
Cyberbullying Detection: Hybrid Models Based on Machine Learning and Natural Language Processing Techniques




Abstract
:1. Introduction
- We propose a novel architecture for cyberbullying detection that employs a bidirectional GRU by using GloVe for text representation. The proposed mechanism outperforms the existing baselines that employed Logistic Regression, CNN, and Bidirectional Encoder Representations from Transformers (BERT).
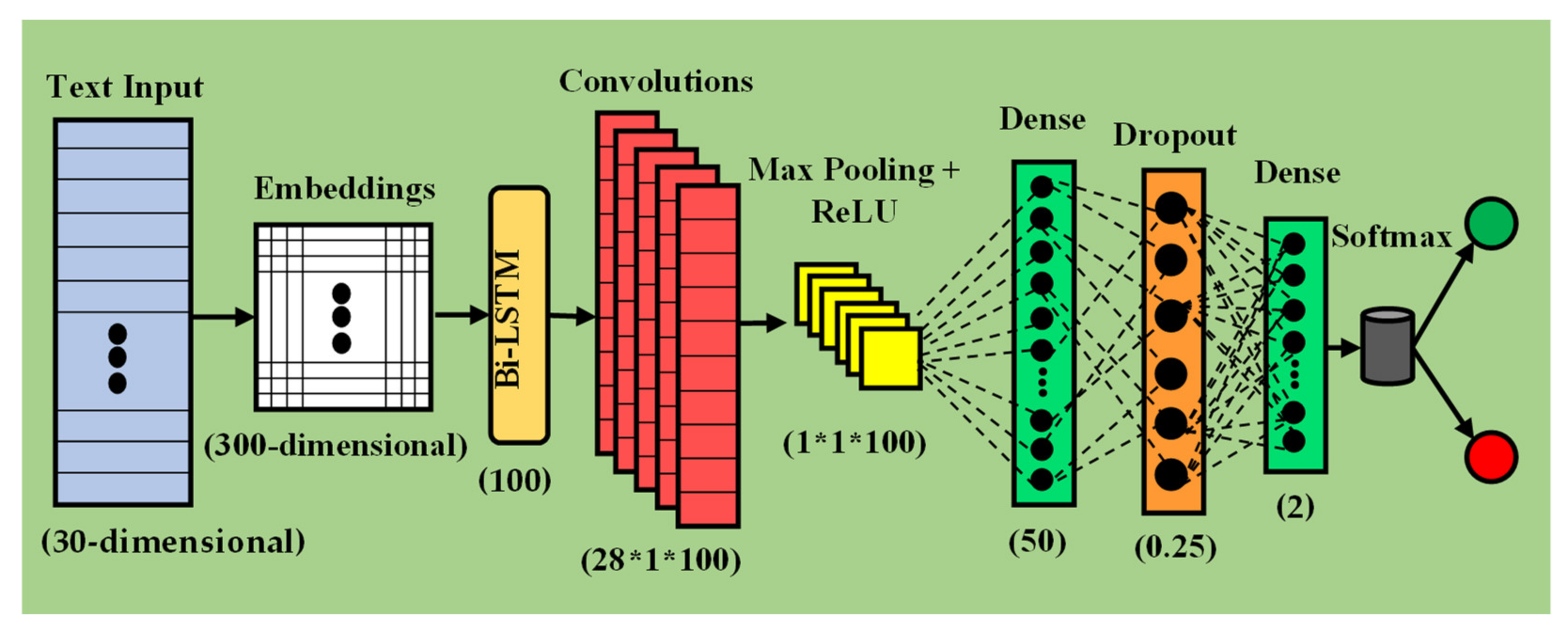
- We also propose a novel CNN-BiLSTM framework for the task which yields results comparable to the existing baselines.
- We provide a comparative study on the classification performance of four traditional machine learning and seven neural-network-based algorithms.
- We experiment with several feature extraction techniques and determine best-suited approaches for feature extraction and text embedding for both traditional machine learning and neural-network-based methods.
- We establish the efficacy of shallow neural networks for cyberbullying classification, thus moderating the need of complexly structures deep neural networks.
