
Selected Genetic Algorithms for Vehicle Routing Problem Solving




Abstract
:1. Introduction
- First, we analyze the use of the GA along with other metaheuristic algorithms to solve the VRP. Here, a prototype modular and flexible general purpose GA is implemented.
- Second, we show the implementation of different GA operators that are modified to solve the VRP. Designing and running experiments enable determination of the best combination of genetic operators for solving the VPR.
- Third, we analyze the impact and participation of GA operators through simulations of the selected problem.
- Finally, experiments are conducted to find an optimal solution for a large-scale real-life instance of the VRP.
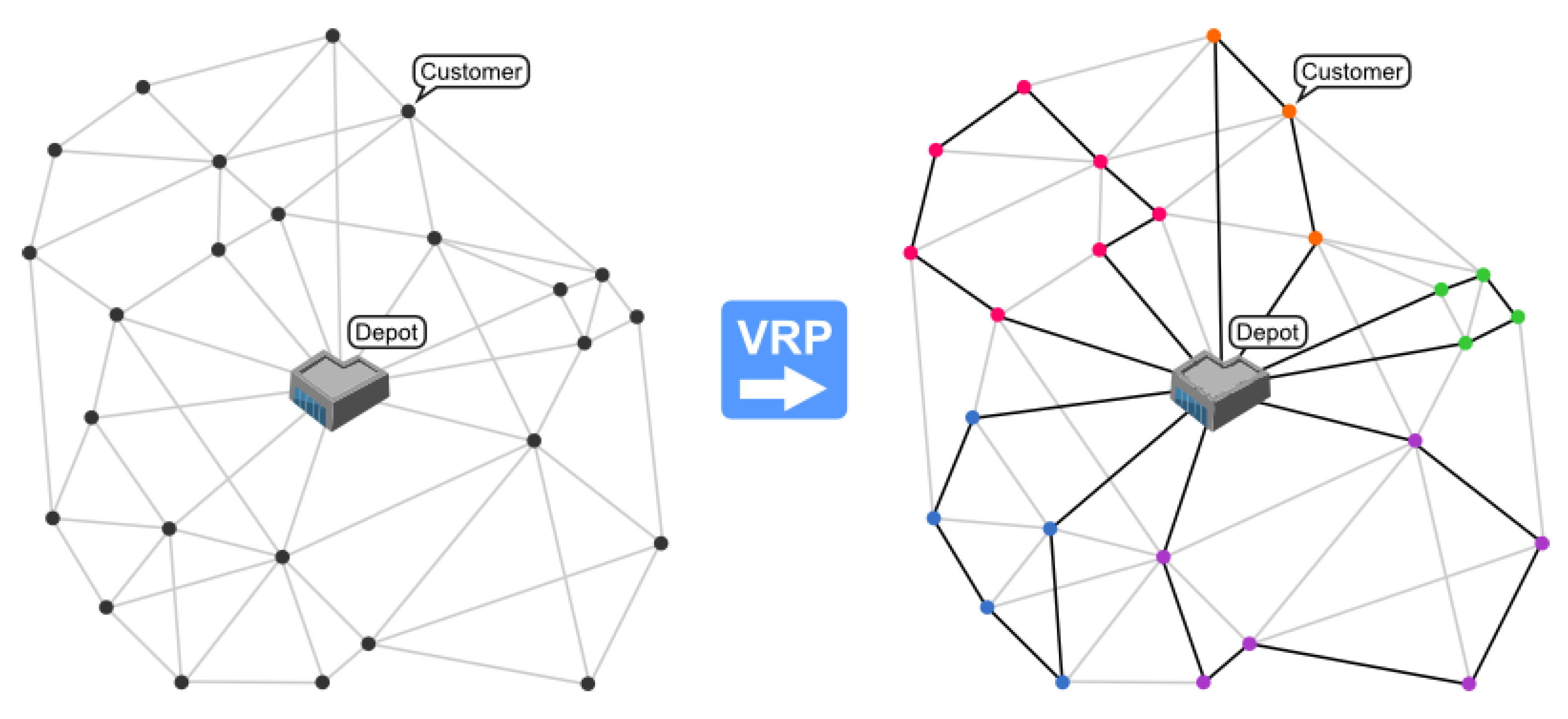
2. The Vehicle Routing Problem and Its Approach
2.1. Definition of a VRP
- Define n points that are delivery locations , define to represent the depot.
- Define a distance matrix that stores the distances between pairs of points .
- Define a delivery vector that describes how many goods have to be delivered to each point .
- Define each single truck capacity .
- If , define points as paired.
- If , define points as not paired.
- Derive the conditionEach point is connected with or at most one other point.
- By all previous definitions for every .
- Finally, define the problem as finding such values of that have a total distancewhere D is minimum, given all the conditions specified above.
2.2. Methods for Solving the VRP
- Simulated Annealing—a method which mimics the metallurgical process of cooling a batch of smithed ingot slowly. A value called temperature is defined that is being evolved during a single run, moving to a minimum. The temperature value is used to escape local minimal values; when the temperature rises, the algorithm selects a worse solution; it then moves away from a local minimum valley to search in the maximum possible search area. A modification known as Deterministic Annealing has produced good results in the VRP problem, where a decision to choose a worse solution is made, based on deterministic threshold calculations, rather than random number generator results [18,19]. In [20], they propose a violation of constraints for a penalty in an objective function.
- Ant algorithms—that is, based on observation of how ant colonies establish routes around their nest. Artificial ant objects are introduced into the VRP, and each moving ant leaves behind a pheromone trail that encourages other ants to move using the same route. There should at least as many ants, as there are customers, for the algorithm to work efficiently [11,21]. In [11], a nearest-neighbour heuristic with probabilistic rules was proposed. Two colonies that cooperate in updating the best solution are proposed to minimize the number of vehicles and total distance.
