
Handwritten Character Recognition on Android for Basic Education Using Convolutional Neural Network



Abstract
:1. Introduction
- In the character segmentation part, we proposed the simple concepts of labeling and projection to overcome the segmentation problems that are found after initial seg-mentation.
- Since the network model is trained on a high-end machine and converted into a very light classifier which will be deployed on mobile devices, therefore, the model can be loaded quickly for each character classification process.
- The application provides an effective learning environment without requirements for experienced teachers or internet service. It can be accessed anytime, anywhere. The standard courses provide equally high quality for all users.
2. Related Work
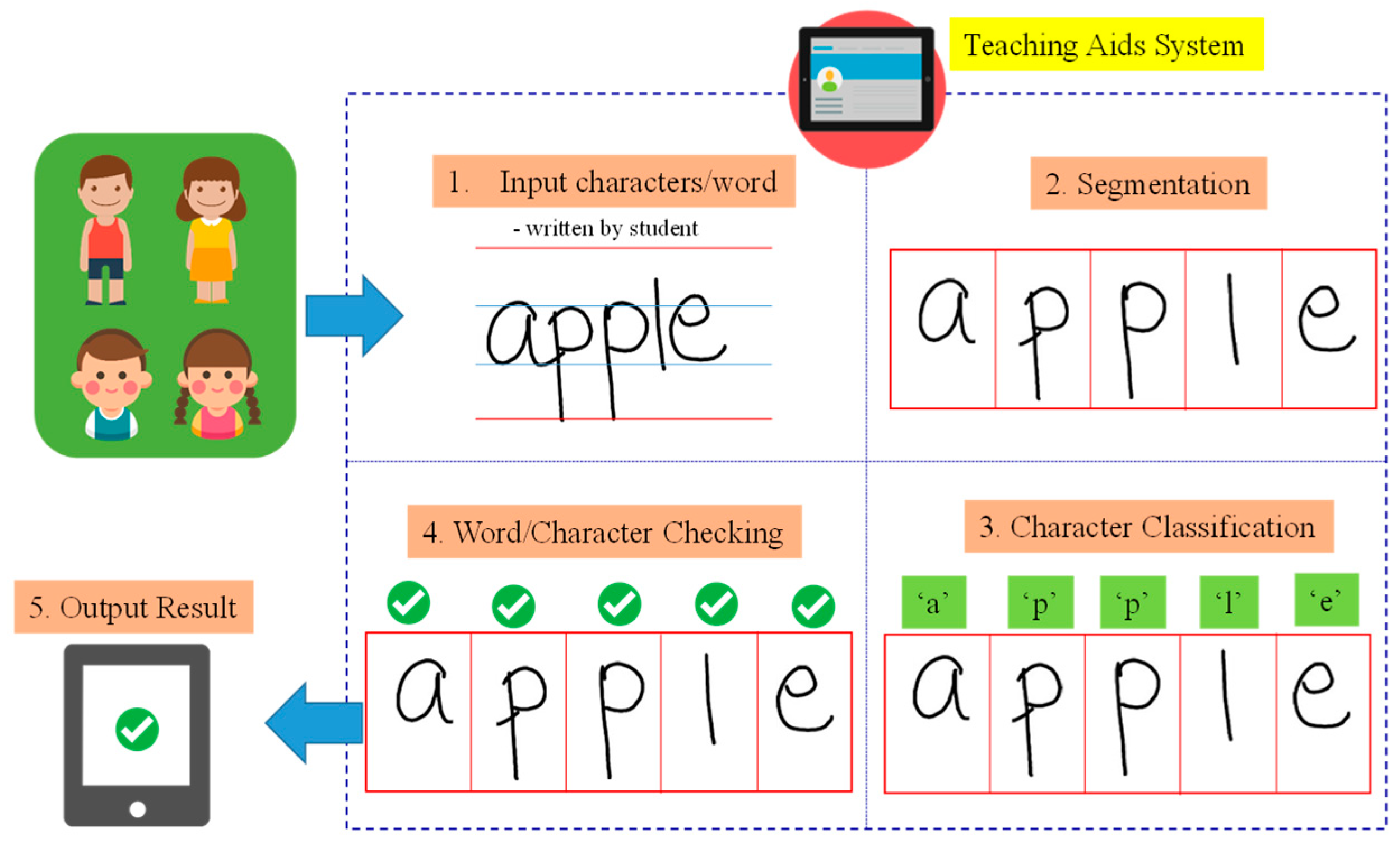
3. Proposed System
3.1. Segmentation
3.1.1. Pre-Processing
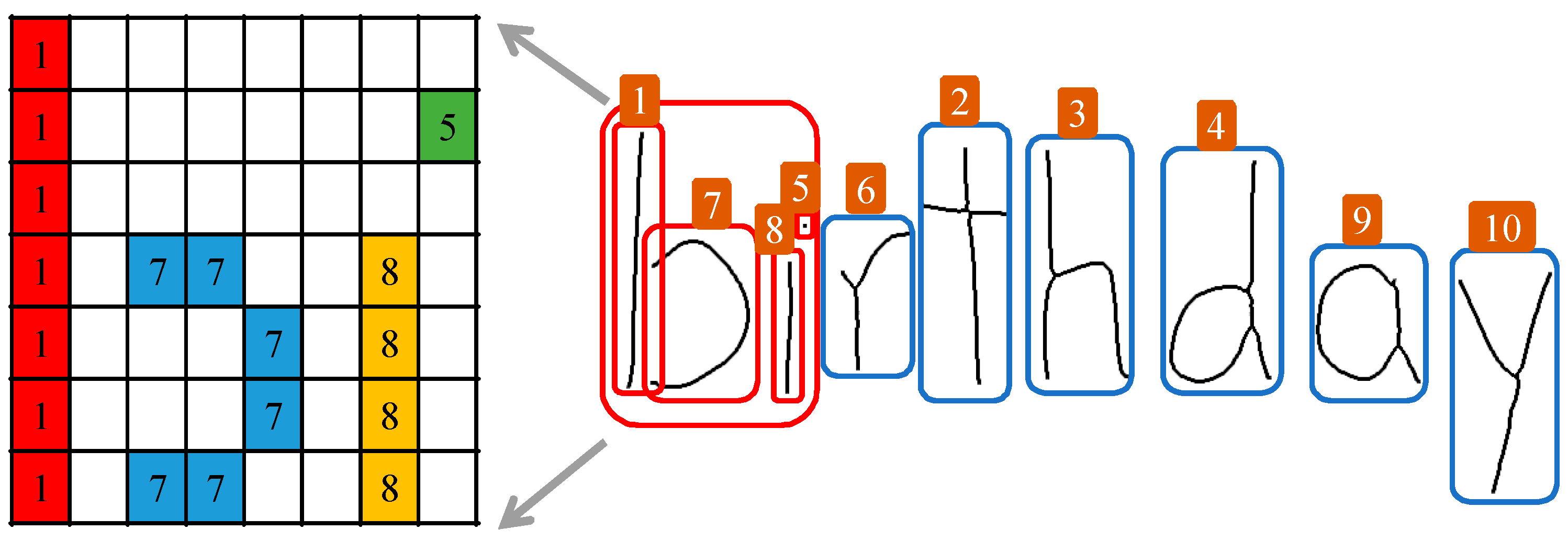
3.1.2. Labeling
- (a)
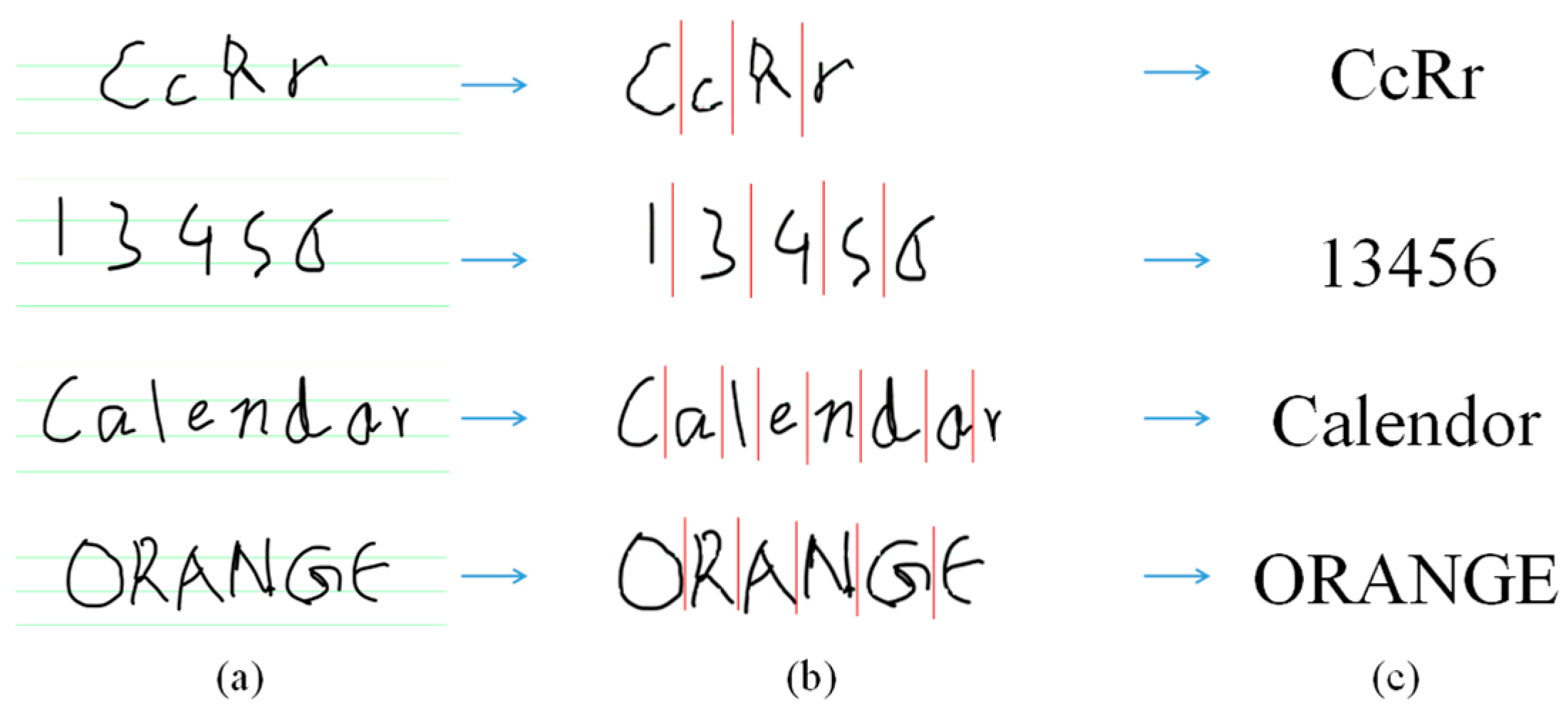
- Initial labeling using connected regions:
- (b)
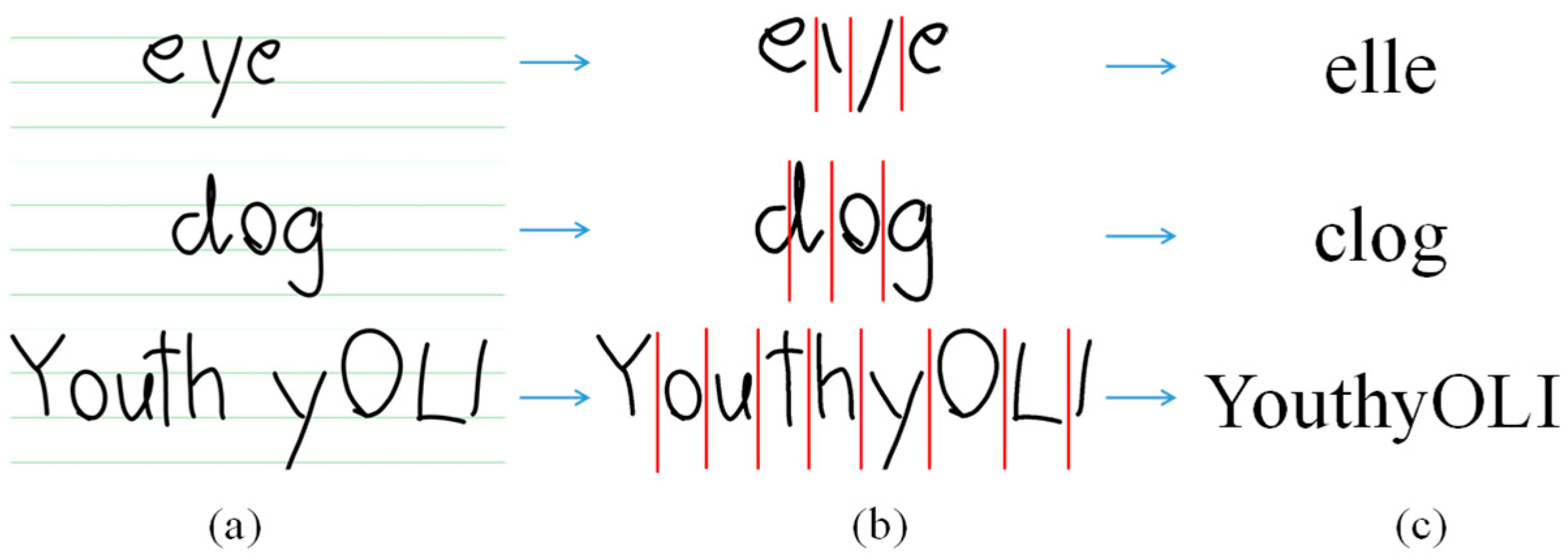
- Label combination for some characters
- (c)
- Label separation
- (d)
- Small disjoint connection
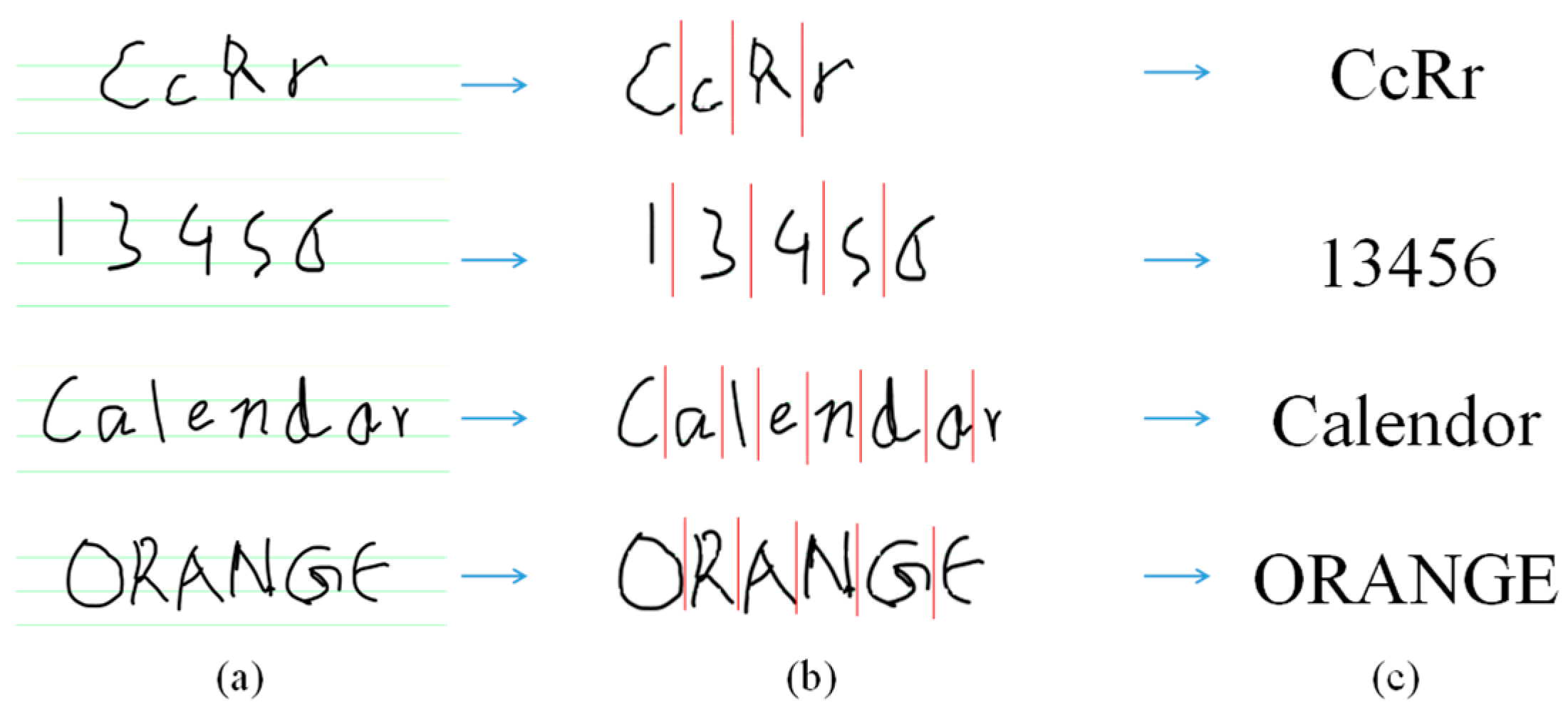
3.1.3. Segmentation with Projection
- Step 1.
