A Low-Complexity Edward-Curve Point Multiplication Architecture




Abstract
:1. Introduction
1.1. Related Work for BEC Implementations
1.2. Limitations of Existing Practices
1.3. Contributions
- A low-complexity binary edward-curve PM architecture over with is proposed.
- For unified PA and PD laws of BEC, the instruction-level-complexity is reduced by eliminating multiple operations in a single instruction format (details are provided in Section 3.2.1).
- To save hardware resources and reduce clock cycles, the minimization of storage elements is provided by using efficient replacements of required memory addresses. It shows 7.2% decrease in total number of required clock cycles and 28.5% decrease in hardware resources (see Section 3.2.2).
- A 32- digit-parallel FF multiplier is employed instead of bit-serial and digit-serial FF multipliers. For one FF multiplication, the digit-parallel requires only one clock cycle while the bit-serial and digit-serial FF multipliers require m and clock cycles (where, m is the field size and v is the digit-size). The used FF multiplier ultimately reduces the required number of clock cycles.
- To speed-up control functionalities, a Finite State Machine (FSM) controller is used in this work.
2. Mathematical Background
2.1. BEC over
2.2. Differential PA and PD Laws for BEC over
2.3. Point Multiplication on BEC
| Algorithm 1: Montgomery point multiplication algorithm [20] |
 |
3. Optimization of Differential Addition Law for BEC
3.1. Limitations of the PA Law for BEC
- There are total 7 complex mathematical instructions, which are required for the complete PA and PD law (i.e., to ), as shown in column 2 of Table 1. The term complexity implies that there are many arithmetic operations in a single instruction. These operations are performed in parallel, which results in higher hardware resources.
- The total number of storage elements, required for the complete PA and PD law of Table 1, are . The number 11 indicates the total storage elements while m determines the width of each element. The requirement of high storage elements ultimately increases the hardware resources utilization.
