
Edge Computing for Data Anomaly Detection of Multi-Sensors in Underground Mining

Abstract
:1. Introduction
- The sensor data in underground mining have very obvious time series characteristics, and the data collected by the sensor vary with time, depending on the construction environment in underground mining.
- Most of the underground construction operation environment is in the tunnel, of which the space is small, but the operation distance is long. Therefore, a large number of sensors need to be deployed in different areas, and there is a correlation between the sensor data at different locations.
- An anomaly detection task migration model is proposed to migrate data anomaly detection tasks to different types of equipment for execution.
- An anomaly detection method for sensor nodes is designed that is based on K-means and C-means algorithms. An anomaly detection algorithm based on ambiguity is proposed in order to perform anomaly detection and data clustering analysis on the redundant data collected by the sensor.
- An anomaly detection method of the sink node is designed for preprocessing the multi-sensors’ data, and then use the sliding window to analyze the time series of the multi-sensors’ data in order to obtain the anomaly detection results.
2. Related Work
2.1. Clustering-Based Methods
2.2. AI-Based Methods
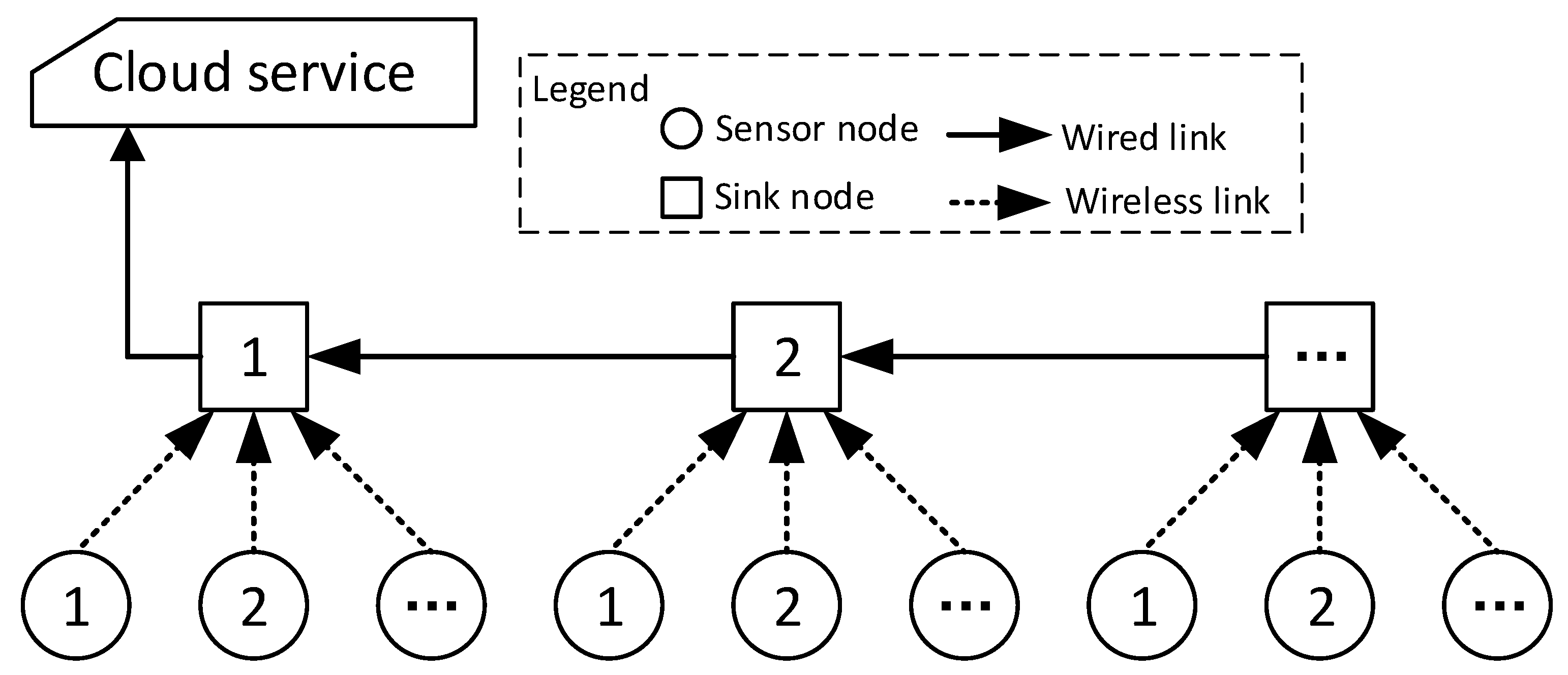
3. System Model
3.1. Application Model of IoT in Underground Mining
3.2. Edge Computing Model of Anomaly Detection
- Data corruption.It means that after the collected data are distorted due to equipment failure, battery loss, etc., which cannot represent the true data value. For example, when a sensor’s battery power is less than the standard value, the data that it collects will cause errors. However, this error is not a true data anomaly.