- Tabu Search—can be described as a metaheuristic that is instituted on another heuristic. The Tabu search explores space by moving from one solution to its neighbours. There may exist a situation where all neighbours are worse than the currently chosen solution, and to prevent the algorithm from coming back to a stronger position that was recently considered as best, the idea of forbidden, or tabu, moves is introduced. Such actions have the capacity of introducing a larger error, but also can gain a better solution, as declaring tabu moves encourages the algorithm to visit more solutions, thus expanding the search area [11]. In [22], Li and Lim present a new approach to insertion and an extended sweep heuristic to simulated annealing with elements of a tabu search.
- Genetic Algorithms—group of well known metaheuristics that mimic biological Darwinian evolution. Solutions are randomly chosen from a group of all possible solutions, and then by modifications, known as genetic operators, they are transformed to create the next generation of solutions. Evaluation is performed on every iteration of the algorithm (meaning, every time a generation is created) and stops after the initially set termination event (number of generations, the solution being good enough, etc.) [2,8,23,24]. In [25], they proposed an evolutionary search based on mutation—each offspring is optimized to improve the total distance by using a local search and route elimination.
- Particle Swarm Optimization, PSO—was designed by Kennedy and Eberhart [26]. This method imitates swarm behavior such as fish schooling and bird flocking. Bird can find food and share this information with others. Therefore, birds flock into a promising position or region for food and this information is shared, and other birds will likely move into this location. The PSO imitates bird behavior by using a population called swarm. Each member in the group is a particle. Each particle finds a solution to the problem. Thus, position sharing of experience or information takes place and the particles update their positions and search for the solution themselves [27]. Similar constraints were found in [28,29,30] even taking in consideration the weight and size of the cargo, as we see in [31].
2.3. Genetic Algorithm Comparison with Other Algorithms
- PSO and GA are both population-based stochastic optimization.
- Both algorithms start with a randomly generated population.
- Both algorithms have fitness values to evaluate the population.
- PSO and GA update the population and search for the optimum with random techniques.
- Both algorithms do not guarantee success.
- PSO does not use genetic operators, such as crossover and mutation. Particles update themselves with internal velocity.
- Particles also have memory, which is important to the algorithm.
- -
- Not “what” that best solution was, but “where” that best solution was.
- Particles do not die.
- The information sharing mechanism in PSO is significantly different.
- -
- The information moves from best to others, where the GA population moves together.
3. Genetic Algorithm and Its Modifications for the Vehicle Routing Problem
3.1. Representation of VRP Solution for Genetic Algorithm
3.2. Selection
- Roulette wheel selection (RWS)—chances of an individual being chosen are proportional to its fitness value; thus, selection may be imagined as a spinning roulette, where each individual takes an amount of space on the roulette wheel according to its fitness.
- Elitism selection (ES)—a certain percentage of the population, ordered by fitness, is always transferred to the next population. In that scenario, the algorithm makes sure that best so far known solutions would not be lost in the process of selection.
- Rank selection (RS)—similar to RWS, but each individual solution’s space on the roulette wheel is not proportional to its fitness, but to its rank in the list of all individuals, ordered by fitness.
- Stochastic universal sampling selection (SUSS)—instead of spinning the wheel of the roulette for a certain amount of times, spin it once. If selecting n individuals, there must exist n spaces on the wheel, and the chosen individual is copied n times to the next generation.
