
CCSDS 131.2-B-1 Transmitter Design on FPGA with Adaptive Coding and Modulation Schemes for Satellite Communications


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- A flexible FPGA design and implementation for an adaptive transmitter for high-speed satellite telemetry following standard CCSDS 131.2-B.1;
- The optimization of the system design;
- Validation of the design with a reference model.
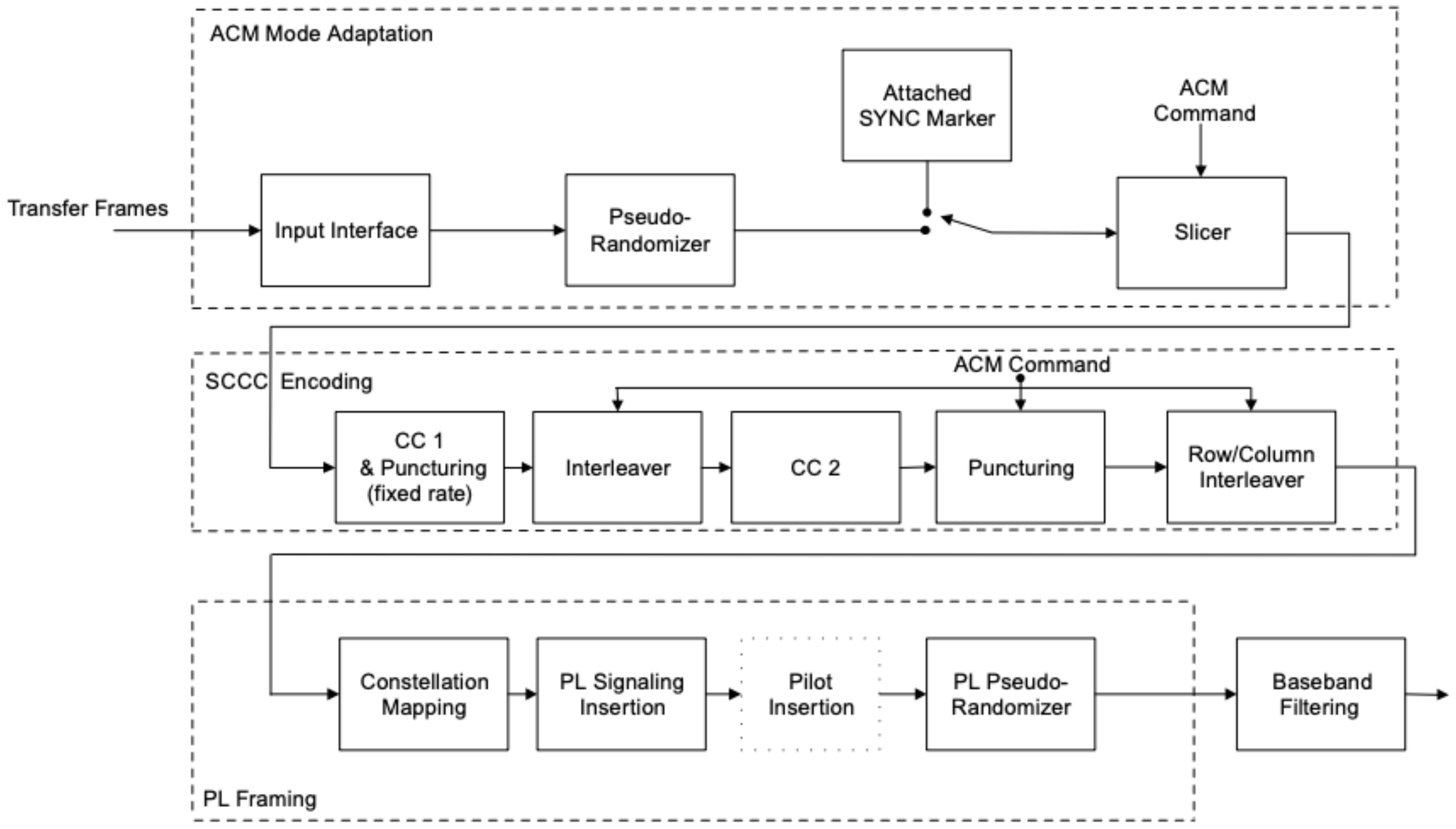
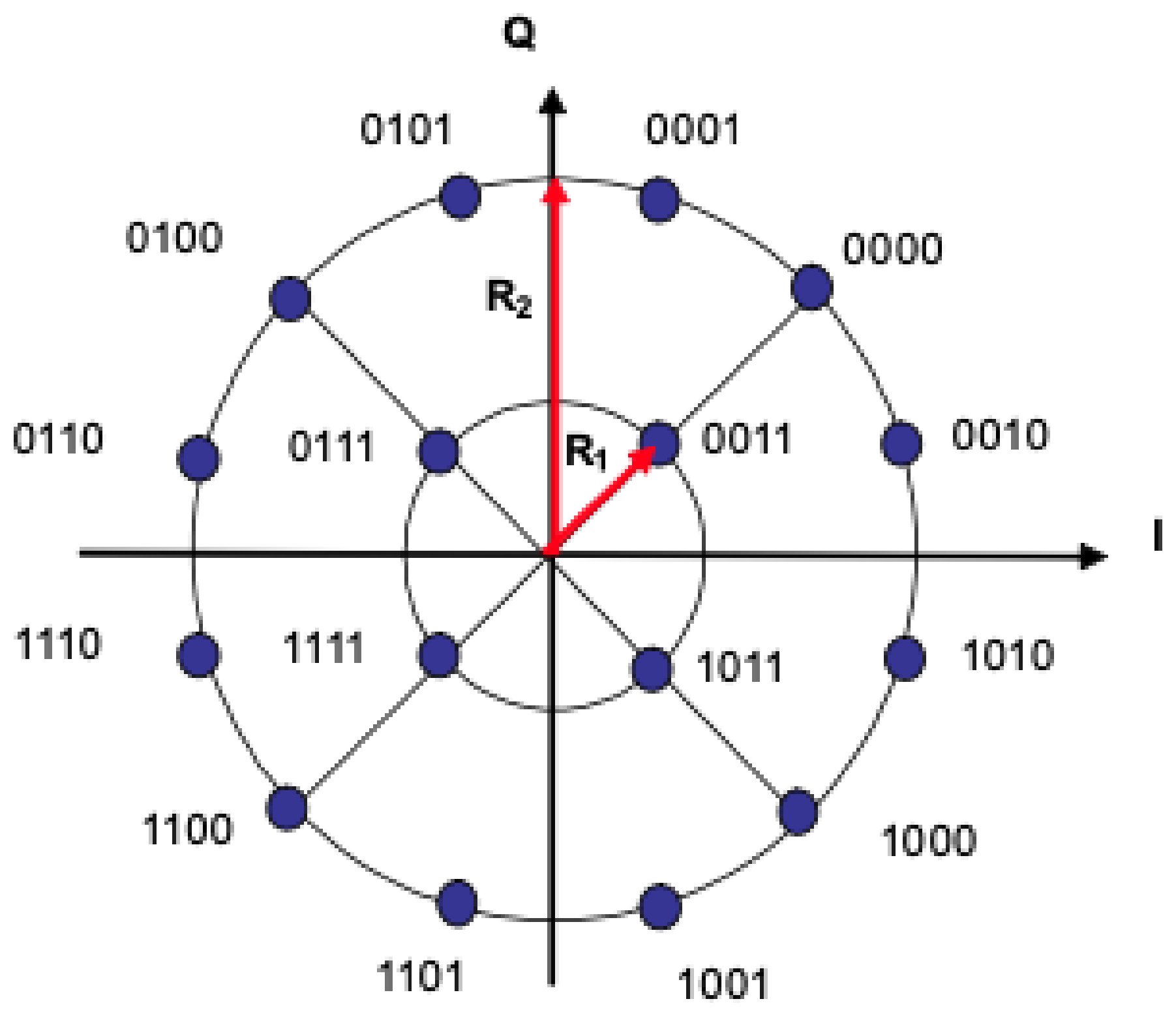
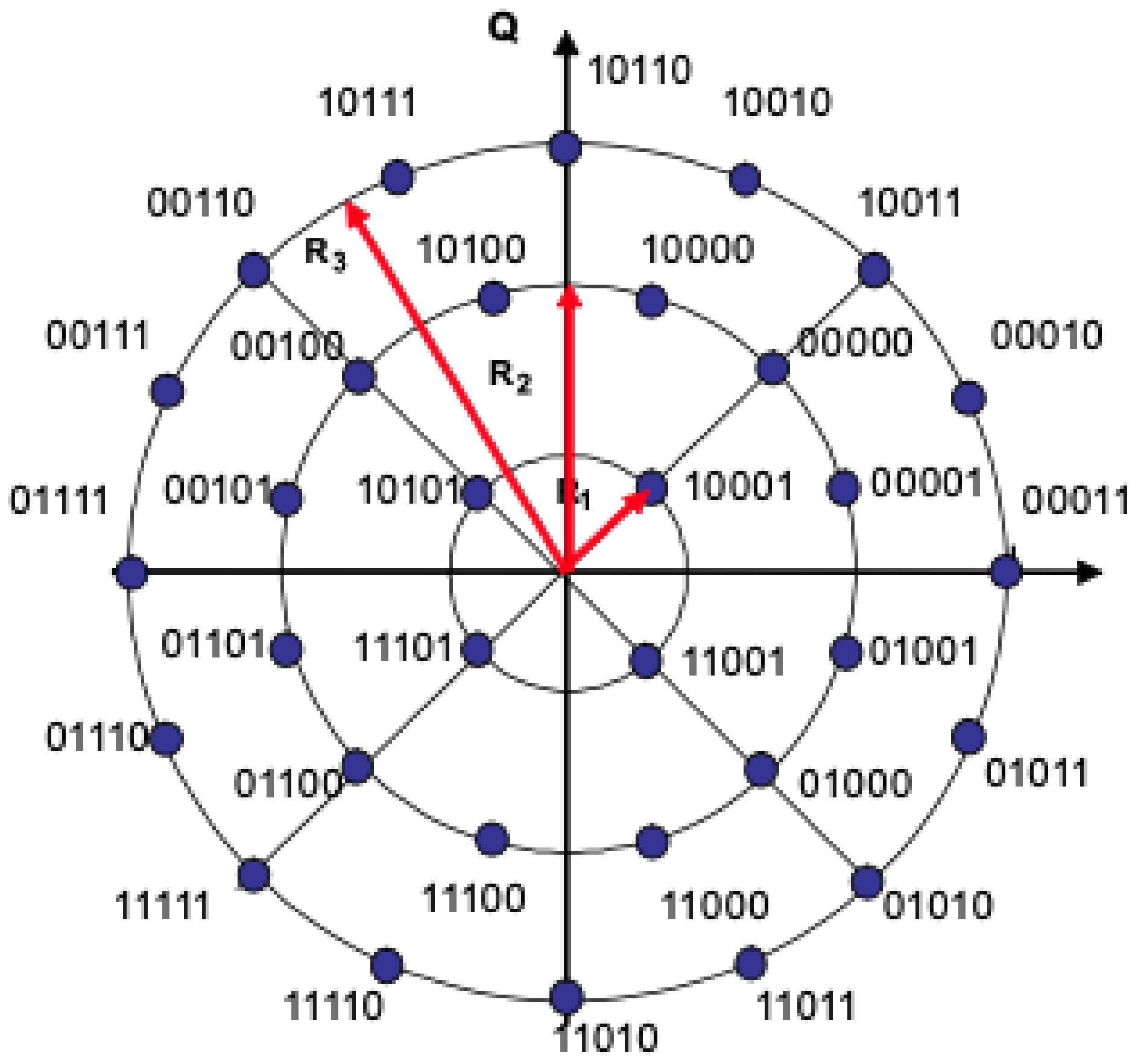
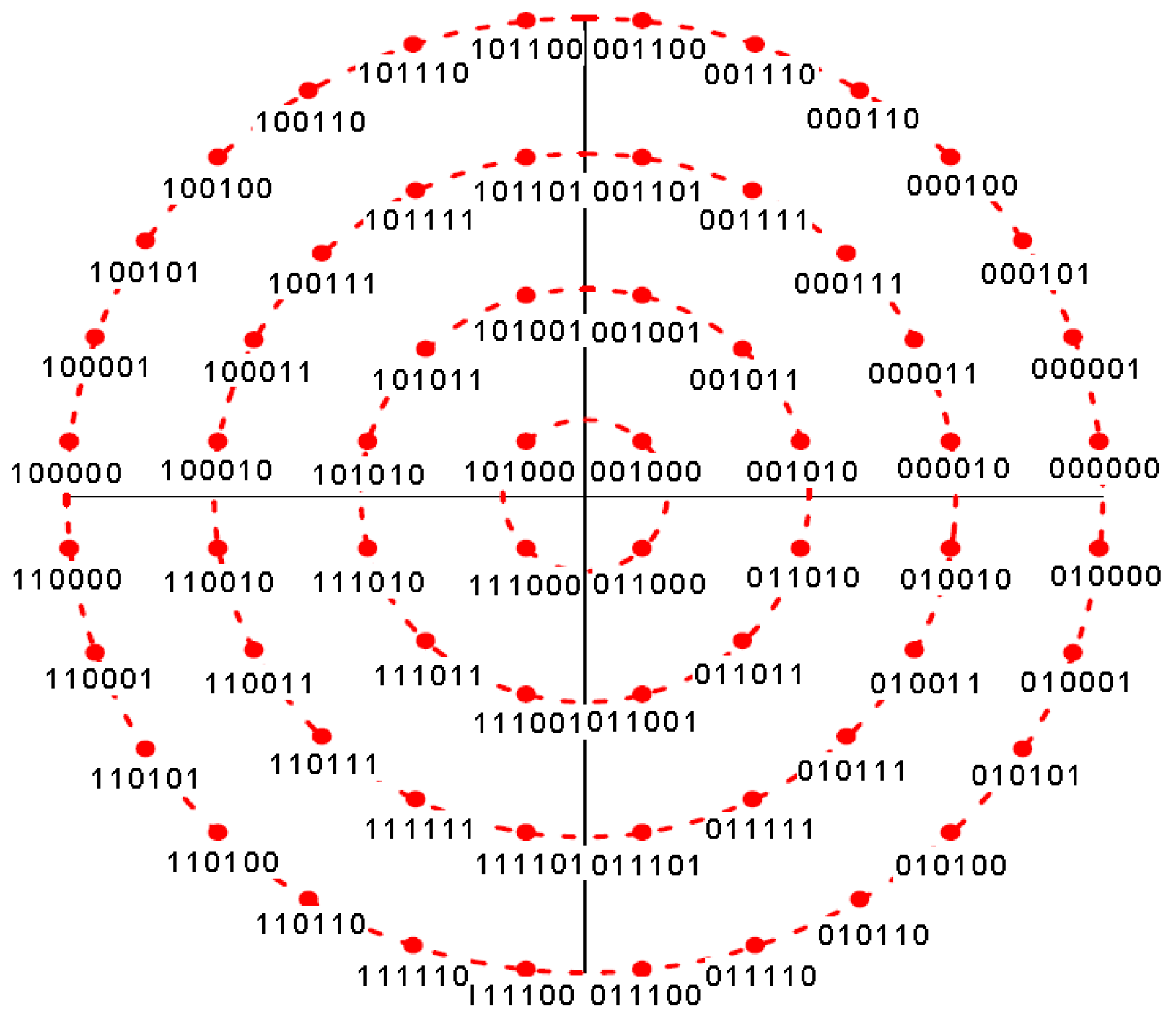
2. High Data Rate Modulator Design Description
- ACM_format denotes the operational mode for the current frame;
- m denotes the modulation order of constellation symbols;
- denotes the number of surviving bits after CC2 puncturing in each input 300-bit segment of systematic bits;
- K is the slicer output block length;
- I is the interleaver block length;
- S is the total number of transmitted systematic bits;
- P is the total number of transmitted parity-check bits;
- N is the row/column interleaver total block size;
- is the number of deleted parity bits in CC2 puncturing.
