
Efficient Depth Map Creation with a Lightweight Deep Neural Network


Abstract
:1. Introduction
2. Related Work
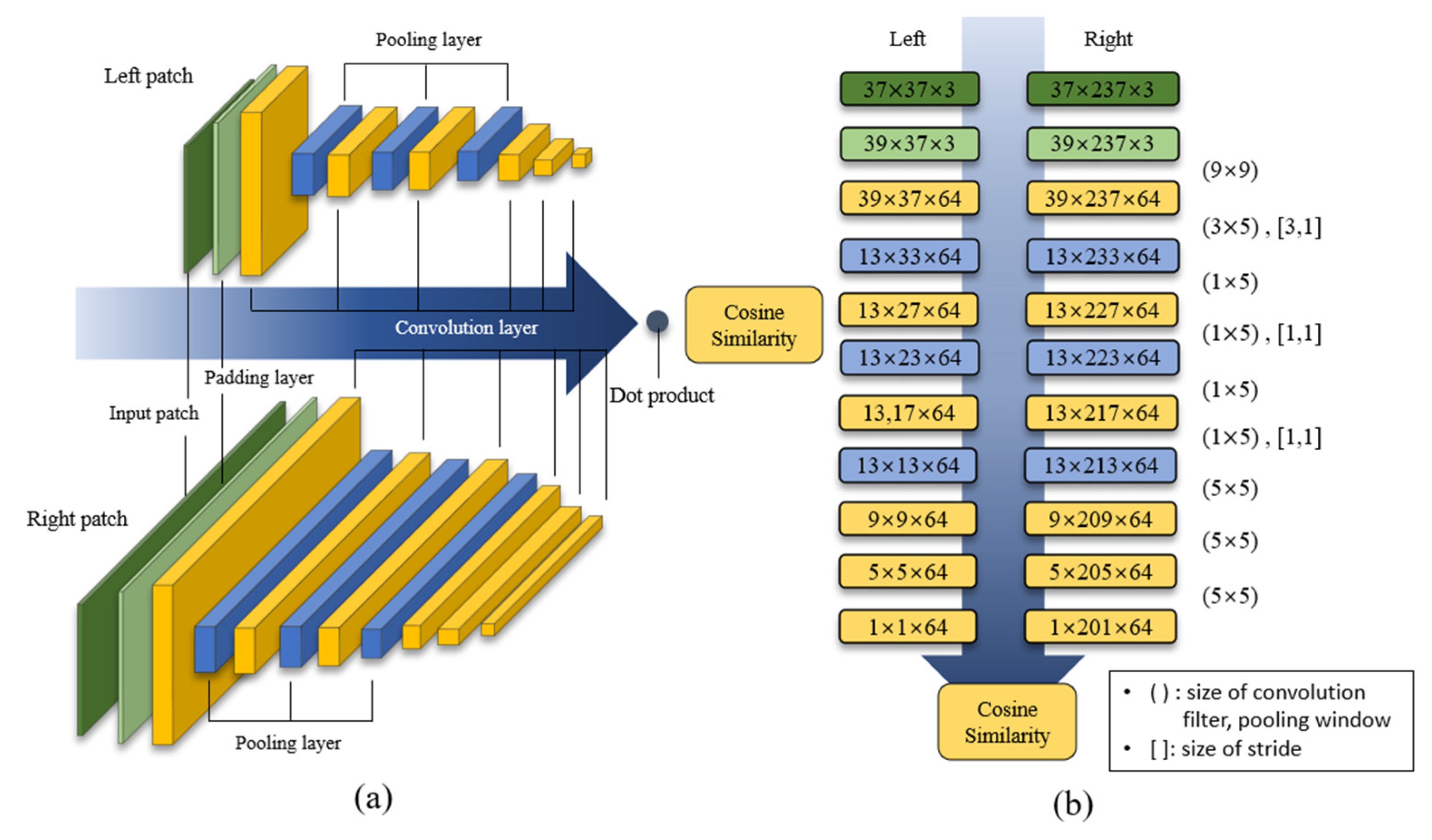
3. Proposed Method
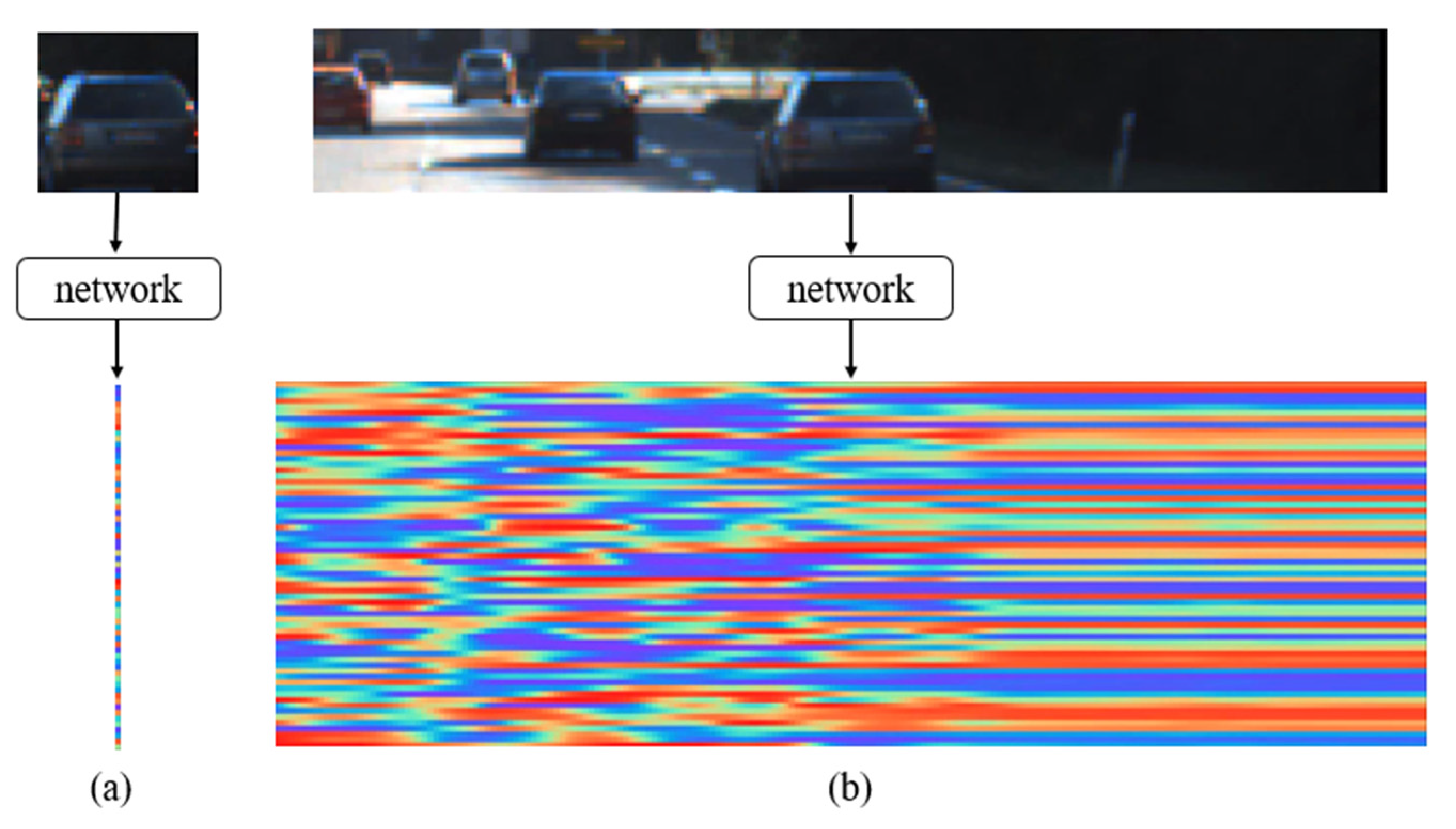
Small Network Algorithm
4. Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Song, T.; Kim, Y.; Oh, C.; Sohn, K. Deep Network for Simultaneous Stereo Matching and Dehazing. In Proceedings of the British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Liu, J.; Ji, S.; Zhang, C.; Qin, Z. Evaluation of deep learning based stereo matching methods: From ground to aerial images. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 593–597. [Google Scholar] [CrossRef] [Green Version]
- Hamzah, R.A.; Hamid, A.M.A.; Salim, S.I.M. The Solution of Stereo Correspondence Problem Using Block Matching Algorithm in Stereo Vision Mobile Robot. In Proceedings of the 2010 Second International Conference on Computer Research and Development, Kuala Lumpur, Malaysia, 7–10 May 2010; pp. 733–737. [Google Scholar]
