1. Introduction
Assurance of acceptable image quality is a crucial task in a very wide range of practical applications, such as video surveillance [
1], medical image processing [
2], or vision systems of autonomous vehicles [
3]. Any kind of image noise or distortion does not only deteriorate the users’ visual experience, but can lead to tragic consequences. For instance, the poor or low illumination conditions can easily deteriorate the performance of vision-based object detection (e.g., pedestrians, lane markings, traffic signs, etc.) and semantic segmentation algorithms of autonomous vehicles [
4]. Moreover, assurance of good image quality is of vital importance in medical applications, such as MRI or endoscopic surgery, where image quality may influence the diagnostic accuracy [
5] or the surgeon’s ability to successfully carry out complex medical interventions [
6].
Image quality assessment (IQA) has been in the focus of research for decades [
7]. Despite recent progress, IQA is still a challenging task in the image processing community. Existing IQA approaches are classified into three groups—full-reference (FR), reduced-reference (RR), and no-reference (NR)—depending on the availability of the distortion-free, reference image [
8,
9]. However, the reference image is not available in the majority of real-life applications, thus the development of NR-IQA methods is a very popular research topic in the literature.
To develop, research, rank, and test NR-IQA algorithms, publicly available databases utilized in the literature. During subjective IQA, a large number of human observers are asked to evaluate the quality of a set of digital images. Next, the acquired scores are cleaned and their average are considered as the final quality score which is called mean opinion score (MOS) in the literature. Subjective IQA is usually carried out in a laboratory environment involving experts, however some researchers adopt crowdsourcing to collect individual quality ratings [
10]. Single stimulation, double stimulation, and stimulation comparison methods are the most common ones for subjective scoring in the literature. For more details about subjective scoring, we refer to the work of Zhang et al. [
11]. An overview about a wide range of publicly available IQA databases can be found in [
12].
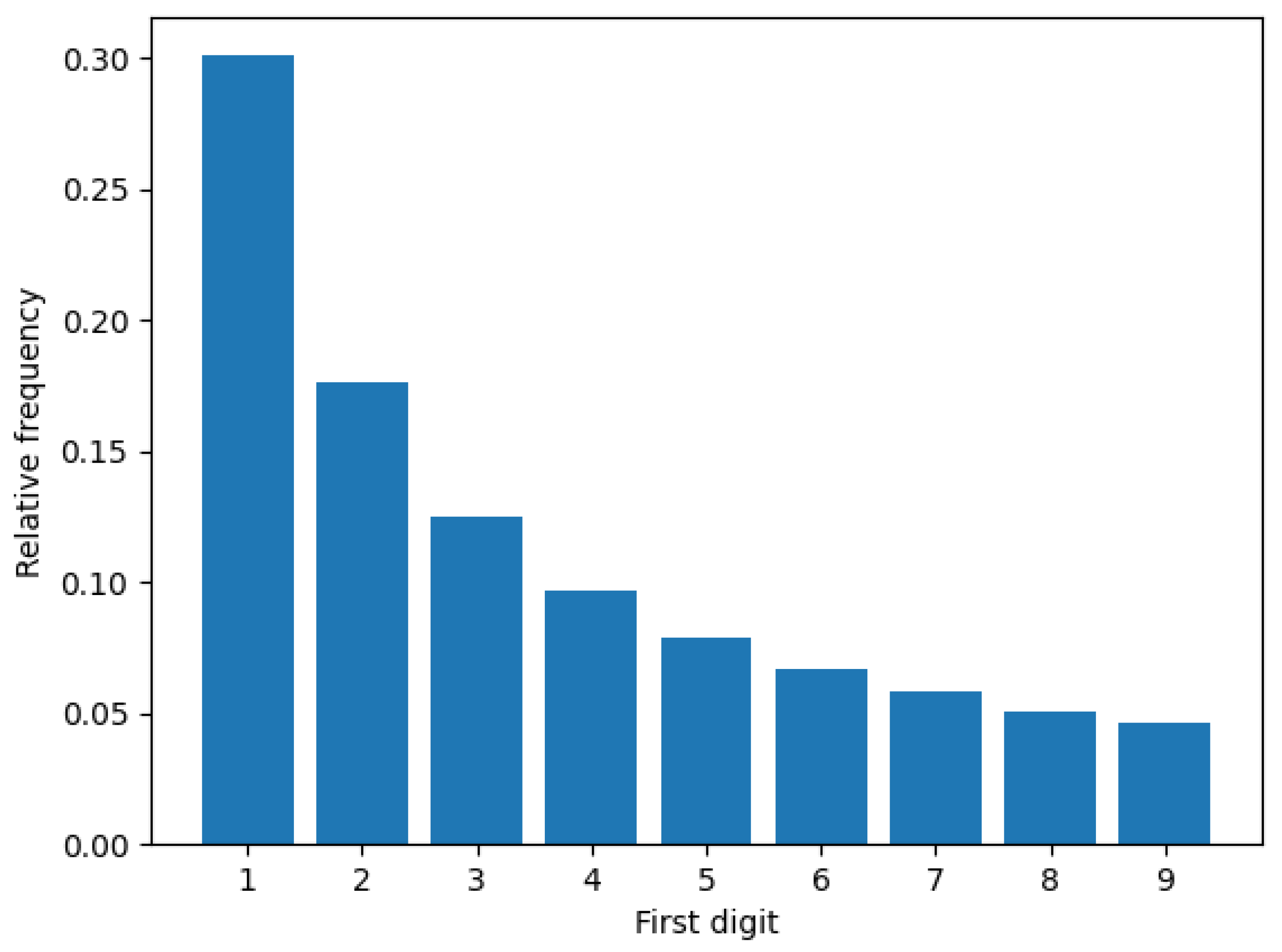