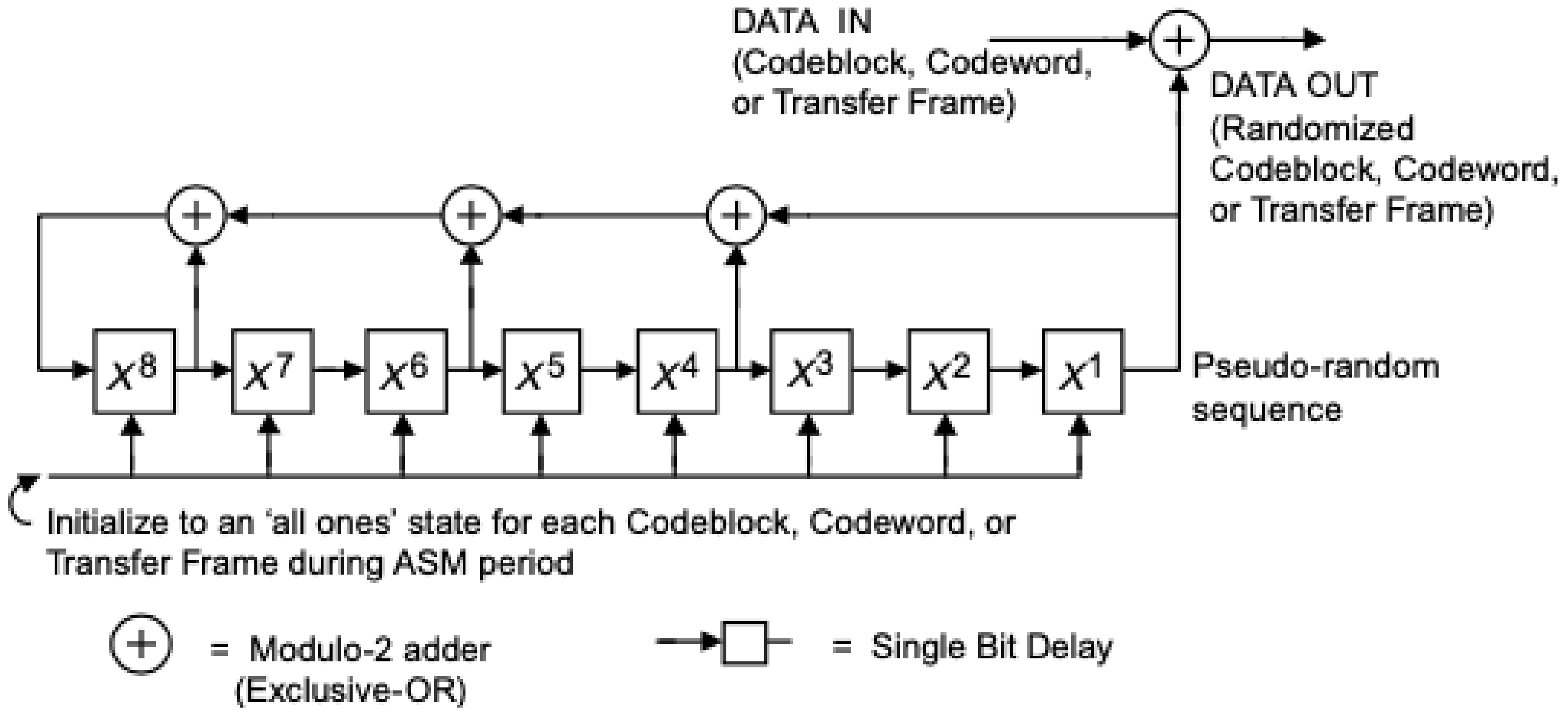
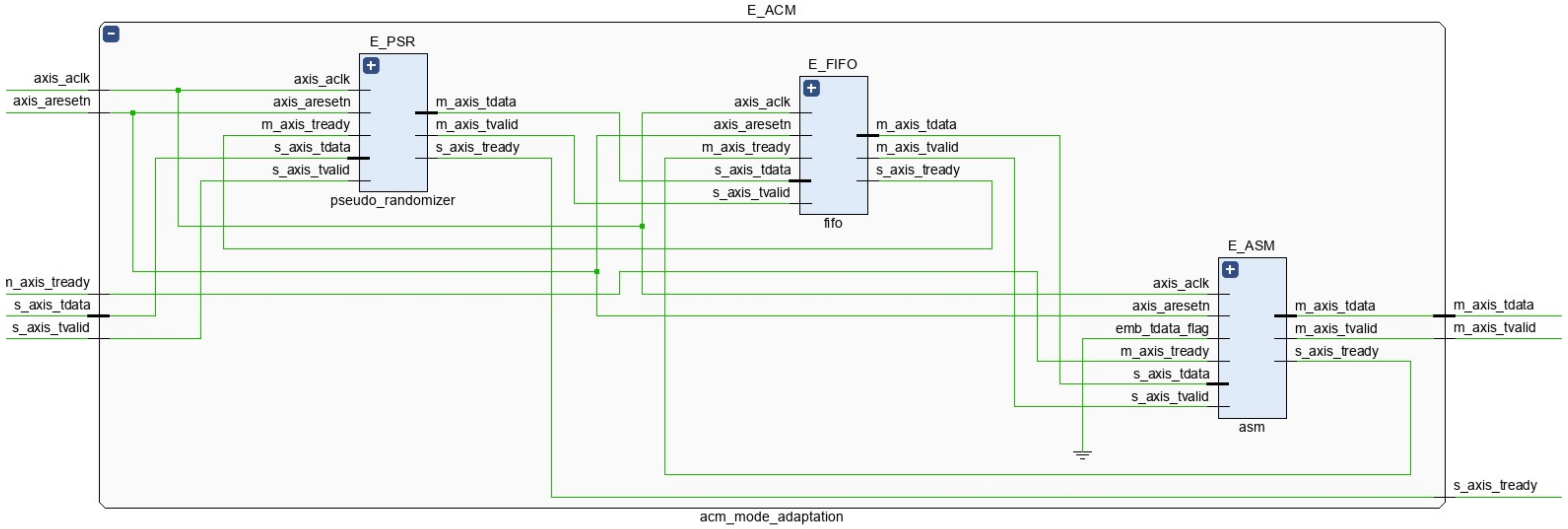
2.1. ACM Mode Adaptation
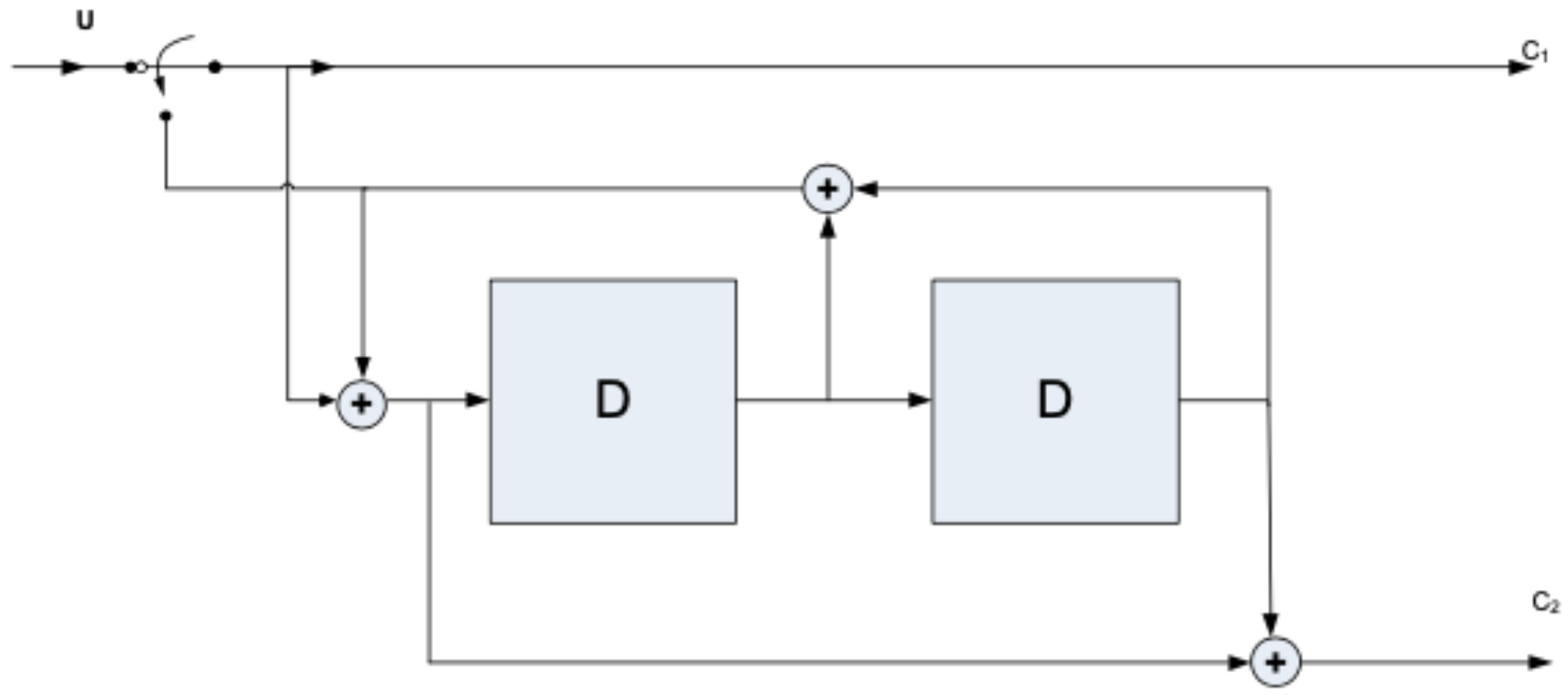
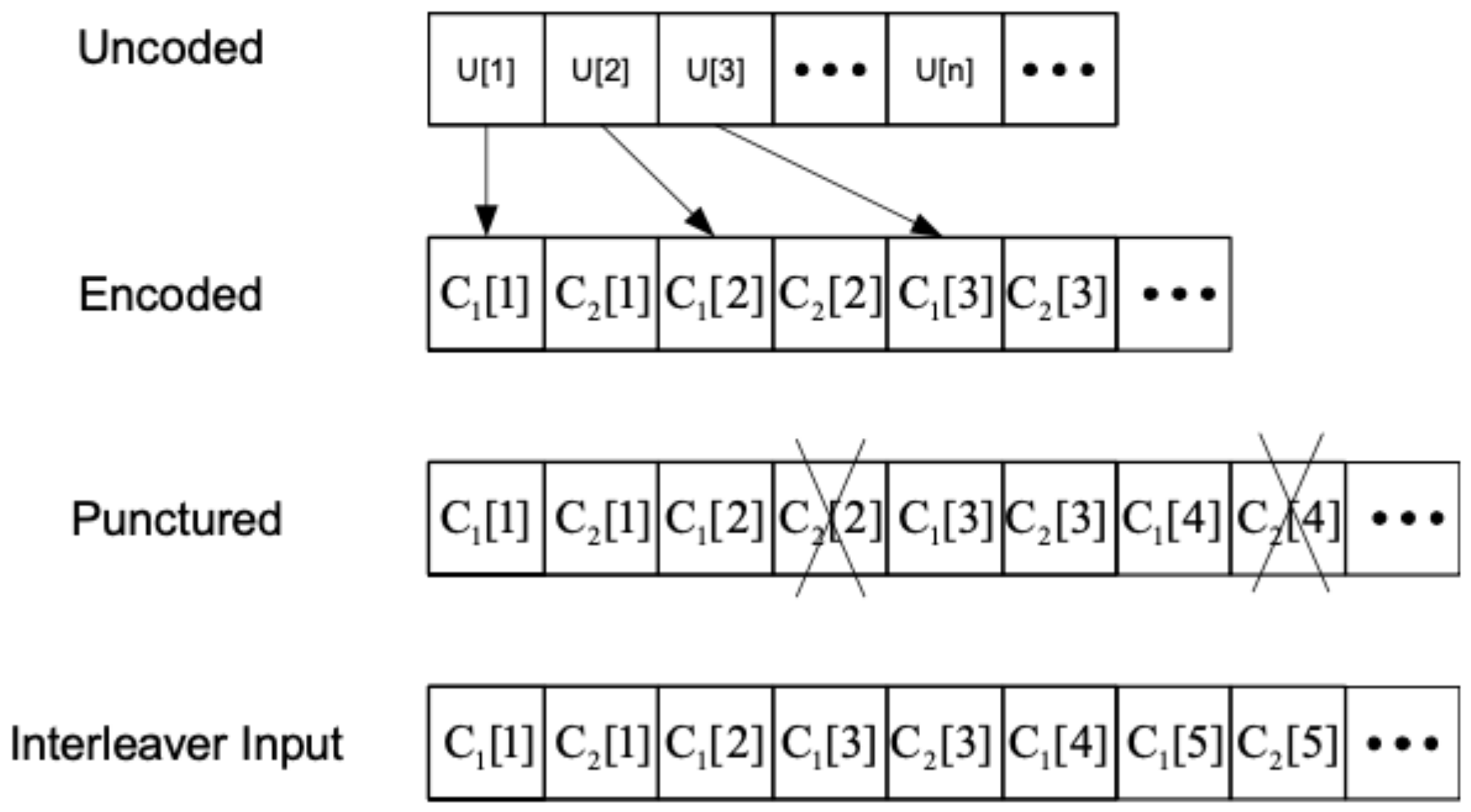
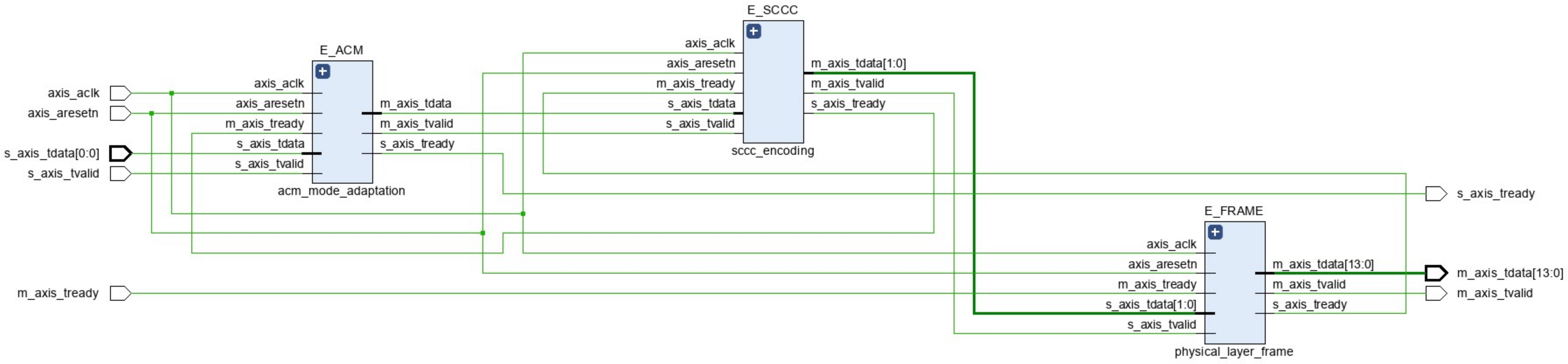
