
A Complexity Reduction Method for VVC Intra Prediction Based on Statistical Analysis and SAE-CNN


Abstract
:1. Introduction
2. Related Works
2.1. Methods for Former Standards
2.2. Approaches for VVC
2.3. Motivation
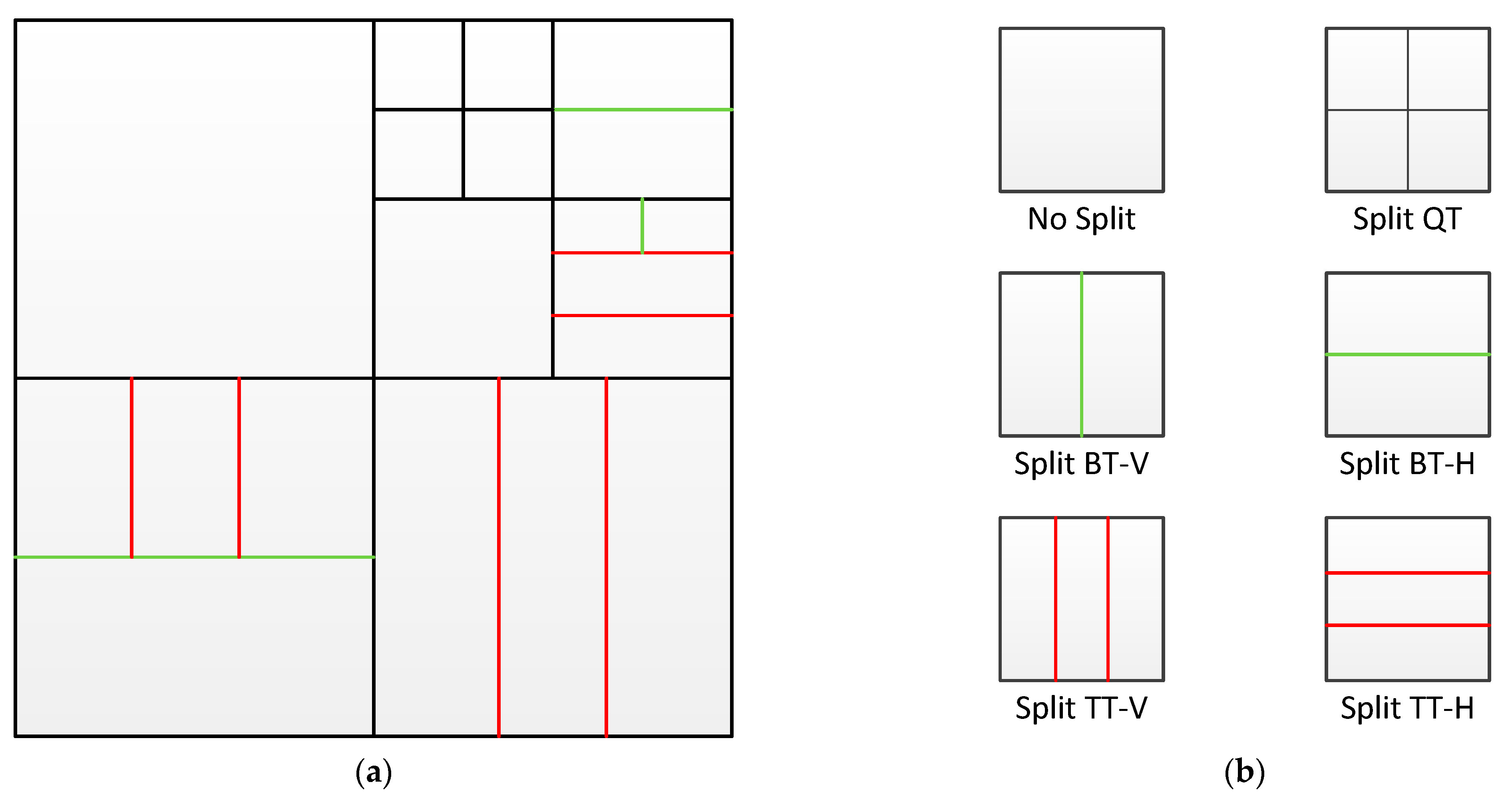
3. Proposed Method
3.1. Pre-Decision Algorithm
3.2. SAE-CNN Architecture
3.3. SAE-CNN Training
4. Experimental Results
4.1. Experimental Setup
4.2. Results and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ouahabi, A. Signal and Image Multiresolution Analysis; ISTE-Wiley: Hoboken, NJ, USA, 2013. [Google Scholar]
- Ouahabi, A. A review of wavelet denoising in medical imaging. In Proceedings of the 2013 8th International Workshop on Systems, Signal Processing and their Applications (WoSSPA), Algiers, Algeria, 12–15 May 2013; pp. 19–26. [Google Scholar]
- Ohm, J.; Sullivan, G.J.; Schwarz, H.; Tan, T.K.; Wiegand, T. Comparison of the Coding Efficiency of Video Coding Standards—Including High Efficiency Video Coding (HEVC). IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1669–1684. [Google Scholar] [CrossRef]
- Ferroukhi, M.; Ouahabi, A.; Attari, M.; Habchi, Y.; Taleb-Ahmed, A. Medical Video Coding Based on 2nd-Generation Wavelets: Performance Evaluation. Electronics 2019, 8, 88. [Google Scholar] [CrossRef] [Green Version]
- Bross, B. Versatile Video Coding (Draft 1). JVET-J1001. 2018. Available online: http://phenix.it-sudparis.eu/jvet/doc_end_user/current_document.php?id=3489 (accessed on 10 October 2021).