- Data anomaly.It refers to the abnormality of the underground construction environment that is shown by the real data value, such as the decrease of oxygen concentration, which indicates that there may be problems with the ventilation system. According to the definition of [30], the data anomalies in this article include three cases:
- Point AnomaliesIf a sensor data value does not meet the range of the normal data value, it is judged as Point Anomalies. For example, if a temperature value is found to be greater than 40, then it is considered that the underground environment at this temperature is abnormal. However, there are correlations between different types of sensors in the mine, such as temperature and humidity sensors. Therefore, the Point Anomalies of a single sensor cannot truly reflect the actual environmental anomalies.
- Contextual AnomaliesIn underground mining, if there are abnormalities in different correlated sensors, then it can be considered that the environment is abnormal under the current conditions. However, due to the deployment of automatic sprinkler, emergency ventilation and other equipment, Contextual Anomalies can only indicate that the environment in underground mining is abnormal at a certain moment, and it is likely that the emergency equipment will start at the next moment, which makes the environment start to become normal. In this case, it cannot be defined as an environmental abnormality and an emergency warning is activated.
- Collective AnomaliesIn a period of time, if multiple consecutive Contextual Anomalies occur, it can be considered to be a collective anomalies.
- Cluster analysis.The sensor node performs cluster analysis. The sensor node analyzes whether the data value is abnormal according to the received data. It is mainly to determine whether the data are damaged due to factors, such as equipment failure. The sensor will collect multiple data in a data acquisition period, and then perform anomaly detection on these data. The sensors in underground mining are powered by batteries, and the computing power of the equipment is also limited. Therefore, there is no guarantee that the data acquisition every time is true, and there may be some errors. Moreover, it is impossible to guarantee whether the device will lose data due to wireless interference during this period, because the acquisition period of some sensors is long (for example, temperature sensors are usually collected every 5 min. or even half an hour). Multiple collections are required for this reason. Multiple redundant data need to be collected in order to reduce the data errors caused by equipment problems. The damaged data need to be cleared in order to obtain more realistic data.
- Abnormal judgment.The abnormality judgment is executed by the sink node. Based on the data that are sent by multiple sensors, comprehensive analysis of sensor data at different locations is performed in order to determine whether the environment is abnormal. For example, in underground mining, the temperature values collected at three locations are different. If only one temperature value is abnormal, then it may be an error caused by the complete damage of the sensor, so comprehensive analysis is required.
- Anomaly prediction.A single environmental indicator is judged by the sink node. The underground construction environment requires multiple indicators for comprehensive judgment, such as temperature, humidity, oxygen concentration, etc. The comprehensive judgment of these sensors can analyze the overall situation of the environment and make predictive judgments. The task of anomaly prediction is performed by the cloud, and it is not the research content of this article.
4. Anomaly Detection Algorithms in Underground Mining
4.1. Anomaly Detection Algorithm of the Sensor Node
- Initialize the sample data, and then sort the data set in ascending order according to its value. See Equation (1), let
- For any , calculate the membership degree () between it and the central element of each cluster n, and select the smallest one to join the cluster. That is, , , s.t. .
- Calculate the average value () of cluster 1, determine whether is satisfied, if not, set , and then re-execute step 2. Otherwise, continue to the next step.