In this paper, we conduct thorough analysis on the features derived from Benford’s law for NR-IQA. Benford’s law, also known as the first digit law or the law of anomalous numbers, is an empirical observation about the relative frequency of first digits in many natural datasets. It was named after Frank Benford who was a physicist at the General Electric Research Laboratories in New York. He noticed that the first few pages of log tables were more worn than the last few pages. As a consequence, the front of the book was more used than the back of the book because there were more numbers that started with low digits than those of started with high digits. According to Benford’s law, the first digit
d occurs with probability
The distribution of Benford’s law prediction (Equation (
1)) is depicted in
Figure 1. Benford’s law has been observed in many natural datasets, such as population numbers, length of rivers, mathematical and physical constants, etc., [
13]. In image processing, Jolion [
14] was the first who demonstrated that gradient images obey the Benford’s law, although it is not satisfied in the pixel domain, as pixel values distribute between 0 and 255. Similarly, Pérez-González et al. [
15] pointed out that the discrete cosine transform (DCT) coefficients of an image follow the distribution predicted by Benford’s law.
First, Li [
16] proposed a Benford’s law based metric combined with color ingredient, image complexity, image order, and Machado–Cardoso metric [
17] to establish an aesthetic-aware feature vector. Specifically, the Benford’s law-based metric was determined as the distance between the first digit distribution (FDD) of Benford’s law prediction and those of 9 bins lightness histogram. A similar approach was taken by Ou et al. [
18] in NR-IQA. A composite feature vector of 51-dimension was proposed where two elements were derived with the help of Benford’s law. Specifically, the Euclidean distance between the FDD of the input image’s DCT coefficients and the FDD predicted by Benford’s law was taken first. Subsequently, one more feature was extracted with the difference that the image is processed first with a Gaussian low pass filter. In our previous work [
19], FDD in the wavelet domain was defined as a quality aware feature vector and used it as a part of a larger composite feature vector for NR-IQA.
The contributions of this work are summarized as follows.
We analyze the FDD-based features in different domains (wavelet, DCT, Shearlet, etc.) for NR-IQA. Unlike in our previous work [
19], we focus on quality-aware feature vectors derived from FDD distributions of different domains.
We apply various regression methods including support vector regression (SVR), Gaussian process regression (GPR), binary tree regression (BTR), and random forest regression (RFR) to give a through performance analysis.
