1. Introduction
The Internet of Things (IoT) and the Industrial IoT (IIoT) are part of the main information and communication technologies of the fourth industrial revolution (Industry 4.0) [
1,
2,
3]. To a large extent, the global coronavirus (COVID-19) pandemic that started in 2020 has restricted human contacts and economic activities in most countries. In view of this, IoT and IIoT technologies will help in connecting people, homes, and businesses to a large-scale of computers, smart devices, sensors, vehicles, and industrial machines in smart cities. Unfortunately, IoT has become the primary target of malicious botnet (A botnet is a network of computing devices that are coordinated by a botmaster to perform specific tasks [
4].) operators due to their proliferation and distributed nature. A large number of connected IoT devices are insecure because their default usernames and passwords remain unchanged [
5,
6]. A malicious botnet poses a serious cybersecurity threat to the Internet of Things (IoT) networks and their applications [
7,
8,
9,
10]. IoT devices are vulnerable to various botnet attacks such as Denial of Service (DoS), Distributed DoS (DDoS), Operating System (OS) fingerprinting, service scanning, data exfiltration, and keylogging [
11]. Recently, a new IoT Peer-to-Peer (P2P) botnet, named HEH, exploited insecure Telnet services on ports 23 and 232 to wipe out all the data in IoT devices using the brute force method [
12]. Therefore, IoT networks must be properly monitored and protected to detect and prevent cyberattacks.
Cybersecurity mechanisms such as encryption, authentication, and access control may not be strong enough to protect IoT networks against botnet attacks [
13,
14]. Therefore, an efficient Network Intrusion Detection System (NIDS) is needed to complement existing security mechanisms. NIDS will scan and monitor all the network traffic traces generated in IoT networks to detect botnet attacks. Signature-based NIDS can detect known attacks with high accuracy but it cannot identify zero-day (unknown) attacks. On the other hand, anomaly-based NIDS can detect unknown attacks but it has a higher False Positive Rate (FPR) than signature-based NIDS. Machine Learning (ML) method can be used to detect both known and unknown malicious network traffic traces in IoT networks [
15,
16,
17,
18,
19]. Popular ML methods include Random Forest (RF), Support Vector Machine (SVM), Decision Tree (DT), k-Nearest Neighbour (kNN), Random Tree (RT), and Naive Bayes (NB). However, IoT networks generate massive network traffic data at very high velocity, and shallow neural networks cannot handle such big data because they have a limited number of trainable parameters.
Deep Learning (DL) is an advanced ML method that has more than one hidden layer in its neural network and it learns the feature representation of training data using multiple levels of abstraction [
20,
21,
22]. Common DL architectures include Deep Neural Network (DNN), Convolutional Neural Network(CNN), Recurrent Neural Network (RNN), Deep Belief Network (DBN), Autoencoder (AE) and Restricted Boltzmann Machine (RBM). RNN is a type of neural network in which the connections between the neurons form a directed graph along a temporal sequence. Unlike other DL methods, it considers the temporal dependencies among the features in the training set. Most times, RNN is combined with fully-connected dense layer(s) to improve model’s classification performance. The integrated model architecture is referred to as Deep RNN (DRNN). In fact, DRNN models have been successfully applied to botnet detection in recent literature [
11,
21,
22,
23]. Therefore, we select DRNN model architecture because of its ability to model the temporal relationships among the features in network traffic data. However, for high feature dimensionality in the training data, a high network bandwidth and a large memory space will be needed to transmit and store the data, respectively in IoT back-end server or cloud platform for DL. Furthermore, given a highly imbalanced network traffic data, DRNN models will produce poor classification performance in minority classes.
In this paper, we propose a memory-efficient DL method, named LS-DRNN, for botnet attack detection in IoT networks. S-DRNN method employs SMOTE and DRNN algorithms only but LS-DRNN combines Long Short-Term Memory Autoencoder (LAE), SMOTE, and DRNN algorithms to achieve an efficient performance. AE is an unsupervised DL that is particularly suitable for feature representation as well as feature dimensionality reduction. There are different variants of AE including Stacked AE (SAE), Variational AE (AE), Sparse AE (SpAE), Convolutional AE (CAE), Deep AE (DAE), Denoising AE (DeAE), and Long Short-Term Memory AE (LAE). Unlike other variants of AE and similar to RNN, LAE uses Long Short-Term Memory (LSTM) to account for long-term dependencies among features while learning their representation and reducing the dimensionality. So, LAE is a good fit for feature dimensionality reduction in the botnet detection task. The main contributions of this paper are as follows:
LAE reduces the feature dimensionality of large-scale network traffic data using unsupervised DL method;
SMOTE generates additional samples for minority classes in low-dimensional network traffic data to achieve class balance;
DRNN performs multi-class classification of network traffic samples in balanced, low-dimensional data using supervised DL method;
DRNN, S-DRNN, and LS-DRNN models are trained, validated, and tested with network traffic samples in the Bot-IoT dataset [
11], and their classification performance in 11-class classification scenario is evaluated.
