1. Introduction
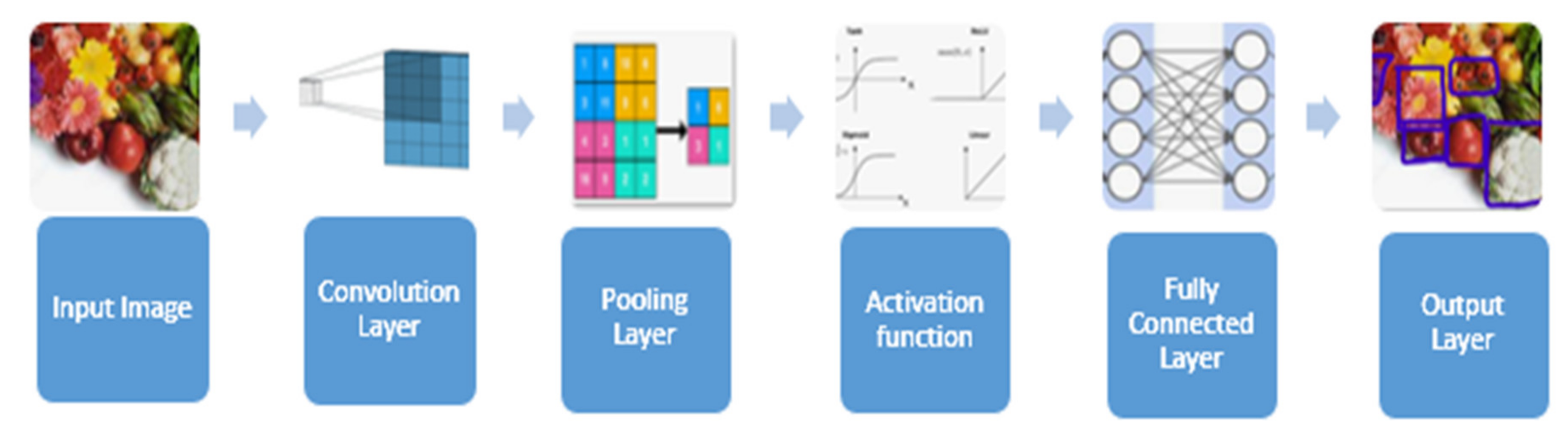
Artificial intelligence is bridging the gap between machine and human talents at a breakneck pace. Many academics and enthusiasts are working on various AI field elements to develop incredible things. One such incredible field includes the domain of computer vision. The primary goal of computer vision is to make machines see the world the same way as humans. Well-known computer vision tasks include image detection, image tagging, image recognition, image classification, image analysis, video analysis, natural language processing, and so on. Deep learning advancements in computer vision have piqued the interest of numerous academics over the years. CNN is used to construct the majority of computer vision algorithms. A convolutional neural network is a method of deep learning that takes an input image and assigns importance (learnable biases and weights) to various objects in the image, distinguishing one from the other [
1].
In comparison to other methods, CNN requires less preprocessing. Therefore, a CNN is the most effective learning algorithm for comprehending picture material [
1]. Furthermore, it has demonstrated exceptional image classification, recognition, segmentation, and retrieval [
2]. The accomplishment of CNN has piqued the interest of people outside of academia. Microsoft, Google, AT&T, NEC, and Facebook are among the companies engaging in the development and advancement of CNN architecture [
3]. In addition, they have active research groups that are investigating novel CNN designs. At the moment, deep CNN-based models are being used by the majority of front-runners in image processing and computer vision competitions. As a result, there are several variants of the basic CNN design. This manuscript covers an introduction to CNN, the evolution of CNN over time, various features of CNN design, and the architectural analysis of each type of CNN with its benefits and drawbacks.
