
Research on the Cascade Vehicle Detection Method Based on CNN



Abstract
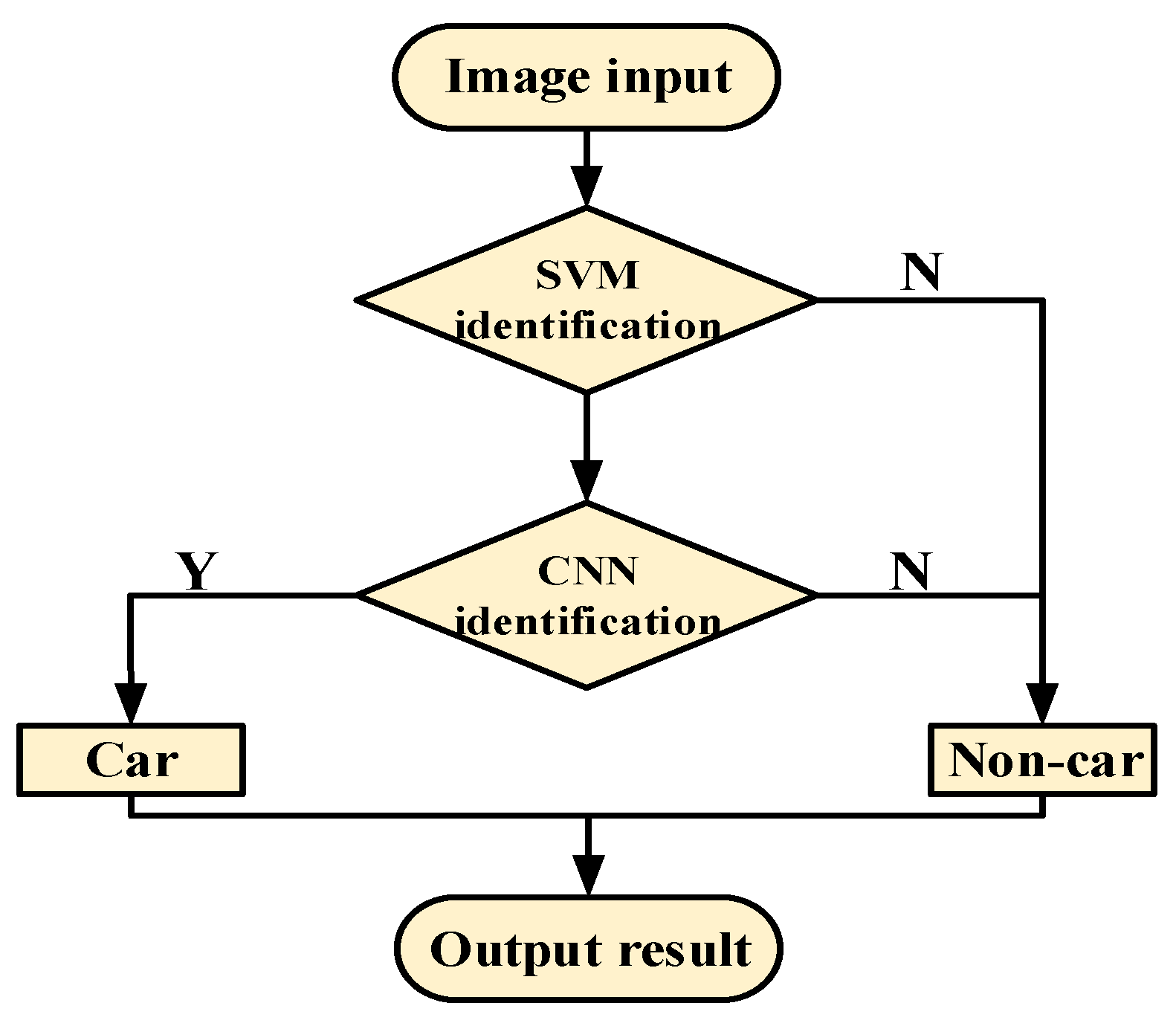
:1. Introduction
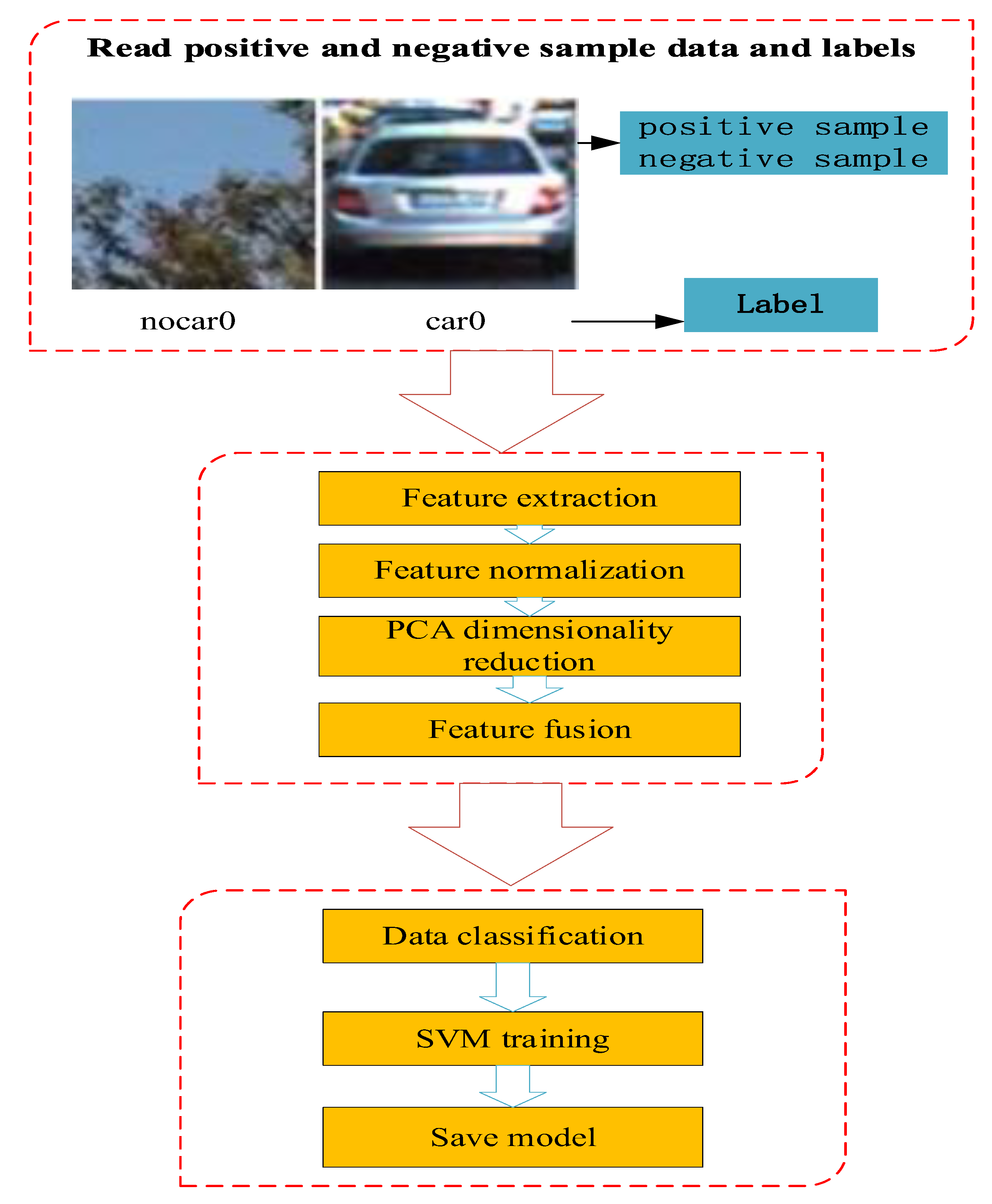
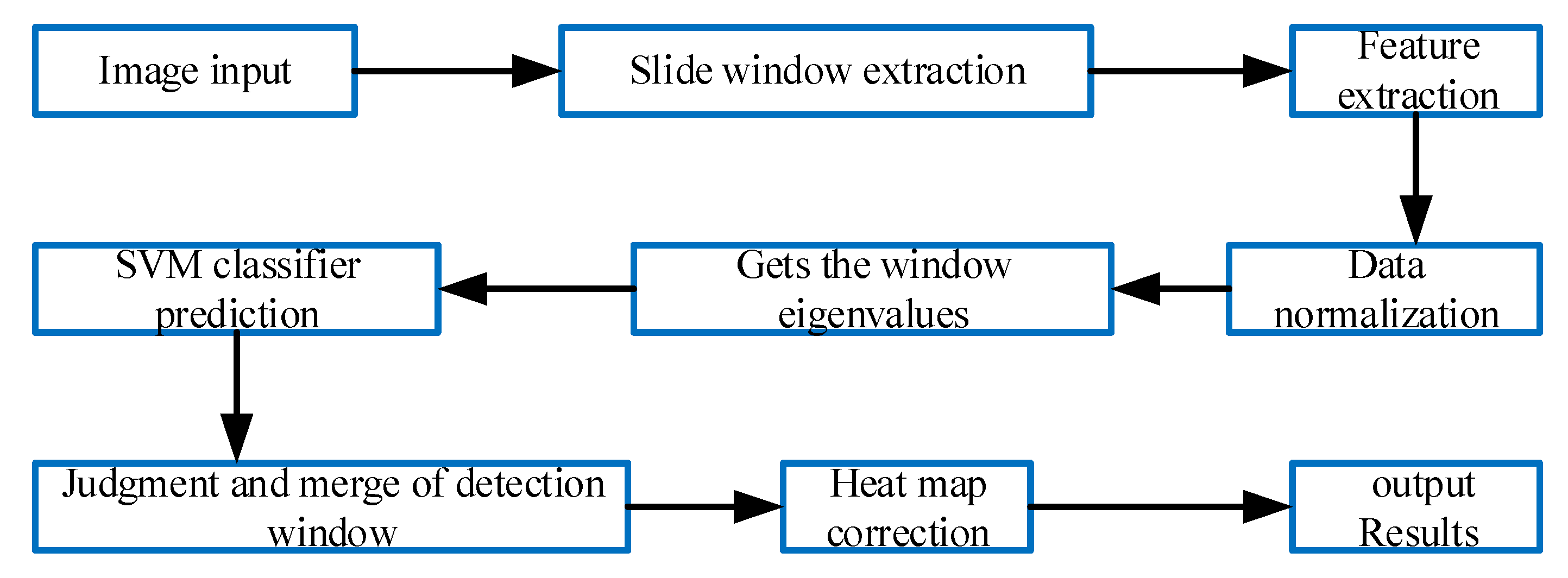
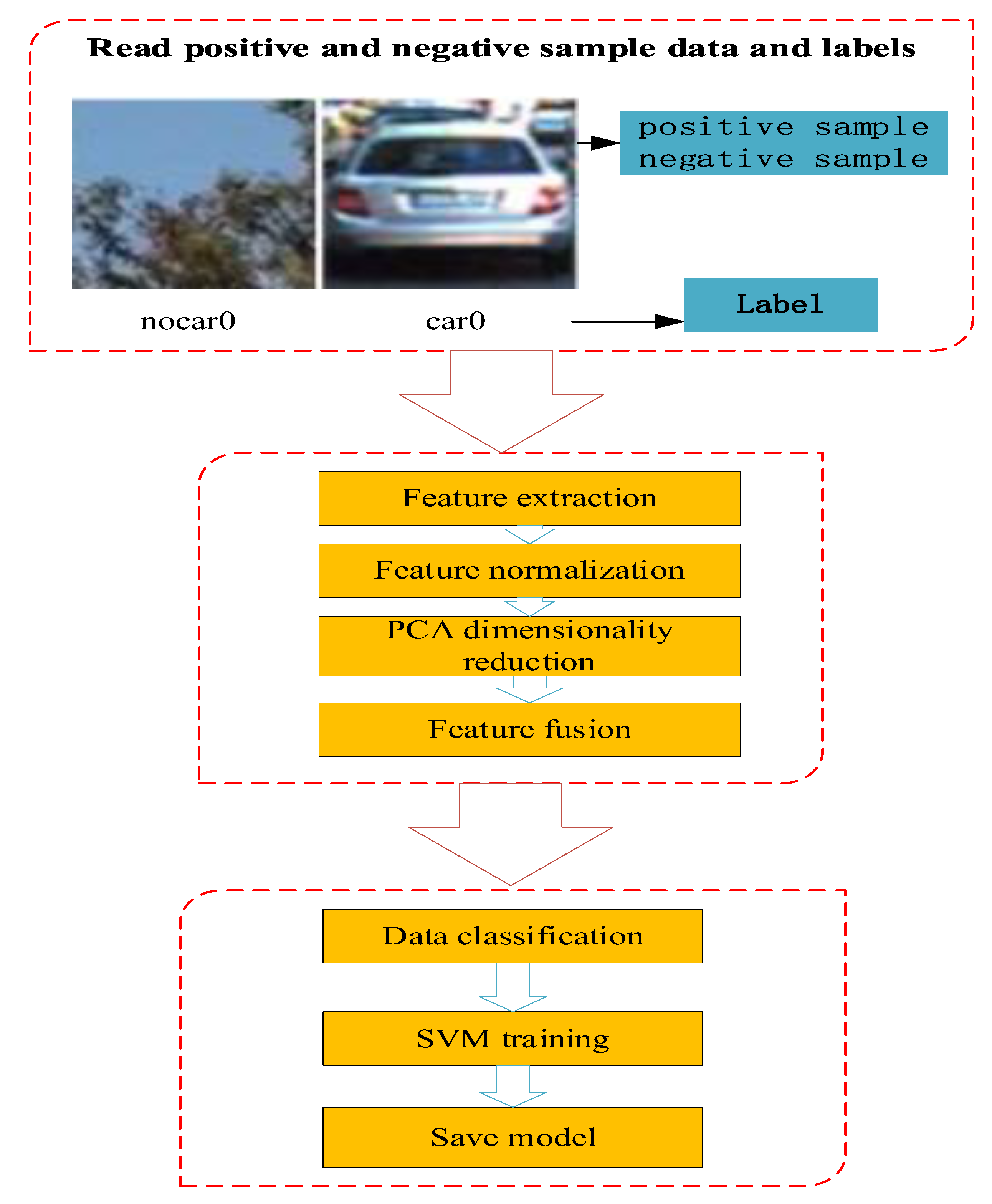
2. Multifeature-Fusion-Based SVM Screening
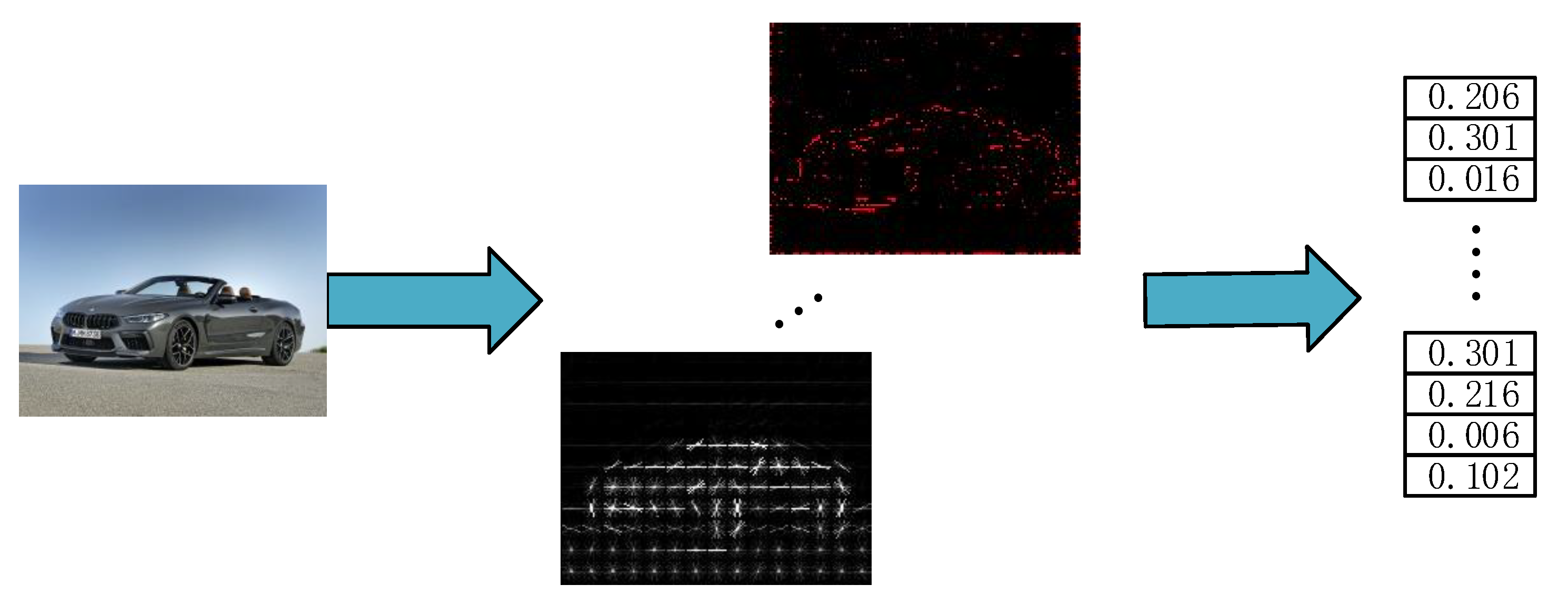
2.1. Front Vehicle-Feature Extraction
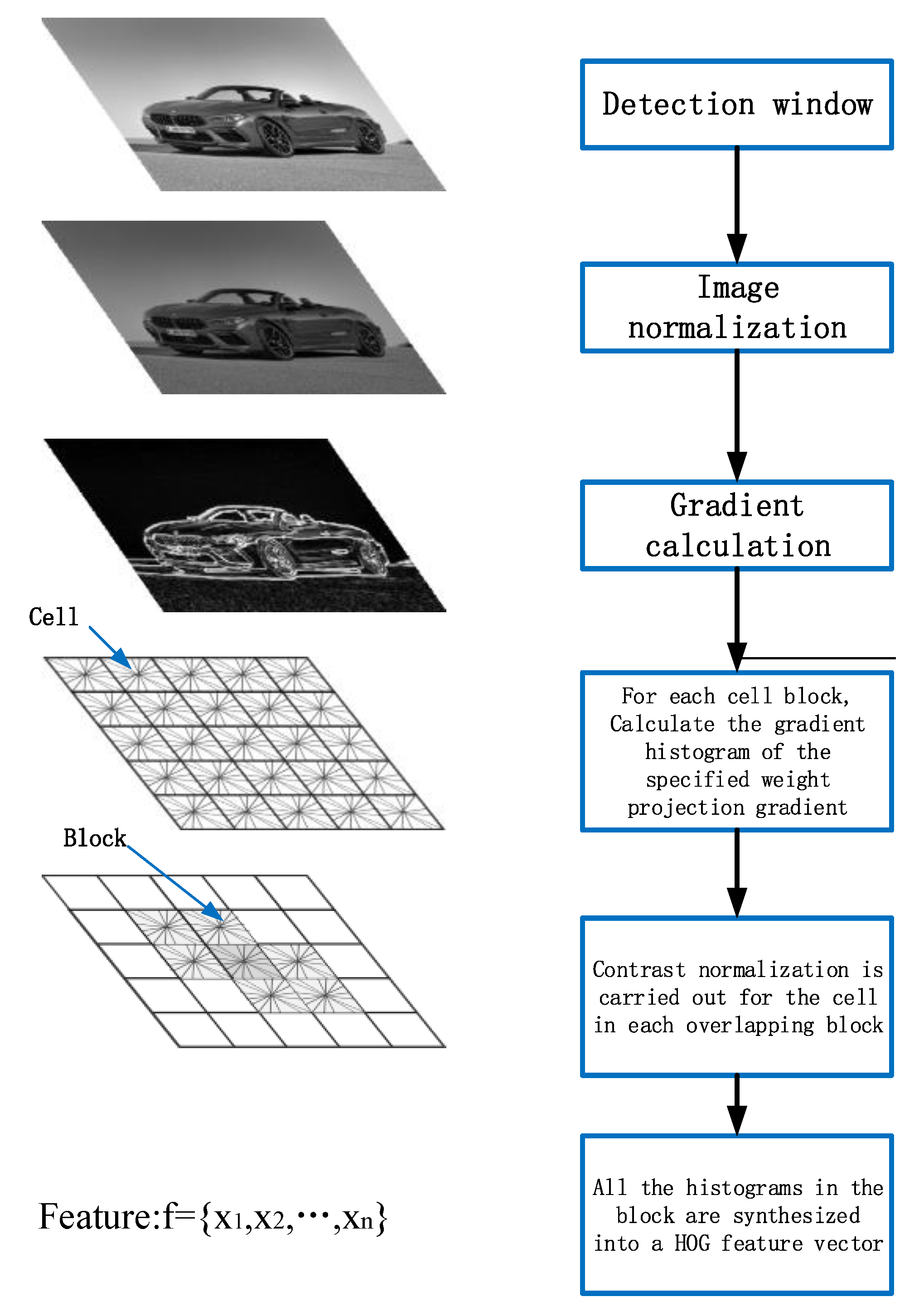
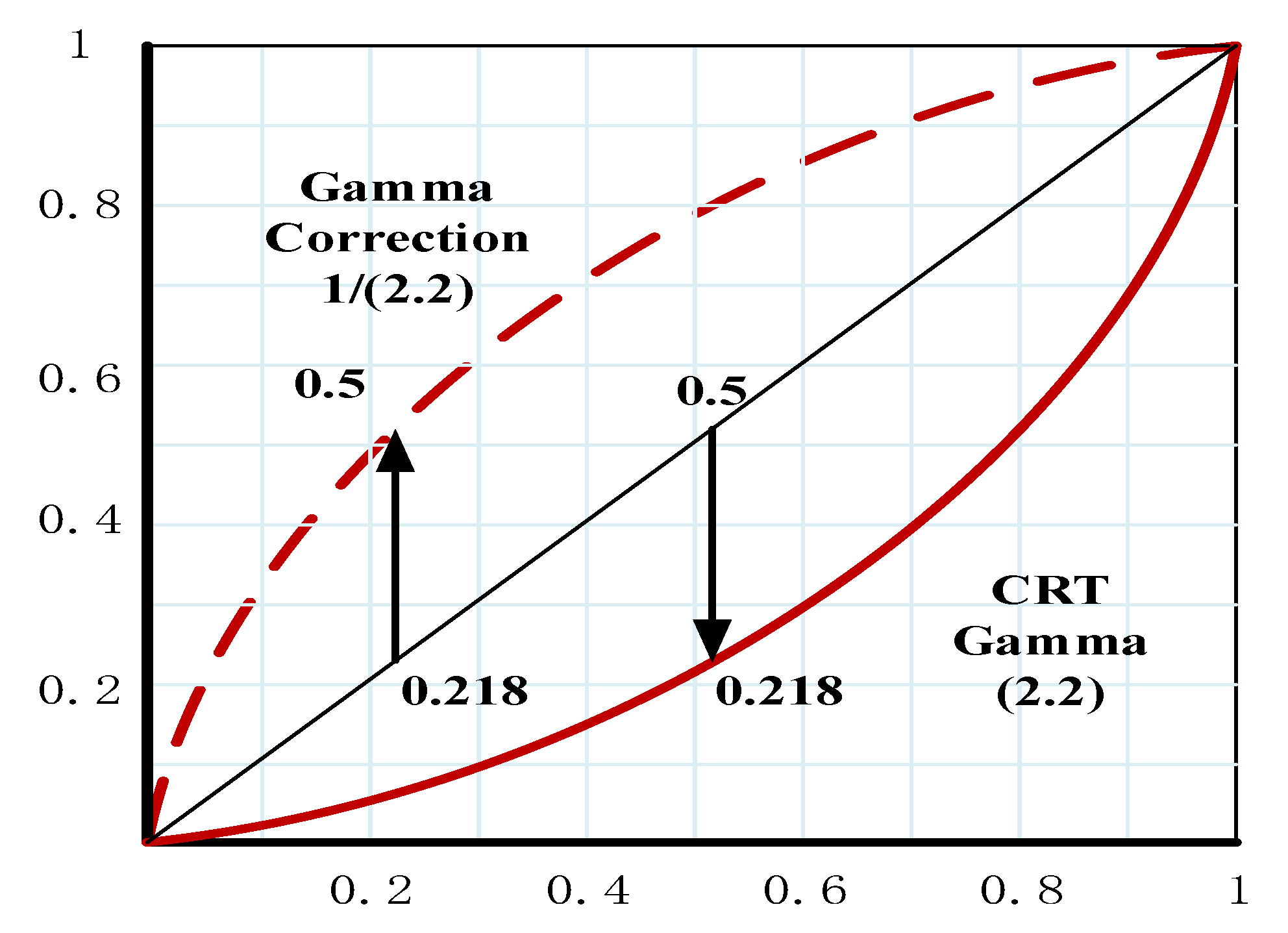
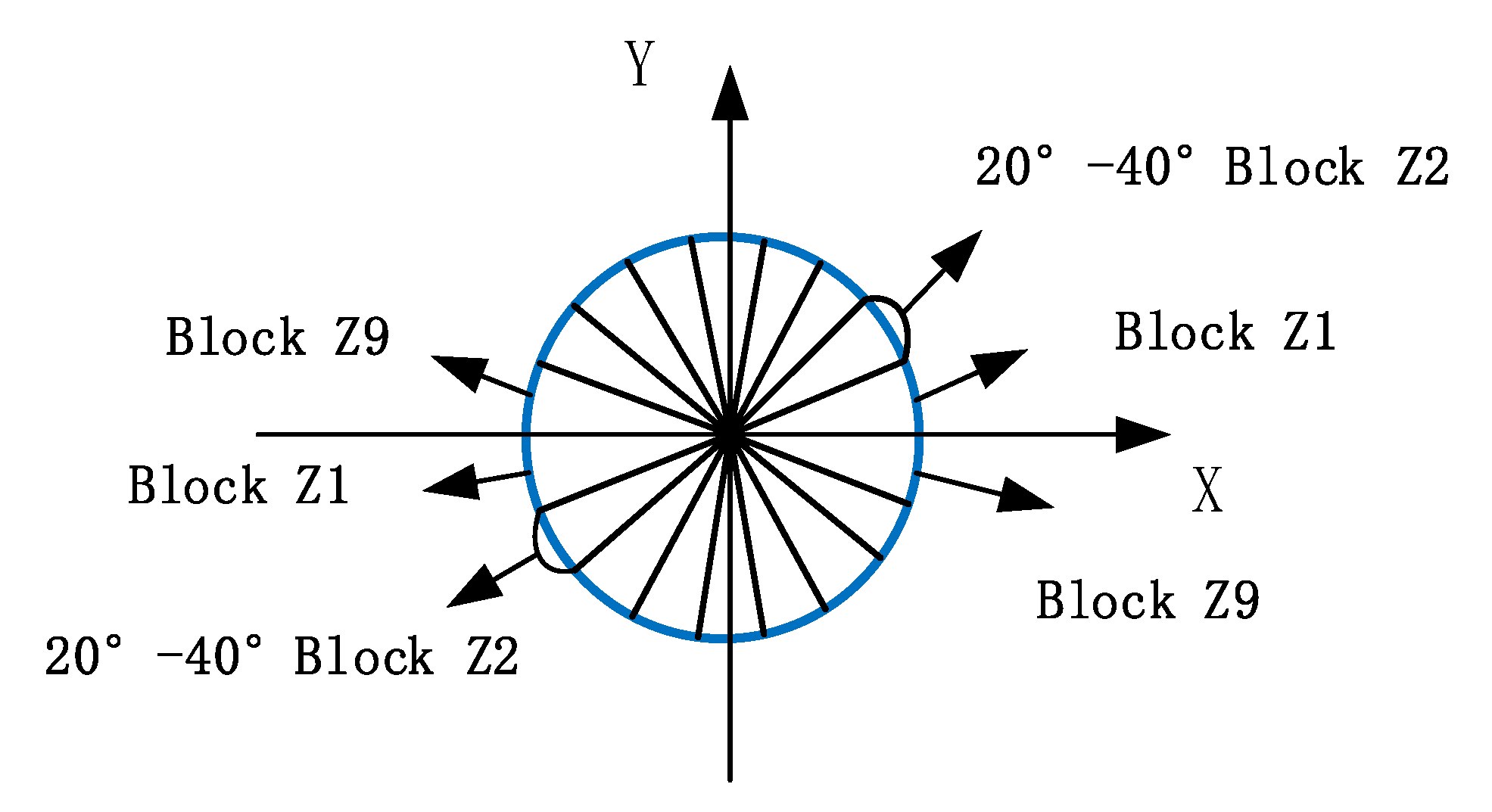
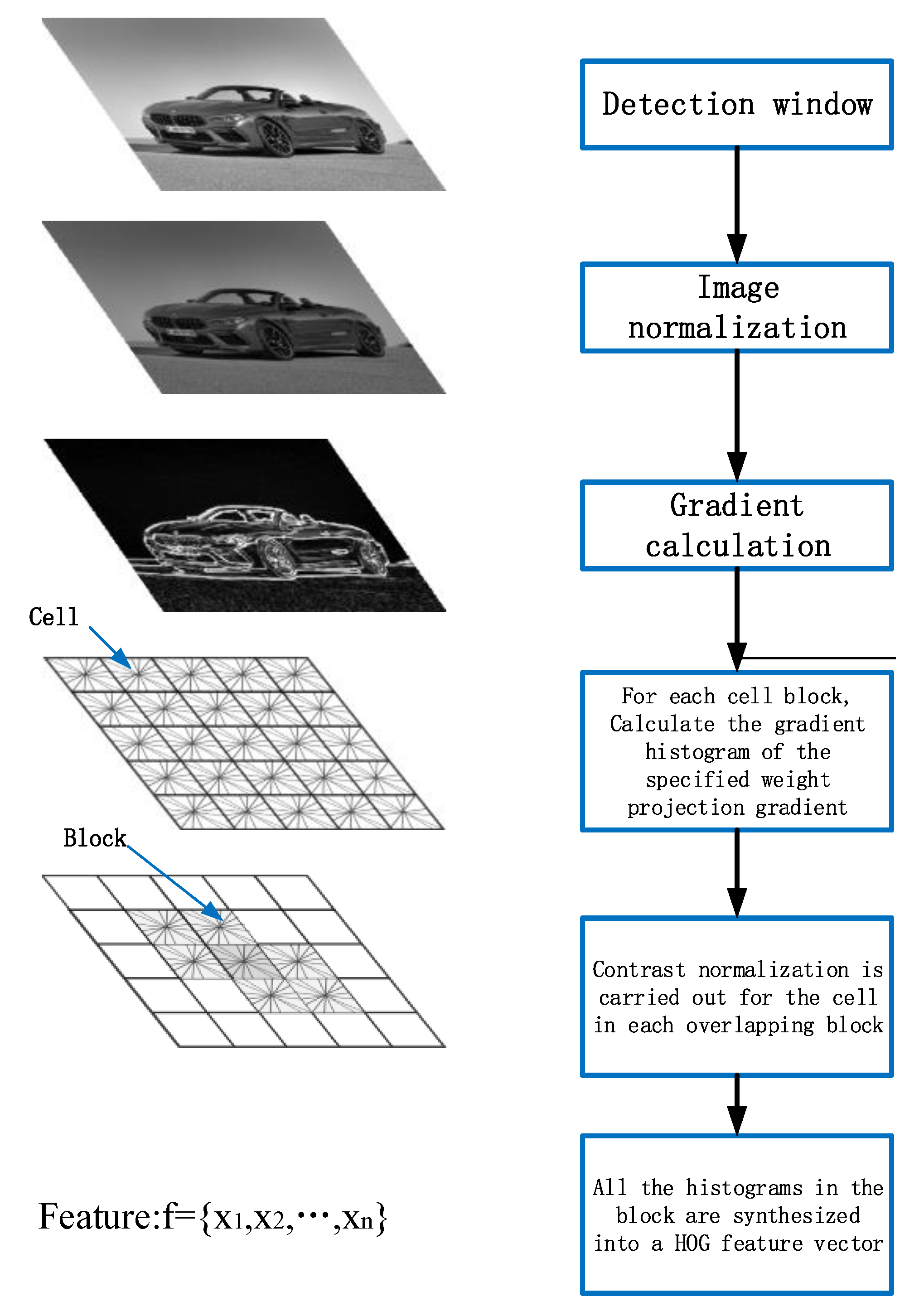
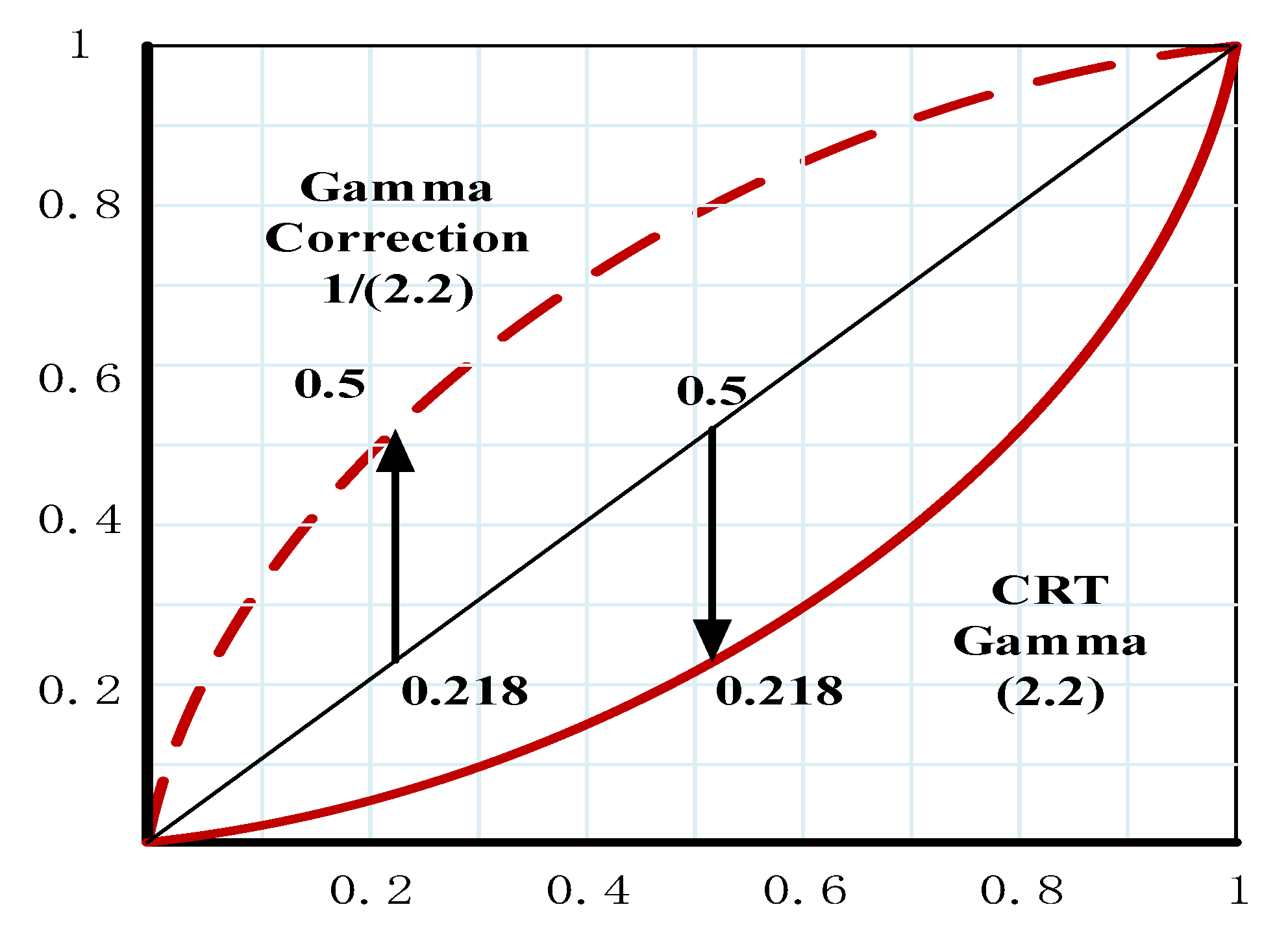
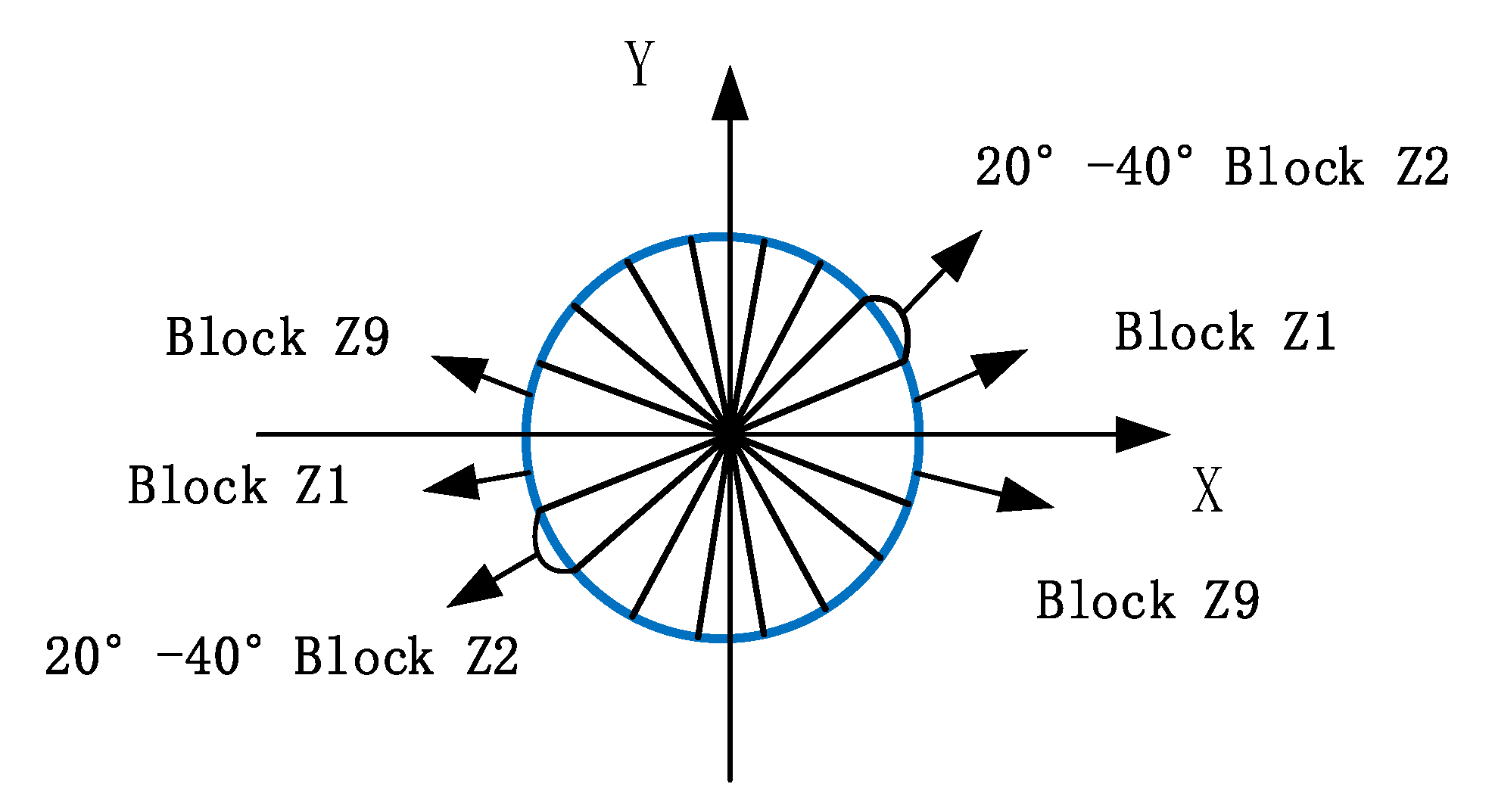
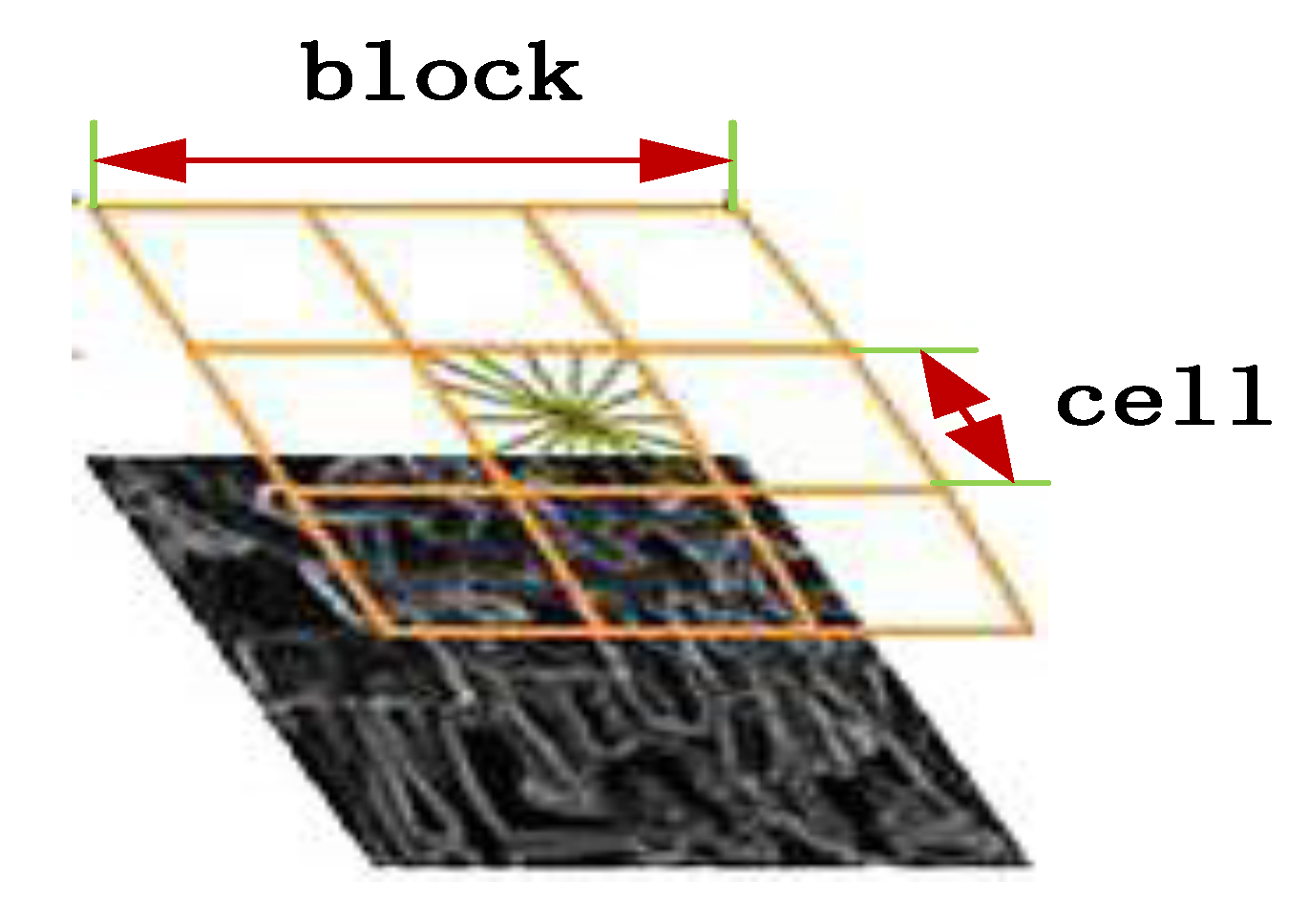
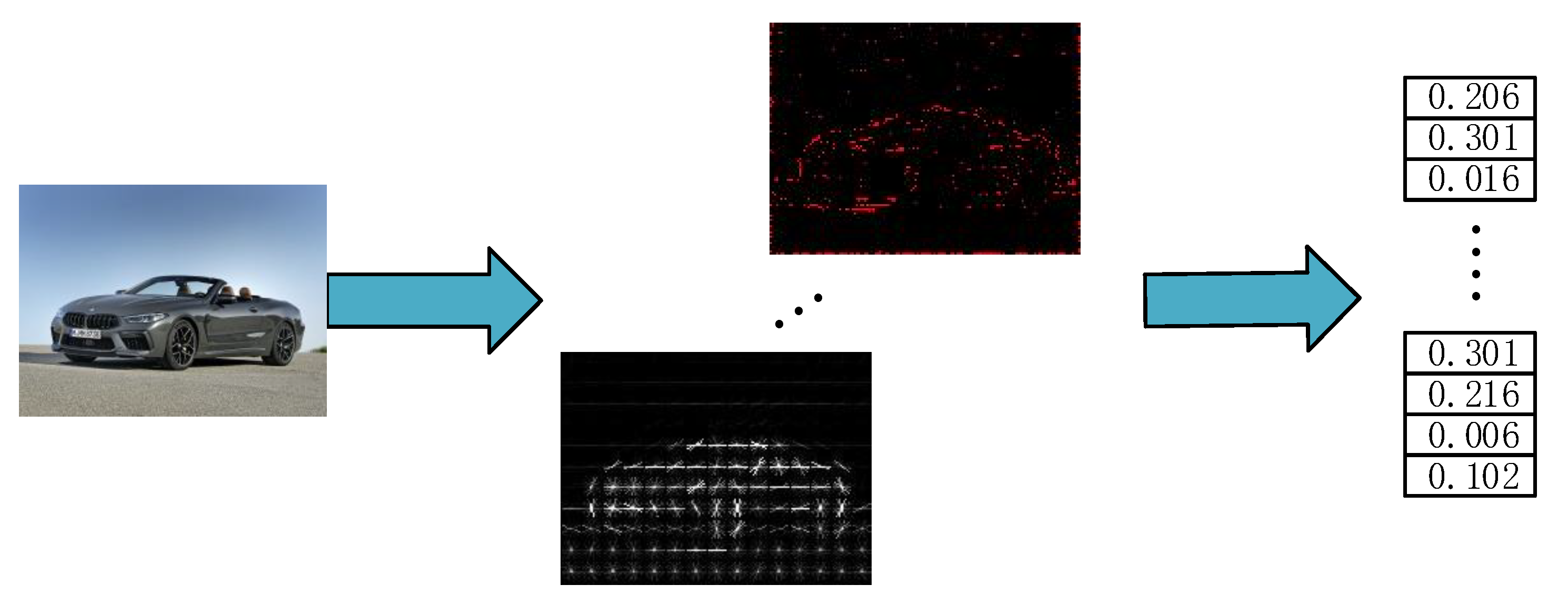
2.1.1. HOG Feature Extraction
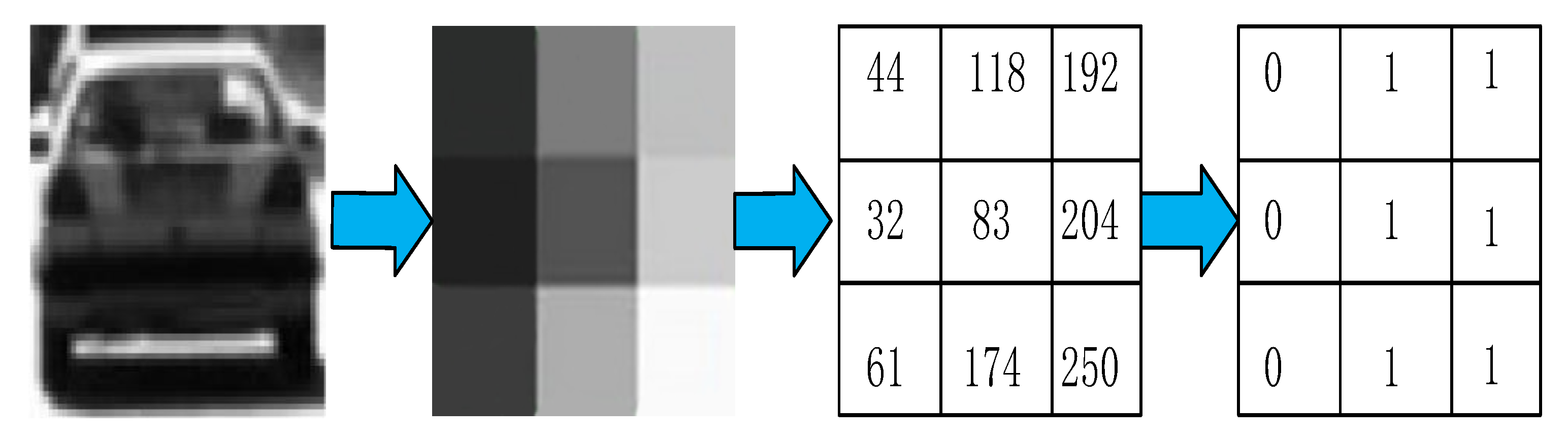
2.1.2. LBP Feature Extraction
2.1.3. Haar-Like Feature Extraction
2.2. Feature Dimension Reduction and Fusion Processing
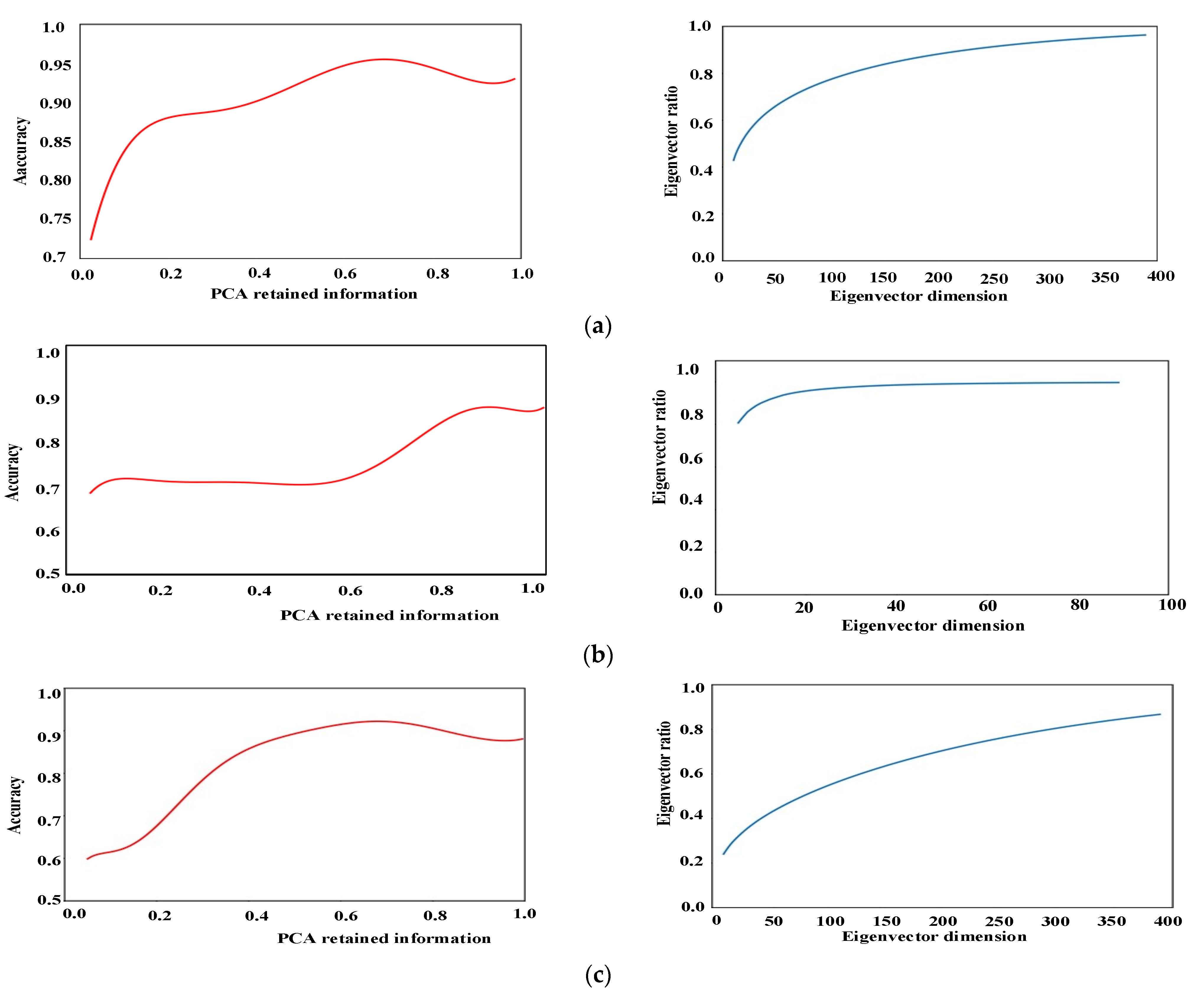
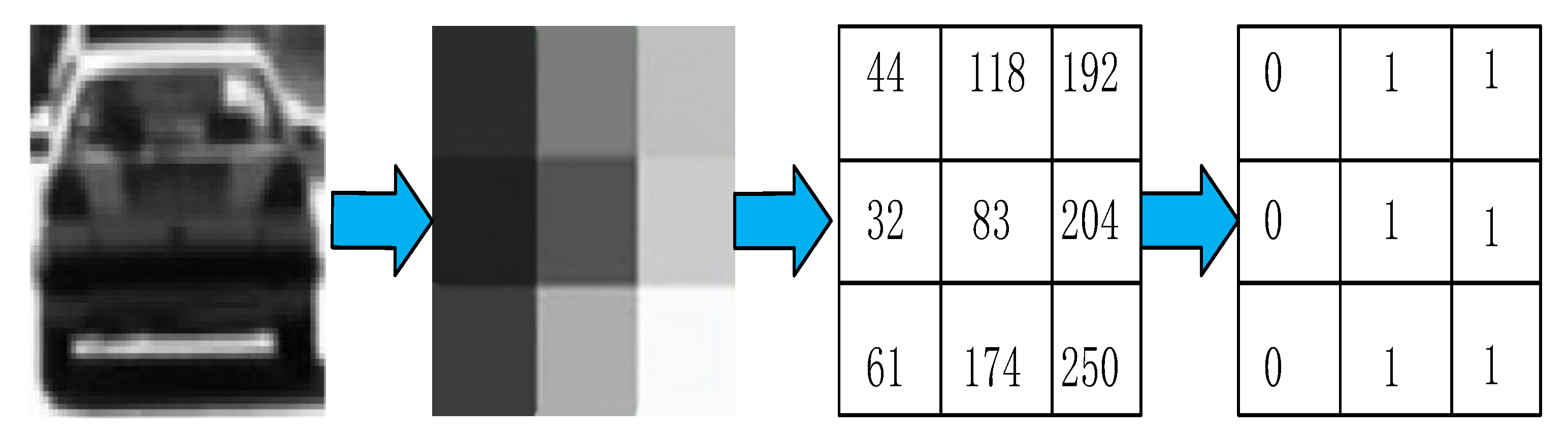
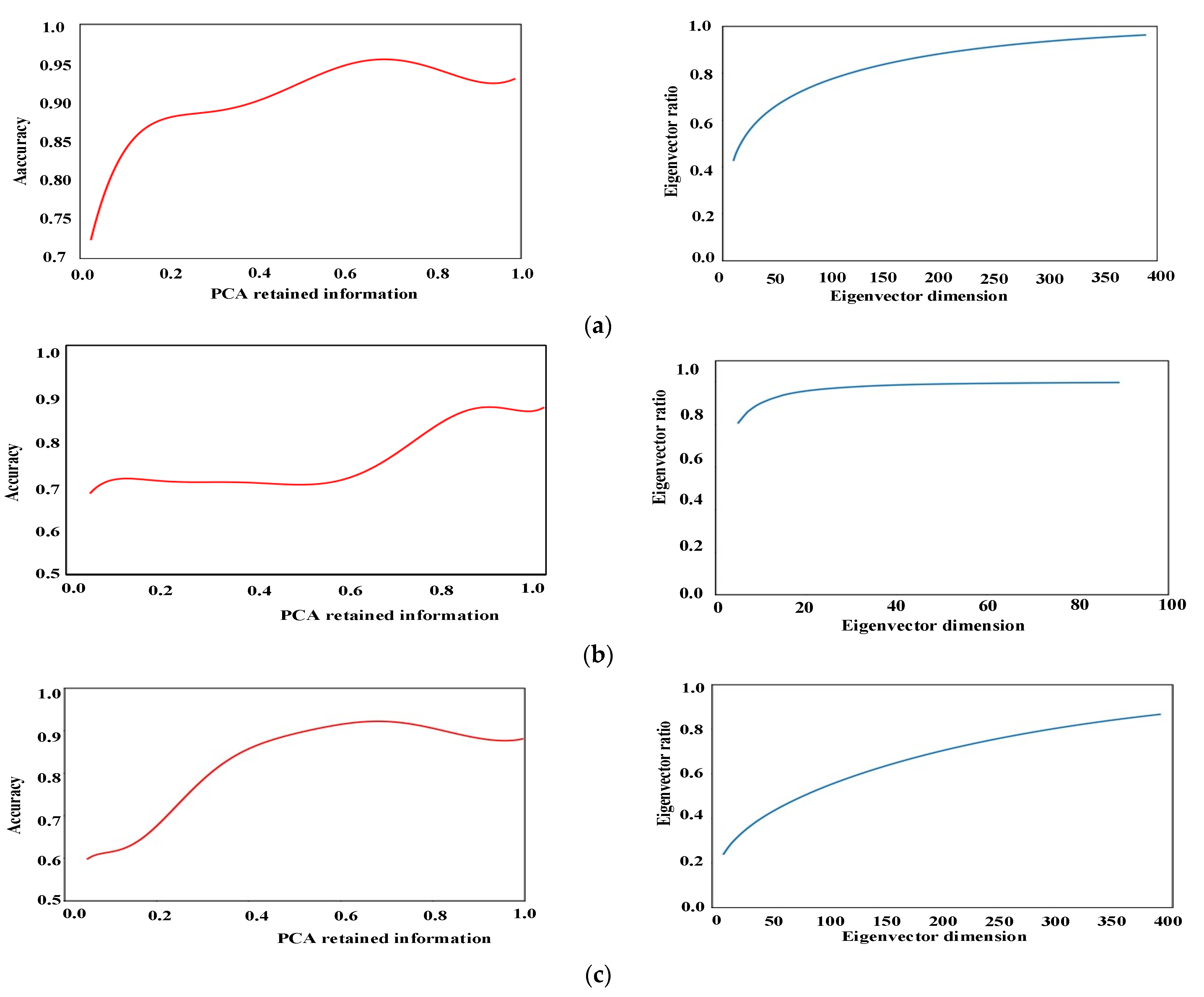
2.2.1. Feature Dimension Reduction
2.2.2. Feature Fusion
2.3. Design and Training of Classifier
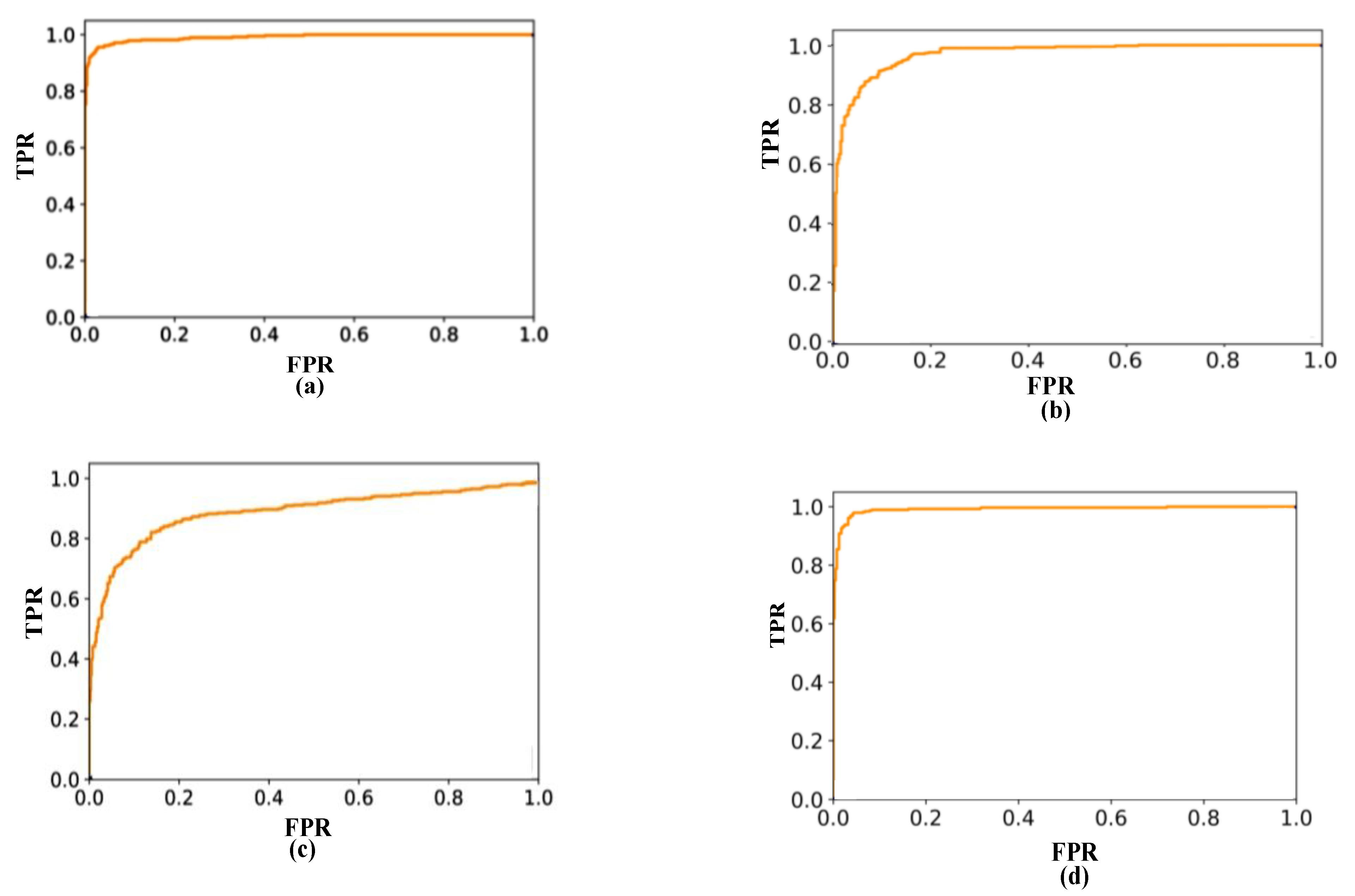
2.4. Experimental Test and Results
