Architecture Design for Feature Extraction and Template Matching in a Real-Time Iris Recognition System

Abstract
:1. Introduction
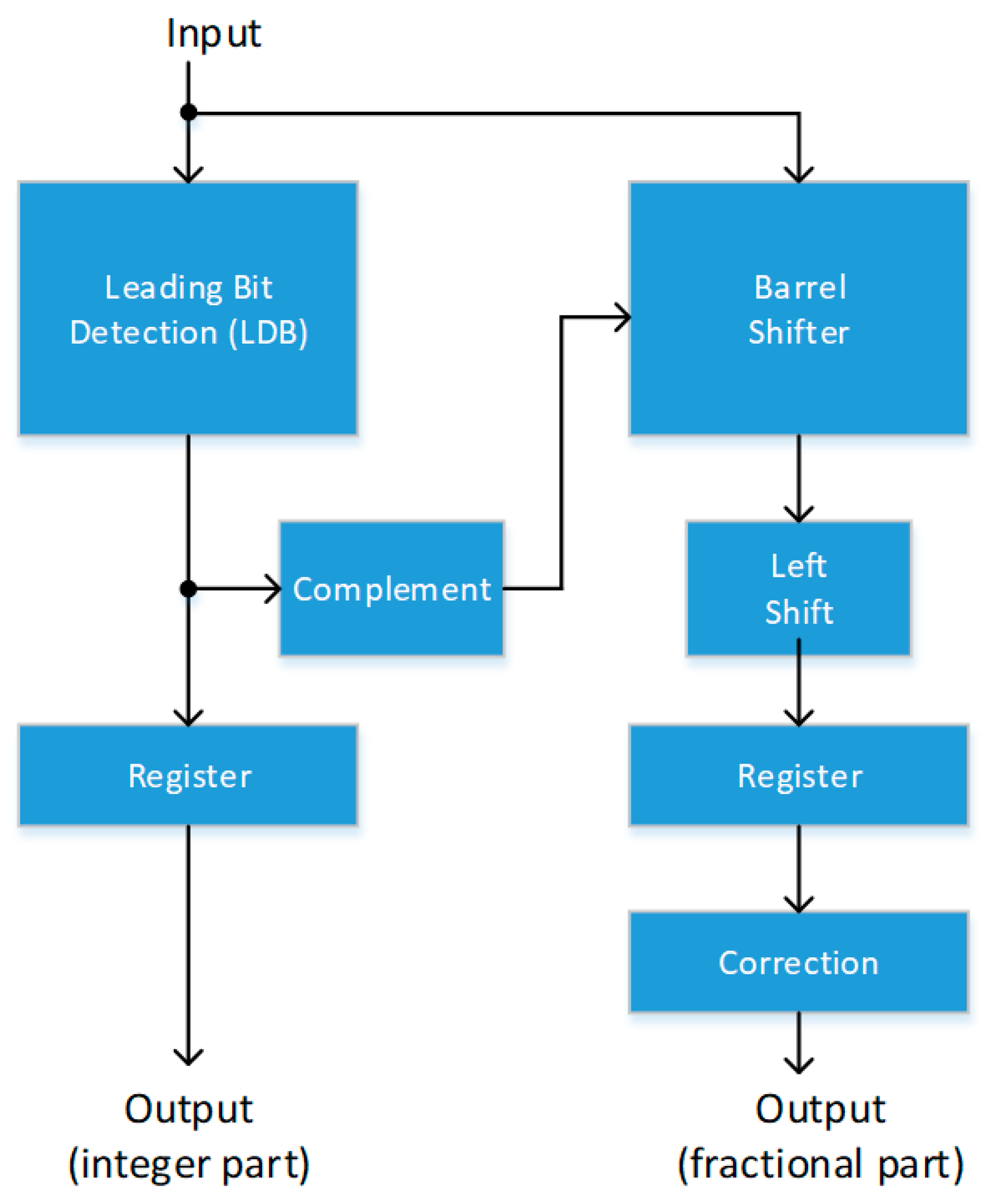
- A novel architecture design that uses BCA in the iris unwrapping process is presented. This approach is utilized to replace trigonometric operations that are widely used in conventional approaches with simple add, subtract, and shift operations;
- A parallel architecture design for the two-dimensional (2D) convolution process in feature extraction is presented. This design uses a full-window buffering scheme to effectively utilize on-chip memory blocks for delay buffers, in order to reduce the memory bandwidth;
- Approximation techniques for reducing complex operations in the architecture design for the template matching process are presented. The proposed approximation techniques transform division operations into log-based subtraction operations to reduce iterative computational processes.