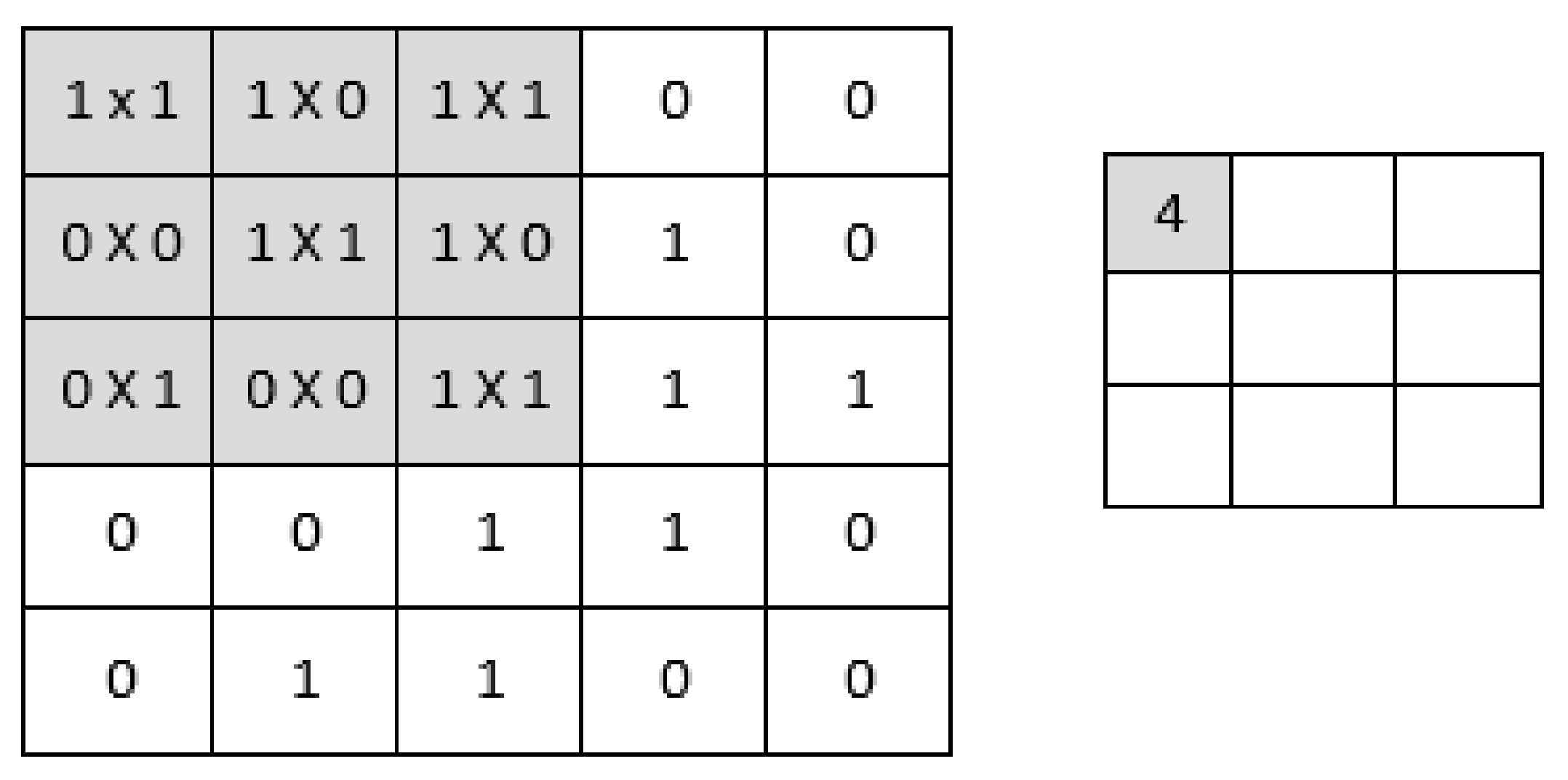
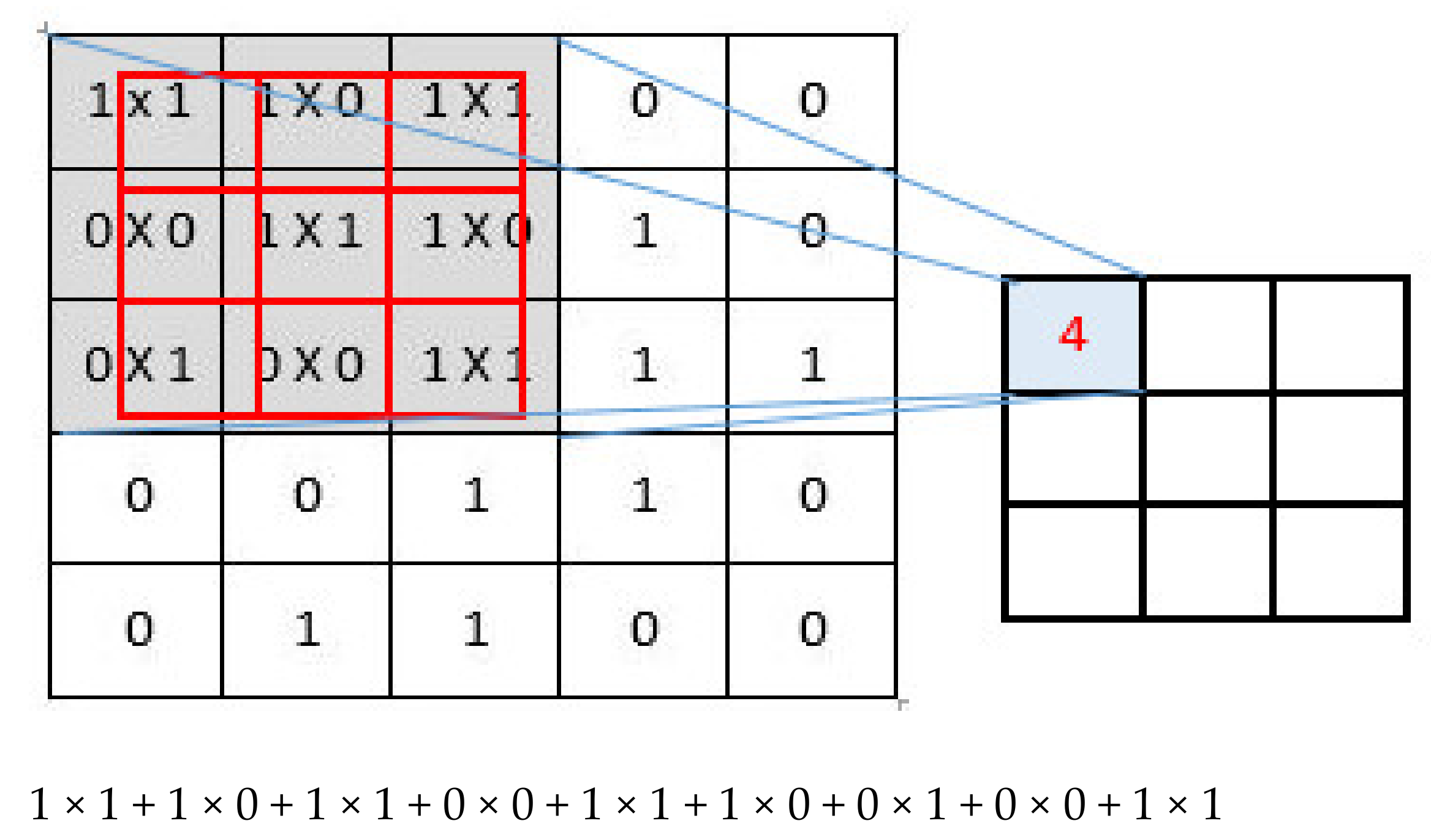
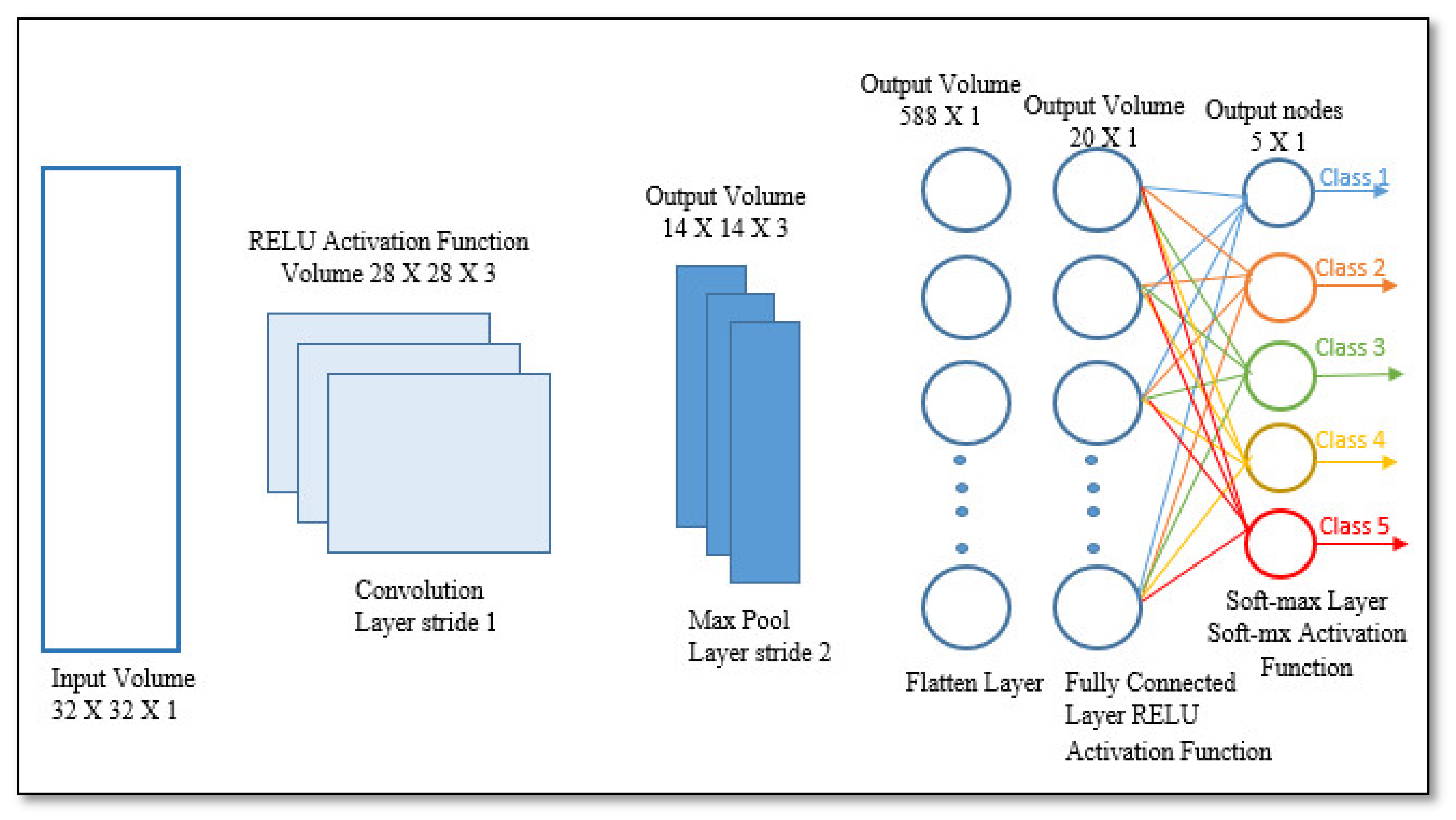
CNN reassembles regular neural networks, but it has an appealing characteristic made up of neurons with learnable weights and biases. Every neuron receives many inputs and then performs a dot product, which is optionally followed by nonlinearity [