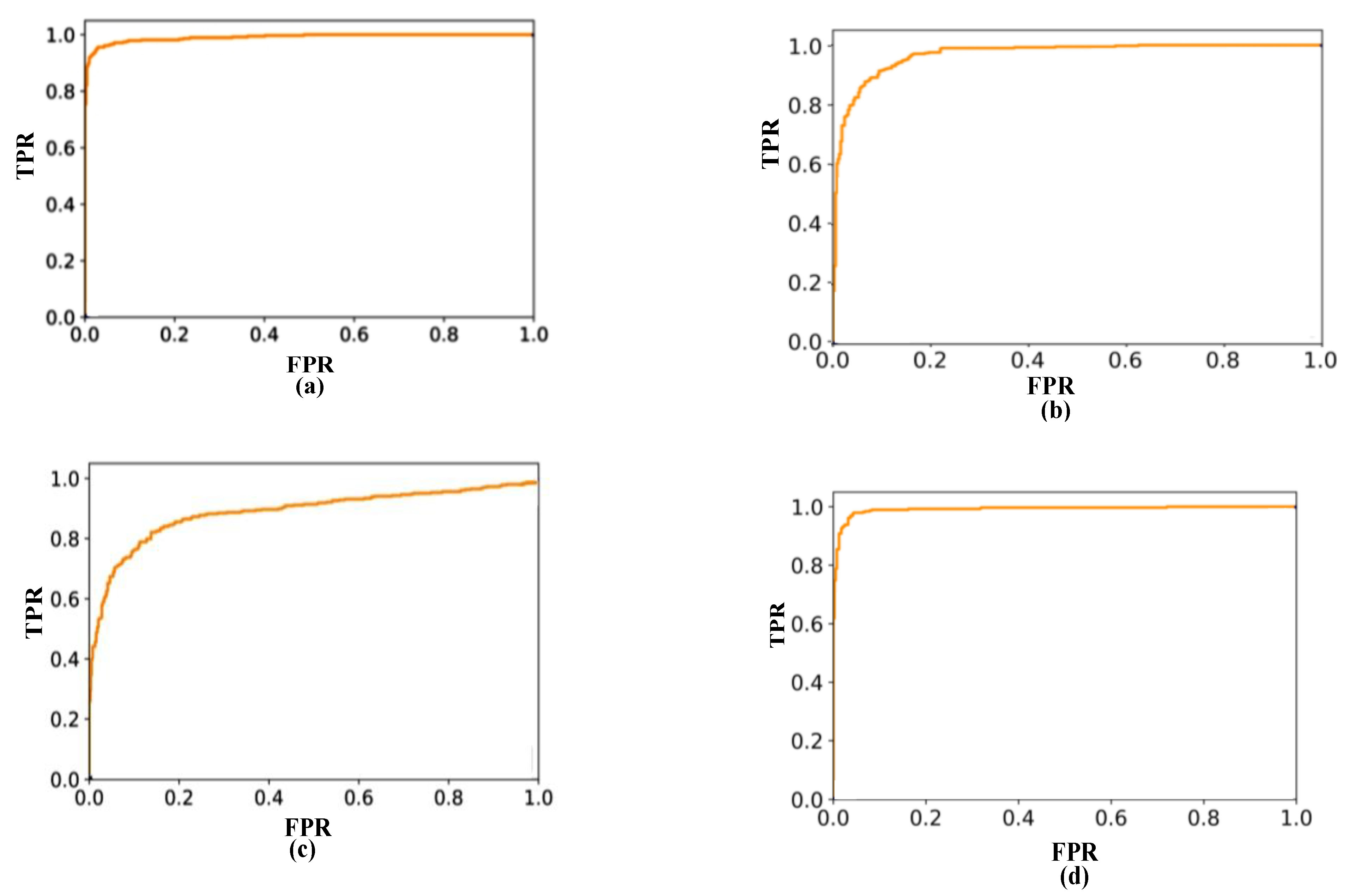
2.4.1. Experimental Evaluation
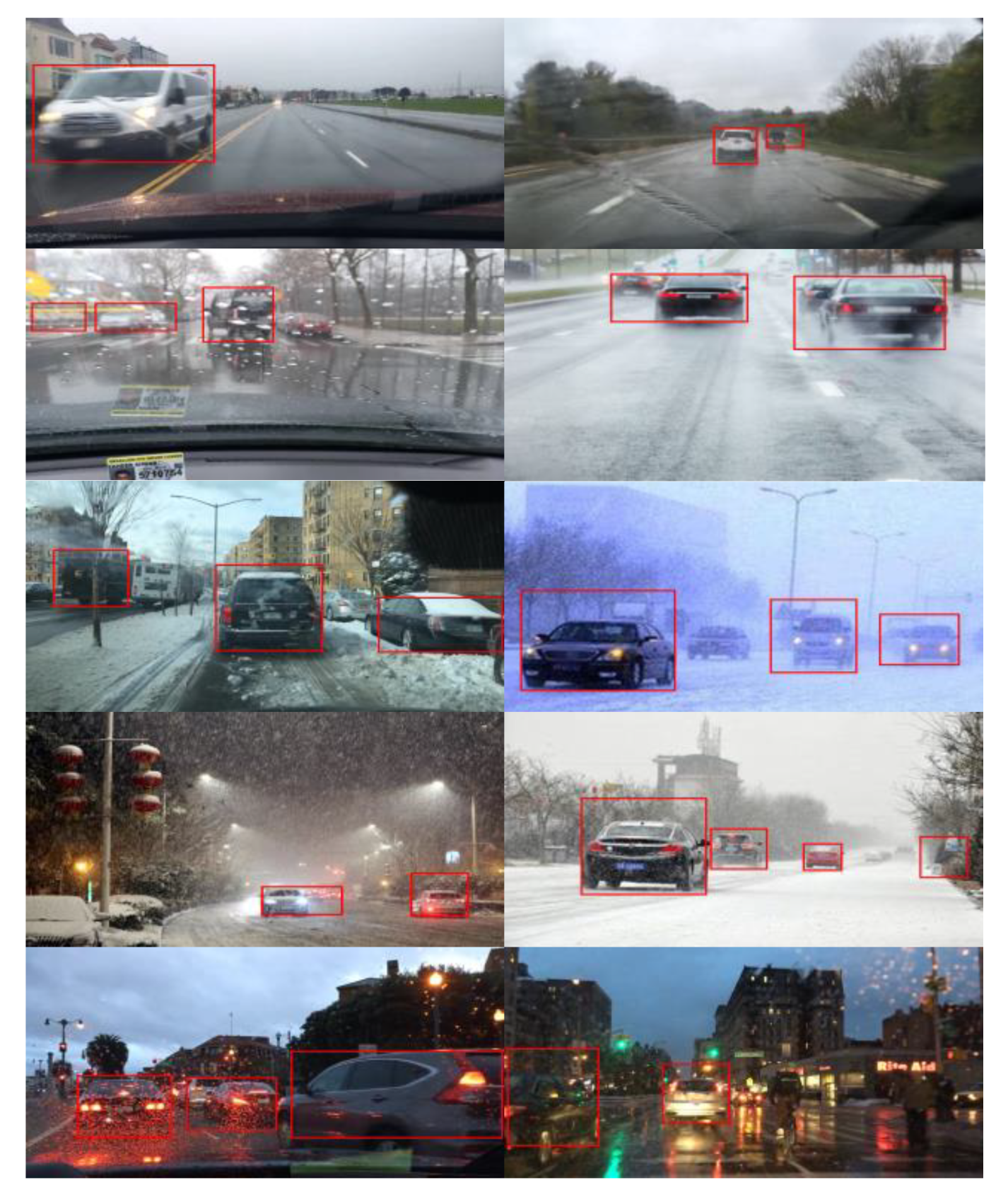
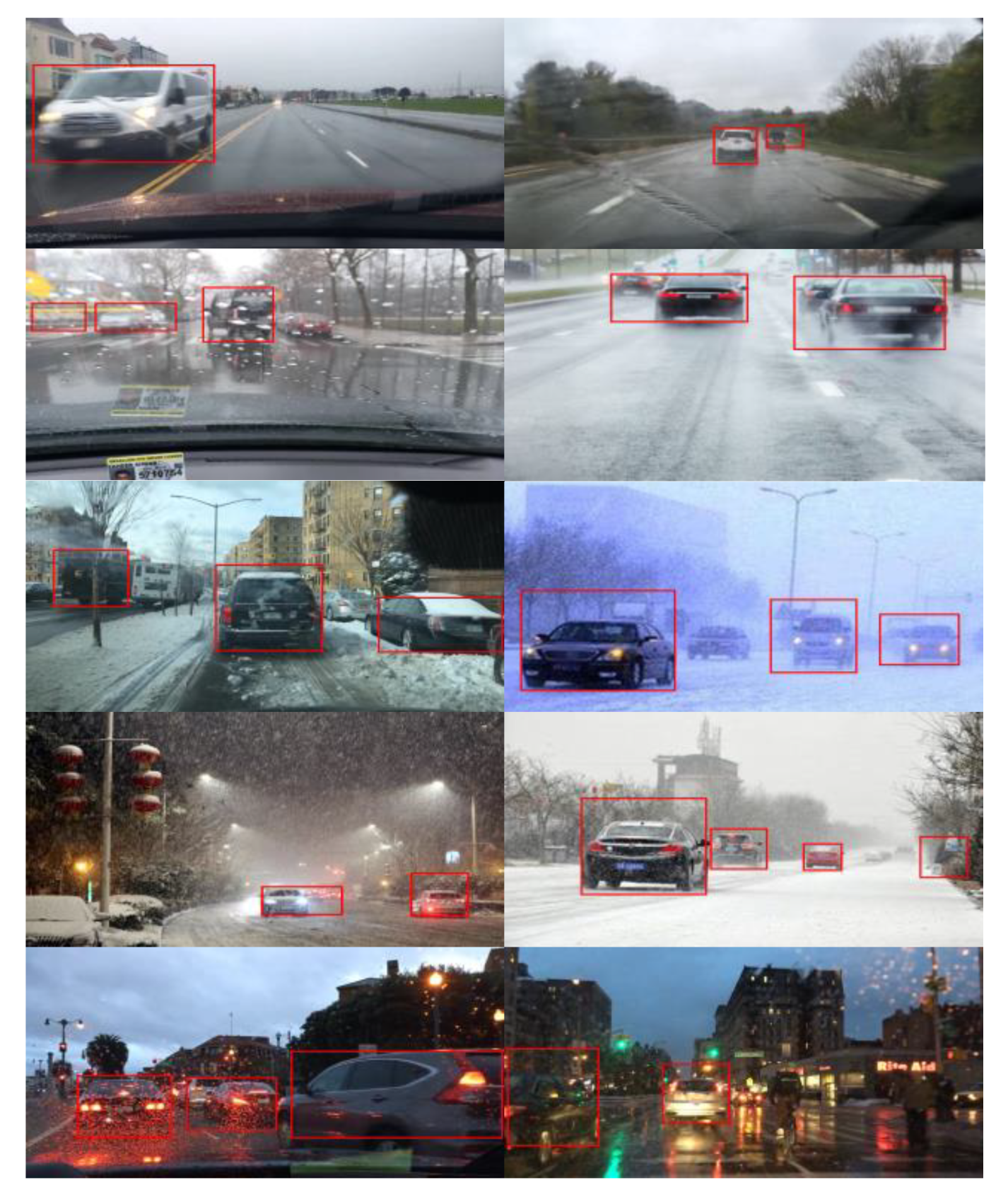
2.4.2. Test Results
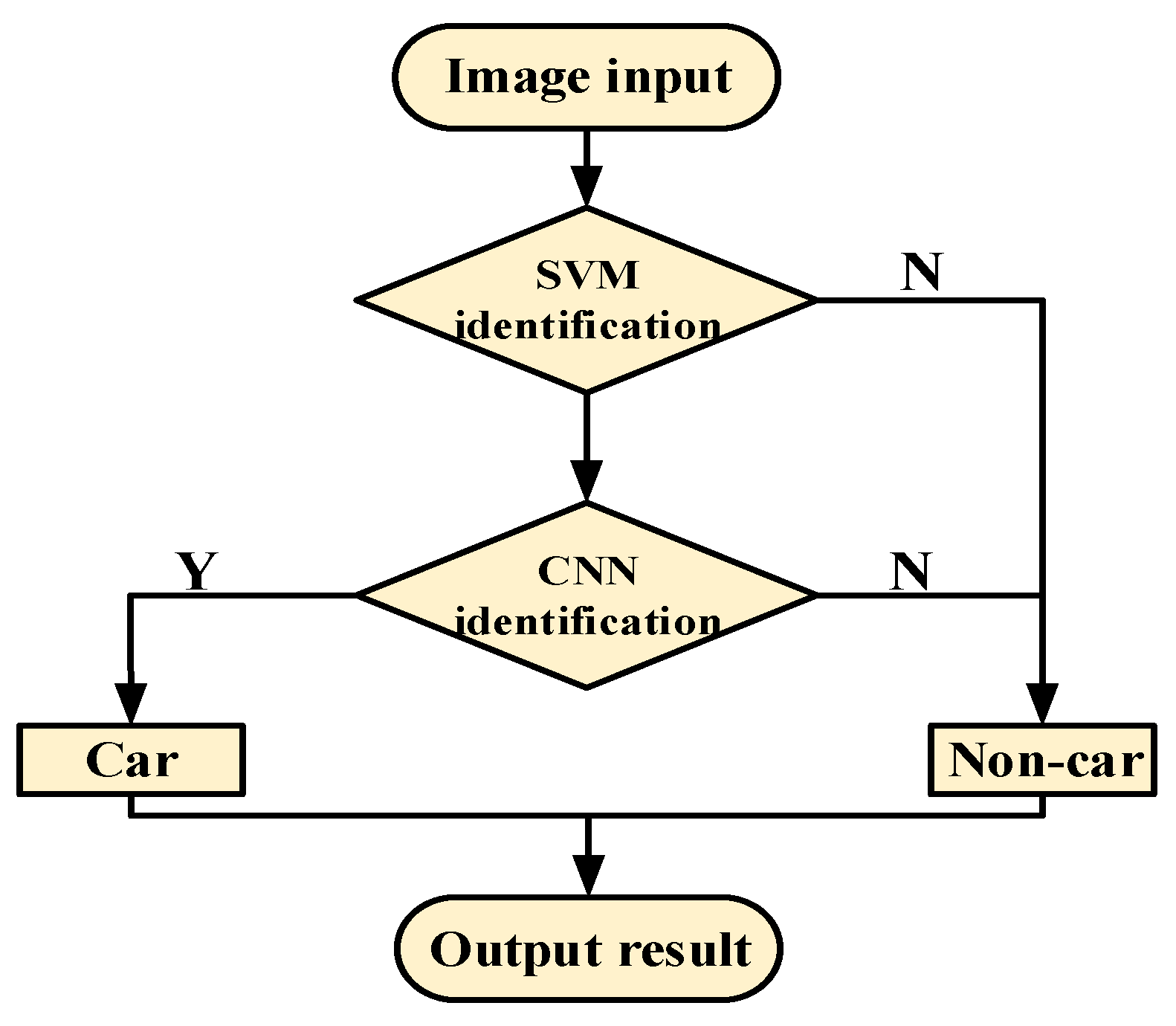
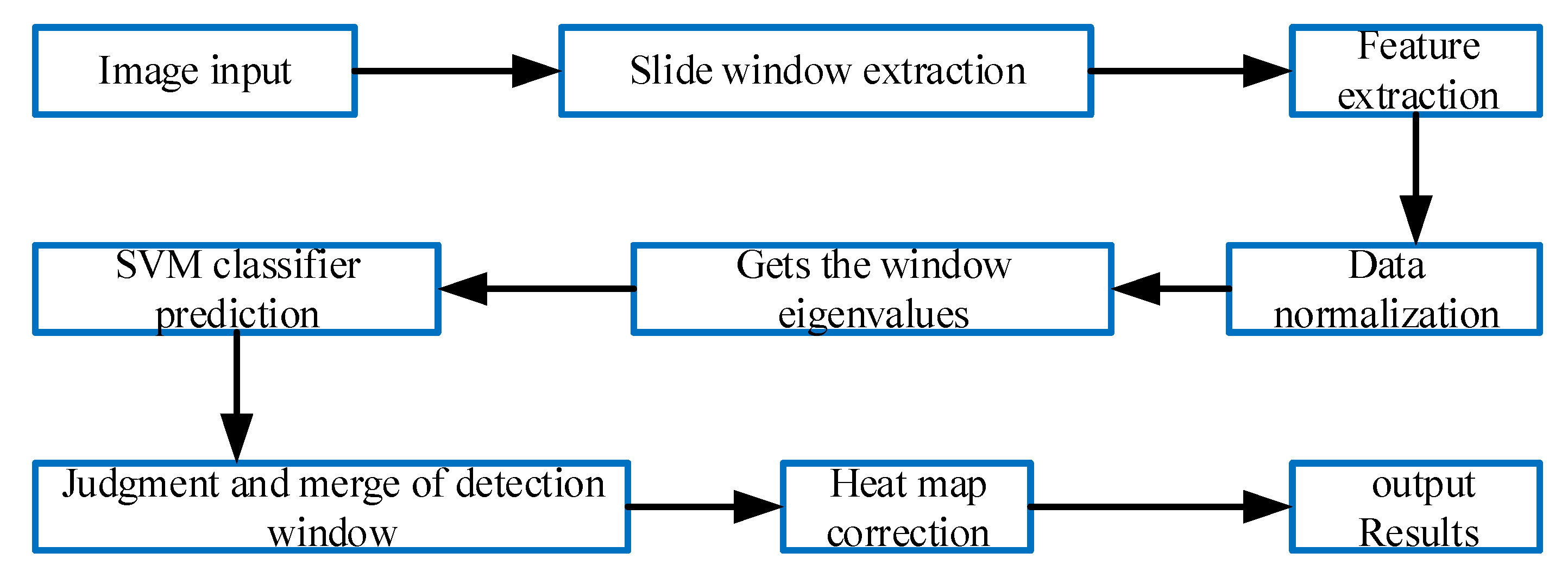
3. Cascade Vehicle Detection Based on CNN
3.1. VGG16 Neural-Network-Model Construction
3.2. Design of Cascade-Detection Confidence of Vehicles
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Private Car Ownership in China in 2019. 2020. Available online: http//www.askci.com/news/chanye/20200107/1624461156140.shtml (accessed on 7 January 2020).
- Batavia, P.H.; Pomerleau, D.A.; Thorpe, C.E. Overtaking Vehicle Detection Using Implicit Optical Flow. In Proceedings of the Conference on Intelligent Transportation Systems, Boston, MA, USA, 12 November 1997. [Google Scholar]
- Shi, L.; Deng, X.; Wang, J.; Chen, Q. Multi-target Tracking based on optical flow method and Kalman Filter. Comput. Appl. 2017, 37, 131–136. [Google Scholar]
- Gao, L. Research on Detection and Tracking Algorithm of Moving Vehicle in Dynamic Scene Based on Optical Flow. Ph.D. Thesis, University of Science and Technology of China, Hefei, China, 2014. [Google Scholar]