- Bross, B.; Chen, J.; Ohm, J.-R.; Sullivan, G.J.; Wang, Y.-K. Developments in International Video Coding Standardization After AVC, With an Overview of Versatile Video Coding (VVC). Proc. IEEE 2021, 109, 1463–1693. [Google Scholar] [CrossRef]
- Bross, B.; Chen, J.; Liu, S. Versatile Video Coding (Draft 7). JVET-P2001. 2019. Available online: http://phenix.it-sudparis.eu/jvet/doc_end_user/current_document.php?id=8857 (accessed on 10 October 2021).
- Song, X.D.; Fan, X.C.; Xiang, C.C.; Ye, Q.W.; Liu, L.Y.; Wang, Z.W.; He, X.J.; Yang, N.; Fang, G.F. A Novel Convolutional Neural Network Based Indoor Localization Framework with WiFi Fingerprinting. IEEE Access 2019, 7, 110698–110709. [Google Scholar] [CrossRef]
- Li, S.; Dai, W.; Zheng, Z.; Li, C.; Zou, J.; Xiong, H. Reversible Autoencoder: A CNN-Based Nonlinear Lifting Scheme for Image Reconstruction. IEEE Trans. Signal Process. 2021, 69, 3117–3131. [Google Scholar] [CrossRef]
- Ouahabi, A.; Taleb-Ahmed, A. Deep learning for real-time semantic segmentation: Application in ultrasound imaging. Pattern Recognit. Lett. 2021, 144, 27–34. [Google Scholar] [CrossRef]
- Heindel, A.; Haubner, T.; Kaup, A. Fast CU split decisions for HEVC inter coding using support vector machines. In Proceedings of the 2016 Picture Coding Symposium (PCS), Nurnberg, Germany, 4–7 December 2016; pp. 1–5. [Google Scholar]
- Zhang, Y.; Kwong, S.; Wang, X.; Yuan, H.; Pan, Z.; Xu, L. Machine Learning-Based Coding Unit Depth Decisions for Flexible Complexity Allocation in High Efficiency Video Coding. IEEE Trans. Image Process. 2015, 24, 2225–2238. [Google Scholar] [CrossRef] [PubMed]
- Xu, C.; Liu, P.; Wu, Y.; Jia, K.; Dong, W. A Fast CTU Depth Selection Algorithm for H.265/HEVC Based on Machine Learning. In Proceedings of the 2018 IEEE 3rd International Conference on Signal and Image Processing (ICSIP), Shenzhen, China, 13–15 July 2018; pp. 154–161. [Google Scholar]
- Jamali, M.; Coulombe, S.; Sadreazami, H. CU Size Decision for Low Complexity HEVC Intra Coding based on Deep Reinforcement Learning. In Proceedings of the 2020 IEEE 63rd International Midwest Symposium on Circuits and Systems (MWSCAS), Springfield, MA, USA, 9–12 August 2020; pp. 586–591. [Google Scholar]
- Kim, K.; Ro, W.W. Fast CU Depth Decision for HEVC Using Neural Networks. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 1462–1473. [Google Scholar] [CrossRef]
- Zhang, G.; Xiong, L.; Lian, X.; Zhou, W. A CNN-based Coding Unit Partition in HEVC for Video Processing. In Proceedings of the 2019 IEEE International Conference on Real-Time Computing and Robotics (RCAR), Irkutsk, Russia, 4–9 August 2019; pp. 273–276. [Google Scholar]
- Guo, X.; Wang, Q.; Jiang, J. A Lightweight CNN for Low-Complexity HEVC Intra Encoder. In Proceedings of the 2020 IEEE 15th International Conference on Solid-State & Integrated Circuit Technology (ICSICT), Kunming, China, 3–6 November 2020; pp. 1–3. [Google Scholar]