We conduct comparative analysis with other state-of-the-art methods on a wide range of publicly available IQA databases containing natural images with authentic and artificial distortions, screen-content images, and synthetic digital images.
Structure of the Paper
The paper is organized as follows. The related work is surveyed in
Section 2. In
Section 3, our method for FDD feature vector compilation is described.
Section 4 presents the experimental results with analysis. Finally, a conclusion is drawn in
Section 5.
2. Related Work
As already mentioned, the goal of NR-IQA is to predict the perceptual quality of digital images without any information about their distortion-free, reference counterpart. In the literature, NR-IQA algorithms are tested on publicly available benchmark image quality assessment databases, such as CLIVE [
20], KonIQ-10k [
21], or SPAQ [
22], where digital images with their mean opinion score (MOS) or differential mean opinion score (DMOS) values are available. Specifically, individual quality scores are collected from human users for each distorted image either in a laboratory environment [
23] or in a crowdsourcing-based experiment [
10]. Moreover, MOS is determined as an arithemtic mean of individual scores, while DMOS is calculated as the difference between the raw quality score of the reference and test images [
24]. An overview about subjective image quality assessment and publicly available benchmark databases can be found in the book of Xu et al. [
25].
NR-IQA algorithms can be grouped into two classes: distortion-specific and general purpose. As the name indicates, distortion-specific NR-IQA algorithms are designed for specific distortion types, such as JPEG [
26] or JPEG2000 [
27] compression noise. In contrast, general purpose NR-IQA methods are designed to perform over different distortion types. The approach of natural scene statistics (NSS) has been very popular in general purpose NR-IQA. Namely, natural images exhibit a number of statistical regularities in spatial and transform domains that have been utilized to compile feature vectors for perceptual image quality prediction. For instance, blind image quality index (BIQI) decomposes first a distorted image over three scales and orientations using wavelet transform. Subsequently, generalized Gaussian distributions (GGD) are fitted to the wavelet coefficients and 18 quality-aware features are extracted. Finally, the features are mapped onto perceptual quality scores using a trained SVR. Another example is Distortion Identification-based Image Verity and INtegrity Evaluation (DIIVINE) [
28] method where a GGD is fitted to the wavelet coefficients of a distorted image. The parameters of the obtained GGD were utilized as quality-aware feature and mapped onto quality scores with the help of a trained SVR. In contrast, Saad et al. [
29] first divided the distorted image into blocks and a GGD is fitted onto the discrete cosine transform (DCT) coefficients of each block. The parameters of the GGDs are pooled from each block to create a feature vector. Finally, this feature vector is mapped onto quality scores with an SVR. Zhang et al. [
30] proposed an improved NSS model where the errors of GGD parameter fitting were taking into account during the feature extraction step.
Recently, data-driven approaches have gained popularity in NR-IQA that do not rely on NSS-based or other hand-crafted features [
31,
32]. The work of Lv et al. [
33] is a transition between hand-crafted features based and deep learning based approaches. Namely, the authors capitalized on the multi-scale difference of Gaussian (DoG) to decompose the distorted image in the spatial domain to extract quality-aware features. Next, a three-layer stacked autoencoder was used for the generation of feature representations and an SVR was utilized for perceptual quality prediction. In contrast, Kang et al. [
34] trained a convolutional neural network (CNN) on image patches from scratch to estimate image quality. Similarly, Li et al. [
35] trained a CNN on image patches but it was combined with the Prewitt magnitude of segmented images to obtain perceptual quality scores. In contrast, Ma et al. [
36] introduced a multi-task CNN to improve the performance of image quality prediction with image distortion identification. The above-mentioned CNN-based NR-IQA approaches consider the input image’s perceptual quality as the arithmetic mean of the image patches’ predicted quality. He et al. [
37] elaborated a pooling strategy where the image patches’ importance depend on their visual saliency. Tang et al. [
38] trained and fine-tuned a deep belief network to estimate perceptual image quality. Kim and Lee [
39] first trained a CNN on a large number of image patches acquiring quality scores with the help of a traditional FR-IQA metric.