- Hu, X.; Liu, Z. Improved Vehicle Detection Algorithm based on Gaussian Background Model. Comput. Eng. Des. 2011, 32, 4111–4114. [Google Scholar]
- Fu, D. Research on Vehicle Detection Algorithm based on Background Modeling. Ph.D. Thesis, University of Science and Technology of China, Hefei, China, 2015. [Google Scholar]
- Yang, H.; Qu, S. Real-Time Vehicle Detection and Counting in Complex Traffic Scenes Using Background Subtraction Model with Low-Rank Decomposition. IET Intell. Transp. Syst. 2018, 12, 75–85. [Google Scholar] [CrossRef]
- Kato, T.; Ninomiya, Y.; Masaki, I. Preceding Vehicle Recognition Based on Learning from Sample Images. IEEE Trans. Intell. Transp. Syst. 2002, 3, 252–260. [Google Scholar] [CrossRef]
- Satzoda, R.K.; Trivedi, M.M. Multipart Vehicle Detection Using Symmetry-Derived Analysis and Active Learning. IEEE Trans. Intell. Transp. Syst. 2016, 17, 926–937. [Google Scholar] [CrossRef]
- Broggi, A.; Cerri, P.; Antonello, P.C. Multi-Resolution Vehicle Detection Using Artificial Vision. In Proceedings of the IEEE Intelligent Vehicles Symposium, Parma, Italy, 14–17 June 2004. [Google Scholar]
