1. Introduction
Inference research through Big Data analysis is being developed in a way that only structured data, only unstructured data, and both structured data and unstructured data are studied. Unstructured data are produced in various types such as image, sound, and text. ITS research has been conducted using the clock-based method such as the Advanced Traveler Information System (ATIS), particularly focusing on the state and space [
1]. In order to express potential traffic flow characteristics such as nonlinear space and time correlation, research on Stacked Auto-encoders Traffic Flow Prediction (SAEs) has been carried out to improve predictive performance by applying greedy class-based non-supervised learning [
2].
Nonetheless, traffic information contains a lot of environmental information. Especially, various kinds of information such as construction information, fire information, and event information are important factors for determining traffic volume. Still, other studies focus only on the volume of traffic.
Furthermore, unstructured data analysis, while analyzing the structured data that already reflects environmental information such as traffic volume, would be more serious. If we assume that there is a certain event in a particular spot, the surrounding traffic volume may grow more than the assumed point of traffic. Nonetheless, this analysis is difficult to predict if the traffic information alone does not include past events and the results are different in the area where the specific event occurs. Therefore, if past event information is examined, the reliability of future traffic prediction information becomes high [
3,
4,
5,
6].
In addition, various studies related to artificial intelligence and data security [
7] are underway. Still, what is most important is the pre-processing part of these data. In the field of artificial intelligence, if the relationship between data is not checked in advance in data extraction for learning, efficient learning cannot be performed. Therefore, the analysis of data using structured and unstructured data is a part to be studied continuously. Determining the relationship between data can be the basis for various studies; if it can be estimated by itself, the burden of hardware through complex algorithms can be minimized. In particular, systems such as support vector machine (SVM) and fuzzy may feel backwards to the times, but it is because the economic cost of the system is small in the system configuration.
The intelligent transportation system can consequently reduce the stress of traffic congestion and become a criterion for minimizing inefficient costs in the economic and industrial sectors. In other words, a large volume of traffic occurs on a specific road; still, if the traffic network is expanded without accurately recognizing its cause, social costs will increase. Moreover, the main cause is the increase in traffic volume for the next two to three years due to the periodic occurrence of certain events around the area, so the transportation network is expanded.
In this paper, we try to solve this problem by using correlation analysis to replace data by day of week and to select the most similar day of the week data to increase the reliability of traffic estimation. We propose a system that reflects event information, which are construction information and event information data corresponding to the relevant area that can be referenced on the Internet. In order to minimize errors that may occur by guessing an area where no such event occurs, we try to analyze the correlation analysis of calculating the net traffic volume.
The rest of this paper is organized as follows: related work is presented in
Section 2;
Section 3 shows the overall structure of the proposed system;
Section 4 discusses the experimentation and evaluation;
Section 5 presents the conclusions and further research.
3. Proposed System Architecture
Figure 3 shows the entire architecture proposed in this paper. In this system, the structured data and unstructured data are saved in the general database using Web Crawler and Data Extractor. The FCM clustering module is used to analyze the structured data, and the unstructured data are typically handled based on LSA clustering [
16].
Here, analyzing the structured data means predicting whether the traffic is increased for the date. In addition, analyzing the unstructured data means finding and reflecting certain sentences including events that affect the traffic volume. Thus, the system will select the appropriate sentence and predict the date of the incident in relation to multiple information. Nonetheless, the traffic volume corresponding to the estimated date is determined by the data related to the event and the other traffic volume used as the traffic volume without the event, because the traffic volume is divided into two: one that is influenced by the event information, and one that is not affected by the event information [
17,
18,
19,
20].
Therefore, users can use the event so that they may guess the value of the event in the future in our system [
21,
22,
23,
24,
25]. If they put it in our system, they can see the included event of traffic volume they choose. Not including the event of traffic volume can also be predicted by our system, because this system is based on pure Big Data that are traffic Big Data except the event information when collecting the Big Data.
The presented structure can be divided into structured data and unstructured data, and structured data are implemented using Fuzzy Inference as shown in
Figure 4. In the algorithm of
Figure 4, the Fuzzy Number is calculated with the group created using FCM clustering, and the calculated Fuzzy Number and Rule are applied. When the inference model is created, the final data are estimated by Defuzzification.
In detail, Fuzzy Inference Engine is an engine for inferring structured data, and it sets the number of inputs, outputs, and Membership Functions based on a large amount of existing crisp structured data and creates a rule. After that, the crisp value entered by the user is calculated using the Membership Function and Rule. The Fuzzy Inference engine consists of Fuzzy C-Means (FCM) Clustering, Fuzzy Number Calculator, and Defuzzification.
