Representation Learning for Motor Imagery Recognition with Deep Neural Network

 ,
, 

Abstract
:1. Introduction
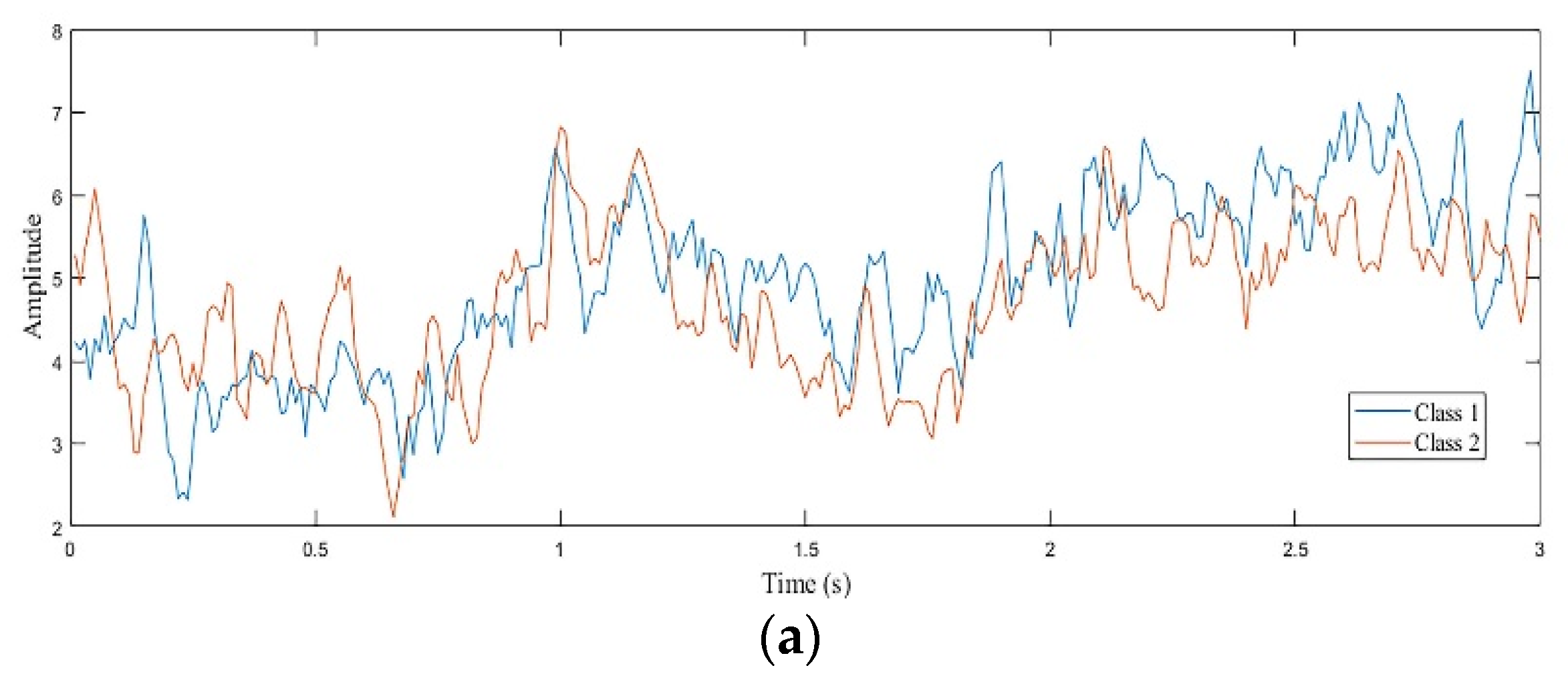
2. ECoG Dataset
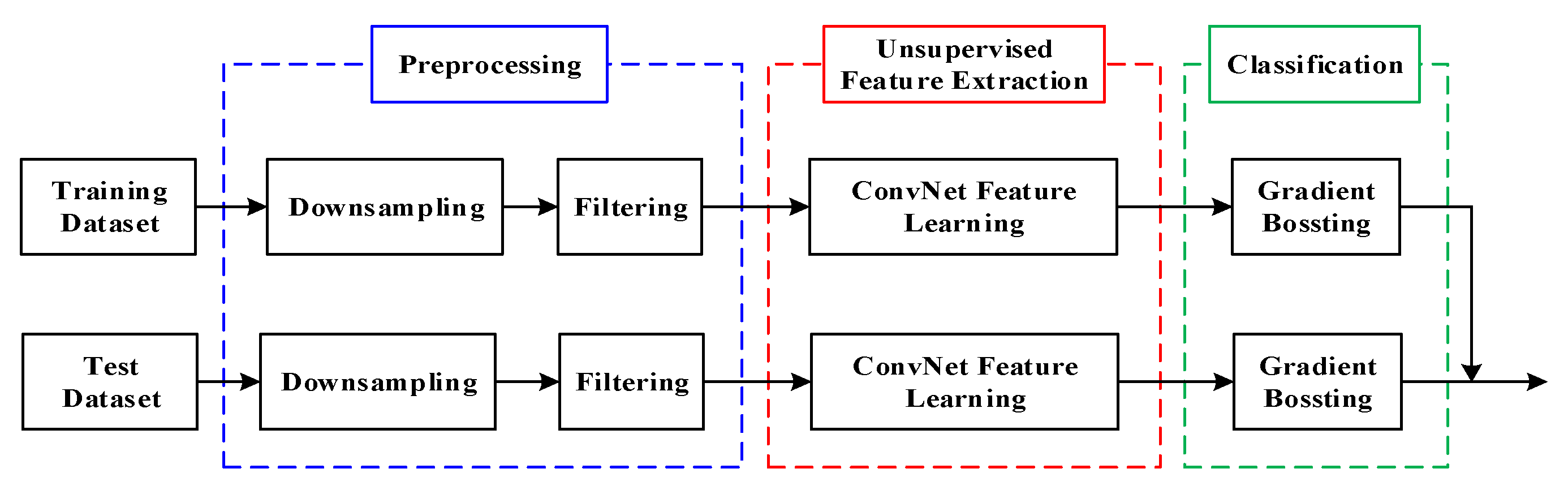
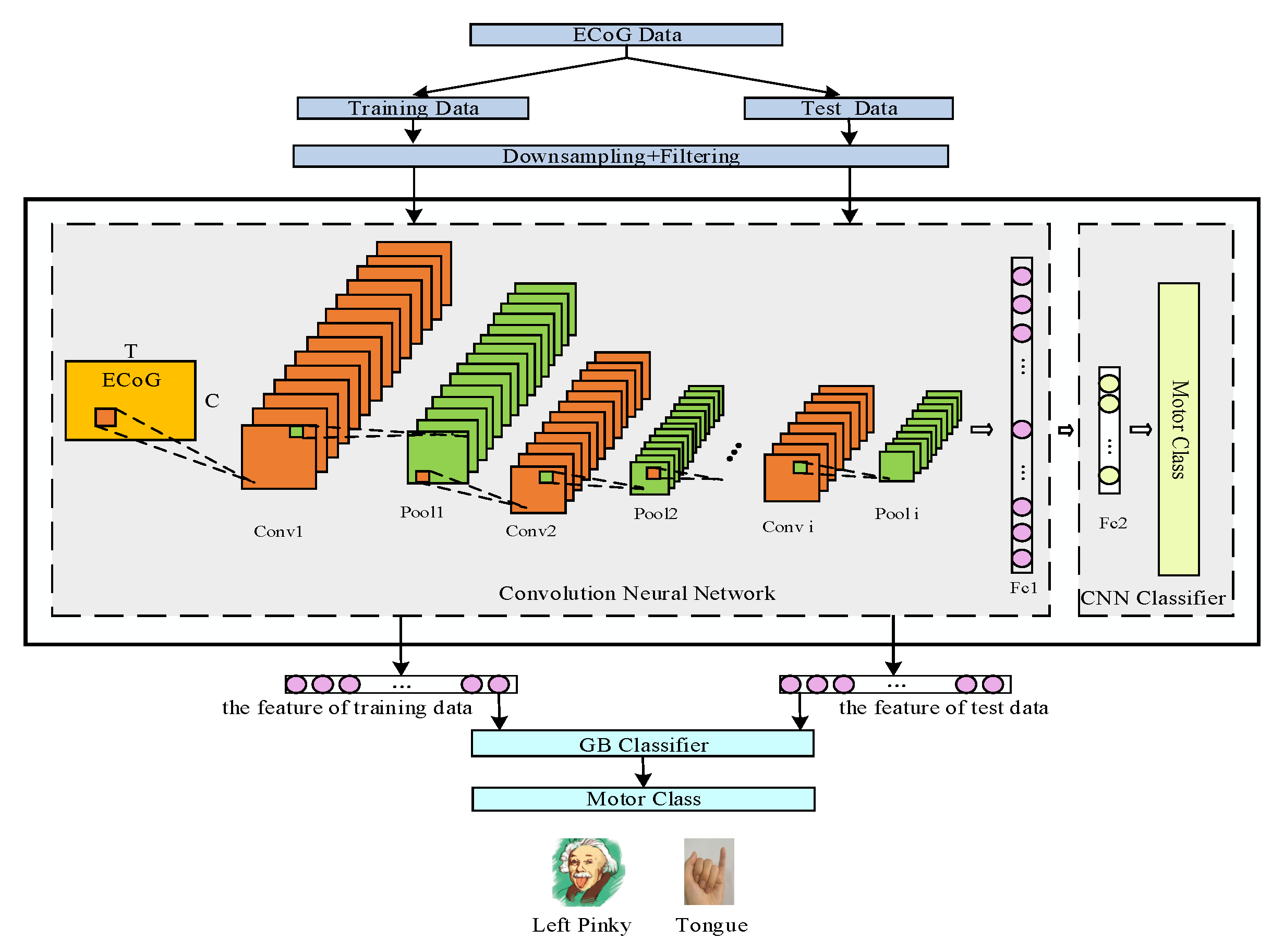
3. Method
3.1. Preprocessing
3.2. Feature Extraction
3.2.1. Convolutional Layer
3.2.2. Pooling Layer
3.2.3. Fully Connected Layer
3.3. Classification
- (1)
- To calculate the gradient of the loss function along the direction of the gradient descent,
- (2)
- OLS selects the best suitable gradient that uses the weak classifier
- (3)
- Now, calculating the weight of the weak classifier,
- (4)
- To improve the generalization performance of the algorithm, the is reduced by multiplying a small per step. A strong classifier is obtained by iteration,
- (5)
- Obtaining the new logarithmic regression value, see the Formula (8)
4. Results and Discussion
4.1. Parameter Settings
4.2. The CNN Features Visualization
4.3. The Comparison of Experimental Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Xu, F.Z.; Zhou, W.D.; Zhen, Y.L.; Yuan, Q.; Wu, Q. Using fractal and local binary pattern features for classification of ECoG motor imagery tasks obtained from the right brain hemisphere. Int. J. Neural. Syst. 2016, 26, 1650022. [Google Scholar] [CrossRef]
- Hamedi, M.; Salleh, S.H.; Noor, A.M. Electroencephalographic motor imagery brain connectivity analysis for BCI: A review. Neural Comput. 2016, 28, 999–1041. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.; Ryu, J.; Kim, K.K.; Took, C.C.; Mandic, D.P.; Park, C. Motor imagery classification using mu and beta rhythms of EEG with strong uncorrelated transform based complex common spatial patterns. Comput. Intel. Neurosci. 2016, 2016, 1489692. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brinkman, L.; Stolk, A.; Dijkerman, H.C.; Lange, F.P.; Toni, I. Distinct roles for alpha-and beta-band oscillations during mental simulation of goal-directed actions. J. Neurosci. 2014, 34, 14783–14792. [Google Scholar]