- Find vertical projection values for each x-coordinate in the segmented image using (2) and use the points where projection values are 1:
- Step 2.
- Use an average point if adjacent points are less than 7 pixels apart, in which a character cannot exist in the part segmented with the adjacent points.
- Step 3.
- Retain points that match the following two constraints as projection segment points.
- The first point of the group of adjacent points is not the leftmost point of the partial image.
- The last point of the group of adjacent points is not the rightmost point of the partial image.
3.1.4. Over-Segments’ Removal
- Find two points, a1 and a2, whose x-coordinates are equal, and the differences between y-coordinates are greater than the threshold.
- Similarly, find an additional two points, b1 and b2. In finding these points, the difference between the x-coordinates of a1 and b1 must also exceed the threshold.
- Find c1 and c2, in the same way as finding a1 and a2, and then find d1 and d2 in the same way as finding b1 and b2.
- If none of these four points are zero, the object is determined to be a closed character.
3.2. Classification
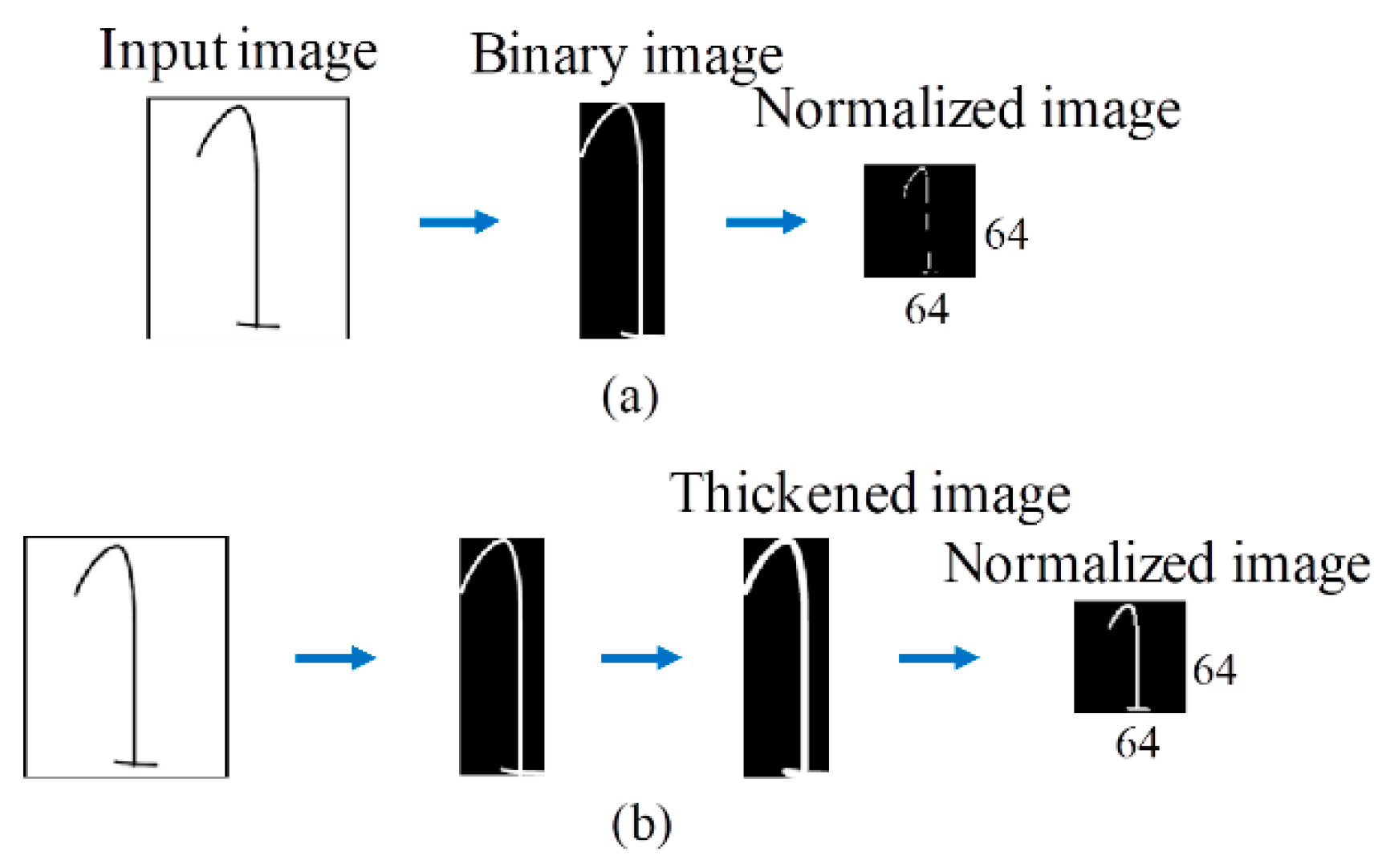
3.2.1. Image Normalization
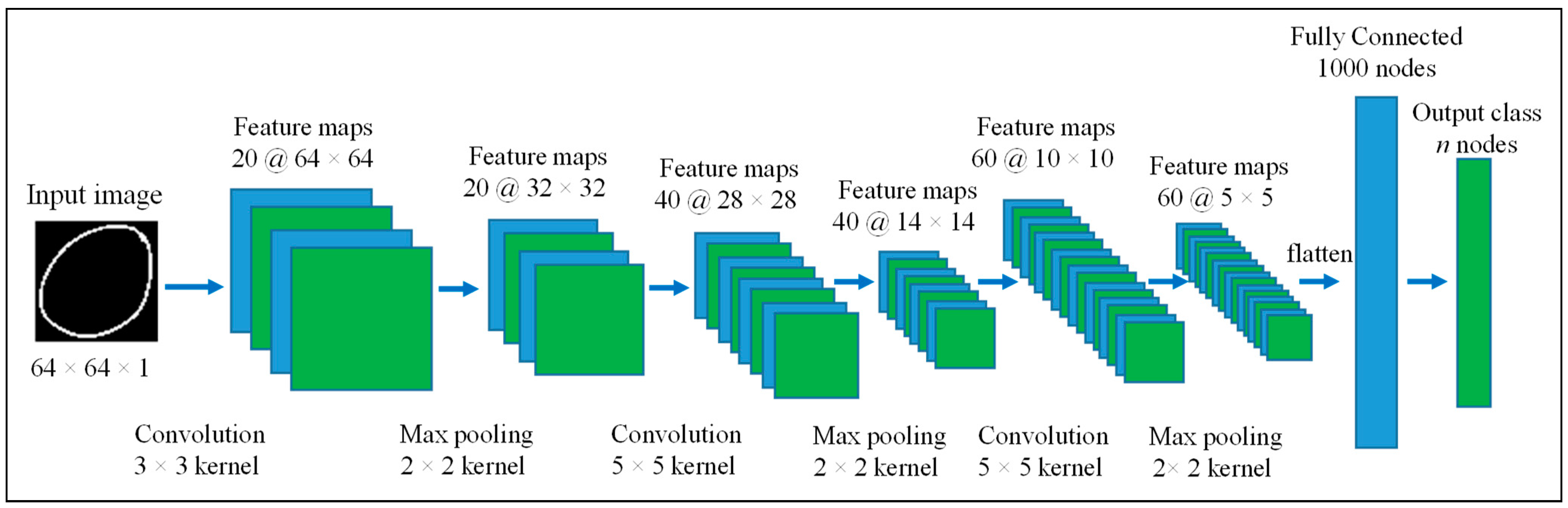
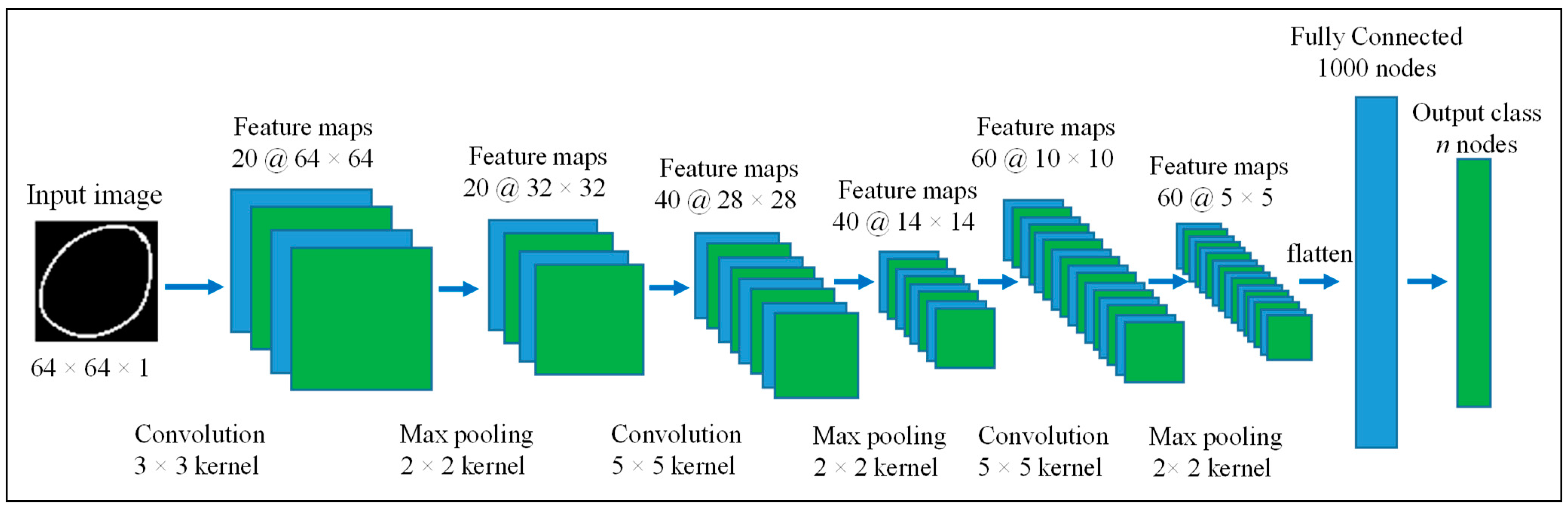
3.2.2. Initial Classification with Convolutional Neural Network
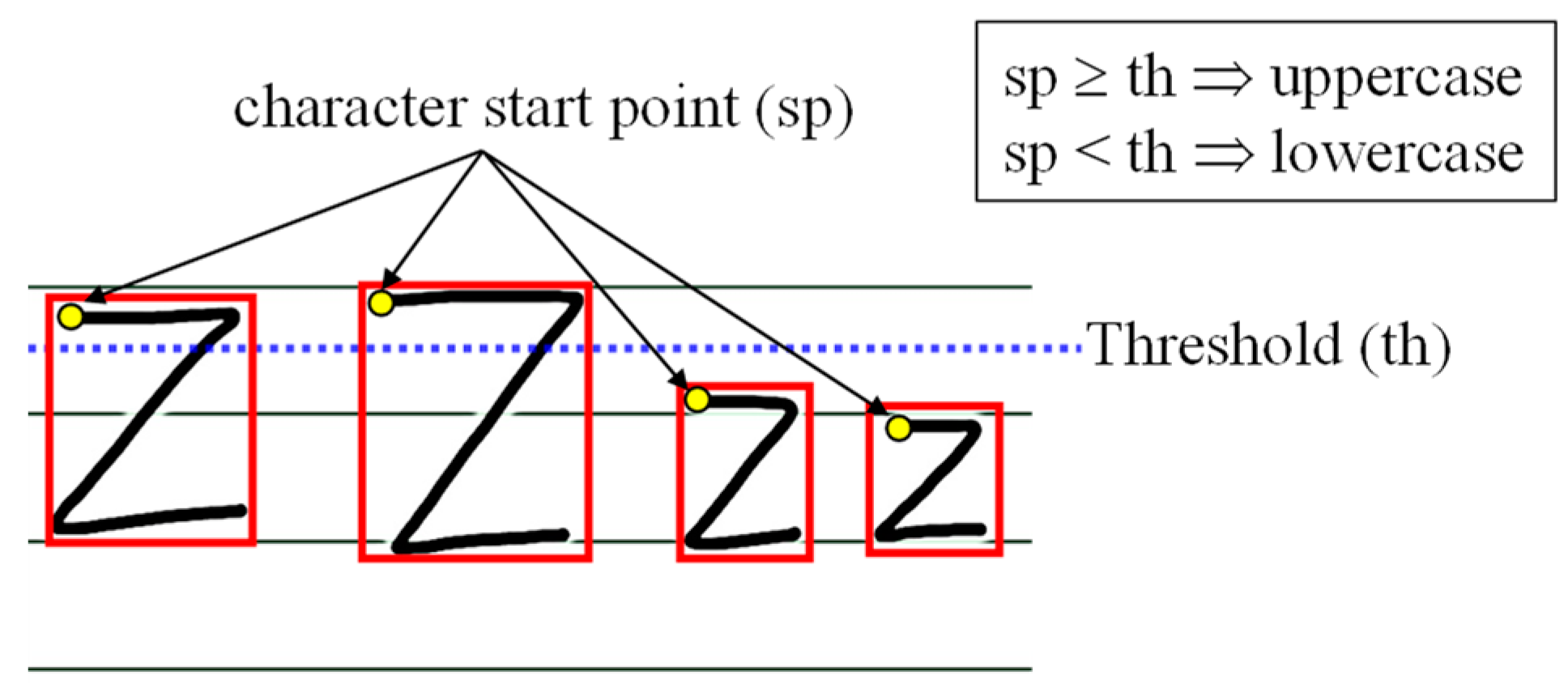
3.2.3. Differentiating Uppercase and Lowercase Characters