- Fu, T.; Zhang, H.; Mu, F.; Chen, H. Fast CU Partitioning Algorithm for H.266/VVC Intra-Frame Coding. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 55–60. [Google Scholar]
- Cui, J.; Zhang, T.; Gu, C.; Zhang, X.; Ma, S. Gradient-Based Early Termination of CU Partition in VVC Intra Coding. In Proceedings of the 2020 Data Compression Conference (DCC), Snowbird, UT, USA, 24–27 March 2020; pp. 103–112. [Google Scholar]
- Wu, G.; Huang, Y.; Zhu, C.; Song, L.; Zhang, W. SVM Based Fast CU Partitioning Algorithm for VVC Intra Coding. In Proceedings of the 2021 IEEE International Symposium on Circuits and Systems (ISCAS), Daegu, Korea, 22–28 May 2021; pp. 1–5. [Google Scholar]
- Tissier, A.; Hamidouche, W.; Vanne, J.; Galpin, F.; Menard, D. CNN Oriented Complexity Reduction of VVC Intra Encoder. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 3139–3143. [Google Scholar]
- Galpin, F.; Racapé, F.; Jaiswal, S.; Bordes, P.; Le Léannec, F.; François, E. CNN-Based Driving of Block Partitioning for Intra Slices Encoding. In Proceedings of the 2019 Data Compression Conference (DCC), Snowbird, UT, USA, 26–29 March 2019; pp. 162–171. [Google Scholar]
- Li, T.; Xu, M.; Tang, R.; Chen, Y.; Xing, Q. DeepQTMT: A Deep Learning Approach for Fast QTMT-Based CU Partition of Intra-Mode VVC. IEEE Trans. Image Process. 2021, 30, 5377–5390. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Wang, S.; Zhang, X.; Wang, S.; Ma, S. Fast QTBT Partitioning Decision for Interframe Coding with Convolution Neural Network. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 2550–2554. [Google Scholar]
- Tang, G.; Jing, M.; Zeng, X.; Fan, Y. Adaptive CU Split Decision with Pooling-variable CNN for VVC Intra Encoding. In Proceedings of the 2019 IEEE Visual Communications and Image Processing (VCIP), Sydney, Australia, 1–4 December 2019; pp. 1–4. [Google Scholar]
- Huang, Y.-H.; Chen, J.-J.; Tsai, Y.-H. Speed Up H.266/QTMT Intra-Coding Based on Predictions of ResNet and Random Forest Classifier. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 10–12 January 2021; pp. 1–6. [Google Scholar]
- Fu, P.-C.; Yen, C.-C.; Yang, N.-C.; Wang, J.-S. Two-phase Scheme for Trimming QTMT CU Partition using Multi-branch Convolutional Neural Networks. In Proceedings of the 2021 IEEE 3rd International Conference on Artificial Intelligence Circuits and Systems (AICAS), Washington, DC, USA, 6–9 June 2021; pp. 1–6. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Structure |
|---|---|
| Input | Residual Block: Wide × Height × 1 |
| Conv1 | Filter: 5 × 5 × 64, Stride:1, Pad:2, ReLU |
| Shape-adaptive Pool1 | Max, Size X = (Wide ≥ 32) + 1, Size Y = (Height ≥ 32) + 1 |
| Conv2 | Filter: 5 × 5 × 64, Stride:1, Pad:2, ReLU |
| Shape-adaptive Pool2 | Max, Size X = (Wide ≥ 32) + 1, Size Y = (Height ≥ 32) + 1 |
