
Adaptive Sparse Representation of Continuous Input for Tsetlin Machines Based on Stochastic Searching on the Line



Abstract
:1. Introduction
- Instead of representing each unique threshold found in the Booleanization process by a TA, we use a Stochastic Searching on the Line (SSL) automaton [45] to learn the lower and upper limits of the continuous feature values. These limits decide the Boolean representation of the continuous value inside the clause. Only two TAs then decide whether to include these bounds in the clause or to exclude them from the clause. In this way, one continuous feature can be represented by only four automata, instead of representing it by hundreds of TAs (decided by the number of unique feature values within the feature).
- A new approach to calculating the clause output is introduced to match with the above Booleanization scheme.
- We update the learning procedure of the TM accordingly, building upon Type I and Type II feedback to learn the lower and upper bounds of the continuous input.
- Empirically, we evaluate our new scheme using eight data sets: Bankruptcy, Balance Scale, Breast Cancer, Liver Disorders, Heart Disease, Fraud Detection, COMPAS, and CA-58. With the first five datasets, we show how our novel approach affects memory consumption, training time, and the number of literals included in clauses, in comparison with the threshold-based scheme [46]. Furthermore, performances on all these datasets are compared against recent state-of-the-art machine learning models.
2. Learning Automata and the Stochastic Searching on the Line Automaton
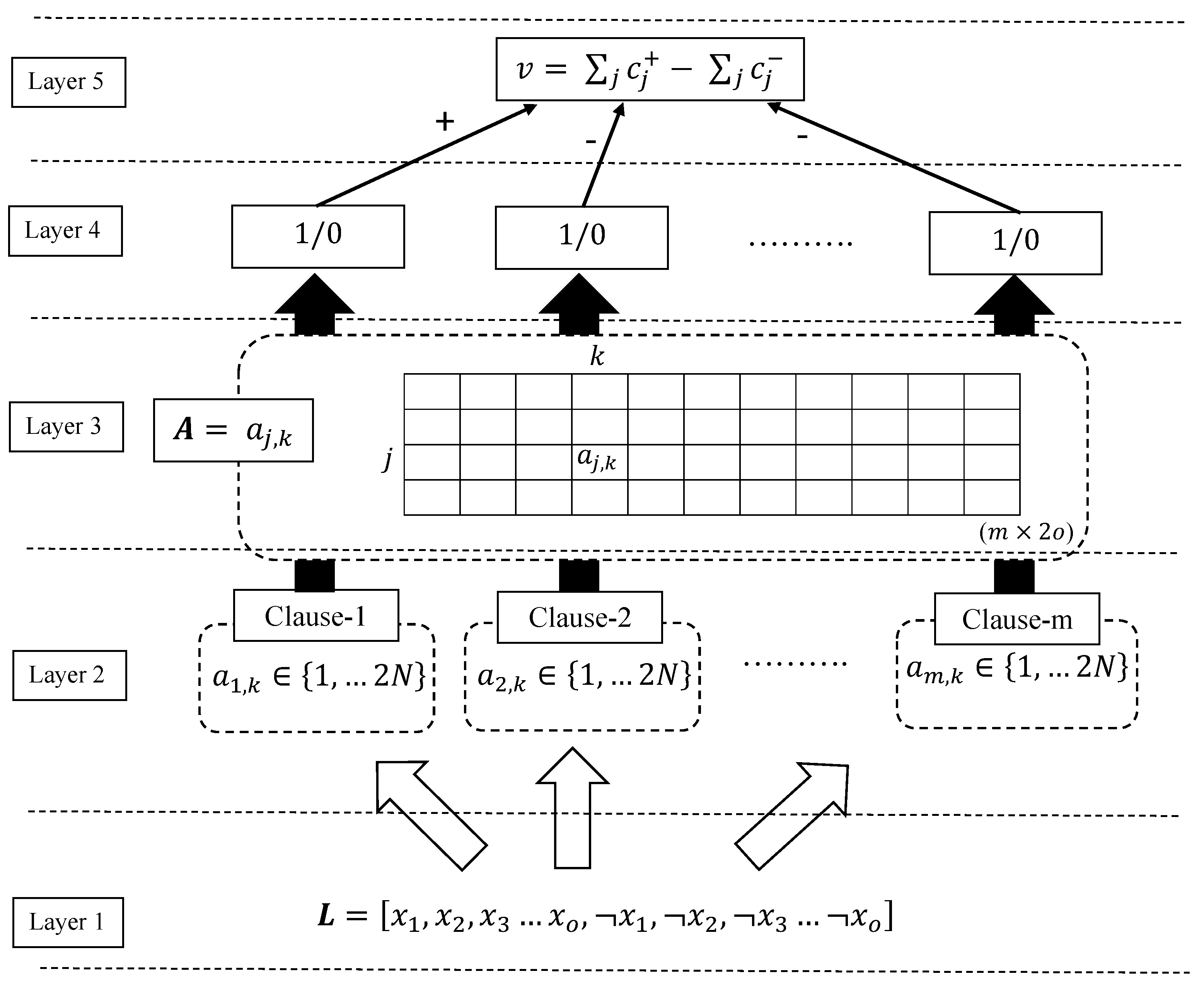
3. Tsetlin Machine (TM) for Continuous Features
- First, for each feature, the unique values are identified;
- The unique values are then sorted from smallest to largest;
- The sorted unique values are considered as thresholds. In the table, these values can be seen in the “Thresholds” row;
- The original feature values are then compared with identified thresholds, only from their own feature value set. If the feature value is greater than the threshold, set the corresponding Boolean variable to 0; otherwise, set it to 1;
- The above steps are repeated until all the features are converted into Boolean form.
4. Sparse Representation of Continuous Features
- Condition 1: Both and which respectively make the decision on and decide to include them in the clause. Then,
- Condition 2: The decides to include in the clause and decides to exclude from the clause. Then,
- Condition 3: The decides to include in the clause and decides to exclude from the clause. Then,
- Condition 4: Both and decide to exclude their corresponding SSLs from the clause, which consequently takes the lower limit to the lowest possible and the upper limit to the highest possible values. Hence, always becomes 1 or can be excluded when conjunction is performed.
