
A Systematic Mapping Study on Cyber Security Indicator Data



Abstract
:1. Introduction
- What is the nature of the research using security indicators?
- What is the intended use of the data?
- What is the origin of the data for the indicators?
- What types of the data are being used?
- What is the data content of the indicators?
2. Background
- Strategic threat intelligence is high-level information used by decision-makers, such as financial impact of attacks based on historical data or predictions of what threat agents are up to.
- Operational threat intelligence is information about specific impending attacks against the organization.
- Tactical threat intelligence is about how threat actors are conducting attacks, for instance attacker tooling and methodology.
- Technical threat intelligence (TTI) is more detailed information about attacker tools and methods, such as low-level indicators that are normally consumed through technical resources (e.g., intrusion detection systems (IDS) and malware detection software).
3. Related Work
4. Methodology
4.1. Search Keywords
4.2. Inclusion Criteria
- related to actual use of indicator data for cyber security risks;
- published between 2015 and 2020 (the selection does not include studies indexed after September 2020);
- written in English; and
- peer-reviewed.
- in the form of patents, general web pages, presentations, books, thesis, tutorials, reports or white papers;
- purely theoretical in nature and with no use of data;
- about visual indicators for tools (e.g., browser extensions);
- addressing topics related to failures, accidents, mistakes or similar;
- repeated studies found in different search engines; or
- inaccessible papers (not retrievable).
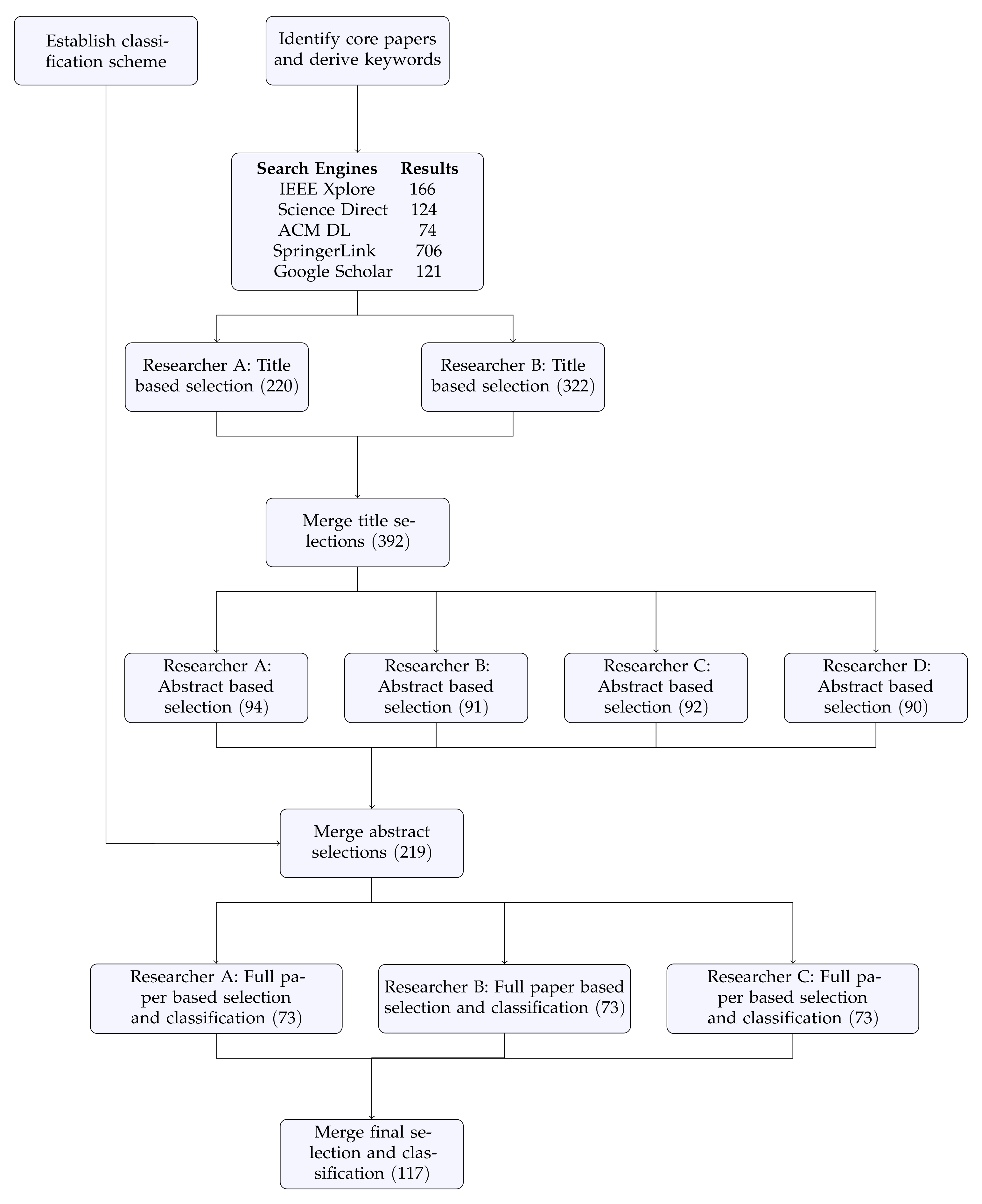
4.3. Database Selection and Query Design
4.4. Screening and Classification Process
5. Results
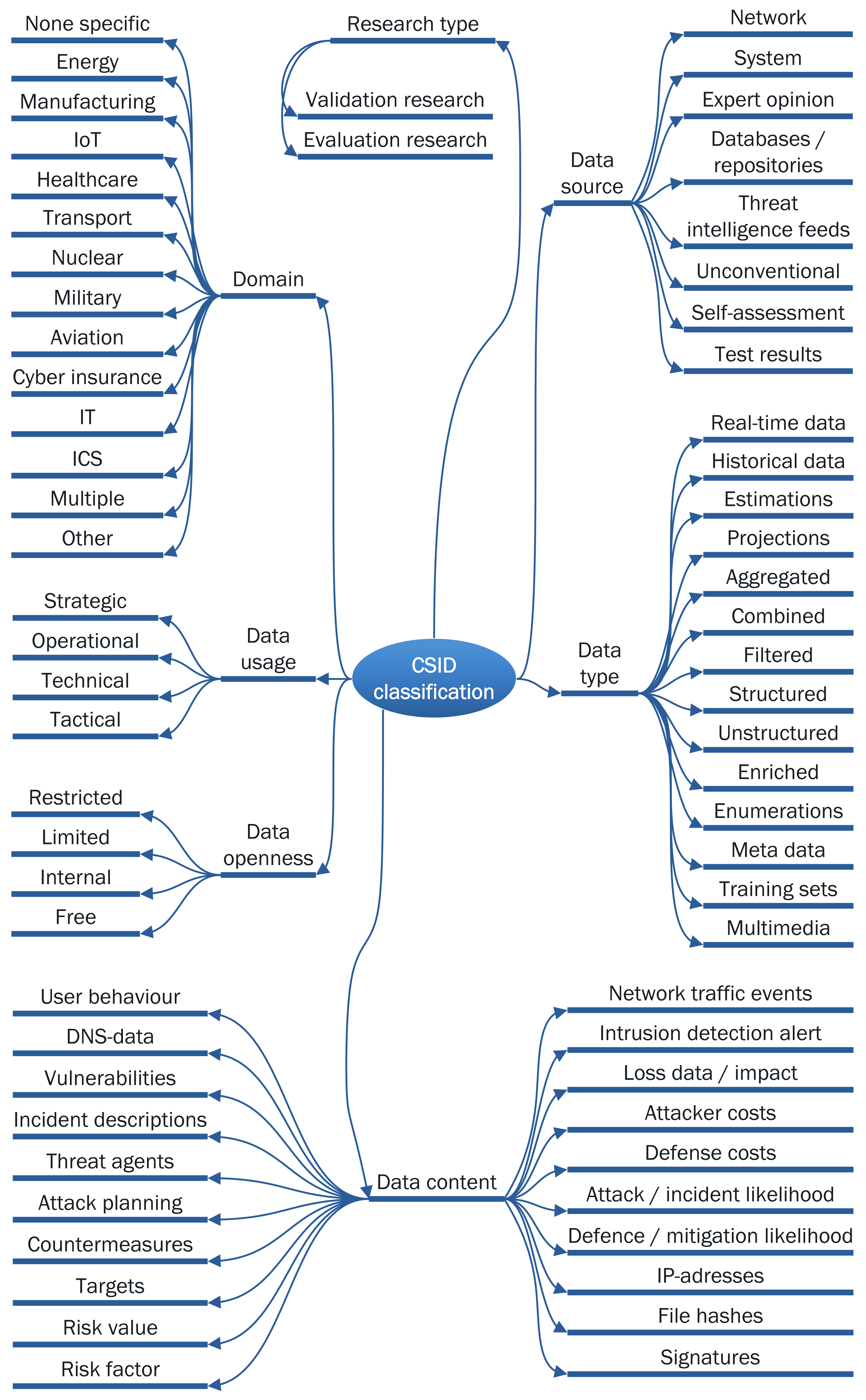
5.1. Classification Scheme
5.2. Mapping Results
6. Discussion
6.1. RQ 1: What Is the Nature of the Research Using Security Indicators?
6.2. RQ 2: What Is the Intended Use of the Data?
6.3. RQ 3: What Is the Origin of the Data for the Indicators?
6.4. RQ 4: What Types of Data Are Being Used?
6.5. RQ 5: What Is the Data Content of the Indicators?
6.6. Limitations and Recommendations for Future Research
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Search String Definitions
Appendix A.1. IEEE Xplore
- (("Document Title":"cyber security" OR
- title:"information security" OR
- title:"cyber risk" OR
- title:"cyber threat" OR
- title:"threat intelligence"
- OR title:"cyber attack") AND