Comprehensive overviews about IQA or NR-IQA can be found in [
9,
25,
40,
41].
3. Methods
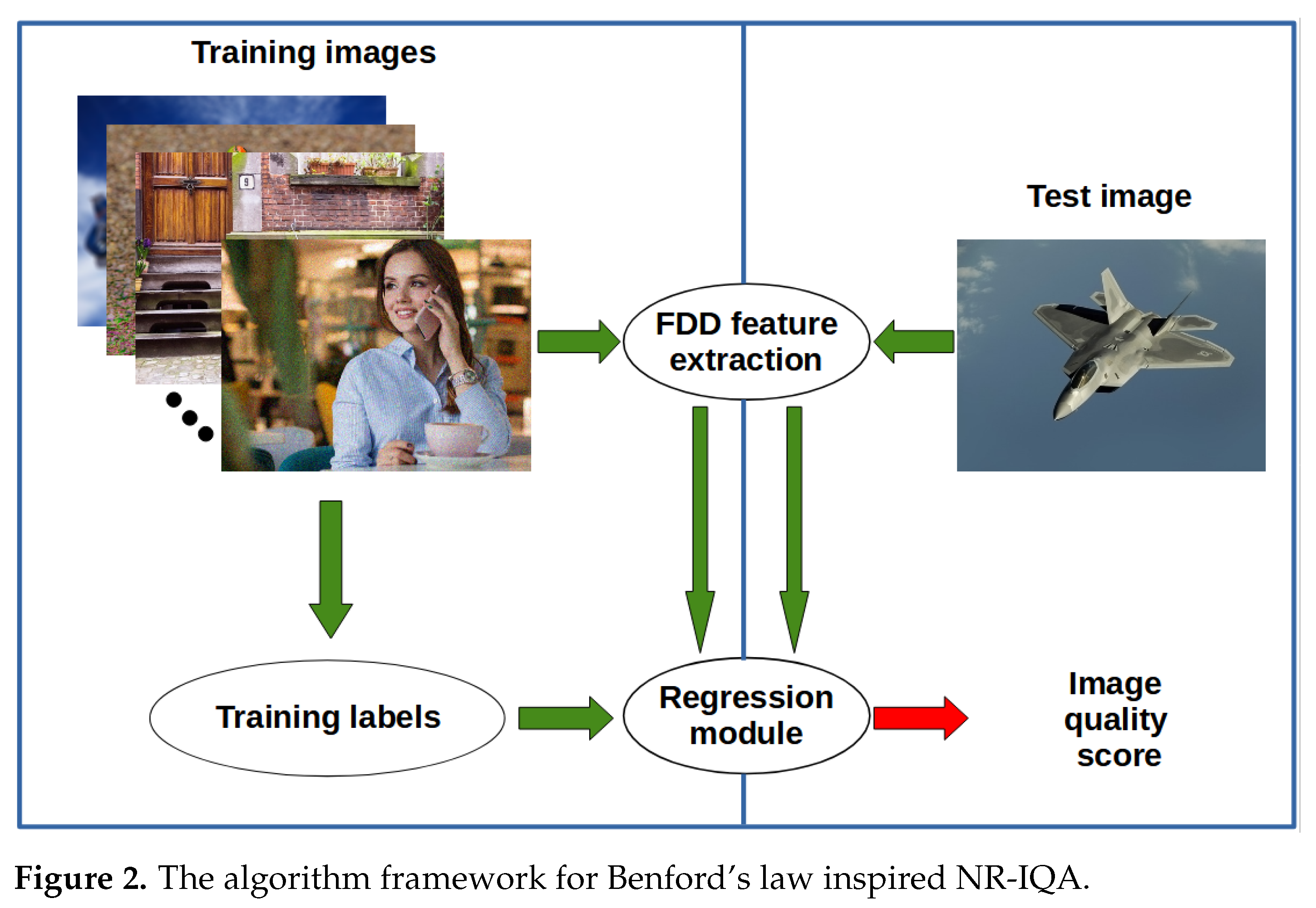
Figure 2 depicts the algorithmic framework of the test environment for Benford’s law inspired no-reference image quality assessment. Specifically, the framework can be divided into two phases. First, the extracted FDD feature vectors and the ground-truth quality scores of the training images are sent to the regression module. Second, the extracted FDD features of a test image are sent to the trained regression module to predict its perceptual quality score. In [
19], it was pointed out that the FDD in different transform domains matches very well with Benford’s law in case of high quality images.