2. Related Work
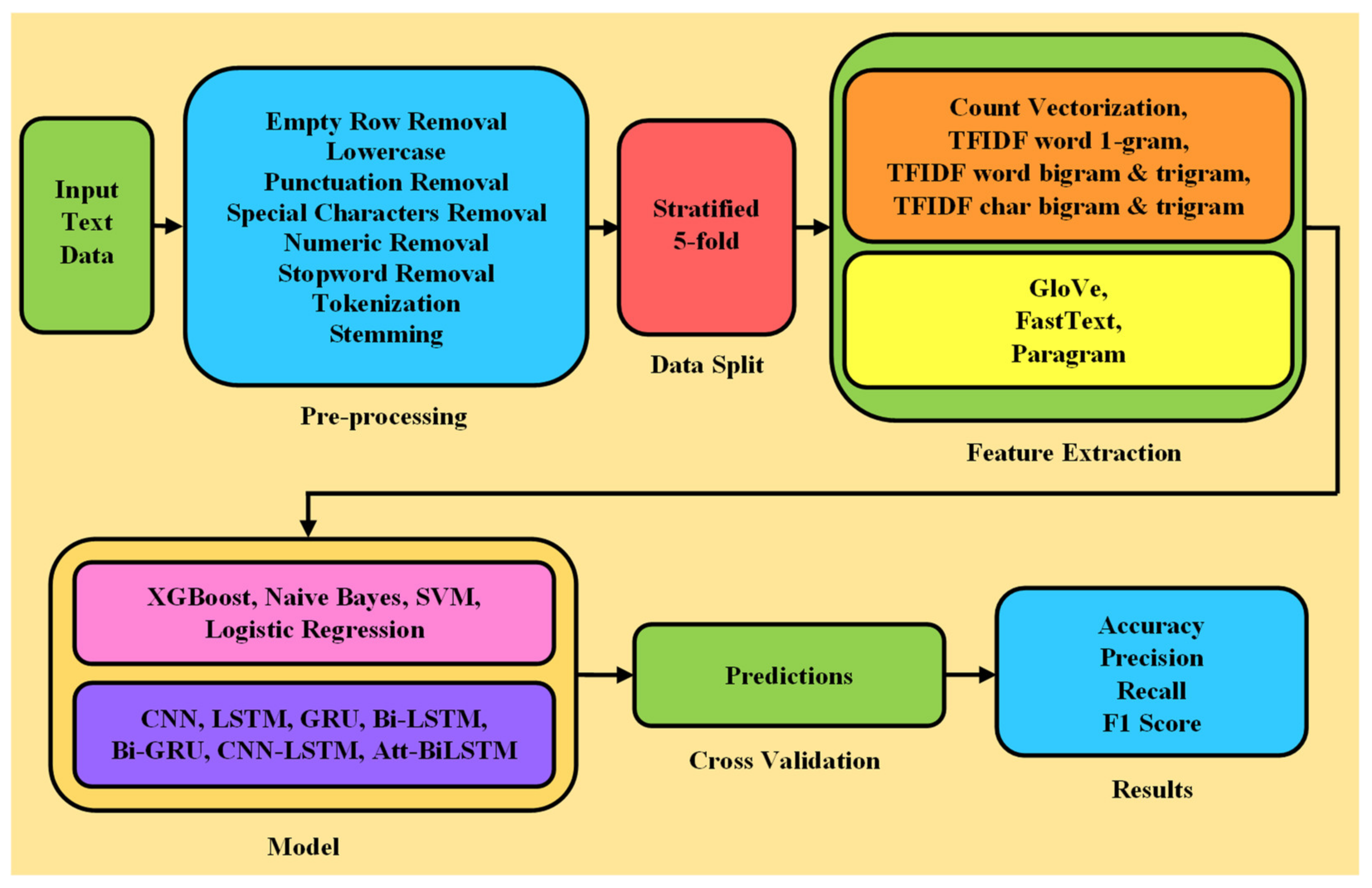
3. Methodology
3.1. Preprocessing and Feature Extraction
3.2. Traditional Machine Learning Approaches
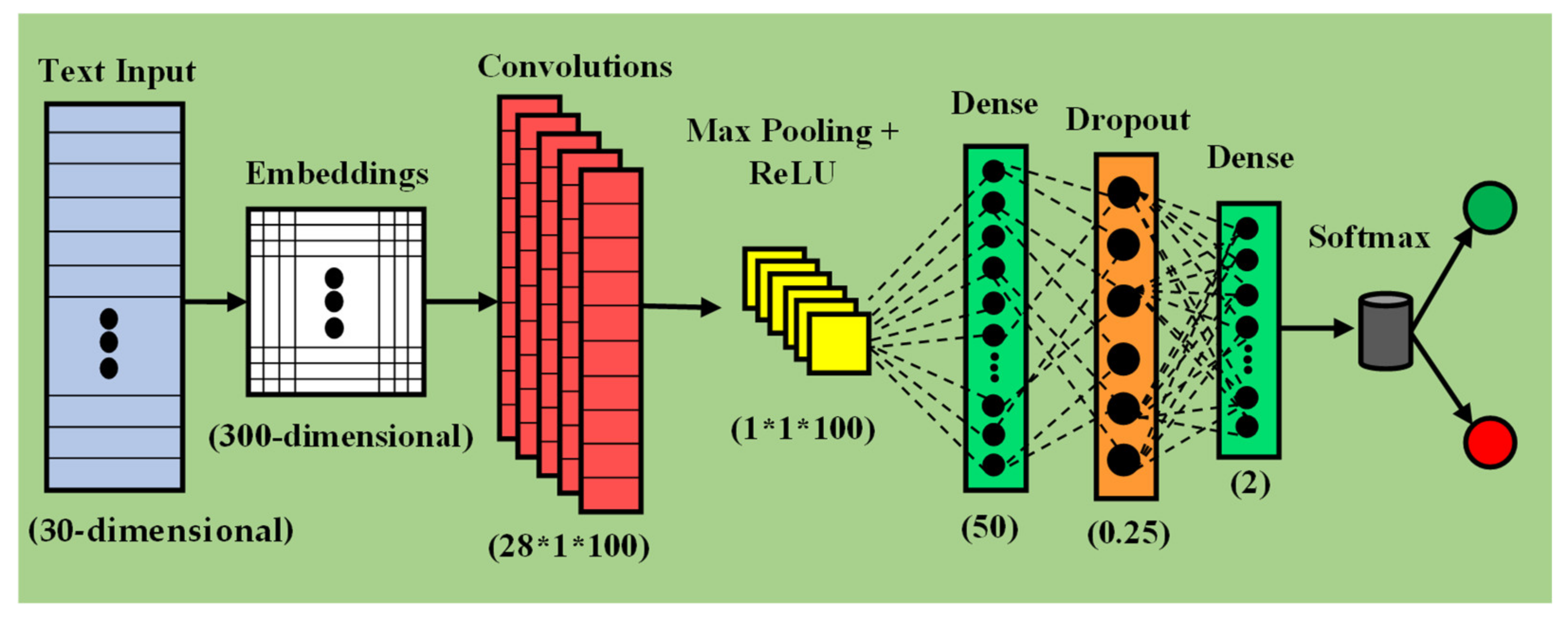
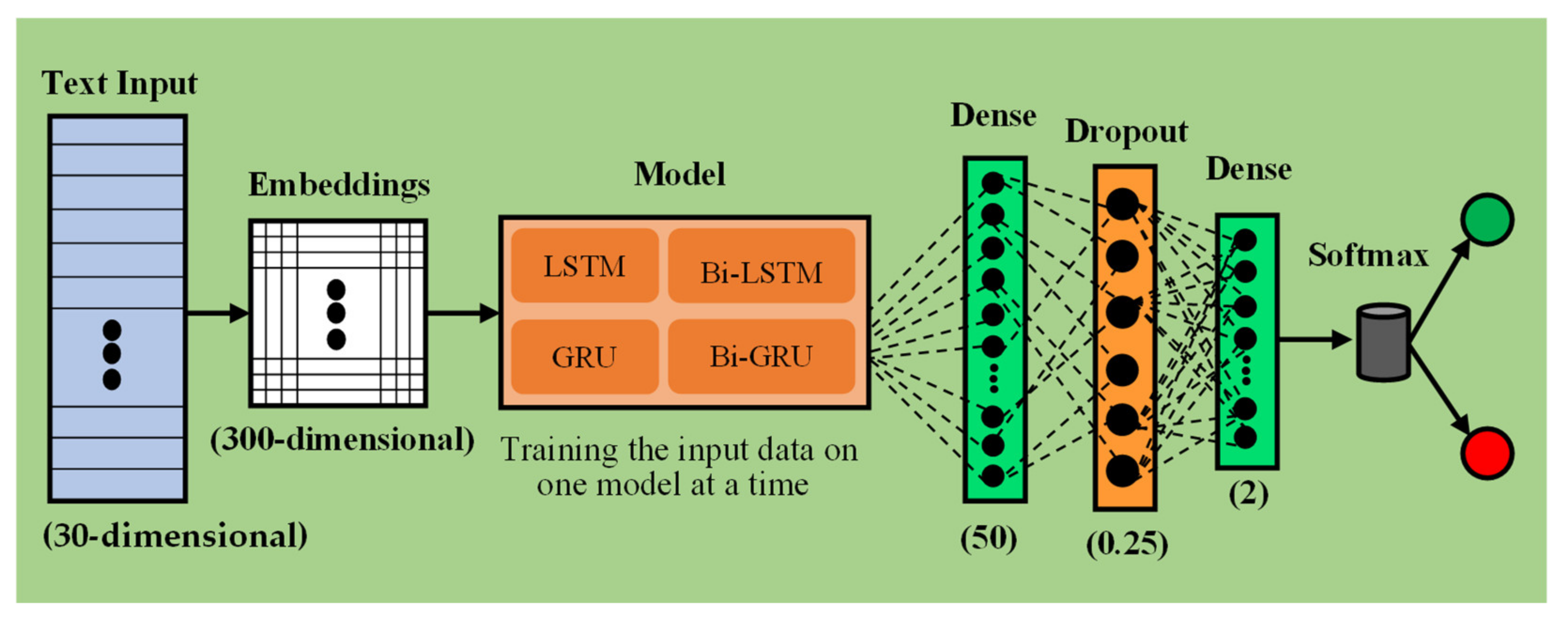
3.3. Neural Network Approaches
3.4. Implementation Details
4. Experimental Result Analysis
4.1. Datasets
4.2. Result Analysis
- Neural networks demonstrated higher performance than state-of-the-art traditional machine learning algorithms due to their robustness and capability to handle large datasets.
- Count Vectorization, although being an old statistical technique, manages to consistently provide good results.
- Across all preprocessing steps, Logistic Regression displayed the highest average performance amongst all machine learning techniques used, followed by SVM, XG Boost, and Naïve Bayes in the said order.
