
Understanding the Performance Characteristics of Computational Storage Drives: A Case Study with SmartSSD


Abstract
:1. Introduction
- We implement the data verification algorithm on Samsung SmartSSD® with various combinations of parallel processing.
- We analyze the performance of the Samsung SmartSSD® in terms of resource utilization, power consumption, and execution time with various combinations of parallel processing techniques.
- The experimental results imply that a well-combined degree of parallelism between different implementation techniques is important in terms of performance and resource utilization.
2. Background
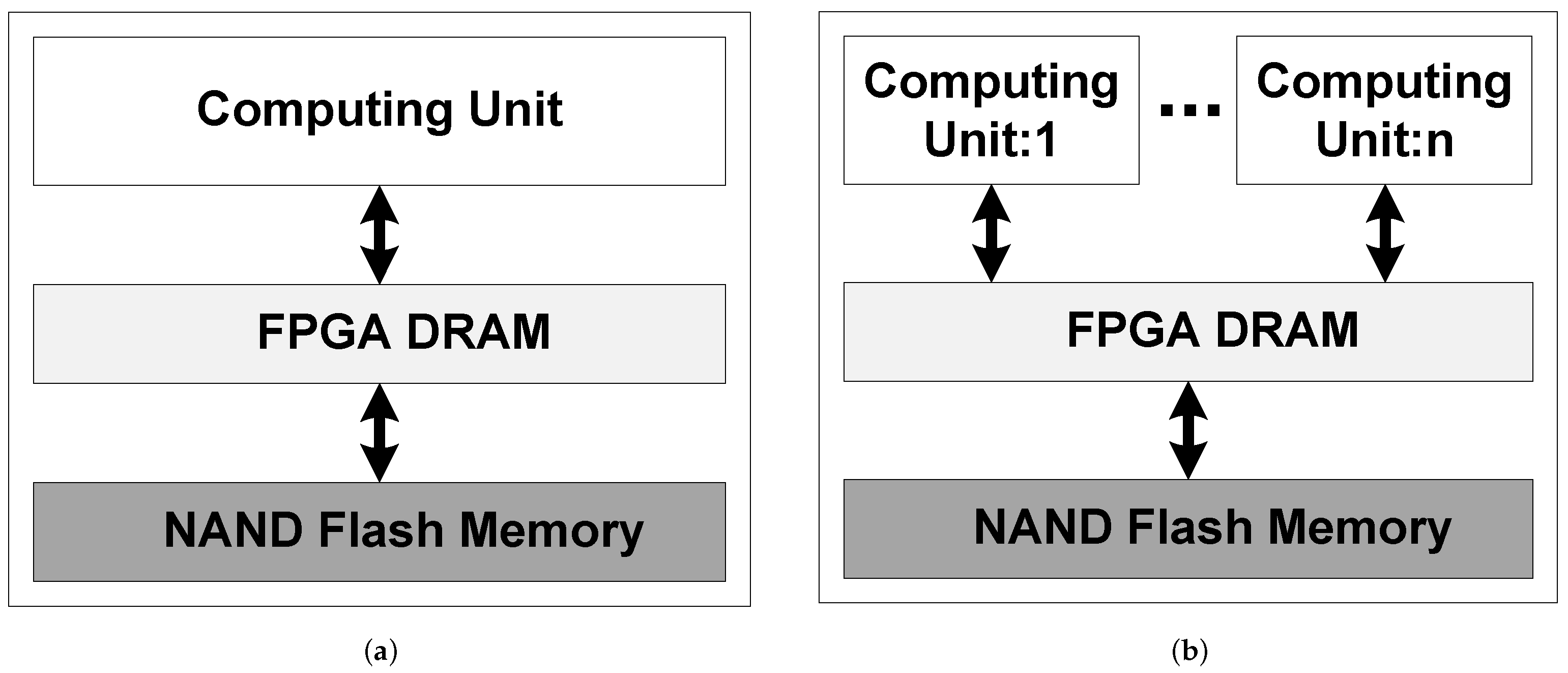
2.1. Architecture of SmartSSD®
