
A Continuous Semantic Embedding Method for Video Compact Representation


Abstract
:1. Introduction
- We propose a continuous video semantic embedding model to learn the actual distribution of video words. Our embedding could encode the context coherence of video semantics.
- We propose a well-designed discriminative negative sampling approach. We pay more attention to discriminating the confusing and convincing video semantics and utilize them for generating the compact video representation. Incorporating with the continuous semantic embedding model, our semantic embedding could encode both the context coherence and the discriminative degree of video semantics. Experimental results demonstrate that discriminative negative sampling helps emphasize the convincing clips in the embedding while weakening the influence of the confusing ones—which also helps to learn more appropriate video semantic embedding..
- We propose an aggregated distribution pooling method to capture the semantic distribution of kernel modes in videos and generate the final video representation. We validated our method on event detection and the mining of representative event parts.
2. Related Work
2.1. Action Recognition
2.2. Temporal Embedding
2.3. Event Understanding
2.4. Complex Event Detection
3. Our Approach
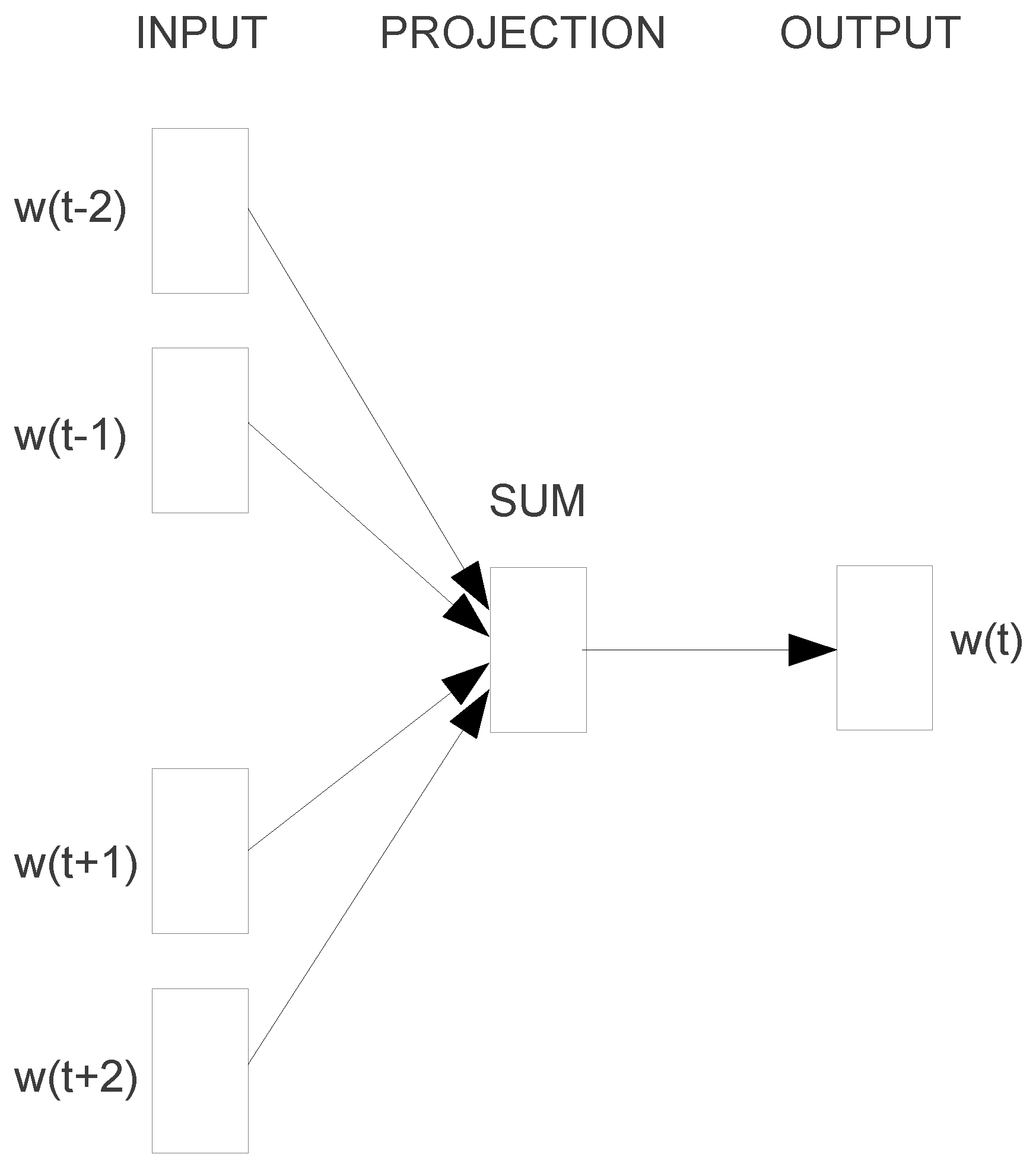
3.1. Continuous Video Semantic Embedding Model
3.1.1. Continuous Video Semantic Embedding
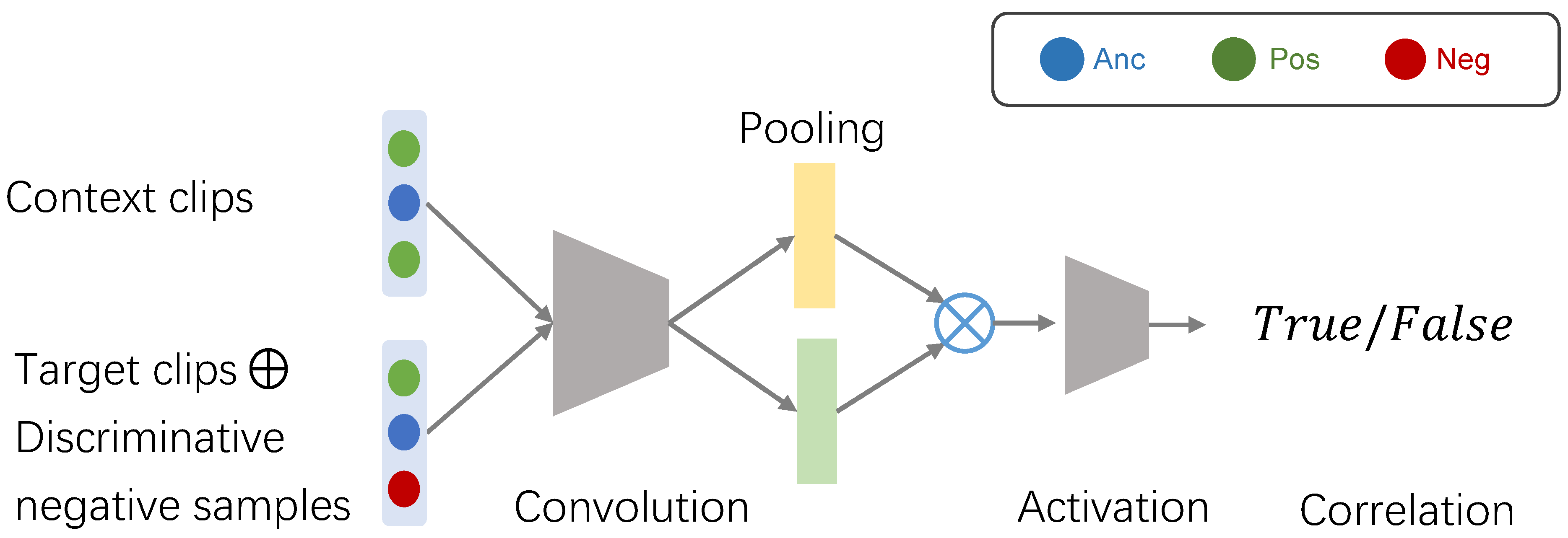
3.1.2. Discriminative Negative Sampling
3.2. Aggregated Distribution Pooling
4. Experiments
4.1. Datasets and Settings
4.1.1. TRECVID MED11 Dataset
4.1.2. CCV Dataset
4.1.3. Implementation Details
4.2. Representative Video Parts Mining
4.3. Event Detection
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Laptev, I. On space-time interest points. Int. J. Comput. Vis. 2005, 64, 107–123. [Google Scholar] [CrossRef]
- Wang, H.; Klaser, A.; Schmid, C.; Liu, C.L. Dense Trajectories and Motion Boundary Descriptors for Action Recognition. Int. J. Comput. Vis. 2013, 103, 60–79. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 5–10 December 2014; pp. 568–576. [Google Scholar]
- Xu, Z.; Yang, Y.; Hauptmann, A.G. A discriminative CNN video representation for event detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1798–1807. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Vondrick, C.; Pirsiavash, H.; Torralba, A. Generating videos with scene dynamics. Adv. Neural Inf. Process. Syst. 2016, 29, 613–621. [Google Scholar]
- Zhu, L.; Xu, Z.; Yang, Y. Bidirectional Multirate Reconstruction for Temporal Modeling in Videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2653–2662. [Google Scholar]