4]. As a result, CNN functions as a feed-forward kernel, undergoing many modifications [
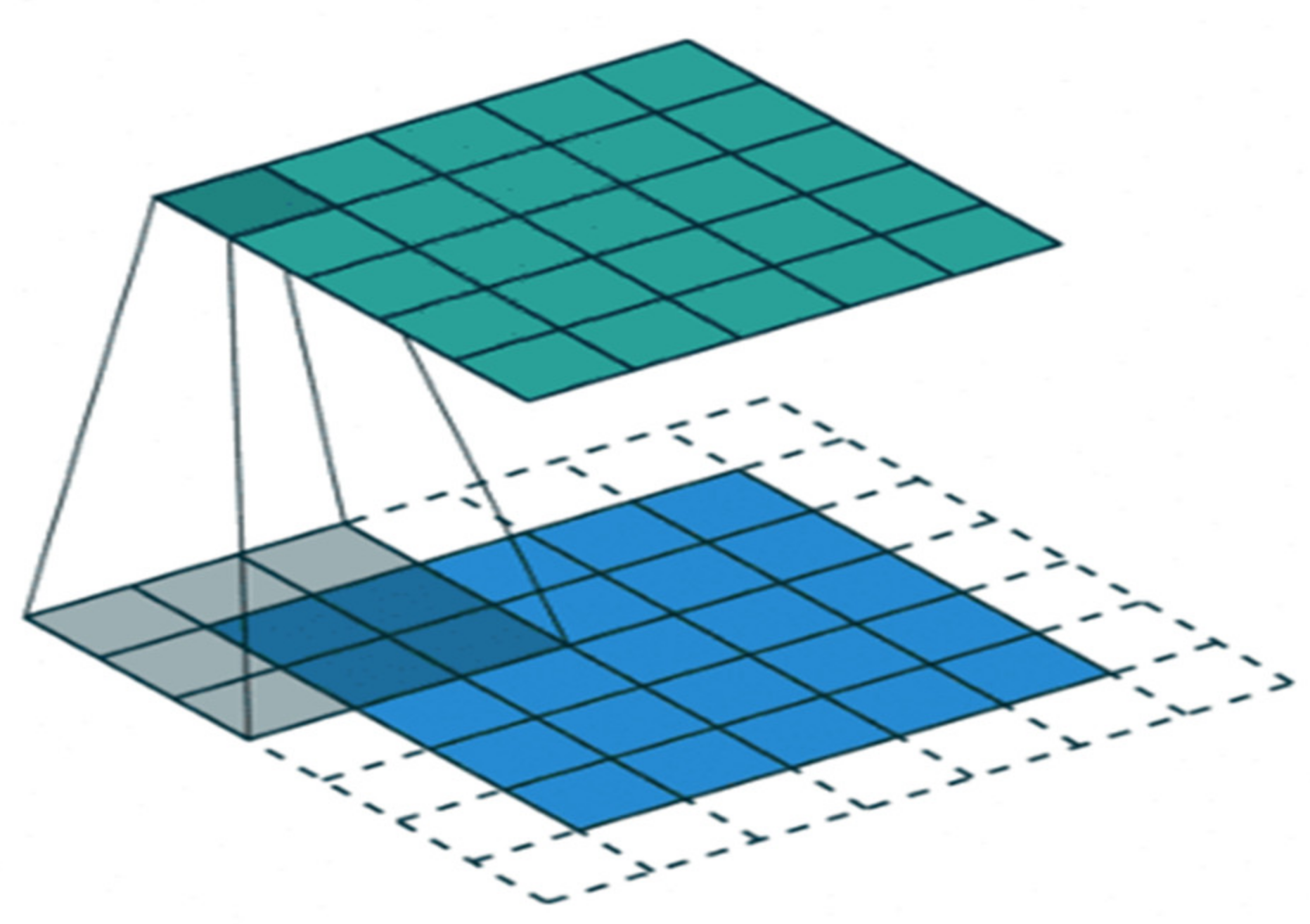
4]. The primary goal of convolution is to extract meaningful features from locally associated data sources. The convolutional kernels’ output is then fed into the activation function, which aids in learning intellections and embeds nonlinearity in the feature space. This nonlinearity produces different activation functions for each reaction, making it easier to learn meaningful dissimilarities in images. Furthermore, a nonlinear activation function produces an output that is frequently trailed by subsampling; this supports summarizing the outputs, which makes the input insensitive to geometrical deceptions.
