Skyrmion Logic-In-Memory Architecture for Maximum/Minimum Search





Abstract
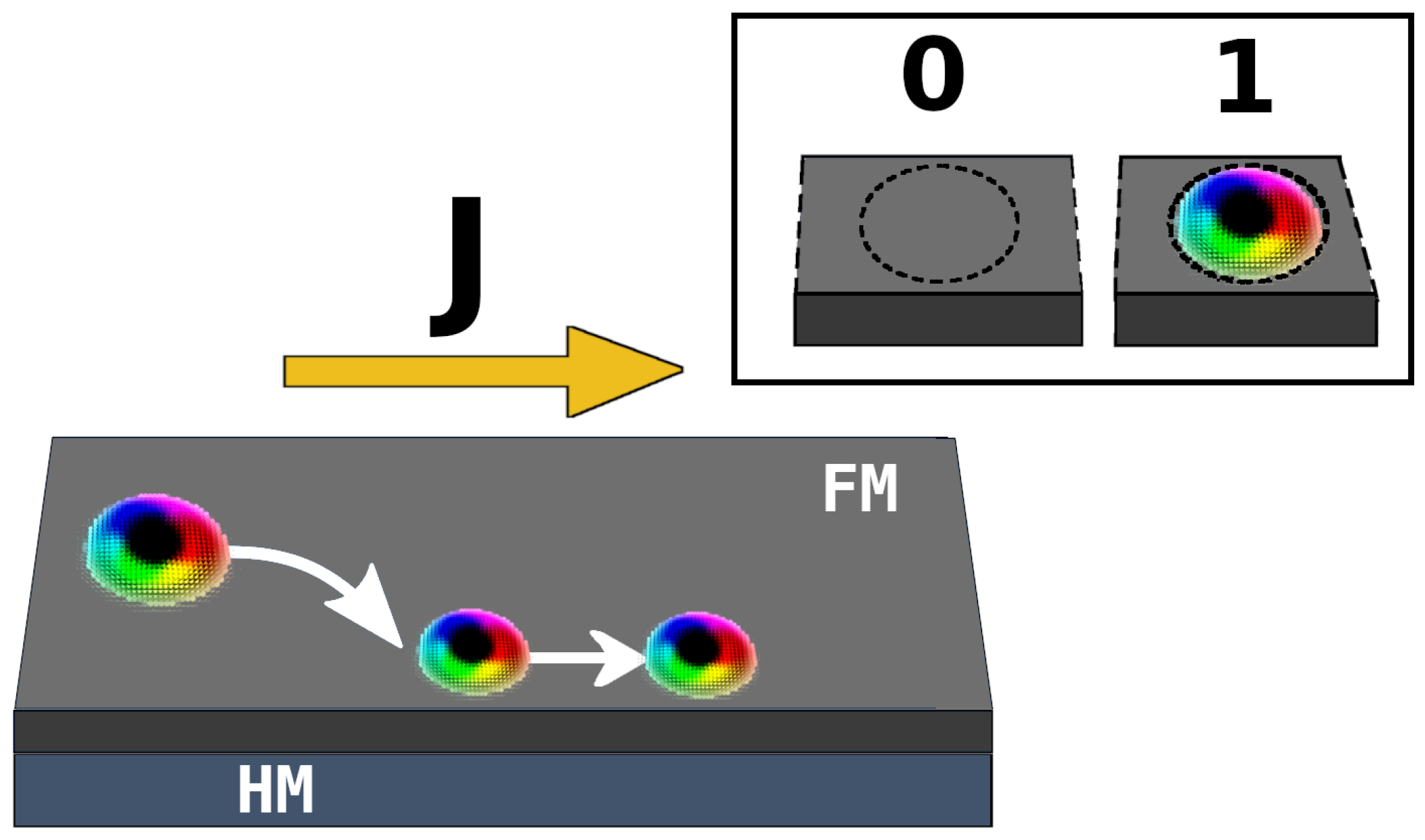
:1. Introduction
- We designed a logic in memory architecture based on skyrmions that can find the minimum or the maximum value stored within the memory;
- We designed a memory cell based on skyrmions, capable of operating not only as memory but also as a computing device. From the storage point of view it can be used as a classical RAM memory, but it integrates logic capabilities implementing AND, OR Boolean functions without the need of and electric conversion for the processing phase;
- The entire entire memory cell was studied through micromagnetic simulations. The cell includes a processing zone, where the elaboration is non-destructive making possible to maintain the information even after computation;
- We evaluated the entire system performance, with an increasing number of words in the array starting from 2048 up to 65,536. The evaluation takes into account not only the skyrmions-based memory array, but also the contribution coming from the peripheral CMOS circuitry to control the array;
- We compared the array performance with an existing CMOS implementation in term of dissipated power and the energy per bit.