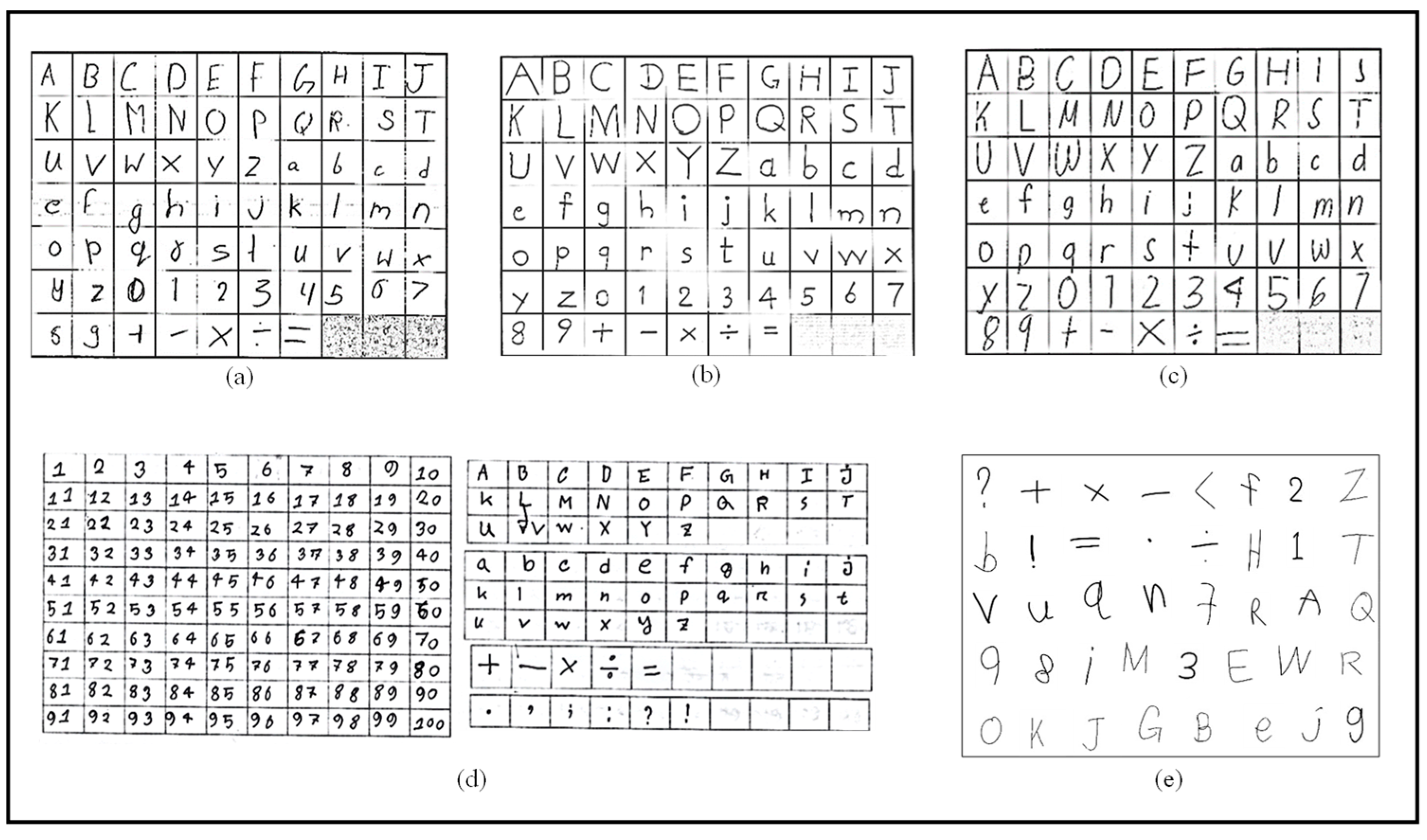
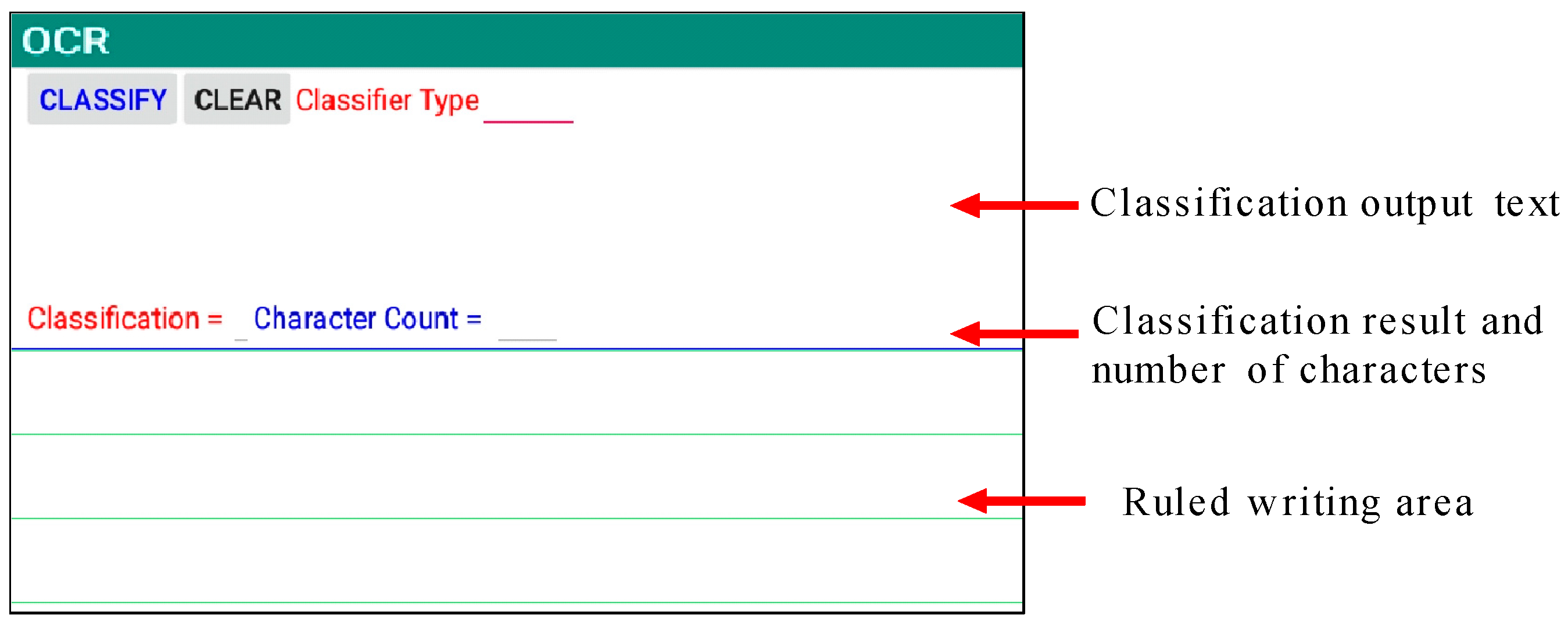
4. Data Collection
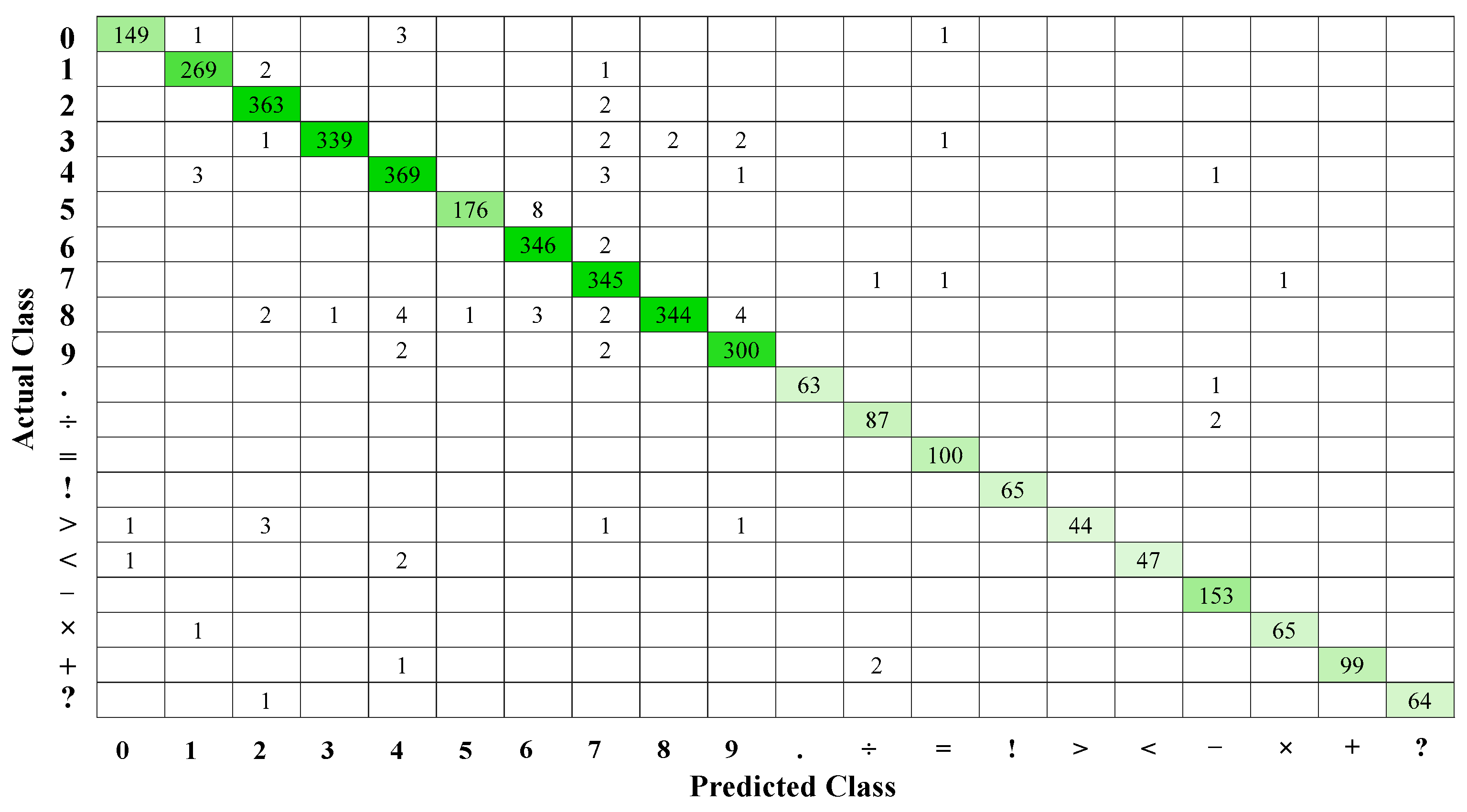
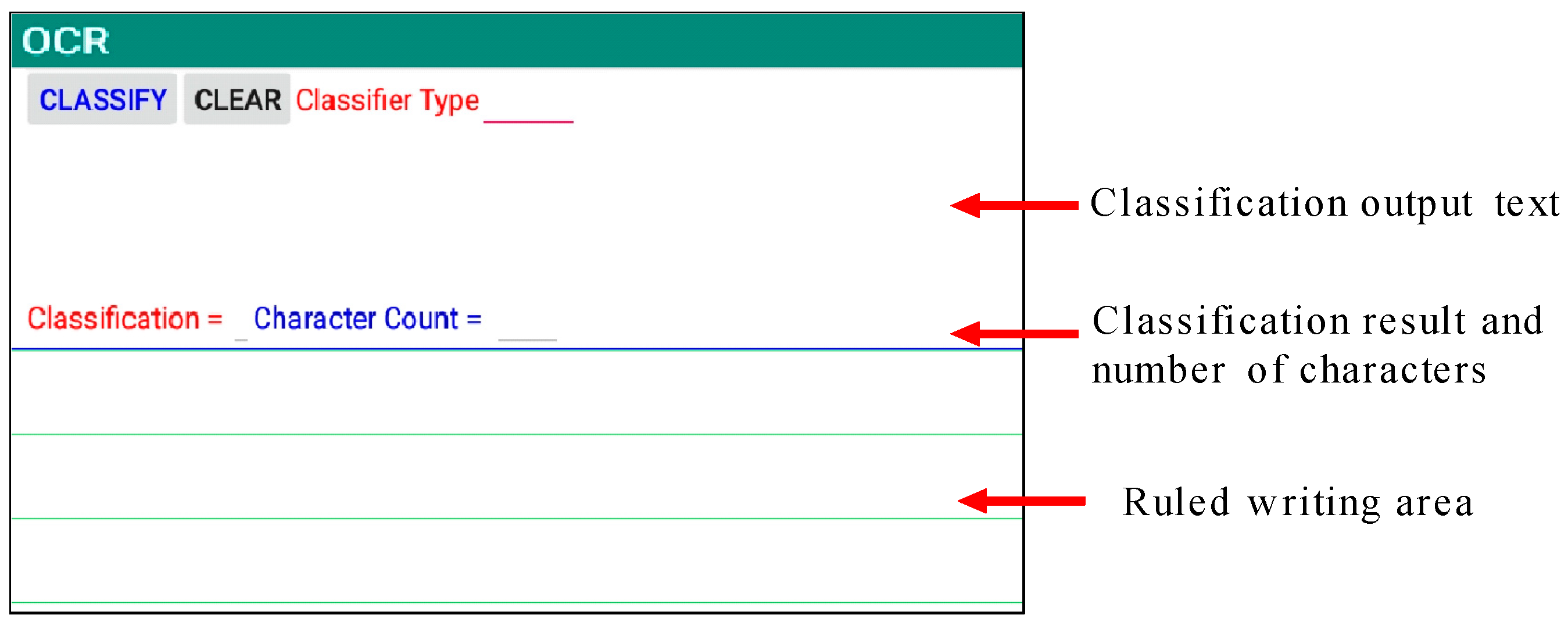
5. Experimental Results
6. Limitations
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sudarsana, K.; Nakayanti, A.R.; Sapta, A.; Haimah; Satria, E.; Saddhono, K.; Daengs GS, A.; Putut, E.; Helda, T.; Mursalin, M. Technology Application in Education and Learning Process. J. Phys. Conf. Ser. 2019, 1363, 1–6. [Google Scholar] [CrossRef]
- Education: Out-of-School Rate for Children of Primary School Age. 2020. Available online: https://data.uis.unesco.org/index.aspx? queryid=123 (accessed on 20 July 2020).