2. Overview of an Iris Recognition Algorithm
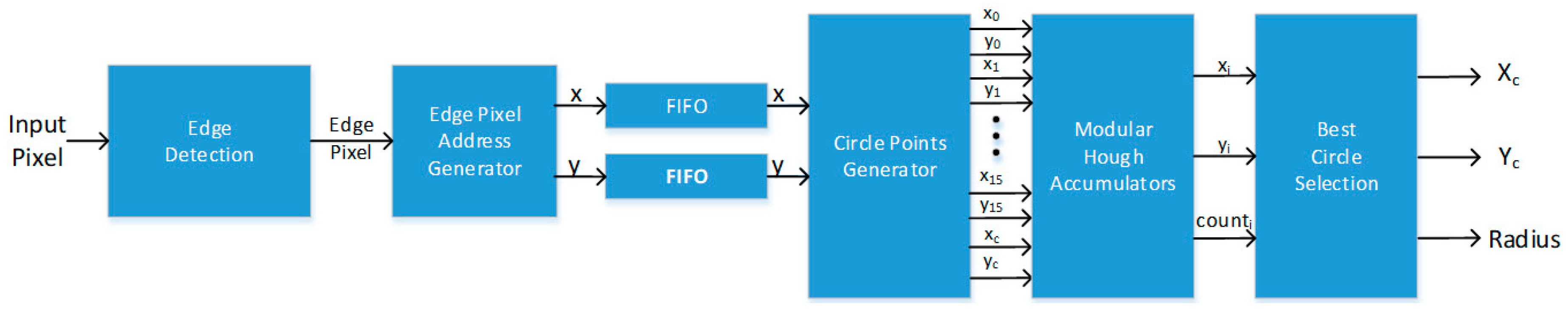
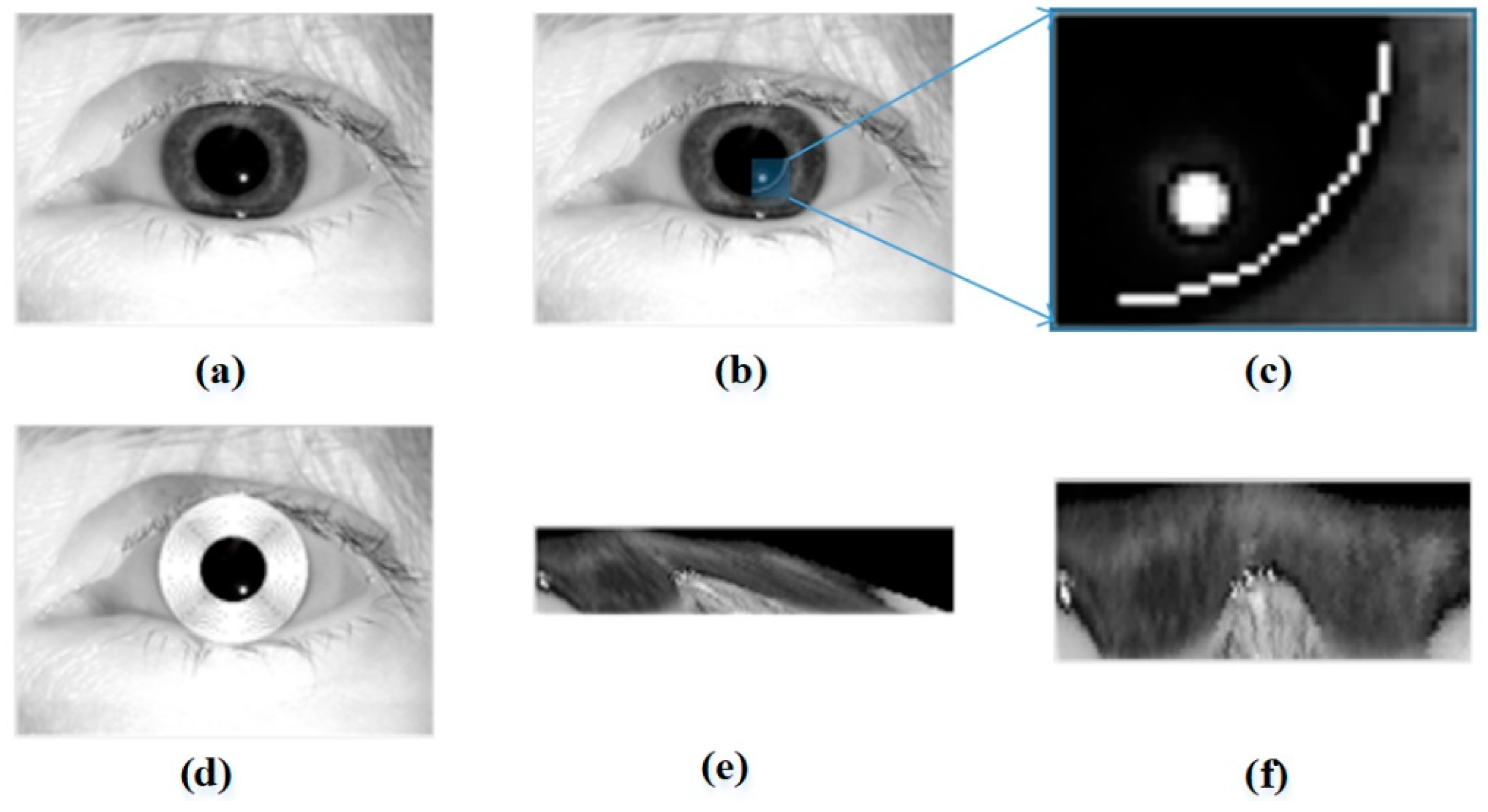
2.1. Iris Boundary Detection
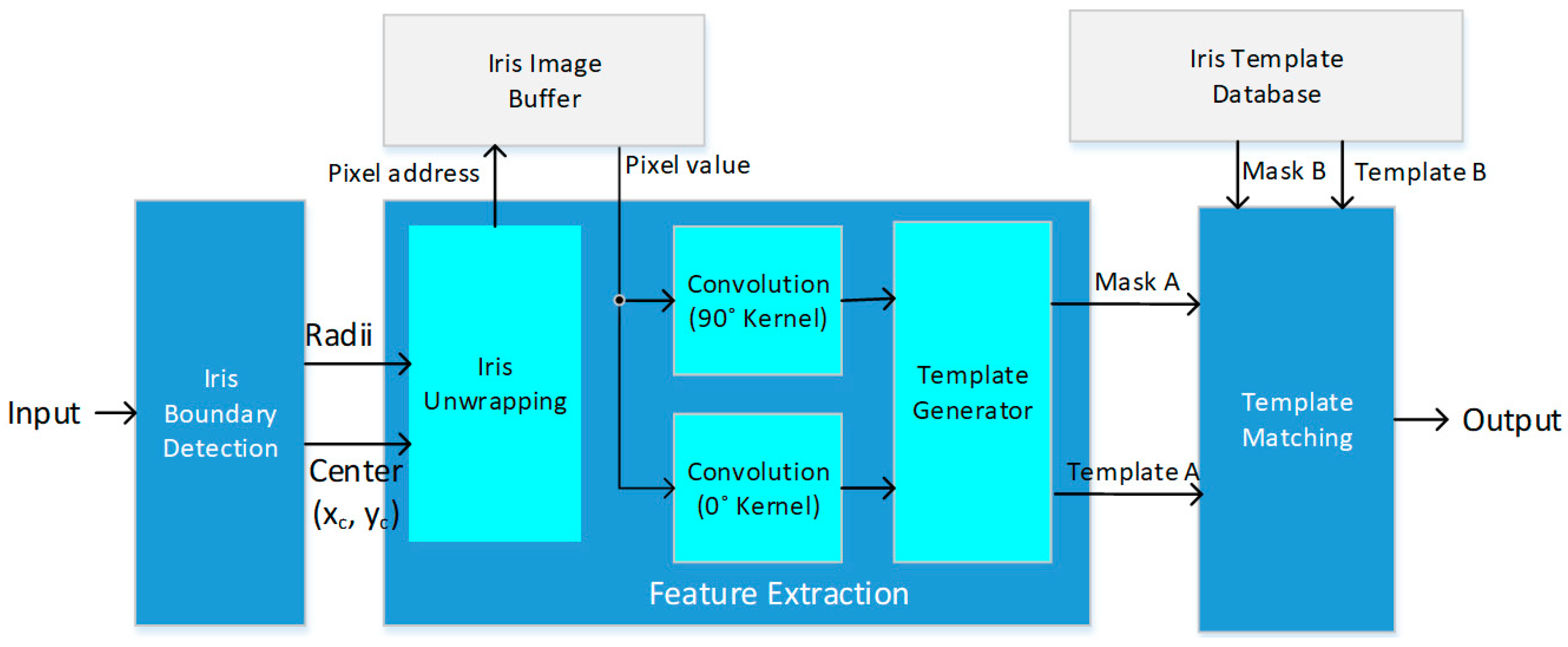
2.2. Feature Extraction
2.3. Template Matching
3. Architecture Design
3.1. Iris Boudary Detection Module
3.2. Feature Extraction Module
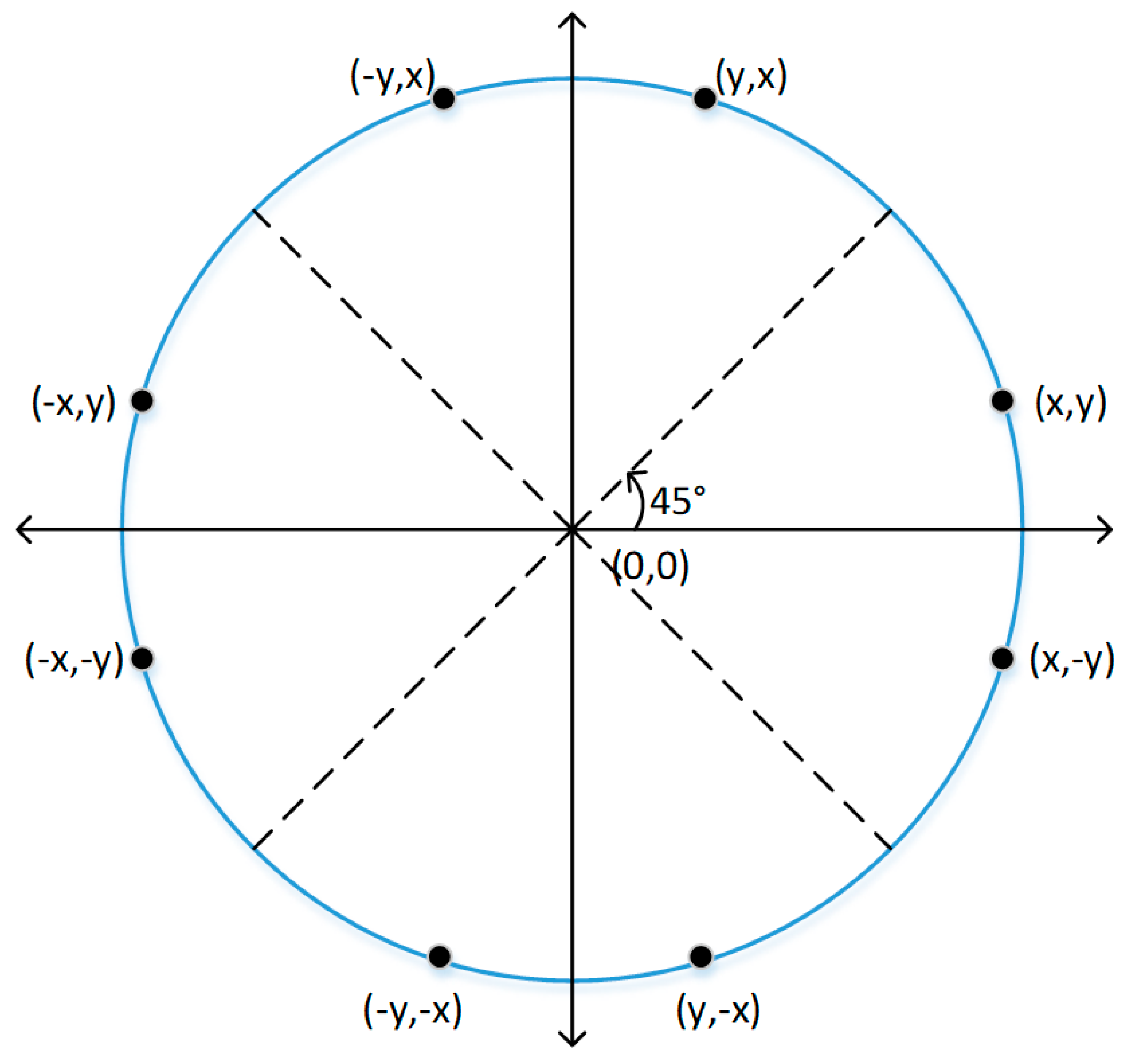
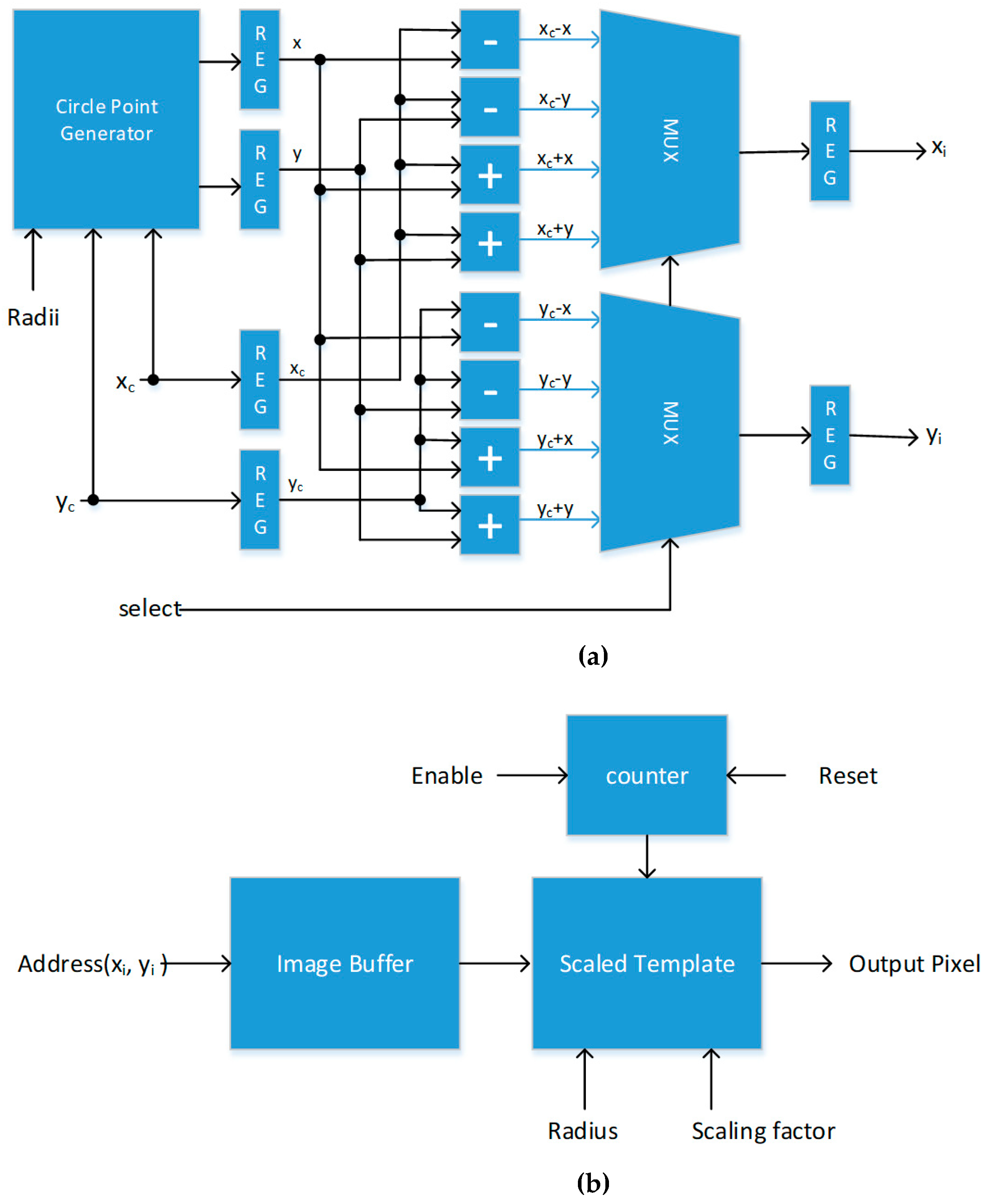
3.2.1. Iris Unwrapping
| Algorithm 1: Bresenham Circle Point Generation. |
|
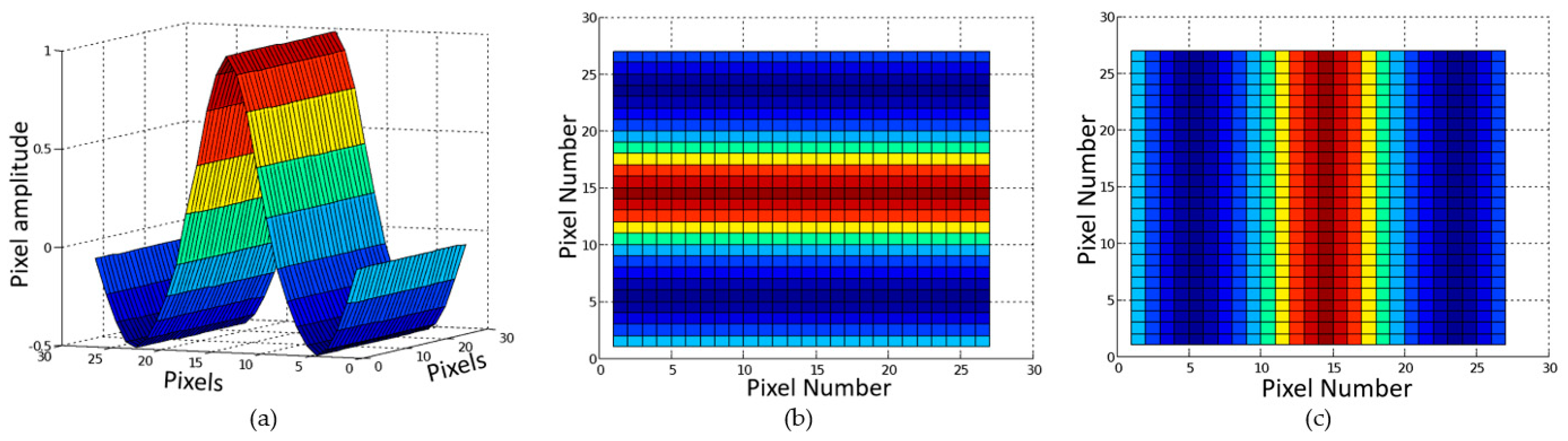
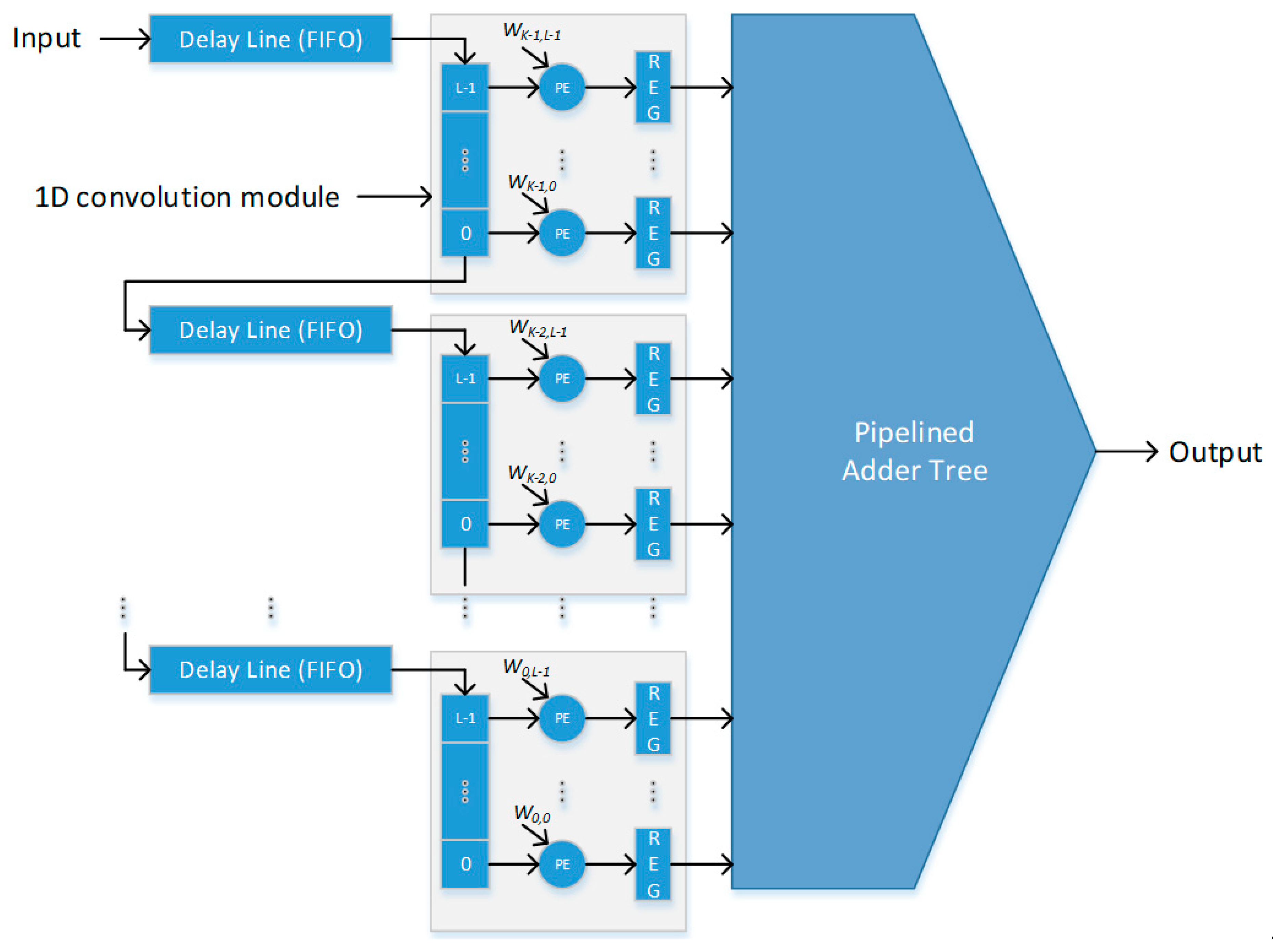
3.2.2. Window-Based Filtering
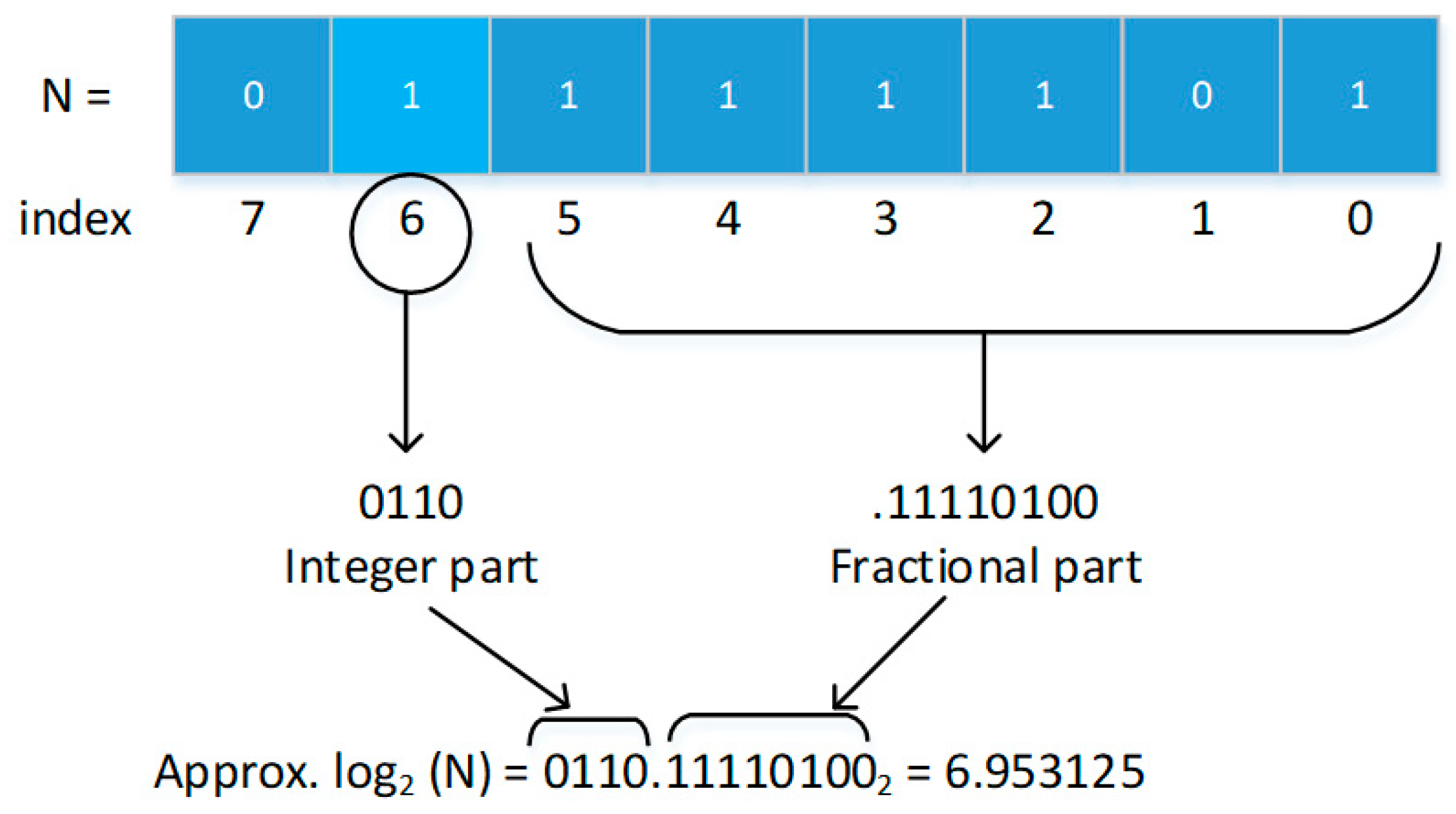
3.3. Template Matching
4. Results and Discussion
4.1. Iris Unwrapping Module
4.2. 2D Convolution (Filtering) Module
4.3. Template Matching Module
4.4. Complete Design
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Prabhakar, S.; Ivanisov, A.; Jain, A. Biometric recognition: Sensor characteristics and image quality. IEEE Instrum. Meas. Mag. 2011, 14, 10–16. [Google Scholar] [CrossRef]
- Ammour, B.; Boubchir, L.; Bouden, T.; Ramdani, M. Face–Iris Multimodal Biometric Identification System. Electronics 2020, 9, 85. [Google Scholar] [CrossRef] [Green Version]
- Khan, M.K.; Zhang, J.; Horng, S.J. An effective iris recognition system for identification of humans. In Proceedings of the 8th International Multitopic Conference (INMIC2004), Lahore, Pakistan, 24–26 December 2004. [Google Scholar]