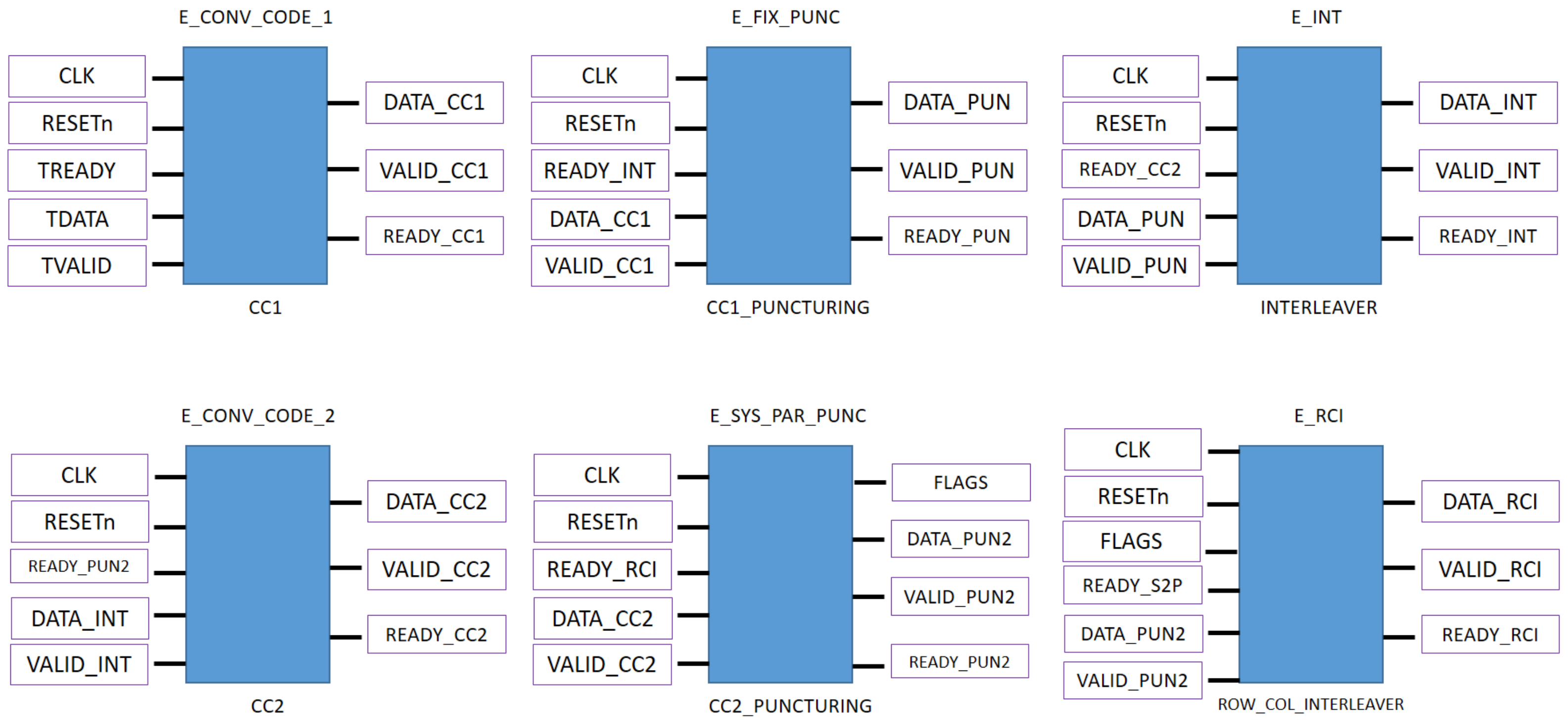
2.2. SCCC Encoding
- denotes the n-th uncoded input bit;
- denotes the n-th coded systematic output bit;
- denotes the n-th coded parity output bit.
