
Jazz Bass Transcription Using a U-Net Architecture


Abstract
:1. Introduction
2. Related Work
2.1. Data-Driven Melody and Bass Transcription
2.2. U-Nets
3. Methodology
3.1. Audio Processing
3.2. Data Augmentation
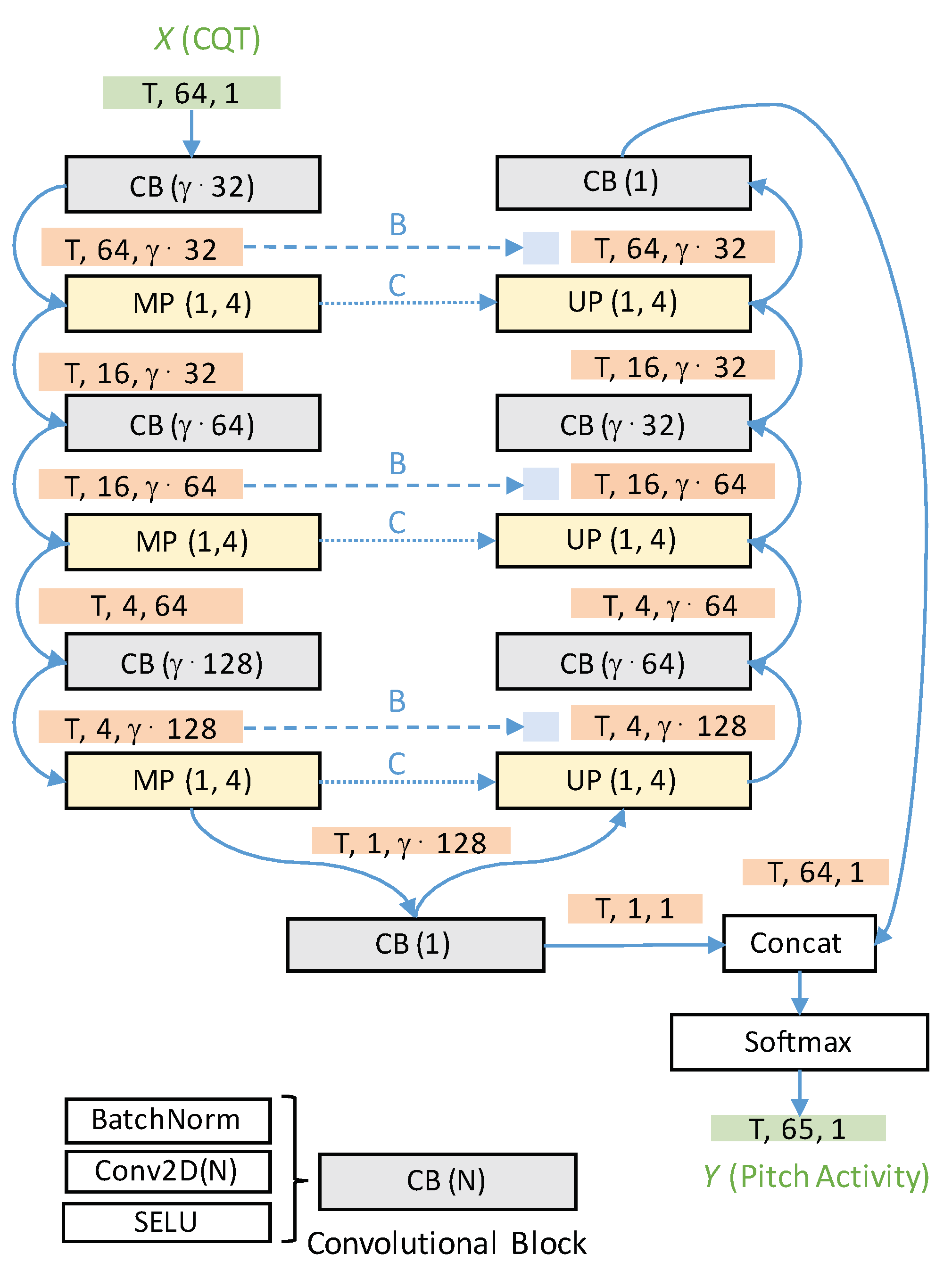
3.3. Network Architecture
3.4. Skip Connection Strategies
4. Datasets
5. Evaluation
5.1. Parameter Optimization Study
5.2. Comparison to the State of the Art
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abeßer, J.; Balke, S.; Frieler, K.; Pfleiderer, M.; Müller, M. Deep Learning for Jazz Walking Bass Transcription. In Proceedings of the AES Conference on Semantic Audio, Erlangen, Germany, 22–24 June 2017; pp. 202–209. [Google Scholar]
- Hsieh, T.H.; Su, L.; Yang, Y.H. A Streamlined Encoder/Decoder Architecture for Melody Extraction. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 156–160. [Google Scholar]
- Bittner, R.M.; Salamon, J.; Tierney, M.; Mauch, M.; Cannam, C.; Bello, J.P. MedleyDB: A Multitrack Dataset for Annotation-Intensive MIR Research. In Proceedings of the 15th International Society for Music Information Retrieval Conference (ISMIR), Taipei, Taiwan, 27–31 October 2014; pp. 155–160. [Google Scholar]
- Goto, M. A real-time music scene description system: Predominant-F0 estimation for detecting melody and bass lines in real-world audio signals. Speech Commun. 2004, 43, 311–329. [Google Scholar] [CrossRef]
- Salamon, J.; Bittner, R.M.; Bonada, J.; Bosch, J.J.; Gómez, E.; Bello, J.P. An Analysis/Synthesis Framework for Automatic F0 Annotation of Multitrack Datasets. In Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), Suzhou, China, 23–27 October 2017; pp. 71–78. [Google Scholar]
- Pfleiderer, M.; Frieler, K.; Abeßer, J.; Zaddach, W.G.; Burkhart, B. (Eds.) Inside the Jazzomat—New Perspectives for Jazz Research; Schott Campus: Santa Barbara, CA, USA, 2018. [Google Scholar]
- McFee, B.; Humphrey, E.J.; Bello, J.P. A Software Framework for Musical Data Augmentation. In Proceedings of the 16th International Society for Music Information Retrieval Conference (ISMIR), Málaga, Spain, 26–30 October 2015; pp. 248–254. [Google Scholar]
- Kim, J.W.; Salamon, J.; Li, P.; Bello, J.P. Crepe: A Convolutional Representation for Pitch Estimation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 161–165. [Google Scholar]
- Singh, S.; Wang, R.; Qiu, Y. DEEPF0: End-To-End Fundamental Frequency Estimation for Music and Speech Signals. arXiv 2021, arXiv:2102.06306. [Google Scholar]
- Park, H.; Yoo, C.D. Melody Extraction and Detection through LSTM-RNN with Harmonic Sum Loss. In Proceedings of the 42nd IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2766–2770. [Google Scholar]
- Bittner, R.M.; McFee, B.; Bello, J.P. Multitask Learning for Fundamental Frequency Estimation in Music. arXiv 2018, arXiv:1809.00381. [Google Scholar]
- Bittner, R.M.; McFee, B.; Salamon, J.; Li, P.; Bello, J.P. Deep Salience Representations for F0 Estimation in Polyphonic Music. In Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), Suzhou, China, 23–27 October 2017; pp. 63–70. [Google Scholar]
