
Real-Time On-Board Deep Learning Fault Detection for Autonomous UAV Inspections †


Abstract
:1. Introduction
1.1. Power Line Inspection Methods
1.1.1. Human-Centered Power Line Inspections
1.1.2. Semi-Automated Power Line Inspections
1.1.3. UAV-Based Power Line Inspections
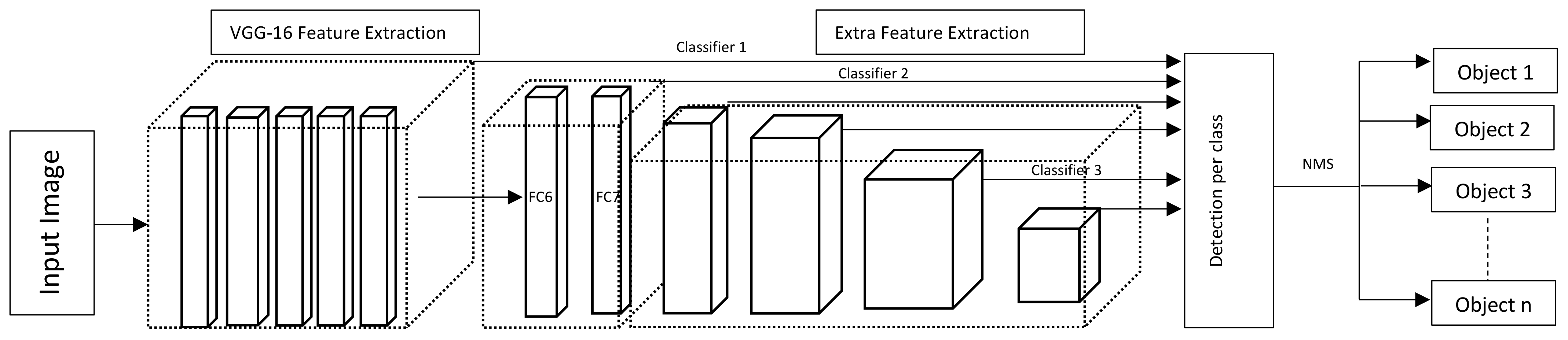
1.2. DL Models for Object Detection
1.3. Components to Build An Autonomous Powerline Inspection System
- Data collection and data analysis
- Autonomous vision systems for UAVs to perform real-time inspection
- Suitable SBDs with a sufficiently strong GPU to run vision-based DL models for real-time on-board inspection
- Communication and mission control systems for BVLOS UAV systems
- Deep integration of path planning and control systems in a visual UAV-based inspection system
- We added extensive experimental evaluations of the object and fault detection systems (Section 3.3 and Figure 13) and compared with previous results (Figures 10 and 11).
2. Related Work
DL-Based Objects Classification and Detection Models
3. Proposed Real-Time On-Board Visual Inspection Model
- Collection and pre-analysis of a dataset.
- Application of DL algorithms for the training, testing, and analysis of the dataset.
- Selection of suitable SBDs for running the inference in real time on-board the UAV.
3.1. Data Collection and Pre-Analysis
3.2. Suitable SBDs for UAV-Based Real-Time On-Board Inspections
3.3. Autonomous DL Algorithm for Real-Time Inspection
3.3.1. Training
3.3.2. Testing
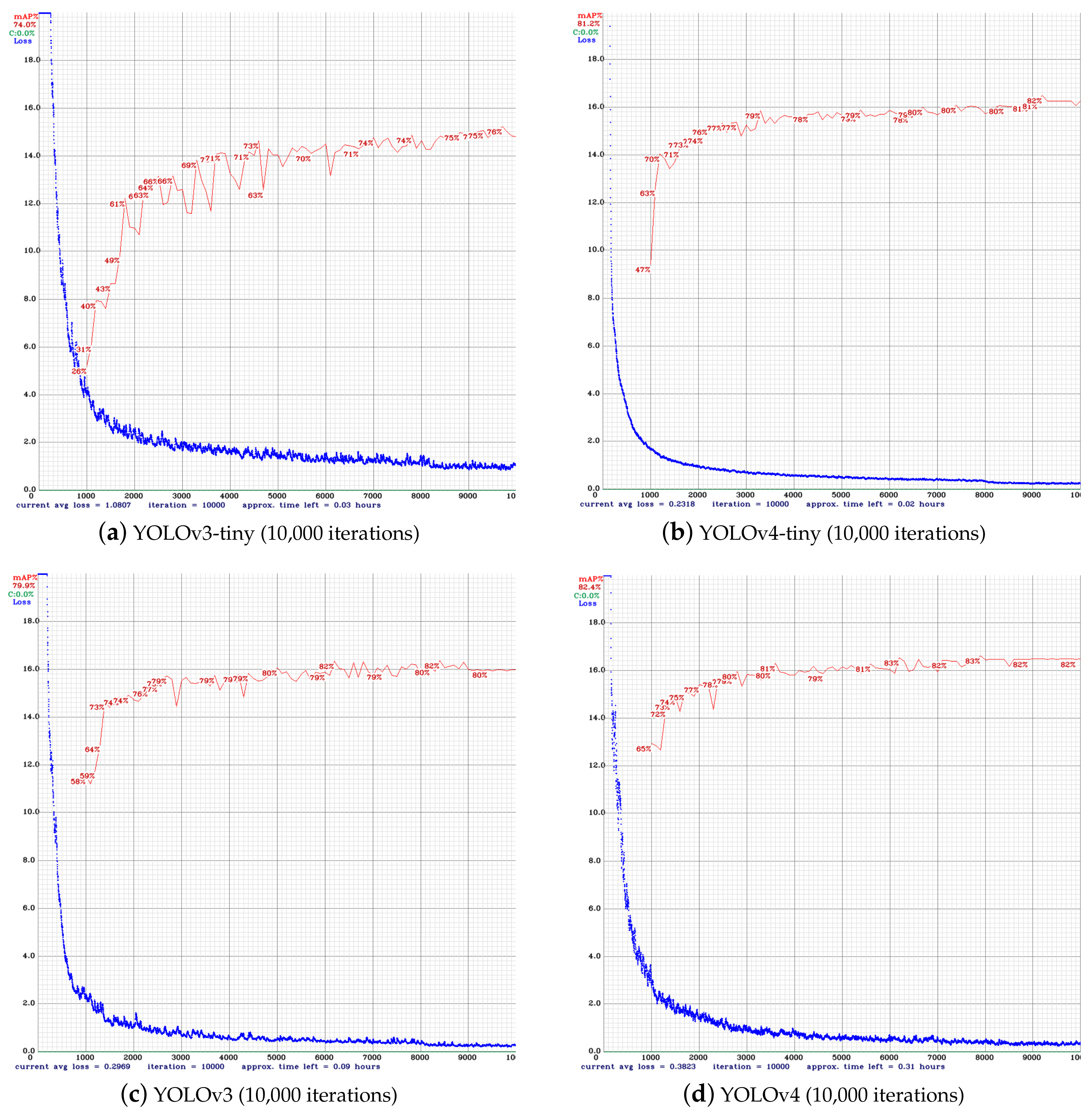
3.4. Experimental Results and Discussion
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mohamed, N.; Al-Jaroodi, J.; Jawhar, I.; Idries, A.; Mohammed, F. Unmanned aerial vehicles applications in future smart cities. Technol. Forecast. Soc. Chang. 2020, 153, 119293. [Google Scholar] [CrossRef]
- Jenssen, R.; Roverso, D. Automatic autonomous vision-based power line inspection: A review of current status and the potential role of deep learning. Int. J. Electr. Power Energy Syst. 2018, 99, 107–120. [Google Scholar]
- Al-Kaff, A.; Martín, D.; García, F.; de la Escalera, A.; Armingol, J.M. Survey of computer vision algorithms and applications for unmanned aerial vehicles. Expert Syst. Appl. 2018, 92, 447–463. [Google Scholar] [CrossRef]