- Weinstein, J. The Problem of Rural Education in the Philippines. 2010. Available online: https://developeconomies.com/ development-economics/the-problem-of-education-in-the-philippines/ (accessed on 20 July 2020).
- Butler, C.; de Pimenta, R.; Fuchs, C.; Tommerdahi, J.; Tamplain, P. Using a handwriting app leads to improvement in manual dexterity in kindergarten children. Res. Learn. Technol. 2019, 27, 1–10. [Google Scholar] [CrossRef]
- Pegrum, M.; Oakley, G.; Faulkner, R. Schools going mobile: A study of the adoption of mobile handheld technologies in Western Australian independent schools. Australas. J. Educ. Technol. 2013, 29, 66–81. [Google Scholar] [CrossRef] [Green Version]
- Stephanie, “Handwriting Apps for Kids”. Available online: https://parentingchaos.com/handwriting-apps-for-kids/ (accessed on 20 July 2020).
- Baldominos, A.; Saez, Y.; Isasi, P. A survey of handwritten character recognition with mnist and emnist. Appl. Sci. 2019, 9, 3169. [Google Scholar] [CrossRef] [Green Version]
- Dewa, C.K.; Fadhilah, A.L.; Afiahayati, A. Convolutional neural networks for handwritten Javanese character recognition. Indones. J. Comput. Cybern. Syst. 2018, 12, 83–94. [Google Scholar] [CrossRef] [Green Version]
- Lincy, R.B.; Gayathri, R. Optimally configured convolutional neural network for Tamil Handwritten Character Recognition by improved lion optimization model. Multimed. Tools Appl. 2021, 80, 5917–5943. [Google Scholar] [CrossRef]
- Zhang, Z.; Tang, Z.; Wang, Y.; Zhang, Z.; Zhan, C.; Zha, Z.; Wang, M. Dense Residual Network: Enhancing global dense feature flow for character recognition. Neural Netw. 2021, 139, 77–85. [Google Scholar] [CrossRef]
- Asif, A.M.A.M.; Hannan, S.A.; Perwej, Y.; Vithalrao, M.A. An Overview and Applications of Optical Character Recognition. Int. J. Adv. Res. Sci. Eng. 2014, 3, 261–274. [Google Scholar]
- Zin, T.T.; Misawa, S.; Pwint, M.Z.; Thant, S.; Seint, P.T.; Sumi, K.; Yoshida, K. Cow Identification System using Ear Tag Recognition. In Proceedings of the 2020 IEEE 2nd Global Conference on Life Sciences and Technologies (LifeTech), Kyoto, Japan, 10–12 March 2020; pp. 65–66. [Google Scholar]
- Zin, T.T.; Pwint, M.Z.; Seint, P.T.; Thant, S.; Misawa, S.; Sumi, K.; Yoshida, K. Automatic Cow Location Tracking System using Ear Tag Visual Analysis. Sensors 2020, 20, 3564. [Google Scholar] [CrossRef]
- Manjunath, A.E.; Sharath, B. Implementing Kannada Optical Character Recognition on the Android Operating System for Kannada Sign Boards. Int. J. Adv. Res. Comput. Commun. Eng. 2013, 2, 932–937. [Google Scholar]
- Perwej, Y.; Chaturvedi, A. Neural Networks for Handwritten English Alphabet Recognition. Int. J. Comput. Appl. 2011, 20, 1–5. [Google Scholar] [CrossRef]
- Gosavi, M.B.; Pund, I.V.; Jadhav, H.V.; Gedam, S.R. Mobile Application with Optical Character Recognition using Neural Network. Int. J. Comput. Sci. Mob. Comput. 2015, 4, 483–489. [Google Scholar]
- Anil, R.; Manjusha, K.; Kumar, S.S.; Soman, K.P. Convolutional Neural Networks for the Recognition of Malayalam Characters. Adv. Intell. Syst. Comput. 2015, 328, 493–500. [Google Scholar] [CrossRef]
- Ly, N.T.; Nguyen, C.T.; Nguyen, K.C.; Nakagawa, M. Deep convolutional recurrent network for segmentation-free offline handwritten Japanese text recognition. In Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; IEEE: Piscataway, NJ, USA, 2017; Volume 7, pp. 5–9. [Google Scholar]
- Xue, W.; Li, Q.; Xue, Q. Text detection and recognition for images of medical laboratory reports with a deep learning approach. IEEE Access 2019, 8, 407–416. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shorim, N.; Ghanim, T.; AbdelRaouf, A. Implementing Arabic Handwritten Recognition Approach using Cloud Computing and Google APIs on a mobile application. In Proceedings of the 14th International Conference on Computer Engineering and Systems (ICCES), Cairo, Egypt, 17 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 88–95. [Google Scholar]
- Ghanim, T.M.; Khalil, M.I.; Abbas, H.M. Multi-stage offline arabic handwritin recognition approach using advanced cascading technique. In Proceedings of the 8th International Conference on Pattern Recognition Applications and Methods (ICPRAM), Prague, Czech Republic, 19–21 February 2019; pp. 532–539. [Google Scholar]
- Zin, T.T.; Thant, S.; Htet, Y. Handwritten Characters Segmentation using Projection Approach. In Proceedings of the 2020 IEEE 2nd Global Conference on Life Sciences and Technologies (LifeTech), Kyoto, Japan, 10–12 March 2020; pp. 107–108. [Google Scholar]
- Vaidya, R.; Trivedi, D.; Satra, S.; Pimpale, M. Handwritten Character Recognition Using Deep-Learning. In Proceedings of the Second International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, 20–21 April 2018; pp. 772–775. [Google Scholar] [CrossRef]
- Weng, Y.; Xia, C. A new deep learning-based handwritten character recognition system on mobile computing devices. Mob. Netw. Appl. 2019, 25, 402–411. [Google Scholar] [CrossRef] [Green Version]
- Anupama, N.; Rupa, C.; Reddy, E.S. Character Segmentation for Telugu Image Document using Multiple Histogram Projections. Glob. J. Comput. Sci. Technol. 2013, 13, 11–15. [Google Scholar]
- Brodowska, M. Oversegmentation Methods for Character Segmentation in Off-line Cursive Handwritten Word Recognition: An Overview. Schedae Inform. 2011, 20, 43–65. [Google Scholar]
- Saba, T.; Rehman, A.; Sulong, G. Cursive Script Segmentation with Neural Confidence. Int. J. Comput. Inf. Control 2011, 7, 4955–4964. [Google Scholar]
- TensorFlow: For Mobile & IoT. Available online: https://www.tensorflow.org/lite (accessed on 20 July 2020).