5. Empirical Evaluation
5.1. Bankruptcy
5.2. Balance Scale
5.3. Breast Cancer
5.4. Liver Disorders
5.5. Heart Disease
5.6. Summary of Empirical Evaluation
5.7. Comparison against Recent State-of-the-Art Machine Learning Models
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Miotto, R.; Wang, F.; Wang, S.; Jiang, X.; Dudley, J.T. Deep learning for healthcare: Review, opportunities and challenges. Brief. Bioinform. 2018, 19, 1236–1246. [Google Scholar] [CrossRef] [PubMed]
- Bellazzi, R.; Zupan, B. Predictive data mining in clinical medicine: Current issues and guidelines. Int. J. Med. Inform. 2008, 77, 81–97. [Google Scholar] [CrossRef] [Green Version]
- Pazzani, M.J.; Mani, S.; Shankle, W.R. Acceptance of rules generated by machine learning among medical experts. Methods Inf. Med. 2001, 40, 380–385. [Google Scholar]
- Baesens, B.; Mues, C.; De Backer, M.; Vanthienen, J.; Setiono, R. Building intelligent credit scoring systems using decision tables. In Enterprise Information Systems V; Springer: Berlin/Heidelberg, Germany, 2004; pp. 131–137. [Google Scholar]
- Huysmans, J.; Dejaeger, K.; Mues, C.; Vanthienen, J.; Baesens, B. An empirical evaluation of the comprehensibility of decision table, tree and rule based predictive models. Decis. Support Syst. 2011, 51, 141–154. [Google Scholar] [CrossRef]
- Lima, E.; Mues, C.; Baesens, B. Domain knowledge integration in data mining using decision tables: Case studies in churn prediction. J. Oper. Res. Soc. 2009, 60, 1096–1106. [Google Scholar] [CrossRef]
- Verbeke, W.; Martens, D.; Mues, C.; Baesens, B. Building comprehensible customer churn prediction models with advanced rule induction techniques. Expert Syst. Appl. 2011, 38, 2354–2364. [Google Scholar] [CrossRef]
- Freitas, A.A.; Wieser, D.C.; Apweiler, R. On the importance of comprehensible classification models for protein function prediction. IEEE/ACM Trans. Comput. Biol. Bioinform. 2008, 7, 172–182. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Szafron, D.; Lu, P.; Greiner, R.; Wishart, D.S.; Poulin, B.; Eisner, R.; Lu, Z.; Anvik, J.; Macdonell, C.; Fyshe, A.; et al. Proteome Analyst: Custom predictions with explanations in a web-based tool for high-throughput proteome annotations. Nucleic Acids Res. 2004, 32, W365–W371. [Google Scholar] [CrossRef]
- Lazreg, M.B.; Goodwin, M.; Granmo, O.C. Deep learning for social media analysis in crises situations. In Proceedings of the 29th Annual Workshop of the Swedish Artificial Intelligence Society (SAIS), Malmö, Sweden, 2–3 June 2016; p. 31. [Google Scholar]
- Agarwal, R.; Frosst, N.; Zhang, X.; Caruana, R.; Hinton, G.E. Neural Additive Models: Interpretable Machine Learning with Neural Nets. arXiv 2020, arXiv:2004.13912. [Google Scholar]
- Molnar, C. Interpretable Machine Learning; Leanpub: Victoria, BC, Canada, 2019. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. LeanpubNat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef] [Green Version]
- Agrawal, R.; Imieliński, T.; Swami, A. Mining Association Rules Between Sets of Items in Large Databases. SIGMOD Rec. 1993, 22, 207–216. [Google Scholar] [CrossRef]
- McCormick, T.; Rudin, C.; Madigan, D. A Hierarchical Model for Association Rule Mining of Sequential Events: An Approach to Automated Medical Symptom Prediction. Ann. Appl. Stat. 2011. [Google Scholar] [CrossRef] [Green Version]
- Feldman, V. Hardness of Approximate Two-Level Logic Minimization and PAC Learning with Membership Queries. J. Comput. Syst. Sci. 2009, 75, 13–26. [Google Scholar] [CrossRef] [Green Version]
- Valiant, L.G. A Theory of the Learnable. Commun. ACM 1984, 27, 1134–1142. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Rudin, C.; Doshi-Velez, F.; Liu, Y.; Klampfl, E.; MacNeille, P. A Bayesian Framework for Learning Rule Sets for Interpretable Classification. J. Mach. Learn. Res. 2017, 18, 2357–2393. [Google Scholar]