Najafabadi, in 2015, investigated that CNN has an automatic feature extraction capability that eliminates the requirement for a distinct feature extractor [
5]. As a result, CNN can learn from a good representation of internal raw pixels without exhausting processing. Automatic feature extraction, multitasking, weight sharing, and hierarchical learning are some of CNN’s appealing features [
6].
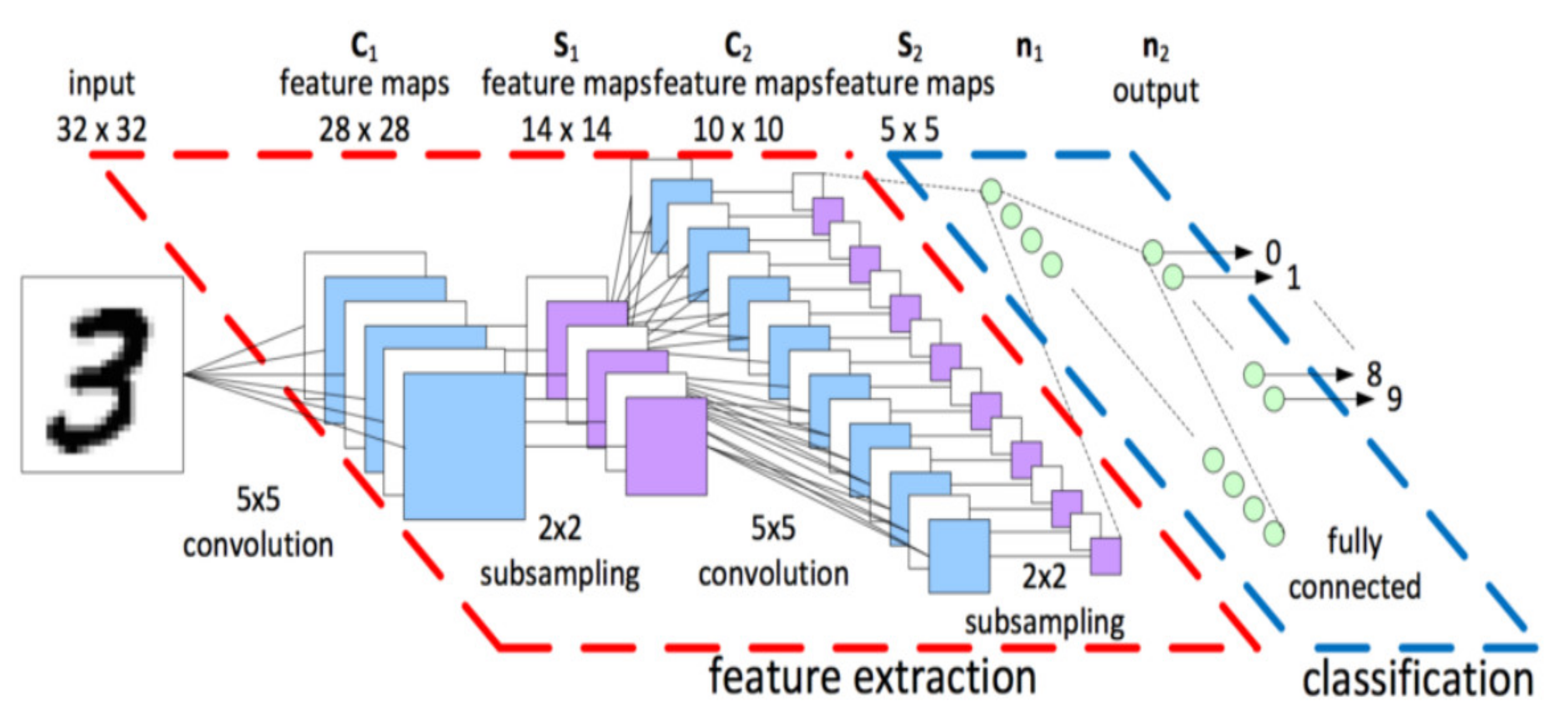
CNN was formerly known as LeNet. LeNet was named after its creator, Yann LeCun. Yann LeCun created a network for handwritten digit identification in 1989, building on the work of Kunihiko Fukushima, a Japanese scientist who designed the neocognitron (essential image recognition neural network). The LeNet-5, which describes the primitive components of CNN, might be regarded as the beginning of CNN. LeNet-5 was not well-known because of hardware equipment paucity, particularly GPUs (graphics processing units). As a result, there was little research on CNN between 1990 and 2000. The success of AlexNet in 2012 opened the door for computer vision applications, and many various forms of CNNs, such as the R-CNN series, have been raised. CNN models now are quite different from LeNet, although they are all based on it.