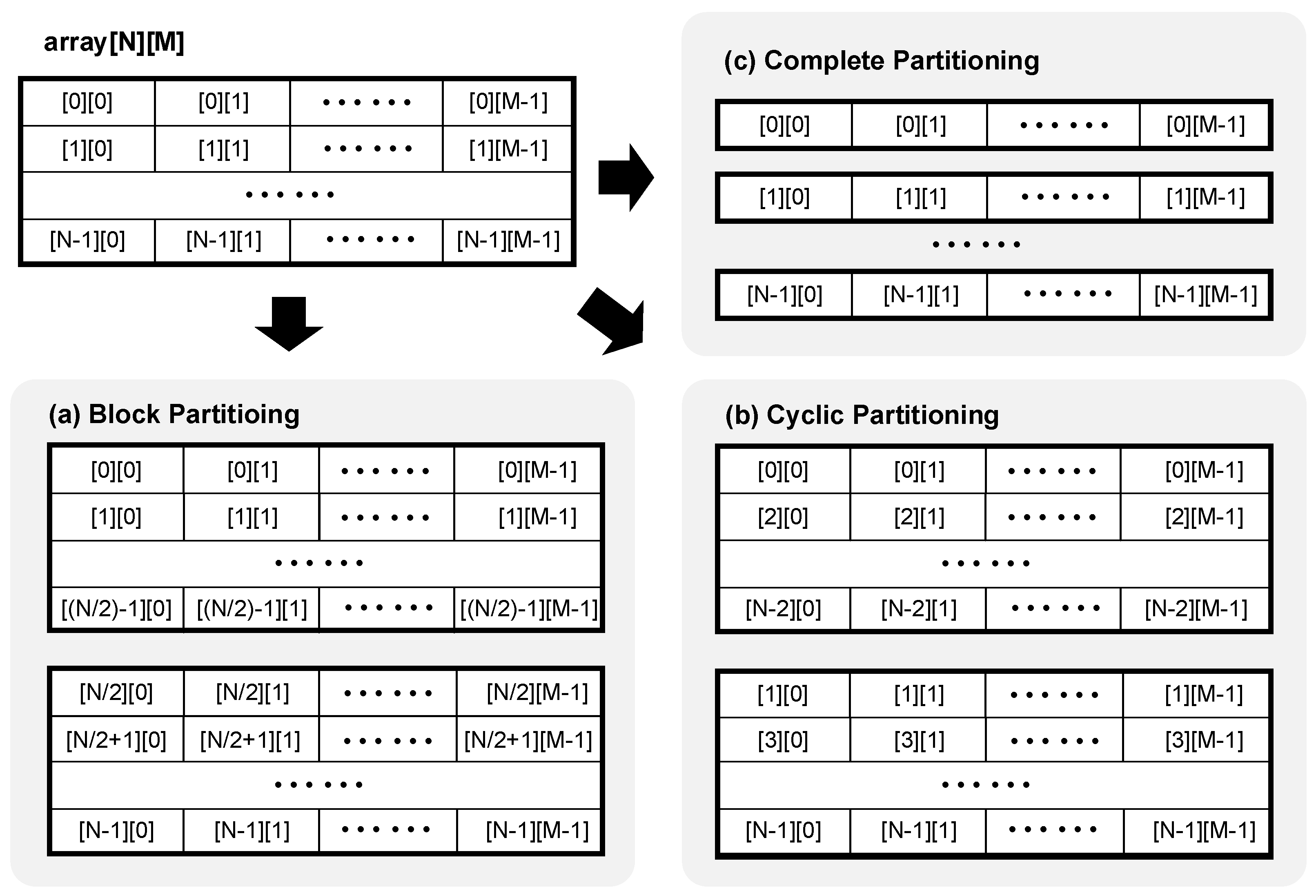
2.2. Techniques for Concurrent Processing within CSD
3. Related Work
3.1. Near-Storage Data Processing
3.2. CSDs
4. Case Study: Data Verification
4.1. Design Overview
4.2. Data Verification Procedure
| Algorithm 1 Computing Unit: Data Verification |
|
4.3. Implementation
4.4. Evaluation Scenario
5. Performance Analysis
5.1. Experimental Setup
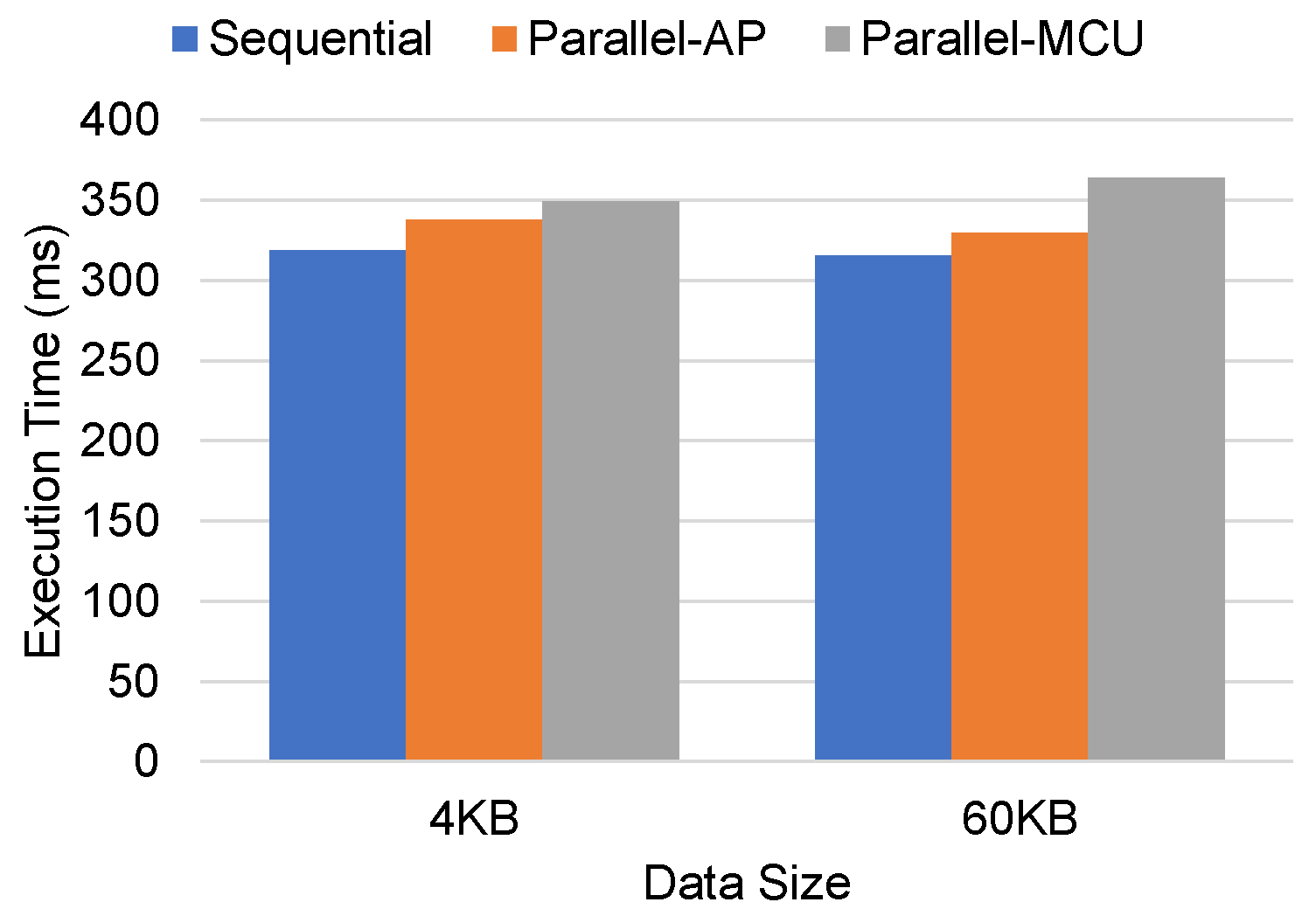
5.2. Single-Page Data Verification Time
5.3. Multiple-Page Data Verification Time
5.4. Resource Utilization
6. Summary and Implications
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- AHA Prodecuts Group. Available online: http://www.aha.com/ (accessed on 10 October 2021).
- Intel QuickAssist Technology Overview. Available online: https://www.intel.com/content/www/us/en/architecture-and-technology/intel-quick-assist-technology-overview.html (accessed on 10 October 2021).
- Microsoft Project Corsica. Available online: https://www.servethehome.com/microsoft-project-corsica-asic-delivers-100gbps-zipline-performance/ (accessed on 10 October 2021).
- Samsung SmartSSD. Available online: https://samsungsemiconductor-us.com/smartssd/ (accessed on 10 October 2021).
- ScaleFlux Computational Storage. Available online: https://www.scaleflux.com/ (accessed on 10 October 2021).
- SNIA Computational Storage. Available online: https://www.snia.org/computational (accessed on 10 October 2021).