- Tournament selection (TS)—as many times as required, choose two individuals randomly, and let the more fit one be chosen.
3.3. Crossover Operators
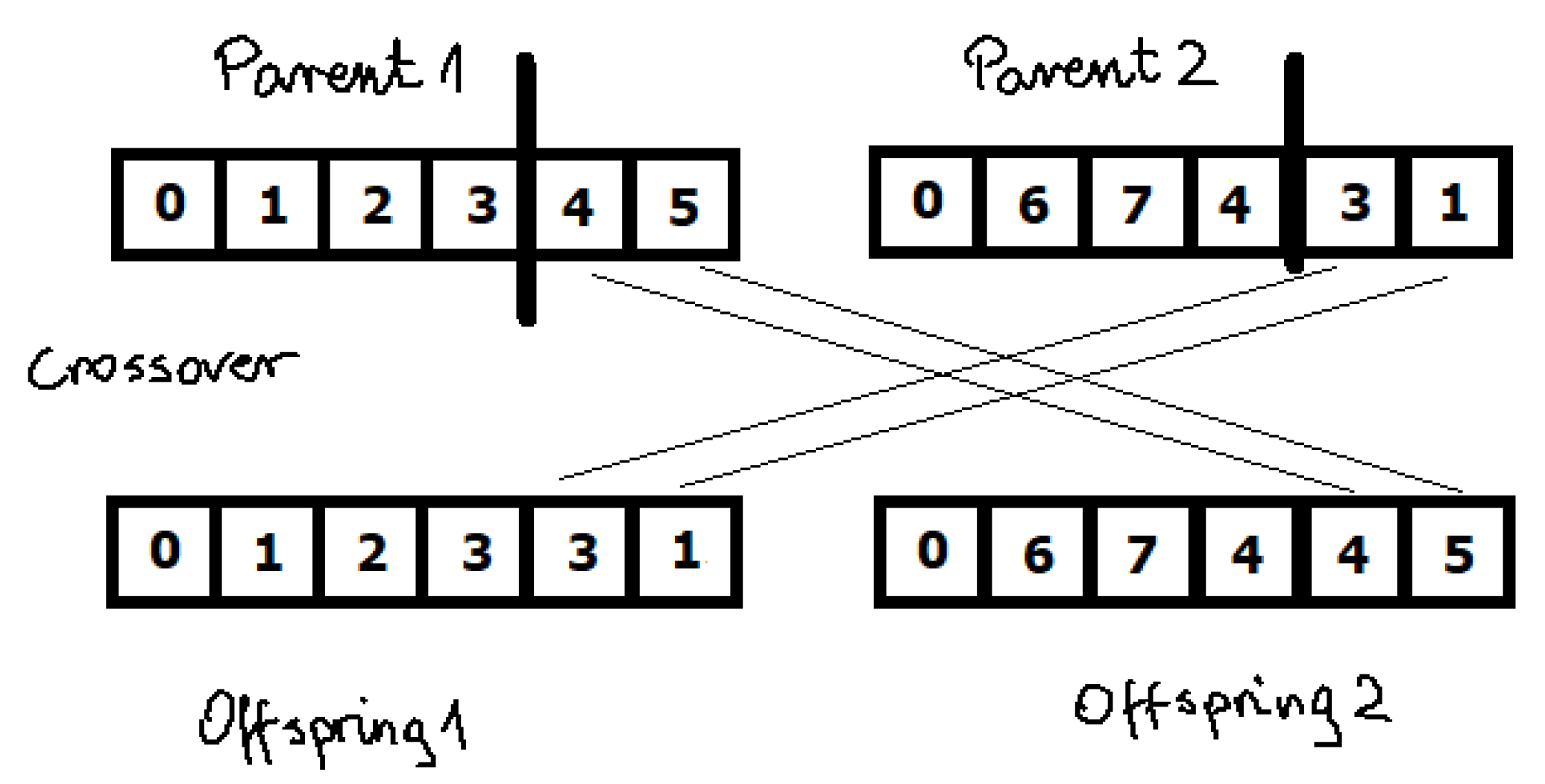
3.3.1. Order Crossover
- Label parents randomly as male and female.
- Take both parents and randomly choose two crossover points, the same for both of them.
- Copy the integers in between the crossover points, from male parent to child, keeping them at the same positions.
- Take the female parent, and starting from the gene after the second crossover point, iterate through all genes. If the end is met, start from the beginning.
- Take the child and starting from the gene after the second crossover point, copy the female parent gene that is considered in the current iteration, only if it is not present yet in the child’s chromosome. If the end is met, start from the beginning.
- The operation is finished if all empty spaces in the child chromosome are filled.
- Optionally, swap the roles of female and male parents, and repeat the whole process to produce a second offspring.
3.3.2. Partially Mapped Crossover
3.3.3. Edge Recombination Crossover
3.3.4. Cycle Crossover
3.4. Mutation Operator Changes in Regard to Integer Solution Representation
3.5. Related Works on Genetic Algorithm and the Vehicle Routing Problem
4. Implementation of Genetic Algorithm to Solve the Vehicle Routing Problem
- initial population size,
- amount of population that will be transferred to the next population,
- amount of population transferred, which is allowed to reproduce,
- amount of population transferred, which is allowed to mutate,
- number of generations after which the algorithm will terminate itself, and
- the class name representing the chromosome with its genetic operators.
4.1. Vehicle Routing Problem Test Instances
- Augerat Set A—described by the Augerat team in 1995 [56], set A consists of 27 examples that were generated randomly. Points are randomly spread across a 100 × 100 square, with demand in each point usually around 15. Demand is chosen in a uniform manner, and 10% of all coordinates have their demand tripled. Capacity for a single vehicle is always 100.
- Augerat Set B—described by the Augerat team in 1995 [56], set B consists of 23 examples, created in a way, such that coordinates are randomly spread but joined together in n clusters, and n is always larger than number of available vehicles. Demand is randomly distributed from 1 to 30, with 10% of all places to visit having their demand tripled.
- Augerat Set P—described by the Augerat team in 1995 [56] is a set of modified examples previously known in the literature.
- Christofides and Eilon Set E—described in the literature in 1969 [57], which contains 13 examples, with coordinates always spread uniformly in the search space.
- Fisher Set F—a set of three, real life problems, used by Fisher in their work [9]. Two are days of grocery deliveries from the Peterboro (Ontario terminal) of National Grocers Limited, and the third one is generated based on data obtained from Exxon associated with the delivery of tires, batteries, and accessories to gasoline service stations.
- TSPLIB converted Ulysses instances—two classic examples, converted to a VRP problem from TSPLIB, which is a library of traveling salesman problem examples. Both chosen ones were based on the mythical journey that Ulysses took, represented on a map.
4.2. Design of Experiments for the Genetic Algorithm in the Vehicle Routing Problem
4.2.1. All Combinations, Moderate Settings, Fast Experiment (AcMsF)
4.2.2. All Combinations, Moderate Settings, Long Experiment (AcMsL)
4.2.3. Crossover Domination Experiment (CD)
4.2.4. Mutation Domination Experiment (MD)
4.2.5. Best Combinations, Long, Large Examples Experiment (BcLBi)
5. Results of the Genetic Algorithm Implementation for the Vehicle Routing Problem
- The all combinations, moderate settings, fast experiment;
- The crossover domination experiment;
- The mutation domination experiment;
- And the best combinations, long, large examples experiment.