- Doras, G.; Esling, P.; Peeters, G. On the use of U-Net for dominant melody estimation in polyphonic music. In Proceedings of the International Workshop on Multilayer Music Representation and Processing (MMRP), Milano, Italy, 24–25 January 2019; pp. 66–70. [Google Scholar]
- Rigaud, F.; Radenen, M. Singing Voice Melody Transcription using Deep Neural Networks. In Proceedings of the 17th International Society for Music Information Retrieval Conference (ISMIR), New York, NY, USA, 7–11 August 2016; pp. 737–743. [Google Scholar]
- Balke, S.; Dittmar, C.; Abeßer, J.; Müller, M. Data-Driven Solo Voice Enhancement for Jazz Music Retrieval. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 196–200. [Google Scholar]
- Abeßer, J.; Balke, S.; Müller, M. Improving Bass Saliency Estimation Using Label Propagation and Transfer Learning. In Proceedings of the 19th International Society for Music Information Retrieval Conference (ISMIR), Paris, France, 23–27 September 2018; pp. 306–312. [Google Scholar]
- Kum, S.; Nam, J. Classification-Based Singing Melody Extraction Using Deep Convolutional Neural Networks. Preprints 2017. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. Lect. Notes Comput. Sci. 2015, 9351, 234–241. [Google Scholar]
- Jansson, A.; Humphrey, E.; Montecchio, N.; Bittner, R.; Kumar, A.; Weyde, T. Singing Voice Separation with Deep U-Net CNN. In Proceedings of the 18th International Society for Music Information Retrieval Conference (ISMIR), Suzhou, China, 23–27 October 2017. [Google Scholar]
- Stoller, D.; Ewert, S.; Dixon, S. Wave-U-Net: A multi-scale neural network for end-to-end audio source separation. In Proceedings of the 19th International Society for Music Information Retrieval Conference (ISMIR), Paris, France, 23–27 September 2018; pp. 334–340. [Google Scholar]
- Wu, Y.T.; Chen, B.; Su, L. Polyphonic Music Transcription with Semantic Segmentation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 166–170. [Google Scholar]
- Stoller, D.; Durand, S.; Ewert, S. End-to-end Lyrics Alignment for Polyphonic Music Using an Audio-to-character Recognition Model. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 181–185. [Google Scholar]
- Lu, W.T.; Su, L. Vocal melody extraction with semantic segmentation and audio-symbolic domain transfer learning. In Proceedings of the 19th International Society for Music Information Retrieval Conference (ISMIR), Paris, France, 23–27 September 2018; pp. 521–528. [Google Scholar]
- Schlüter, J.; Grill, T. Exploring Data Augmentation for Improved Singing Voice Detection with Neural Networks. In Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), Málaga, Spain, 26–30 October 2015; pp. 121–126. [Google Scholar]
- Goto, M.; Hashiguchi, H.; Nishimura, T.; Oka, R. RWC Music Database: Popular, Classical, and Jazz Music Databases. In Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), Paris, France, 13–17 October 2002; pp. 287–288. [Google Scholar]
- Cohen-Hadria, A.; Roebel, A.; Peeters, G. Improving singing voice separation using deep u-net and wave-u-net with data augmentation. arXiv 2019, arXiv:1903.01415. [Google Scholar]
- Thickstun, J.; Harchaoui, Z.; Foster, D.P.; Kakade, S.M. Invariances and Data Augmentation for Supervised Music Transcription. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2241–2245. [Google Scholar]
