1. Introduction
Biological neural networks are complex and are composed of a large number of interconnected neurons. A neuron is an electrically excitable cell and consists of three typical parts, including a soma (cell body), dendrites, and an axon. Dendrites are filamentous and branch multiple times, constituting the dendritic tree of a neuron. An axon is a slender projection of a neuron. In general, a neuron receives signals via the synapses, which are located on its dendritic tree. Then, the neuron sends out processed signals down its axon. Inspired by the biological neuron model, McCulloch and Pitts first mathematically proposed an artificial neuron model in 1943 [
1]. This model worked as a linear threshold gate by comparing a predefined threshold with the sum of inputs that were multiplied by a set of weights. Later, Rosenblatt optimized the artificial neuron model and developed the first perceptron [
2]. However, these models are considered to be simplistic and lack flexible computational features. Specifically, nonlinear mechanisms of dendrites were not involved in these models [
3].
Koch, Poggio, and Torre are the pioneers who investigated the nonlinear mechanisms of dendrites. They proposed a dendritic neuron model called
cell in [
4,
5]. This model was based on the nonlinear interactions between excitation and inhibition on a dendritic branch. Further studies [
6,
7,
8] also made researchers aware of the importance of dendrites in neural computation. Subsequently, numerous neuron models based on dendritic computation were proposed. For example, Rhodes et al. proposed a model with apical dendrites to reproduce different neuronal firing patterns [
9]. Poirazi et al. proposed a neural network model with a nonlinear operation on dendrites [
10]. Todo et al. enhanced the nonlinear interaction on the dendrites of a neuron model to simulate directionally selective cells [
11]. These works all strengthened the necessity of incorporating mechanisms of dendrites into neural computation.
A classification problem refers to the task where similar objects are grouped into the same classes according to their attributes. Owing to the distinguishing learning capability of artificial neural networks (ANNs), they have been regarded as an alternative classification model for various classification problems, such as credit risk evaluation [
12], human recognition [
13,
14], electroencephalography analysis [
15], and disease diagnostics [
16]. Although ANNs have shown their high performance for solving classification problems, some issues remain challenging in the application of ANNs. For example, an ANN is not considered as an interpretable model [
17]. A determined ANN provides us with little insight into how the classification results are concluded [
18]. In addition, as the number of dimensions of a classification problem increases, the size of the ANN grows sharply. Consequently, the training process becomes difficult, and the classification process becomes more time-consuming.
The performance of an ANN is characterized by its learning methods [
19]. Backpropagation (BP) algorithms [
20,
21,
22] are commonly used to train ANNs. These BP algorithms utilize the gradient information of the loss function and adjust the weights of neurons in the negative gradient direction. However, the BP algorithms and their variations suffer from two main disadvantages. First, since BP algorithms are the gradient descent algorithms, they are highly sensitive to the initial conditions of an ANN. In other words, BP algorithms may not always find a solution and easily become trapped in local minima [
23]. Second, it is not easy to set the learning rate for fast and stable learning. An unsuitable value results in slow convergence or divergence [
24]. On the other hand, recent studies have shown that heuristic optimization methods are considered to perform well in the training of ANNs because ANNs are natively suitable for global optimization [
25]. These training methods based on heuristic optimization include particle swarm optimization (PSO) [
26], the genetic algorithm (GA) [
27], the biogeography-based optimizer (BBO) [
28], and differential evolution (DE) [
29].