- Ayoub, N.; Schneider-Kamp, P. Real-time On-board Detection of Components and Faults in an Autonomous UAV System for Power Line Inspection. In Proceedings of the 1st International Conference on Deep Learning Theory and Applications—Volume 1: DeLTA, INSTICC, Paris, France, 8–10 July 2020; SciTePress: Setúbal, Portugal, 2020; pp. 68–75. [Google Scholar] [CrossRef]
- Takaya, K.; Ohta, H.; Kroumov, V.; Shibayama, K.; Nakamura, M. Development of UAV System for Autonomous Power Line Inspection. In Proceedings of the 2019 23rd International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 9–11 October 2019; pp. 762–767. [Google Scholar]
- Bühringer, M.; Berchtold, J.; Büchel, M.; Dold, C.; Bütikofer, M.; Feuerstein, M.; Fischer, W.; Bermes, C.; Siegwart, R. Cable-crawler—Robot for the inspection of high-voltage power lines that can passively roll over mast tops. Ind. Robot. Int. J. 2010, 3. [Google Scholar] [CrossRef]
- Zhou, G.; Yuan, J.; Yen, I.L.; Bastani, F. Robust real-time UAV based power line detection and tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 744–748. [Google Scholar]
- Zhou, X.; Fang, B.; Qian, J.; Xie, G.; Deng, B.; Qian, J. Data Driven Faster R-CNN for Transmission Line Object Detection. In Cyberspace Data and Intelligence, and Cyber-Living, Syndrome, and Health; Springer: Singapore, 2019; pp. 379–389. [Google Scholar] [CrossRef]
- Contreras-Cruz, M.A.; Ramirez-Paredes, J.P.; Hernandez-Belmonte, U.H.; Ayala-Ramirez, V. Vision-Based Novelty Detection Using Deep Features and Evolved Novelty Filters for Specific Robotic Exploration and Inspection Tasks. Sensors 2019, 19, 2965. [Google Scholar] [CrossRef] [Green Version]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Li, Y.; Hao, Z.; Lei, H. Survey of convolutional neural network. J. Comput. Appl. 2016, 36, 2508–2515. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. arXiv 2016, arXiv:1605.06409. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Amsterdam, The Netherlands, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Markidis, S.; Der Chien, S.W.; Laure, E.; Peng, I.B.; Vetter, J.S. Nvidia tensor core programmability, performance & precision. In Proceedings of the 2018 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Vancouver, BC, Canada, 21–25 May 2018; pp. 522–531. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evaluation ⟶ ↓ DL Models | 10,000 Iterations | 20,000 Iterations | ||
