1. Introduction
With the development of computer vision technologies, many visual tasks, such as object detection, semantic segmentation, and image classification, have been widely applied in many fields [
1,
2,
3]. Image classification is one of the most common and important visual tasks [
4,
5,
6], and a large number of models have been proposed based on traditional machine learning methods and deep learning methods [
7,
8,
9]. Recently, Convolutional Neural Network(CNN)-based image classification methods, such as AlexNet [
10], Visual Geometry Group 16 (VGG16) [
11], ResNet [
12], and Densely Connected Networks (DenseNet) [
13,
14], were widely applied in many visual tasks. Generally speaking, the networks with fewer layers usually extract the low-level visual features, while the networks with more layers can extract the more abstract visual features.
These primary research works focus on how to extract distinguishable local features to improve the image classification performance. In practice, however, there are large numbers of various types of objects, and many images suffer from poor illumination conditions, varying degrees of occlusion, similarities between objects, and so on. It is difficult to accurately classify all images by a consistent model, which presents great challenges to image classification [
15,
16]. For human beings, different types of objects are recognized through different processes, and people tend to quickly make judgments on easy-to-recognize objects based on their own subjective and objective cognition or prior knowledge. Meanwhile, people need further analysis and understanding for relatively difficult-to-recognize objects, and may further perform information abstraction and knowledge reasoning. Therefore, we contend that there are meaningful differences between images, and various models encounter various difficulties when attempting to accurately classify them. For example, images with appropriate lighting conditions are more easily classified correctly by the model than those with strong or weak lighting conditions; it is easier to perform disease screening on medical images for prominent lesions [
17,
18]. Therefore, we should select the appropriate networks according to the particular tasks. However, in most traditional CNN-based methods, all images need to be sent to the same classification process, which neglects the differences in discrepant classification difficulties for different images [
19,
20,
21].
Inspired by the mechanism of human cognition and the fact that different images present different levels of cognitive difficulty, we design a hierarchical integrated deep learning model named HCNN. The HCNN treats multiple CNNs as sub-networks and uses them progressively for feature extraction [
22,
23]. Specifically, the simple sub-networks are used to extract visual features for the images that are easy to classify accurately. Moreover, the complex sub-networks are used to extract the more abstract visual features, which are more suitable for the images which are more difficult to accurately classify. The final classification results are obtained by integrating the results of these sub-networks. Most existing models integrate multiple CNNs by fusing the high-level feature/decision of the CNNs to obtain a final result. Our HCNN selectively extracts the composite features of multiple sub-networks in different levels, which is more reasonable and complies with the process of human cognition.
Furthermore, the multi-class joint loss is designed to offer the features of the samples within the same category higher similarity, while the similarity between the features of different categories is made as low as possible. Gradient descent is used to train the entire network end-to-end. Finally, several experiments are conducted on a medical image dataset, two common image classification datasets (CIFAR-10, CIFAR-100 [
24]), and a chimpanzee dataset [
25]. The comparison experimental results show that the HCNN achieves superior performance to the existing related models. Moreover, ablation experiments prove that our model’s performance is superior to that of each single network and combinations of several sub-networks. In addition, it is worth noting that the HCNN has good scalability, since the types and combinations of CNN modules can be dynamically adjusted depending on the specific tasks involved.
The main contributions of this paper are as follows:
(1) We propose a progressive image classification model, named HCNN, which can progressively use its sub-network modules (with different depths of network layers) to extract different levels of visual features from images, while the classification results of different images are output by corresponding sub-network modules. In brief, the HCNN can use the sub-network modules with fewer network layers to quickly yield image classification results for the images that are easy to classify accurately, while the images that are difficult to classify accurately need to pass through more complex sub-network modules.
(2) A multi-class joint loss is designed to reduce the distance between the features of samples within the same category, while increasing the distance between the features of samples in different categories. In addition, gradient descent is used for the entire model training end-to-end.
(3) The performance and scalability of the HCNN are verified on four image classification datasets. The comparison and ablation experimental results show that the HCNN achieves significant performance improvements compared with existing models and combinations of several sub-networks.
This paper is organized as follows. In
Section 2, we review the related image classification models, ensemble learning models, and metric learning models and describes their relationships with our model. In
Section 3, we elaborate the basic framework and loss functions of HCNNs and give the model implementation process in the test stage. In
Section 4, we compare HCNNs and eight related methods on our own ultrasonic image dataset and three public image datasets. We also perform validation experiments to further analyze the HCNNs. The final conclusion is given in
Section 5.
