
SORT-YM: An Algorithm of Multi-Object Tracking with YOLOv4-Tiny and Motion Prediction



Abstract
:
1. Introduction
- We utilize the YOLOv4-tiny in the TBD paradigm to improve the tracking accuracy and speed of our model.
- We design a motion prediction strategy to predict the location of lost objects, effectively reducing the number of ID switches and tracklet segments.
- We compare our approach with state-of-the-art methods and analyze the effects of introducing the YOLOv4-tiny and the motion prediction strategy with the MOT-15 and MOT-16 datasets.
2. Related Works
2.1. Object Detection Approaches
2.2. Data Association Approaches
3. The Proposed Method
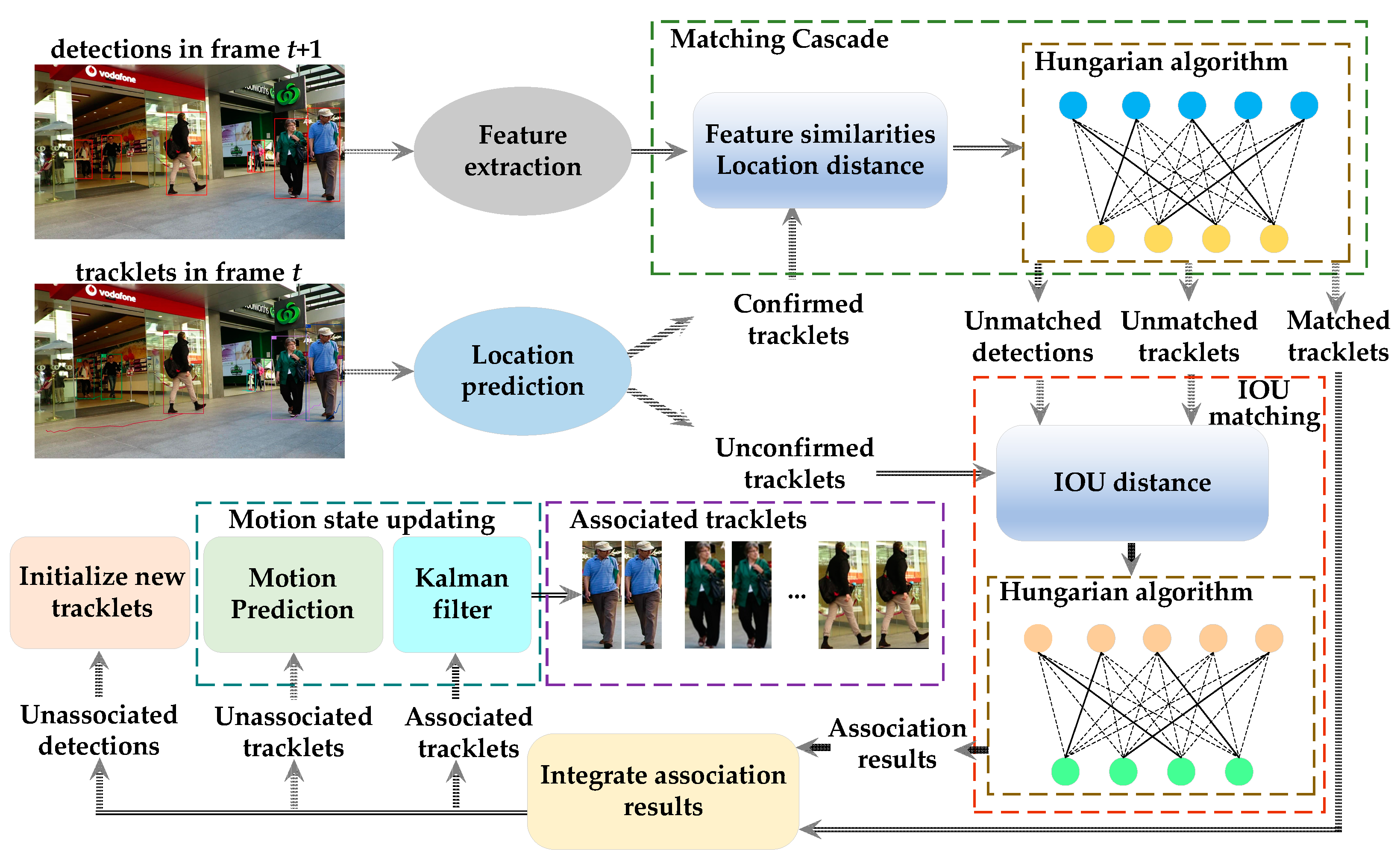
3.1. Overall Framework of SORT-YM
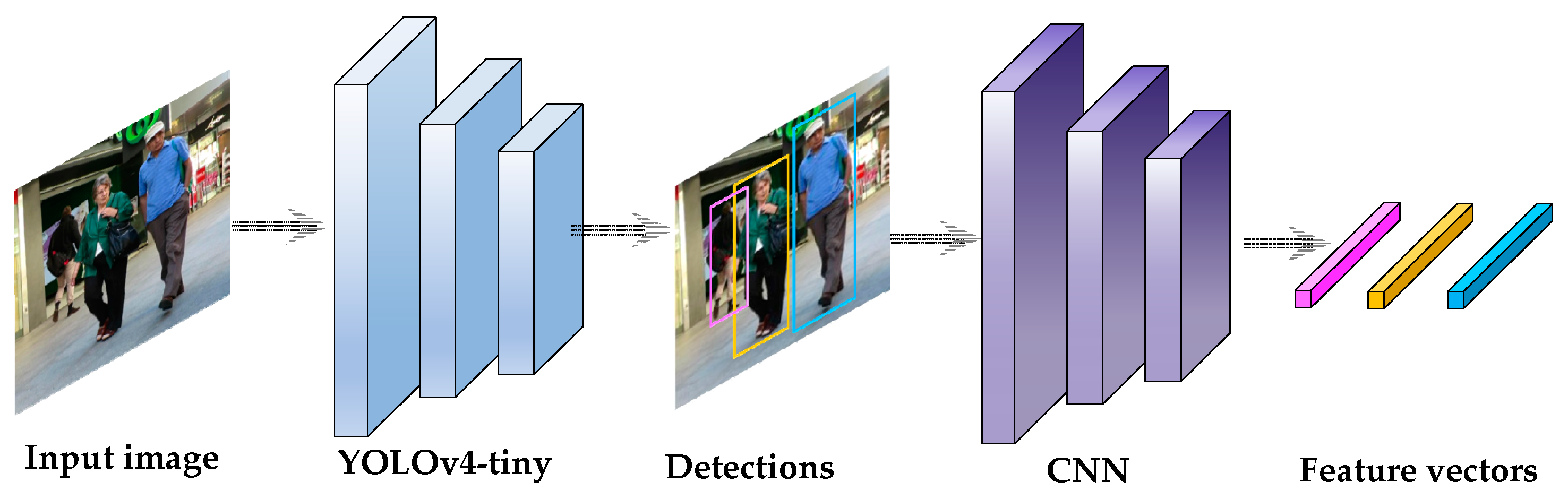
- Step 1. The detection generation: We apply efficient YOLOv4-tiny to produce the detections for each video frame.
- Step 2. The appearance feature extraction: The appearance features of each detection are extracted through a convolutional neural network.
- Step 3. The tracklet location prediction: We can obtain the predicted location of every tracklet in the next frame by utilizing the Kalman filter.
- Step 4. The matching cascade: We calculate the appearance feature similarity and location distance between the confirmed tracklets and detections. After that, the association results of the confirmed tracklets and detections are obtained through the Hungarian algorithm.
- Step 5. The IOU matching: We compute the intersection-over-union (IOU) between the detection boxes and predicted bounding boxes of candidate tracklets. After that, the association results of the candidate tracklets and detections are obtained through the Hungarian algorithm.