- Chapman, K.; Nik, M.; Robatmili, B.; Mirkhani, S.; Lavasani, M. Computational Storage For Big Data Analytics. In Proceedings of the 10th International Workshop on Accelerating Analytics and Data Management Systems (ADMS’19), Los Angeles, CA, USA, 26 August 2019. [Google Scholar]
- Lee, J.H.; Zhang, H.; Lagrange, V.; Krishnamoorthy, P.; Zhao, X.; Ki, Y.S. SmartSSD: FPGA Accelerated Near-Storage Data Analytics on SSD. IEEE Comput. Archit. Lett. 2020, 19, 110–113. [Google Scholar] [CrossRef]
- Cao, W.; Liu, Y.; Cheng, Z.; Zheng, N.; Li, W.; Wu, W.; Ouyang, L.; Wang, P.; Wang, Y.; Kuan, R.; et al. POLARDB Meets Computational Storage: Efficiently Support Analytical Workloads in Cloud-Native Relational Database. In Proceedings of the 18th USENIX Conference on File and Storage Technologies (FAST 20), Santa Clara, CA, USA, 25–27 February 2020; pp. 29–41. [Google Scholar]
- Gu, B.; Yoon, A.S.; Bae, D.H.; Jo, I.; Lee, J.; Yoon, J.; Kang, J.U.; Kwon, M.; Yoon, C.; Cho, S.; et al. Biscuit: A Framework for Near-Data Processing of Big Data Workloads. In Proceedings of the 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), IEEE, Seoul, Korea, 18–22 June 2016; pp. 153–165. [Google Scholar]
- SDAccel Environment. Available online: https://www.xilinx.com/html_docs/xilinx2017_4/sdaccel_doc/gle1504034361378.html (accessed on 10 October 2021).
- SDAccel Environment. Available online: https://www.xilinx.com/html_docs/xilinx2017_4/sdaccel_doc/rad1504034309598.html (accessed on 10 October 2021).
- SDAccel Environment. Available online: https://www.xilinx.com/html_docs/xilinx2017_4/sdaccel_doc/uyd1504034366571.html (accessed on 10 October 2021).
- SDAccel Environment. Available online: https://www.xilinx.com/html_docs/xilinx2017_4/sdaccel_doc/yih1504034306435.html (accessed on 10 October 2021).
- SmartSSD Computational Storage Drive. Available online: https://samsungatfirst.com/smartssd/ (accessed on 10 October 2021).
- Samsung SmartSSD Product Brief. Available online: https://samsungsemiconductor-us.com/labs/pdfs/Samsung_PM983_Product_Brief.pdf (accessed on 10 October 2021).
- Xilinx UltraScale+ FPGAs. Available online: https://www.xilinx.com/products/silicon-devices/fpga/kintex-ultrascale-plus.html (accessed on 10 October 2021).
- UltraScale+ FPGA Product Tables and Product Selection Guide. Available online: https://www.xilinx.com/support/documentation/selection-guides/ultrascale-plus-fpga-product-selection-guide.pdf (accessed on 10 October 2021).
- Samsung PM1733 Product Brief. Available online: https://samsungsemiconductor-us.com/labs/pdfs/PM1733_U2_Product_Brief.pdf (accessed on 10 October 2021).