- Select each element in cluster 0 and cluster 2. If the Equation (3) holds, then it is an abnormal data. That is oris the bound parameter of the clustering algorithm, which is set according to the actual situation of the project.
| Algorithm 1 Anomaly data clustering algorithm of the sensor node |
Function ADCA(){ // s is the data array of the buffer queue. // is the convergence parameter of the membership function (see in Equation (2)). // is the bound parameter for anomaly detection(see in Equation (3)). // is the time parameter of edge computing
} |
4.2. Anomaly Detection Algorithm of the Sink Node
- The sink node pushes the received sensor data into the sliding window w according to the sensor’s type.
- Traverse the sliding window w, preprocess M data of each data block, delete the abnormal data in the M data according to the sensor node abnormal detection method (see Algorithm 1), and obtain the final average value.
- Re-traverse the sliding window to determine whether the latest data value meets the normal threshold interval. If it does not meet the normal threshold interval, then it is determined to be abnormal and the algorithm ends, otherwise it proceeds to step 4.
- Calculate the variance from the N data before the current moment (according to the Equation (5)), and then determine whether the calculation result meets the threshold. If it does not meet the threshold, then it is judged to be abnormal and the algorithm ends, otherwise it goes to step 5.
- Calculate the trend of change for N data according to Equation (6). If the final result exceeds the threshold, it is judged to be abnormal, otherwise it is judged that the data are normal and the algorithm ends.
| Algorithm 2 Anomaly data detection algorithm of the sink node |
Function ADDA(){ // w is the data array of the sliding window. // and are the lower and upper bound of normal data. // e is the bound of Equation (5). // is the bound of Equation (6).
} |
5. Experiment Analysis
5.1. Experiment Settings
5.2. Accuracy Analysis
5.3. Delay Analysis
5.4. Energy Consumption Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zheng, C.; Jiang, B.; Xue, S.; Chen, Z.; Li, H. Coalbed methane emissions and drainage methods in underground mining for mining safety and environmental benefits: A review. Process Saf. Environ. Prot. 2019, 127, 103–124. [Google Scholar] [CrossRef]
- Iii, J.H.; Harteis, S.P.; Yuan, L. A survey of atmospheric monitoring systems in U.S. underground coal mines. Min. Eng. 2018, 70, 37–40. [Google Scholar]
- Pałaka, D.; Paczesny, B.; Gurdziel, M.; Wieloch, W. Industry 4.0 in development of new technologies for underground mining. E3S Web Conf. 2020, 174, 01002. [Google Scholar] [CrossRef]
- Muduli, L.; Mishra, D.P.; Jana, P.K. Optimized Fuzzy Logic-Based Fire Monitoring in Underground Coal Mines: Binary Particle Swarm Optimization Approach. IEEE Syst. J. 2019, 99, 1–8. [Google Scholar] [CrossRef]
- Mishra, D.P.; Panigrahi, D.C.; Kumar, P.; Kumar, A.; Sinha, P.K. Assessment of relative impacts of various geo-mining factors on methane dispersion for safety in gassy underground coal mines: An artificial neural networks approach. Neural Comput. Appl. 2020, 2020, 1–10. [Google Scholar] [CrossRef]