- Step 6. The motion state updating: We update the motion state of the tracklets by the Kalman filter and the motion prediction model. Then, we initialize new tracklets for unassociated detections.
3.2. YOLOv4-Tiny Model
3.3. Data Association
3.3.1. Feature Extraction
3.3.2. Motion State Estimation
3.3.3. Matching Cascade
3.3.4. IOU Matching
3.3.5. Motion State Updating
3.3.6. Motion Prediction Strategy
| Algorithm 1 SORT-YM | ||
| Input: A video with T frames | ||
| Output: Tracklets of the video | ||
| fort = 1,…, T do | ||
| Detect the location of objects by YOLOv4-tiny | ||
| Extract the appearance feature of each detected object through the CNN | ||
| Predict new location of each tracklet using Kalman filter | ||
| foreach confirmed trackletdo | ||
| Calculate the cost matrix C = [ci,j] using cosine distance between the feature of tracklet and each detection | ||
| Calculate the Mahalanobis distance matrix B = [bi,j] between the predicted location of the i-th tracklet and the j-th detection | ||
| ifbi,j ≥ ζ do | ||
| ci,j = 10 | ||
| end | ||
| end | ||
| Obtain the association results of matching cascade using Hungarian algorithm based on C | ||
| foreach unconfirmed tracklet and unassociated confirmed trackletdo | ||
| Calculate the IOU matrix U = [ui,j] using the IOU between the predicted box of tracklet and each detection box | ||
| end | ||
| Obtain the association results of IOU matching using Hungarian algorithm based on U | ||
| Integrate the association results of matching cascade and IOU matching | ||
| foreach associated trackletdo | ||
| Update the predicted location using Kalman filter | ||
| end | ||
| foreach unassociated trackletdo | ||
| ifthe tracklet is continuously unassociated for 30 framesdo | ||
| Remove the tracklet from candidates | ||
| else | ||
| Predict the location using motion prediction | ||
| end | ||
| end | ||
| fordetections not associated with trackletsdo | ||
| Initialize a new tracklet based on the detection results | ||
| end | ||
| end | ||
4. Experimental Results and Analyses
4.1. Experimental Settings
4.2. Dataset and Evaluation Metrics
4.2.1. Dataset Protocol
- A large number of objects: The number of the annotated bounding boxes for all testing video sequences is 61,440. Therefore, it is difficult for the algorithm to achieve a high tracking accuracy with a fast speed.
- Static or moving camera: Among the 11 testing video sequences, six videos are taken by a static camera, and a moving camera takes the remaining videos. These two modes of videos increase the requirement for the algorithm to predict the location of tracklets.
- Different viewpoints: Each video sequence has a different viewpoint owing to the different heights of the camera. Videos from multiple perspectives increase the difficulty of object detection and feature extraction.
- Varying weather conditions: A sunny weather video may contain some shadows, while the videos with dark or cloudy weather have lower visibility, making pedestrian detection and tracking more difficult.