- Pfurtscheller, G.; Sliva, F.H.L.D. Event-related EEG/MEG synchronization and desynchronization: Basic principles. Clin. Neurophsiol. 1999, 110, 1842–1857. [Google Scholar]
- Pregenzer, M.; Pfurtscheller, G. Frequency component selection for an EEG-based brain to computer Interface. IEEE. Trans. Rehabil. Eng. 1999, 7, 413–419. [Google Scholar]
- Aghaei, A.S.; Mahanta, M.S.; Plataniotis, K.N. Separable common spatio-spectral patterns for motor imagery BCI systems. IEEE. Trans. Bio-Med. Eng. 2016, 63, 15–29. [Google Scholar]
- Ortiz-Rosario, A.; Adeli, H. Brain-computer interface technologies: From signal to action. Rev. Neurosci. 2013, 24, 537–552. [Google Scholar]
- Leuthardt, E.C.; Schalk, G.; Roland, J.; Rouse, A.; Moran, D.W. Evolution of brain-computer interfaces: Going beyond classic motor physiology. Neurosurg. Focus. 2009, 27, 1–21. [Google Scholar] [CrossRef]
- Yuan, H.; He, B. Brain-computer interfaces using sensorimotor rhythms: Current state and future perspectives. IEEE. Trans. Bio-Med. Eng. 2014, 6, 1425–1435. [Google Scholar]
- Meng, J.; Zhang, S.; Bekyo, A.; Olsoe, J.; Baxter, B.; He, B. Noninvasive electroencephalogram based control of a robotic arm for reach and grasp tasks. Sci. Rep. UK 2016, 6, 38565. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Horki, P.; Solis-Escalante, T.; Neuper, C.; Müller-Putz, G. Combined motor imagery and SSVEP based BCI control of a 2 DoF artificial upper lmb. Med. Biol. Eng. Comput. 2011, 49, 567–577. [Google Scholar] [CrossRef] [PubMed]
- Xu, F.Z.; Zhen, Y.; Yuan, Q. Classification of motor imagery tasks for electrocorticogram based brain-computer interface. Biomed. Eng. Lett. 2014, 4, 149–157. [Google Scholar] [CrossRef]
- Wolpaw, J.R.; Birbaumer, N.; McFarland, D.J.; Pfurtscheller, G.; Vaughan, T.M. Brain–computer interfaces for communication and control. Clin. Neurophsiol. 2002, 113, 767–791. [Google Scholar] [CrossRef]