3.2. Proposed Optimizations
3.2.1. Elimination of Multiple Operations in a Single Instruction
3.2.2. Minimization of Storage Elements
4. Proposed Binary Edward Curve Point Multiplication Architecture
4.1. Memory Unit
4.2. Data Path Unit
4.2.1. Routing Networks
4.2.2. Arithmetic Logic Unit
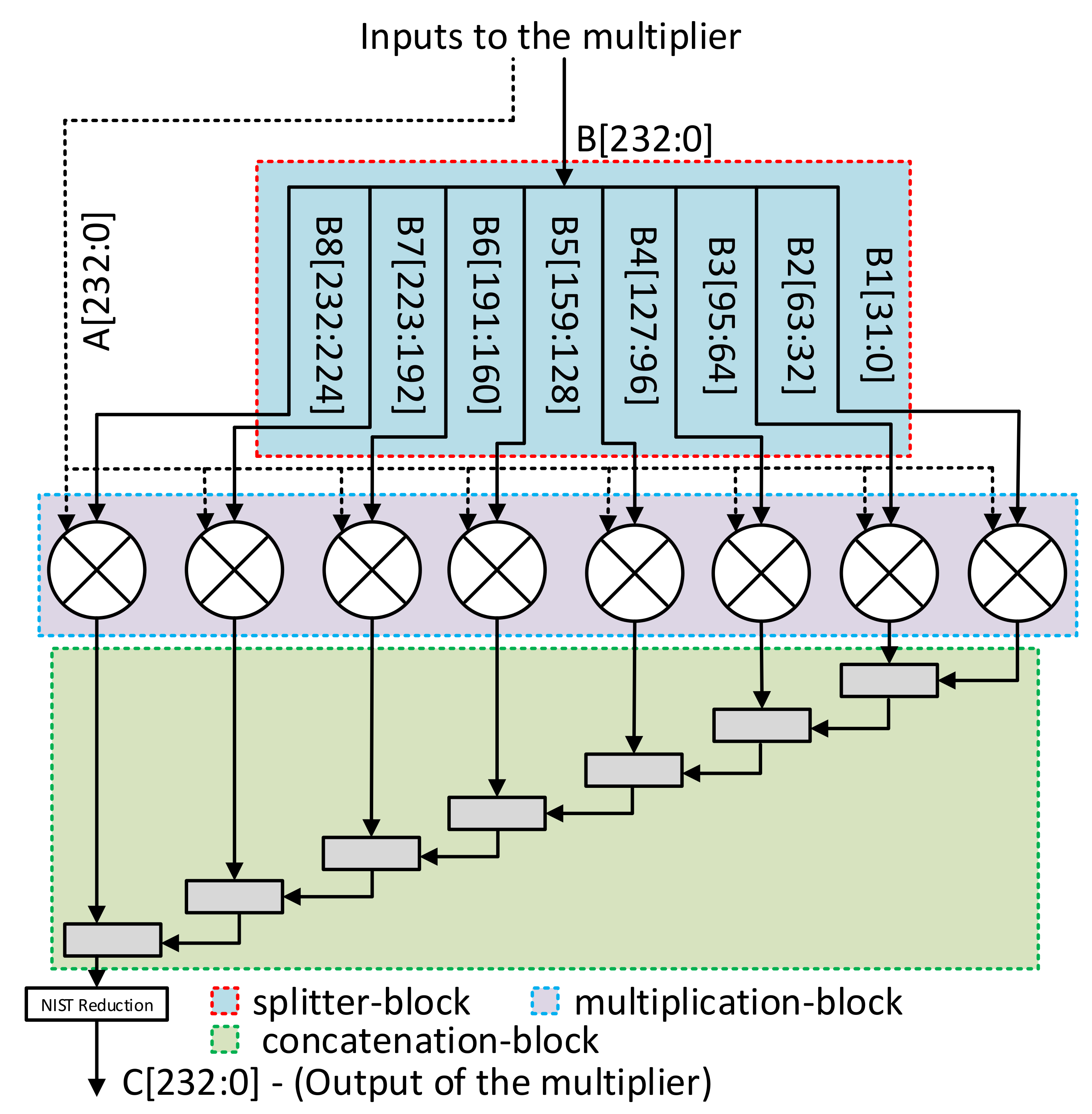
- splitter-block: The splitter-block takes one 233- polynomial (i.e., B) as an input and results digits (i.e., to ) of polynomial B as an output. In other words, it is responsible to split one input polynomial out of the required two (the multiplier requires two operands as inputs and results one operand as an output). The selection of an operand to split always depends on the designer. Figure 3 shows that the input polynomial is divided B into eight digits, i.e., to , with a digit size of 32- each except the last digit, i.e., . To perform multiplication, the required size for the last digit is 9-.
- multiplication-block: As shown in Figure 3, the complete multiplication-block comprises of eight instances of smaller multipliers. Each smaller instance of a multiplier is responsible to perform a polynomial multiplication in parallel. Furthermore, it takes two input polynomials. These polynomials are A and a digit of polynomial B. The corresponding lengths of A and B are 232 and 32-, respectively. Consequently, the output of each instance of a smaller multiplier is -. Here, d represents the size of each created digit of polynomial B (i.e., 32-). Similarly, m shows the length of input polynomial A (i.e., 233-).
- concatenation-block: The concatenation-block takes eight inputs. The length of each input is - each (generated by the multiplication-block). It provides an output polynomial of length -. The length of output polynomial is not shown in Figure 3. The internal structure of a concatenation block consists of seven arrays of XOR gates. These arrays are shown with the gray color blocks inside the concatenation-block of Figure 3. The concatenation operation is performed using shift and add operations.