- Hsiung, T.W.; Mohamed, S.S. Performance of iris recognition using low resolution iris image for attendance monitoring. In Proceedings of the 2011 IEEE International Conference of Computer Applications and Industrial Electronics (ICCAIE), Penang, Malaysia, 4–7 December 2011. [Google Scholar]
- Agarwal, H.; Pandey, G.N. Online voting system for India based on AADHAAR ID. In Proceedings of the 2013 11th International Conference on ICT and Knowledge Engineering, Bangkok, Thailand, 20–22 November 2013. [Google Scholar]
- Ngo, H.; Rakvic, R.; Broussard, R.; Ives, R. Resource-aware architecture design and implementation of hough transform for a real-time iris boundary detection system. IEEE Trans. Consum. Electron. 2014, 60, 485–492. [Google Scholar] [CrossRef]
- Fang, B.; Lu, Y.; Zhou, Z.; Li, Z.; Yan, Y.; Yang, L.; Jiao, G.; Li, G. Classification of Genetically Identical Left and Right Irises Using a Convolutional Neural Network. Electronics 2019, 8, 1109. [Google Scholar] [CrossRef] [Green Version]
- Ives, R.W.; Broussard, R.P.; Kennell, L.R.; Rakvic, R.N.; Etter, D.M. Iris recognition using the Ridge Energy Direction (RED) algorithm. In Proceedings of the 42nd Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 26–29 October 2008. [Google Scholar]