- Luo, W.; Schwing, A.G.; Urtasun, R. Efficient deep learning for stereo matching. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5695–5703. [Google Scholar]
- Xu, B.; Zhao, S.; Sui, X.; Hua, C. High-speed Stereo Matching Algorithm for Ultra-high Resolution Binocular Image. In Proceedings of the 2018 IEEE International Conference on Automation, Electronics and Electrical Engineering (AUTEEE), Shenyang, China, 16–18 November 2018; pp. 87–90. [Google Scholar]
- Zbontar, J.; LeCun, Y. Stereo matching by training a convolutional neural network to compare image patches. J. Mach. Learn. Res. 2016, 17, 1–32. [Google Scholar]
- Zbontar, J.; LeCun, Y. Computing the Stereo Matching Cost with a Convolutional Neural Network. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1592–1599. [Google Scholar]
- Patrick, B.; Mazomenos, E.; Stoyanov, D. Widening Siamese architectures for stereo matching. Pattern Recognit. Lett. 2019, 120, 75–81. [Google Scholar]
- Hamwood, J.; Alonso-Caneiro, D.; Read, S.A.; Vincent, S.J.; Collins, M.J. Effect of patch size and network architecture on a convolutional neural network approach for automatic segmentation of OCT retinal layers. Biomed. Opt. Express 2018, 9, 3049–3066. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.; Lai, Z.; Huang, G.; Wang, B.; Maaten, L.; Campbel, M.; Weinberger, K. Anytime Stereo Image Depth Estimation on Mobile Devices. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Ding, X.; Guo, Y.; Ding, G.; Han, J. ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, J. Rethinking the inception architecture for computer vision. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Wang, S.; Dong, J. Asymmetric filtering-based dense convolutional neural network for person re-identification combined with Joint Bayesian and re-ranking. J. Vis. Commun. Image Represent. 