- Stanek, M. Mobile Intelligence—TensorFlow Lite Classification on Android (added support for TF2.0). 2019. Available online: https://proandroiddev.com/mobile-intelligence-tensorflow-lite-classification-on-android-c081278d9961 (accessed on 20 July 2020).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- MathWorks, “Transfer Learning Using AlexNet”. Available online: https://www.mathworks.com/help/deeplearning/ug/transfer-learning-using-alexnet.html (accessed on 1 March 2021).

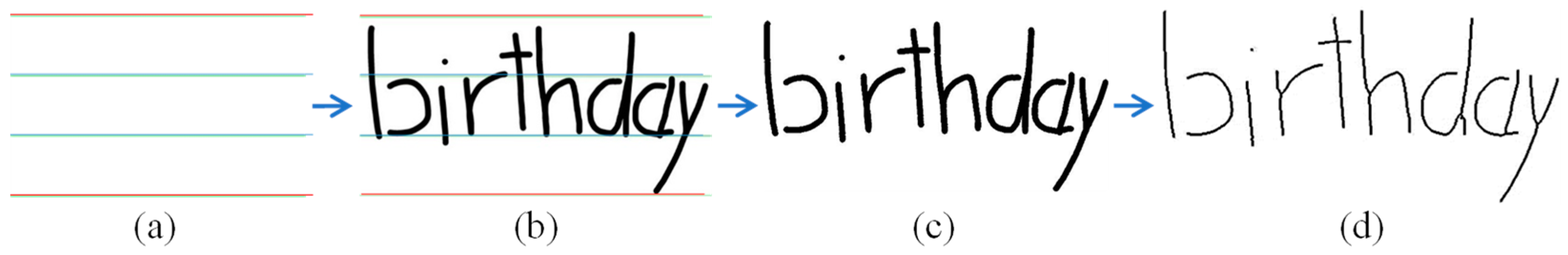




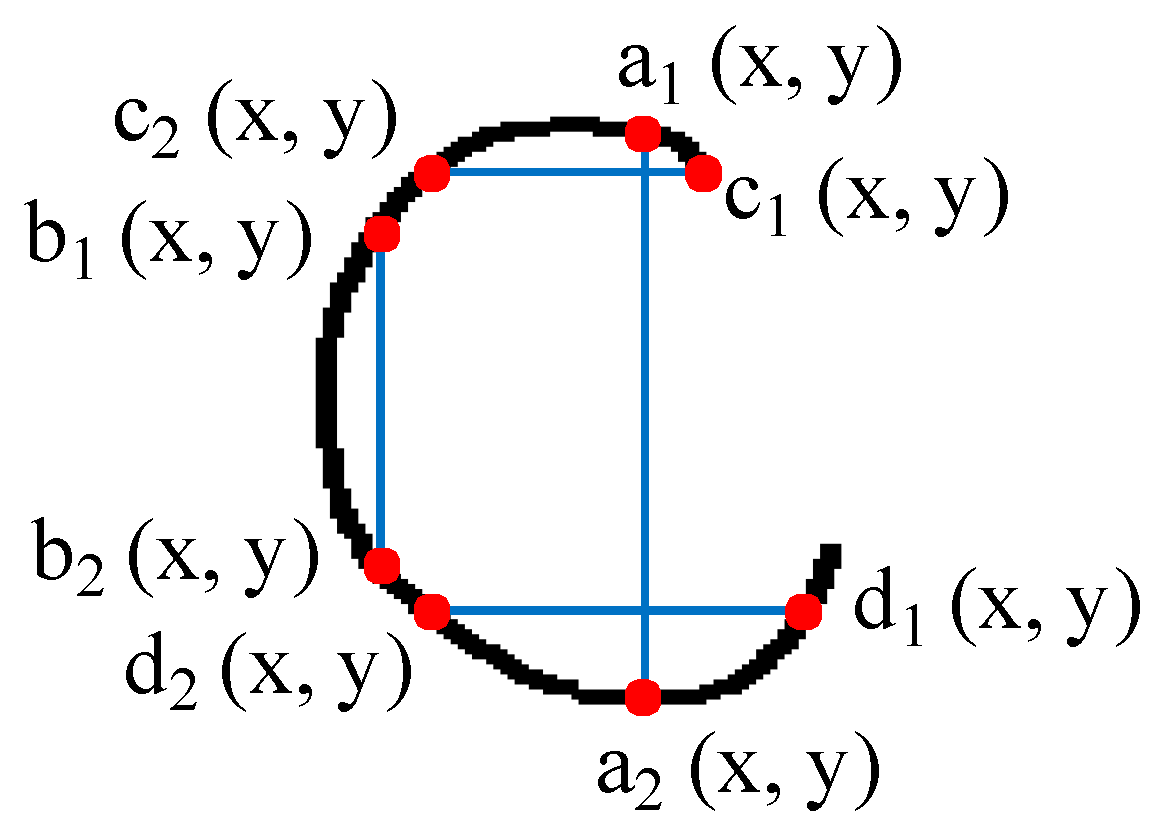





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
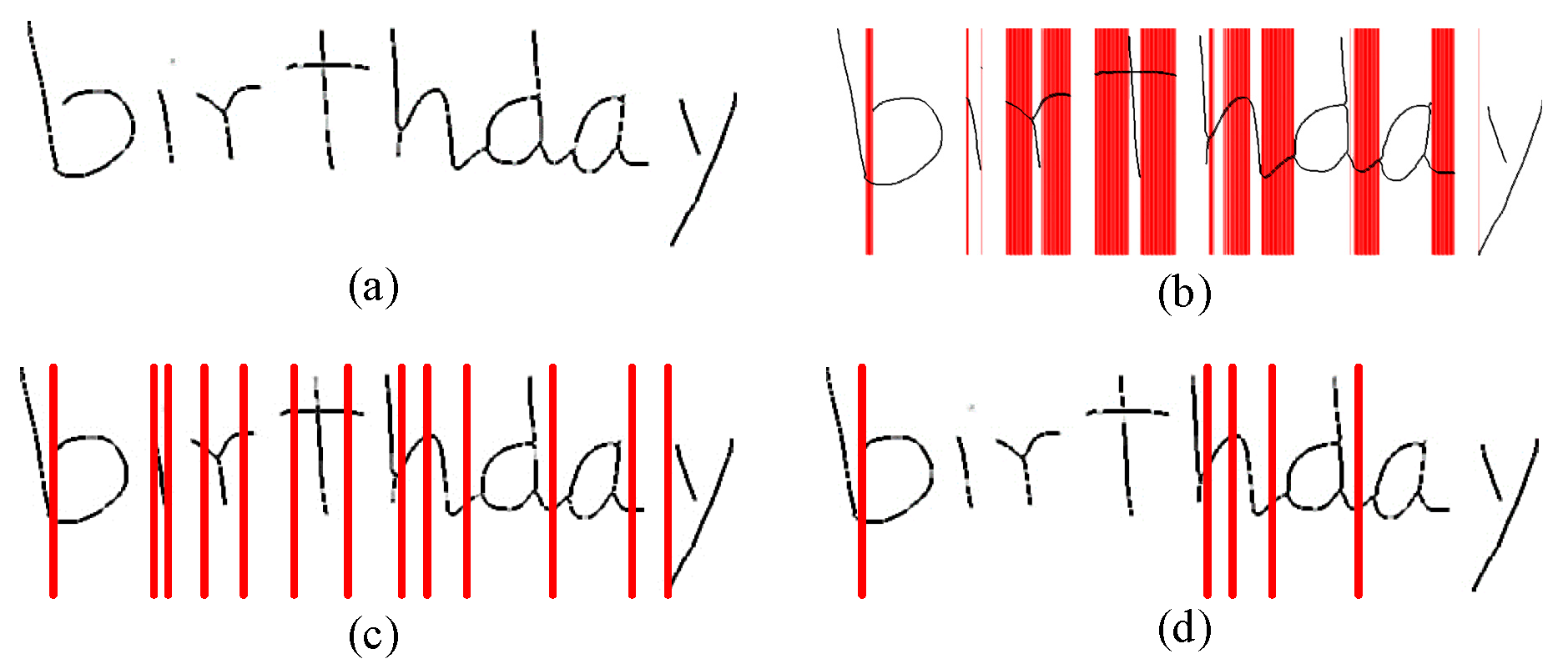{kind=link}
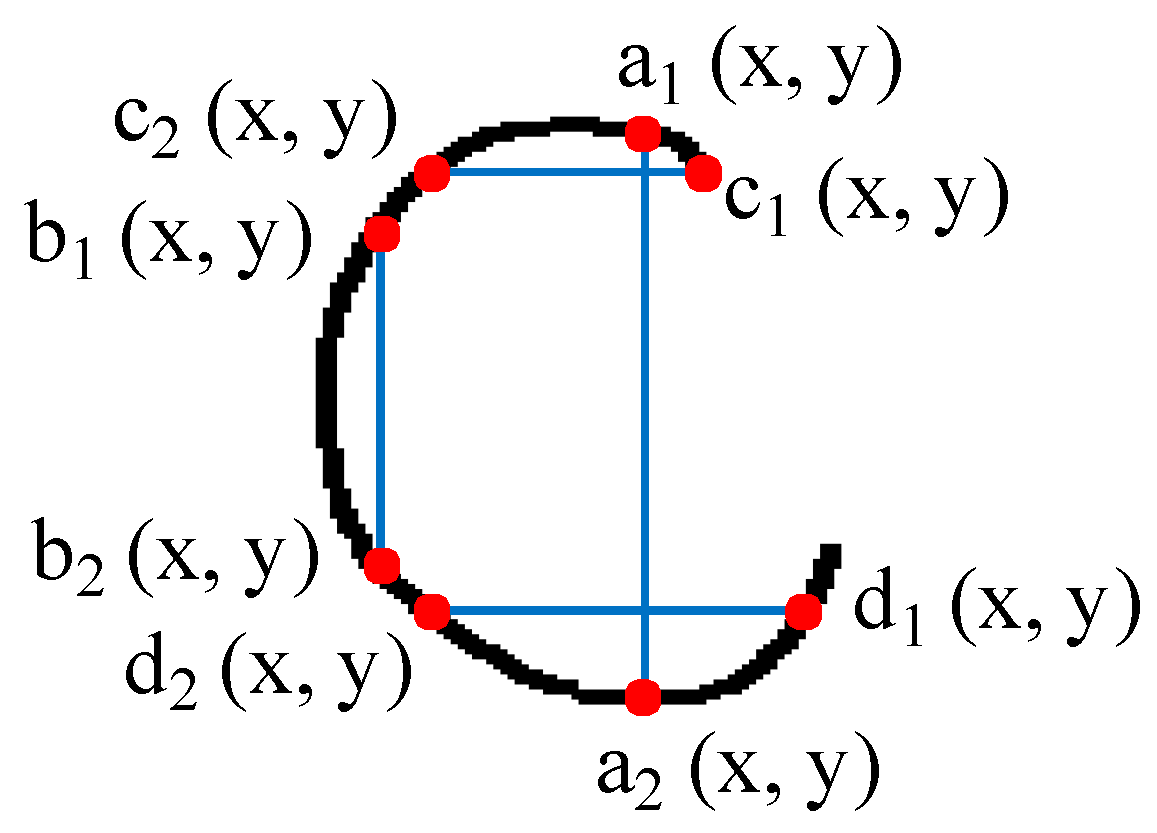{kind=link}
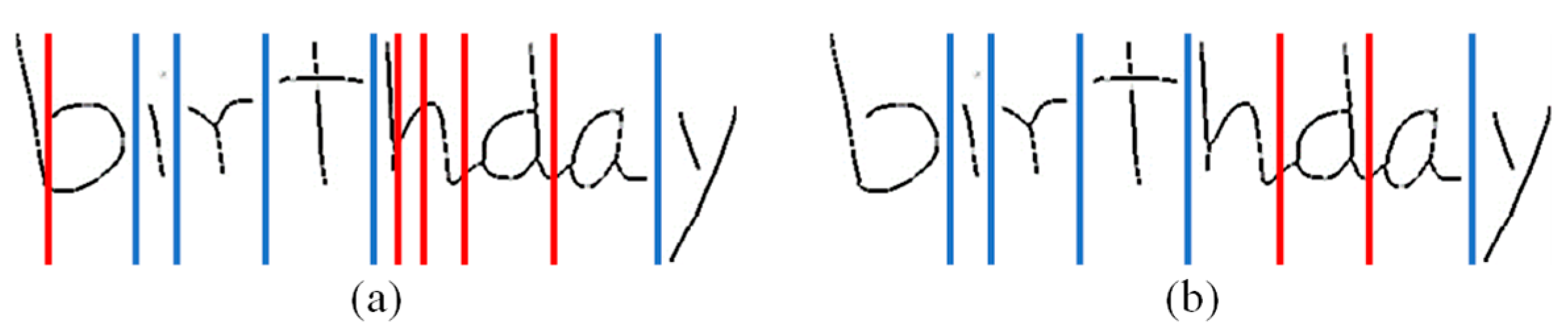{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Information | Digits | Uppercase | Lowercase | Special Characters | Total |
|---|---|---|---|---|---|
| Bangladesh | 5107 | 758 | 754 | 350 | 6969 |
| Nepal | 221 | 600 | 385 | 125 | 1331 |
| Myanmar | 451 | 788 | 1026 | 120 | 2385 |
| Philippines | 134 | 690 | 628 | 283 | 1735 |
| Tablet collected data | 2450 | 6287 | 6292 | 2217 | 17,246 |
| Total | 8363 | 9123 | 9085 | 3095 | 29,666 |
| No. | Type | ID | Training | |
|---|---|---|---|---|
| No. of Images | Accuracy (%) | |||
| 1 | Digits and Special Characters | 1 | 7594 | 99.25 |
| 2 | Uppercase | 2 | 6907 | 98.80 |
| 3 | Lowercase | 3 | 6749 | 98.67 |
| 4 | Uppercase and Lowercase | 4 | 13,656 | 91.97 |
| 5 | Digits and Lowercase | 6 | 12,052 | 95.46 |
| 6 | All combined | 5 | 21,250 | 91.63 |
| No. | Model Name | Layer | Filter Size | Output Feature Map |
|---|---|---|---|---|
| 1 | M1 | First Layer | 5 × 5 | 16 |
| Second Layer | 5 × 5 | 32 | ||
| Third Layer | 3 × 3 | 64 | ||
| 2 | M2 | First Layer | 5 × 5 | 32 |
| Second Layer | 5 × 5 | 64 | ||
| Third Layer | 3 × 3 | 128 | ||
| 3 | Mp | First Layer | 3 × 3 | 20 |
| Second Layer | 5 × 5 | 40 | ||
| Third Layer | 5 × 5 | 60 |
| No. | Type | No. of Testing Images | Testing Accuracy (%) | ||