5.1. All Combinations, Moderate Settings, Fast Experiment
- Small examples:
- -
- Augerat, Set A, 32 deliveries, 5 vehicles,
- -
- Augerat, Set B, 32 deliveries, 5 vehicles,
- -
- Augerat, Set P, 35 deliveries, 5 vehicles,
- -
- Christophides and Eilon, Set E, 22 deliveries, 4 vehicles,
- -
- Fisher, Set F, 45 deliveries, 4 vehicles,
- -
- Ulysses, Set U, 16 deliveries, 3 vehicles,
- -
- Ulysses, Set U, 22 deliveries, 4 vehicles.
- Medium examples:
- -
- Augerat, Set A, 55 deliveries, 9 vehicles,
- -
- Augerat, Set B, 57 deliveries, 9 vehicles,
- -
- Augerat, Set P, 57 deliveries, 5 vehicles,
- -
- Christophides and Eilon, Set E, 51 deliveries, 5 vehicles,
- -
- Fisher, Set F, 72 deliveries, 4 vehicles.
- Large examples:
- -
- Augerat, Set A, 80 deliveries, 10 vehicles,
- -
- Augerat, Set B, 78 deliveries, 10 vehicles,
- -
- Augerat, Set P, 78 deliveries, 10 vehicles,
- -
- Christophides and Eilon, Set E, 101 deliveries, 14 vehicles,
- -
- Fisher, Set F, 135 deliveries, 7 vehicles.
5.1.1. Averaged Results for All Combinations
5.1.2. Graphical Representation of Results and Best Found Solutions
5.2. Crossover Domination Experiment
- Augerat, Set A, 45 deliveries, 7 vehicles,
- Augerat, Set A, 54 deliveries, 7 vehicles,
- Augerat, Set B, 45 deliveries, 6 vehicles,
- Augerat, Set B, 56 deliveries, 7 vehicles,
- Augerat, Set P, 45 deliveries, 6 vehicles,
- Augerat, Set P, 56 deliveries, 7 vehicles,
- Christophides and Eilon, Set E, 33 deliveries, 4 vehicles,
- Christophides and Eilon, Set E, 51 deliveries, 5 vehicles.
- alternating edges crossover with rank selection,
- alternating edges crossover with tournament selection,
- edge recombination crossover with tournament selection,
5.2.1. Averaged Results for Crossover Domination
5.2.2. Graphical Representation of Results and Best Found Solutions
5.3. Mutation Domination Experiment
5.3.1. Averaged Results for Mutation Domination
5.3.2. Graphical Representation of Results and Best Found Solutions
5.4. Comparison of Mutation and Crossover Domination
5.5. Best Combinations, Long, Large Examples Experiment
- Augerat, Set A, 80 deliveries, 10 vehicles,
- Augerat, Set B, 78 deliveries, 10 vehicles,
- Augerat, Set P, 78 deliveries, 10 vehicles,
- Christophides and Eilon, Set E, 101 deliveries, 14 vehicles,
- Fisher, Set F, 135 deliveries, 7 vehicles.
- alternating edges crossover with rank selection,
- alternating edges crossover with tournament selection,
- edge recombination crossover with tournament selection.
5.5.1. Averaged Results for Mutation Domination
5.5.2. Graphical Representation of Results and Best Found Solutions
6. Discussion and Conclusions
- Vertex-based crossovers provide higher entropy, therefore perform better in short runs.
- Edge-based crossovers perform better, when given enough time. relative to instance size.
- Selection method does not seem to impact final results very much.
- If any selection method were to be chosen, tournament would be the one, as it provides slightly better results than rest.
- The average solution is not optimal but not completely random.
- Better results were obtained in case of smaller examples.
- One thousand iterations is definitely not enough for the GA to even start producing non-random solutions for larger examples.
- Despite harsh conditions for the algorithm, it was still able to find a very optimal solution for one of the examples.
- Making crossover a dominating genetic operator provides reasonable results.
- Complete lack of mutation results in very bad individuals.
- In general, when the algorithm is run with enough computational resources, more dominant crossover provides better individuals, than more dominant best individuals’ copying.
- With tight constraints, crossover domination behaves as badly as more stable approaches.
- When crossover is dominant, at some point the algorithm starts to rapidly descend and find good representatives, but after that rapid inflation process, further improvement is slow.
- Making mutation a dominating genetic operator provides reasonable results.
- Mutation alone cannot provide results as well as a properly adjusted more stable run with edge crossover.
- Mutation behaves well, when the example has a uniform distribution of destinations.