- ("All Metadata":"predict" OR
- Search_All:"strategic" OR
- Search_All:"tactical" OR
- Search_All:"likelihood" OR
- Search_All:"probability" OR
- Search_All:"metric" OR
- Search_All:"indicator"))
Appendix A.2. Science Direct
Appendix A.3. ACM Digital Library
- [[Publication Title: "cyber security"] OR
- [Publication Title: "information security"] OR
- [Publication Title: "cyber risk"] OR
- [Publication Title: "cyber threat"] OR
- [Publication Title: "threat intelligence"] OR
- [Publication Title: "cyber attack"]] AND
- [[Abstract: predict] OR [Abstract: strategic] OR
- [Abstract: tactical] OR [Abstract: likelihood] OR
- [Abstract: probability] OR [Abstract: metric] OR
- [Abstract: indicator]] AND
- [Publication Date: (01/01/2015 TO 12/31/2020)]
Appendix A.4. SpingerLink
Appendix A.5. Google Scholar
- allintitle: ("cyber security" |
- “information security”| "cyber risk" |
- “cyber threat"| ”threat intelligence" |
- “cyber attack”) (Predict | strategic |
- tactical | likelihood | probability |
- metric | indicator)
Appendix B. The Selected Primary Studies
- Kolosok, Irina and Liudmila Gurina (2014). “Calculation of cyber security index in the problem of power system state estimation based on SCADA and WAMS measurements”. In: International Conference on Critical Information Infrastructures Security. Springer, pp. 172–177.
- Liu, Yang et al. (2015). “Predicting cyber security incidents using feature-based characterization of network-level malicious activities”. In: Proceedings of the 2015 ACM Inter- national Workshop on International Workshop on Security and Privacy Analytics, pp. 3–9.
- Llansó, Thomas, Anurag Dwivedi and Michael Smeltzer (2015). “An approach for estimating cyber attack level of effort”. In: 2015 Annual IEEE Systems Conference (SysCon) Proceedings. IEEE, pp. 14–19.
- Shin, Jinsoo, Hanseong Son, Gyunyoung Heo, et al. (2015). “Development of a cyber security risk model using Bayesian networks”. In: Reliability Engineering & System Safety 134, pp. 208–217.
- Zhan, Zhenxin, Maochao Xu and Shouhuai Xu (2015). “Predicting cyber attack rates with extreme values”. In: IEEE Transactions on Information Forensics and Security 10.8, pp. 1666–1677.
- Atighetchi, Michael et al. (2016). “Experimentation support for cyber security evaluations”. In: Proceedings of the 11th Annual Cyber and Information Security Research Conference, pp. 1–7.
- Aziz, Benjamin, Ali Malik and Jeyong Jung (2016). “Check your blind spot: a new cyber-security metric for measuring incident response readiness”. In: International Workshop on Risk Assessment and Risk-driven Testing. Springer, pp. 19– 33.