|---|---|---|---|---|---|
| M1 | M2 | Mp | |||
| 1 | Digit and Special Characters | 3864 | 95.39 | 96.84 | 98.01 |
| 2 | Uppercase | 2216 | 96.34 | 96.12 | 97.43 |
| 3 | Lowercase | 2336 | 88.14 | 89.43 | 92.72 |
| 4 | Uppercase and Lowercase | 4552 | 80.67 | 79.13 | 82.97 |
| 5 | Digit and Lowercase | 5396 | 88.55 | 88.88 | 91.14 |
| 6 | All combine | 8416 | 82.32 | 82.31 | 85.74 |
| No. | Type | Testing Accuracy (%) | ||
|---|---|---|---|---|
| HOG + SVM | AlexNet | Mp | ||
| 1 | Digit and Special Characters | 97.05 | 97.23 | 98.01 |
| 2 | Uppercase | 97.25 | 97.02 | 97.43 |
| 3 | Lowercase | 90.03 | 88.36 | 92.72 |
| 4 | Uppercase and Lowercase | 79.70 | 81.24 | 82.97 |
| 5 | Digit and Lowercase | 88.64 | 89.60 | 91.14 |
| 6 | All combine | 82.56 | 84.19 | 85.74 |
| Result | Correct Count | Incorrect Count | Total Count | Accuracy (%) |
|---|---|---|---|---|
| Words | 985 | 15 | 1000 | 98.50 |
| Result | Correct Count | Incorrect Count | Total Count | Accuracy (%) |
|---|---|---|---|---|
| Words | 956 | 44 | 1000 | 95.60 |
| Characters | 4550 | 57 | 4607 | 98.76 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zin, T.T.; Thant, S.; Pwint, M.Z.; Ogino, T. Handwritten Character Recognition on Android for Basic Education Using Convolutional Neural Network. Electronics 2021, 10, 904. https://doi.org/10.3390/electronics10080904
Zin TT, Thant S, Pwint MZ, Ogino T. Handwritten Character Recognition on Android for Basic Education Using Convolutional Neural Network. Electronics. 2021; 10(8):904. https://doi.org/10.3390/electronics10080904
Chicago/Turabian StyleZin, Thi Thi, Shin Thant, Moe Zet Pwint, and Tsugunobu Ogino. 2021. "Handwritten Character Recognition on Android for Basic Education Using Convolutional Neural Network" Electronics 10, no. 8: 904. https://doi.org/10.3390/electronics10080904
APA StyleZin, T. T., Thant, S., Pwint, M. Z., & Ogino, T. (2021). Handwritten Character Recognition on Android for Basic Education Using Convolutional Neural Network. Electronics, 10(8), 904. https://doi.org/10.3390/electronics10080904