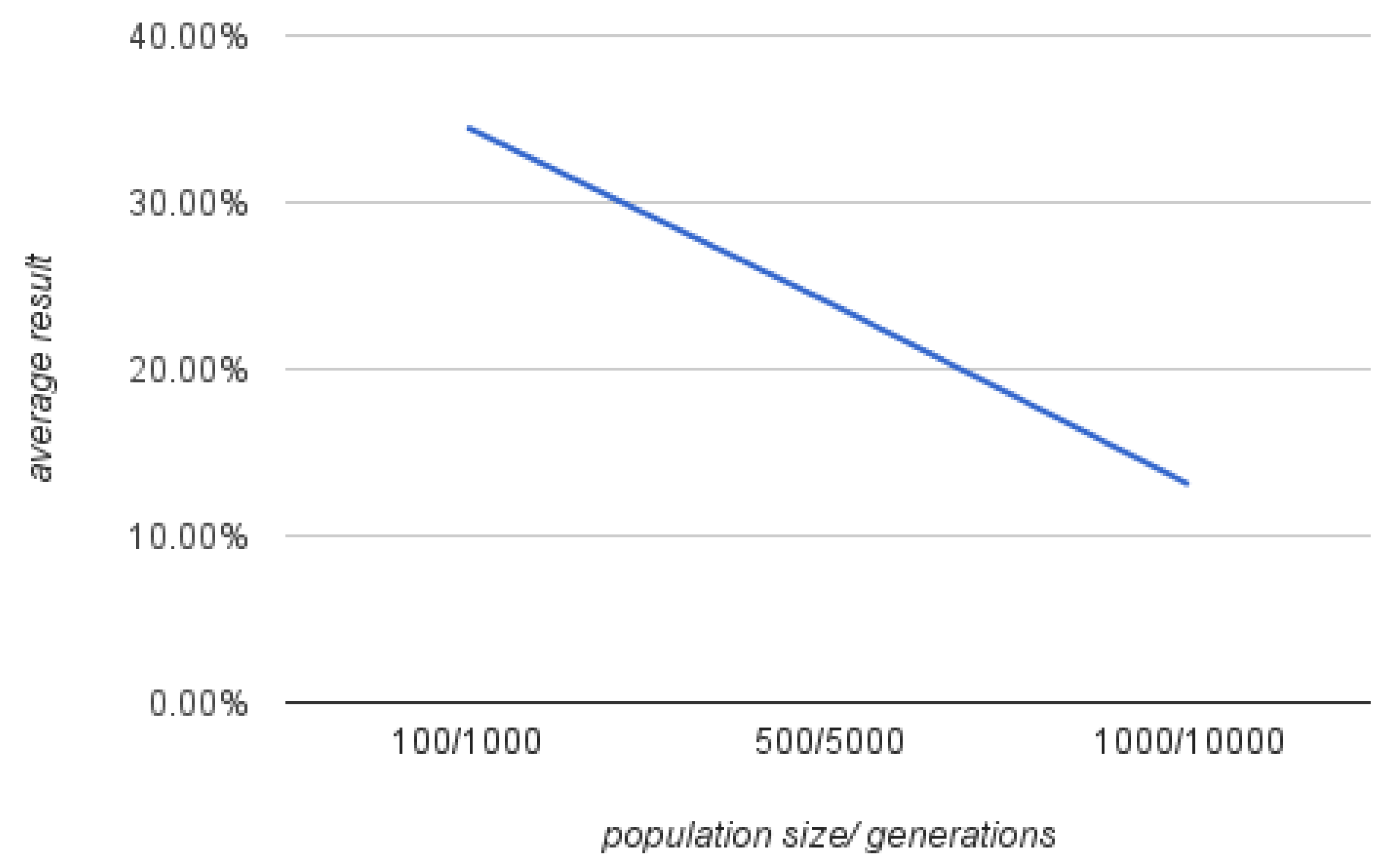
- On a smaller scale, assigning more computational resources results in a linear decrease in the average results.
- It is recommended to use slightly higher amounts of mutated offspring in the first iteration of the algorithm, as mutation is better than any type of crossover in spreading solutions across the search area.
- Reasonably chosen genetic algorithm parameters can provide enough stability to start reaching satisfying results even for large examples.
- Real life instances pose greater difficulties compared to randomly distributed ones.
- Given enough time and computational power, genetic algorithm implementation can produce competitive results even in the largest known test instances.
- Optimizations of paths in areas with higher density is easier and appears earlier in the whole optimization process than optimization of routes leading to further points of interest.
- Alternating edges crossover combined with rank selection is the most stable choice for genetic operators, capable of finding results comparable with the worldwide best-known ones.
- Simple cooperation with clustering methods for initial routes and then running independent genetic algorithms for each cluster in order to find proper routes on smaller scale,
- Hybrid usage of deterministic or heuristic methods incorporated to aid the genetic algorithm in finding better individuals,
- Exchanging parts of the genetic algorithm, especially mutation with, for example, local search methods, as mentioned in Section 2,
- Combining the work of the genetic algorithm with other metaheuristics, such as Tabu Search or Deterministic Annealing.
Author Contributions
Funding
Conflicts of Interest
References
- Dantzig, G.B.; Ramser, R.H. The Truck Dispatching Problem. Manag. Sci. 1959, 6, 80–91. [Google Scholar] [CrossRef]
- Alba, E.; Dorronsoro, B. Solving the Vehicle Routing Problem by Using Cellular Genetic Algorithms. In Lecture Notes in Computer Science, Proceedings of the Conference on Evolutionary Computation in Combinatorial Optimization, LNCS, Coimbra, Portugal, 5–7 April 2004; Springer: Berlin/Heidelberg, Germnay, 2004; Volume 3004, pp. 11–20. [Google Scholar]
- Vaira, G. Genetic Algorithm for Vehicle Routing Problem. Ph.D. Thesis, Vilnus University, Vilnius, Lithuania, 2014. [Google Scholar]
- Toth, P.; Vigo, D. The Vehicle Routing Problem. In Monographs on Discrete Mathematics and Applications; SIAM: Philadelphia, PA, USA, 2001. [Google Scholar]
- Bianchi, L. Notes on Dynamic Vehicle Routing—The State of Art. Technical Report; IDSIA-05-01; IDSIA: Lugano, Switzerland, 2000. [Google Scholar]
- Vehicle Routing Problem. Available online: http://neo.lcc.uma.es/vrp/vehicle-routing-problem/ (accessed on 30 September 2021).