2. Related Work
Image classification is one of the most important visual tasks in computer vision. Due to the rapid development of deep learning technologies and its superior performance in computer vision, image classification methods based on DNNs have become increasingly mature. To accurately classify images, various types of artificial visual features are designed, and the visual features are automatically learned by DNNs. Related classifiers are then used to distinguish the categories of the images. To date, a large number of deep learning-based image classification methods have been proposed [
26,
27] and have been widely used in different computer vision tasks. In addition, several improved models have been successively proposed to improve the image classification performance. Xi et al. [
28] proposed a parallel neural network by combining texture features. This model can extract features that are highly correlated with facial changes, and thus achieves better performance in facial expression recognition. Hossain et al. [
29] developed an automatic date fruit classification system to satisfy the interest of date fruit consumers. Goren et al. [
30] collected the street images taken by roadside cameras to form a dataset, and then designed a CNN to check the vacancy in the collected dataset. To form an efficient classification mechanism that integrates feature extraction, feature selection, and a classification model, Yao et al. [
31] proposed an end-to-end image classification method based on an aided capsule network and applied it to traffic image classification. An image classification framework for securing against indistinguishable plaintext attacks was proposed by Hassan et al. [
32]. This framework performs a secure image classification on the cloud without the need for constant device interaction. To solve the multi-class classification problems, Vasan et al. [
33] proposed a new method to convert raw malware binaries into color images, which are used by the fine-tuned CNN architecture to detect and identify malware families.
A single CNN may be impacted by gradient disappearance, gradient explosion, and other similar factors, while network models based on ensemble learning have better immunity to these adverse factors due to the cooperative complementation of multiple CNNs. For example, Ciregan et al. [
34] designed a method by utilizing multiple CNNs, which are trained by using the same training datasets. These trained CNNs are then used to obtain multiple prediction results, which are in turn fused to obtain the final result. This method employs the simple addition of the predicted results of different CNNs, which it treats in isolation. Frazao et al. [
35] assigned different weights to multiple CNNs; the CNNs with better performance have higher weights, and therefore have greater impacts on the final results. An integration of CNNs is used to detect polyps by Tajbakhsh et al. [
36]; this approach can accurately identify the specific types of polyps by using their color, texture, and shape features. Ijjina et al. [
37] proposed a human action prediction method, which combines several CNNs and uses the best predicted result as the final result. Although these methods use multiple neural network modules to carry out related classification tasks, the modules are independent of each other and the interactions between models are ignored. To solve these problems, Adaboost CNN models have been proposed. For example, Taherkhani et al. [
38] combined several CNN sub-networks based on the Adaboost algorithm. These CNN sub-networks have the same network structure; thus, the transfer learning method can be used between adjacent layers, and the last CNN sub-network module outputs the final results. The model in [
38] is unable to selectively and progressively use the CNN sub-networks for feature extraction, and the testing images need to go through all CNN sub-networks to obtain the final results.
A key problem with the semantic understanding of images is that of learning a good metric to measure the similarity between images. Deep metric learning-based methods have been proposed to learn the appropriate similarity measures between pairs of samples, while samples with higher similarities are classified into a single category according to the distances between samples. These approaches have been widely used for image retrieval [
39], face recognition [
40], and person re-identification [
41]. For example, Schroff et al. [
42] proposed a face recognition system named FaceNet, and a triplet loss was designed to measure the similarities between samples. Wang et al. [
43] proposed a general weighting framework for a series of existing pair-based loss functions by fully considering three similarities for pair weighting, and then collecting and weighting the informative pairs. These metric learning methods focus on optimizing the similarity of image pairs. Furthermore, center loss is proposed by Wen et al. [
44] to define a category center for each category, as well as to minimize the distance within one category. Wang et al. [
45] proposed an angular loss, which considers the angle relationship to learn a better similarity metric, while the angular loss aims at constraining the angle at the negative point of triplet triangles.
The related works mentioned above mainly involve DNNs, ensemble learning, and metric learning. Meanwhile, there are intrinsic correlations between these fields. In general, ensemble learning needs to use multiple DNN models, and the design of both ensemble learning and DNNs should be on the basis of the theory of metric learning. Specifically, the proposed HCNN is an ensemble learning model based on DNNs for the image classification task, and the multi-class joint loss is designed for the HCNN according to the basic theory of metric learning.