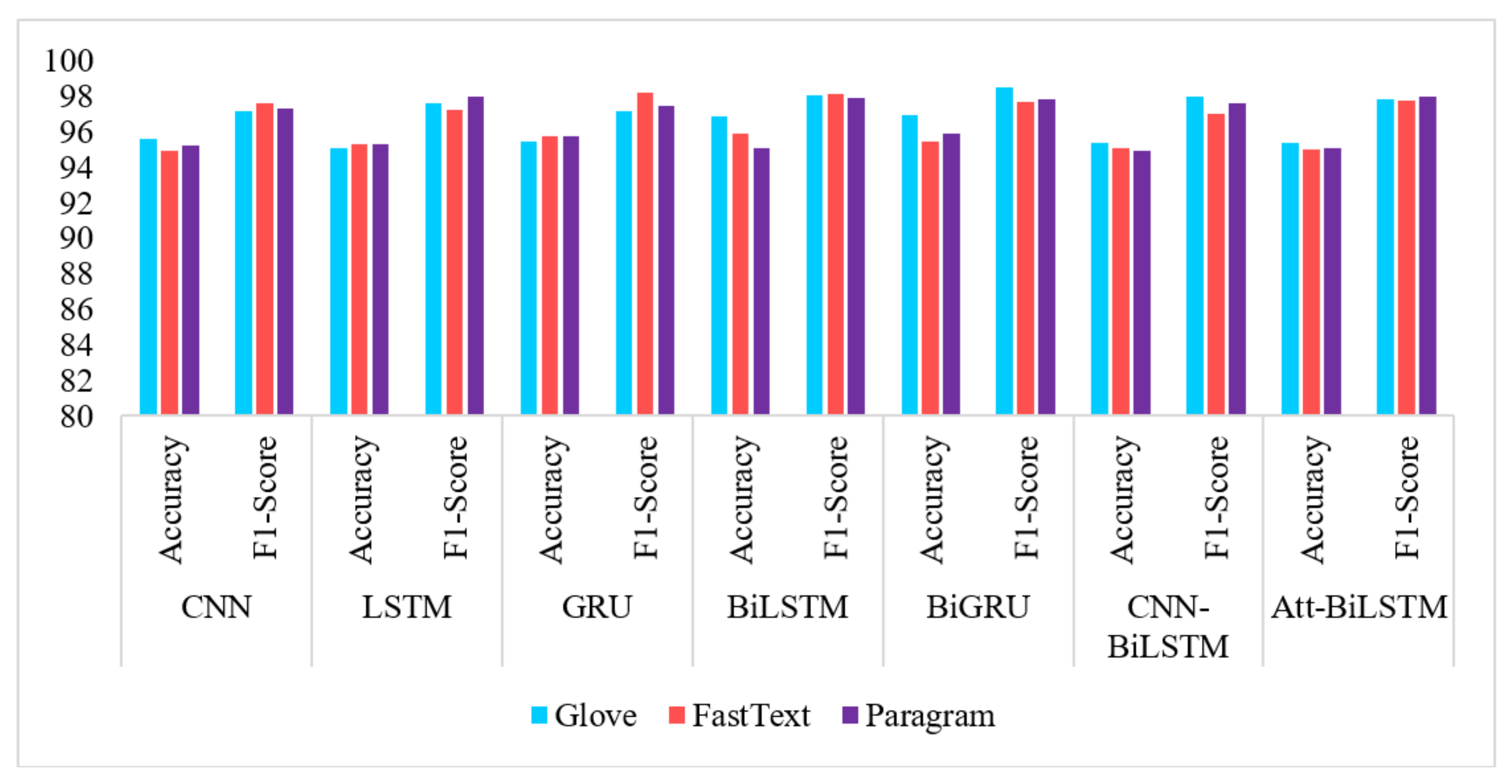
- GloVe embeddings resulted in a maximum number of high outputs than FastText and Paragram, although similar results were achieved by the other two methods in a similar fashion.
- F1-measures convey high performance through all neural network models. By observing the accuracy scores, we conclude that RNN networks such as GRU, Bi-GRU, and Bi-LSTM offered highest performance. Attention mechanism is also close to achieving results similar to these.