- Salamon, J.; Gómez, E. Melody Extraction From Polyphonic Music Signals Using Pitch Contour Characteristics. IEEE Trans. Audio, Speech Lang. Process. 2012, 20, 1759–1770. [Google Scholar] [CrossRef] [Green Version]
- Salamon, J.; Serrà, J.; Gómez, E. Tonal representations for music retrieval: From version identification to query-by-humming. Int. J. Multimed. Inf. Retr. 2013, 2, 45–58. [Google Scholar] [CrossRef] [Green Version]
- Salamon, J.; Gómez, E.; Ellis, D.P.; Richard, G. Melody Extraction from Polyphonic Music Signals. IEEE Signal Process. Mag. 2014, 31, 118–134. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
| Dataset | Subset | # Files |
|---|---|---|
| Mixed Genre Set (MGS) | - | 137 |
| - | MDB-bass-synth | 70 |
| - | MedleyDB | 21 |
| - | RWC | 16 |
| - | WJD | 30 |
| Jazz Set (JS) | - | 36 |
| - | WJD | 36 |
| Set | Data Partition Strategy | |
|---|---|---|
| Mixed | Jazz | |
| Training Set | MGS (80 %) | MGS (full) |
| Validation Set | MGS (20 %) | JS (20 %) |
| Test Set | JS (80 %) | |
| Hyperparameter | Section | Search Space |
|---|---|---|
| Data augmentation | Section 3.2 | {no, PS, REQ, PS+REQ} |
| Scaling factor | Section 3.3 | {, , , 1} |
| Skip connection strategy | Section 3.4 | {A, B, C, D } |
| Hyperparameter | Data Partition Strategy | |
|---|---|---|
| Mixed | Jazz | |
| Data augmentation | REQ | PS |
| Skip connection strategy | B | C |
| Filter number factor | 1 | |
| Highest overall accuracy (OA) on validation set | 0.82 | 0.6 |
| Configuration | Data Partition Strategy | |
|---|---|---|
| Mixed (BassUNet) | Jazz (BassUNet) | |
| Best parameter settings (see Table 4) | 0.82 | 0.6 |
| No data augmentation | 0.81 | 0.52 |
| No skip connections | 0.78 | 0.58 |
| No data augmentation & no skip connections | 0.76 | 0.5 |
| Method | Algorithm & Reference | ||||
|---|---|---|---|---|---|
| BassUNet | Convolutional U-net (proposed) | ||||
| BassUNet | Trained with Jazz data partition strategy. | ||||
| BassUNet | Trained with mixed data partition strategy. | ||||
| BI18 | Convolutional Neural Network, Multitask Learning [11] | ||||
| AB17 | Fully Connected Neural Network [1] | ||||
| SA12 | Melodia Bass [28,29] | ||||
| Method | VR↑ | VFA↓ | RPA↑ | RCA↑ | OA↑ |
| BassUNet | 0.75 | 0.39 | 0.60 | 0.66 | 0.60 |
| BassUNet | 0.78 | 0.55 | 0.56 | 0.62 | 0.55 |
| BI18 () | 0.80 | 0.72 | 0.55 | 0.61 | 0.53 |
| AB17 () | 0.80 | 0.58 | 0.55 | 0.62 | 0.54 |
| SA12 | 0.90 | 0.80 | 0.49 | 0.65 | 0.46 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abeßer, J.; Müller, M. Jazz Bass Transcription Using a U-Net Architecture. Electronics 2021, 10, 670. https://doi.org/10.3390/electronics10060670
Abeßer J, Müller M. Jazz Bass Transcription Using a U-Net Architecture. Electronics. 2021; 10(6):670. https://doi.org/10.3390/electronics10060670
Chicago/Turabian StyleAbeßer, Jakob, and Meinard Müller. 2021. "Jazz Bass Transcription Using a U-Net Architecture" Electronics 10, no. 6: 670. https://doi.org/10.3390/electronics10060670
APA StyleAbeßer, J., & Müller, M. (2021). Jazz Bass Transcription Using a U-Net Architecture. Electronics, 10(6), 670. https://doi.org/10.3390/electronics10060670