
DCRN: An Optimized Deep Convolutional Regression Network for Building Orientation Angle Estimation in High-Resolution Satellite Images


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
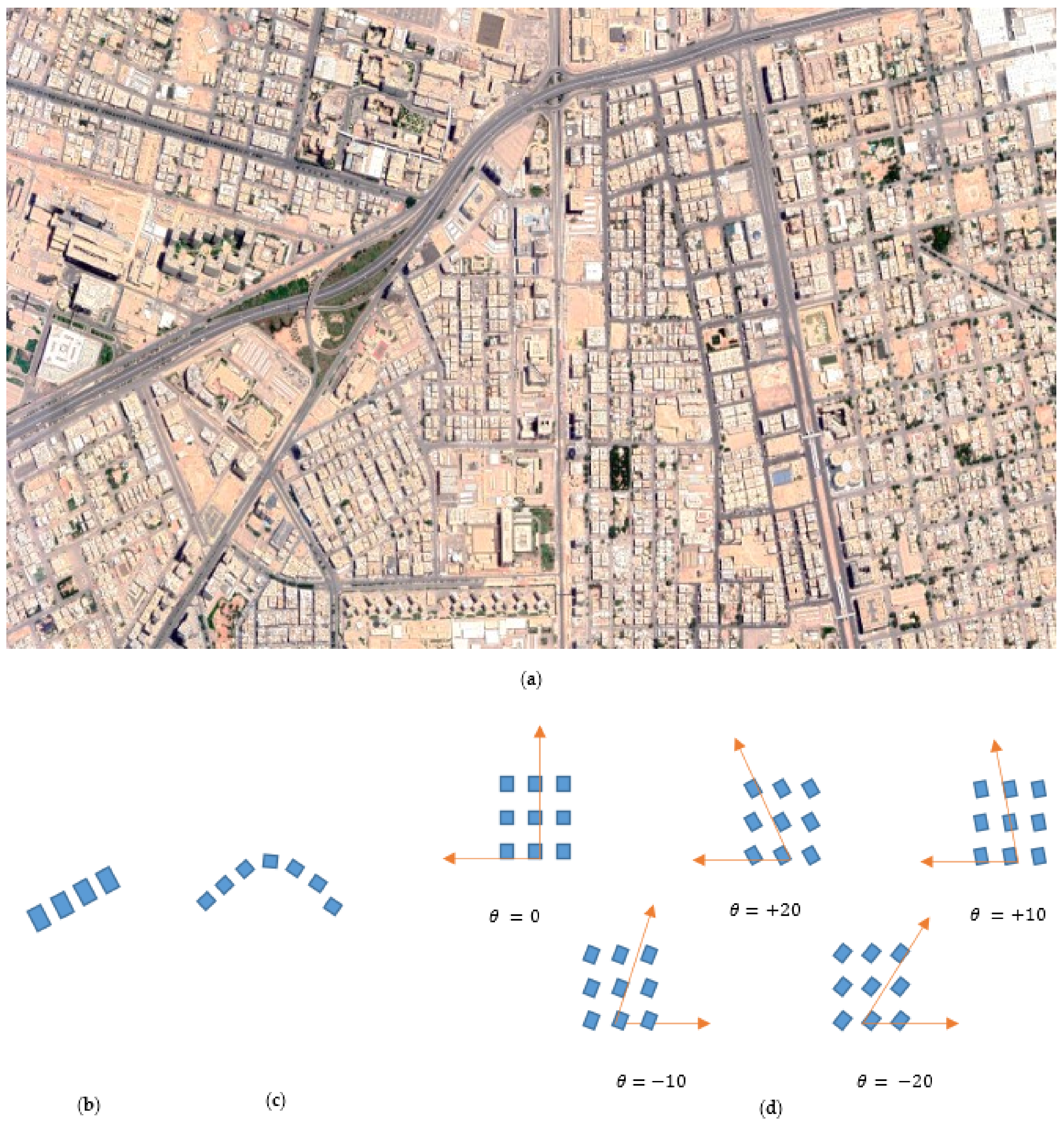
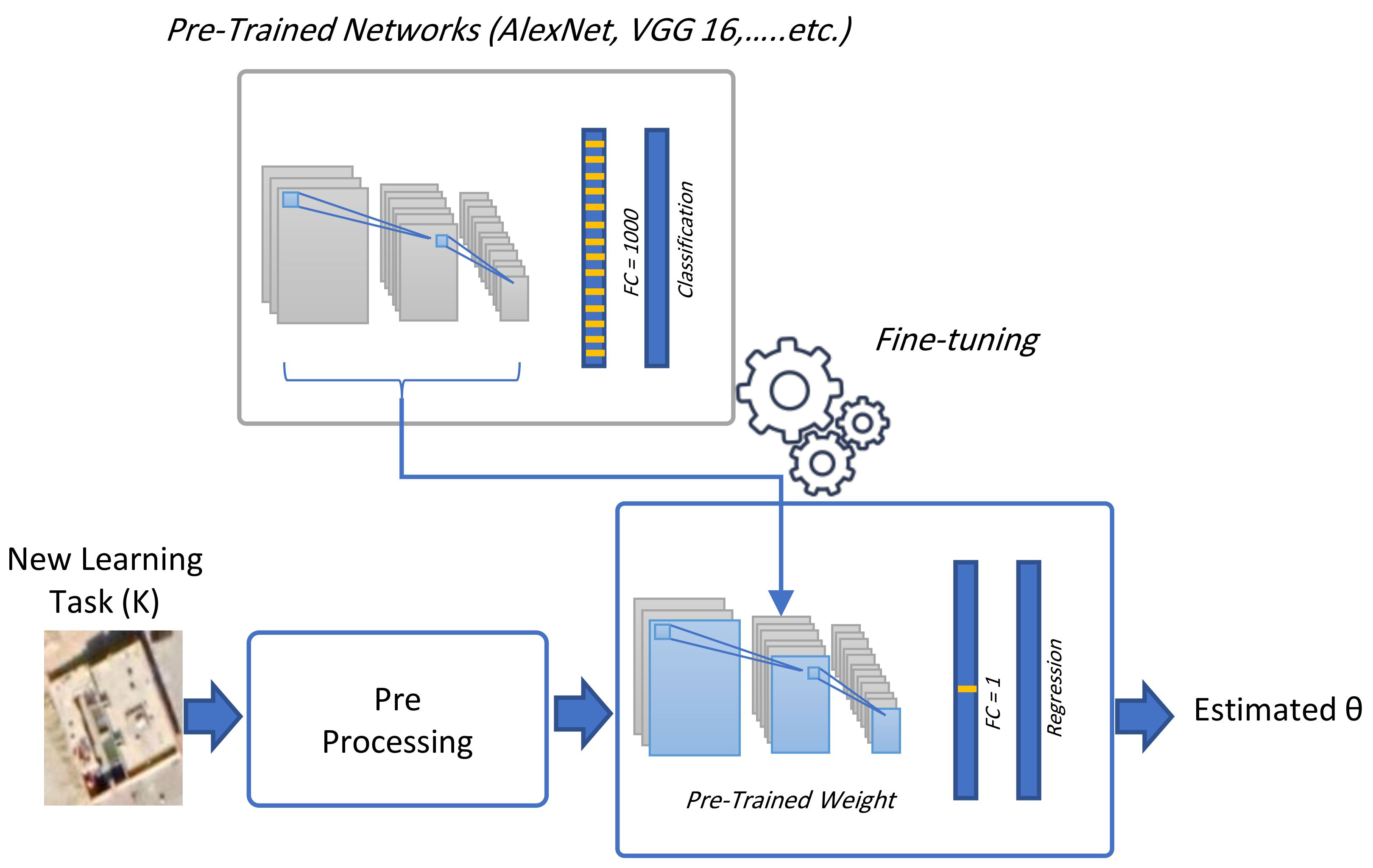
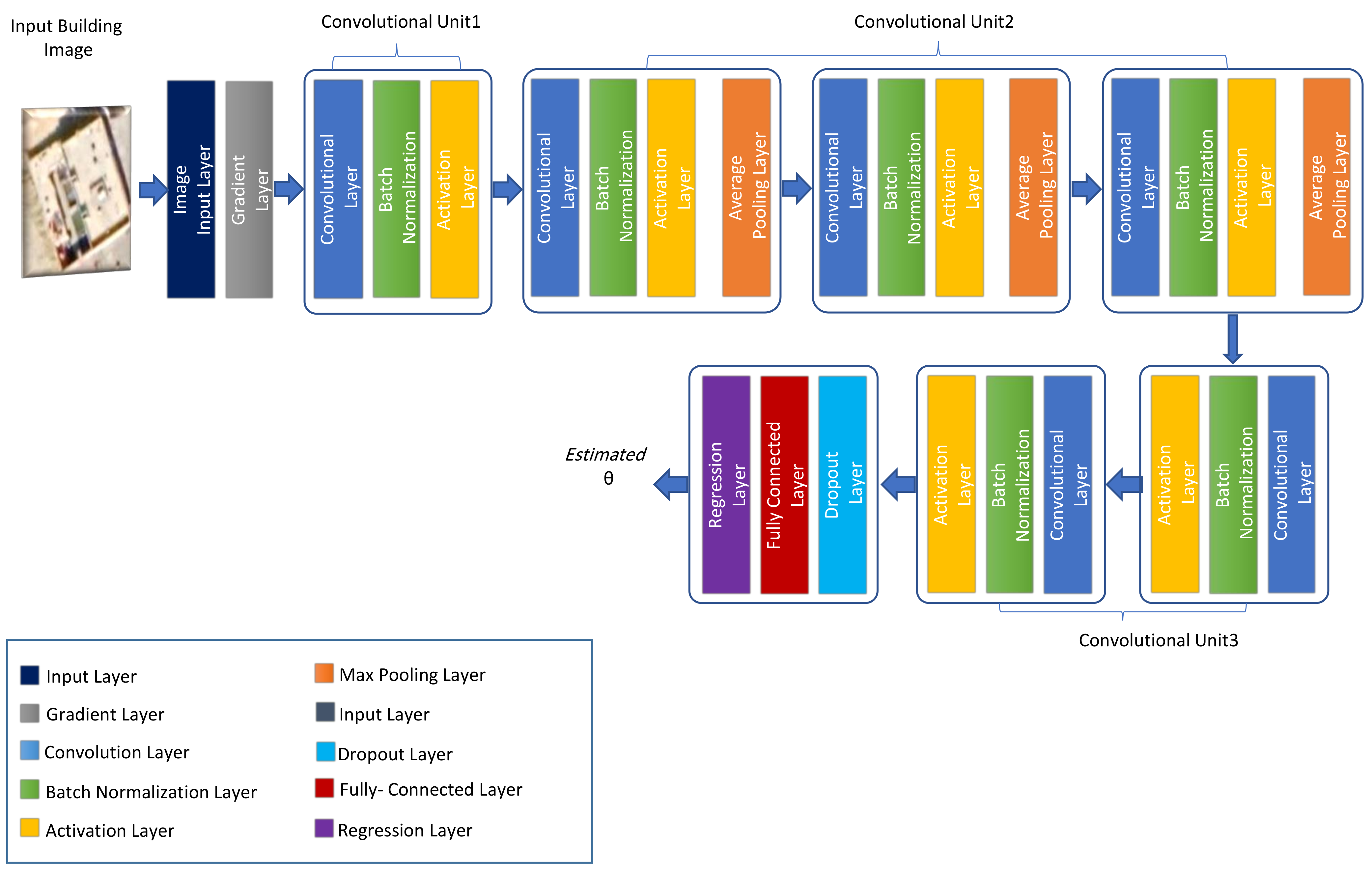
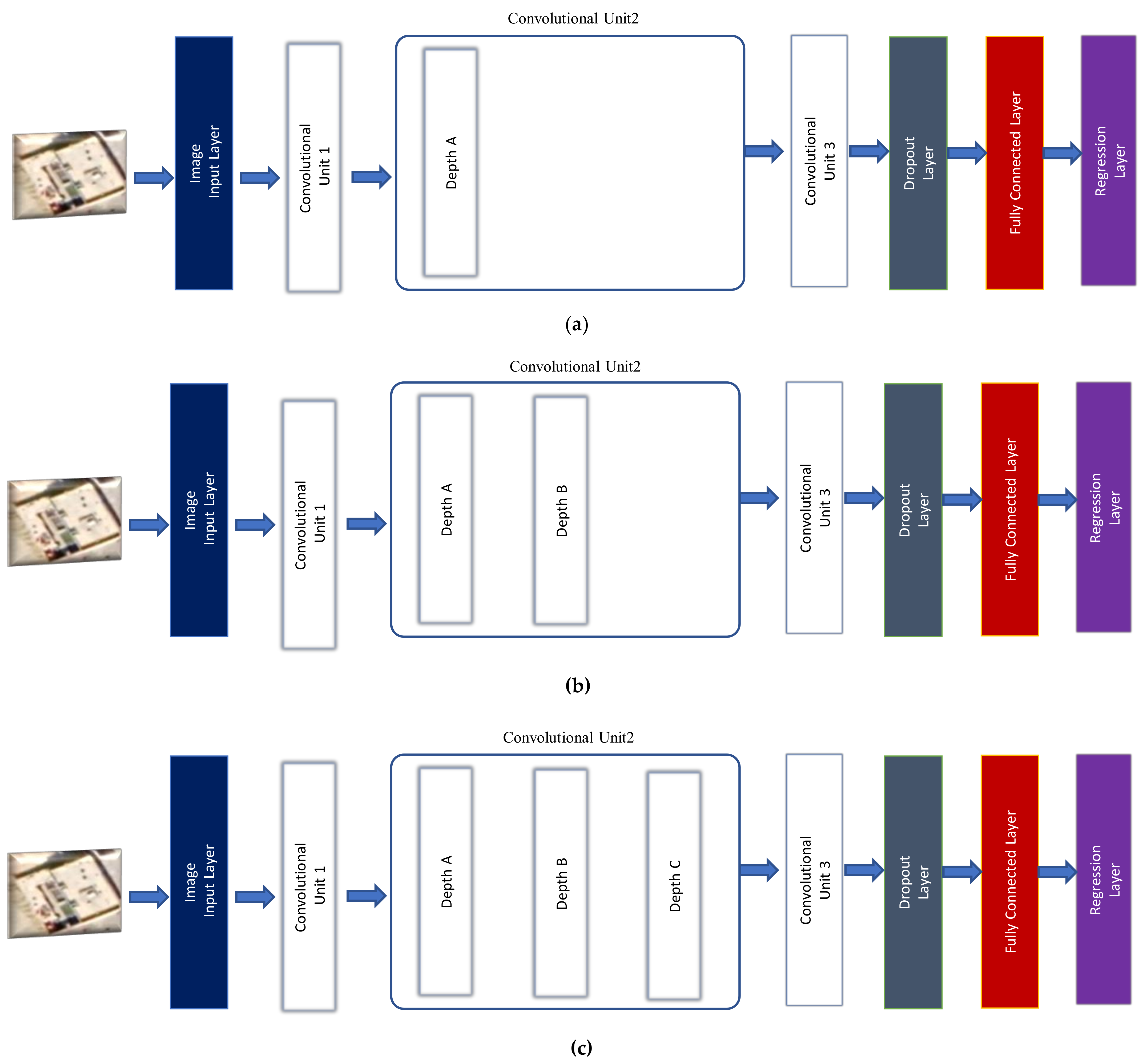
Abstract
Share and Cite
Shahin, A.I.; Almotairi, S. DCRN: An Optimized Deep Convolutional Regression Network for Building Orientation Angle Estimation in High-Resolution Satellite Images. Electronics 2021, 10, 2970. https://doi.org/10.3390/electronics10232970
Shahin AI, Almotairi S. DCRN: An Optimized Deep Convolutional Regression Network for Building Orientation Angle Estimation in High-Resolution Satellite Images. Electronics. 2021; 10(23):2970. https://doi.org/10.3390/electronics10232970
Chicago/Turabian StyleShahin, Ahmed I., and Sultan Almotairi. 2021. "DCRN: An Optimized Deep Convolutional Regression Network for Building Orientation Angle Estimation in High-Resolution Satellite Images" Electronics 10, no. 23: 2970. https://doi.org/10.3390/electronics10232970
APA StyleShahin, A. I., & Almotairi, S. (2021). DCRN: An Optimized Deep Convolutional Regression Network for Building Orientation Angle Estimation in High-Resolution Satellite Images. Electronics, 10(23), 2970. https://doi.org/10.3390/electronics10232970