- Schalk, G.; Mcfarland, D.J.; Hinterberger, T.; Birbaumer, N.; Wolpaw, J.R. BCI2000: A general-purpose brain-computer interface (BCI) system. IEEE. Trans. Bio-Med. Eng. 2004, 51, 1034–1043. [Google Scholar] [CrossRef] [PubMed]
- Wang, F.; Zhang, X.; Fu, R.; Sun, G. Study of the home-auxiliary robot based on BCI. Sensors 2018, 18, 1779. [Google Scholar] [CrossRef] [Green Version]
- Albuquerque, V.H.C.d.; Damaševičius, R.; Garcia, N.M.; Pinheiro, P.R.; Pedro Filho, P.R. Brain computer interface systems for neurorobotics: Methods and applications. Biomed. Res. Int. 2017, 2017, 1–3. [Google Scholar] [CrossRef] [Green Version]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 512, 436–444. [Google Scholar] [CrossRef]
- Pfurtscheller, G.; Brunner, C.; Schlögl, A.; Lopes da Silva, F.H. Mu rhythm (de) synchronization and EEG single-trial classification of different motor imagery tasks. Neuroimage 2006, 31, 153–159. [Google Scholar] [CrossRef]
- Zhao, Y.; Han, J.; Chen, Y.; Sun, H.; Chen, J.; Ke, A.; Han, Y.; Zhang, P.; Zhang, Y.; Zhou, Y.; et al. Improving generalization based onl1-norm regularization for EEG-based motor imagery classification. Front. Neurosci-Switz. 2018, 12, 272. [Google Scholar] [CrossRef] [Green Version]
- Lotte, F.; Guan, C. Regularizing common spatial patterns to improve BCI designs: Unified theory and new algorithms. IEEE Trans. Biomed. Eng. 2011, 58, 355–362. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sharma, P.; Khan, Y.U.; Farooq, O.; Tripathi, M.; Adeli, H. A wavelet-statistical features spproach for nonconvulsive seizure detection. Clin. EEG Neurosci. 2014, 45, 274–284. [Google Scholar] [CrossRef] [PubMed]
- Sankari, Z.; Adeli, H.; Adeli, A. Wavelet coherence model for diagnosis of alzheimer Disease. Clin. EEG Neurosci. 2012, 43, 268–278. [Google Scholar] [CrossRef] [PubMed]