- Chhetri, Sujit Rokka, Arquimedes Canedo and Mohammad Abdullah Al Faruque (2016). “Kcad: kinetic cyber-attack detection method for cyber-physical additive manufacturing systems”. In: 2016 IEEE/ACM International Conference on Computer-Aided Design (ICCAD). IEEE, pp. 1–8.
- Dog, Spike E et al. (2016). “Strategic cyber threat intelligence sharing: A case study of ids logs”. In: 2016 25th International Conference on Computer Communication and Networks (ICCCN). IEEE, pp. 1–6.
- Hamid, T et al. (2016). “Cyber security risk evaluation research based on entropy weight method”. In: 2016 9th International Conference on Developments in eSystems Engineering (DeSE). IEEE, pp. 98–104.
- Je, Young-Man, Yen-Yoo You and Kwan-Sik Na (2016). “Information security evaluation using multi-attribute threat index”. In: Wireless Personal Communications 89.3, pp. 913–925.
- Liao, Xiaojing et al. (2016). “Acing the ioc game: Toward automatic discovery and analysis of open-source cyber threat intelligence”. In: Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, pp. 755–766.
- Noble, Jordan and Niall M Adams (2016). “Correlation-based streaming anomaly detection in cyber-security”. In: 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW). IEEE Computer Society, pp. 311–318.
- Singh, Umesh Kumar and Chanchala Joshi (2016). “Network security risk level estimation tool for information security measure”. In: 2016 IEEE 7th Power India International Conference (PIICON). IEEE, pp. 1–6.
- Wagner, Cynthia et al. (2016). “Misp: The design and implementation of a collaborative threat intelligence sharing platform”. In: Proceedings of the 2016 ACM on Workshop on Information Sharing and Collaborative Security, pp. 49– 56.
- Wang, Jiao et al. (2016). “A method for information security risk assessment based on the dynamic bayesian network”. In: 2016 International Conference on Networking and Network Applications (NaNA). IEEE, pp. 279–283.
- Wangen, Gaute and Andrii Shalaginov (2016). “Quantitative risk, statistical methods and the four quadrants for information security”. In: International Conference on Risks and Security of Internet and Systems. Springer, pp. 127–143.
- Ahrend, Jan M and Marina Jirotka (2017). “Anticipation in Cyber-Security”. In: Handbook of Anticipation. Springer, Cham, pp. 1–28.
- Aksu, M Ugur et al. (2017). “A quantitative CVSS-based cyber security risk assessment methodology for IT systems”. In: 2017 International Carnahan Conference on Security Technology (ICCST). IEEE, pp. 1–8.
- AlEroud, Ahmed and Izzat Alsmadi (2017). “Identifying cyber-attacks on software defined networks: An inference- based intrusion detection approach”. In: Journal of Network and Computer Applications 80, pp. 152–164.
- Andress, J et al. (2017). “Chapter 10–Information Security Program Metrics”. In: Building a Practical Information Security Program, pp. 169–183.
- Bernsmed, Karin et al. (2017). “Visualizing cyber security risks with bow-tie diagrams”. In: International Workshop on Graphical Models for Security. Springer, pp. 38–56.
- Best, Daniel M et al. (2017). “Improved cyber threat indicator sharing by scoring privacy risk”. In: 2017 IEEE International Symposium on Technologies for Homeland Security (HST). IEEE, pp. 1–5.
- Černivec, Aleš et al. (2017). “Employing Graphical Risk Models to Facilitate Cyber-Risk Monitoring-the WISER Approach”. In: International Workshop on Graphical Models for Security. Springer, pp. 127–146.
- Cheng, Ran, Yueming Lu and Jiefu Gan (2017). “Environment-Related Information Security Evaluation for Intrusion Detection Systems”. In: International Conference on Communicatins and Networking in China. Springer, pp. 373–382.
- Dalton, Adam et al. (2017). “Improving cyber-attack predictions through information foraging”. In: 2017 IEEE International Conference on Big Data (Big Data). IEEE, pp. 4642–4647.
- Doynikova, Elena and Igor Kotenko (2017). “Enhancement of probabilistic attack graphs for accurate cyber security monitoring”. In: 2017 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computed, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI). IEEE, pp. 1–6.
- Kandias, Miltiadis et al. (2017). “Stress level detection via OSN usage pattern and chronicity analysis: An OSINT threat intelligence module”. In: Computers & Security 69, pp. 3–17.
- Khandpur, Rupinder Paul et al. (2017). “Crowdsourcing cybersecurity: Cyber attack detection using social media”. In: Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, pp. 1049–1057.
- Lee, Kuo-Chan et al. (2017). “Sec-Buzzer: cyber security emerging topic mining with open threat intelligence retrieval and timeline event annotation”. In: Soft Computing 21.11, pp. 2883–2896.
- Liu, Ruyue et al. (2017). “A Research and Analysis Method of Open Source Threat Intelligence Data”. In: International Conference of Pioneering Computer Scientists, Engineers and Educators. Springer, pp. 352–363.
- Polatidis, Nikolaos, Elias Pimenidis, Michalis Pavlidis and Haralambos Mouratidis (2017). “Recommender systems meeting security: From product recommendation to cyber- attack prediction”. In: International Conference on Engineering Applications of Neural Networks. Springer, pp. 508–519.
- Price-Williams, Matthew, Nick Heard and Melissa Turcotte (2017). “Detecting periodic subsequences in cyber security data”. In: 2017 European Intelligence and Security Informatics Conference (EISIC). IEEE, pp. 84–90.
- Qamar, Sara et al. (2017). “Data-driven analytics for cyber- threat intelligence and information sharing”. In: Computers & Security 67, pp. 35–58.
- Ślezak, Dominik et al. (2017). “Scalable cyber-security analytics with a new summary-based approximate query engine”. In: 2017 IEEE International Conference on Big Data (Big Data). IEEE, pp. 1840–1849.
- Stine, Ian et al. (2017). “A cyber risk scoring system for medical devices”. In: International Journal of Critical Infrastructure Protection 19, pp. 32–46.
- Teoh, TT et al. (2017). “Analyst intuition based Hidden Markov Model on high speed, temporal cyber security big data”. In: 2017 13th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD). IEEE, pp. 2080–2083.