In recent years, the use of an artificial neuron model to resolve practical problems has aroused the interest of many researchers. For example, Arec et al. proposed a dendrite morphological neural network with an efficient training algorithm for some synthetic problems and a real-life problem [
30]. Hernandez-Barragan et al. proposed an adaptive single-neuron proportional–integral–derivative controller to manipulate a four-wheeled omnidirectional mobile robot [
31]. Luo et al. proposed a decision-tree-initialized dendritic neuron model for fast and accurate data classification [
32]. In our previous works, various neuron models involved with dendritic computation have been proposed to tackle several real-world issues, such as classification [
33,
34], function approximation [
35], financial time series prediction [
36], liver disorder diagnosis [
37], tourism demand forecasting [
38], and credit risk evaluation [
39]. These applications demonstrated the advantages of the dendritic neuron models in solving complicated problems. However, it should be pointed out that the sizes of these proposed neuron models are not very large because the corresponding problems are small-scale applications. Applying dendritic neuron models to large-scale problems has not yet been explored. This prompts us to verify whether a dendritic neuron model can be applied to solve high-dimensional classification problems. On the other hand, with the trend of big data [
40,
41], not only the dimension but also the number of instances of classification problems becomes increasingly large. As a result, the classification speed of a classifier has drawn the attention of researchers [
42,
43]. Importantly, we also focus on this aspect when applying dendritic neuron models to high-dimensional classification problems.
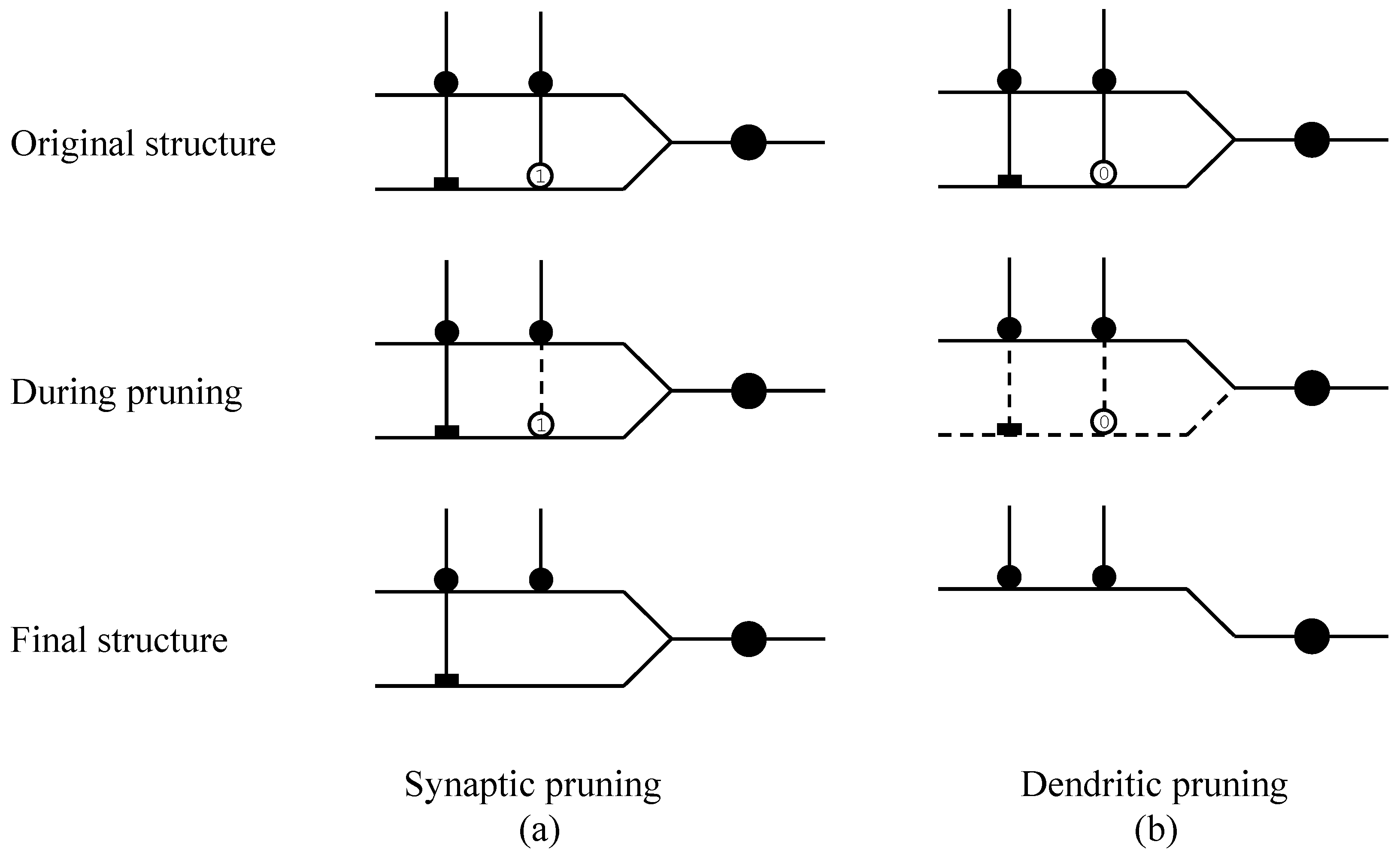
In this study, a neuron model with dendrite morphology called LDNM is proposed to solve high-dimensional classification problems. This neuron model contains four layers: a synaptic layer, a dendritic layer, a membrane layer, and a soma body. The LDNM has structural plasticity, and a trained LDNM can be simplified by means of synaptic pruning and dendritic pruning. It is worth emphasizing that a simplified LDNM can be further transformed into a logic circuit classifier (LCC), which only consists of digital components: comparator, NOT, AND, and OR gates. Compared to most conventional classification methods [
44], the proposed LDNM has two novel features. First, for a specific classification problem, the architecture of the trained LDNM can give us some insights into how the classification results are concluded. Second, the trained LDNM can be transformed into an LCC. The classification speed of the LCC is greatly improved when it is implemented in hardware because it only consists of digital components. On the other hand, since the size of the LDNM is considered large when it is applied in high-dimensional classification problems, a heuristic optimization algorithm instead of a BP algorithm is employed in training the LDNM. In addition, feature selection is employed as the dimension reduction method to address the high-dimensional challenge. Finally, five high-dimensional benchmark classification problems are used to evaluate the performance of the proposed model. The experimental results evidence the high performance of LDNM as a very competitive classifier.