2. Background
3. Memory Cell
3.1. Cell Operation
- To start the circuit operation, the current in the racetrack is reversed and the skyrmion can enter inside the processing zone (Figure 4a);
- The skyrmion is guided inside the duplication element. The magnetic bubble, here, converted in a domain wall pair is duplicated. The two domain wall pairs are pushed to the edge of the constriction and then converted back into two skyrmions by means of a second current pulse (Figure 4b). Both the skyrmions are then pushed to reach the correspondent notches for synchronization. During this step another skyrmion is nucleated by the write head inside the processing zone to perform the masking operation;
- The skyrmion in the top track is pushed over the notch to reach the AND gate to execute the masking with the input from the mask operation. The skyrmion in the bottom track enters in the return path to reach the memory cell (Figure 4c);
- The result of the masking operation is guided through the racetrack to reach the reading head in order to be collected. The skyrmion on the bottom is put back inside the memory track (Figure 4d).
4. Memory Array
5. Logic in Memory
5.1. Maximum/Minimum Search Algorithm
| Algorithm 1: Maximum algorithm. |
 |
5.2. Control Logic
5.3. Maximum/Minimum Search Operation
5.4. Bitwise Operations between Rows and Columns
6. Methods
7. Results
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Saulsbury, A.; Pong, F.; Nowatzyk, A. Missing the Memory Wall: The Case for Processor/Memory Integration. SIGARCH Comput. Archit. News 1996, 24, 90–101. [Google Scholar] [CrossRef]
- Santoro, G.; Turvani, G.; Graziano, M. New logic-in-memory paradigms: An architectural and technological perspective. Micromachines 2019, 10, 368. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Parkin, S.S.P.; Hayashi, M.; Thomas, L. Magnetic Domain-Wall Racetrack Memory. Science 2008, 320, 190–194. [Google Scholar] [CrossRef]
- Zhang, X.; Ezawa, M.; Zhou, Y. Magnetic skyrmion logic gates: Conversion, duplication and merging of skyrmions. Sci. Rep. 2015, 5, 1–8. [Google Scholar]
- Chauwin, M.; Hu, X.; Garcia-Sanchez, F.; Betrabet, N.; Paler, A.; Moutafis, C.; Friedman, J.S. Skyrmion Logic System for Large-Scale Reversible Computation. Phys. Rev. Appl. 2019, 12, 064053. [Google Scholar] [CrossRef] [Green Version]
- Sampaio, J.; Cros, V.; Rohart, S.; Thiaville, A.; Fert, A. Nucleation, stability and current-induced motion of isolated magnetic skyrmions in nanostructures. Nat. Nanotechnol. 2013, 8, 839–844. [Google Scholar] [CrossRef] [PubMed]
- Kang, W.; Zheng, C.; Huang, Y.; Zhang, X.; Zhou, Y.; Lv, W.; Zhao, W. Complementary Skyrmion Racetrack Memory With Voltage Manipulation. IEEE Electron Device Lett. 2016, 37, 924–927. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.; Kang, W.; Zhang, X.; Zhou, Y.; Zhao, W. Magnetic skyrmion-based synaptic devices. Nanotechnology 2017, 28, 08LT02. [Google Scholar] [CrossRef]
- Song, K.M.; Jeong, J.S.; Pan, B.; Zhang, X.; Xia, J.; Cha, S.; Park, T.E.; Kim, K.; Finizio, S.; Raabe, J.; et al. Skyrmion-based artificial synapses for neuromorphic computing. Nat. Electron. 2020, 3, 148–155. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Gu, S.; Chen, M.; Kang, W.; Hu, J.; Zhuge, Q.; Sha, E.H.M. An efficient racetrack memory-based Processing-in-memory architecture for convolutional neural networks. In Proceedings of the 2017 IEEE International Symposium on Parallel and Distributed Processing with Applications and 2017 IEEE International Conference on Ubiquitous Computing and Communications (ISPA/IUCC), Guangzhou, China, 12–15 December 2017; pp. 383–390. [Google Scholar]