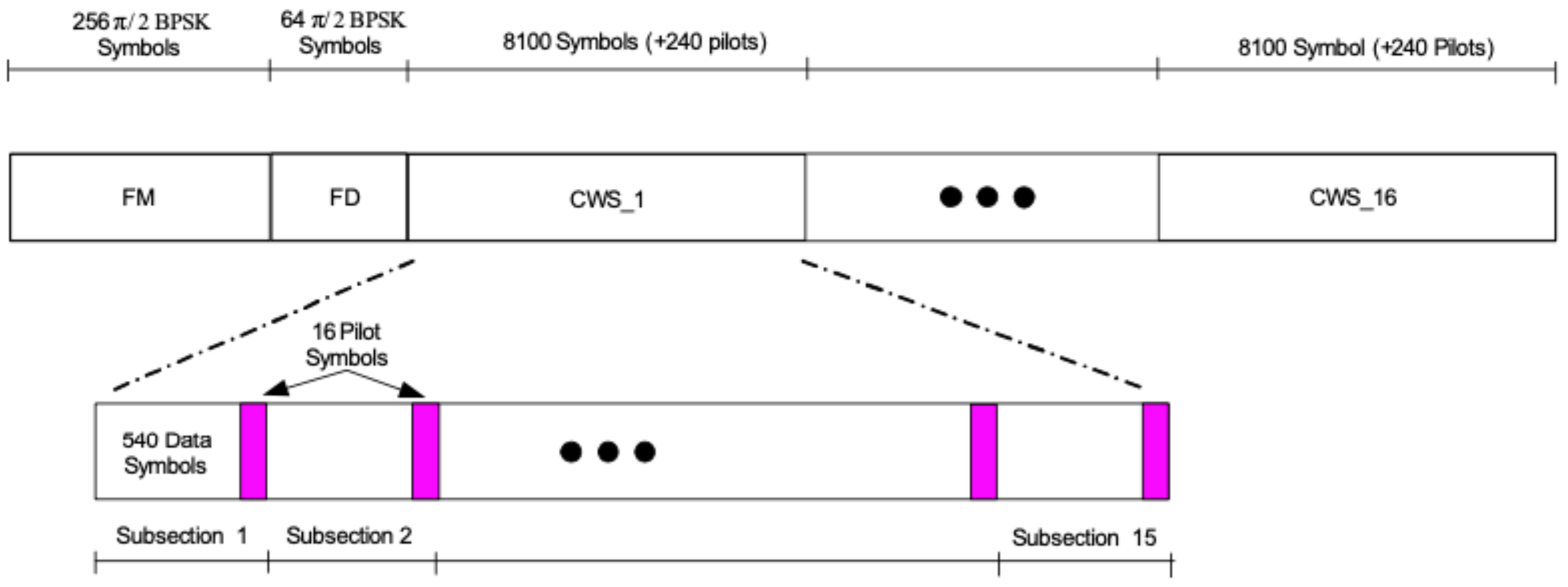
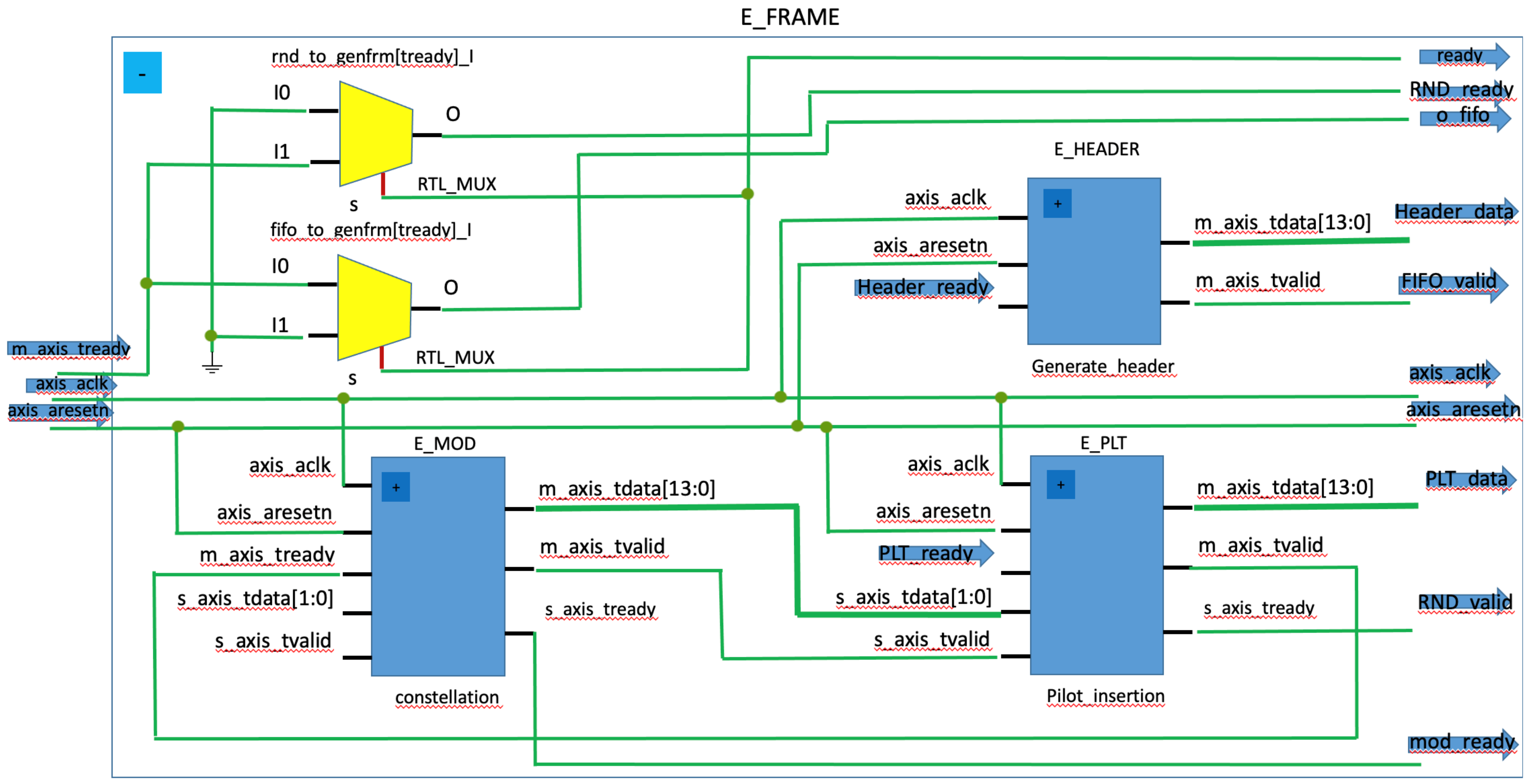
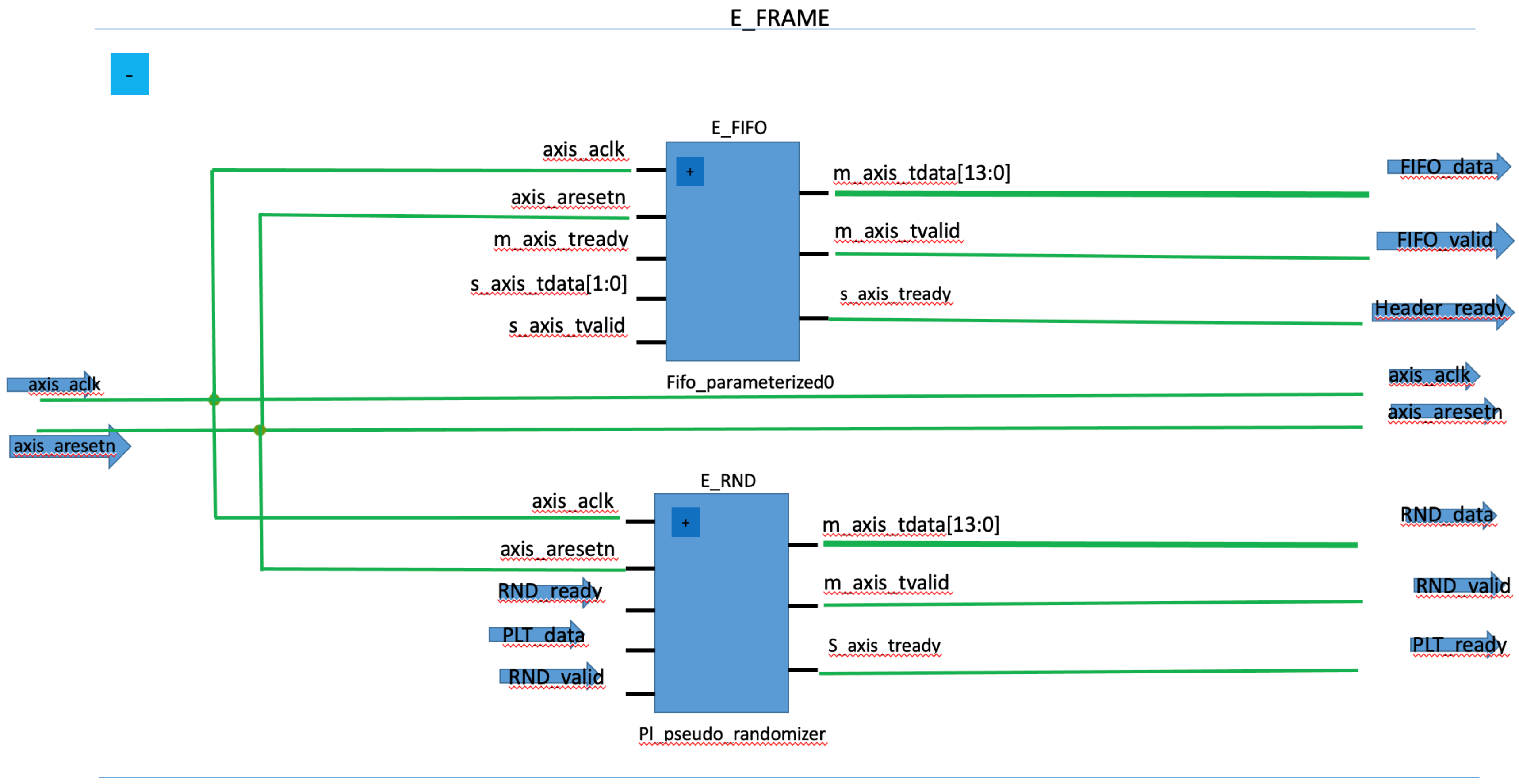
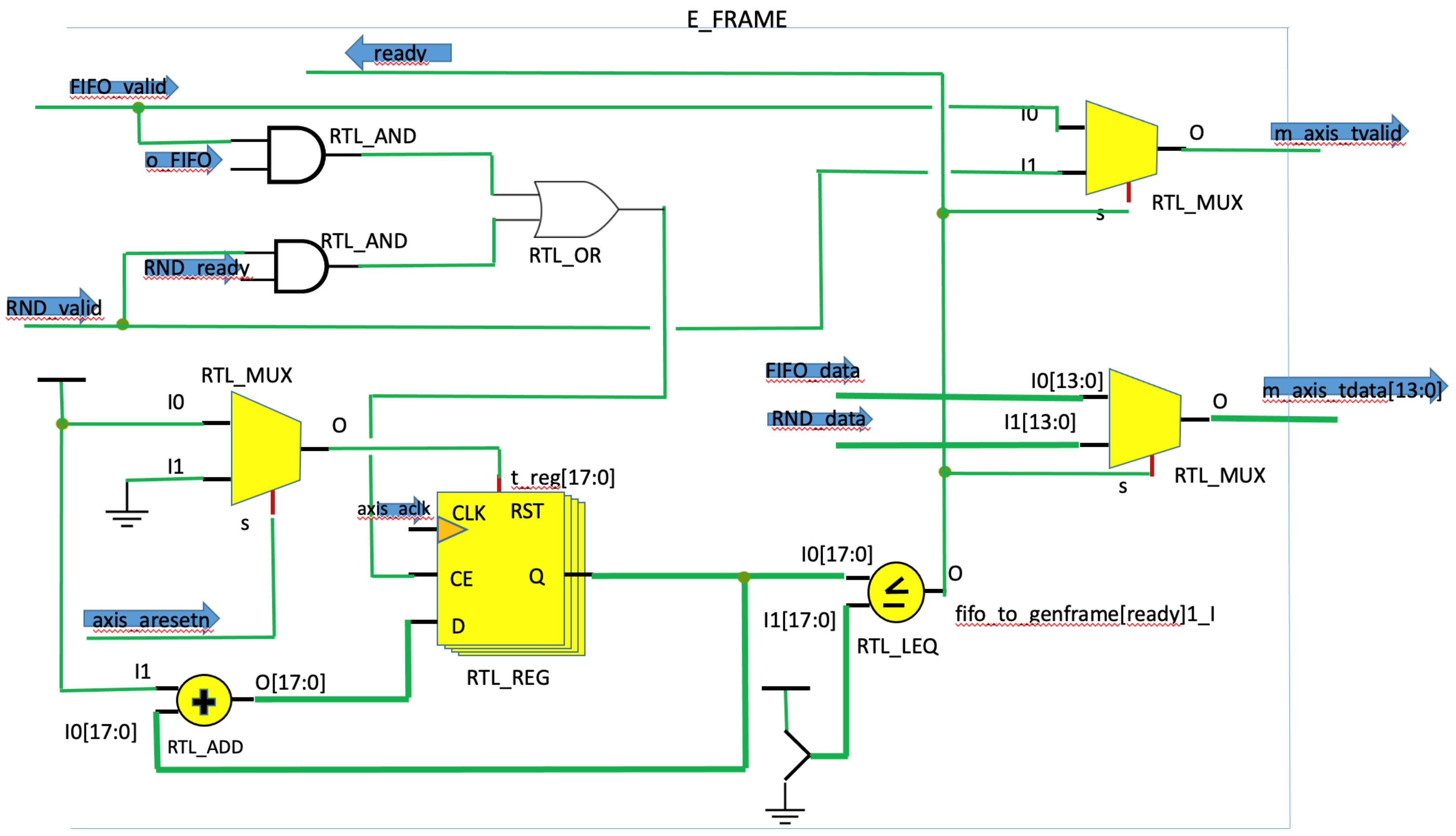
2.3. PL Framing
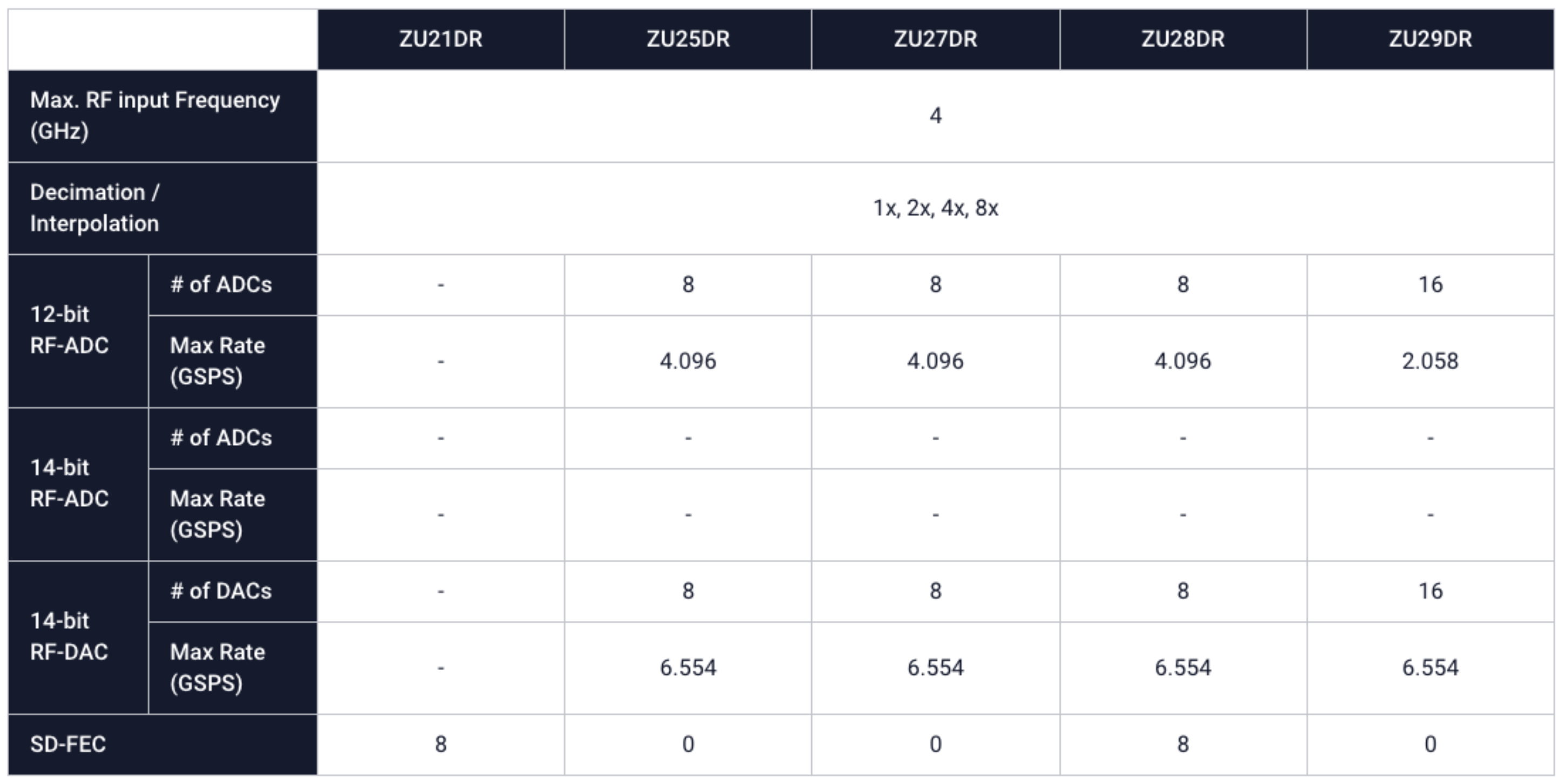
3. Flexible and Adaptive Embedded Prototype
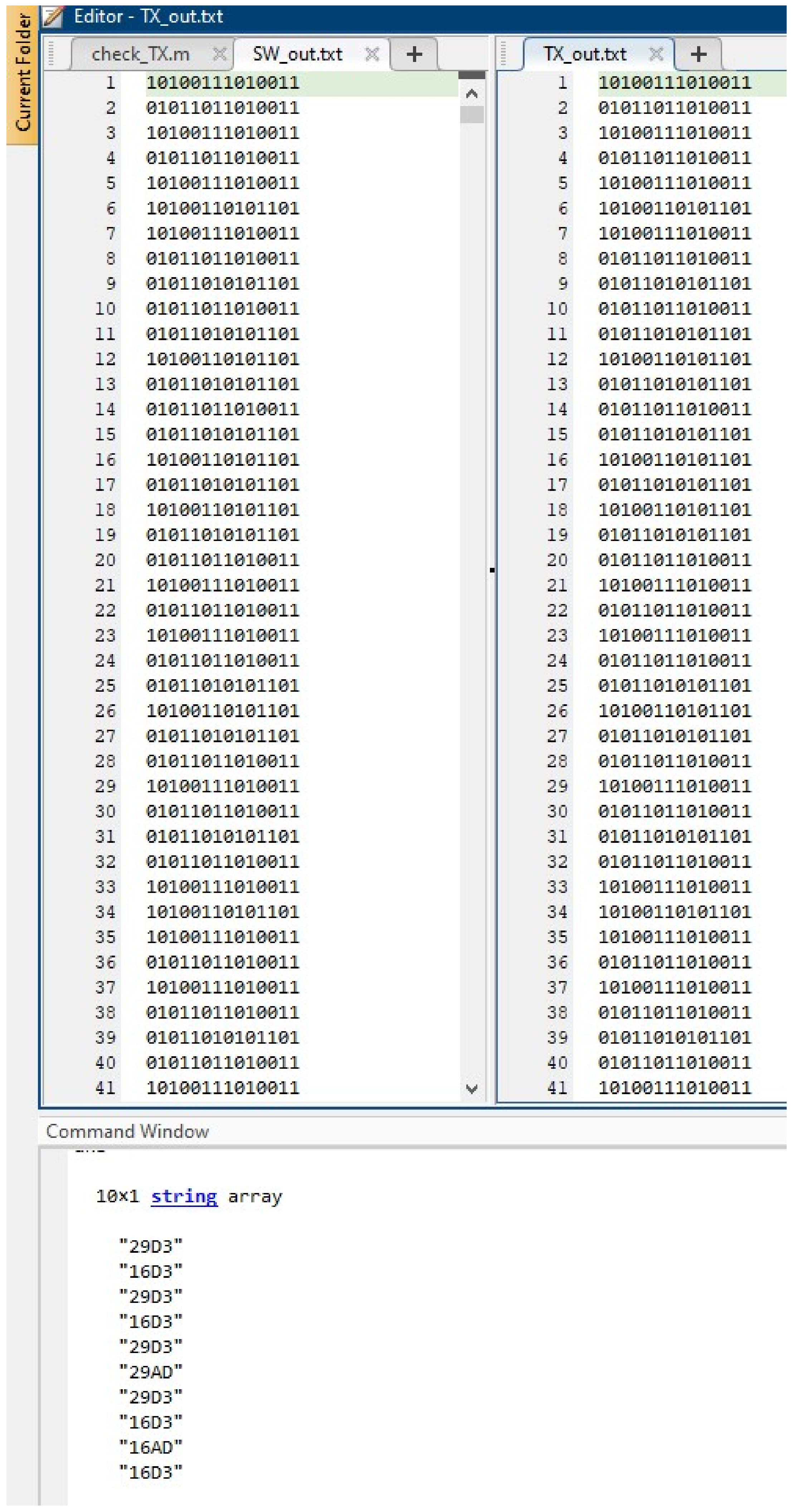
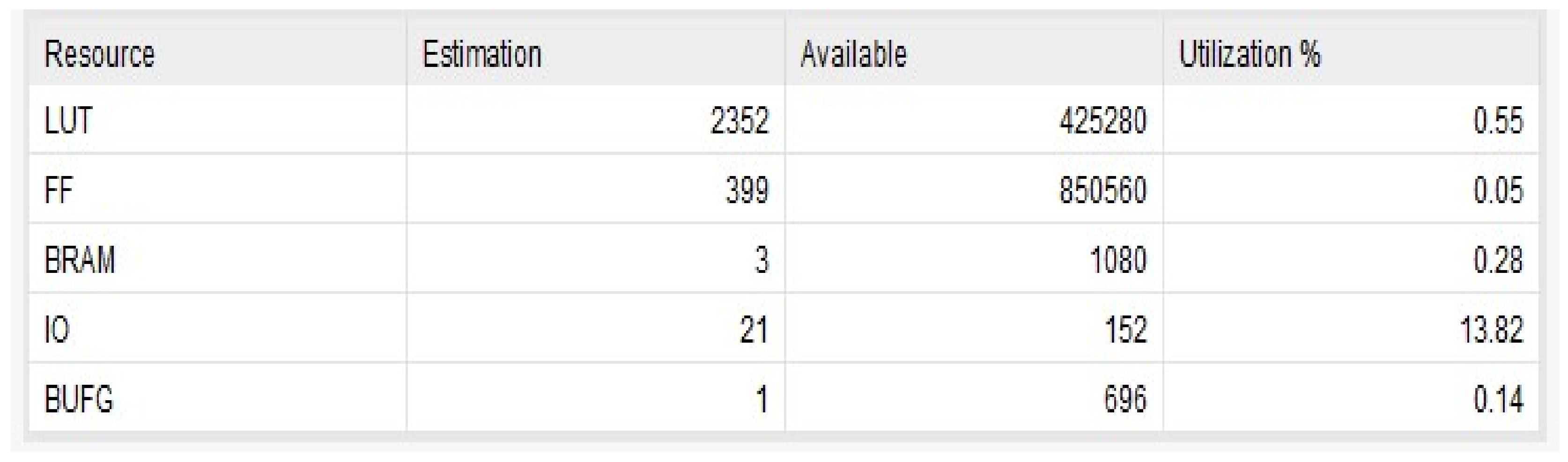
4. Results
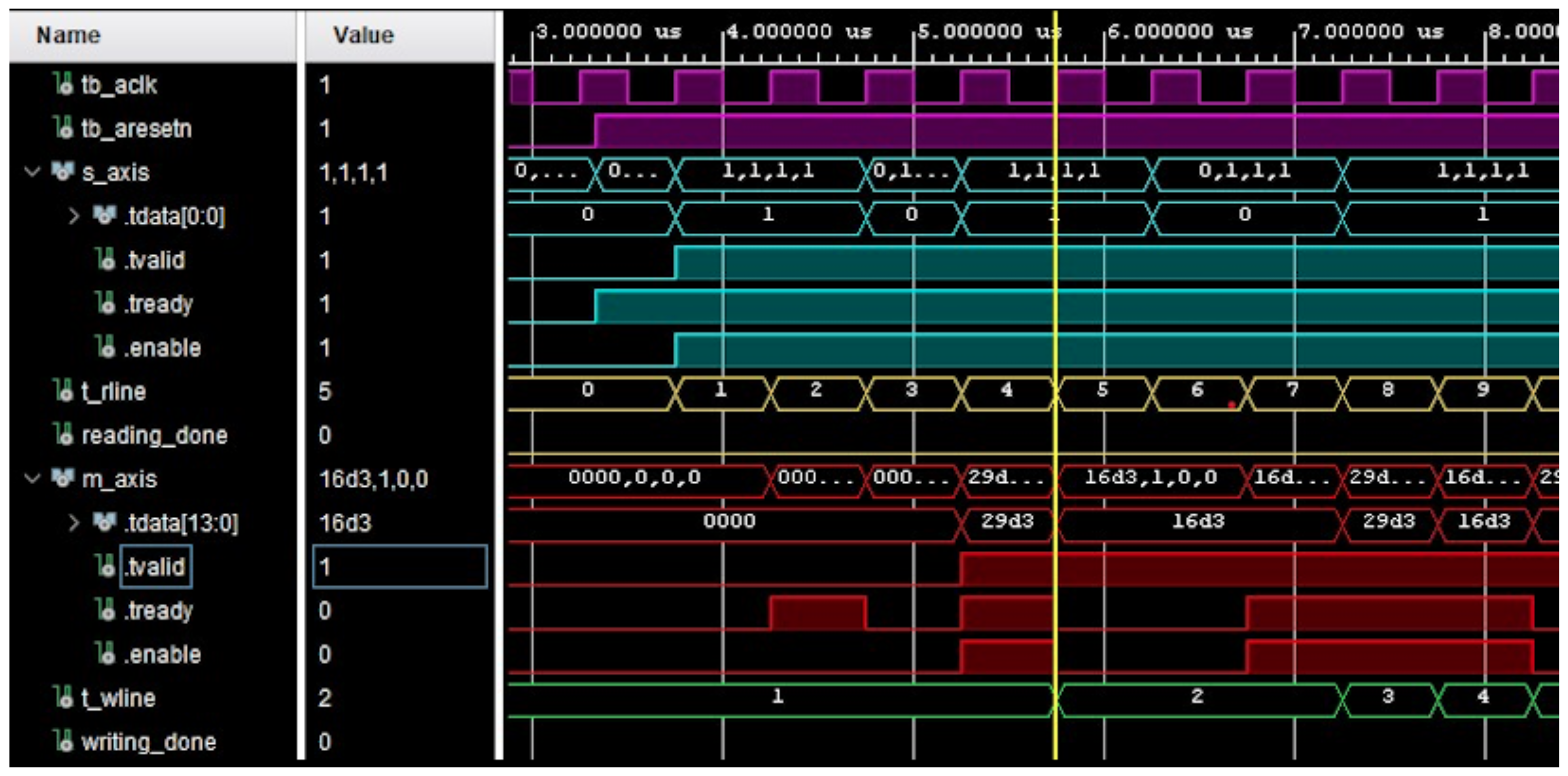
- tb_aclk (IN) 2 MHz input clock;
- tb_aresetn (IN) synchronous active-low reset;
- s_axis.tdata (IN) contains input data to feed into the device.
- s_axis.tvalid (IN) if ’1’ then the s_axis.tdata signal is considered valid;
- s_axis.tready (OUT) is set to ’1’ when the device is ready to process the data.
- s_axis.enable (IN) = s_axis.tvalid and s_axis.tready, signals a valid transfer of data to the device;
- t_rline timer to count the number of lines read from the input file;
- reading_done set to ’1’ when the input file has been read;
- m_axis.tdata (OUT) contains output data generated by the device;
- m_axis.tvalid (OUT) is set to ’1’ when the input data m_axis.tdata signal is considered valid;
- m_axis.tready (IN) if ’1’, then the next device paired to the master interface is waiting to receive data;
- m_axis.enable (OUT) = m_axis.tvalid and m_axis.tready, indicates correct data transfer through the master interface;