2. Review of Related Works
In this section, we review related works to establish the novelty and the main contributions of this paper.
Table 1 presents a summary of the state-of-the-art feature dimensionality reduction methods and class balance methods proposed for botnet detection in IoT networks.
Koroniotis et al. [
11] used Pearson Correlation Coefficient (PCC) and joint entropy techniques to select the 10 most relevant features. Support Vector Machine (SVM), DRNN, and Long Short-Term Memory (LSTM) models were trained with these features to perform binary classification. The reduction in the number of features shortened the time taken to train the ML and DL models, but the classification performance was lower than when the full features were used for model training. Furthermore, the authors did not evaluate the performance of the feature selection method in a multi-class classification scenario. The same set of features was also used for ML-based intrusion detection in [
24,
25,
26,
27,
28,
29,
30].
Kumar et al. [
31] proposed a hybrid feature selection method, which combined PCC with Random Forest Mean Decrease Accuracy (RFMDA) and Gain Ratio (GR), to select the 10 most important features. Random Forest (RF), k-Nearest Neighbour (kNN), and Extreme Gradient Boosting (XGBoost) models were trained with these features to perform 5-class classification. Kumar et al. [
32] used a mutual information-based feature selection method to select the 10 most relevant features. RF and XGBoost models were trained with these features for the 5-class classification task. Shafiq et al. [
33,
35] proposed a new feature selection algorithm based on the wrapper technique and Area Under Curve (AUC) metric. Then, C4.5, Naive Bayes (NB), RF, and SVM models were trained for 8-class classification. Koroniotis et al. [
34] developed Multilayer Perceptron (MLP) and RNN models using 13 network traffic features. Asadi et al [
36] proposed Particle Swarm Optimisation (PSO) algorithm to select 10 outstanding features. These features were used to train ML/DL models for binary classification. Popoola et al. [
10] performed feature dimensionality reduction based on the LAE algorithm, while the Bidirectional LSTM (BLSTM) algorithm was used for the 5-class classification task. Other feature dimensionality reduction methods include Principal Component Analysis (PCA) in [
37,
38,
39], and t-distributed Stochastic Neighbour Embedding (t-SNE) in [
40].
Khan and Kim [
48] proposed a hybrid intelligent model using both anomaly-based and misuse-based NIDS approaches. At the first stage, Logistic Regression (LR) and XGBoost algorithms were used to develop anomaly-based NIDS, while the LAE algorithm was used for misuse-based NIDS in the second stage of the system. The effectiveness of the hybrid model was evaluated with the ISCX-2012 data set. Roopak et al. [
49] investigated the effectiveness of Multi-Layer Perceptron (MLP), CNN, LSTM, and CNN-LSTM models for DDoS attack detection in IoT networks. The authors simulated these models with the CICIDS2017 data set. Liaqat et al. [
41] used the up-sampling method to increase the number of benign samples in the training data set. In [
42,
43,
44,
45], Synthetic Minority Oversampling Technique (SMOTE) method was used to generate additional samples for the minority classes. Mulyanto et al. [
46] performed feature selection to reduce dimensionality while focal loss function was used to address class imbalance problem. Similarly, Injadat et al. [
47] selected the most relevant features and additional minority samples were generated using SMOTE.
3. LS-DRNN: A Memory-Efficient Deep Learning Method
In this section, we explain how the LS-DRNN method is developed for botnet attack detection in IoT networks. LS-DRNN employs an unsupervised DL method (LAE), a sampling method (SMOTE), and a supervised DL method (DRNN).