- Tasan, A.S.; Gen, M. A genetic algorithm based approach to vehicle routing problem with simultaneous pick-up and deliveries. Comput. Ind. Eng. 2012, 62, 755–761. [Google Scholar] [CrossRef]
- Sharma, D.; Pal, S.; Sahay, A.; Kumar, P.; Agarwal, G.; Vignesh, K. Local Search Heuristics-Based Genetic Algorithm for Capacitated Vehicle Routing Problem. In Advances in Computational Methods in Manufacturing; Lecture Notes on Multidisciplinary Industrial Engineering; Narayanan, R., Joshi, S., Dixit, U., Eds.; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Fisher, M.L. Optimal Solution of Vehicle Routing Problems Using Minimum K-trees. Oper. Res. 1994, 42, 626–642. [Google Scholar] [CrossRef]
- Altinkemer, K.; Gavish, B. Parallel Savings Based Heuristic for the Delivery Problem. Oper. Res. 1991, 39, 456–469. [Google Scholar] [CrossRef]
- Gambardella, L.M.; Taillard, E.; Agazzi, G. MACS-VRPTW: A Multiple Ant Colony System for Vehicle Routing Problems with Time Windows. In New Ideas in Optimization; Corne, D., Dorigo, M., Glover, F., Eds.; McGraw-Hill Ltd.: Maidenhead, UK, 1999; pp. 63–76. [Google Scholar]
- Clarke, G.; Wright, J. Scheduling of vehicles from a central depot to a number of delivery points. Oper. Res. 1964, 12, 568–581. [Google Scholar] [CrossRef]
- Thompson, P.M.; Psaraftis, H.N. Cyclic Transfer Algorithms for the Multivehicle Routing and Scheduling Problems. Oper. Res. 1993, 41, 935–946. [Google Scholar] [CrossRef]
- Van Breedam, A. An Analysis of the Behaviour of Heuristics for the Vehicle Routing Problem for a Selection of Problems with Vehicle-Related, Customer-Related, and Time-Related Constraints. Ph.D. Thesis, University of Antwerp, Antwerp, Belgium, 1994. [Google Scholar]
- Kinderwater, G.A.P.; Savelsbergh, M.W.P. Vehicle Routing: Handling Edge Exchanges. In Local Search in Combinatorial Optimization; Aarts, E.H.L., Lenstra, J.K., Eds.; Wiley: Chichester, UK, 1997. [Google Scholar]
- Ryan, D.M.; Hjorring, C.; Glover, F. Extensions of the Petal Method for Vehicle Routing. J. Oper. Res. Soc. 1993, 44, 289–296. [Google Scholar] [CrossRef]
- Taillard, A.D. Parallel Iterative Search Methods for Vehicle Routing Problems. Networks 1993, 23, 661–673. [Google Scholar] [CrossRef]
- Dueck, G.; Scheurer, T. Threshold Accepting: A General Purpose Optimization Algorithm. J. Comput. Phys. 1990, 90, 161–175. [Google Scholar] [CrossRef]
- Dueck, G. New Optimization Heuristics: The Great Deluge Algorithm and the Record-To-Record Travel. J. Comput. Phys. 1993, 104, 86–92. [Google Scholar] [CrossRef]
- Chiang, W.-C.; Russell, R.A. Simulated annealing metaheuristics for the vehicle routing problem with time windows. Ann. Oper. Res. 1996, 63, 3–27. [Google Scholar] [CrossRef]
- Bullnheimer, B.; Strauss, R.F.H.A.C. Applying the Ant System to the Vehicle Routing Problem. In Proceedings of the 2nd International Conference on Metaheuristics, Versailles, France, 21–24 July 1997. [Google Scholar]
- Li, H.; Lim, A. Local search with annealing-like restarts to solve the VRPT. Eur. J. Oper. Res. 2003, 150, 115–127. [Google Scholar] [CrossRef]
- Yusuf, I.; Baba, M.S.; Iksan, N. Applied Genetic Algorithm for Solving Rich VRP. Appl. Artif. Intell. 2014, 28, 957–991. [Google Scholar] [CrossRef]
- De Oliveira da Costa, P.R.; Mauceri, S.; Carroll, P.; Pallonetto, F. A Genetic Algorithm for a Green Vehicle Routing Problem. Electron. Notes Discret. Math. 2018, 64, 65–74. [Google Scholar] [CrossRef] [Green Version]
- Repoussis, P.P.; Tarantilis, C.D.; Ioannou, G. Arc-guided evolutionary algorithm for the vehicle routing problem with time windows. IEEE Trans. Evol. Comput. 2009, 13, 624–647. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; IEEE: Perth, WA, Australia, 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Anantathanavit, M.; Munlin, M. Radius Particle Swarm Optimization. In Proceedings of the 2013 International Computer Science and Engineering Conference (ICSEC), Nakhonpathom, Thailand, 4–6 September 2013; pp. 126–130. [Google Scholar]
- Demirtas, Y.E.; Ozdemir, E.; Demirtas, U. A particle swarm optimization for the dynamic vehicle routing problem. In Proceedings of the 2015 6th International Conference on Modeling, Simulation, and Applied Optimization (ICMSAO), Istanbul, Turkey, 27–29 May 2015; pp. 1–5. [Google Scholar]
- Lagos, C.; Guerrero, G.; Cabrera, E.; Moltedo, A.; Johnson, F.; Paredes, F. An improved Particle Swarm Optimization Algorithm for the VRP with Simultaneous Pickup and Delivery and Time Windows. IEEE Latin Am. Trans. 2018, 16, 1732–1740. [Google Scholar] [CrossRef]
- Han, L.; Hou, H.; Yang, J.; Xie, J. E-commerce distribution vehicle routing optimization research based on genetic algorithm. In Proceedings of the 2016 International Conference on Logistics, Informatics and Service Sciences (LISS), Sydney, NSW, Australia, 24–27 July 2016; pp. 1–5. [Google Scholar]