- Lee, B.; Kim, G. Robust detection of preceding vehicles in crowded traffic conditions. Int. J. Automot. Technol. 2012, 13, 671–678. [Google Scholar] [CrossRef]
- Li, L.; Deng, Y.; Rao, X. Application of color feature Model in static vehicle detection. J. Wuhan Univ. Technol. 2015, 37, 73–78. [Google Scholar]
- Kutsuma, Y.; Yaguchi, H.; Hamamoto, T. Real-Time Lane Line and Forward Vehicle Detection by Smart Image Sensor. In Proceedings of the IEEE International Symposium on Communications and Information Technology, Sapporo, Japan, 26–29 October 2004. [Google Scholar]
- Han, S.; Han, Y.; Hahn, H. Vehicle Detection Method using Haar-like Feature on Real Time System. Chemistry 2009, 15, 9521–9529. [Google Scholar]
- Mohamed, E.H.; Sara, E.; Ramy, S. Real-Time Vehicle Detection and Tracking Using Haar-like Features and Compressive Tracking; Springer: Berlin, Germany, 2014. [Google Scholar]
- Neumann, D.; Langner, T.; Ulbrich, F.; Spitta, D.; Goehring, D. Online Vehicle Detection Using Haar-Like, Lbp and Hog Feature Based Image Classifiers with Stereo Vision Preselection. In Proceedings of the 2017 28th IEEE Intelligent Vehicles Symposium, Los Angeles, CA, USA, 11–14 June 2017. [Google Scholar]