4.2.2. Evaluation Metrics
4.3. Comparison with the State-of-the-Art Algorithms
4.3.1. Experiment on MOT-15 Dataset
4.3.2. Experimental on MOT-16 Dataset
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- He, Y.H.; Wei, X.; Hong, X.P.; Shi, W.W.; Gong, Y.H. Multi-Target Multi-Camera Tracking by Tracklet-to-Target Assignment. IEEE Trans. Image Process. 2020, 29, 5191–5205. [Google Scholar] [CrossRef]
- Sun, S.J.; Akhtar, N.; Song, H.S.; Mian, A.S.; Shah, M. Deep Affinity Network for Multiple Object Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 104–119. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Felzenszwalb, P.; Girshick, R.; McAllester, D.; Ramanan, D. Object detection with discriminative trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Everingham, M.; Van, G.L.; Williams, C.; Winn, J.; Zisserman, A. The pascal visual object classes (VoC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolution networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Renmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, WA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Renmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Reid, D. An algorithm for tracking multiple targets. IEEE Trans. Automat. Contr. 1979, 24, 843–854. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagent classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 2, 1097–1105. [Google Scholar]
- Kim, C.; Li, F.; Ciptadi, A.; Rehg, J.M. Multiple hypothesis tracking revisited. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 4696–4704. [Google Scholar]
- Fortmann, T.; Bar-Shalom, Y.; Scheffe, M. Sonar tracking of multiple targets using joint probabilistic data association. IEEE J. Oceanic Eng. 1983, 8, 173–184. [Google Scholar] [CrossRef] [Green Version]
- Rezatofighi, S.H.; Milan, A.; Zhang, Z.; Shi, Q.F.; Dick, A.; Reid, I. Joint Probabilistic Data Association Revisited. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 3047–3055. [Google Scholar]
- Han, X.W.; Wang, Y.W.; Xie, Y.H.; Gao, Y.; Lu, Z. Multi-channel scale adaptive target tracking based on double correlation filter. Chin. J. Sci. Instrum. 2019, 40, 73–81. [Google Scholar]
- Bae, S.H.; Yoon, K.J. Robust online multi-object tracking based on tracklet confidence and online discriminative appearance learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1218–1225. [Google Scholar]
- Xiang, Y.; Alahi, A.; Savarese, S. Learning to track: Online multi-object tracking by decision making. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Santiago, Chile, 11–18 December 2015; pp. 4705–4713. [Google Scholar]
- Leal-Taixe, L.; Milan, A.; Reid, I.; Roth, S.; Schindler, K. MOTChallenge 2015: Towards a Benchmark for Multi-Target Tracking. arXiv 2015, arXiv:1504-01942. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Chen, L.; Ai, H.Z.; Zhuang, Z.J.; Shang, C. Real-time Multiple People Tracking with Deeply Learned Candidate Selection and Person Re-Identification. In Proceedings of the IEEE Conference on Multimedia and Expo, San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Milan, A.; Leal-Taixe, L.; Reid, I.; Roth, S.; Schindler, K. Mot16: A benchmark for multi-object tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Wang, Z.; Zheng, L.; Liu, Y.X.; Wang, S.J. Towards real-time multi-object tracking. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 107–122. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Unde, A.S.; Rameshan, R.M. MOTS R-CNN: Cosine-margin-triplet loss for multi-object tracking. arXiv 2021, arXiv:2102.03512. [Google Scholar]