- Pan, Y.; Ouyang, P.; Zhao, Y.; Yin, S.; Zhang, Y.; Wei, S.; Zhao, W. A Skyrmion Racetrack Memory Based Computing In-Memory Architecture for Binary Neural Convolutional Network. In Proceedings of the 2019 on Great Lakes Symposium on VLSI, GLSVLSI’19, Washington, DC, USA, 9–11 May 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 271–274. [Google Scholar] [CrossRef]
- Chen, M.; Ranjan, A.; Raghunathan, A.; Roy, K. Cache Memory Design with Magnetic Skyrmions in a Long Nanotrack. IEEE Trans. Magn. 2019, 55, 1–9. [Google Scholar] [CrossRef]
- Huang, S.X.; Chien, C.L. Extended Skyrmion Phase in Epitaxial FeGe(111) Thin Films. Phys. Rev. Lett. 2012, 108, 267201. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiang, W.; Zhang, X.; Yu, G.; Zhang, W.; Wang, X.; Jungfleisch, M.B.; Pearson, J.E.; Cheng, X.; Heinonen, O.; Wang, K.L.; et al. Direct observation of the skyrmion Hall effect. Nat. Phys. 2017, 13, 162–169. [Google Scholar] [CrossRef]
- Woo, S.; Litzius, K.; Krüger, B.; Im, M.Y.; Caretta, L.; Richter, K.; Mann, M.; Krone, A.; Reeve, R.M.; Weigand, M.; et al. Observation of room-temperature magnetic skyrmions and their current-driven dynamics in ultrathin metallic ferromagnets. Nat. Mater. 2016, 15, 501–506. [Google Scholar] [CrossRef] [PubMed]
- Tomasello, R.; Martinez, E.; Zivieri, R.; Torres, L.; Carpentieri, M.; Finocchio, G. A strategy for the design of skyrmion racetrack memories. Sci. Rep. 2014, 4, 6784. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fert, A.; Cros, V.; Sampaio, J. Skyrmions on the track. Nat. Nanotechnol. 2013, 8, 152–156. [Google Scholar] [CrossRef] [PubMed]
- Tomasello, R.; Puliafito, V.; Martinez, E.; Manchon, A.; Ricci, M.; Carpentieri, M.; Finocchio, G. Performance of synthetic antiferromagnetic racetrack memory: Domain wall versus skyrmion. J. Phys. D Appl. Phys. 2017, 50, 325302. [Google Scholar] [CrossRef] [Green Version]
- Fook, H.T.; Gan, W.L.; Lew, W.S. Gateable skyrmion transport via field-induced potential barrier modulation. Sci. Rep. 2016, 6, 21099. [Google Scholar] [CrossRef] [Green Version]
- Fook, H.T.; Gan, W.L.; Purnama, I.; Lew, W.S. Mitigation of magnus force in current-induced skyrmion dynamics. IEEE Trans. Magn. 2015, 51, 1–4. [Google Scholar] [CrossRef]
- Amiri, P.K.; Wang, K.L. Voltage-controlled magnetic anisotropy in spintronic devices. In Spin; World Scientific: Singapore, 2012; Volume 2, p. 1240002. [Google Scholar]
- Li, X.; Fitzell, K.; Wu, D.; Karaba, C.T.; Buditama, A.; Yu, G.; Wong, K.L.; Altieri, N.; Grezes, C.; Kioussis, N.; et al. Enhancement of voltage-controlled magnetic anisotropy through precise control of Mg insertion thickness at CoFeB| MgO interface. Appl. Phys. Lett. 2017, 110, 052401. [Google Scholar] [CrossRef]
- Martinez, J.; Lew, W.; Gan, W.; Jalil, M. Theory of current-induced skyrmion dynamics close to a boundary. J. Magn. Magn. Mater. 2018, 465, 685–691. [Google Scholar] [CrossRef]