- Du, T.; Tihong, R.; Wu, J.; Fan, J. Vehicle recognition method based on Haar-like and HOG feature combination in traffic video. J. Zhejiang Univ. Technol. 2015, 43, 503–507. [Google Scholar]
- Li, X.; Guo, X. A HOG Feature and SVM Based Method for Forward Vehicle Detection with Single Camera. In Proceedings of the 2013 5th International Conference on Intelligent Human-Machine Systems and Cybernetics, Hangzhou, China, 26–27 August 2013; pp. 263–266. [Google Scholar]
- Li, Z.; Liu, W. A Moving vehicle Detection Method Based on Local HOG Feature. J. Guangxi Norm. Univ. 2017, 35, 1–13. [Google Scholar]
- Lei, M.; Xiao, Z.; Cui, Q. Real-time detection of forward vehicles based on two features. J. Tianjin Norm. Univ. 2010, 30, 23–26. [Google Scholar]
- Ma, W.; Miao, Z.; Zhang, Q. Vehicle classification based on multi-feature fusion. In Proceedings of the 5th IET International Conference on Wireless, Mobile and Multimedia Networks (ICWMMN 2013), Beijing, China, 22–25 November 2013; pp. 215–219. [Google Scholar]
- Haselhoff, A.; Kummert, A. A Vehicle Detection System Based on Haar and Triangle Features. In Proceedings of the 2009 IEEE Intelligent Vehicles Symposium, Xi’an, China, 3–5 June 2009. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 142–158. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R. Fast R-Cnn. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-Cnn: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In European Conference Computer Vision; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Kong, D.; Huang, J.; Sun, L.; Zhong, Z.; Sun, Y. Front vehicle detection algorithm in multi-lane complex environment. J. Henan Univ. Sci. Technol. 2018, 39, 25–30. [Google Scholar]
- Liu, T.; Zheng, N.N.; Zhao, L.; Cheng, H. Learning Based Symmetric Features Selection for Vehicle Detection. In Proceedings of the IEEE Proceedings. Intelligent Vehicles Symposium, Las Vegas, NV, USA, 6–8 June 2005. [Google Scholar]
- Cheng, W.; Yuan, W.; Zhang, M.; Li, Z. Recognition of front vehicle and longitudinal vehicle distance Detection based on tail edge features. Mech. Des. Manuf. 2017, 152–156. [Google Scholar] [CrossRef]
- Laopracha, N.; Sunat, K. Comparative Study of Computational Time That HOG-Based Features Used for Vehicle Detection; Springer: Berlin, Germany, 2018. [Google Scholar]