In recent years, several exciting survey papers have been published on deep CNN. For example, (Asifullah Khan et al., 2018) examined prominent structures from 2012 to 2018 and their major components. (Alzubaidi et al., 2021) reviewed deep learning concepts, CNN architecture, challenges, and future trends. This paper was the first paper to include various DL aspects. It also includes the impact of CPU, GPU, and FPGA on various deep learning approaches. It includes one section about the introduction to CNN and its architecture. (Smarandache et al., 2019) reviewed trends in convolutional neural network architecture. This paper primarily focuses on the design of the architecture of around 10 well-known CNN models.
Similarly, there are many authors, such as Liu (2017), LeCun (2010), Guo (2016), and Srinivas (2016), who have discussed CNN’s many applications and tactics [
4,
6,
7,
8]. As a result, this survey exemplifies the essential taxonomy discovered in the most recent and well-known CNN designs reported between 2012 and 2021. This manuscript includes around eight major categories of CNN based on its architecture evolution. This investigation reveals the fundamental structure of CNN, as well as its roots. It also represents a wide range of CNN architectures, from their conception to their most current advancements and achievements. This survey will assist readers in developing architectural novelties in convolutional neural networks by providing a more profound theoretical knowledge of CNN design concepts.
The primary goal of this survey is to highlight the most significant components of CNN to provide readers with a comprehensive picture of CNN from a single survey paper. In addition, this survey will assist readers in learning more about CNN and CNN variants, which helps to improve the field. The contributions of this survey paper are summarized below:
This is the first review that almost provides each detail about CNN for computer vision, its history, CNN architecture designs, its merits and demerits, application, and the future work to take upon in a single paper.
This review assists readers in making sound decisions about their research work in the area of CNN for computer vision;
This manuscript includes existing CNN architectures and their architectural limitations, leading it to design new architecture. Furthermore, it clearly explains the merits and demerits of almost all popular CNN variants;
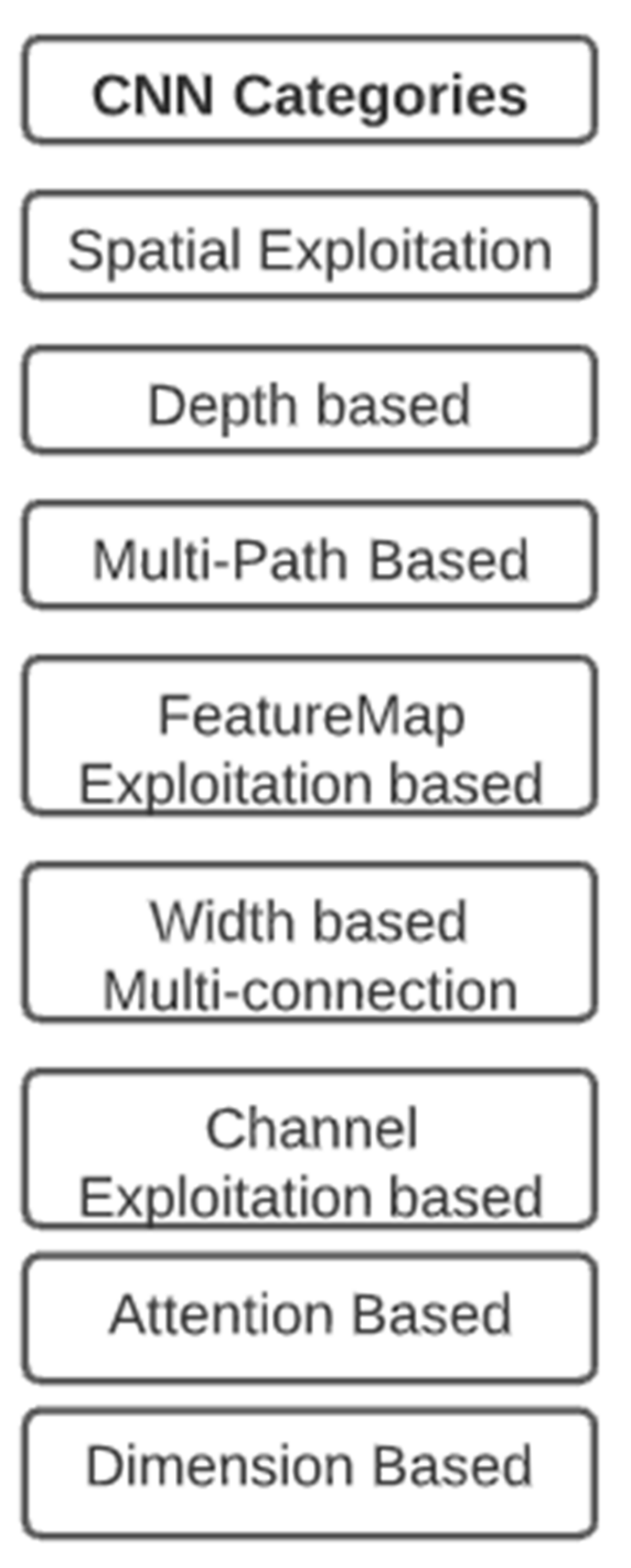
It divides the CNN architecture into eight categories based on their implementation criteria, which is an exciting part of this survey paper;
Various applications of CNN are also explained so that readers can also take on any other application area of CNN other than computer vision;
It provides a clear listing of future research trends in the area of CNN for computer vision.