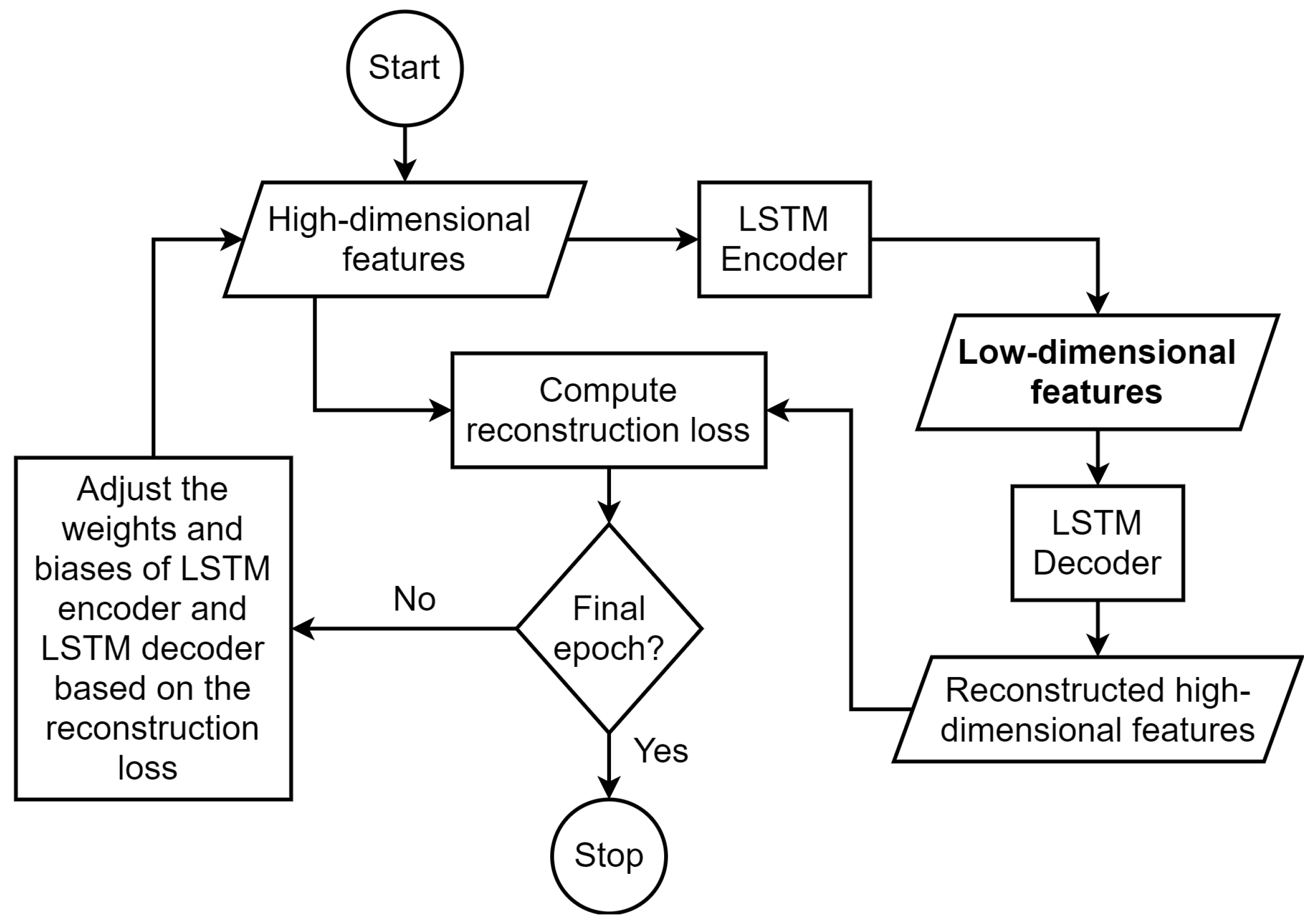
3.1. LSTM Autoencoder
LAE method is an unsupervised DL method and it was used to reduce the dimensionality of network traffic features. Consequently, this process is expected to reduce the amount of memory space that will be required to store training data for DL in IoT back-end server or cloud platform.
A high-dimensional network traffic feature set is represented with
, where
n is the total number of network traffic samples, and
a is the feature dimensionality. This matrix was reshaped to form a sequential 3D tensor,
. LSTM is a recurrent neural network which learns latent space representation of network traffic features using input gate, forget gate, memory cell state, output gate, and hidden state. A single LSTM layer was used to reduce the dimensionality of the feature set based on Equations (
1)–(
6):
where
is the input gate vector;
is the forget gate vector;
is the memory cell state vector;
is the output gate vector;
is the hidden state vector;
are the weight matrices;
are the bias vectors;
is a sigmoid activation function; and
is a Rectified Linear Unit (ReLU). The weight matrices were initialised using He uniform technique [
50].