- Hauser, J.R.; Toubia, O.; Evgeniou, T.; Befurt, R.; Dzyabura, D. Disjunctions of Conjunctions, Cognitive Simplicity, and Consideration Sets. J. Mark. Res. 2010, 47, 485–496. [Google Scholar] [CrossRef]
- Liang, Y.; Van den Broeck, G. Learning logistic circuits. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Hilton Hawaiian Village, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4277–4286. [Google Scholar]
- Nori, H.; Jenkins, S.; Koch, P.; Caruana, R. InterpretML: A Unified Framework for Machine Learning Interpretability. arXiv 2019, arXiv:1909.09223. [Google Scholar]
- Lou, Y.; Caruana, R.; Gehrke, J. Intelligible models for classification and regression. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 150–158. [Google Scholar]
- Granmo, O.C. The Tsetlin Machine—A game theoretic bandit driven approach to optimal pattern recognition with propositional logic. arXiv 2018, arXiv:1804.01508. [Google Scholar]
- Phoulady, A.; Granmo, O.C.; Gorji, S.R.; Phoulady, H.A. The Weighted Tsetlin Machine: Compressed Representations with Clause Weighting. In Proceedings of the Ninth International Workshop on Statistical Relational AI (StarAI2020), New York, NY, USA, 7 February 2020. [Google Scholar]
- Berge, G.T.; Granmo, O.C.; Tveit, T.O.; Goodwin, M.; Jiao, L.; Matheussen, B.V. Using the Tsetlin Machine to learn human-interpretable rules for high-accuracy text categorization with medical applications. IEEE Access 2019, 7, 115134–115146. [Google Scholar] [CrossRef]
- Abeyrathna, K.D.; Granmo, O.C.; Zhang, X.; Jiao, L.; Goodwin, M. The Regression Tsetlin Machine—A Novel Approach to Interpretable Non-Linear Regression. Philos. Trans. R. Soc. A 2019, 378, 20190165. [Google Scholar] [CrossRef] [Green Version]
- Gorji, S.R.; Granmo, O.C.; Phoulady, A.; Goodwin, M. A Tsetlin Machine with Multigranular Clauses. In Lecture Notes in Computer Science: Proceedings of the Thirty-ninth International Conference on Innovative Techniques and Applications of Artificial Intelligence (SGAI-2019); Springer: Berlin/Heidelberg, Germany, 2019; Volume 11927. [Google Scholar]
- Gorji, S.R.; Granmo, O.-G.; Glimsdal, S.; Edwards, J.; Goodwin, M. Increasing the Inference and Learning Speed of Tsetlin Machines with Clause Indexing. In International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Wheeldon, A.; Shafik, R.; Yakovlev, A.; Edwards, J.; Haddadi, I.; Granmo, O.C. Tsetlin Machine: A New Paradigm for Pervasive AI. In Proceedings of the SCONA Workshop at Design, Automation and Test in Europe (DATE), Grenoble, France, 9–13 March 2020. [Google Scholar]
- Tsetlin, M.L. On behaviour of finite automata in random medium. Avtomat. Telemekh 1961, 22, 1345–1354. [Google Scholar]
- Yadav, R.K.; Jiao, L.; Granmo, O.C.; Goodwin, M. Interpretability in Word Sense Disambiguation using Tsetlin Machine. In Proceedings of the 13th International Conference on Agents and Artificial Intelligence (ICAART), Vienna, Austria, 4 February 2021; INSTICC: Lisboa, Portugal, 2021. [Google Scholar]
- Bhattarai, B.; Jiao, L.; Granmo, O.C. Measuring the Novelty of Natural Language Text Using the Conjunctive Clauses of a Tsetlin Machine Text Classifier. In Proceedings of the 13th International Conference on Agents and Artificial Intelligence (ICAART), Vienna, Austria, 4 February 2021; INSTICC: Lisboa, Portugal, 2021. [Google Scholar]
- Sharma, J.; Yadav, R.; Granmo, O.C.; Jiao, L. Human Interpretable AI: Enhancing Tsetlin Machine Stochasticity with Drop Clause. arXiv 2021, arXiv:2105.14506. [Google Scholar]
- Lei, J.; Rahman, T.; Shafik, R.; Wheeldon, A.; Yakovlev, A.; Granmo, O.C.; Kawsar, F.; Mathur, A. Low-Power Audio Keyword Spotting Using Tsetlin Machines. J. Low Power Electron. Appl. 2021, 11, 18. [Google Scholar] [CrossRef]