- Faust, O.; Acharya, U.R.; Adeli, H.; Adeli, A. Wavelet-based EEG processing for computer-aided seizure detection and epilepsy diagnosis. Seizure 2015, 26, 56–64. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Adeli, H.; Ghoshdastidar, S.; Dadmehr, N. A spatio-temporal wavelet-chaos methodology for EEG-based diagnosis of alzheimer’s disease. Neurosci. Lett. 2008, 444, 190–194. [Google Scholar] [CrossRef]
- Meisheri, H.; Ramrao, N.; Mitra, S. Multiclass common spatial pattern for EEG based brain computer interface with adaptive learning classifier. arXiv 2018, arXiv:1802.09046. [Google Scholar]
- Ahmadlou, M.; Adeli, H.; Adeli, A. Improved Visibility Graph Fractality with Application for the Diagnosis of Autism Spectrum Disorder. Physica A 2012, 391, 4720–4726. [Google Scholar] [CrossRef]
- Chu, Y.; Zhao, X.; Zou, Y.; Xu, W.; Han, J.; Zhao, Y. A decoding scheme for incomplete motor imagery EEG with deep belief network. Front. Neurosci-Switz. 2018, 12, 680. [Google Scholar] [CrossRef]
- Ahmadlou, M.; Adeli, H.; Adeli, A. Fractality analysis of frontal brain in major depressive disorder. Int. J. Psychophysiol. 2012, 85, 206–211. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Donahue, J.; Hendricks, L.A.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. IEEE. Trans. Pattern. Anal. 2017, 39, 677–691. [Google Scholar] [CrossRef] [PubMed]
- Taylor, S.; Kim, T.; Yue, Y.; Mahler, M.; Krahe, J.; Rodriguez, A.G.; Hodgins, J.; Mattews, I. A deep learning approach for generalized speech animation. ACM Trans. Graph. 2017, 36, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Bashivan, P.; Rish, I.; Yeasin, M.; Codella, N. Learning representations from EEG with deep recurrent-convolutional neural networks. arXiv 2015, arXiv:1511.06448. [Google Scholar]
- Li, Y.; Dzirasa, K.; Carin, L.; Carlson, D.E. Targeting EEG/LFP synchrony with neural nets. Adv. Neural Inf. Process. Syst. 2015, 30, 4620–4630. [Google Scholar]
- Frydenlund, A.; Rudzicz, F. Emotional affect estimation using video and EEG data in deep neural networks. Adva. Artif. Intell. (AI 2015) 2015, 9091, 273–280. [Google Scholar]