- Gupta, N.; Khosravy, M.; Gupta, S.; Dey, N.; Crespo, R.G. Lightweight Artificial Intelligence Technology for Health Diagnosis of Agriculture Vehicles: Parallel Evolving Artificial Neural Networks by Genetic Algorithm. Int. J. Parallel Program. 2020. [Google Scholar] [CrossRef]
- Rakvic, R.; Broussard, R.; Ngo, H. Energy Efficient Iris Recognition with Graphics Processing Units. IEEE Access 2016, 4, 2831–2839. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.; Cho, J.; Jung, Y.; Lee, S.; Jung, Y. Area-Efficient Vision-Based Feature Tracker for Autonomous Hovering of Unmanned Aerial Vehicle. Electronics 2020, 9, 1591. [Google Scholar] [CrossRef]
- Aranda, L.A.; Sánchez, A.; Garcia-Herrero, F.; Barrios, Y.; Sarmiento, R.; Maestro, J.A. Reliability Analysis of the SHyLoC CCSDS123 IP Core for Lossless Hyperspectral Image Compression Using COTS FPGAs. Electronics 2020, 9, 1681. [Google Scholar] [CrossRef]
- Kwan, E.Y.L.; Nunez-Yanez, J. Entropy-Driven Adaptive Filtering for High-Accuracy and Resource-Efficient FPGA-Based Neural Network Systems. Electronics 2020, 9, 1765. [Google Scholar] [CrossRef]
- Huang, H.; Liu, Z.; Chen, T.; Hu, X.; Zhang, Q.; Xiong, X. Design Space Exploration for YOLO Neural Network Accelerator. Electronics 2020, 9, 1921. [Google Scholar] [CrossRef]
- Ea, T.; Valentian, A.; Rossant, F.; Amiel, F.; Amara, A. Algorithm implementation for iris identification. In Proceedings of the 48th Midwest Symposium on Circuits and Systems, Covington, KY, USA, 7–10 August 2005. [Google Scholar]