- Granmo, O.C.; Glimsdal, S.; Jiao, L.; Goodwin, M.; Omlin, C.W.; Berge, G.T. The Convolutional Tsetlin Machine. arXiv 2019, arXiv:1905.09688. [Google Scholar]
- Abeyrathna, K.D.; Granmo, O.C.; Zhang, X.; Goodwin, M. A scheme for continuous input to the Tsetlin Machine with applications to forecasting disease outbreaks. In International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2019; pp. 564–578. [Google Scholar]
- Abeyrathna, K.D.; Granmo, O.C.; Goodwin, M. Extending the Tsetlin Machine With Integer-Weighted Clauses for Increased Interpretability. IEEE Access 2021, 9, 8233–8248. [Google Scholar] [CrossRef]
- Wheeldon, A.; Shafik, R.; Rahman, T.; Lei, J.; Yakovlev, A.; Granmo, O.C. Learning Automata based Energy-efficient AI Hardware Design for IoT. Philos. Trans. R. Soc. A 2020, 378, 20190593. [Google Scholar] [CrossRef] [PubMed]
- Abeyrathna, K.D.; Bhattarai, B.; Goodwin, M.; Gorji, S.; Granmo, O.C.; Jiao, L.; Saha, R.; Yadav, R.K. Massively Parallel and Asynchronous Tsetlin Machine Architecture Supporting Almost Constant-Time Scaling. In Proceedings of the Thirty-eighth International Conference on Machine Learning (ICML2021), Virtual, 18–24 July 2021. [Google Scholar]
- Shafik, R.; Wheeldon, A.; Yakovlev, A. Explainability and Dependability Analysis of Learning Automata based AI Hardware. In Proceedings of the IEEE 26th International Symposium on On-Line Testing and Robust System Design (IOLTS), Napoli, Italy, 13–15 July 2020. [Google Scholar]
- Abeyrathna, K.D.; Granmo, O.C.; Goodwin, M. A Regression Tsetlin Machine with Integer Weighted Clauses for Compact Pattern Representation. In International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Zhang, X.; Jiao, L.; Granmo, O.C.; Goodwin, M. On the Convergence of Tsetlin Machines for the IDENTITY- and NOT Operators. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 1. [Google Scholar] [CrossRef]
- Jiao, L.; Zhang, X.; Granmo, O.C.; Abeyrathna, K.D. On the Convergence of Tsetlin Machines for the XOR Operator. arXiv 2021, arXiv:2101.02547. [Google Scholar]
- Oommen, B.J. Stochastic searching on the line and its applications to parameter learning in nonlinear optimization. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 1997, 27, 733–739. [Google Scholar] [CrossRef] [Green Version]
- Abeyrathna, K.D.; Granmo, O.C.; Goodwin, M. Adaptive Sparse Representation of Continuous Input for Tsetlin Machines Based on Stochastic Searching on the Line. 2020; In Preparation. [Google Scholar]
- Lucena, B. StructureBoost: Efficient Gradient Boosting for Structured Categorical Variables. arXiv 2020, arXiv:2007.04446. [Google Scholar]
- Narendra, K.S.; Thathachar, M.A. Learning Automata: An Introduction; Courier Corporation: Chelmsford, MA, USA, 2012. [Google Scholar]
- Thathachar, M.A.L.; Sastry, P.S. Networks of Learning Automata: Techniques for Online Stochastic Optimization; Kluwer Academic Publishers: London, UK, 2004. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Kim, M.J.; Han, I. The discovery of experts’ decision rules from qualitative bankruptcy data using genetic algorithms. Expert Syst. Appl. 2003, 25, 637–646. [Google Scholar] [CrossRef]
- McDermott, J.; Forsyth, R.S. Diagnosing a disorder in a classification benchmark. Pattern Recognit. Lett. 2016, 73, 41–43. [Google Scholar] [CrossRef]
- Lucena, B. Exploiting Categorical Structure Using Tree-Based Methods. arXiv 2020, arXiv:2004.07383. [Google Scholar]
- Abeyrathna, K.D.; Granmo, O.C.; Goodwin, M. On Obtaining Classification Confidence, Ranked Predictions and AUC with Tsetlin Machines. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, ACT, Australia, 1–4 December 2020; pp. 662–669. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter/Symbol | Description | Parameter/Symbol | Description |