- Song, X.; Wang, W.; Zhang, W. Vehicle detection and tracking based on LBP texture and Improved Camshift Operator. J. Hunan Univ. 2013, 40, 52–57. [Google Scholar]
- Zhang, X.; Fang, T.; Li, Z.; Dong, M. Vehicle Recognition Technology Based on Haar-like Feature and AdaBoost. J. East China Univ. Sci. Technol. 2016, 260–262. [Google Scholar] [CrossRef]
- Kim, M.S.; Liu, Z.; Kang, D.J. On Road Vehicle Detection by Learning Hard Samples and Filtering False Alarms from Shadow Features. J. Mech. Sci. Technol. 2016, 30, 2783–2791. [Google Scholar] [CrossRef]
- Mao, W. Research on Feature Extraction and Target Tracking Algorithm based on Support Vector Machine. Ph.D. Thesis, Chongqing University, Chongqing, China, 2014. [Google Scholar]
- Gaopan, C.; Meihua, X.; Qi, W.; Aiying, G. Front vehicle detection method based on monocular vision. J. Shanghai Univ. 2019, 25, 56–65. [Google Scholar]
- Liu, R. Research on Video Target Detection Based on Deep learning. Ph.D. Thesis, South China University of Technology, Guangzhou, China, 2019. [Google Scholar]
- BDD-100K. 2018. Available online: https://bair.berkeley.edu/blog/2018/05/30/bdd/ (accessed on 30 May 2018).