- t_wline timer to count the number of lines written in output file;
- writing_done set to ’1’ when all output data have been captured in output TXT file.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

References
- Goldsmith, A. Wireless Communications; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Flexible Advanced Coding and Modulation Scheme for High Rate Telemetry Applications. CCSDS 131.2-B-1. 2012. Available online: https://public.ccsds.org/Pubs/131x2b1e1.pdf (accessed on 10 August 2021).
- Benedetto, S.; Divsalar, D.; Montorsi, G.; Pollara, F. Serial concatenation of interleaved codes: Performance analysis, design, and iterative decoding. IEEE Trans. Inf. Theory 1998, 44, 909–926. [Google Scholar] [CrossRef]
- Benedetto, S.; Garello, R.; Montorsi, G.; Berrou, C.; Douillard, C.; Giancristofaro, D.; Ginesi, A.; Giugno, L.; Luise, M. MHOMS: High-speed ACM modem for satellite applications. IEEE Wirel. Commun. 2005, 12, 66–77. [Google Scholar] [CrossRef]
- Ugolini, A.; Montorsi, G.; Colavolpe, G. Next Generation High-Rate Telemetry. IEEE J. Sel. Areas Commun. 2018, 36, 327–337. [Google Scholar] [CrossRef]
- Xilinx, D. UltraScale Architecture and Product Data Sheet: Overview. Available online: https://www.xilinx.com/support/documentation/data_sheets/ds890-ultrascale-overview.pdf (accessed on 10 August 2021).