- Zheng, L.; Bie, Z.; Sun, Y.F.; Wang, J.D.; Su, C.; Wang, S.J.; Tian, Q. MARS: A Video Benchmark for Large-Scale Person Re-Identification. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 868–884. [Google Scholar]
- Kalman, R. A New Approach to Linear Filtering and Prediction Problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef] [Green Version]
- Kuhn, H.W. The Hungarian Method for the assignment problem. Nav. Res. Logist. 2005, 52, 7–21. [Google Scholar] [CrossRef] [Green Version]
- Ess, A.; Leibe, B.; Schindler, K.; Van, G.L. A mobile vision system for robust multi-person tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1857–1864. [Google Scholar]
- Zhang, S.S.; Benenson, R.; Schiele, B. CityPersons: A Diverse Dataset for Pedestrian Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4457–4465. [Google Scholar]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: A benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 304–311. [Google Scholar]
- Xiao, T.; Li, S.; Wang, B.C.; Lin, L.; Wang, X.G. Joint Detection and Identification Feature Learning for Person Search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3376–3385. [Google Scholar]
- Zheng, L.; Zhang, H.H.; Sun, S.Y.; Chandraker, M.; Yang, Y.; Tian, Q. Person Re-identification in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3346–3355. [Google Scholar]
- Dendofer, P.; Osep, A.; Milan, A.; Schindler, K.; Cremers, D.; Reid, I.; Roth, S.; Leal-Taixe, L. MOTChallenge: A Benchmark for Single-Camera Multiple Target Tracking. Int. J. Comput. Vis. 2020, 129, 845–881. [Google Scholar] [CrossRef]
- Laura, L.T.; Cristian, C.F.; Konrad, S. Learning by tracking: Siamese cnn for robust target association. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 418–425. [Google Scholar]
- Son, J.; Beak, M.; Cho, M.; Han, B. Multi-Object Tracking with Quadruplet Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3786–3795. [Google Scholar]
- Chen, L.T.; Peng, X.J.; Ren, M.W. Recurrent Metric Networks and Batch Multiple Hypothesis for Multi-Object Tracking. IEEE Access 2019, 7, 3093–3105. [Google Scholar] [CrossRef]
- Milan, A.; Rezatofighi, S.H.; Dick, A.; Reid, I.; Schindler, K. Online Multi-Target Tracking Using Recurrent Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4225–4232. [Google Scholar]
- Chu, Q.; Ouyang, W.L.; Li, H.S.; Wang, X.G.; Liu, B.; Yu, N.H. Online Multi-Object Tracking Using CNN-based Single Object Tracker with Spatial-Temporal Attention Mechanism. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4846–4855. [Google Scholar]
- Yang, M.; Wu, Y.W.; Jia, Y.D. A Hybrid Data Association Framework for Robust Online Multi-Object Tracking. IEEE Trans. Image Process. 2017, 26, 5667–5679. [Google Scholar] [CrossRef] [Green Version]
- Sadeghian, A.; Alahi, A.; Savarese, S. Tracking The Untrackable: Learning to Track Multiple Cues with Long-Term Dependencies. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 300–311. [Google Scholar]
- Chen, L.; Ai, H.Z.; Shang, C.; Zhuang, Z.J.; Bai, B. Online multi-object tracking with convolutional neural networks. In Proceedings of the International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 645–649. [Google Scholar]
- Fang, K.; Xiang, Y.; Li, X.C.; Savarese, S. Recurrent Autoregressive Networks for Online Multi-Object Tracking. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 466–475. [Google Scholar]