4.3. Baseline Comparison
5. Conclusions and Future Prospects
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Moreno, M.A. Cyberbullying. JAMA Pediatrics 2014, 168, 500. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bu, S.J.; Cho, S.B. A hybrid deep learning system of CNN and LRCN to detect cyberbullying from SNS comments. In Proceedings of the International Conference on Hybrid Artificial Intelligence Systems, Oviedo, Spain, 20–22 June 2018; Springer: Cham, Switzerland, 2018; pp. 561–572. [Google Scholar] [CrossRef]
- Mishra, P.; del Tredici, M.; Yannakoudakis, H.; Shutova, E. Author Profiling for Abuse Detection. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 1088–1098. [Google Scholar]
- Pavlopoulos, J.; Malakasiotis, P.; Bakagianni, J.; Androutsopoulos, I. Improved Abusive Comment Moderation with User Embeddings. In Proceedings of the 2017 EMNLP Workshop: Natural Language Processing meets Journalism, Copenhagen, Denmark, 2 May 2017. [Google Scholar] [CrossRef]
- Davidson, T.; Warmsley, D.; Macy, M.; Weber, I. Automated hate speech detection and the problem of offensive language. In Proceedings of the International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 15–18 May 2017. [Google Scholar]
- Djuric, N.; Zhou, J.; Morris, R.; Grbovic, M.; Radosavljevic, V.; Bhamidipati, N. Hate Speech Detection with Comment Embeddings. In Proceedings of the WWW 15 Companion: Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015. [Google Scholar] [CrossRef]
- Nobata, C.; Tetreault, J.; Thomas, A.; Mehdad, Y.; Chang, Y. Abusive Language Detection in Online User Content. In Proceedings of the 25th International Conference on World Wide Web, Montreal, QC, Canada, 11–15 April 2016. [Google Scholar] [CrossRef] [Green Version]
- Muneer, A.; Fati, S.M. A Comparative Analysis of Machine Learning Techniques for Cyberbullying Detection on Twitter. Futur. Internet 2020, 12, 187. [Google Scholar] [CrossRef]
- Rawat, C.; Sarkar, A.; Singh, S.; Alvarado, R.; Rasberry, L. Automatic Detection of Online Abuse and Analysis of Problematic Users in Wikipedia. In Proceedings of the 2019 Systems and Information Engineering Design Symposium (SIEDS), Charlottesville, VA, USA, 26 April 2019. [Google Scholar] [CrossRef]
- Waseem, Z.; Hovy, D. Hateful Symbols or Hateful People? Predictive Features for Hate Speech Detection on Twitter. In Proceedings of the NAACL Student Research Workshop, San Diego, CA, USA, 13–15 June 2016. [Google Scholar] [CrossRef]
- Badjatiya, P.; Gupta, S.; Gupta, M.; Varma, V. Deep Learning for Hate Speech Detection in Tweets. In Proceedings of the 26th International Conference on World Wide Web Companion—WWW ’17 Companion, Perth, Australia, 3–7 April 2017. [Google Scholar] [CrossRef] [Green Version]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014. [Google Scholar] [CrossRef] [Green Version]
- Lu, N.; Wu, G.; Zhang, Z.; Zheng, Y.; Ren, Y.; Choo, K.R. Cyberbullying detection in social media text based on character-level convolutional neural network with shortcuts. Concurr. Comput. Pr. Exp. 2020, 32, e5627. [Google Scholar] [CrossRef]
- Zhang, X.; Tong, J.; Vishwamitra, N.; Whittaker, E.; Mazer, J.P.; Kowalski, R.; Hu, H.; Luo, F.; Macbeth, J.; Dillon, E. Cyberbullying Detection with a Pronunciation Based Convolutional Neural Network. In Proceedings of the 2016 15th IEEE International Conference on Machine Learning and Applications (ICMLA), Anaheim, CA, USA, 18–20 December 2016. [Google Scholar] [CrossRef]
- Warner, W.; Hirschberg, J. Detecting hate speech on the world wide web. In Proceedings of the LSM’12 Proceedings of the Second Workshop on Language in Social Media, Montreal, QC, Canada, 7 June 2012. [Google Scholar]
- Reynolds, K.; Kontostathis, A.; Edwards, L. Using Machine Learning to Detect Cyberbullying. In Proceedings of the 2011 10th International Conference on Machine Learning and Applications and Workshops, Honolulu, HI, USA, 18–21 December 2011; Volume 2. [Google Scholar] [CrossRef] [Green Version]
- Wulczyn, E.; Thain, N.; Dixon, L. Ex Machina. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017. [Google Scholar] [CrossRef]
- Schmidt, A.; Wiegand, M. A Survey on Hate Speech Detection using Natural Language Processing. In Proceedings of the Fifth International Workshop on Natural Language Processing for Social Media, Valencia, Spain, 3 April 2017. [Google Scholar] [CrossRef] [Green Version]