First. FCM Clustering: In FCM clustering, the number of input/output variables and the number of Membership Functions are set, and clustering is performed based on the input data. FCM consists of Fuzzy Number and Rule.
Fuzzy Number: Defines and stores the Membership Function based on the maximum, minimum, and center values calculated in FCM clustering.
Rule: Creates a Rule based on the calculated Membership Function and actual result value and saves this value.
Second. Fuzzy Number Calculator: Calculates the Fuzzy Number based on the crisp value and Membership Function inputted by the user from outside.
Third. Defuzzification: Calculates the crisp value using the area center method by applying the calculated Fuzzy Number and rule.
In the case of unstructured data analysis fuzzy reasoning system algorithm, it is analyzed as shown in
Figure 5. When major information in several documents is inputted, multidimensional analysis is performed through the LSA engine. That is, the singular points of each word are extracted and stored in matrix form. It is delivered for analysis in FCM Inference of major environmental information and unstructured data, and the traffic volume for the last specific day is estimated.
4. Implementation and Evaluation
Figure 6 shows the simulator of FCM. The FCM simulator performs clustering using the actual traffic volume and precipitation, and then estimates the traffic volume and traffic time corresponding to each day of the week. As shown in the figure, on Saturday, the traffic volume is estimated to be 40,666, and the traffic time is 274,500 ms. In actual implementation, such observation tool is not required but produced separately for the review of the actual estimate.
Figure 7 shows the analysis of word distribution using LSA. In the LSA simulator, entering a value on the Document Input Window on the upper left enables monitoring the decomposition of each document token by the Tokenization Window on the lower left and checking the tokenized words on the Transition Table Window at the upper center. Word Distribution on the lower right is for viewing the distribution according to the correlation of words; the Structured Word Window on the upper right can confirm the final standardized Big Data.
In this paper, we construct a system using traffic volume between Busan and Gimhae in June 2016. These data were used in previous studies, and the final goal was to predict the traffic volume in July 2016. For this purpose, the actual July data were collected together, and our system also estimated the July data and compared them.
By using the Membership Function created using FCM clustering, the rule for the result value is created, the Fuzzy Number is estimated for the value entered afterward, and the result is calculated by converting it into the final crisp value.
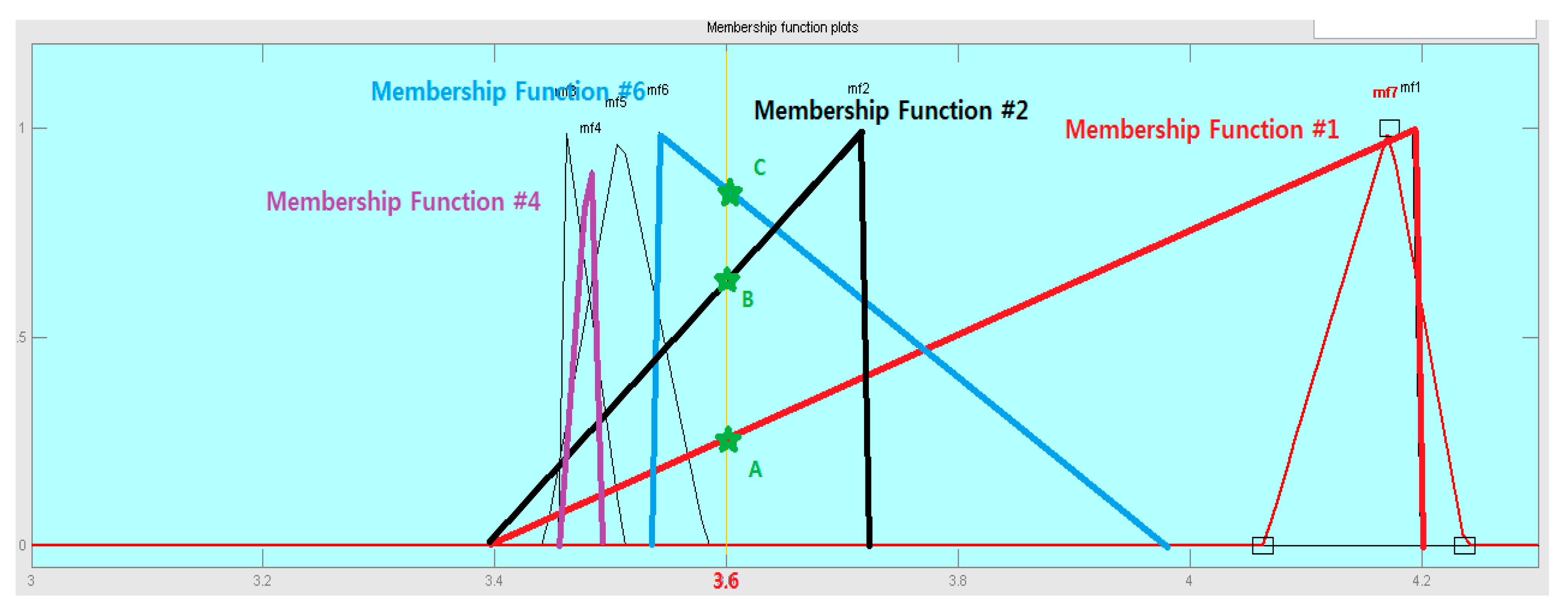
Figure 8 is a visualization of the learning results for the Big Data for the month of June based on the crisp value of traffic volume using MatLab. In this paper, this part is written as a Java program. Learning is represented by the slope of 7 Membership Functions, showing that the range of fluctuations according to the day of the week is irregular and varied. In particular, 3 Membership Functions (1, 2, 6) pass through 36,000 traffic points, which means that the three values are set according to the rule decision by prior learning.