- Xiang, J.; Zhang, G.S.; Hou, J.H. Online Multi-Object Tracking Based on Feature Representation and Bayesian Filtering Within a Deep Learning Architecture. IEEE Access 2019, 7, 27923–27935. [Google Scholar] [CrossRef]
- Bewley, A.; Ge, Z.Y.; Ott, L.; Ramov, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Bullinger, S.; Bodensteiner, C.; Arens, M. Instance flow based online multiple object tracking. In Proceedings of the IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 785–789. [Google Scholar]
- Geiger, A.; Lauer, M.; Wojek, C.; Stiller, C.; Urtasun, R. 3D traffic scene understanding from movable platforms. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1012–1025. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Le, N.; Heili, A.; Odobez, J.M. Long-term time-sensitive costs for crf-based tracking by detection. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 43–51. [Google Scholar]
- Fagot-Bouquet, L.; Audigier, R.; Dhome, Y.; Lerasle, F. Improving multi-frame data association with sparse representations for robust near-online multi-object tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 774–790. [Google Scholar]
- Keuper, M.; Tang, S.; Zhongjie, Y.; Andres, B.; Brox, T.; Schiele, B. A multi-cut formulation for joint segmentation and tracking of multiple objects. arXiv 2018, arXiv:1607.06317. [Google Scholar]
- Choi, W. Near-online multi-target tracking with aggregated local flow descriptor. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 3029–3037. [Google Scholar]
- Yu, F.W.; Li, W.B.; Li, Q.Q.; Liu, Y.; Shi, X.H.; Yan, J.J. POI: Multiple Object Tracking with High Performance Detection and Appearance Feature. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 9–16 October 2016; pp. 36–42. [Google Scholar]
- Tang, S.; Andriluka, M.; Andres, B.; Schiele, B. Multiple people tracking by lifted multicut and person reidentification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3539–3548. [Google Scholar]
- Ban, Y.; Ba, S.; Alameda-Pineda, X.; Horaud, R. Tracking multiple persons based on a variational bayesian model. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 52–67. [Google Scholar]
- Sanchez-Matilla, R.; Poiesi, F.; Cavallaro, A. Online Multi-target Tracking with Strong and Weak Detections. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 9–16 October 2016; pp. 84–99. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Patch Size/Stride | Output Size | |
|---|---|---|
| Conv 1 | 3 × 3/1 | 32 × 128 × 64 |
| Conv 2 | 3 × 3/1 | 32 × 128 × 64 |
| Max-pooling 3 | 3 × 3/2 | 32 × 64 × 32 |
| Residual block 4 | 3 × 3/1 | 32 × 64 × 32 |
| Residual block 5 | 3 × 3/1 | 32 × 64 × 32 |
| Residual block 6 | 3 × 3/2 | 64 × 32 × 16 |
| Residual block 7 | 3 × 3/1 | 64 × 32 × 16 |
| Residual block 8 | 3 × 3/2 | 128 × 16 × 8 |
| Residual block 9 | 3 × 3/1 | 128 × 16 × 8 |
| Dense 10 | 128 | |
| Normalization | 128 |
| Method | Mode | MOTA↑ | MOTP↑ | MT↑ | ML↓ | IDs↓ | FN↓ | FM↓ | FPS↑ |
|---|---|---|---|---|---|---|---|---|---|
| SiameseCNN [39] | Offline | 29.0% | 71.2% | 8.5% | 48.4% | 639 | 37,798 | 1316 | 52.8 |
| Quad-CNN [40] | Offline | 33.8% | 73.4% | 12.9% | 36.9% | 703 | 32,061 | 1430 | 3.7 |
| RMNet [41] | Offline | 28.1% | 74.3% | - | - | 477 | 36,952 | 790 | 16.9 |
| MHT-DAM [17] | Online | 32.4% | 71.8% | 16.0% | 43.8% | 435 | 32,060 | 826 | 0.7 |
| RNN_LSTM [42] | Online | 19.0% | 71.0% | 5.5% | 45.6% | 1490 | 36,706 | 2081 | 165.2 |
| STAM [43] | Online | 34.3% | 70.5% | 11.4% | 43.4% | 348 | 34,848 | 1463 | 0.5 |