- Zhang, J.; Xu, K.; You, G.; Wang, B.; Zhao, L. Causation Analysis of Risk Coupling of Gas Explosion Accident in Chinese Underground Coal Mines. Risk Anal. 2019, 39, 1634–1646. [Google Scholar] [CrossRef]
- Vaziri, V.; Hamidi, J.K.; Sayadi, A.R. An integrated GIS-based approach for geohazards risk assessment in coal mines. Environ. Earth Sci. 2018, 77, 1–18. [Google Scholar] [CrossRef]
- Han, D.; Guo, F.; Pan, J.; Zheng, W.; Chen, W. Visual Analysis for Anomaly Detection in Time-Series: A Survey. Jisuanji Yanjiu Yu Fazhan/Comput. Res. Dev. 2018, 55, 1843–1852. [Google Scholar]
- Taha, A.; Hadi, A.S. Anomaly Detection Methods for Categorical Data: A Review. ACM Comput. Surv. 2019, 52, 1–35. [Google Scholar] [CrossRef]
- Dogo, E.M.; Nwulu, N.I.; Twala, B.; Aigbavboa, C. A survey of machine learning methods applied to anomaly detection on drinking-water quality data. Urban Water J. 2019, 16, 1–14. [Google Scholar] [CrossRef]
- Moustafa, N.; Hu, J.; Slay, J. A holistic review of Network Anomaly Detection Systems: A comprehensive survey. J. Netw. Comput. Appl. 2019, 128, 33–55. [Google Scholar] [CrossRef]
- Cook, A.A.; Msrl, G.; Zhong, F. Anomaly Detection for IoT Time-Series Data: A Survey. IEEE Internet Things J. 2020, 7, 6481–6494. [Google Scholar] [CrossRef]
- Agarwal, J.; Nagpal, R.; Sehgal, R. Crime Analysis using K-Means Clustering. Int. J. Comput. Appl. 2018, 83, 1–4. [Google Scholar] [CrossRef]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- Hancer, E.; Xue, B.; Zhang, M. A survey on feature selection approaches for clustering. Artif. Intell. Rev. 2020, 53, 4519–4545. [Google Scholar] [CrossRef]
- Ariyaluran Habeeb, R.A.; Nasaruddin, F.; Gani, A.; Amanullah, M.A.; Hashem, I.A.T.; Ahmed, E.; Imran, M. Clustering-based real-time anomaly detection—A breakthrough in big data technologies. Trans. Emerg. Telecommun. Technol. 2019, e3647. [Google Scholar] [CrossRef]
- Nouretdinov, I.; Gammerman, J.; Fontana, M.; Rehal, D. Multi-level conformal clustering: A distribution-free technique for clustering and anomaly detection. Neurocomputing 2020, 397, 279–291. [Google Scholar] [CrossRef] [Green Version]
- Ghezelbash, R.; Maghsoudi, A.; Carranza, E.J.M. Optimization of geochemical anomaly detection using a novel genetic K-means clustering (GKMC) algorithm. Comput. Geosci. 2020, 134, 104335. [Google Scholar] [CrossRef]
- Huang, S.; Guo, Y.; Yang, N.; Zha, S.; Liu, D.; Fang, W. A weighted fuzzy C-means clustering method with density peak for anomaly detection in IoT-enabled manufacturing process. J. Intell. Manuf. 2020, 131, 1–17. [Google Scholar] [CrossRef]
- Bilal, A.; Jian, W.; Ali, Z.; Tanvir, S.; Khan, M. Hybrid Anomaly Detection by Using Clustering for Wireless Sensor Network. Wirel. Pers. 2019, 106, 1841–1853. [Google Scholar]
- Nguyen, K.; Renault, E.; Milocco, R. Environment Monitoring for Anomaly Detection System Using Smartphones. Sensors 2019, 19, 3834. [Google Scholar] [CrossRef] [Green Version]
- Aggarwal, A.; Toshniwal, D. Detection of anomalous nitrogen dioxide (NO2) concentration in urban air of India using proximity and clustering methods. J. Air Waste Manag. Assoc. 2019, 69, 805–822. [Google Scholar] [CrossRef]
- Pecht, M.G.; Kang, M. Machine Learning: Anomaly Detection. Available online: https://onlinelibrary.wiley.com/doi/abs/10.1002/9781119515326.ch6 (accessed on 24 August 2018).