In particular, membership functions 1 and 6 have a large difference in Fuzzy Numbers depending on the selection result. This means that, due to the characteristics of the Fuzzy System that applies the area-centered method during Defuzzification, center shift occurs considerably to the left or right, with the returned result value eventually fluctuating. This result is considered to be the ITS characteristic, and it can be seen that it reacts sensitively to small values; this sensitivity shows that precise measurement of information is possible.
This system is designed to predict the last one week and is composed of a dual system of 1 input 1 output and 2 inputs 1 output; the whole data are divided into days with and without rainfall, and learning is conducted. This is because, in the case of measured data, the test is performed based on the data in which the peculiar value has already been reflected, so it is considered to obtain more intact data.
Rainy days are classified according to the amount of precipitation, and learning is applied to enable more efficient and accurate prediction; FCM is applied to cluster large amounts of Crisp and fuzzy values accurately.
This result is shown in
Figure 9. Unlike other weeks as shown in
Figure 9, traffic on Sunday and Friday sees an irregular increase in the 4th week, due to the international motor festival held on the 4th of June. Therefore, if the international motor festival was not held, we wanted to know the traffic volume that would be generated.
It collects unstructured data (construction information, event information), divides it into an extractor, and calculates the final machine learning basic data through formalization using date marking characteristics.
First: Based on event information, it is decomposed into behavioral units and stored in an array.
It creates a matrix of a column consisting of document information and a row consisting of word information. In this study, the matching results for 1214 words after duplicate removal among 1754 words are used.
Select the most similar documents. In the study, the similarity values for the words “event”, “performance”, and “Busan” are calculated, and the highest similarity value is document #3, which is confirmed as a document for the Busan International Motor Show 2016.
Figure 9 is a visualization of the Membership Function applied with unstructured data. Function #1, Function #2, and Function #6 are showing a lot of fluctuations, and it can be seen that the existing points A and C have changed from 3600 traffic volume. In particular, the center point of Function #1 has moved to Saturday, so the event is held on Saturday. You can see a sharp increase in traffic volume.
As shown in
Figure 10, it is possible to estimate the result of the traffic volume for each week in the same way as above.
We thought that we had to separate the data with the event and without the event to solve the problem. We also realized that we had to consider how to get pure traffic value that is not affected by the events. Nonetheless, it is difficult to determine the volume of traffic on the scale of the event from the data with the actual event; rather, it would be easier to estimate the volume of traffic when the event was originally included, but there was no event. This is because we can find traffic on a similar day.