- Qaiser, S.; Ali, R. Text Mining: Use of TF-IDF to Examine the Relevance of Words to Documents. Int. J. Comput. Appl. 2018, 181, 25–29. [Google Scholar] [CrossRef]
- Allahyari, M.; Pouriyeh, S.; Assefi, M.; Safaei, S.; Trippe, E.D.; Gutierrez, J.B.; Kochut, K. A brief survey of text mining: Classification, clustering and extraction techniques. arXiv 2017, arXiv:1707.02919. [Google Scholar]
- Shah, F.P.; Patel, V. A review on feature selection and feature extraction for text classification. In Proceedings of the 2016 International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET), Chennai, India, 23–25 March 2016. [Google Scholar] [CrossRef]
- Dzisevic, R.; Sesok, D. Text Classification using Different Feature Extraction Approaches. In Proceedings of the 2019 Open Conference of Electrical, Electronic and Information Sciences (eStream), Vilnius, Lithuania, 25 April 2019. [Google Scholar] [CrossRef]
- Kwok, I.; Wang, Y. Locate the hate: Detecting tweets against blacks. In Proceedings of the Twenty-Seventh AAAI Conference on Artificial Intelligence, Bellevue, WA, USA, 14 July 2013. [Google Scholar]
- Yin, D.; Xue, Z.; Hong, L.; Davison, B.D.; Kontostathis, A.; Edwards, L. Detection of Harassment on Web 2.0. In Proceedings of the Content Analysis in the WEB, Madrid, Spain, 21 April 2009; Volume 2. [Google Scholar]
- Tokunaga, R.S. Following you home from school: A critical review and synthesis of research on cyberbullying victimization. Comput. Hum. Behav. 2010, 26, 277–287. [Google Scholar] [CrossRef]
- Themeli, C.; Giannakopoulos, G.; Pittaras, N. A study of text representations in Hate Speech Detection. arXiv 2021, arXiv:2102.04521. [Google Scholar]
- Agrawal, S.; Awekar, A. Deep Learning for Detecting Cyberbullying Across Multiple Social Media Platforms. In Advances in Information Retrieval; Springer: Cham, Switzerland, 2018; Volume 10772. [Google Scholar] [CrossRef] [Green Version]
- Aroyehun, S.T.; Gelbukh, A. Aggression Detection in Social Media: Using Deep Neural Networks, Data Augmentation, and Pseudo Labeling. In Proceedings of the First Workshop on Trolling, Aggression and Cyberbullying, Santa Fe, NM, USA, 25 August 2018. [Google Scholar]
- Aglionby, G.; Davis, C.; Mishra, P.; Caines, A.; Yannakoudakis, H.; Rei, M.; Shutova, E.; Buttery, P. CAMsterdam at SemEval-2019 Task 6: Neural and graph-based feature extraction for the identification of offensive tweets. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019. [Google Scholar] [CrossRef]
- Chen, H.; McKeever, S.; Delany, S.J. The use of deep learning distributed representations in the identification of abusive text. In Proceedings of the International AAAI Conference on Web and Social Media, Münich, Germany, 11–14 June 2019. [Google Scholar]
- Chu, T.; Jue, K.; Wang, M. Comment Abuse Classification with Deep Learning. Glob. J. Comput. Sci. Technol. 2012, 12. [Google Scholar]
- Anand, M.; Eswari, R. Classification of Abusive Comments in Social Media using Deep Learning. In Proceedings of the 2019 3rd International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 27–29 March 2019. [Google Scholar] [CrossRef]
- Pavlopoulos, J.; Malakasiotis, P.; Androutsopoulos, I. Deep Learning for User Comment Moderation. In Proceedings of the First Workshop on Abusive Language Online, Vancouver, BC, Canada, 4 August 2017. [Google Scholar] [CrossRef] [Green Version]
- Banerjee, V.; Telavane, J.; Gaikwad, P.; Vartak, P. Detection of Cyberbullying Using Deep Neural Network. In Proceedings of the 2019 5th International Conference on Advanced Computing & Communication Systems (ICACCS), Coimbatore, India, 15–16 March 2019. [Google Scholar] [CrossRef]
- Agarwal, A.; Chivukula, A.S.; Bhuyan, M.H.; Jan, T.; Narayan, B.; Prasad, M. Identification and Classification of Cyberbullying Posts: A Recurrent Neural Network Approach Using Under-Sampling and Class Weighting. In Information Processing and Management of Uncertainty in Knowledge-Based Systems; Springer: New York, NY, USA, 2020; Volume 1333. [Google Scholar]
- Salton, G.; Wong, A.; Yang, C.S. A vector space model for automatic indexing. Commun. ACM 1975, 18, 613–620. [Google Scholar] [CrossRef] [Green Version]