- Madrid Flight on Chip. 2019. Available online: https://flightonchip.es/ (accessed on 1 August 2021).
- Wertz, P.; Hespeler, B.; Kiessling, M.; Hagmanns, F.J. Next generation high data rate downlink subsystems based on a flexible APSK modulator applying SCCC encoding. In Proceedings of the 2016 International Workshop on Tracking, Telemetry and Command Systems for Space Applications (TTC), IEEE, Noordwijk, The Netherlands, 9–16 September 2016; pp. 1–7. [Google Scholar]
- Meoni, G.; Cassettari, R.; Bertolucci, M.; Marino, A.; Davalle, D.; Trafeli, M.; Fanucci, L. CCSDS 131.2-B-1 telemetry transmitter: A VHDL IP core and a validation architecture on board RTG4 FPGA. Acta Astronaut. 2020, 176, 484–493. [Google Scholar] [CrossRef]
- ARM. AMBA AXI-Stream Protocol Specification. Available online: https://developer.arm.com/documentation/ihi0051/latest (accessed on 2 August 2021).
- Louliej, A.; Jabrane, Y.; Jiménez, V.P.G.; Guilloud, F. Dimensioning an FPGA for Real-Time Implementation of State of the Art Neural Network-Based HPA Predistorter. Electronics 2021, 10, 1538. [Google Scholar] [CrossRef]