3. The Proposed Hierarchical CNNs (HCNNs)
In order to classify different images in real life, we design a hierarchical progressive DNN framework, named Hierarchical CNNs (HCNNs), which consists of several sub-networks. The images need to go through one or more sub-networks so as to obtain a more reliable classification result. In this paper, we refer to the definitions of samples in self-paced learning methods [
46]: the samples that are easy for models to identify are defined as easy samples, while the difficult-to-identify samples are denoted as hard samples. In this section, we will describe the overall structure of the HCNN and its loss function. Multiple CNNs are combined to form HCNNs, which can progressively carry out the sub-networks to classify the images; the cross-entropy loss and triple loss are combined for model training to more accurately extract the distinguishing features of the images.
3.1. The Model Framework of HCNNs
Based on the basic concept of ensemble learning, we try to aggregate multiple CNNs into a strong image classification model [
1,
47,
48]. However, unlike traditional ensemble learning methods or Adaboost CNNs [
38], which consist of the same type of sub-networks that are indiscriminately trained and tested, our HCNN consists of several different types of CNNs as the sub-networks, and these sub-networks are trained progressively in order. In this paper, we choose Alexnet [
10], VGG16 [
11], Inception V3 [
49], Mobilenet V2 [
50], and Resnet-50 [
12] as the basic sub-networks (see
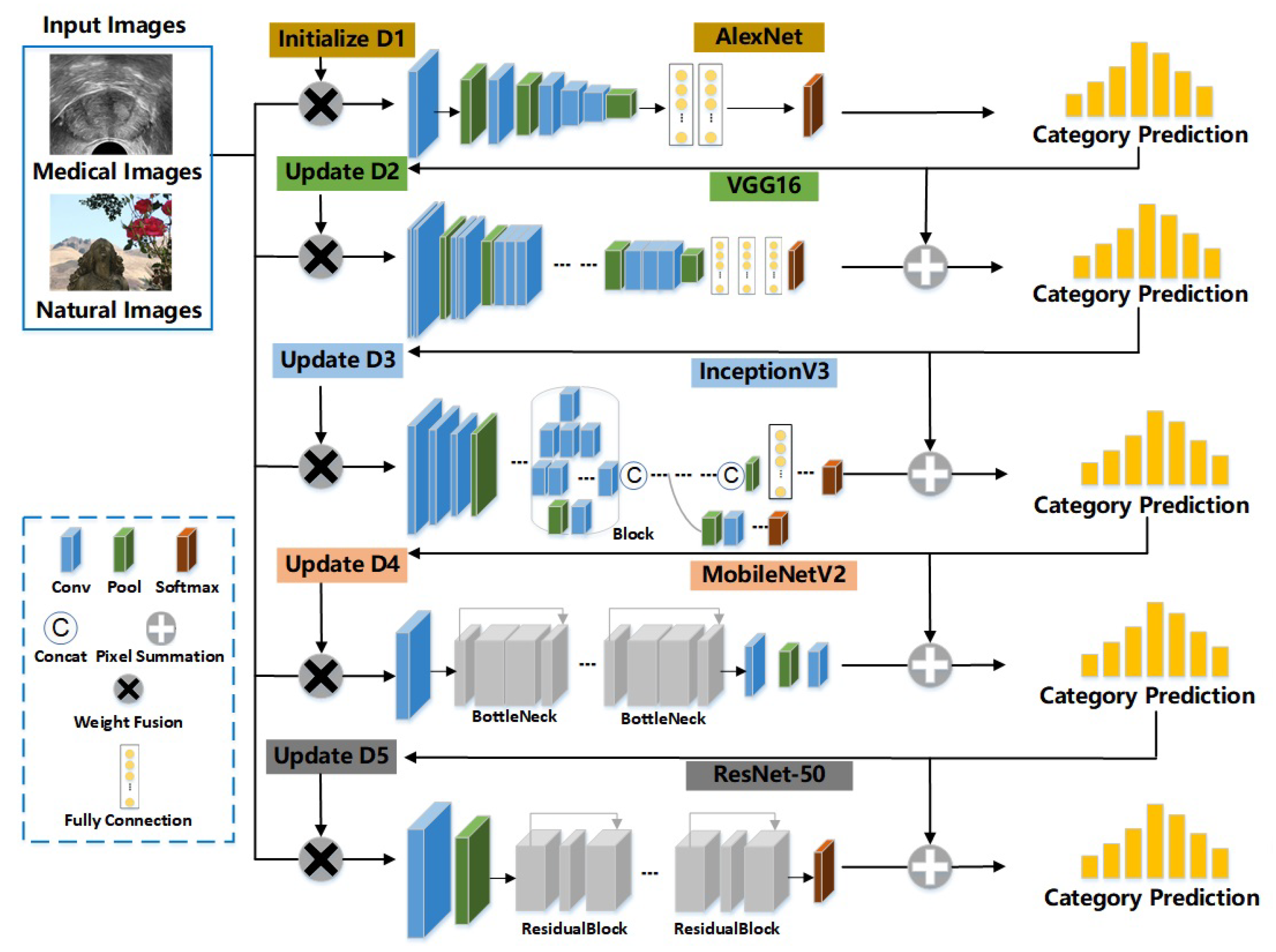
Figure 1). In addition, there are no limits on the number of sub-networks and their types. At the training stage, images are assigned weights to express the difficulties encountered by models in accurately classifying them. If an image can not be accurately classified by a sub-network, its weight will be increased. Images with updated weights are then input into the next sub-network for extracting more abstract and effective visual features. In this section, we will elaborate on HCNNs in more detail.
Assume that HCNNs have M sub-networks, and they are trained one by one. Let be the weight of the i-th image for the m-th sub-network, and . Here, , , while n is the number of all images in the training dataset.
First of all, the weights of all images need to be initialized. We therefore input all these training images with their initial weights into the first sub-network (Alexnet,
) for model training.
where
. The first sub-network is then trained through multiple iterations. The gradient descent is used to update its parameters in each iteration. Finally, the trained sub-network can give the predictions:
where
represents the
m-th sub-network, and
is the predicted label of the
i-th sample by the
m-th sub-network
. Next, we select the samples that meet the condition of
, where