- Shi, C.Y.; Xu, C.J.; Yang, X.J. Study of TFIDF algorithm. J. Comput. Appl. 2009, 29, 167–170. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar] [CrossRef]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef] [Green Version]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. In Proceedings of the 15th Con-ference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; Volume 2. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781v3. [Google Scholar]
- Wieting, J.; Bansal, M.; Gimpel, K.; Livescu, K. From Paraphrase Database to Compositional Paraphrase Model and Back. Trans. Assoc. Comput. Linguist. 2015, 3, 345–358. [Google Scholar] [CrossRef]
- Vulić, I.; Mrkšić, N.; Reichart, R.; Séaghdha, D.Ó.; Young, S.; Korhonen, A.; Barzilay, R.; Kan, M.-Y. Morph-fitting: Fine-Tuning Word Vector Spaces with Simple Language-Specific Rules. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1. [Google Scholar] [CrossRef]
- Mrkšić, N.; Séaghdha, D.Ó.; Thomson, B.; Gašić, M.; Rojas-Barahona, L.M.; Su, P.-H.; VanDyke, D.; Wen, T.-H.; Young, S. Counter-fitting Word Vectors to Linguistic Constraints. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016. [Google Scholar] [CrossRef]
- Mrkšić, N.; Vulić, I.; Séaghdha, D.Ó.; Leviant, I.; Reichart, R.; Gašić, M.; Korhonen, A.; Young, S. Semantic Specialization of Distributional Word Vector Spaces using Monolingual and Cross-Lingual Constraints. Trans. Assoc. Comput. Linguist. 2017, 5, 309–324. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; He, T.; Benesty, M. XGBoost: eXtreme Gradient Boosting. R package version 0.71-2. 1 August 2015. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar] [CrossRef] [Green Version]
- Sulzmann, J.-N.; Fürnkranz, J.; Hüllermeier, E. On Pairwise Naive Bayes Classifiers. Lect. Notes Comput. Sci. 2007, 4701, 371–381. [Google Scholar] [CrossRef] [Green Version]
- Sarkar, A.; Chatterjee, S.; Das, W.; Datta, D. Text Classification using Support Vector Machine Anurag. Int. J. Eng. Sci. Invent. 2015, 8, 33–37. [Google Scholar]
- Wright, R.E. Logistic Regression. In Reading and Understanding Multivariate Statistics; Grimm, L.G., Yarnold, P.R., Eds.; American Psychological Association: Washington, DC, USA, 1995; pp. 217–244. [Google Scholar]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A Convolutional Neural Network for Modelling Sentences. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Baltimore, MD, USA, 23–25 June 2014; Volume 1. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S. The Vanishing Gradient Problem During Learning Recurrent Neural Nets and Problem Solutions. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 1998, 6, 107–116. [Google Scholar] [CrossRef] [Green Version]
- Schuster, M.; Paliwal, K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Bourgonje, P.; Moreno-Schneider, J.; Srivastava, A.; Rehm, G. Automatic Classification of Abusive Language and Personal Attacks in Various Forms of Online Communication. In Transactions on Computational Science XI; Springer Science and Business Media LLC: Cham, Switzerland, 2018; Volume 10713. [Google Scholar] [CrossRef] [Green Version]
- Bodapati, S.; Gella, S.; Bhattacharjee, K.; Al-Onaizan, Y. Neural Word Decomposition Models for Abusive Language Detection. In Proceedings of the Third Workshop on Abusive Language Online, Florence, Italy, 1 August 2019. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Extraction | ML Algorithms | Wikipedia Attack Dataset | Wikipedia Web Toxicity | ||||||
|---|---|---|---|---|---|---|---|---|---|
| A | P | R | F1 | A | P | R | F1 | ||
| Count Vectorization | XG Boost | 94.43 | 99.55 | 95.36 | 97.14 | 94.19 | 99.14 | 94.35 | 97.21 |
| Naïve Bayes | 95.44 | 99.73 | 96.27 | 96.92 | 95.62 | 98.48 | 96.9 | 98.14 | |
| SVM | 93.8 | 96.78 | 96.6 | 96.24 | 95.55 | 98.65 | 97.82 | 97.88 | |
| Logistic Regression | 94.55 | 98.34 | 96.11 | 96.79 | 96.49 | 99.39 | 97.55 | 97.73 | |
| TFIDF Word unigram | XG Boost | 95.23 | 99.51 | 95.6 | 97.86 | 94.33 | 99.95 | 94.46 | 96.82 |
| Naïve Bayes | 91.34 | 93.12 | 90.67 | 95.42 | 92.57 | 97.56 | 92.89 | 96.36 | |
| SVM | 95.02 | 98.94 | 96.41 | 98.12 | 96.29 | 99.93 | 97.59 | 98.77 | |
| Logistic Regression | 95.11 | 99.09 | 95.27 | 97.18 | 95.91 | 99.33 | 96.43 | 98.55 | |
| TFIDF Word bigram and trigram | XG Boost | 93.26 | 98.71 | 92.93 | 96.79 | 92.38 | 96.46 | 91.74 | 96.12 |
| Naïve Bayes | 89.11 | 92.12 | 89.25 | 94.77 | 91.81 | 98.12 | 90.91 | 95.54 | |