|---|---|---|---|
| Input vector containing o propositional variables | The augmented feature set containing both original and negated features | ||
| propositional variable | literal | ||
| m | The number of clauses | clause and stored in vector | |
| The index set of the included literals in clause j | N | The number of states per action in the TA | |
| State of the literal in the clause, stored in matrix | The indexes of the literals of value 1 | ||
| v | The difference between positive and negative clause outputs | Decision on receiving Type I or Type II feedback, stored in vector | |
| T | Feedback threshold | s | Learning sensitivity |
| The decision whether the TA of the clause is to receive Type Ia feedback, stored in matrix | The decision whether the TA of the clause is to receive Type Ib feedback, stored in matrix | ||
| Stores TA indexes selected for Type Ia feedback | Stores TA indexes selected for Type Ib feedback | ||
| ⊕ | Denotes adding 1 to the current state value of the TA | ⊖ | Denotes substracting 1 from the current state value of the TA |
| Stores TA indexes selected for Type II feedback |
| Raw Feature | Thresholds | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | ≤3.834 | ≤5.779 | ≤10.008 | ≤11.6 | ≤25.7 | ≤32.4 | ≤56.1 |
| 5.779 | 25.7 | 0 | 1 | 1 | 0 | 1 | 1 | 1 |
| 10.008 | 56.1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 5.779 | 11.6 | 0 | 1 | 1 | 1 | 1 | 1 | 1 |
| 3.834 | 32.4 | 1 | 1 | 1 | 0 | 0 | 1 | 1 |
| Parameter/Symbol | Description | Parameter/Symbol | Description |
|---|---|---|---|
| Input vector containing o continuous features | continuous feature | ||
| Lower limit of the continuous feature k in clause j | Upper limit of the continuous feature k in clause j | ||
| Feedback to the SSL automata which represent the lower limit of the feature k in clause j | Feedback to the SSL automata which represent the upper limit of the feature k in clause j | ||
| TA which decides whether to include or exclude lower limit of the feature in clause j | TA which decides whether to include or exclude upper limit of the feature in clause j | ||
| The decision whether the TA of the lower limit of feature in the clause is to receive Type Ia feedback | The decision whether the TA of the upper limit of feature in the clause is to receive Type Ia feedback | ||
| The decision whether the TA of the lower limit of feature in the clause is to receive Type Ib feedback | The decision whether the TA of the upper limit of feature in the clause is to receive Type Ib feedback | ||
| Computed literal value for the feature in clause j |
| Dataset | Number of Instances | Number of Attributes | Interpretability Needed |
|---|---|---|---|
| Corporate Bankruptcy | 250 | 7 | Yes |
| Balance Scale | 625 | 4 | Not necessarily |
| Breast Cancer | 286 | 9 | Yes |
| Liver Disorders | 345 | 7 | Yes |
| Heart Disease | 270 | 13 | Yes |
| Category | Integer Code | Thresholds | ||
|---|---|---|---|---|
| ≤0 | ≤1 | ≤2 | ||
| A | 0 | 1 | 1 | 1 |
| N | 1 | 0 | 1 | 1 |
| P | 2 | 0 | 0 | 1 |
| Clause | Class | TM with | |
|---|---|---|---|
| Booleanized | SSLs | ||
| 1 | 1 | ¬ | - |
| 2 | 0 | ¬ ∧ | |
| 3 | 1 | ¬ | |
| 4 | 0 | ¬ ∧ | |
| 5 | 1 | ¬ | - |
| 6 | 0 | ¬ ∧ | |
| 7 | 1 | - | - |
| 8 | 0 | ¬ ∧ | |
| 9 | 1 | ¬ | - |
| 10 | 0 | ¬ ∧ | |
| Accuracy (Training/Testing) | 0.98/1.00 | 0.99/0.96 | |
| Clause | Class | TM with | |
|---|---|---|---|
| Booleanized | SSLs | ||
| 1 | 1 | ¬ | |
| 2 | 0 | ¬ ∧ | |
| Accuracy (Training/Testing) | 0.99/0.96 | 0.96/0.98 | |
| m | 2 | 10 | 100 | 500 | 2000 | 8000 |
|---|---|---|---|---|---|---|
| Precision | 0.754 | 0.903 | 0.997 | 0.994 | 0.996 | 0.994 |