- Girdhar, R.; Ramanan, D.; Gupta, A.; Sivic, J.; Russell, B. ActionVLAD: Learning spatio-temporal aggregation for action classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? a new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6202–6211. [Google Scholar]
- Yue-Hei Ng, J.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond short snippets: Deep networks for video classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4694–4702. [Google Scholar]
- Gao, L.; Guo, Z.; Zhang, H.; Xu, X.; Shen, H.T. Video captioning with attention-based lstm and semantic consistency. IEEE Trans. Multimed. 2017, 19, 2045–2055. [Google Scholar] [CrossRef]
- Škrlj, B.; Kralj, J.; Lavrač, N.; Pollak, S. Towards robust text classification with semantics-aware recurrent neural architecture. Mach. Learn. Knowl. Extr. 2019, 1, 575–589. [Google Scholar] [CrossRef] [Green Version]
- Pan, P.; Xu, Z.; Yang, Y.; Wu, F.; Zhuang, Y. Hierarchical recurrent neural encoder for video representation with application to captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1029–1038. [Google Scholar]
- Jégou, H.; Douze, M.; Schmid, C.; Pérez, P. Aggregating local descriptors into a compact image representation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3304–3311. [Google Scholar]
- Yang, X.; Zhang, T.; Xu, C.; Hossain, M.S. Automatic visual concept learning for social event understanding. IEEE Trans. Multimed. 2015, 17, 346–358. [Google Scholar] [CrossRef]
- Ye, G.; Li, Y.; Xu, H.; Liu, D.; Chang, S.F. Eventnet: A large scale structured concept library for complex event detection in video. In Proceedings of the ACM Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 471–480. [Google Scholar]
- Zhang, X.; Yang, Y.; Zhang, Y.; Luan, H.; Li, J.; Zhang, H.; Chua, T.S. Enhancing video event recognition using automatically constructed semantic-visual knowledge base. IEEE Trans. Multimed. 2015, 17, 1562–1575. [Google Scholar] [CrossRef]
- Mazloom, M.; Li, X.; Snoek, C.G. Tagbook: A semantic video representation without supervision for event detection. IEEE Trans. Multimed. 2016, 18, 1378–1388. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.G.; Dai, Q.; Mei, T.; Rui, Y.; Chang, S.F. Super fast event recognition in internet videos. IEEE Trans. Multimed. 2015, 17, 1174–1186. [Google Scholar] [CrossRef]
- Mazloom, M.; Gavves, E.; Snoek, C.G. Conceptlets: Selective semantics for classifying video events. IEEE Trans. Multimed. 2014, 16, 2214–2228. [Google Scholar] [CrossRef]
- Phan, S.; Le, D.D.; Satoh, S. Multimedia event detection using event-driven multiple instance learning. In Proceedings of the ACM Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1255–1258. [Google Scholar]