4.3. Control Unit
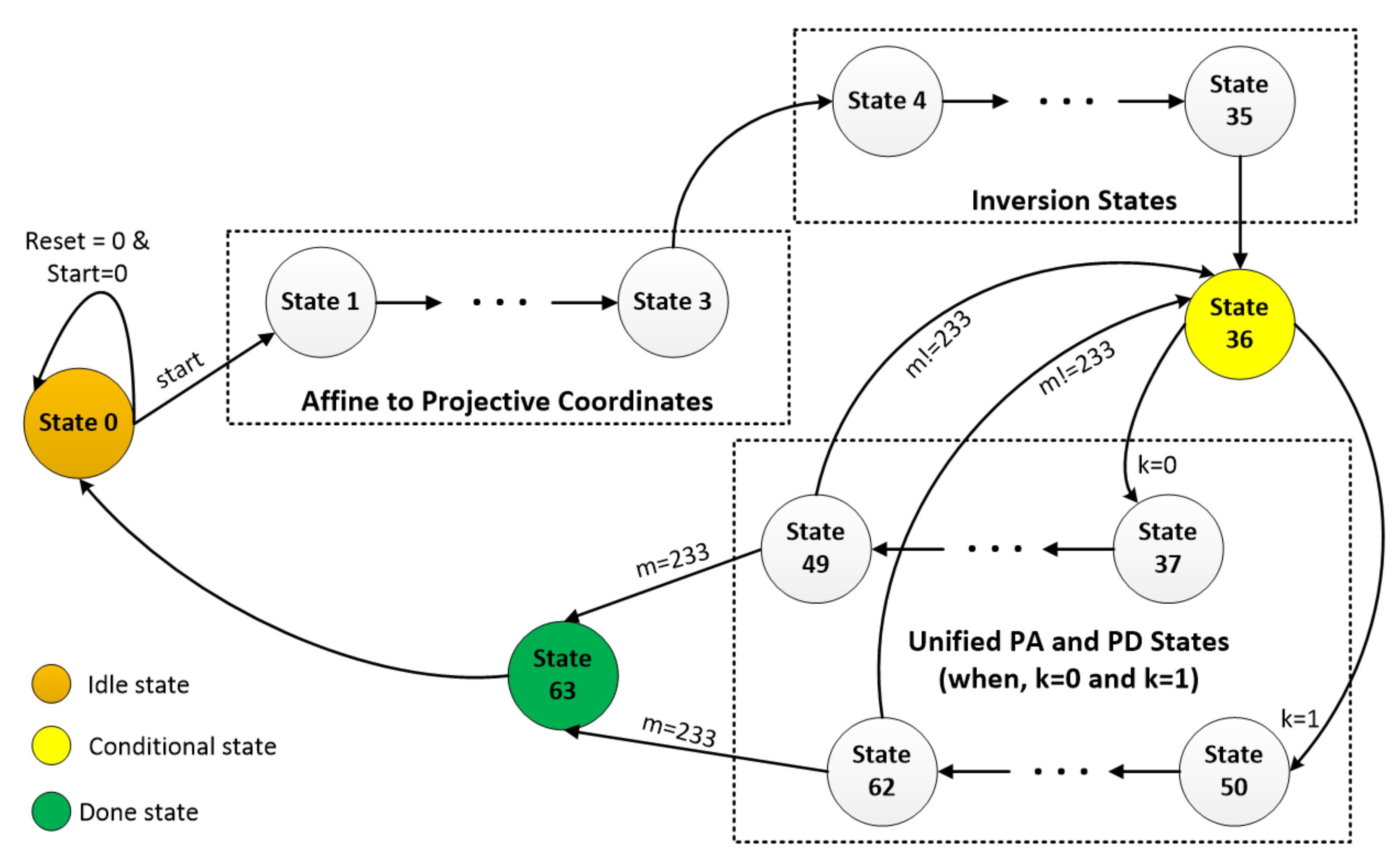
- State 0 is an idle state. The reset and start signals determine the start of execution process.
- Once the start signal becomes 1, the current state (State 0) of the processor switches to nextstate (State 1), as shown in Figure 2. Moreover, the State 1 to State 3 generate control signals for the affine to projective conversions of Algorithm 1.
- The State 4 to State 35 generate control signals for inversion operation using Quad block Ithoh-Tusuji algorithm of [34].
- State 36 counts the number of points on the specified BEC curve. Additionally, it also checks the inspected key bit (k). If the value of k is 1, the nextstate from State 36 is 50, otherwise the nextstate is State 37, as shown in Figure 4.
- State 50 to State 62 compute part of the Algorithm 1. Similarly, State 37 to State 49 generate control signals for the part of Algorithm 1. For each value of k (either 0 or 1), the last states, i.e., State 49 and State 62, also check the number of points (using m in Figure 4) on the specified BEC curve. Once the value for m becomes 233 (initially, it is set to 1), the next state from State 49 and State 62 becomes State 63, otherwise the nextstate is State 36. Finally, the last state (State 63) sets the signal indicating that processor has finished the computation of PM operation and returns back to State 0.