| HybridDAT [44] | Online | 35.0% | 72.6% | 11.4% | 42.2% | 358 | 31,140 | 1267 | 4.6 |
| AMIR [45] | Online | 37.6% | 71.7% | 15.8% | 26.8% | 1026 | 29,397 | 2024 | 1.0 |
| AP_RCNN [46] | Online | 38.5% | 72.6% | 8.7% | 37.4% | 586 | 33,204 | 1263 | 6.7 |
| RAN_DPM [47] | Online | 35.1% | 70.9% | 13.0% | 42.3% | 381 | 32,717 | 1523 | 5.4 |
| TripT + BF [48] | Online | 37.1% | 72.5% | 12.6% | 39.7% | 580 | 29,732 | 1193 | 1.0 |
| SORT [49] | Online | 33.4% | 72.1% | 11.7% | 30.9% | 1001 | 32,615 | 1764 | 260.0 |
| MNC + CPM [50] | Online | 32.1% | 70.9% | 13.2% | 30.1% | 1687 | 33,473 | 2471 | - |
| AP_RCNN [46] | Online | 53.0% | 75.5% | 29.1% | 20.2% | 708 | 22,984 | 1476 | 6.7 |
| RAN_FRCNN [47] | Online | 56.5% | 73.0% | 45.1% | 14.6% | 428 | 16,921 | 1364 | 5.1 |
| SORT-YM (proposed) | Online | 58.2% | 79.3% | 44.4% | 12.2% | 604 | 20,753 | 901 | 24.4 |
| Methods | MOTA↑ | MOTP↑ | ML↓ | IDs↓ | FN↓ | FM↓ | FPS↑ |
|---|---|---|---|---|---|---|---|
| Baseline | 61.4% | 79.1% | 18.2% | 781 | 56,668 | 2008 | 14 |
| Baseline + YOLOv4-tiny | 62.6% | 81.2% | 17.3% | 739 | 30,771 | 1995 | 23.8 |
| Baseline + motion prediction | 62.3% | 79.6% | 17.0% | 746 | 28,768 | 1923 | 13.7 |
| SORT-YM | 63.4% | 81.4% | 16.7% | 707 | 21,439 | 1888 | 23.1 |
| Method | Mode | MOTA↑ | MOTP↑ | MT↑ | ML↓ | IDs↓ | FN↓ | FM↓ | FPS↑ |
|---|---|---|---|---|---|---|---|---|---|
| TBD | Offline | 33.7% | 76.5% | 7.2% | 54.2% | 2418 | 112,587 | 2252 | - |
| LTTSC-CRF | Offline | 37.6% | 75.9% | 9.6% | 55.2% | 481 | 101,343 | 1012 | 0.6 |
| LINF | Offline | 41.0% | 74.8% | 11.6% | 51.3% | 430 | 99,224 | 963 | 4.2 |
| MHT_DAM | Offline | 42.9% | 76.6% | 13.6% | 46.9% | 499 | 97,919 | 659 | 0.8 |
| JMC | Offline | 46.3% | 75.7% | 15.5% | 39.7% | 657 | 90,914 | 1114 | 0.8 |
| NOMT | Offline | 46.4% | 76.6% | 18.3% | 41.4% | 359 | 87,565 | 504 | 2.6 |
| NOMTwSDP16 | Offline | 62.2% | 79.6% | 32.5% | 31.1% | 406 | - | 642 | 3 |
| KDNT | Offline | 68.2% | 79.4% | 41.0% | 19.0% | 933 | 45,605 | 1093 | 0.7 |
| LMP_P | Offline | 71.0% | 80.2% | 46.9% | 21.9% | 434 | 44,564 | 587 | 0.5 |
| OVBT | Online | 38.4% | 75.4% | 7.5% | 47.3% | 1321 | 99,463 | 2140 | 0.3 |
| EAMTT_public | Online | 38.8% | 75.1% | 7.9% | 49.1% | 965 | 102,452 | 1657 | 11.8 |
| EAMTT_private | Online | 52.5% | 78.8% | 19.0% | 34.9% | 910 | 81,223 | 1321 | 12 |
| SORT | Online | 59.8% | 79.6% | 25.4% | 22.7% | 1423 | 63,245 | 1835 | 60 |
| Deep SORT (baseline) | Online | 61.4% | 79.1% | 32.8% | 18.2% | 781 | 56,668 | 2008 | 14 |
| SORT-YM | Online | 63.4% | 81.7% | 33.8% | 16.7% | 707 | 21,439 | 1888 | 23.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, H.; Du, C.; Ji, Z.; Gao, M.; He, Z. SORT-YM: An Algorithm of Multi-Object Tracking with YOLOv4-Tiny and Motion Prediction. Electronics 2021, 10, 2319. https://doi.org/10.3390/electronics10182319
Wu H, Du C, Ji Z, Gao M, He Z. SORT-YM: An Algorithm of Multi-Object Tracking with YOLOv4-Tiny and Motion Prediction. Electronics. 2021; 10(18):2319. https://doi.org/10.3390/electronics10182319
Chicago/Turabian StyleWu, Han, Chenjie Du, Zhongping Ji, Mingyu Gao, and Zhiwei He. 2021. "SORT-YM: An Algorithm of Multi-Object Tracking with YOLOv4-Tiny and Motion Prediction" Electronics 10, no. 18: 2319. https://doi.org/10.3390/electronics10182319
APA StyleWu, H., Du, C., Ji, Z., Gao, M., & He, Z. (2021). SORT-YM: An Algorithm of Multi-Object Tracking with YOLOv4-Tiny and Motion Prediction. Electronics, 10(18), 2319. https://doi.org/10.3390/electronics10182319