- Wagner, Thomas D et al. (2017). “Towards an Anonymity Supported Platform for Shared Cyber Threat Intelligence”. In: International Conference on Risks and Security of Internet and Systems. Springer, pp. 175–183.
- Yaseen, Amer Atta and Mireille Bayart (2017). “Cyber-attack detection with fault accommodation based on intelligent generalized predictive control”. In: IFAC-PapersOnLine 50.1, pp. 2601–2608.
- Aditya, K, Slawomir Grzonkowski and Nhien-An Le-Khac (2018). “Riskwriter: Predicting cyber risk of an enterprise”. In: International Conference on Information Systems Security. Springer, pp. 88–106.
- Almohannadi, Hamad et al. (2018). “Cyber threat intelligence from honeypot data using elasticsearch”. In: 2018 IEEE 32nd International Conference on Advanced Information Networking and Applications (AINA). IEEE, pp. 900–906.
- Araujo, Frederico et al. (2018). “Cross-Stack Threat Sensing for Cyber Security and Resilience”. In: 2018 48th Annual IEEE/IFIP International Conference on Dependable Systems and Networks Workshops (DSN-W). IEEE, pp. 18–21.
- Barboni, Angelo, Francesca Boem and Thomas Parisini (2018). “Model-based detection of cyber-attacks in networked MPC-based control systems”. In: IFAC-PapersOnLine 51.24, pp. 963–968.
- Böhm, Fabian, Florian Menges and Günther Pernul (2018). “Graph-based visual analytics for cyber threat intelligence”. In: Cybersecurity 1.1, p. 16.
- Cho, Hyeisun et al. (2018). “Method of Quantification of Cyber Threat Based on Indicator of Compromise”. In: 2018 International Conference on Platform Technology and Service (PlatCon). IEEE, pp. 1–6.
- Ghazi, Yumna et al. (2018). “A supervised machine learning based approach for automatically extracting high-level threat intelligence from unstructured sources”. In: 2018 International Conference on Frontiers of Information Technology (FIT). IEEE, pp. 129–134.
- Gokaraju, Balakrishna et al. (2018). “Identification of spatio- temporal patterns in cyber security for detecting the signature identity of hacker”. In: SoutheastCon 2018. IEEE, pp. 1–5.
- Gonzalez-Granadillo, G et al. (2018). “Dynamic risk management response system to handle cyber threats”. In: Future Generation Computer Systems 83, pp. 535–552.
- Gschwandtner, Mathias et al. (2018). “Integrating threat intelligence to enhance an organization’s information security management”. In: Proceedings of the 13th International Conference on Availability, Reliability and Security, pp. 1–8.
- Guerrero-Higueras, Ángel Manuel, Noemi DeCastro-Garcia and Vicente Matellan (2018). “Detection of Cyber-attacks to indoor real time localization systems for autonomous robots”. In: Robotics and Autonomous Systems 99, pp. 75– 83.
- Haughey, Hamish et al. (2018). “Adaptive traffic fingerprinting for darknet threat intelligence”. In: Cyber Threat Intelligence. Springer, pp. 193–217.
- Iqbal, Zafar, Zahid Anwar and Rafia Mumtaz (2018). “STIXGEN-A Novel Framework for Automatic Generation of Structured Cyber Threat Information”. In: 2018 International Conference on Frontiers of Information Technology (FIT). IEEE, pp. 241–246.
- Kim, Eunsoo et al. (2018). “CyTIME: Cyber Threat Intelligence ManagEment framework for automatically generating security rules”. In: Proceedings of the 13th International Conference on Future Internet Technologies, pp. 1–5.
- Kim, Nakhyun et al. (2018). “Study of Natural Language Processing for Collecting Cyber Threat Intelligence Using SyntaxNet”. In: International Symposium of Information and Internet Technology. Springer, pp. 10–18.
- Kotenko, Igor et al. (2018). “AI-and metrics-based vulnerability-centric cyber security assessment and countermeasure selection”. In: Guide to Vulnerability Analysis for Computer Networks and Systems. Springer, pp. 101–130.
- Lee, Chanyoung, Ho Bin Yim and Poong Hyun Seong (2018). “Development of a quantitative method for evaluating the efficacy of cyber security controls in NPPs based on intrusion tolerant concept”. In: Annals of Nuclear Energy 112, pp. 646–654.
- Moskal, Stephen, Shanchieh Jay Yang and Michael E Kuhl (2018). “Extracting and evaluating similar and unique cyber attack strategies from intrusion alerts”. In: 2018 IEEE International Conference on Intelligence and Security Informatics (ISI). IEEE, pp. 49–54.
- Pitropakis, Nikolaos et al. (2018). “An enhanced cyber attack attribution framework”. In: International Conference on Trust and Privacy in Digital Business. Springer, pp. 213– 228.
- Prabhu, Vinayak et al. (2018). “Towards Data-Driven Cyber Attack Damage and Vulnerability Estimation for Manufacturing Enterprises”. In: International Conference on Remote Engineering and Virtual Instrumentation. Springer, pp. 333– 343.
- Radanliev, Petar et al. (2018). “Economic impact of IoT cyber risk-analysing past and present to predict the future developments in IoT risk analysis and IoT cyber insurance”. In:
- Shu, Kai et al. (2018). “Understanding cyber attack behaviors with sentiment information on social media”. In: International Conference on Social Computing, Behavioral- Cultural Modeling and Prediction and Behavior Representation in Modeling and Simulation. Springer, pp. 377–388.
- Smith, Matthew David and M Elisabeth Paté-Cornell (2018). “Cyber risk analysis for a smart grid: how smart is smart enough? a multiarmed bandit approach to cyber security investment”. In: IEEE Transactions on Engineering Management 65.3, pp. 434–447.
- Vinayakumar, R, Prabaharan Poornachandran and KP Soman (2018). “Scalable framework for cyber threat situational awareness based on domain name systems data analysis”. In: Big data in engineering applications. Springer, pp. 113– 142.
- Wang, Junshe et al. (2018). “Network attack prediction method based on threat intelligence”. In: International Conference on Cloud Computing and Security. Springer, pp. 151–160.
- Zieger, Andrej, Felix Freiling and Klaus-Peter Kossakowski (2018). “The -time-to-compromise metric for practical cyber security risk estimation”. In: 2018 11th International Conference on IT Security Incident Management & IT Forensics (IMF). IEEE, pp. 115–133.