The remainder of this paper is organized as follows. The characteristics of the proposed LDNM are described in
Section 2.
Section 3 presents the two training methods. The experimental studies are provided in
Section 4. Finally,
Section 5 presents the conclusions of this paper.
5. Conclusions
Recent research has strongly suggested that dendrites play an important role in neural computation. In this paper, a novel neuron model with dendrite morphology, called the logic dendritic neuron model, was proposed for solving classification problems. This model consists of four layers: a synaptic layer, a dendritic layer, a membrane layer, and a soma body. To apply this model to high-dimensional classification problems, we employed the feature selection method to reduce the dimensionality of the classification problems, although the reduced dimensionality is still comparatively high for the proposed LDNM. In addition, we attempted to use a heuristic optimization algorithm called CSO to train the proposed LDNM. This method was verified to be more suitable than BP in training the LDNM with numerous synaptic parameters. Finally, we compared LDNM with the other six classical classifiers on five classification problems to verify its performance. The comparison result indicated that the proposed LDNM can obtain better or very competitive results with these classifiers in terms of test classification accuracy.
It is worth pointing out that the proposed LDNM has two unique characteristics. First, a trained LDNM can be simplified by synaptic pruning and dendritic pruning. Second, the simplified LDNM can be transformed into a logic circuit classifier for a specific classification problem. It can be expected that the speed achieved by the logic circuit classifier is high when this model is implemented in hardware. In addition, the the trained LDNM provides us with some insights into the specific problem. However, it should be noted that the feature selection method chosen in this study was very simple. Therefore, more effective feature selection methods are required when solving more complicated problems.
In future studies, we will apply the proposed LDNM to more classification tasks to verify its effectiveness. The improvement of the architecture of the dendritic neuron model and the learning methods deserve our unremitting efforts. In addition, extending the proposed LDNM to dealing with multiclass classification problems is worth investigating. Moreover, implementing the proposed LDNM as a module unit in hardware is our future research topic.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}