- Hsieh, F.-S.; Huang, H.W. Decision support for cooperative carriers based on clustering requests and discrete particle swarm optimization. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016; pp. 762–769. [Google Scholar]
- Yang, C.; Guo, Z.; Liu, L. Comparison Study on Algorithms for Vehicle Routing Problem with Time Windows. In Proceedings of the 21st International Conference on Industrial Engineering and Engineering Management; Qi, E., Shen, J., Dou, R., Eds.; Atlantis Press: Paris, France, 2015; pp. 257–260. [Google Scholar]
- Arora, T.; Gigras, Y. A survey of comparison between various metaheuristic techniques for path planning problem. Int. J. Comput. Eng. Sci. 2013, 3, 62–66. [Google Scholar]
- Iswari, T.; Asih, A.M.S. Comparing genetic algorithm and particle swarm optimization for solving capacitated vehicle routing problem. Conf. Ser. Mater. Sci. Eng. 2018, 337, 012004. [Google Scholar] [CrossRef]
- Mitchell, M. An Introduction to Genetic Algorithms; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Holland, J.H. Adaptation in Neural and Artificial Systems; The University of Michigan Press: Ann Arbor, MI, USA, 1975. [Google Scholar]
- Alabsi, F.; Naoum, R. Comparison of Selection Methods and Crossover Operations using Steady State Genetic Based Intrusion Detection System. J. Emerg. Trends Comput. Inf. Sci. 2012, 3, 1053–1058. [Google Scholar]
- Gog, A.; Chira, C. Comparative analysis of recombination operators in genetic algorithms for the traveling salesman problem. In Hybrid Artificial Intelligent Systems, Proceedings of the 6th International Conference, Part II, LNCS 6679, Wroclaw, Poland, 23–25 May 2011; Corchado, E., Kurzynski, M., Wozniak, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 10–17. [Google Scholar]
- Hwang, H.-S. An improved model for vehicle routing problem with time constraint based on genetic algorithm. Comput. Ind. Eng. 2002, 42, 361–369. [Google Scholar] [CrossRef]
- Nazif, H.; Lee, L.S. Optimised crossover genetic algorithm for capacitated vehicle routing problem. Appl. Math. Model. 2012, 36, 2110–2117. [Google Scholar] [CrossRef]
- Kumar, V.; Panneerselvam, R. A Study of Crossover Operators for Genetic Algorithms to Solve VRP and its Variants and New Sinusoidal Motion Crossover Operator. Int. J. Comput. Intell. Res. 2017, 13, 1717–1733. [Google Scholar]
- Goldberg, D.E. Genetic Algorithms; Pearson Education: London, UK, 2006. [Google Scholar]
- Mulhenbein, H.; Gorges-Schleuter, M.; Kramer, O. Evolution algorithms in combinatorial optimization. Parallel Comput. 1988, 7, 65–85. [Google Scholar] [CrossRef]
- Fleurent, C.; Ferland, J.A. Genetic and hybrid algorithms for graph colouring. Ann. Oper. Res. 1996, 63, 437–461. [Google Scholar] [CrossRef]
- Thangiah, G.D. Vehicle routing with time window using genetic algorithms. In Application Handbook of Genetic Algorithm: New Frontiers; Chambers, L., Ed.; CRC Press: New York, NY, USA, 1995; pp. 253–377. [Google Scholar]
- Potvin, J.Y.; Bengio, S. The vehicle routing problem with time windows–Part II: Genetic search. INFORMS J. Comput. 1996, 8, 165–177. [Google Scholar] [CrossRef]
- Mulloorakam, A.T.; Nidhiry, N.M. Combined Objective Optimization for Vehicle Routing Using Genetic Algorithm. Mater. Today Proc. 2019, 11 Pt 3, 891–902. [Google Scholar] [CrossRef]
- Sitek, P.; Wikarek, J.; Rutczynska-Wdowiak, K.; Bocewicz, G.; Banaszak, Z. Optimization of capacitated vehicle routing problem with alternative delivery, pick-up and time windows: A modified hybrid approach. Neurocomputing 2021, 423, 670–678. [Google Scholar] [CrossRef]
- Euchi, J.; Sadok, A. Hybrid genetic-sweep algorithm to solve the vehicle routing problem with drones. Phys. Commun. 2021, 44, 101236. [Google Scholar] [CrossRef]
- Ongcunaruk, W.; Ongkunaruk, P.; Janssens, G.K. Genetic algorithm for a delivery problem with mixed time windows. Comput. Ind. Eng. 2021, 159, 107478. [Google Scholar] [CrossRef]
- Sbai, I.; Krichen, S. A real-time Decision Support System for Big Data Analytic: A case of Dynamic Vehicle Routing Problems. Procedia Comput. Sci. 2020, 176, 938–947. [Google Scholar] [CrossRef]
- He, J.; Tan, C.; Zhang, Y. Yard crane scheduling problem in a container terminal considering risk caused by uncertainty. Adv. Eng. Inform. 2019, 39, 14–24. [Google Scholar] [CrossRef]
- Vaira, G.; Kurasova, O. Genetic Algorithm for VRP with Constraints Based on Feasible Insertion. Informatica 2014, 25, 155–184. [Google Scholar] [CrossRef] [Green Version]