- Hematian, A.; Manaf, A.A.; Chuprat, S.; Khaleghparast, R.; Yazdani, S. Field programmable gate array system for real-time IRIS recognition. In Proceedings of the 2012 IEEE Conference on Open Systems (ICOS), Kuala Lumpur, Malaysia, 21–24 October 2012. [Google Scholar]
- Zaim, A.; Sawalha, A.; Quweider, M.; Iglesias, J.; Tang, R. A New Method for Iris Recognition using Gray-Level Coccurence Matrix. In Proceedings of the 2006 IEEE International Conference on Electro/information Technology, East Lansing, MI, USA, 7–10 May 2006. [Google Scholar]
- Bresenham, J.E. A Linear Algorithm for Incremental Digital Display of Circular Arc. Commut. ACM 1977, 20, 100–106. [Google Scholar] [CrossRef]
- Wright, W.E. Parallelization of Bresenham’s line and circle algorithms. IEEE Comput. Graph. Appl. 1990, 10, 60–67. [Google Scholar] [CrossRef]
- Carothers, M.T.; Ngo, H.T.; Rakvic, R.N.; Broussard, R.P. Iris unwrapping using the Bresenham circle algorithm for real-time iris recognition. In Proceedings of the SPIE/IS&T Electronic Imaging Conference, San Francisco, CA, USA, 8–12 February 2015. [Google Scholar]
- Sedaaghi, M.H.; Daj, R.; Khosravi, M. Mediated morphological filters. In Proceedings of the 2001 International Conference on Image Processing, Thessaloniki, Greece, 7–10 October 2001. [Google Scholar]
- Gutierrez, C.E.; Alsharif, M.R.; Khosravy, M.; Yamashita, K.; Miyagi, H.; Villa, R. Main large data set features detection by a linear predictor model. In Proceedings of the AIP Conference, Athens, Greece, 4–7 April 2014. [Google Scholar]