5. Results and Comparisons
5.1. Performance Metric
5.2. Performance Results
5.3. Performance Comparison with State-of-the-Art
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bansal, S.; Kumar, D. IoT Ecosystem: A Survey on Devices, Gateways, Operating Systems, Middleware and Communication. Int. J. Wirel. Inf. Netw. 2020, 27, 340–364. [Google Scholar] [CrossRef]
- Pal, S.; Hitchens, M.; Rabehaja, T.; Mukhopadhyay, S. Security Requirements for the Internet of Things: A Systematic Approach. Sensors 2020, 20, 5897. [Google Scholar] [CrossRef] [PubMed]
- Mthunzi, S.N.; Benkhelifa, E.; Bosakowski, T.; Guegan, C.G.; Barhamgi, M. Cloud computing security taxonomy: From an atomistic to a holistic view. Future Gener. Comput. Syst. 2020, 107, 620–644. [Google Scholar] [CrossRef]
- Hossain, M.; Fotouhi, M.; Hasan, R. Towards an Analysis of Security Issues, Challenges, and Open Problems in the Internet of Things. In Proceedings of the 2015 IEEE World Congress on Services, New York, NY, USA, 27 June–2 July 2015; pp. 21–28. [Google Scholar]
- Agarwal, S.; Oser, P.; Lueders, S. Detecting IoT Devices and How They Put Large Heterogeneous Networks at Security Risk. Sensors 2019, 19, 4107. [Google Scholar] [CrossRef] [Green Version]
- Kumar, P.; Bhatt, A.K. Enhancing multi-tenancy security in the cloud computing using hybrid ECC-based data encryption approach. IET Commun. 2020, 14, 3212–3222. [Google Scholar] [CrossRef]
- Sfar, A.R.; Natalizio, E.; Challal, Y.; Chtourou, Z. A roadmap for security challenges in the Internet of Things. Digit. Commun. Netw. 2018, 4, 118–137. [Google Scholar] [CrossRef]
- Hu, X.; Zheng, X.; Zhang, S.; Li, W.; Cai, S.; Xiong, X. A High-Performance Elliptic Curve Cryptographic Processor of SM2 over GF(p). Electronics 2019, 8, 431. [Google Scholar] [CrossRef] [Green Version]
- Rashid, M.; Jafri, A.R.; Al-Somani, T.F. Flexible architectures for cryptographic algorithms: a systematic literature review. J. Circuits Syst. Comput. 2019, 28, 1930003. [Google Scholar] [CrossRef]
- Hu, X.; Zheng, X.; Zhang, S.; Cai, S.; Xiong, X. A Low Hardware Consumption Elliptic Curve Cryptographic Architecture over GF(p) in Embedded Application. Electronics 2018, 7, 104. [Google Scholar] [CrossRef] [Green Version]
- Rashid, M.; Imran, M.; Sajid, A. An Efficient Elliptic-curve Point Multiplication Architecture for High-speed Cryptographic Applications. Electronics 2020, 9, 2126. [Google Scholar] [CrossRef]
- Awaludin, A.M.; Larasati, H.T.; Kim, H. High-Speed and Unified ECC Processor for Generic Weierstrass Curves over GF(p) on FPGA. Sensors 2021, 21, 1451. [Google Scholar] [CrossRef]
- Bernstein, D.; Lange, T.; Farashahi, R.R. Binary Edwards Curves. Lect. Notes Comput. Sci. 2008, 5154, 244–265. [Google Scholar]
- Smart, N.P. The Hessian form of an elliptic curve. Lect. Notes Comput. Sci. 2001, 2162, 118–125. [Google Scholar]
- Joye, M.; Tibouchi, M.; Vergnaud, D. Huff’s model for elliptic curve, Algorithmic Number Theory (ANTS-IX). Lect. Notes Comput. Sci. 2010, 6197, 234–250. [Google Scholar]
- Suárez-Albela, M.; Fraga-Lamas, P.; Fernández-Caramés, T.M. A Practical Evaluation on RSA and ECC-Based Cipher Suites for IoT High-Security Energy Efficient Fog and Mist Computing Devices. Sensors 2018, 18, 3868. [Google Scholar] [CrossRef] [Green Version]
- Azarderakhsh, R.; Reyhani-Masoleh, A. Efficient FPGA Implementations of Point Multiplication on Binary Edwards and Generalized Hessian Curves Using Gaussian Normal Basis. IEEE Trans. Very Large Scale Integr. Syst. 2012, 20, 1453–1466. [Google Scholar] [CrossRef]