- Bo, Tao et al. (2019). “TOM: A Threat Operating Model for Early Warning of Cyber Security Threats”. In: International Conference on Advanced Data Mining and Applications. Springer, pp. 696–711.
- Doynikova, Elena, Andrey Fedorchenko and Igor Kotenko (2019). “Ontology of metrics for cyber security assessment”. In: Proceedings of the 14th International Conference on Availability, Reliability and Security, pp. 1–8.
- Dragos, Valentina et al. (2019). “Entropy-Based Metrics for URREF Criteria to Assess Uncertainty in Bayesian Networks for Cyber Threat Detection”. In: 2019 22th Interna- tional Conference on Information Fusion (FUSION). IEEE, pp. 1–8.
- Gautam, Apurv Singh, Yamini Gahlot and Pooja Kamat (2019). “Hacker Forum Exploit and Classification for Proactive Cyber Threat Intelligence”. In: International Conference on Inventive Computation Technologies. Springer, pp. 279–285.
- Kannavara, Raghudeep et al. (2019). “A threat intelligence tool for the security development lifecycle”. In: Proceedings of the 12th Innovations on Software Engineering Conference (formerly known as India Software Engineering Conference), pp. 1–5.
- Keim, Yansi and AK Mohapatra (2019). “Cyber threat intelligence framework using advanced malware forensics”. In: International Journal of Information Technology, pp. 1–10.
- Al-khateeb, Samer and Nitin Agarwal (2019). “Social cyber forensics: leveraging open source information and social network analysis to advance cyber security informatics”. In: Computational and Mathematical Organization Theory, pp. 1–19.
- Li, Yi-Fan et al. (2019). “Multistream classification for cyber threat data with heterogeneous feature space”. In: The World Wide Web Conference, pp. 2992–2998.
- Marukhlenko, AL, AV Plugatarev and DO Bobyntsev (2019). “Complex Evaluation of Information Security of an Object with the Application of a Mathematical Model for Calculation of Risk Indicators”. In: International Russian Automation Conference. Springer, pp. 771–778.
- Merino, Tim et al. (2019). “Expansion of cyber attack data from unbalanced datasets using generative adversarial networks”. In: International Conference on Software Engi- neering Research, Management and Applications. Springer, pp. 131–145.
- Milajerdi, Sadegh M et al. (2019). “Poirot: Aligning attack behavior with kernel audit records for cyber threat hunting”. In: Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, pp. 1795–1812.
- Milošević, Jezdimir, Henrik Sandberg and Karl Henrik Johansson (2019). “Estimating the impact of cyber-attack strategies for stochastic networked control systems”. In: IEEE Transactions on Control of Network Systems 7.2, pp. 747–757
- Mokaddem, Sami et al. (2019). “Taxonomy driven indicator scoring in MISP threat intelligence platforms”. In: arXiv preprint arXiv:1902.03914.
- Mukhopadhyay, Arunabha et al. (2019). “Cyber risk assessment and mitigation (CRAM) framework using logit and probit models for cyber insurance”. In: Information Systems Frontiers 21.5, pp. 997–1018.
- Noor, Umara et al. (2019). “A machine learning framework for investigating data breaches based on semantic analysis of adversary’s attack patterns in threat intelligence repositories”. In: Future Generation Computer Systems 95, pp. 467–487.
- Okutan, Ahmet and Shanchieh Jay Yang (2019). “ASSERT: attack synthesis and separation with entropy redistribution towards predictive cyber defense”. In: Cybersecurity 2.1, pp. 1–18.
- Papastergiou, Spyridon, Haralambos Mouratidis and Eleni- Maria Kalogeraki (2019). “Cyber security incident handling, warning and response system for the european critical information infrastructures (cybersane)”. In: International Conference on Engineering Applications of Neural Networks. Springer, pp. 476–487.
- Pour, Morteza Safaei et al. (2019). “Comprehending the IoT cyber threat landscape: A data dimensionality reduction technique to infer and characterize Internet-scale IoT probing campaigns”. In: Digital Investigation 28, S40–S49.
- Riesco, Raúl and Víctor A Villagrá (2019). “Leveraging cyber threat intelligence for a dynamic risk framework”. In: International Journal of Information Security 18.6, pp. 715–739.
- Rijswijk-Deij, Roland van et al. (2019). “Privacy-conscious threat intelligence using DNSBLoom”. In: 2019 IFIP/IEEE Symposium on Integrated Network and Service Management (IM). IEEE, pp. 98–106.
- Simran, K et al. (2019). “Deep Learning Approach for Enhanced Cyber Threat Indicators in Twitter Stream”. In: International Symposium on Security in Computing and Communication. Springer, pp. 135–145.
- Sliva, Amy, Kai Shu and Huan Liu (2019). “Using social media to understand cyber attack behavior”. In: International Conference on Applied Human Factors and Ergonomics. Springer, pp. 636–645.
- Subroto, Athor and Andri Apriyana (2019). “Cyber risk prediction through social media big data analytics and statistical machine learning”. In: Journal of Big Data 6.1, pp. 1–19.
- Tonn, Gina et al. (2019). “Cyber risk and insurance for transportation infrastructure”. In: Transport policy 79, pp. 103–114.
- Trivedi, Tarun et al. (2019). “Threat Intelligence Analysis of Onion Websites Using Sublinks and Keywords”. In: Emerging Technologies in Data Mining and Information Security. Springer, pp. 567–578.
- Ullah, Sharif et al. (2019). “Cyber Threat Analysis Based on Characterizing Adversarial Behavior for Energy Delivery System”. In: International Conference on Security and Privacy in Communication Systems. Springer, pp. 146–160.
- Ustebay, Serpil, Zeynep Turgut and M Ali Aydin (2019). “Cyber Attack Detection by Using Neural Network Approaches: Shallow Neural Network, Deep Neural Network and AutoEncoder”. In: International Conference on Com- puter Networks. Springer, pp. 144–155.
- Vielberth, Manfred, Florian Menges and Günther Pernul (2019). “Human-as-a-security-sensor for harvesting threat intelligence”. In: Cybersecurity 2.1, pp. 1–15.
- Vinayakumar, R, KP Soman, et al. (2019). “Deep learning framework for cyber threat situational awareness based on email and url data analysis”. In: Cybersecurity and Secure Information Systems. Springer, pp. 87–124.