| Conv3 | Filter: 3 × 3 × 64, Stride:1, Pad:1, ReLU |
| Conv4 | Filter: 3 × 3 × 64, Stride:1, Pad:1, ReLU |
| Pool3 | Max, Size X = 2, Size Y = 2 |
| FC | 64, include: QP, Wide, Height; ReLU |
| SoftMax | 2 |
| Sequence | Class | Resolution |
|---|---|---|
| DaylightRoad2 | A | 3810 × 2160 |
| ArenaOfValor | B | 1920 × 1080 |
| BasketballDrillText | C | 832 × 480 |
| BasketballPass | D | 416 × 240 |
| Vidyo3 | E | 1280 × 720 |
| Class | Sequence | Ref. [23], VTM7.0 | Ref. [25], VTM5.0 | Proposed Algorithm | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BD-BR (%) | ∆T (%) | ∆T/BD-BR | BD-BR (%) | ∆T (%) | ∆T/BD-BR | BD-BR (%) | ∆T (%) | ∆T/BD-BR | ||
| A | Campfire | 2.91 | 59.87 | 20.57 | 1.05 | 34.96 | 33.29 | 1.01 | 35.78 | 35.43 |
| CatRobot1 | 3.28 | 55.99 | 17.07 | / | / | / | 0.96 | 36.98 | 38.52 | |
| B | BQTerrace | 1.79 | 56.94 | 31.81 | 0.95 | 34.50 | 36.31 | 0.89 | 36.79 | 41.34 |
| Cactus | 1.86 | 60.56 | 32.56 | / | / | / | 0.87 | 34.12 | 39.22 | |
| MarketPlace | 1.28 | 58.22 | 45.48 | / | / | / | 0.82 | 37.74 | 46.02 | |
| Kimono | / | / | / | 0.87 | 33.32 | 38.29 | 0.71 | 34.59 | 48.71 | |
| C | BasketballDrill | 2.98 | 52.62 | 17.66 | 1.30 | 33.39 | 25.68 | 1.10 | 35.03 | 31.84 |
| PartyScene | 1.16 | 58.94 | 50.81 | 0.55 | 31.10 | 56.54 | 0.67 | 34.55 | 51.57 | |
| RaceHorsesC | 1.61 | 57.89 | 35.96 | 0.37 | 23.63 | 63.86 | 0.75 | 33.89 | 45.19 | |
| D | BlowingBubbles | 1.57 | 53.40 | 34.01 | 0.95 | 33.90 | 35.68 | 0.97 | 35.86 | 36.97 |
| BQSquare | 1.33 | 55.16 | 41.47 | 0.68 | 30.73 | 45.19 | 0.71 | 32.35 | 45.56 | |
| RaceHorses | 1.88 | 53.34 | 28.37 | 0.71 | 31.79 | 44.77 | 0.76 | 33.14 | 43.61 | |
| E | FourPeople | 2.20 | 59.74 | 27.15 | 1.38 | 38.01 | 27.54 | 0.99 | 38.40 | 38.79 |
| KristenAndSara | 2.75 | 60.01 | 21.82 | 1.61 | 34.84 | 21.63 | 1.08 | 35.84 | 33.19 | |
| Video 1 | / | / | / | 1.63 | 38.73 | 23.76 | 1.32 | 38.93 | 29.49 | |
| Average | 2.05 | 57.13 | 27.87 | 1.00 | 33.24 | 33.24 | 0.91 | 35.60 | 39.12 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, J.; Dai, P.; Zhang, Q. A Complexity Reduction Method for VVC Intra Prediction Based on Statistical Analysis and SAE-CNN. Electronics 2021, 10, 3112. https://doi.org/10.3390/electronics10243112
Zhao J, Dai P, Zhang Q. A Complexity Reduction Method for VVC Intra Prediction Based on Statistical Analysis and SAE-CNN. Electronics. 2021; 10(24):3112. https://doi.org/10.3390/electronics10243112
Chicago/Turabian StyleZhao, Jinchao, Pu Dai, and Qiuwen Zhang. 2021. "A Complexity Reduction Method for VVC Intra Prediction Based on Statistical Analysis and SAE-CNN" Electronics 10, no. 24: 3112. https://doi.org/10.3390/electronics10243112
APA StyleZhao, J., Dai, P., & Zhang, Q. (2021). A Complexity Reduction Method for VVC Intra Prediction Based on Statistical Analysis and SAE-CNN. Electronics, 10(24), 3112. https://doi.org/10.3390/electronics10243112