- Gutierrez, C.E.; Alsharif, M.R.; He, C.; Khosravy, M.; Villa, R.; Yamashita, K.; Miyagi, H. Uncover news dynamic by Principal Component Analysis. ICIC Express Lett. 2013, 7, 1245–1250. [Google Scholar]
- Bhuria, S.; Muralidhar, P. FPGA implementation of sine and cosine value generators using Cordic algorithm for satellite attitude determination and calculators. In Proceedings of the 2010 International Conference on Power, Control and Embedded Systems (ICPCES), Allahabad, India, 29 November–1 December 2010. [Google Scholar]
- Perri, S.; Spagnolo, F.; Frustaci, F.; Corsonello, P. Efficient Approximate Adders for FPGA-Based Data-Paths. Electronics 2020, 9, 1529. [Google Scholar] [CrossRef]
- Ngo, H.T.; Asari, V.J. Design of a Logarithmic Domain 2-D Convolver for Low Power Video Processing Applications. In Proceedings of the 6th International Conference on Information Technology: New Generations, Las Vegas, NV, USA, 27–29 April 2009. [Google Scholar]
- Mitchell, J.N. Computer multiplication and division using binary logarithms. IRE Trans. Electron. Comput. 1962, 11, 512–517. [Google Scholar] [CrossRef]
- Strollo, A.; De Caro, D.; Petra, N. A 430 MHz, 280 mW Processor for the Conversion of Cartesian to Polar Coordinates in 0.25 CMOS. IEEE J. Solid-State Circuits 2008, 43, 2503–2513. [Google Scholar] [CrossRef]