is the ground truth of the category label of the
i-th sample. We further use the following equation to calculate the weighted error rate
of the
m-th sub-network
on all selected samples in the training set:
where
is the weight of the
-th selected samples for
, and
is the number of selected samples. Subsequently,
is used to obtain the weight coefficient
of
, which denotes the importance coefficient of
in HCNNs:
As Equation (
4) shows,
is inversely proportional to
, i.e., with a smaller error rate
, the corresponding sub-network will have larger values of the importance coefficient throughout the whole model. Furthermore,
is used to update the weights of the samples to train the next sub-network.
For the images that meet the condition
, we have
Therefore, if the predicted results exhibit a high degree of agreement with the true labels of the images, then the weights of the images for the next sub-network decrease; otherwise, their weights increase. We then use the image samples with their updated weights to train the next sub-network for multiple iterations.
For a dataset containing a small number of samples, the initial and updated weights of the samples are applicable to training of HCNNs. However, if the dataset consists of a large number of samples, there is a risk of gradient explosion occurring during model training due to the loss values being too small (possibly even approaching zero); this means that the network parameters cannot be updated normally. To solve this problem, we use the weights of samples to obtain the category weights using Equation (
8):
where
represents the weight of the
j-th category for the
-th sub-network, and
is the weight of the
-th sample belonging to the
j-th category, which has
samples. We then use
as the weights of the samples belonging to the
j-th category (Equation (
9)).
Therefore, before training each sub-network, we need to update the weights of all samples according to the weights of their corresponding categories. The sub-network will then pay more attention to the samples with larger weights.
HCNN is a scalable model, and its architecture is illustrated in
Figure 1. In addition, HCNN enhances the correlation between different sub-networks by transmitting the feature vectors and the sample weights in the previous sub-network to the next sub-network.
3.2. Multi-Class Joint Loss in HCNNs
During model training, we constantly updated the weights of the image categories and the images to express the difficulties encountered by the model. We then needed to design the loss function, which can guide the model to extract the specific visual features from different images. In addition, this loss function should attempt to make the difference in the visual features within the same category as small as possible, while the difference in the visual features in different categories should be as large as possible.