| Recall | 1.000 | 1.000 | 1.000 | 0.998 | 1.000 | 1.000 |
| F1-Score | 0.859 | 0.948 | 0.984 | 0.996 | 0.998 | 0.997 |
| Accuracy | 0.807 | 0.939 | 0.998 | 0.996 | 0.998 | 0.996 |
| Specificity | 0.533 | 0.860 | 0.995 | 0.993 | 0.996 | 0.990 |
| No. of Lit. | 19 | 88 | 222 | 832 | 3622 | 15,201 |
| m | 2 | 10 | 100 | 500 | 2000 | 8000 |
|---|---|---|---|---|---|---|
| Precision | 0.622 | 0.777 | 0.975 | 0.995 | 0.994 | 0.996 |
| Recall | 0.978 | 0.944 | 0.994 | 1.000 | 0.997 | 0.995 |
| F1-Score | 0.756 | 0.843 | 0.984 | 0.997 | 0.995 | 0.995 |
| Accuracy | 0.640 | 0.787 | 0.982 | 0.997 | 0.995 | 0.994 |
| Specificity | 0.191 | 0.568 | 0.967 | 0.994 | 0.993 | 0.993 |
| No. of Lit. | 8 | 40 | 94 | 398 | 1534 | 7286 |
| Prec. | Reca. | F1 | Acc. | Spec. | No. of Lit. | Memory Required (Training/Testing) | Training Time | |
|---|---|---|---|---|---|---|---|---|
| ANN-1 | 0.990 | 1.000 | 0.995 | 0.994 | 0.985 | - | ≈942.538 KB/≈26.64 KB | 0.227 s. |
| ANN-2 | 0.995 | 0.997 | 0.996 | 0.995 | 0.993 | - | ≈3476.76 KB/≈590.76 KB | 0.226 s. |
| ANN-3 | 0.997 | 0.998 | 0.997 | 0.997 | 0.995 | - | ≈28,862.65 KB/≈1297.12 KB | 0.266 s. |
| DT | 0.988 | 1.000 | 0.993 | 0.993 | 0.985 | - | ≈0.00 KB/≈0.00 KB | 0.003 s. |
| SVM | 1.000 | 0.989 | 0.994 | 0.994 | 1.000 | - | ≈90.11 KB/≈0.00 KB | 0.001 s. |
| KNN | 0.998 | 0.991 | 0.995 | 0.994 | 0.998 | - | ≈0.00 KB/≈286.71 KB | 0.001 s. |
| RF | 0.979 | 0.923 | 0.949 | 0.942 | 0.970 | - | ≈180.22 KB/≈0.00 KB | 0.020 s. |
| XGBoost | 0.996 | 0.977 | 0.983 | 0.983 | 0.992 | - | ≈4964.35 KB/≈0.00 KB | 0.009 s. |
| EBM | 0.987 | 1.000 | 0.993 | 0.992 | 0.980 | - | ≈1425.40 KB/≈0.00 KB | 13.822 s. |
| TM (Booleanized) | 0.996 | 1.000 | 0.998 | 0.998 | 0.996 | 3622 | ≈0.00 KB/≈0.00 KB | 0.148 s. |
| TM (SSLs) | 0.995 | 1.000 | 0.997 | 0.997 | 0.994 | 398 | ≈0.00 KB/≈0.00 KB | 0.119 s. |
| m | 2 | 10 | 100 | 500 | 2000 | 8000 |
|---|---|---|---|---|---|---|
| Precision | 0.647 | 0.820 | 0.966 | 0.949 | 0.926 | 0.871 |
| Recall | 0.986 | 0.965 | 0.930 | 0.934 | 0.884 | 0.746 |
| F1-Score | 0.781 | 0.886 | 0.945 | 0.933 | 0.880 | 0.749 |
| Accuracy | 0.728 | 0.875 | 0.948 | 0.936 | 0.889 | 0.780 |
| Specificity | 0.476 | 0.782 | 0.966 | 0.935 | 0.905 | 0.819 |
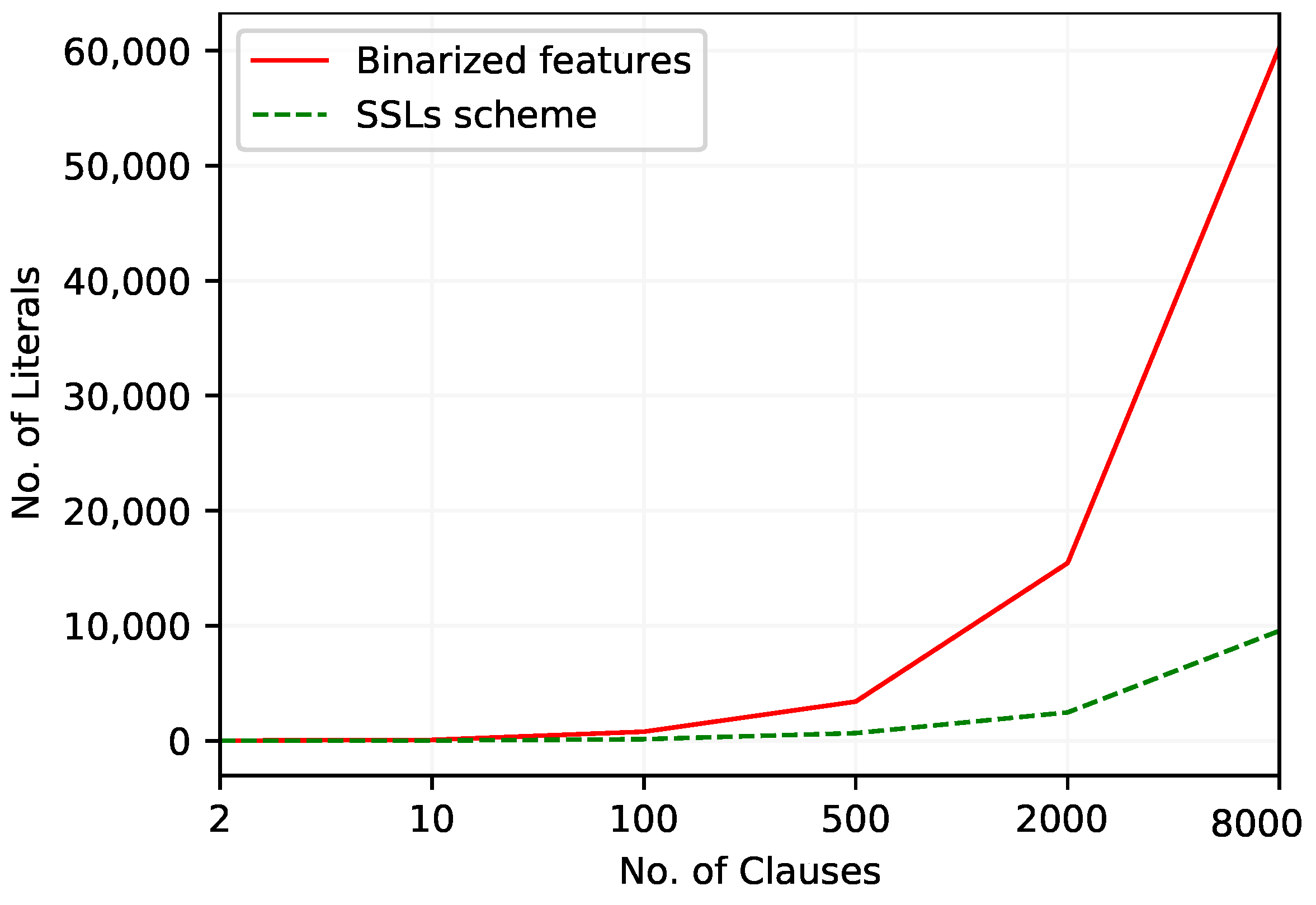
| No. of Lit. | 17 | 77 | 790 | 3406 | 15,454 | 60,310 |
| m | 2 | 10 | 100 | 500 | 2000 | 8000 |
|---|---|---|---|---|---|---|
| Precision | 0.579 | 0.717 | 0.919 | 0.961 | 0.877 | 0.851 |
| Recall | 0.957 | 0.947 | 0.972 | 0.938 | 0.867 | 0.794 |
| F1-Score | 0.717 | 0.812 | 0.944 | 0.946 | 0.854 | 0.781 |
| Accuracy | 0.612 | 0.777 | 0.943 | 0.948 | 0.854 | 0.795 |
| Specificity | 0.254 | 0.598 | 0.916 | 0.959 | 0.840 | 0.795 |
| No. of Lit. | 4 | 17 | 140 | 668 | 2469 | 9563 |
| Prec. | Reca. | F1 | Acc. | Spec. | No. of Lit. | Memory Required (Training/Testing) | Training Time | |
|---|---|---|---|---|---|---|---|---|
| ANN-1 | 0.993 | 0.987 | 0.990 | 0.990 | 0.993 | - | ≈966.57 KB/≈24.56 KB | 0.614 s. |
| ANN-2 | 0.995 | 0.995 | 0.995 | 0.995 | 0.994 | - | ≈3612.65 KB/≈589.82 KB | 0.588 s. |
| ANN-3 | 0.995 | 0.995 | 0.995 | 0.995 | 0.995 | - | ≈33,712.82 KB/≈1478.64 KB | 0.678 s. |
| DT | 0.984 | 0.988 | 0.986 | 0.986 | 0.985 | - | ≈131.07 KB/≈0.00 KB | 0.007 s. |
| SVM | 0.887 | 0.889 | 0.887 | 0.887 | 0.884 | - | ≈65.53 KB/≈241.59 KB | 0.001 s. |
| KNN | 0.968 | 0.939 | 0.953 | 0.953 | 0.969 | - | ≈249.77 KB/≈126.87 KB | 0.001 s. |
| RF | 0.872 | 0.851 | 0.859 | 0.860 | 0.871 | - | ≈0.00 KB/≈0.00 KB | 0.021 s. |
| XGBoost | 0.942 | 0.921 | 0.931 | 0.931 | 0.942 | - | ≈1126.39 KB/≈0.00 KB | 0.030 s. |
| EBM | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | - | ≈1642.49 KB/≈0.00 KB | 15.658 s. |
| TM (Booleanized) | 0.966 | 0.930 | 0.945 | 0.948 | 0.966 | 790 | ≈16.37 KB/≈0.00 KB | 0.011 s. |