- Lucca, A.V.; Sborz, G.A.M.; Leithardt, V.R.Q.; Beko, M.; Zeferino, C.A.; Parreira, W.D. A Review of Techniques for Implementing Elliptic Curve Point Multiplication on Hardware. J. Sens. Actuator Netw. 2021, 10, 3. [Google Scholar] [CrossRef]
- Chatterjee, A.; Gupta, I.S. FPGA implementation of extended reconfigurable binary Edwards curve based processor. In Proceedings of the International Conference on Computing, Networking and Communications, Maui, HI, USA, 30 January–2 February 2012; pp. 211–215. [Google Scholar]
- Rashidi, B. Efficient hardware implementations of point multiplication for binary Edwards curves. Int. J. Circuit Theory Appl. 2018, 46, 1516–1533. [Google Scholar] [CrossRef]
- Rashidi, B.; Abedini, M. Efficient Lightweight Hardware Structures of Point Multiplication on Binary Edwards Curves for Elliptic Curve Cryptosystems. J. Circuits Syst. Comput. 2019, 28, 1950149. [Google Scholar] [CrossRef]
- Rashidi, B.; Farashahi, R.R.; Sayedi, S.M. High-speed Hardware Implementations of Point Multiplication for Binary Edwards and Generalized Hessian Curves. IACR Cryptol. Eprint Arch. 2017, 2017, 5. [Google Scholar]
- Fournaris, A.P.; Koufopavlou, O. Affine coordinate binary edwards curve scalar multiplier with side channel attack resistance. In Proceedings of the Euromicro Conference on Digital System Design, Madeira, Portugal, 26–28 August 2015; pp. 431–437. [Google Scholar]
- Lara-Nino, C.A.; Diaz-Perez, A.; Morales-Sandoval, M. Lightweight elliptic curve cryptography accelerator for internet of things applications. Ad Hoc Netw. 2020, 103, 102159. [Google Scholar] [CrossRef]
- Salarifard, R.; Bayat-Sarmadi, S.; Mosanaei-Boorani, H. A Low-Latency and Low-Complexity Point-Multiplication in ECC. IEEE Trans. Circuits Syst. I Regul. Pap. 2018, 65, 2869–2877. [Google Scholar] [CrossRef]
- Choi, P.; Lee, M.; Kim, J.; Kim, D.K. Low-Complexity Elliptic Curve Cryptography Processor Based on Configurable Partial Modular Reduction Over NIST Prime Fields. IEEE Trans. Circuits Syst. II Express Briefs 2018, 65, 1703–1707. [Google Scholar] [CrossRef]
- Choi, P.; Lee, M.; Kim, J.; Kim, D.K. Low-Cost and Fast Hardware Implementations of Point Multiplication on Binary Edwards Curves. In Proceedings of the Iranian Conference on Electrical Engineering (ICEE), Mashhad, Iran, 8–10 May 2018; pp. 17–22. [Google Scholar]
- Mehrabi, M.A.; Doche, C. Low-Cost, Low-Power FPGA Implementation of ED25519 and CURVE25519 Point Multiplication. Information 2019, 10, 285. [Google Scholar] [CrossRef] [Green Version]
- Islam, M.M.; Hossain, M.S.; Hasan, M.K.; Shahjalal, M.; Jang, Y.M. Design and Implementation of High-Performance ECC Processor with Unified Point Addition on Twisted Edwards Curve. Sensors 2020, 20, 5148. [Google Scholar] [CrossRef]
- Jin, C.; Xu, C.; Zhang, X.; Li, F. A Secure ECC-based RFID Mutual Authentication Protocol to Enhance Patient Medication Safety. J. Med Syst. 2016, 40, 1. [Google Scholar] [CrossRef]
- Lee, C.; Li, C.; Chen, Z.; Chen, S.; Lai, Y. A novel authentication scheme for anonymity and digital rights management based on elliptic curve cryptography. Int. J. Electron. Secur. Digit. Forensics 2019, 11, 96–117. [Google Scholar] [CrossRef]
- Farashahi, R.R.; Hosseini, S.G. Differential Addition on Binary Elliptic Curves. In Proceeding of International Workshop on the Arithmetic of Finite Fields, Ghent, Belgium, 13–15 July 2016; pp. 349–364. [Google Scholar]
- Federal Information Processing Standards Publication (FIPS PUB 186-4). Digital Signature Standard (DSS). Available online: https://nvlpubs.nist.gov/nistpubs/FIPS/NIST.FIPS.186-4.pdf (accessed on 13 April 2021).