- Alhagry, S.; Fahmy, A.A.; El-Khoribi, R.A. Emotion recognition based on EEG using LSTM recurrent neural network. Emotion 2010, 8, 355–358. [Google Scholar] [CrossRef] [Green Version]
- Shen, Y.; Lu, H.; Jie, J. Classification of motor imagery EEG signals with deep learning models. In International Conference on Intelligent Science and Big Data Engineering; Springer: Cham, Switzerland, 2017; pp. 181–190. [Google Scholar]
- Lal, T.N.; Hinterberger, T.; Widman, G.; Schroder, M.; Hill, J.; Rosenstiel, W.; Elger, C.E.; Scholklpf, B.; Birbaumer, N. Methods towards invasive human brain computer interfaces. Adv. Neural Inf. Process. Syst. 2005, 17, 737–744. [Google Scholar]
- Foss, S.; Korshunov, D.; Zachary, S. Convolutions of long-tailed and subexponential distributions. J. Appl. Probab. 2009, 46, 756–767. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhouchk, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2015, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the ACM International Conference on Multimedi, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial, Front. Neurorobotics 2013, 7, 21. [Google Scholar]
- Blagus, R.; Lusa, L. Boosting for high-dimensional two-class prediction. BMC Bioinform. 2015, 16, 1–17. [Google Scholar]
- Wang, D.; Miao, D.; Blohm, G. Multi-class motor imagery EEG decoding for brain-computer interfaces. Front. Neurosci-Switz. 2012, 6, 151. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Blankertz, B.; Muller, K.R.; Krusienski, D.J.; Schalk, G.; Wolpaw, J.R.; Schlogl, A.; Pfurtscheller, G.; Millan, J.R.; Schroder, M.; Pfurscheller, G.; et al. The BCI Competition. III: Validating alternative approaches to actual BCI problems. IEEE. Trans. Neural Syst. Rehabil. 2006, 14, 153–159. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Yang, J.; Hao, D.; Jia, S. ECoG recognition of motor imagery based on SVM ensemble. In Proceedings of the IEEE International Conference on Robotics & Biomimetics, Guilin, China, 19–23 December 2009; pp. 1967–1972. [Google Scholar]