| SVM | 93.58 | 98.52 | 94.51 | 96.31 | 95.32 | 100 | 95.64 | 97.97 | |
| Logistic Regression | 91.6 | 94.55 | 91.76 | 96.13 | 93.24 | 97.17 | 92.93 | 96.82 | |
| TFIDF Char bigram and trigram | XG Boost | 93.87 | 99.97 | 94.22 | 96.86 | 95 | 99.74 | 94.62 | 97.8 |
| Naïve Bayes | 91.24 | 99.9 | 90.91 | 96.05 | 92.07 | 99.8 | 92.91 | 96.64 | |
| SVM | 81.01 | 98.92 | 69.05 | 81.24 | 96.21 | 99.35 | 97.34 | 98.32 | |
| Logistic Regression | 95.16 | 99.52 | 95.29 | 97.13 | 96.13 | 99.46 | 96.45 | 98.15 | |
| Feature Extraction | DL Algorithms | Wikipedia Attack Dataset | Wikipedia Web Toxicity | ||||||
|---|---|---|---|---|---|---|---|---|---|
| A | P | R | F1 | A | P | R | F1 | ||
| GloVe | CNN | 95.6 | 98.43 | 96.69 | 97.16 | 96.53 | 99.33 | 97.56 | 98.69 |
| LSTM | 95.08 | 98.53 | 96.85 | 97.61 | 96.44 | 99.14 | 97.24 | 98.34 | |
| GRU | 95.46 | 99.19 | 96.17 | 97.16 | 96.24 | 98.99 | 97.28 | 98.42 | |
| Bi-LSTM | 96.88 | 98.29 | 97.01 | 98.1 | 95.99 | 98.94 | 97.48 | 98.05 | |
| Bi-GRU | 96.98 | 99.22 | 96.74 | 98.56 | 96.01 | 99.45 | 96.8 | 98.63 | |
| CNN-BiLSTM | 95.36 | 98.88 | 96.84 | 98.03 | 96.74 | 99.63 | 96.78 | 98.07 | |
| Att-BiLSTM | 95.4 | 98.45 | 96.91 | 97.88 | 96.84 | 98.5 | 97.84 | 98.06 | |
| FastText | CNN | 94.94 | 98.21 | 96.54 | 97.6 | 96.36 | 99.19 | 97.87 | 97.88 |
| LSTM | 95.34 | 99.22 | 96.82 | 97.25 | 96.57 | 99.64 | 96.72 | 98.37 | |
| GRU | 95.8 | 98.72 | 96.72 | 98.23 | 95.93 | 98.42 | 97.17 | 98.55 | |
| Bi-LSTM | 95.93 | 98.81 | 96.58 | 98.15 | 96.51 | 99.18 | 97.34 | 98.07 | |
| Bi-GRU | 95.5 | 99.37 | 96.06 | 97.68 | 96.45 | 98.12 | 96.61 | 98.58 | |
| CNN-BiLSTM | 95.1 | 98.72 | 96.06 | 97.05 | 96.1 | 99.71 | 97.23 | 98.2 | |
| Att-BiLSTM | 95.01 | 99.12 | 96.51 | 97.81 | 96.6 | 99.18 | 97.06 | 98.65 | |
| Paragram | CNN | 95.25 | 98.2 | 97.36 | 97.36 | 96.31 | 99.41 | 97.06 | 98.61 |
| LSTM | 95.32 | 98.28 | 96.51 | 98.01 | 96.18 | 99.09 | 96.82 | 97.81 | |
| GRU | 95.78 | 98.03 | 97.39 | 97.48 | 96.58 | 98.92 | 96.83 | 98.22 | |
| Bi-LSTM | 95.12 | 99.17 | 96.74 | 97.95 | 95.87 | 99.41 | 96.63 | 98.46 | |
| Bi-GRU | 95.88 | 98.66 | 97.6 | 97.82 | 96.65 | 99.92 | 97.27 | 98.43 | |
| CNN-BiLSTM | 94.94 | 97.76 | 96.63 | 97.64 | 96.53 | 99.35 | 97.31 | 98.34 | |
| Att-BiLSTM | 95.12 | 98.21 | 96.73 | 98.03 | 96.77 | 98.91 | 97.72 | 98.49 | |
| Dataset | Method | A | P | R | F1 |
|---|---|---|---|---|---|
| Wikipedia Attack Dataset | Bourgonje et al. [57] (Logistic Regression) | 80.90 | 79.36 | 80.97 | 79.74 |
| Bourgonje et al. [57] (Bayes Exp. Max) | 82.70 | 81.33 | 82.83 | 81.36 | |
| Bourgonje et al. [57] (Bayes) | 83.11 | 81.78 | 83.14 | 81.58 | |
| Agrawal and Awekar [27] (CNN) | 92.91 | 92.09 | 83.78 | 88.63 | |
| Bodapati et al. [58] (BERT) | 95.34 | 92.61 | 93.57 | 95.70 | |
| Our Approach (Bi-GRU with GloVe) | 96.98 | 99.22 | 96.74 | 98.56 | |
| Wikipedia Web Toxicity Dataset | Bourgonje et al. [57] (Logistic Regression) | 80.42 | 78.91 | 80.46 | 79.23 |
| Bourgonje et al. [57] (Bayes Exp. Max) | 82.10 | 80.60 | 81.87 | 80.57 | |
| Bourgonje et al. [57] (Bayes) | 82.19 | 80.68 | 82.01 | 80.60 | |
| Agrawal and Awekar [27] (CNN) | 93.52 | 92.79 | 88.67 | 91.56 | |
| Bodapati et al. [58] (BERT) | 95.69 | 92.71 | 95.11 | 96.82 | |
| Our Approach (Bi-GRU with GloVe) | 96.01 | 99.45 | 96.8 | 98.63 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Raj, C.; Agarwal, A.; Bharathy, G.; Narayan, B.; Prasad, M. Cyberbullying Detection: Hybrid Models Based on Machine Learning and Natural Language Processing Techniques. Electronics 2021, 10, 2810. https://doi.org/10.3390/electronics10222810
Raj C, Agarwal A, Bharathy G, Narayan B, Prasad M. Cyberbullying Detection: Hybrid Models Based on Machine Learning and Natural Language Processing Techniques. Electronics. 2021; 10(22):2810. https://doi.org/10.3390/electronics10222810
Chicago/Turabian StyleRaj, Chahat, Ayush Agarwal, Gnana Bharathy, Bhuva Narayan, and Mukesh Prasad. 2021. "Cyberbullying Detection: Hybrid Models Based on Machine Learning and Natural Language Processing Techniques" Electronics 10, no. 22: 2810. https://doi.org/10.3390/electronics10222810
APA StyleRaj, C., Agarwal, A., Bharathy, G., Narayan, B., & Prasad, M. (2021). Cyberbullying Detection: Hybrid Models Based on Machine Learning and Natural Language Processing Techniques. Electronics, 10(22), 2810. https://doi.org/10.3390/electronics10222810