Cross-entropy loss with category weights. The cross-entropy function
is a classic and commonly used loss function. In this paper, to enable the HCNN to select its corresponding sub-networks and therefore extract the visual features in different levels, a category weight is assigned to each image category; subsequently, the new cross-entropy loss with category weights can be expressed by the following equation:
Here, is the cross-entropy loss with category weights for the -th sub-network, and is the traditional cross-entropy loss.
Weighted triplet loss. For image classification, the problem may arise that there may be less similarity between images within the same category, while there is more similarity between images in different categories; as a result, it is difficult to effectively improve the image classification performance. The triplet loss can guide models to learn the visual features to further cluster the samples within the same category and separate the samples of different categories. Therefore, we use a weighted triplet loss in each sub-network. This guides HCNNs to extract more discriminative visual features between the samples of different categories, as shown in
Figure 2.
Assume that we have a series of image samples
, and
are their true labels. We then define an anchor image
, a positive image sample
, and a negative image sample
. More specifically,
is an image in one category,
is another image in the same category with
, and
is an image in another category that differs from the category of
. During model training, we can obtain a triplet set consisting of
,
, and
in each batch, and then randomly select the corresponding samples to form a triple
as the input of each sub-network. We can then obtain the triplet loss
for the
m-th sub-network:
Here,
,
, and
represent the visual features extracted by the
m-th sub-network from the images of
, respectively, while
is the Euclidean distance. Moreover,
is a threshold parameter used to distinguish between the positive and negative samples of the anchor samples.
is a parameter that is close to 0 without being equal to 0. Triplet loss is used to reduce the distance between the features of
and
and expand the distance between the features of
and
, as shown in
Figure 2. Then, triplet loss can be used to solve the following three situations in HCNNs.
Case I: If , then . This situation shows that the current sub-network can accurately classify these three image samples; thus, there is no need to pay more attention to them in the subsequent sub-networks.
Case II: . This situation shows that high similarity exists among these three image samples, and the current sub-network finds it difficult to distinguish them. This triple S then needs to pass through the subsequent sub-networks with more complex network structures.
Case III: . This situation shows that the current sub-network cannot distinguish these image samples, and that their more abstract features need to be extracted by the subsequent sub-networks.
Weighted multi-class joint loss function. HCNNs can progressively classify images and achieve visual feature learning at different levels. In addition, in each batch during model training, a weighted multi-class joint loss function is designed by combining cross-entropy loss with category weights and weighted triplet loss.
Here, is the weighted multi-class joint loss for the m-th sub-network. is a hyperparameter; in this paper, .
3.3. Model Testing
To test the proposed model, we need to provide a threshold
for each sub-network so as to make the model output the final classification results. When image classification confidence in the
m-th sub-network is higher than
, this prediction is reliable; otherwise, the credibility of the image classification results is lower. Generally speaking, the values of
can be set larger, which ensures that the difficult-to-identify images can pass through the subsequent sub-networks with more complex network structures.
Figure 3 shows the simple process of image classification of HCNNs.
In more detail, the testing process of HCNNs with M sub-networks can be described as follows.
Step 1: The test image is input into the m-th sub-network for visual feature learning ( for the first sub-network). The model then outputs the probability distribution of the image classification results , where is the number of image categories.
Step 2: A comparison is drawn between the maximum classification probability and .
Step 3: If or , then the model outputs the classification results corresponding to ; otherwise, , and return to Step 1.
5. Conclusions
At present, all the image classification models treat the images equally. However, there are meaningful differences between images, so different images should be treated differently by various models, which would comply with the basic mechanism of human cognition. Therefore, we propose HCNNs, which classify different images by different numbers of sub-networks. In HCNNs, the easy-to-identify images are recognized by simple sub-networks and output the results directly, while images that are more difficult to identify may need to go through multiple complex sub-networks to extract their more abstract visual features. Through this image classification mechanism, HCNNs achieve better image classification performance compared with existing single-network models and Adaboost CNN with its multiple simple sub-networks. In addition, the HCNN has better scalability and variability; that is, the number of sub-networks can be increased or decreased, and the types of sub-networks can be changed according to the specific visual tasks involved. Therefore, in the future, more detailed models similar to HCNNs may be constructed based on the complexity of the image classification task, which would gradually become closer to the basic mechanism of human cognition, and the models will have higher recognition accuracy and efficiency.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}