- Yan, S.Y.; Guan, D.J. ECoG classification research based on wavelet variance and probabilistic neural network. AMM 2013, 380, 2280–2285. [Google Scholar] [CrossRef]
- Zhao, H.-b.; Yu, C.-y.; Liu, C.; Wang, H. ECoG-based brain-computer interface using relative wavelet energy and probabilistic neural network. In Proceedings of the International Conference on Biomedical Engineering and Informatics, Yantai, China, 16–18 October 2010. [Google Scholar]
- Xu, F.; Zhou, W.; Zhen, Y.; Yuan, Q. Classification of ECoG with modified S-Transform for brain-computer interface. J. Comput. Inform. Syst. 2014, 10, 8029–8804. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy (%) | Convolution Layer | |||||
|---|---|---|---|---|---|---|
| 3 | 4 | 5 | 6 | 7 | ||
| Convolution Kernel | 1 3 | 89% | 90% | 93% | 95% | 93% |
| 1 5 | 89% | 91% | 94% | 95% | 92% | |
| 1 7 | 89% | 91% | 95% | 93% | 93% | |
| 1 9 | 89% | 92% | 94% | 93% | - | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, F.; Rong, F.; Miao, Y.; Sun, Y.; Dong, G.; Li, H.; Li, J.; Wang, Y.; Leng, J. Representation Learning for Motor Imagery Recognition with Deep Neural Network. Electronics 2021, 10, 112. https://doi.org/10.3390/electronics10020112
Xu F, Rong F, Miao Y, Sun Y, Dong G, Li H, Li J, Wang Y, Leng J. Representation Learning for Motor Imagery Recognition with Deep Neural Network. Electronics. 2021; 10(2):112. https://doi.org/10.3390/electronics10020112
Chicago/Turabian StyleXu, Fangzhou, Fenqi Rong, Yunjing Miao, Yanan Sun, Gege Dong, Han Li, Jincheng Li, Yuandong Wang, and Jiancai Leng. 2021. "Representation Learning for Motor Imagery Recognition with Deep Neural Network" Electronics 10, no. 2: 112. https://doi.org/10.3390/electronics10020112
APA StyleXu, F., Rong, F., Miao, Y., Sun, Y., Dong, G., Li, H., Li, J., Wang, Y., & Leng, J. (2021). Representation Learning for Motor Imagery Recognition with Deep Neural Network. Electronics, 10(2), 112. https://doi.org/10.3390/electronics10020112