- Quatrini, E.; Costantino, F.; Gravio, G.D.; Patriarca, R. Machine learning for anomaly detection and process phase classification to improve safety and maintenance activities. J. Manuf. Syst. 2020, 56, 117–132. [Google Scholar] [CrossRef]
- Park, S.; Choi, J.Y. Hierarchical Anomaly Detection Model for In-Vehicle Networks Using Machine Learning Algorithms. Sensors 2020, 20, 3934. [Google Scholar] [CrossRef]
- Tsukada, M.; Kondo, M.; Matsutani, H. A Neural Network-Based On-device Learning Anomaly Detector for Edge Devices. IEEE Trans. Comput. 2020, 99, 1. [Google Scholar] [CrossRef] [Green Version]
- Tang, T.W.; Kuo, W.H.; Lan, J.H.; Ding, C.F.; Hsu, H.; Young, H.T. Anomaly Detection Neural Network with Dual Auto-Encoders GAN and Its Industrial Inspection Applications. Sensors 2020, 20, 3336. [Google Scholar] [CrossRef]
- Tan, A.; Wang, Q.; Nan, G.; Deng, Q.; Hu, X.S. Inter-cell Channel Time-Slot Scheduling for Multichannel Multiradio Cellular Fieldbuses. In Proceedings of the 2015 IEEE Real-Time Systems Symposium, San Antonio, TX, USA, 1–4 December 2015. [Google Scholar]
- Xu, C.; Lei, J.; Li, W.; Fu, X. Efficient Multi-User Computation Offloading for Mobile-Edge Cloud Computing. IEEE/ACM Trans. Netw. 2016, 24, 2795–2808. [Google Scholar]
- Chola, V.; Banerjee, A.; Kumar, V. Anomaly Detection: A Survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar]
- Le Boudec, J.Y.; Thiran, P. Network Calculus: A Theory of Deterministic Queuing Systems for the Internet; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Chola, V.; Banerjee, A.; Kumar, V. Anomaly Detection for Discrete Sequences: A Survey. IEEE Trans. Knowl. Data Eng. 2012, 24, 823–839. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Degree of Membership | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Central Data/Raw Data | 1 | 2 | 3 | 4 | 5 | 7 | 9 | 11 | 13 | 15 | |
| First cluster | 1 | 1.0 | 0.67 | 0.5 | 0.4 | 0.33 | 0.25 | 0.2 | 0.17 | 0.14 | 0.125 |
| 7 | 0.25 | 0.29 | 0.33 | 0.4 | 0.5 | 1.0 | 0.5 | 0.33 | 0.25 | 0.2 | |
| 15 | 0.125 | 0.14 | 0.14 | 0.15 | 0.16 | 0.2 | 0.25 | 0.33 | 0.5 | 1.0 | |
| Second cluster | 1 | 1.0 | 0.67 | 0.5 | 0.4 | 0.33 | 0.25 | 0.2 | 0.17 | 0.14 | 0.125 |
| 8.4 | 0.2 | 0.25 | 0.29 | 0.33 | 0.4 | 0.67 | 0.67 | 0.4 | 0.29 | 0.2 | |
| 15 | 0.125 | 0.14 | 0.14 | 0.15 | 0.16 | 0.2 | 0.25 | 0.33 | 0.5 | 1.0 | |
| Anomaly detection | 8.4 | 0 | 0.02 | 0.03 | 0.06 | 0.03 | 0 | ||||
| Parameter Item | Parameter Description | |
|---|---|---|
| Hardware | TI CC2530 F256 | 10 CC2530 (1 sink node and 6 sensors) |
| Wireless protocol | TI Z-Stack | A star network, the sink node serves as the central node |
| Performances | Accuracy, delay and energy consumption | |
| Program language | C, Python3 | C for embedded development and Python3 for data analysis |
| Length of sliding windows | 5, 10 respectively | |
| Number of sensors M | 3, 6 respectively | |
| Data acquisition period p | 20 s | |
| Program parameters | Number of data | 200 |
| Labeled samples for anomalies | 20–30% | |
| Duration of each experiment | 35 min | |
| Number of experiments | 10 | |
| Length of buffer queue of sensor L | 5, 10 respectively | |
| Upper bound | 30 | |
| Lower bound | −20 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; Su, X.; Li, C. Edge Computing for Data Anomaly Detection of Multi-Sensors in Underground Mining. Electronics 2021, 10, 302. https://doi.org/10.3390/electronics10030302
Liu C, Su X, Li C. Edge Computing for Data Anomaly Detection of Multi-Sensors in Underground Mining. Electronics. 2021; 10(3):302. https://doi.org/10.3390/electronics10030302
Chicago/Turabian StyleLiu, Chunde, Xianli Su, and Chuanwen Li. 2021. "Edge Computing for Data Anomaly Detection of Multi-Sensors in Underground Mining" Electronics 10, no. 3: 302. https://doi.org/10.3390/electronics10030302
APA StyleLiu, C., Su, X., & Li, C. (2021). Edge Computing for Data Anomaly Detection of Multi-Sensors in Underground Mining. Electronics, 10(3), 302. https://doi.org/10.3390/electronics10030302