- Wang, Huaizhi et al. (2019). “Deep learning aided interval state prediction for improving cyber security in energy internet”. In: Energy 174, pp. 1292–1304.
- Wangen, Gaute (2019). “Quantifying and Analyzing Information Security Risk from Incident Data”. In: International Workshop on Graphical Models for Security. Springer, pp. 129–154.
- Yang, Wenzhuo and Kwok-Yan Lam (2019). “Automated Cyber Threat Intelligence Reports Classification for Early Warning of Cyber Attacks in Next Generation SOC”. In: International Conference on Information and Communications Security. Springer, pp. 145–164.
- Zhang, Hongbin et al. (2019). “Network attack prediction method based on threat intelligence for IoT”. In: Multimedia Tools and Applications 78.21, pp. 30257–30270.
- Almukaynizi, Mohammed et al. (2020). “A Logic Programming Approach to Predict Enterprise-Targeted Cyberattacks”. In: Data Science in Cybersecurity and Cyberthreat Intelligence. Springer, pp. 13–32.
- Barrère, Martın et al. (2020). “Measuring cyber-physical security in industrial control systems via minimum-effort attack strategies”. In: Journal of Information Security and Applications 52, p. 102471.
- Chen, Scarlett, Zhe Wu and Panagiotis D Christofides (2020). “Cyber-attack detection and resilient operation of nonlinear processes under economic model predictive control”. In: Computers & Chemical Engineering, p. 106806.
- Evangelou, Marina and Niall M Adams (2020). “An anomaly detection framework for cyber-security data”. In: Computers & Security 97, p. 101941.
- Facchinetti, Silvia, Paolo Giudici and Silvia Angela Osmetti (2020). “Cyber risk measurement with ordinal data”. In: Statistical Methods & Applications 29.1, pp. 173–185.
- Figueira, Pedro Tubıo, Cristina López Bravo and José Luis Rivas López (2020). “Improving information security risk analysis by including threat-occurrence predictive models”. In: Computers & Security 88, p. 101609.
- Huang, Linan and Quanyan Zhu (2020). “A dynamic games approach to proactive defense strategies against advanced persistent threats in cyber-physical systems”. In: Computers & Security 89, p. 101660.
- Khosravi, Mehran and Behrouz Tork Ladani (2020). “Alerts Correlation and Causal Analysis for APT Based Cyber Attack Detection”. In: IEEE Access 8, pp. 162642–162656.
- Kour, Ravdeep, Adithya Thaduri and Ramin Karim (2020). “Predictive model for multistage cyber-attack simulation”. In: International Journal of System Assurance Engineering and Management 11.3, pp. 600–613.
- Krisper, Michael, Jürgen Dobaj and Georg Macher (2020). “Assessing Risk Estimations for Cyber-Security Using Expert Judgment”. In: European Conference on Software Process Improvement. Springer, pp. 120–134.
- Liao, Yi-Ching (2020). “Quantitative Information Security Vulnerability Assessment for Norwegian Critical Infrastructure”. In: International Conference on Critical Information Infrastructures Security. Springer, pp. 31–43.
- Luh, Robert and Sebastian Schrittwieser (2020). “Advanced threat intelligence: detection and classification of anomalous behavior in system processes”. In: e & i Elektrotechnik und Informationstechnik 137.1, pp. 38–44.
- Marin, Ericsson, Mohammed Almukaynizi and Paulo Shakarian (2020). “Inductive and deductive reasoning to assist in cyber-attack prediction”. In: 2020 10th Annual Computing and Communication Workshop and Conference (CCWC). IEEE, pp. 0262–0268.
- Al-Mohannadi, Hamad, Irfan Awan and Jassim Al Hamar (2020). “Analysis of adversary activities using cloud-based web services to enhance cyber threat intelligence”. In: Service Oriented Computing and Applications, pp. 1–13.
- Mohasseb, Alaa et al. (2020). “Cyber security incidents analysis and classification in a case study of Korean enterprises”. In: Knowledge and Information Systems.
- Polatidis, Nikolaos, Elias Pimenidis, Michalis Pavlidis, Spyridon Papastergiou, et al. (2020). “From product recommendation to cyber-attack prediction: generating attack graphs and predicting future attacks”. In: Evolving Systems, pp. 1– 12.
- Rahman, Md Anisur, Yeslam Al-Saggaf and Tanveer Zia (2020). “A Data Mining Framework to Predict Cyber Attack for Cyber Security”. In: The 15th IEEE Conference on Industrial Electronics and Applications (ICIEA2020). IEEE Xplore.
- Tundis, Andrea, Samuel Ruppert and Max Mühlhäuser (2020). “On the Automated Assessment of Open-Source Cyber Threat Intelligence Sources”. In: International Conference on Computational Science. Springer, pp. 453–467.
- Uyheng, Joshua et al. (2020). “Interoperable pipelines for social cyber-security: Assessing Twitter information Operations during NATO Trident Juncture 2018”. In: Computational and Mathematical Organization Theory 26.4, pp. 465–483.
- Zhao, Jun et al. (2020). “TIMiner: Automatically Extracting and Analyzing Categorized Cyber Threat Intelligence from Social Data”. In: Computers & Security, p. 101867.
References
- Madnick, S. How Do You Prepare for the Unexpected Cyber Attack? SSRN Electron. J. 2020. [Google Scholar] [CrossRef]
- Anderson, R.; Böhme, R.; Clayton, R.; Moore, T. Security Economics and the Internal Market. Available online: https://www.enisa.europa.eu/publications/archive/economics-sec/ (accessed on 23 March 2021).
- Kitchenham, B.; Charters, S. Guidelines for Performing Systematic Literature Reviews in Software Engineering; Technical Report EBSE-2007-01, Joint Report; Keele University: Keele, UK; University of Durham: Durham, UK, 2007. [Google Scholar]
- Petersen, K.; Vakkalanka, S.; Kuzniarz, L. Guidelines for Conducting Systematic Mapping Studies in Software Engineering: An Update. Inf. Softw. Technol. 2015, 64, 1–18. [Google Scholar] [CrossRef]
- Lea, D.; Bradbery, J. Oxford Advanced Learner’s Dictionary. 2021. Available online: https://www.oxfordlearnersdictionaries.com/definition/english/indicator (accessed on 22 April 2021).