- Fifield, J.; Keryell, R.; Ratigner, H.; Styles, H.; Wu, J. Optimizing opencl applications on xilinx fpga. In Proceedings of the 4th International Workshop on OpenCL, Vienna, Austria, 19–21 April 2016; pp. 1–2. [Google Scholar]
- Zhang, T.; Wang, J.; Cheng, X.; Xu, H.; Yu, N.; Huang, G.; Zhang, T.; He, D.; Li, F.; Cao, W.; et al. FPGA-Accelerated Compactions for LSM-based Key-Value Store. In Proceedings of the 18th USENIX Conference on File and Storage Technologies (FAST 20), Santa Clara, CA, USA, 25–27 February 2020; pp. 225–237. [Google Scholar]
- Sun, X.; Yu, J.; Zhou, Z.; Xue, C.J. FPGA-based Compaction Engine for Accelerating LSM-tree Key-Value Stores. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), IEEE, Dallas, TX, USA, 20–24 April 2020; pp. 1261–1272. [Google Scholar]
- Ajdari, M.; Lee, W.; Park, P.; Kim, J.; Kim, J. FIDR: A Scalable Storage System for Fine-Grain Inline Data Reduction with Efficient Memory Handling. In Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, Columbus, OH, USA, 12–16 October 2019; pp. 239–252. [Google Scholar]
- Ajdari, M.; Park, P.; Kim, J.; Kwon, D.; Kim, J. CIDR: A cost-effective in-line data reduction system for terabit-per-second scale SSD arrays. In Proceedings of the 2019 IEEE International Symposium on High Performance Computer Architecture (HPCA), IEEE, Washington, DC, USA, 16–20 February 2019; pp. 28–41. [Google Scholar]
- Schmid, R.; Plauth, M.; Wenzel, L.; Eberhardt, F.; Polze, A. Accessible near-storage computing with FPGAs. In Proceedings of the Fifteenth European Conference on Computer Systems, Heraklon, Greece, 27–30 April 2020; pp. 1–12. [Google Scholar]
- Akagić, A.; Amano, H. Performance evaluation of multiple lookup tables algorithms for generating CRC on an FPGA. In Proceedings of the 2011 1st International Symposium on Access Spaces (ISAS), IEEE, Yokohama, Japan, 17–19 June 2011; pp. 164–169. [Google Scholar]
- Hu, X.; Wang, F.; Li, W.; Li, J.; Guan, H. QZFS:QAT Accelerated Compression in File System for Application Agnostic and Cost Efficient Data Storage. In Proceedings of the 2019 USENIX Annual Technical Conference (USENIX ATC 19), Renton, WA, USA, 10–12 July 2019; pp. 163–176. [Google Scholar]
- Promberger, L.; Schwemmer, R.; Fröning, H. Assessing the Overhead of Offloading Compression Tasks. In Proceedings of the 49th International Conference on Parallel Processing-ICPP: Workshops, Edmonton, AB, Canada, 17–20 August 2020; pp. 1–10. [Google Scholar]
- Alibaba.com. Available online: https://www.alibaba.com (accessed on 10 October 2021).
- Lagrange Moutinho dos Reis, V.; Li, H.; Shayesteh, A. Modeling Analytics for Computational Storage. In Proceedings of the ACM/SPEC International Conference on Performance Engineering, Edmonton, AB, Canada, 25–30 April 2020; pp. 88–99. [Google Scholar]
- Barbalace, A.; Do, J. Computational Storage: Where Are We Today? In Proceedings of the Annual Conference on Innovative Data Systems Research, Chaminade, CA, USA, 10–13 January 2021. [Google Scholar]
- Charyyev, B.; Alhussen, A.; Sapkota, H.; Pouyoul, E.; Gunes, M.H.; Arslan, E. Towards securing data transfers against silent data corruption. In Proceedings of the IEEE/ACM International Symposium in Cluster, Cloud, and Grid Computing, IEEE/ACM, Larnaca, Cyprus, 14–17 May 2019. [Google Scholar]
- Vitis High-Level Synthesis. Available online: https://www.xilinx.com/products/design-tools/vivado/integration/esl-design.html (accessed on 10 October 2021).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LUT | LUTRAM | FF | BRAM | |
|---|---|---|---|---|
| 33 | 8 | 25 | 85 | |
| 32 | 7 | 24 | 81 | |
| 30 | 7 | 22 | 73 | |
| 29 | 7 | 21 | 71 | |
| 32 | 7 | 22 | 69 | |
| 33 | 6 | 21 | 67 | |
| 31 | 6 | 21 | 65 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, H.; Yeom, H.Y.; Sung, H. Understanding the Performance Characteristics of Computational Storage Drives: A Case Study with SmartSSD. Electronics 2021, 10, 2617. https://doi.org/10.3390/electronics10212617
Kim H, Yeom HY, Sung H. Understanding the Performance Characteristics of Computational Storage Drives: A Case Study with SmartSSD. Electronics. 2021; 10(21):2617. https://doi.org/10.3390/electronics10212617
Chicago/Turabian StyleKim, Hwajung, Heon Y. Yeom, and Hanul Sung. 2021. "Understanding the Performance Characteristics of Computational Storage Drives: A Case Study with SmartSSD" Electronics 10, no. 21: 2617. https://doi.org/10.3390/electronics10212617
APA StyleKim, H., Yeom, H. Y., & Sung, H. (2021). Understanding the Performance Characteristics of Computational Storage Drives: A Case Study with SmartSSD. Electronics, 10(21), 2617. https://doi.org/10.3390/electronics10212617