- Parrilla, L.; Lloris, A.; Castillo, E.; Garcia, A. Minimum-clock-cycle Itoh-Tsujii algorithm hardware implementation for cryptography applications over GF(2233) fields. Electron. Lett. 2012, 48, 1126–1128. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Instri | Complete PA and PD Laws. It Requires Memory Size |
|---|---|
| w) |
| Clock | Instri | Addition Law (from Table 1) | Proposed Simplified Formulations | Memory |
|---|---|---|---|---|
| Cycles | Storage Elements) | Storage Elements) | Replacements | |
| 1 | A with | |||
| 2 | B with | |||
| 3 | C with | |||
| 4 | = | with | ||
| 5 | with | |||
| 6 | with | |||
| 7 | merged with | merged with | ||
| 8 | with | |||
| 9 | with | |||
| 10 | with | |||
| 11 | with | |||
| 12 | with | |||
| 13 | with | |||
| 14 | with |
| Initial | PA + PD = | Inv | Total Cycles | |
|---|---|---|---|---|
| 233 | 3 | 2784 | 225 | 3244 |
| Parameters | Frequency (in MHz) | Slices | LUTS | Time (in s) | Throughput/Slices | Power (in mW) |
|---|---|---|---|---|---|---|
| d = 59 | 2662 | 24,533 | 266 | |||
| d = 26 | 2662 | 24,727 | 266 |
| Specifications of | Platform | Frequency | Slices | LUTS | Time | T/slices | Dyn Power |
|---|---|---|---|---|---|---|---|
| Reference Solutions | (in MHz) | (in s) | (in W) | ||||
| BEC architectures over GF(2) field | |||||||
| BEC [19] | Virtex-4 | 48 | − | − | − | ||
| BEC halving [19] | Virtex-4 | 48 | − | − | |||
| GBEC: [20] | Virtex-4 | − | − | ||||
| GBEC: [20] | Virtex-4 | − | − | ||||
| BEC: [22] | Virtex-4 | − | − | ||||
| GBEC: [20] | Virtex-5 | 9233 | − | − | |||
| GBEC: [20] | Virtex-5 | 5504 | − | − | |||
| GBEC: [20] | Virtex-5 | 4019 | − | − | |||
| GBEC: [20] | Virtex-5 | 2637 | − | 8 | − | ||
| GBEC: , [21] | Virtex-5 | − | 5919 | − | − | ||
| GBEC: [21] | Virtex-5 | − | 4581 | − | − | ||
| BEC: [22] | Virtex-5 | 4987 | − | − | |||
| BEC: [22] | Virtex-5 | − | − | ||||
| BEC: [24] | Virtex-5 | 1397 | 4340 | 4560 | − | ||
| BEC: [23] | Virtex-5 | 308 | − | − | − | − | |
| BEC: [27] | Virtex-5 | 352 | 2637 | − | − | ||
| BEC: [27] | Virtex-5 | 398 | 5504 | − | − | ||
| BEC: [24] | Virtex-6 | 107 | 1245 | 3878 | 6720 | − | |
| BEC architectures over GF(p) field with bits | |||||||
| ED25519 [29] | Virtex-6 | 93 | 6600 | − | 2130 | − | |
| ED25519 [28] | Zynq7000 | 137 | − | 8680 | |||
| CURVE25519 [28] | Zynq7000 | 137 | − | 7380 | |||
| GBEC: – This work | Virtex-4 | 2663 | |||||
| GBEC: – This work | Virtex-4 | 2663 | |||||
| GBEC: – This work | Virtex-5 | 2662 | |||||
| GBEC: – This work | Virtex-5 | 2662 | |||||
| GBEC: – This work | Virtex-6 | 2664 | |||||
| GBEC: – This work | Virtex-6 | 2664 | |||||
| GBEC: – This work | Virtex-7 | 2662 | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sajid, A.; Rashid, M.; Imran, M.; Jafri, A.R. A Low-Complexity Edward-Curve Point Multiplication Architecture. Electronics 2021, 10, 1080. https://doi.org/10.3390/electronics10091080
Sajid A, Rashid M, Imran M, Jafri AR. A Low-Complexity Edward-Curve Point Multiplication Architecture. Electronics. 2021; 10(9):1080. https://doi.org/10.3390/electronics10091080
Chicago/Turabian StyleSajid, Asher, Muhammad Rashid, Malik Imran, and Atif Raza Jafri. 2021. "A Low-Complexity Edward-Curve Point Multiplication Architecture" Electronics 10, no. 9: 1080. https://doi.org/10.3390/electronics10091080