- Louliej, A.; Jabrane, Y.; Gil Jiménez, V.P.; García Armada, A. Practical Guidelines for Approaching the Implementation of Neural Networks on FPGA for PAPR Reduction in Vehicular Networks. Sensors 2019, 19, 116. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Caba, J.; Rincón, F.; Barba, J.; de la Torre, J.A.; López, J.C. FPGA-Based Solution for On-Board Verification of Hardware Modules Using HLS. Electronics 2020, 9, 2024. [Google Scholar] [CrossRef]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lamoral Coines, A.; Jiménez, V.P.G. CCSDS 131.2-B-1 Transmitter Design on FPGA with Adaptive Coding and Modulation Schemes for Satellite Communications. Electronics 2021, 10, 2476. https://doi.org/10.3390/electronics10202476
Lamoral Coines A, Jiménez VPG. CCSDS 131.2-B-1 Transmitter Design on FPGA with Adaptive Coding and Modulation Schemes for Satellite Communications. Electronics. 2021; 10(20):2476. https://doi.org/10.3390/electronics10202476
Chicago/Turabian StyleLamoral Coines, Adrián, and Víctor P. Gil Jiménez. 2021. "CCSDS 131.2-B-1 Transmitter Design on FPGA with Adaptive Coding and Modulation Schemes for Satellite Communications" Electronics 10, no. 20: 2476. https://doi.org/10.3390/electronics10202476
APA StyleLamoral Coines, A., & Jiménez, V. P. G. (2021). CCSDS 131.2-B-1 Transmitter Design on FPGA with Adaptive Coding and Modulation Schemes for Satellite Communications. Electronics, 10(20), 2476. https://doi.org/10.3390/electronics10202476