| TM (SSLs) | 0.961 | 0.938 | 0.946 | 0.948 | 0.959 | 668 | ≈9.43 KB/≈0.00 KB | 0.004 s. |
| m | 2 | 10 | 100 | 500 | 2000 | 8000 |
|---|---|---|---|---|---|---|
| Precision | 0.518 | 0.485 | 0.295 | 0.101 | 0.058 | 0.054 |
| Recall | 0.583 | 0.380 | 0.416 | 0.205 | 0.200 | 0.250 |
| F1-Score | 0.531 | 0.389 | 0.283 | 0.089 | 0.090 | 0.088 |
| Accuracy | 0.703 | 0.737 | 0.644 | 0.633 | 0.649 | 0.581 |
| Specificity | 0.742 | 0.864 | 0.731 | 0.800 | 0.800 | 0.750 |
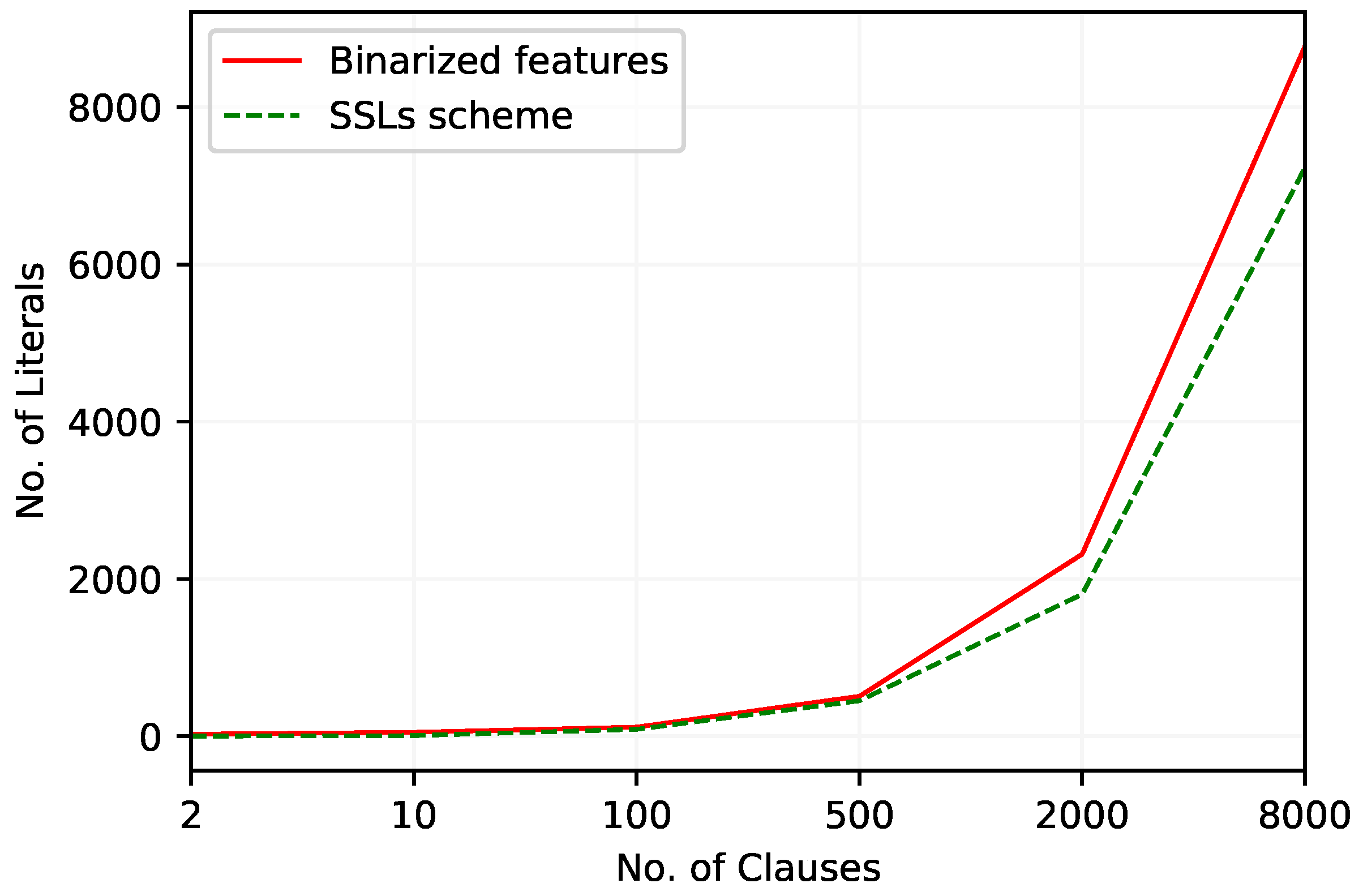
| No. of Lit. | 21 | 73 | 70 | 407 | 1637 | 6674 |
| m | 2 | 10 | 100 | 500 | 2000 | 8000 |
|---|---|---|---|---|---|---|
| Precision | 0.465 | 0.468 | 0.071 | 0.126 | 0.090 | 0.070 |
| Recall | 0.759 | 0.575 | 0.233 | 0.467 | 0.333 | 0.233 |
| F1-Score | 0.555 | 0.494 | 0.109 | 0.195 | 0.141 | 0.107 |
| Accuracy | 0.645 | 0.701 | 0.630 | 0.525 | 0.589 | 0.628 |
| Specificity | 0.599 | 0.753 | 0.778 | 0.551 | 0.682 | 0.775 |
| No. of Lit. | 4 | 16 | 101 | 321 | 997 | 4276 |
| Prec. | Reca. | F1 | Acc. | Spec. | No. of Lit. | Memory Required (Training/Testing) | Training Time | |
|---|---|---|---|---|---|---|---|---|
| ANN-1 | 0.489 | 0.455 | 0.458 | 0.719 | 0.822 | - | ≈1001.97 KB/≈35.74 KB | 0.249 s. |
| ANN-2 | 0.430 | 0.398 | 0.403 | 0.683 | 0.792 | - | ≈3498.47 KB/≈608.71 KB | 0.248 s. |
| ANN-3 | 0.469 | 0.406 | 0.422 | 0.685 | 0.808 | - | ≈38,645.07 KB/≈1837.76 KB | 0.288 s. |
| DT | 0.415 | 0.222 | 0.276 | 0.706 | 0.915 | - | ≈102.39 KB/≈0.00 KB | 0.005 s. |
| SVM | 0.428 | 0.364 | 0.384 | 0.678 | 0.805 | - | ≈241.66 KB/≈299.00 KB | 0.001 s. |
| KNN | 0.535 | 0.423 | 0.458 | 0.755 | 0.871 | - | ≈249.85 KB/≈61.43 KB | 0.001 s. |
| RF | 0.718 | 0.267 | 0.370 | 0.747 | 0.947 | - | ≈139.26 KB/≈0.00 KB | 0.020 s. |
| XGBoost | 0.428 | 0.344 | 0.367 | 0.719 | 0.857 | - | ≈1327.10 KB/≈0.00 KB | 0.026 s. |
| EBM | 0.713 | 0.281 | 0.389 | 0.745 | 0.944 | - | ≈1724.41 KB/≈0.00 KB | 6. 007 s. |
| TM (Booleanized) | 0.518 | 0.583 | 0.531 | 0.703 | 0.742 | 21 | ≈0.00 KB/≈0.00 KB | 0.001 s. |
| TM (SSLs) | 0.465 | 0.759 | 0.555 | 0.645 | 0.599 | 4 | ≈0.00 KB/≈0.00 KB | 0.001 s. |
| m | 2 | 10 | 100 | 500 | 2000 | 8000 |
|---|---|---|---|---|---|---|
| Precision | 0.566 | 0.540 | 0.506 | 0.455 | 0.442 | 0.417 |
| Recall | 0.799 | 0.597 | 0.508 | 0.595 | 0.500 | 0.593 |
| F1-Score | 0.648 | 0.550 | 0.389 | 0.450 | 0.375 | 0.437 |
| Accuracy | 0.533 | 0.540 | 0.516 | 0.522 | 0.526 | 0.504 |
| Specificity | 0.204 | 0.436 | 0.497 | 0.395 | 0.500 | 0.396 |
| No. of Lit. | 27 | 51 | 117 | 509 | 2315 | 8771 |
| m | 2 | 10 | 100 | 500 | 2000 | 8000 |
|---|---|---|---|---|---|---|
| Precision | 0.619 | 0.591 | 0.546 | 0.420 | 0.414 | 0.522 |
| Recall | 0.905 | 0.924 | 0.605 | 0.700 | 0.700 | 0.407 |
| F1-Score | 0.705 | 0.709 | 0.447 | 0.525 | 0.520 | 0.298 |
| Accuracy | 0.587 | 0.574 | 0.526 | 0.546 | 0.543 | 0.461 |
| Specificity | 0.101 | 0.098 | 0.400 | 0.300 | 0.300 | 0.600 |
| No. of Lit. | 2 | 9 | 89 | 452 | 1806 | 7229 |
| Prec. | Reca. | F1 | Acc. | Spec. | No. of Lit. | Memory Required (Training/Testing) | Training Time | |
|---|---|---|---|---|---|---|---|---|
| ANN-1 | 0.651 | 0.702 | 0.671 | 0.612 | 0.490 | - | ≈985.13 KB/≈18.53 KB | 0.305 s. |
| ANN-2 | 0.648 | 0.664 | 0.652 | 0.594 | 0.505 | - | ≈3689.39 KB/≈598.26 KB | 0.305 s. |
| ANN-3 | 0.650 | 0.670 | 0.656 | 0.602 | 0.508 | - | ≈38,365.46 KB/≈1758.23 KB | 0.356 s. |
| DT | 0.591 | 0.957 | 0.728 | 0.596 | 0.135 | - | ≈49.15 KB/≈0.00 KB | 0.025 s. |
| SVM | 0.630 | 0.624 | 0.622 | 0.571 | 0.500 | - | ≈1597.43 KB/≈0.00 KB | 0.005 s. |
| KNN | 0.629 | 0.651 | 0.638 | 0.566 | 0.440 | - | ≈0.00 KB/≈434.17 KB | 0.001 s. |
| RF | 0.618 | 0.901 | 0.729 | 0.607 | 0.192 | - | ≈0.00 KB/≈0.00 KB | 0.017 s. |