- Pfleeger, S.L.; Caputo, D.D. Leveraging Behavioral Science to Mitigate Cyber Security Risk. Comput. Secur. 2012, 31, 597–611. [Google Scholar] [CrossRef]
- Brown, S.; Gommers, J.; Serrano, O. From Cyber Security Information Sharing to Threat Management. WISCS ’15: Proceedings of the 2nd ACM Workshop on Information Sharing and Collaborative Security; Association for Computing Machinery: New York, NY, USA, 2015; pp. 43–49. [Google Scholar]
- McMillan, R. Definition: Threat Intelligence. Available online: https://www.gartner.com/imagesrv/media-products/pdf/webroot/issue1_webroot.pdf (accessed on 26 March 2021).
- Tounsi, W.; Rais, H. A Survey on Technical Threat Intelligence in the Age of Sophisticated Cyber Attacks. Comput. Secur. 2018, 72, 212–233. [Google Scholar] [CrossRef]
- Chismon, D.; Ruks, M. Threat Intelligence: Collecting, Analysing, Evaluating. Available online: https://informationsecurity.report/whitepapers/threat-intelligence-collecting-analysing-evaluating/10 (accessed on 26 March 2021).
- Mateski, M.; Trevino, C.M.; Veitch, C.K.; Michalski, J.; Harris, J.M.; Maruoka, S.; Frye, J. Cyber Threat Metrics. Available online: https://fas.org/irp/eprint/metrics.pdf (accessed on 26 March 2021).
- Wang, A.J.A. Information Security Models and Metrics. In Proceedings of the 43rd Annual Southeast Regional Conference, (ACM-SE 43), Kennesaw, GA, 18 –20 March 2005; pp. 178–184. [Google Scholar]
- Herrmann, D.S. Complete Guide to Security and Privacy Metrics: Measuring Regulatory Compliance, Operational Resilience, and ROI, 1st ed.; Auerbach Publications: Boston, MA, USA, 2007. [Google Scholar]
- Humayun, M.; Niazi, M.; Jhanjhi, N.Z.; Alshayeb, M.; Mahmood, S. Cyber Security Threats and Vulnerabilities: A Systematic Mapping Study. Arab. J. Sci. Eng. 2020, 45, 3171–3189. [Google Scholar] [CrossRef]
- Grajeda, C.; Breitinger, F.; Baggili, I. Availability of Datasets for Digital Forensics—And What is Missing. Digit. Investig. 2017, 22, S94–S105. [Google Scholar] [CrossRef]
- Zheng, M.; Robbins, H.; Chai, Z.; Thapa, P.; Moore, T. Cybersecurity Research Datasets: Taxonomy and Empirical Analysis. In Proceedings of the 11th USENIX Workshop on Cyber Security Experimentation and Test (CSET’18), Baltimore, MD, USA, 13 August 2018. [Google Scholar]
- Griffioen, H.; Booij, T.; Doerr, C. Quality Evaluation of Cyber Threat Intelligence Feeds. In Proceedings of the 18th International Conference on Applied Cryptography and Network Security (ACNS’20), Rome, Italy, 19–22 October 2020; pp. 277–296. [Google Scholar]
- Tundis, A.; Ruppert, S.; Mühlhäuser, M. On the Automated Assessment of Open-Source Cyber Threat Intelligence Sources. In Proceedings of the 20th International Conference on Computational Science (ICCS’20), Amsterdam, The Netherlands, 3–5 June 2020; pp. 453–467. [Google Scholar]
- Pendleton, M.; Garcia-Lebron, R.; Cho, J.H.; Xu, S. A Survey on Systems Security Metrics. ACM Comput. Surv. CSUR 2016, 49, 1–35. [Google Scholar] [CrossRef] [Green Version]
- Cadena, A.; Gualoto, F.; Fuertes, W.; Tello-Oquendo, L.; Andrade, R.; Tapia Leon, F.; Torres, J. Metrics and Indicators of Information Security Incident Management: A Systematic Mapping Study. In Smart Innovation, Systems and Technologies; Springer Nature Singapore Private Limited: Singapore, 2020; pp. 507–519. [Google Scholar] [CrossRef]
- Husák, M.; Komárková, J.; Bou-Harb, E.; Čeleda, P. Survey of Attack Projection, Prediction, and Forecasting in Cyber Security. IEEE Commun. Surv. Tutor. 2018, 21, 640–660. [Google Scholar] [CrossRef] [Green Version]
- Sriavstava, R.; Singh, P.; Chhabra, H. Review on Cyber Security Intrusion Detection: Using Methods of Machine Learning and Data Mining. In Internet of Things and Big Data Applications: Recent Advances and Challenges; Springer: Cham, Switzerland, 2020; pp. 121–132. [Google Scholar] [CrossRef]
- Sun, N.; Zhang, J.; Rimba, P.; Gao, S.; Zhang, L.Y.; Xiang, Y. Data-Driven Cybersecurity Incident Prediction: A Survey. IEEE Commun. Surv. Tutor. 2019, 21, 1744–1772. [Google Scholar] [CrossRef]
- Laube, S.; Böhme, R. Strategic Aspects of Cyber Risk Information Sharing. ACM Comput. Surv. CSUR 2017, 50, 1–36. [Google Scholar] [CrossRef]
- Diesch, R.; Krcmar, H. SoK: Linking Information Security Metrics to Management Success Factors. In Proceedings of the 15th International Conference on Availability, Reliability and Security (ARES’20), Dublin, Ireland, 25–28 August 2020; pp. 1–10. [Google Scholar]
- Kotenko, I.; Doynikova, E.; Chechulin, A.; Fedorchenko, A. AI- and Metrics-Based Vulnerability-Centric Cyber SecurityAssessment and Countermeasure Selection. In Guide to Vulnerability Analysis for Computer Networks and Systems: An Artificial Intelligence Approach; Springer: Cham, Switzerland, 2018; pp. 101–130. [Google Scholar] [CrossRef]
- Gheyas, I.A.; Abdallah, A.E. Detection and Prediction of Insider Threats to Cyber Security: A Systematic Literature Review and Meta-Analysis. Big Data Anal. 2016, 1, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Keim, Y.; Mohapatra, A.K. Cyber Threat Intelligence Framework Using Advanced Malware Forensics. Int. J. Inf. Technol. 2019, 1–10. [Google Scholar] [CrossRef]