The organization of this survey paper includes the first section, which presents a methodical comprehension of CNN. Then, it explains CNN’s similarities to the primate’s visual brain.
Section 2, the Literature Review, is divided into two subsections. The outline of the CNN components is explained in
Section 2.1, and
Section 2.2 describes various profound CNN architectural evolutions. It also includes CNN’s eight broad categories of architectural advancements.
Section 3 explores CNN applications in a variety of disciplines,
Section 4 discusses current issues in CNN architecture, and
Section 5 discusses the future scope of research. Finally,
Section 6 concludes a survey of various CNN variants.
4. CNN Challenges
Deep CNNs have shown to be effective for data that are either time-series or have a grid-like structure. Deep CNN architectures have also been used to solve several additional problems.
Different researchers have enthralling arguments about the performance of CNN on various ML tasks. The following are some of the difficulties encountered while training deep CNN models:
As deep CNNs are typically a black box, they may be challenging to comprehend and explain. As a result, verifying them can be challenging at times;
According to Szegedy et al. (2013), training a CNN on noisy picture data can increase the misclassification error (Szegedy et al., 2014). Adding a small amount of random noise to the input image can deceive the network, causing the original and slightly agitated variant to be classified incorrectly;
Each CNN layer is organized in such a manner that it extracts problem-specific information associated with the task automatically. In some of the cases, before classification, some jobs require knowledge of the behavior of features retrieved by deep CNN. Thus, the feature visualization concept in CNN may be helpful. Similarly, Hinton stated that lower levels should only pass on their knowledge to the relevant neurons of the following layer. Hinton presented an intriguing capsule network technique in this area [
66];
Deep CNNs use supervised learning processes, which require huge amount of annotated data to train the network. Humans, on the other hand, can learn from a few examples;
The choice of hyper-parameters has a significant impact on the CNN performance. A slight change can influence the overall performance of a CNN in hyper-parameter values. As a result, selecting hyper-parameters with care is a critical design issue that must be addressed using an appropriate optimization technique;
Effective CNN training necessitates the use of robust hardware resources, such as GPUs. However, the effective use of CNNs in embedded and intelligent devices is still required [
53,
67];
One of CNN’s limitations in vision-related jobs is that it rarely performs well when used to estimate an object’s pose, orientation, or location. In 2012, AlexNet attempted to address this difficulty by developing data augmentation, which solved the problem to some extent. In addition, data augmentation aids CNN in learning a variety of internal representations, potentially improving its performance.
Spatial exploitation: Since convolutional operations take into account the neighborhood (correlation) of input pixels, different levels of the correlation can be examined by utilizing different filter sizes.
Table 2 describes major challenges in spatial exploitation based CNN architecture.
Depth-Based: The network can better approximate the target function using a number of nonlinear mappings and enhanced feature representations as its depth increases. The main hurdle that deep architectures face is the issue of vanishing gradients and negative learning.
Table 3 describes major challenges in depth based CNN architecture.
Multi-Path: Shortcut paths provide the option to skip some layers. Different types of shortcut connections used in literature are zero padded, projection, dropout, 1 × 1 connections, etc.
Table 4 describes major challenges in multi path based CNN architecture.
Width-Based: Previously, it was considered that increasing the number of layers would improve the accuracy. However, when the number of layers increases, the vanishing gradient problem develops, and training may become slow. As a result, the concept of layer widening was also examined.
Table 5 describes major challenges in width based CNN architecture.
Feature-Map Selection: As the deep learning topology is extended, an increasing amount of features maps are generated at each step. Many of the feature-maps might be important for the classification task, whereas others might be redundant or less important. Hence, feature-map selection is another important dimension in deep learning architectures.
Table 6 describes major challenges in feature map based CNN architecture.
Channel Boosting: CNN learning is also dependent on the input representation. The CNN performance may be hampered by a lack of diversity and class discernible information in the input. To that end, the notion of channel boosting (input channel dimension) utilizing auxiliary learners is introduced in CNN to improve the network’s representation [
1].
Table 7 describes major challenges in channel-boosting based CNN architecture.
Attention-Based: There are many advantages of attention networks in determining which patch is the focus or most essential in a picture.
Table 8 describes major challenges in attention based CNN architecture.
Dimension-Based: Dimension-wise convolutions use light-weight convolutional filtering across each dimension of the input tensor, whereas dimension-wise fusion merges these dimension-wise representations efficiently.
Table 9 describes major challenges in dimension based CNN architecture.