Table 1 illustrates the mean FDD of singular values in KADID-10k with respect to the five distortion levels found in this database. On the other hand,
Table 2 depicts the mean FDD of DCT coefficients with respect to five equal MOS intervals in KonIQ-10k [
21] database. It can be observed that the distance between the actual FDD and Benford’s law prediction is roughly proportional to the level of distortion. In these tables, the distance between distributions is characterized by the symmetric Kullback–Leibler
divergence which is defined as between distributions
and
:
where the Kullback–Leibler (KL) divergence is given as
In this paper, we analyze the efficiency of FDD in horizontal wavelet coefficients, vertical wavelet coefficients, diagonal wavelet coefficients, DCT coefficients, singular values, and the absolute values of shearlet coefficients for image quality prediction without reference images.
Wavelet transforms were devised to overcome the limitations of the Fourier transform. Namely, the Fourier transform decomposes signals into sine and cosine waves of specific frequencies. In contrast, the wavelet transform decomposes signals into shifted and scaled versions of a wavelet. Moreover, a function’s average has to be equal to zero to be a wavelet. In this study, we take the single-level 2D discrete wavelet transform of a digital image applying the order 4 symlet and periodic extension. Moreover, we obtain the FDD from the horizontal, vertical, and diagonal coefficients of the input image’s wavelet transform.
DCT describes digital images as sums of sinusoids of varying amplitudes and frequencies. It is often applied in image compression, as significant information about the image can be found in a few DCT coefficients [
43]. The DCT of a
grayscale image
I is defined as follows:
where
values are the DCT coefficients of image
I.
Singular value decomposition (SVD) can be described as an algorithm for data reduction, as it identifies and orders the dimensions along which data points show the most variation. SVD decomposed a matrix into three other matrices:
where
A is an
matrix,
U is an
orthogonal matrix,
S is an
diagonal matrix, and
V is an
orthogonal matrix. Moreover,
S contains the square roots of eigenvalues from
U or
V in descending order.
The shearlet transform is a multi-scale extension of the traditional wavelet transform so that can handle anisotropic and directional information at multiple scales [
44]. The parabolic scale matrix
and the shear matrix
are required to define a Shearlet system. Formally, they can be expressed as
Subsequently, the shearlet system can be given as
where
g is the scale parameter,
h is the angle parameter, and
m is the position parameter. If these parameters are discretized, a discrete shearlet system can be obtained. The discrete shearlet transform of function
corresponds to the inner product of
f with all the shearlets that can be found in the discrete shearlet system.
In this study, the effects of extended FDD feature vectors for NR-IQA are also investigated. The extended FDD feature vectors augment FDD feature vectors by adding certain divergence and shape parameters to the original FDD. After obtaining the FDD feature vector of an image, the divergence between the actual FDD and Benford’s law prediction, the skewness, the kurtosis, the entropy, the median, and the standard deviation of the actual FDD were attached to the FDD feature vector to obtain the extended FDD feature vector. As a result, the length of the extended FDD is 15.
5. Conclusions
In this paper, Benford’s law, also known as the first digit law, inspired feature vectors were proposed and studied for NR-IQA. Specifically, we analyzed FDD-based feature vectors extracted from different domains (wavelet, DCT, shearlet, singular values) for no-reference quality assessment of natural images with authentic or artificial distortions, screen-content images, and synthetic images. First, a detailed parameter study was presented with respect to different domains and different regression modules. Second, we demonstrated that state-of-the-art performance can be achieved by considering FDDs from different domains. Experimental results have been presented on various IQA benchmark databases containing natural, screen-content, and synthetic digital images.




{kind=link}
{kind=link}