- Lee, S.; Kwon, K.; Park, I. Pipelined Cartesian-to-Polar Coordinate Conversion Based on SRT Division. IEEE Trans. Circuits Syst. II Express Briefs 2007, 54, 680–684. [Google Scholar] [CrossRef]
- Broussard, R.P.; Kennell, L.; Ives, R. Identifying discriminatory information content within the iris. In Proceedings of the SPIE 6944, Biometric Technology for Human Identification V, Orlando, FL, USA, 17 March 2008. [Google Scholar]
- Phillips, P.J.; Bowyer, K.W.; Flynn, P.J.; Liu, X.; Scruggs, W.T. The iris challenge evaluation. In Proceedings of the International Conference on Biometrics: Theory, Applications, and System, Washington, DC, USA, 29 September–2 October 2008. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technology | Performance (Cycle/Template Bit) | Clock Frequency (MHz) | Average Unwrapping Time (µs) | |
|---|---|---|---|---|
| Strollo et al. [28] | 0.25 µm CMOS | 13 | 430 | 500.65 |
| Lee et al. [29] | 0.25 µm CMOS | 9 | 400 | 372.60 |
| This work | FPGA | 1 | 26.71 | 342.79 |
| Number of Non-Match Pixels | Number of Valid Pixels | HD (Conventional) | HD (Proposed) | |
|---|---|---|---|---|
| HD example 1 | 2001 | 8285 | 0.2415 | 0.2428 |
| HD example 2 | 3128 | 8945 | 0.3497 | 0.3589 |
| HD example 3 | 3079 | 13,788 | 0.2233 | 0.2275 |
| HD example 4 | 6963 | 15,137 | 0.4600 | 0.4630 |
| Description | Implementation Result |
|---|---|
| Device | 5CGXFC9E7F35C8 |