Figure 11,
Figure 12,
Figure 13 and
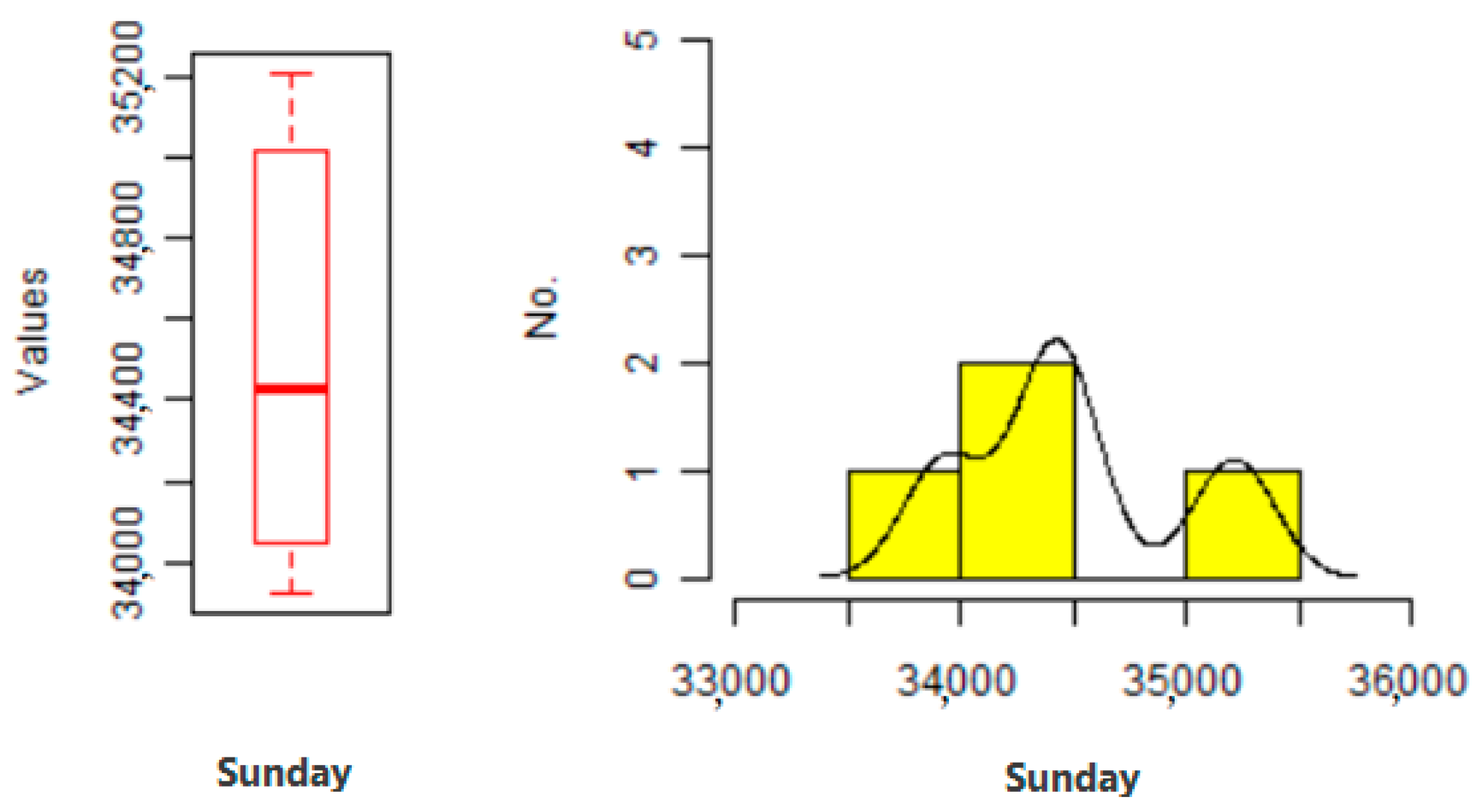
Figure 14 show the distribution of data with and without event data, among which
Figure 11 shows data for Sunday. Here, we can see that the average point is downward. This means that data for the first week, second week, third week, and fifth week on Sunday are in the range of 36,000 vehicles to 34,000 vehicles, and that the data of the fourth week are in the range of 40,000 vehicles to 42,000 vehicles, which is consistent with the analysis in
Figure 10. We analyzed the unstructured data and predicted an increase in the number of vehicles due to the motor show in the fourth week.
In order to obtain such variance data, we refer to the traffic information at the past time for the traffic volumes at the time of the event. Of course, too old information was not used. This is because the natural increase due to the development of the region must be considered.
4.1. Implementation
These Big Data are an increased value of traffic volume due to environmental information. If the user wants to analyze the traffic volume when there is no event, it can be regarded as a noise value. Therefore, this value is deleted. Big Data analysis after deletion is shown in
Figure 12, where the middle value and the average value move to the center as the noise disappears. In this paper, we examine the traffic volume on the day when an event occurs. If the user wants the volume of traffic on the day without an event, delete the data on the day when the event occurs.