- Xie, W.; Yao, H.; Sun, X.; Zhao, S.; Han, T.; Pang, C. Mining representative actions for actor identification. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing, Shanghai, China, 20–25 March 2016; pp. 1253–1257. [Google Scholar]
- Li, C.; Huang, Z.; Yang, Y.; Cao, J.; Sun, X.; Shen, H.T. Hierarchical Latent Concept Discovery for Video Event Detection. IEEE Trans. Image Process. 2017, 26, 2149–2162. [Google Scholar] [CrossRef]
- Xie, W.; Yao, H.; Sun, X.; Han, T.; Zhao, S.; Chua, T.S. Discovering Latent Discriminative Patterns for Multi-Mode Event Representation. IEEE Trans. Multimed. 2018, 21, 1425–1436. [Google Scholar] [CrossRef]
- Morin, F.; Bengio, Y. Hierarchical probabilistic neural network language model. In Proceedings of the Tenth International Workshop on Artificial Intelligence and Statistics, Bridgetown, Barbados, 6–8 January 2005; pp. 246–252. [Google Scholar]
- Ramanathan, V.; Tang, K.; Mori, G.; Fei-Fei, L. Learning temporal embeddings for complex video analysis. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4471–4479. [Google Scholar]
- Wu, C.; Zhang, J.; Savarese, S.; Saxena, A. Watch-n-patch: Unsupervised understanding of actions and relations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4362–4370. [Google Scholar]
- Xu, Z.; Qing, L.; Miao, J. Activity Auto-Completion: Predicting Human Activities From Partial Videos. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3191–3199. [Google Scholar]
- Li, C.; Cao, J.; Huang, Z.; Zhu, L.; Shen, H.T. Leveraging Weak Semantic Relevance for Complex Video Event Classification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3647–3656. [Google Scholar]
- Zhao, S.; Yao, H.; Gao, Y.; Ding, G.; Chua, T.S. Predicting Personalized Image Emotion Perceptions in Social Networks. IEEE Trans. Affect. Comput. 2017, 526–540. [Google Scholar] [CrossRef]
- Lai, K.T.; Yu, F.X.; Chen, M.S.; Chang, S.F. Video event detection by inferring temporal instance labels. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2243–2250. [Google Scholar]
- Li, Y.; Liu, C.; Ji, Y.; Gong, S.; Xu, H. Spatio-temporal deep residual network with hierarchical attentions for video event recognition. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2020, 16, 1–21. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Buch, S.; Escorcia, V.; Shen, C.; Ghanem, B.; Carlos Niebles, J. SST: Single-stream temporal action proposals. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2911–2920. [Google Scholar]