| Logic Utilization (ALM) | 11,169 (10%) |
| Register Utilization | 24,940 |
| Memory Utilization (bits) | 1,125,024 (9%) |
| Block RAMs | 160 (3%) |
| Clock Frequency (MHz) | 25.38 |
| Conventional Method (Clock Cycle) | Proposed Method (Clock Cycle) | |
|---|---|---|
| Iris Unwrapping | 82,800 | 9156 |
| 2D convolution and HD | 96,644,161 | 35,605 |
| Total | 96,726,961 | 44,761 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ngo, H.; Rakvic, R.; Broussard, R.; Ives, R.; Carothers, M. Architecture Design for Feature Extraction and Template Matching in a Real-Time Iris Recognition System. Electronics 2021, 10, 241. https://doi.org/10.3390/electronics10030241
Ngo H, Rakvic R, Broussard R, Ives R, Carothers M. Architecture Design for Feature Extraction and Template Matching in a Real-Time Iris Recognition System. Electronics. 2021; 10(3):241. https://doi.org/10.3390/electronics10030241
Chicago/Turabian StyleNgo, Hau, Ryan Rakvic, Randy Broussard, Robert Ives, and Matthew Carothers. 2021. "Architecture Design for Feature Extraction and Template Matching in a Real-Time Iris Recognition System" Electronics 10, no. 3: 241. https://doi.org/10.3390/electronics10030241
APA StyleNgo, H., Rakvic, R., Broussard, R., Ives, R., & Carothers, M. (2021). Architecture Design for Feature Extraction and Template Matching in a Real-Time Iris Recognition System. Electronics, 10(3), 241. https://doi.org/10.3390/electronics10030241