- Saxena, R.; Jain, M.; Malhotra, K.; Vasa, K.D. An Optimized OpenMP-Based Genetic Algorithm Solution to Vehicle Routing Problem. In Smart Computing Paradigms: New Progresses and Challenges; Advances in Intelligent Systems and Computing; Elci, A., Sa, P., Modi, C., Olague, G., Sahoo, M., Bakshi, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 767. [Google Scholar]
- Ji, X.; Yong, X. Application of Genetic Algorithm in Logistics Path Optimization. Acad. J. Comput. Inf. Sci. 2019, 2, 155–161. [Google Scholar]
- Augerat, P. Approche Polyedrale du Probleme de Tournees de Vehicules. Ph.D. Thesis, Institut National Polytechnique de Grenoble, Grenoble, France, 1995. [Google Scholar]
- Christofides, N.; Eilon, S. An algorithm for the vehicle routing dispatching problem. Oper. Res. Quaterly 1969, 20, 309–318. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment | Large Examples | Medium Examples | Small Examples | Total Instances | Combinations | Populations | Generations |
|---|---|---|---|---|---|---|---|
| AcMsF | 5 | 5 | 7 | 17 | 20 | 100 | 1000 |
| AcMsL | 5 | 5 | 7 | 17 | 20 | 500 | 10,000 |
| CD | 0 | 8 | 0 | 8 | 3 | 100, 500, 1000 | 1000, 5000, 10,000 |
| MD | 0 | 8 | 0 | 8 | 1 | 100, 500, 1000 | 1000, 5000, 10,000 |
| BcLBi | 5 | 0 | 0 | 5 | 3 | 10,000 | 25,000 |
| Elitism | Rank | Roulette | Tournament | |
|---|---|---|---|---|
| alternating_edges_crossover | 78.98% | 67.81% | 78.18% | 69.53% |
| cycle_crossover | 52.20% | 49.87% | 47.36% | 48.57% |
| edge_recombination_crossover | 79.53% | 80.18% | 82.40% | 77.13% |
| order_crossover | 49.31% | 50.12% | 50.78% | 45.76% |
| partially_mapped_crossover | 46.76% | 42.28% | 48.73% | 43.63% |
| Small | Medium | Large | All | |
|---|---|---|---|---|
| alternating_edges_crossover | 14.69% | 74.92% | 142.79% | 73.62% |
| cycle_crossover | 20.41% | 49.72% | 84.13% | 49.50% |
| edge_recombination_crossover | 12.88% | 82.42% | 157.00% | 79.81% |
| order_crossover | 20.26% | 50.68% | 81.43% | 48.99% |
| partially_mapped_crossover | 19.04% | 49.95% | 71.40% | 45.35% |
| Small | Medium | Large | All | |
|---|---|---|---|---|
| elitism | 16.85% | 63.87% | 111.74% | 61.36% |
| rank | 18.97% | 58.05% | 104.95% | 58.05% |
| roulette | 16.87% | 66.18% | 109.40% | 61.49% |
| tournament | 17.14% | 58.05% | 103.31% | 56.92% |
| Size | Generations | Average Distance |
|---|---|---|
| 100 | 1000 | 56.05% |
| 500 | 5000 | 17.48% |
| 1000 | 10000 | 12.57% |
| Crossover | Selection | Average Distance |
|---|---|---|
| alternating_edges | rank | 26.06% |
| alternating_edges | tournament | 27.28% |
| edge_recombination | tournament | 32.76% |
| Size | Generations | Average Distance |
|---|---|---|
| 100 | 1000 | 34.51% |
| 500 | 5000 | 24.01% |
| 1000 | 10,000 | 13.09% |
| Instance | Average Distance |
|---|---|
| set A | 18.34% |
| set B | 22.13% |
| set P | 24.17% |
| set E | 25.73% |
| Instance Type | Instance Size | Crossover | Selection | Result |
|---|---|---|---|---|
| set A | n80k10 | alternating_edges | rank | 12.16% |
| set A | n80k10 | alternating_edge | tournament | 12.52% |
| set A | n80k10 | edge_recombination | tournament | 18.76% |
| set B | n78k10 | alternating_edges | rank | 7.13% |
| set B | n78k10 | alternating_edges | tournament | 7.52% |
| set B | n78k10 | edge_recombination | tournament | 6.64% |
| set P | n78k10 | alternating_edges | rank | 7.33% |
| set P | n78k10 | alternating_edges | tournament | 13.48% |
| set P | n78k10 | edge_recombination | tournament | 31.17% |
| set E | n101k14 | alternating_edges | rank | 10.49% |
| set E | n101k14 | alternating_edges | tournament | 11.30% |
| set E | n101k14 | edge_recombination | tournament | 9.36% |
| set F | n135k7 | alternating_edges | rank | 25.51% |
| set F | n135k7 | alternating_edges | tournament | 26.18% |
| set F | n135k7 | edge_recombination | tournament | 21.96% |
| Crossover | Selection | Average Distance |
|---|---|---|
| alternating_edges | rank | 12.52% |
| alternating_edges | tournament | 14.20% |
| edge_recombination | tournament | 17.58% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ochelska-Mierzejewska, J.; Poniszewska-Marańda, A.; Marańda, W. Selected Genetic Algorithms for Vehicle Routing Problem Solving. Electronics 2021, 10, 3147. https://doi.org/10.3390/electronics10243147
Ochelska-Mierzejewska J, Poniszewska-Marańda A, Marańda W. Selected Genetic Algorithms for Vehicle Routing Problem Solving. Electronics. 2021; 10(24):3147. https://doi.org/10.3390/electronics10243147
Chicago/Turabian StyleOchelska-Mierzejewska, Joanna, Aneta Poniszewska-Marańda, and Witold Marańda. 2021. "Selected Genetic Algorithms for Vehicle Routing Problem Solving" Electronics 10, no. 24: 3147. https://doi.org/10.3390/electronics10243147
APA StyleOchelska-Mierzejewska, J., Poniszewska-Marańda, A., & Marańda, W. (2021). Selected Genetic Algorithms for Vehicle Routing Problem Solving. Electronics, 10(24), 3147. https://doi.org/10.3390/electronics10243147