- Zhang, C.; Fukami, S.; Watanabe, K.; Ohkawara, A.; DuttaGupta, S.; Sato, H.; Matsukura, F.; Ohno, H. Critical role of W deposition condition on spin-orbit torque induced magnetization switching in nanoscale W/CoFeB/MgO. Appl. Phys. Lett. 2016, 109, 192405. [Google Scholar] [CrossRef]
- Penthorn, N.E.; Hao, X.; Wang, Z.; Huai, Y.; Jiang, H.W. Experimental Observation of Single Skyrmion Signatures in a Magnetic Tunnel Junction. Phys. Rev. Lett. 2019, 122, 257201. [Google Scholar] [CrossRef] [PubMed]
- Vai, M.; Moy, M. Real-time maximum value determination on an easily testable VLSI architecture. IEEE Trans. Circuits Syst. I Fundam. Theory Appl. 1993, 40, 283–285. [Google Scholar] [CrossRef]
- Vacca, M.; Tavva, Y.; Chattopadhyay, A.; Calimera, A. Logic-In-Memory Architecture For Min/Max Search. In Proceedings of the 2018 25th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Bordeaux, France, 9–12 December 2018; pp. 853–856. [Google Scholar]
- Vansteenkiste, A.; Leliaert, J.; Dvornik, M.; Helsen, M.; Garcia-Sanchez, F.; Van Waeyenberge, B. The design and verification of Mumax3. AIP Adv. 2014, 4, 107133. [Google Scholar] [CrossRef] [Green Version]
- Mulkers, J.; Van Waeyenberge, B.; Milošević, M.V. Effects of spatially-engineered Dzyaloshinskii-Moriya interaction in ferromagnetic films. Phys. Rev. B 2017, 95, 144401. [Google Scholar] [CrossRef] [Green Version]
- ElmerFEM. Open Source Multiphysical Simulation Software. Available online: http://www.elmerfem.org/ (accessed on 15 September 2020).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Simulation Parameters | ||
|---|---|---|
| Saturation Magnetization [16] | −1 | |
| Uniaxial Anisotropy Constant [16] | −2 | |
| Exchange Stiffness [16] | ||
| Damping constant [16] | 0.015 | |
| Spin Hall Angle [24] | 0.4 | |
| Film resistivity [24] | 165 | |
| Words | Area (μm) | Frequency (MHz) | Latency (ns) | |||||
|---|---|---|---|---|---|---|---|---|
| Proposed | [27] | Ratio | Proposed | [27] | Proposed | [27] | Ratio | |
| 2048 | 42,307 | 89,665 | 0.47 | 285 * | 1785 | 1120 | 108 | 10.30 |
| 4096 | 95,036 | 181,694 | 0.52 | 285 * | 1041 | 1120 | 183 | 6.20 |
| 8192 | 190,056 | 368,489 | 0.51 | 285 * | 571 | 1120 | 373 | 3.00 |
| 16,384 | 381,625 | 747,729 | 0.51 | 285 * | 298 | 1120 | 647 | 1.74 |
| 32,768 | 748,076 | 1,516,103 | 0.49 | 285 * | 149 | 1120 | 1293 | 0.86 |
| 65,536 | 1,427,936 | 3,045,940 | 0.46 | 285 * | 75 | 1120 | 2560 | 0.44 |
| Phase | Power (uW) |
|---|---|
| Move Skyrmion | 0.07 |
| Duplication | 21.67 |
| AND | 6.44 |
| Collection | 0.14 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gnoli, L.; Riente, F.; Vacca, M.; Ruo Roch, M.; Graziano, M. Skyrmion Logic-In-Memory Architecture for Maximum/Minimum Search. Electronics 2021, 10, 155. https://doi.org/10.3390/electronics10020155
Gnoli L, Riente F, Vacca M, Ruo Roch M, Graziano M. Skyrmion Logic-In-Memory Architecture for Maximum/Minimum Search. Electronics. 2021; 10(2):155. https://doi.org/10.3390/electronics10020155
Chicago/Turabian StyleGnoli, Luca, Fabrizio Riente, Marco Vacca, Massimo Ruo Roch, and Mariagrazia Graziano. 2021. "Skyrmion Logic-In-Memory Architecture for Maximum/Minimum Search" Electronics 10, no. 2: 155. https://doi.org/10.3390/electronics10020155
APA StyleGnoli, L., Riente, F., Vacca, M., Ruo Roch, M., & Graziano, M. (2021). Skyrmion Logic-In-Memory Architecture for Maximum/Minimum Search. Electronics, 10(2), 155. https://doi.org/10.3390/electronics10020155