2018, 57, 262–271. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Sun, X.; Wang, L.; Yu, Y.; Huang, C. A Deep Visual Correspondence Embedding Model for Stereo Matching Costs. In Proceedings of the 2015 IEEE International Conference on Computer Vision ICCV, Santiago, Chile, 7–13 December 2015; pp. 972–980. [Google Scholar]

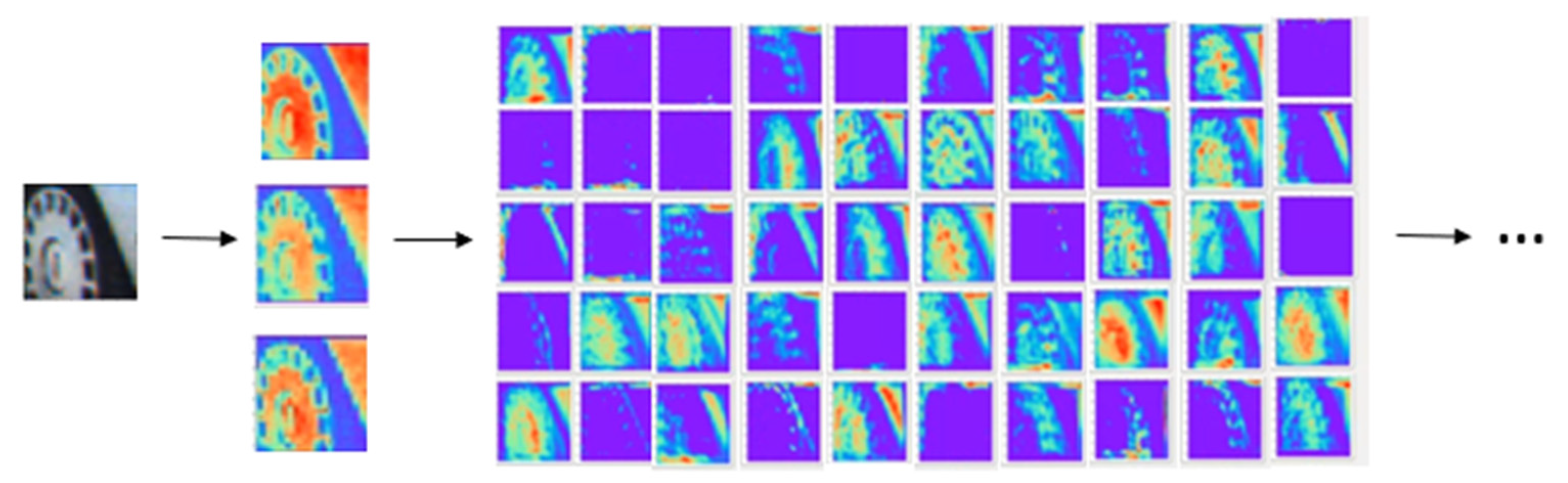



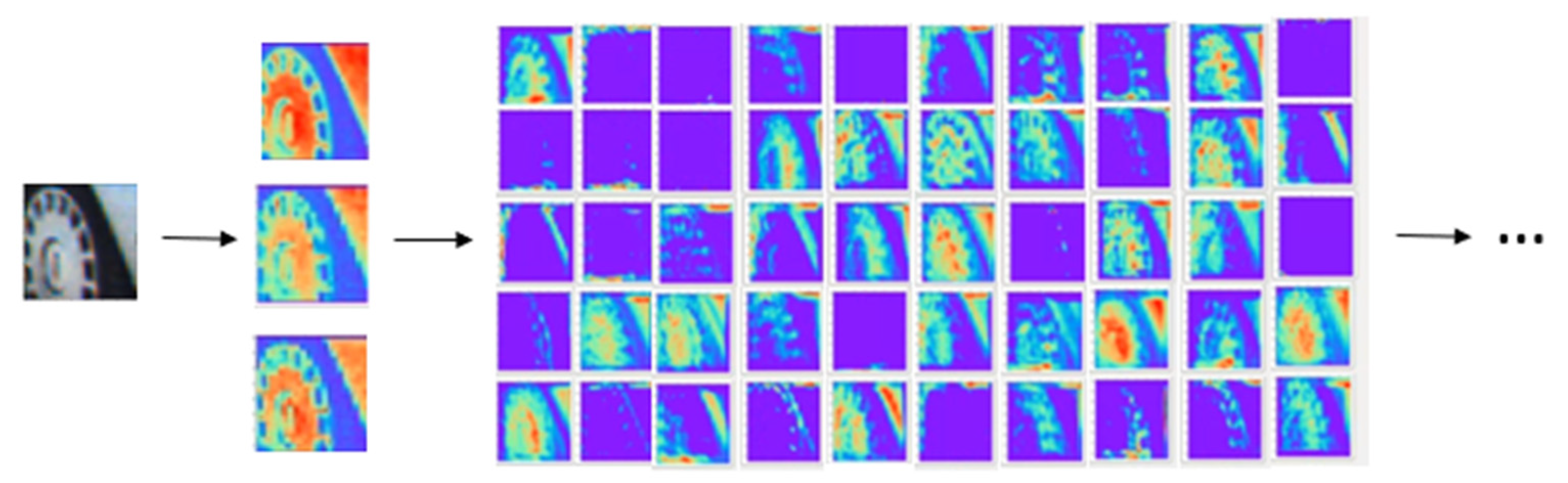
{kind=link}
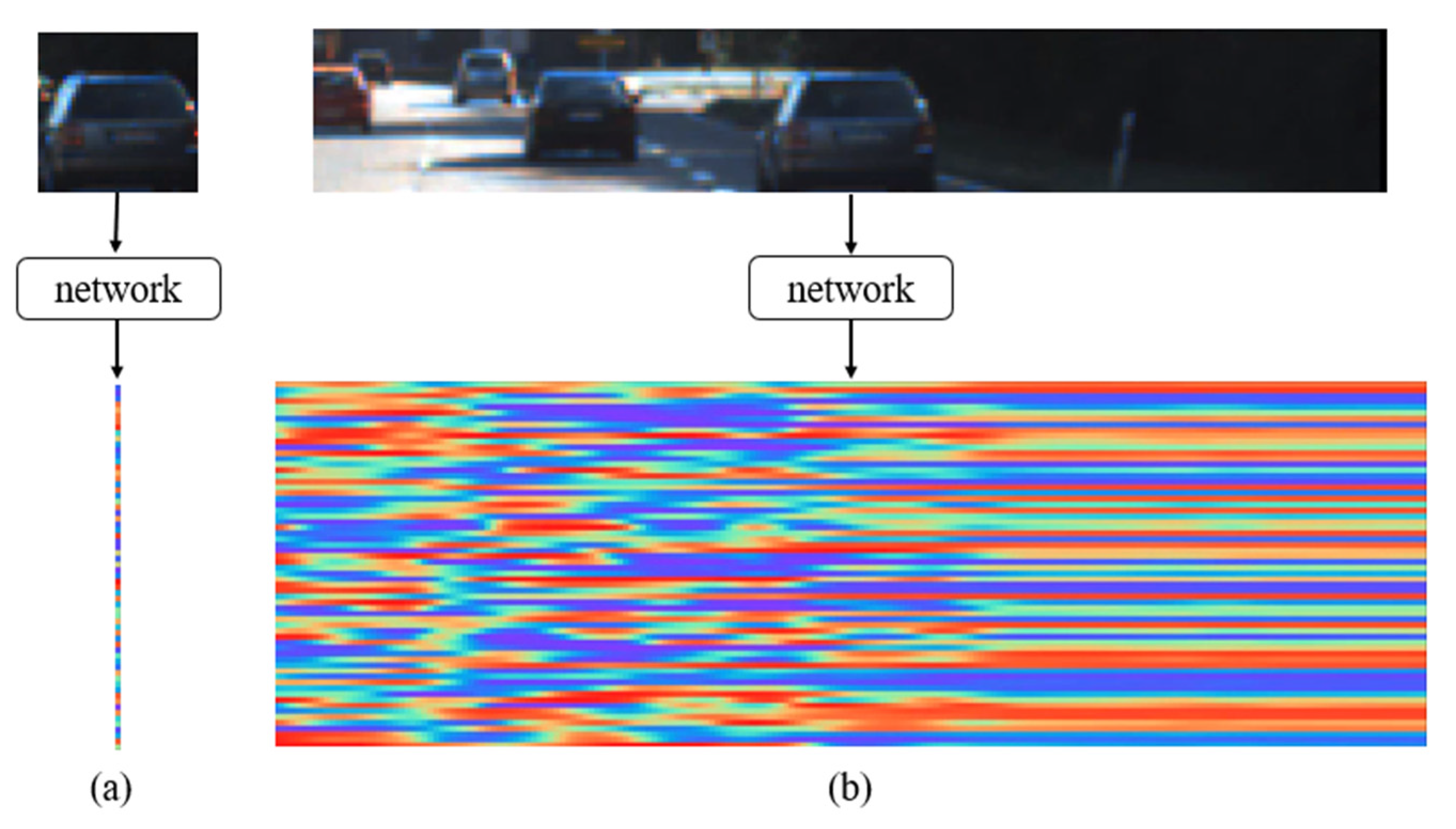
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Proposed | MC-CNN-Fast [6] | Patrick’s [8] | Luo’s (37) [4] | Luo’s (29) | Luo’s (19) | AnyNet [10] | ||
|---|---|---|---|---|---|---|---|---|
| Network Parameters | 382,016 | 263,104 | 436,288 | 694,112 | 562,432 | 297,216 | 43,269 | |
| Pixel Error (%) | 3 | 6.44 | 14.40 | 8.14 | 7.07 | 7.15 | 10.01 | 9.01 |
| 4 | 5.12 | 13.59 | 7.37 | 5.94 | 6.01 | 9.35 | 8.35 | |
| 5 | 4.44 | 12.72 | 6.23 | 5.29 | 5.34 | 8.56 | 7.57 | |
| Runtime(s) | 0.11 | 0.13 | 0.15 | 0.17 | 0.16 | 0.14 | 0.20 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, J.; Lee, S.-W. Efficient Depth Map Creation with a Lightweight Deep Neural Network. Electronics 2021, 10, 479. https://doi.org/10.3390/electronics10040479
Kang J, Lee S-W. Efficient Depth Map Creation with a Lightweight Deep Neural Network. Electronics. 2021; 10(4):479. https://doi.org/10.3390/electronics10040479
Chicago/Turabian StyleKang, Join, and Seong-Won Lee. 2021. "Efficient Depth Map Creation with a Lightweight Deep Neural Network" Electronics 10, no. 4: 479. https://doi.org/10.3390/electronics10040479
APA StyleKang, J., & Lee, S.-W. (2021). Efficient Depth Map Creation with a Lightweight Deep Neural Network. Electronics, 10(4), 479. https://doi.org/10.3390/electronics10040479