|---|---|---|---|---|
| Accuracy | Avg. Loss | Accuracy | Avg. Loss | |
| YOLOv3-tiny | 74% | 1.08 | 78.3% | 0.97 |
| YOLOv4-tiny | 81.2 % | 0.23 | 84.4% | 0.15 |
| YOLOv3-full | 79.9 % | 0.29 | 84.3% | 0.11 |
| YOLOv4-full (Mish) | 82.4 % | 0.38 | 83.6% | 0.44 |
| YOLOv4-full (leaky) | 81.6 % | 0.35 | 82.8 % | 0.21 |
| DL Model | YOLOv3-Tiny (Non-Optimized) | YOLOv4-Tiny (Non-Optimized) | ||||
|---|---|---|---|---|---|---|
| Input Size → | 288 | 416 | 608 | 288 | 416 | 608 |
| Raspberry Pi 4 | 3 | 1 | 0.2 | – | – | – |
| Nvidia Jetson nano | 3.4 | 1.2 | 0.5 | 3 | 2.5 | 1.1 |
| Nvidia Jetson TX2 | 20 | 17 | 10 | 8 | 7 | 5.4 |
| Nvidia AGX Xavier | 30 | 21.6 | 14 | 16 | 15 | 12 |
| DL Model | YOLOv3-Tiny Optimized | YOLOv4-Tiny Optimized | ||||
|---|---|---|---|---|---|---|
| Input size → | 288 | 416 | 608 | 288 | 416 | 608 |
| Nvidia Jetson Nano | 22 | 15 | 4.5 | 9.2 | 7.8 | 6 |
| Nvidia Jetson TX2 | 25 | 19 | 12 | 14 | 11.5 | 4.3 |
| Nvidia AGX Xavier | 50 | 32 | 22 | 26 | 22 | 19 |
| DL Model | YOLOv3-darknet53 Optimized | YOLOv4-CSPdarknet53 Optimized | ||||
|---|---|---|---|---|---|---|
| Input size → | 288 | 416 | 608 | 288 | 416 | 608 |
| Nvidia Jetson Nano | 5.28 | 3 | 1.45 | 3.7 | 2.3 | 1.2 |
| Nvidia Jetson TX2 | 11.4 | 6.4 | 3 | 7.2 | 6.6 | 4.3 |
| Nvidia AGX Xavier | 24 | 17 | 11 | 20 | 13 | 9.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ayoub, N.; Schneider-Kamp, P. Real-Time On-Board Deep Learning Fault Detection for Autonomous UAV Inspections. Electronics 2021, 10, 1091. https://doi.org/10.3390/electronics10091091
Ayoub N, Schneider-Kamp P. Real-Time On-Board Deep Learning Fault Detection for Autonomous UAV Inspections. Electronics. 2021; 10(9):1091. https://doi.org/10.3390/electronics10091091
Chicago/Turabian StyleAyoub, Naeem, and Peter Schneider-Kamp. 2021. "Real-Time On-Board Deep Learning Fault Detection for Autonomous UAV Inspections" Electronics 10, no. 9: 1091. https://doi.org/10.3390/electronics10091091