| XGBoost | 0.641 | 0.677 | 0.656 | 0.635 | 0.568 | - | ≈3219.45 KB/≈0.00 KB | 0.081 s. |
| EBM | 0.641 | 0.804 | 0.710 | 0.629 | 0.406 | - | ≈7790.59 KB/≈0.00 KB | 10.772 s. |
| TM (Booleanized) | 0.566 | 0.799 | 0.648 | 0.533 | 0.204 | 27 | ≈0.00 KB/≈0.00 KB | 0.003 s. |
| TM (SSLs) | 0.591 | 0.924 | 0.709 | 0.574 | 0.098 | 9 | ≈0.00 KB/≈0.00 KB | 0.001 s. |
| m | 2 | 10 | 100 | 500 | 2000 | 8000 |
|---|---|---|---|---|---|---|
| Precision | 0.547 | 0.607 | 0.835 | 0.507 | 0.351 | 0.360 |
| Recall | 0.938 | 0.815 | 0.626 | 0.408 | 0.646 | 0.486 |
| F1-Score | 0.682 | 0.687 | 0.665 | 0.383 | 0.446 | 0.392 |
| Accuracy | 0.593 | 0.672 | 0.749 | 0.619 | 0.533 | 0.584 |
| Specificity | 0.306 | 0.566 | 0.848 | 0.803 | 0.460 | 0.665 |
| No. of Lit. | 118 | 346 | 810 | 1425 | 11,399 | 52,071 |
| m | 2 | 10 | 100 | 500 | 2000 | 8000 |
|---|---|---|---|---|---|---|
| Precision | 0.529 | 0.588 | 0.562 | 0.305 | 0.674 | 0.687 |
| Recall | 0.971 | 0.915 | 0.504 | 0.431 | 0.660 | 0.667 |
| F1-Score | 0.680 | 0.714 | 0.510 | 0.343 | 0.571 | 0.555 |
| Accuracy | 0.591 | 0.674 | 0.709 | 0.630 | 0.633 | 0.581 |
| Specificity | 0.272 | 0.471 | 0.853 | 0.701 | 0.582 | 0.512 |
| No. of Lit. | 10 | 42 | 151 | 783 | 3152 | 12,365 |
| Prec. | Reca. | F1 | Acc. | Spec. | No. of Lit. | Memory Required (Training/Testing) | Training Time | |
|---|---|---|---|---|---|---|---|---|
| ANN-1 | 0.764 | 0.724 | 0.738 | 0.772 | 0.811 | - | ≈973.64 KB/≈16.46 KB | 0.297 s. |
| ANN-2 | 0.755 | 0.736 | 0.742 | 0.769 | 0.791 | - | ≈3659.59 KB/≈578.11 KB | 0.266 s. |
| ANN-3 | 0.661 | 0.662 | 0.650 | 0.734 | 0.784 | - | ≈33,952.49 KB/≈1513.41 KB | 0.308 s. |
| DT | 0.827 | 0.664 | 0.729 | 0.781 | 0.884 | - | ≈0.00 KB/≈266.23 KB | 0.016 s. |
| SVM | 0.693 | 0.674 | 0.679 | 0.710 | 0.740 | - | ≈1363.96 KB/≈262.14 KB | 0.004 s. |
| KNN | 0.682 | 0.615 | 0.641 | 0.714 | 0.791 | - | ≈0.00 KB/≈319.48 KB | 0.001 s. |
| RF | 0.810 | 0.648 | 0.713 | 0.774 | 0.879 | - | ≈413.69 KB/≈0.00 KB | 0.017 s. |
| XGBoost | 0.712 | 0.696 | 0.701 | 0.788 | 0.863 | - | ≈3694.58 KB/≈0.00 KB | 0.057 s. |
| EBM | 0.827 | 0.747 | 0.783 | 0.824 | 0.885 | - | ≈4763.64 KB/≈0.00 KB | 11.657 s. |
| TM (Booleanized) | 0.607 | 0.815 | 0.687 | 0.672 | 0.566 | 346 | ≈0.00 KB/≈0.00 KB | 0.014 s. |
| TM (SSLs) | 0.588 | 0.915 | 0.714 | 0.674 | 0.471 | 42 | ≈0.00 KB/≈0.00 KB | 0.001 s. |
| Model | Fraud Detection | COMPAS | CA-58 |
|---|---|---|---|
| Logistic Regression | 0.975 | 0.730 | - |
| DT | 0.956 | 0.723 | - |
| NAMs | 0.980 | 0.741 | - |
| EBM | 0.976 | 0.740 | - |
| XGBoost | 0.981 | 0.742 | - |
| DNNs | 0.978 | 0.735 | - |
| LightBoost | - | - | ≈0.760 † |
| CatBoost | - | - | ≈0.760 † |
| StructureBoost | - | - | ≈0.764 † |
| TM (SSLs) | 0.981 | 0.732 | 0.770 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abeyrathna, K.D.; Granmo, O.-C.; Goodwin, M. Adaptive Sparse Representation of Continuous Input for Tsetlin Machines Based on Stochastic Searching on the Line. Electronics 2021, 10, 2107. https://doi.org/10.3390/electronics10172107
Abeyrathna KD, Granmo O-C, Goodwin M. Adaptive Sparse Representation of Continuous Input for Tsetlin Machines Based on Stochastic Searching on the Line. Electronics. 2021; 10(17):2107. https://doi.org/10.3390/electronics10172107
Chicago/Turabian StyleAbeyrathna, Kuruge Darshana, Ole-Christoffer Granmo, and Morten Goodwin. 2021. "Adaptive Sparse Representation of Continuous Input for Tsetlin Machines Based on Stochastic Searching on the Line" Electronics 10, no. 17: 2107. https://doi.org/10.3390/electronics10172107
APA StyleAbeyrathna, K. D., Granmo, O.-C., & Goodwin, M. (2021). Adaptive Sparse Representation of Continuous Input for Tsetlin Machines Based on Stochastic Searching on the Line. Electronics, 10(17), 2107. https://doi.org/10.3390/electronics10172107