- Cao, X.; Wu, C.; Yan, P.; Li, X. Linear SVM classification using boosting HOG features for vehicle detection in low-altitude airborne videos. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011. [Google Scholar]
- Meng, J.; Liu, J.; Li, Q.; Zhao, P. Vehicle Detection Method Based on Improved HOG-LBP[A]. Wuhan Zhicheng Times Cultural Development Co. In Proceedings of the 3rd International Conference on Vehicle, Mechanical and Electrical Engineering (ICVMEE 2016), Wuhan, China, 30–31 July 2016; Available online: https://www.dpi-proceedings.com/index.php/dtetr/article/viewFile/4861/4490 (accessed on 14 February 2021).
- Jabri, S.; Saidallah, M.; El Alaoui, A.E.B.; El Fergougui, A. Moving Vehicle Detection Using Haar-Like, Lbp and a Machine Learning Adaboost Algorithm. In Proceedings of the 2018 IEEE International Conference on Image Processing, Applications and Systems (IPAS), Sophia Antipolis, France, 12–14 December 2018. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]


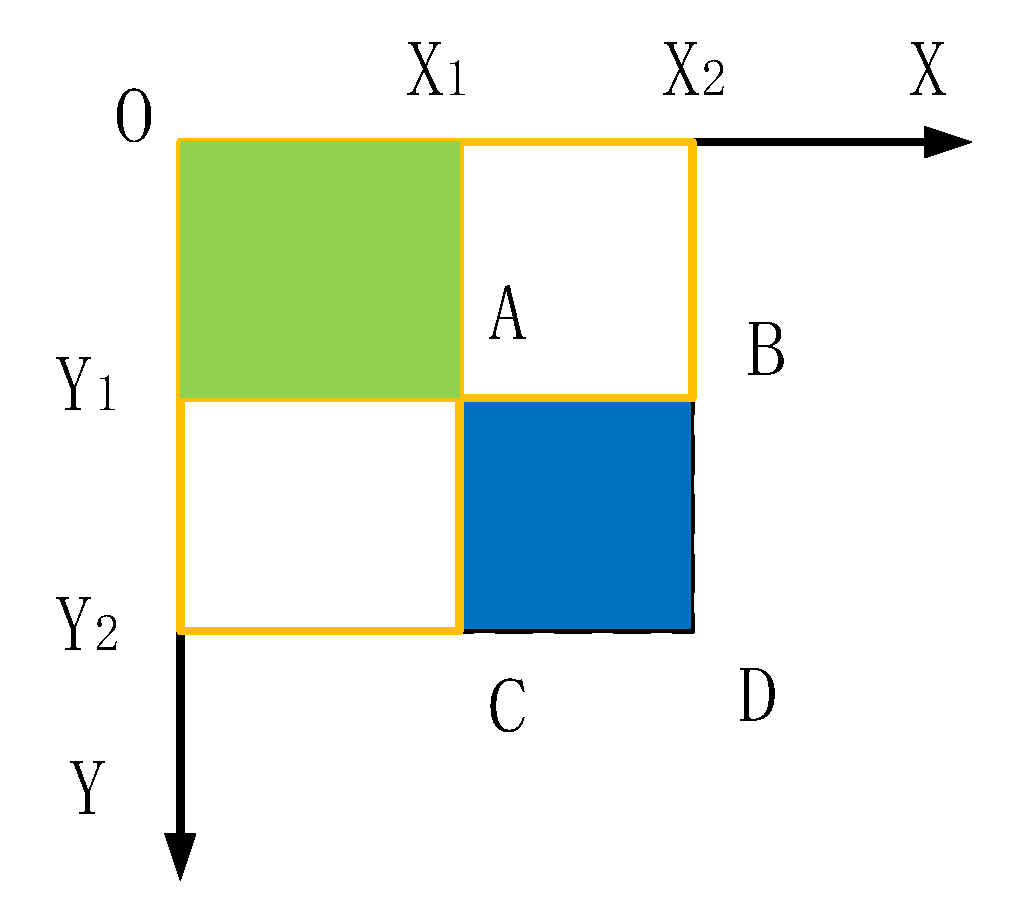





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
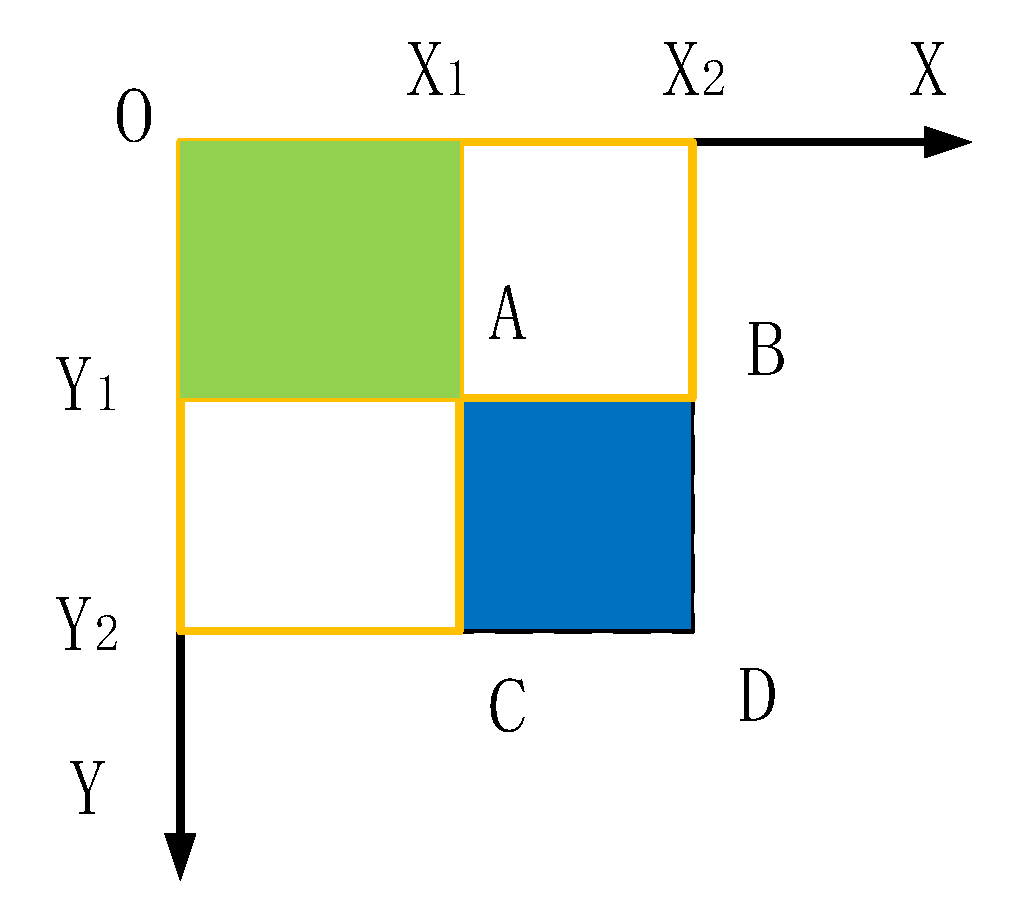{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Precision | Error Rate | Omission Rate |
|---|---|---|---|
| HOG+SVM [40] | 90.47% | 9.53% | 5.42% |
| HOG-LBP+SVM [41] | 96.64% | 3.36% | 2.74% |
| Haar-like+Adaboost [42] | 93.50% | 6.50% | 6.75% |
| multi-feature fusion algorithm (Ours) | 97.81% | 2.19% | 2.15% |
| Methods | Precision | Error Rate | Omission Rate |
|---|---|---|---|
| HOG+SVM [40] | 84.45% | 15.55% | 7.05% |
| HOG-LBP+SVM [41] | 92.42% | 7.58% | 3.64% |
| Haar-like+Adaboost [42] | 89.21% | 10.79% | 7.92% |
| multi-feature fusion algorithm (Ours) | 95.73% | 4.27% | 3.06% |
| Methods | Precision | Error Rate | Omission Rate |
|---|---|---|---|
| multi-feature fusion algorithm | 97.81% | 2.19% | 2.15% |
| CVDM-CNN | 98.69% | 1.31% | 1.37% |
| Methods | Precision | Error Rate | Omission Rate |
|---|---|---|---|
| multi-feature fusion algorithm | 95.73% | 4.27% | 3.06% |
| CVDM-CNN | 97.32% | 2.68% | 2.07% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, J.; Sun, Y.; Xiong, S. Research on the Cascade Vehicle Detection Method Based on CNN. Electronics 2021, 10, 481. https://doi.org/10.3390/electronics10040481
Hu J, Sun Y, Xiong S. Research on the Cascade Vehicle Detection Method Based on CNN. Electronics. 2021; 10(4):481. https://doi.org/10.3390/electronics10040481
Chicago/Turabian StyleHu, Jianjun, Yuqi Sun, and Songsong Xiong. 2021. "Research on the Cascade Vehicle Detection Method Based on CNN" Electronics 10, no. 4: 481. https://doi.org/10.3390/electronics10040481
APA StyleHu, J., Sun, Y., & Xiong, S. (2021). Research on the Cascade Vehicle Detection Method Based on CNN. Electronics, 10(4), 481. https://doi.org/10.3390/electronics10040481