6. Conclusions
In the recent decade, convolutional neural networks have received much attention. They have a large impact on image processing and vision-related tasks, which has piqued academics’ curiosity. Many academics have carried out outstanding work in this area, modifying the CNN design to improve its performance. Changes in activation functions, developing or modifying loss functions, optimization, architectural innovations, application-specific modifications in architecture, developing various learning algorithms, and regularization are some of the categories in which researchers have made advancements in CNN. This manuscript summarizes recent developments in CNN architectures. The eight fundamental architectural advances in CNN are spatial exploitation, depth, multi-path, breadth, dimension, feature-map exploitation, channel boosting, and attention. It can be concluded by surveying various architectural modifications in CNN that CNN’s block-based architecture supports modular learning, making the architecture more basic and accessible. Another dimension-based category has a positive impact on CNN’s total performance. Dimension-based CNN can also be used to recognize three-dimensional objects. Training CNN for an exemplary performance in 3D object recognition is a promising and complicated research field. Researchers in this area can still work on 3D object recognition and NAS-based techniques. Modular or block-based architecture has shown excellent optimization in both time and accuracy.



 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
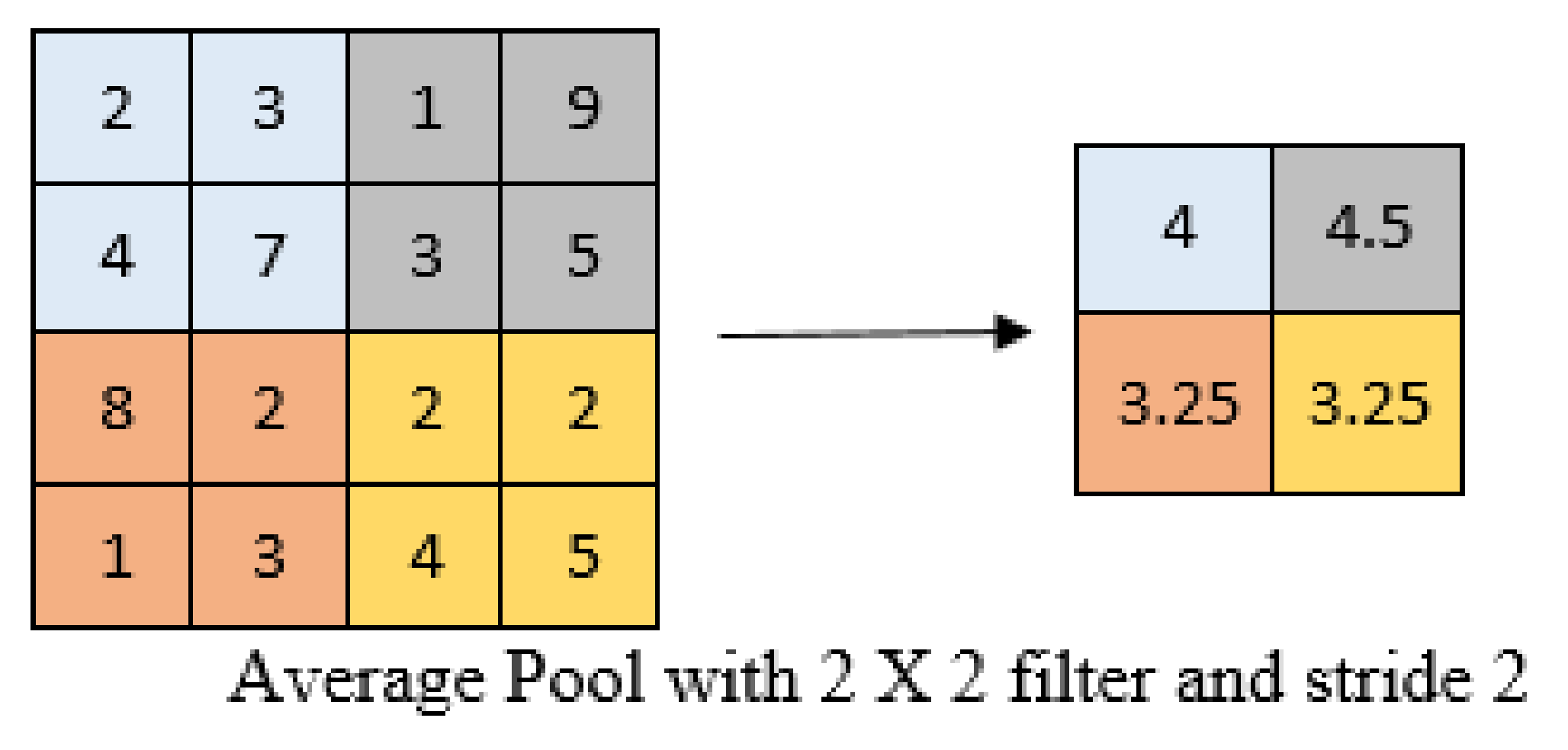{kind=link}
{kind=link}
{kind=link}
{kind=link}