- Lin, T.; Liu, X.; Li, X.; Ding, E.; Wen, S. Bmn: Boundary-matching network for temporal action proposal generation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 3889–3898. [Google Scholar]
- Jiang, Y.G.; Ye, G.; Chang, S.F.; Ellis, D.P.W.; Loui, A.C. Consumer video understanding: A benchmark database and an evaluation of human and machine performance. In Proceedings of the ACM International Conference on Multimedia Retrieval, Trento, Italy, 17–20 April 2011. [Google Scholar]
- Huang, T.; Zhao, R.; Bi, L.; Zhang, D.; Lu, C. Neural Embedding Singular Value Decomposition for Collaborative Filtering. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Xie, W.; Yao, H.; Zhao, S.; Sun, X.; Han, T. Event patches: Mining effective parts for event detection and understanding. Signal Process. 2018, 149, 82–87. [Google Scholar] [CrossRef]
- Izadinia, H.; Shah, M. Recognizing complex events using large margin joint low-level event model. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 430–444. [Google Scholar]
- Ramanathan, V.; Liang, P.; Fei-Fei, L. Video event understanding using natural language descriptions. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 2–8 December 2013; pp. 905–912. [Google Scholar]
- Sun, C.; Nevatia, R. Active: Activity concept transitions in video event classification. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 2–8 December 2013; pp. 913–920. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | mAP (%) |
|---|---|
| CNN [4] | 74.7 |
| Multi-Mode [25] | 83.0 |
| Video Embedding | 74.4 |
| Video Embedding + DNS | 87.2 |
| Algorithms | mAP (%) |
|---|---|
| CNN [4] | 61.1 |
| Multi-Mode [25] | 68.9 |
| STDRN-HA [33] | 74.2 |
| Video Embedding | 61.8 |
| Video Embedding + DNS | 72.4 |
| Methods | mAP (%) |
|---|---|
| Joint+LL [40] | 66.1 |
| topic SR [41] | 66.4 |
| K-means-State [24] | 68.7 |
| HRNE [14] | 68.8 |
| fc7 [27] | 69.1 |
| InstanceInfer [32] | 70.3 |
| HMMFV [42] | 70.8 |
| Temporal Embedding [27] | 71.1 |
| Semantic-Visual [18] | 73.3 |
| CNN [4] | 74.7 |
| Latent Concepts [24] | 76.8 |
| Multi-Mode [25] | 83.0 |
| Ours | 87.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, T.; Qi, Y.; Zhu, S. A Continuous Semantic Embedding Method for Video Compact Representation. Electronics 2021, 10, 3106. https://doi.org/10.3390/electronics10243106
Han T, Qi Y, Zhu S. A Continuous Semantic Embedding Method for Video Compact Representation. Electronics. 2021; 10(24):3106. https://doi.org/10.3390/electronics10243106
Chicago/Turabian StyleHan, Tingting, Yuankai Qi, and Suguo Zhu. 2021. "A Continuous Semantic Embedding Method for Video Compact Representation" Electronics 10, no. 24: 3106. https://doi.org/10.3390/electronics10243106