| SqueezeNet_scratch | 0.609 |
| SqueezeNet_pre-train | 0.765 |
| MobileNet_scratch | 0.658 |
| MobileNet_pre-train | 0.776 |
| Our method_scratch | 0.781 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, B.; Tang, W.; Pan, Y.; Han, Y.; Wang, W. Aircraft Type Recognition in Remote Sensing Images: Bilinear Discriminative Extreme Learning Machine Framework. Electronics 2021, 10, 2046. https://doi.org/10.3390/electronics10172046
Zhao B, Tang W, Pan Y, Han Y, Wang W. Aircraft Type Recognition in Remote Sensing Images: Bilinear Discriminative Extreme Learning Machine Framework. Electronics. 2021; 10(17):2046. https://doi.org/10.3390/electronics10172046
Chicago/Turabian StyleZhao, Baojun, Wei Tang, Yu Pan, Yuqi Han, and Wenzheng Wang. 2021. "Aircraft Type Recognition in Remote Sensing Images: Bilinear Discriminative Extreme Learning Machine Framework" Electronics 10, no. 17: 2046. https://doi.org/10.3390/electronics10172046
APA StyleZhao, B., Tang, W., Pan, Y., Han, Y., & Wang, W. (2021). Aircraft Type Recognition in Remote Sensing Images: Bilinear Discriminative Extreme Learning Machine Framework. Electronics, 10(17), 2046. https://doi.org/10.3390/electronics10172046