In this section, an arbitrary rank value is assigned to each day, and the correlation coefficient is calculated first followed by the t score using the determined correlation coefficient. t means the value of the horizontal axis belonging to the range of 0.5% in the dispersion. The final
p-value is calculated from the t score. The results of using the Statistical Analysis Tool (SALT) program are shown in
Table 1 and
Figure 15.
In
Figure 15, the vertical axis and the horizontal axis represent the volume of traffic corresponding to each day of the week. It can be estimated as a more consistent value if the increased size is identical, and the closest accordance value is shown to the center line between Monday and Sunday.
In
Table 1, for each day of the week, we apply the Spearman correlation coefficient. The
p-values of Thursday and Wednesday, Saturday and Friday, and Monday and Sunday are correlated to less than 0.05, and the value of the relevant event is changed by the correlated traffic value.
Nonetheless, there was a matter that could not be considered relevant in the remaining relationship. In this paper, we select the lowest volume of p-value. In the results of this experiment, we calculated the daily and weekly correlations and replaced the values on the day of the event. In other words, there was a correlation between Monday and Sunday and between the 4th and 2nd weeks. Therefore, the value on the 4th Sunday could be regarded as correlated with the value on the Sunday of the 2nd and changed. This way, we find the highly correlated week and day and increase the accuracy of the average data by assigning the derived value to the place with the excluded data included with the event.
In
Table 2, for each week of the week, and we applied in same way as
Table 1.
4.2. Evaluation
Table 3 describes the forecast of the traffic value with the proposed system and the existing system. There were events on Tuesday and Monday in June, but not in July. If we estimate the data for July, except for the traffic volume increased by the event, we should estimate the volume of traffic on Tuesday and Monday in July. Therefore, the traffic value on the day including the event information was removed, the traffic volume on the day the event was not included was predicted according to correlation analysis, and the data was replaced. As a result, we can see that it is better than the existing results.
Nonetheless, on Sunday, the event information was assumed to have been reflected, and the existing data were removed and the substitute data were inserted; thus resulting in lower reliability. This is expected to require more scrutiny from unstructured data analysis.
Figure 16 is a graph comparing the existing system with the proposed system in July. On Monday and Tuesday, we found that the proposed system is closer to the actual data than the existing system. Nonetheless, on Saturday, we found that the proposed system’s traffic information is not accurate compared to the existing system. The results show that pure traffic information is not detected accurately on Saturdays when many events occur, and this difficulty is found in this part.
Meanwhile, our goal was to estimate the average traffic volume. Therefore, we implemented the traffic volume estimation system with FCM. However, when estimating from these FCMs, it is necessary to use the old traffic volume, the problem is that the actual traffic volume information is traffic volume including regional influence.
Therefore, we preemptively used the LSA to calculate an estimate including regional traffic volume so that we can know the extent of regional impact on the FCM.
After that, we began to study how statistical techniques could be used to exclude local traffic.
The scientific contribution you mentioned is in a method of comparing the traffic volume estimated using the LSA (including regional events) and the traffic volume without regional events, and is based on systemizing this.
The importance of this is that it is difficult to measure traffic volume in the absence of specific events from the Big Data collected. This is because a lot of problems arise when designing such as urban planning with traffic volume that includes these short-term specific events. As a result that the event can end at any time, it can disappear.
5. Conclusions
Most of the actual data are affected by the surrounding environment information, and we have researched these influencing factors. If we can analyze these elements well, it will help us study actual data. Nonetheless, such data may or may not be readily recognizable by us, and it is especially difficult to define clearly the parts that affect traffic volume such as traffic volume analysis. Therefore, a system that accurately predicts the volume of traffic without an event is required, but this research is still lacking until now. Actually, it is true that there are many difficulties when we use environment information. Nonetheless, we need to attempt such to implement the system.
Therefore, we proposed Big Data prediction systems based on various kinds of information such as structured data and unstructured data. In addition, the proposed system was applied with statistical method in order to address the traffic volume Big Data containing specific environmental information.
We also proposed applying the system by statistical method to process the traffic Big Data including specific environmental information. We implemented the proposed system and confirmed that the results were more efficient and more accurate than the existing system. We also expect pure data without event information to be applied to various systems requiring traffic information.
Although we could not analyze various other inference systems in parallel in this research, we could obtain net data that did not include environmental information using various algorithms. These results are better than those of one exact algorithm only. Based on the results, we could predict the correct volume of traffic according to the condition of environmental information.
In further research, we intend to reinforce environmental information in unstructured data analysis and to include analysis related to neural network.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}