- Samtani, S.; Abate, M.; Benjamin, V.; Li, W. Cybersecurity as an Industry: A Cyber Threat Intelligence Perspective. In The Palgrave Handbook of International Cybercrime and Cyberdeviance; Palgrave Macmillan: Cham, Switzerland, 2020; pp. 135–154. [Google Scholar] [CrossRef]
- Chockalingam, S.; Pieters, W.; Teixeira, A.; van Gelder, P. Bayesian Network Models in Cyber Security: A Systematic Review. In Proceedings of the 22nd Nordic Conference on Secure IT Systems (NordSec’17), Tartu, Estonia, 8–10 November 2017; pp. 105–122. [Google Scholar]
- Petersen, K.; Feldt, R.; Mujtaba, S.; Mattsson, M. Systematic Mapping Studies in Software Engineering. In Proceedings of the 12th International Conference on Evaluation and Assessment in Software Engineering (EASE’08), Bari, Italy, 26–27 June 2008; pp. 1–10. [Google Scholar]
- Brereton, P.; Kitchenham, B.A.; Budgen, D.; Turner, M.; Khalil, M. Lessons from Applying the Systematic Literature Review Process within the Software Engineering Domain. J. Syst. Softw. 2007, 80, 571–583. [Google Scholar] [CrossRef] [Green Version]
- Wohlin, C. Guidelines for Snowballing in Systematic Literature Studies and a Replication in Software Engineering. In Proceedings of the 18th International Conference on Evaluation and Assessment in Software Engineering (EASE’14), London, UK, 13–14 May 2014; pp. 1–10. [Google Scholar]
- Wieringa, R.; Maiden, N.; Mead, N.; Rolland, C. Requirements Engineering Paper classification and Evaluation Criteria: A Proposal and a Discussion. Requir. Eng. 2006, 11, 102–107. [Google Scholar] [CrossRef]
- The MITRE Corporation. Common Weakness Enumeration (CWE). 2021. Available online: https://cwe.mitre.org/ (accessed on 22 April 2021).
- Meland, P.H.; Tokas, S.; Erdogan, G.; Bernsmed, K.; Omerovic. Cyber Security Indicators Mapping Scheme and Result. 2021. Available online: https://doi.org/10.5281/zenodo.4639585 (accessed on 19 March 2021).
- Erdogan, G.; Gonzalez, A.; Refsdal, A.; Seehusen, F. A Method for Developing Algorithms for Assessing Cyber-Risk Cost. In Proceedings of the 2017 IEEE International Conference on Software Quality, Reliability and Security (QRS’17), Prague, Czech Republic, 25–29 July 2017; pp. 192–199. [Google Scholar]
- Moore, T.; Kenneally, E.; Collett, M.; Thapa, P. Valuing Cybersecurity Research Datasets. In Proceedings of the 18th Workshop on the Economics of Information Security (WEIS’19), Boston, MA, USA, 3–4 June 2019; pp. 1–27. [Google Scholar]
- Wagner, T.D.; Mahbub, K.; Palomar, E.; Abdallah, A.E. Cyber Threat Intelligence Sharing: Survey and Research Directions. Comput. Secur. 2019, 87, 101589. [Google Scholar] [CrossRef]
- Barnum, S. Standardizing Cyber Threat Intelligence Information with the Structured Threat Information eXpression (STIX). Mitre Corp. 2012, 11, 1–22. [Google Scholar]
- Ramsdale, A.; Shiaeles, S.; Kolokotronis, N. A Comparative Analysis of Cyber-Threat Intelligence Sources, Formats and Languages. Electronics 2020, 9, 824. [Google Scholar] [CrossRef]
- Bromander, S.; Muller, L.P.; Eian, M.; Jøsang, A. Examining the “Known Truths” in Cyber Threat Intelligence–The Case of STIX. In Proceedings of the 15th International Conference on Cyber Warfare and Security, Norfolk, VA, USA, 12–13 March 2020; p. 493-XII. [Google Scholar]
- Bromander, S.; Swimmer, M.; Muller, L.; Jøsang, A.; Eian, M.; Skjøtskift, G.; Borg, F. Investigating Sharing of Cyber Threat Intelligence and Proposing a New Data Model for Enabling Automation in Knowledge Representation and Exchange. Digit. Threat. Res. Pract. 2021. [Google Scholar] [CrossRef]
- Mavroeidis, V.; Bromander, S. Cyber Threat Intelligence Model: An Evaluation of Taxonomies, Sharing Standards, and Ontologies within Cyber Threat Intelligence. In Proceedings of the 2017 European Intelligence and Security Informatics Conference (EISIC’17), Athens, Greece, 11–13 September 2017; pp. 91–98. [Google Scholar]
- Garousi, V.; Felderer, M.; Mäntylä, M.V. The Need for Multivocal Literature Reviews in Software Engineering: Complementing Systematic Literature Reviews with Grey Literature. In Proceedings of the 20th International Conference on Evaluation and Assessment in Software Engineering (EASE’16), Limerick, Ireland, 1–3 June 2016; pp. 1–6. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Title Keywords | Title, Abstract, Author Defined |
|---|---|
| “cyber security”, “information security”, “cyber risk”, “cyber threat”, “threat intelligence”, “cyber attack” | “predict”, “strategic”, “tactical”, “likelihood, probability”, “metric”, “indicator” |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meland, P.H.; Tokas, S.; Erdogan, G.; Bernsmed, K.; Omerovic, A. A Systematic Mapping Study on Cyber Security Indicator Data. Electronics 2021, 10, 1092. https://doi.org/10.3390/electronics10091092
Meland PH, Tokas S, Erdogan G, Bernsmed K, Omerovic A. A Systematic Mapping Study on Cyber Security Indicator Data. Electronics. 2021; 10(9):1092. https://doi.org/10.3390/electronics10091092
Chicago/Turabian StyleMeland, Per Håkon, Shukun Tokas, Gencer Erdogan, Karin Bernsmed, and Aida Omerovic. 2021. "A Systematic Mapping Study on Cyber Security Indicator Data" Electronics 10, no. 9: 1092. https://doi.org/10.3390/electronics10091092
APA StyleMeland, P. H., Tokas, S., Erdogan, G., Bernsmed, K., & Omerovic, A. (2021). A Systematic Mapping Study on Cyber Security Indicator Data. Electronics, 10(9), 1092. https://doi.org/10.3390/electronics10091092