Similarly, a single LSTM layer was also used to reconstruct the original high-dimensional features from the encoded, low-dimensional features based on Equations (
7)–(
12):
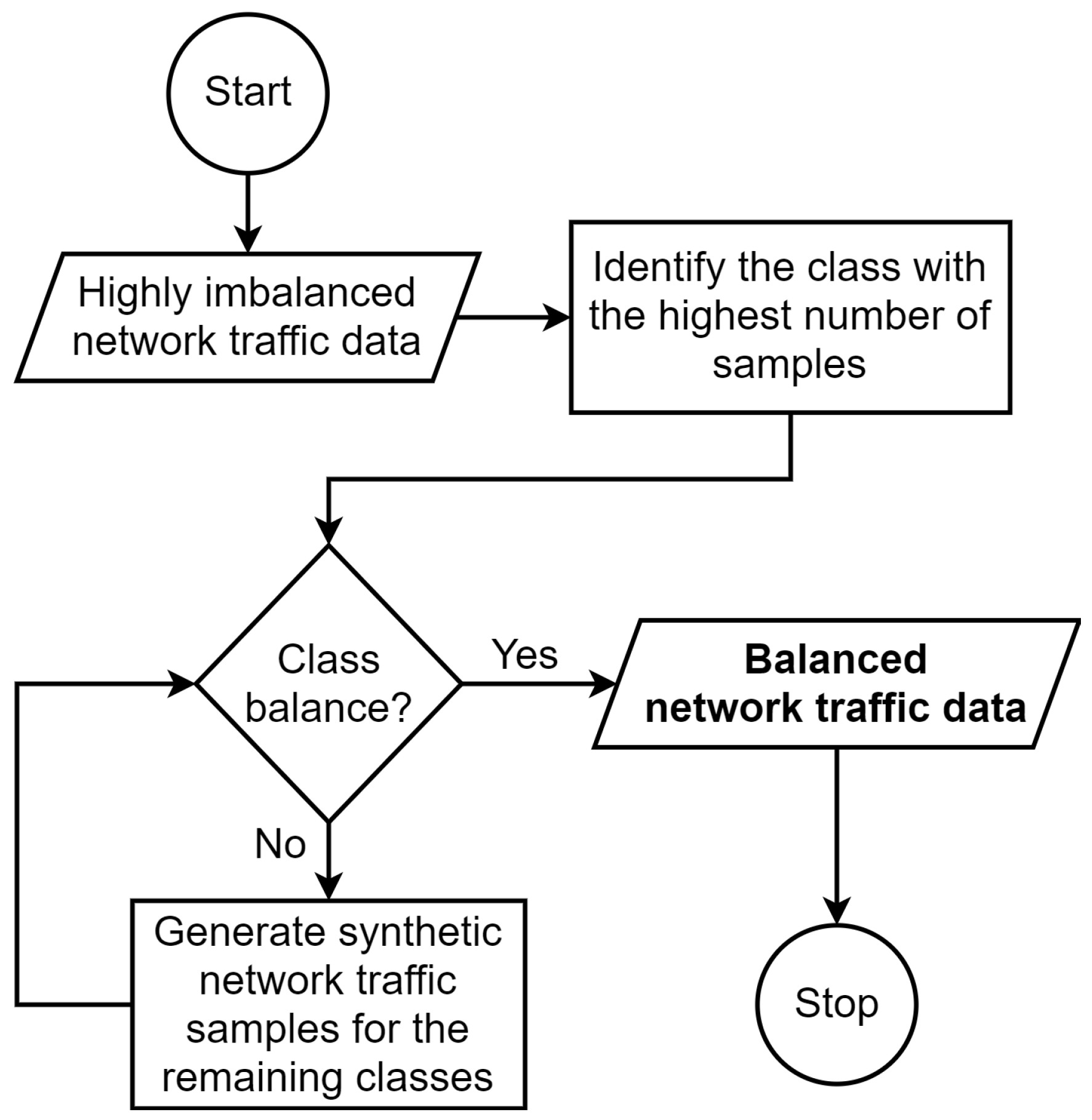
3.2. Synthetic Minority Oversampling Technique
High class imbalance adversely affects the classification performance of ML/DL models. The class imbalance problem is usually handled by either under-sampling or over-sampling the data in the training set to achieve class balance. However, the under-sampling approach is not suitable for cases where the number of samples in one of the minority classes is very small (<10). In our case, there are only four samples in one of the minority classes (more details will be provided later in
Section 4). Therefore, we simply ruled out the option of the under-sampling approach.
Recent studies recommended SMOTE as an efficient over-sampling method [
42,
43,
44,
45,
47,
51]. Therefore, SMOTE algorithm was proposed to deal with the high class imbalance problem in the training set in an 11-class classification scenario. Unlike the method in [
52,
53], which over-samples minority classes with replacement, the method employed in this paper generates synthetic examples by using techniques such as rotation and skew in order to achieve class balance [
54].
These synthetic network traffic data were generated along the line segments joining any or all of the
k nearest neighbours of the minority classes, where
k . Therefore, neighbours from the three nearest neighbours were randomly selected. The step-wise process of SMOTE is presented in Algorithm 1. The generation of synthetic samples (
S) in the minority classes depends on the number of minority class samples (
T), the over-sampling rate (
), and the number of nearest neighbours (
k). If
N is less than
, the minority class samples are randomised. We compute
k nearest neighbours for each of the minority class only. This is a function of
N, the current minority class sample (
i), the integral multiples of 100 in
N (
j), and an array of random numbers (
).
is an array of original minority class samples;
r is the count of a number of synthetic samples generated, and
is an array of synthetic samples.
| Algorithm 1: SMOTE Algorithm |
![Electronics 10 01104 i001]() |
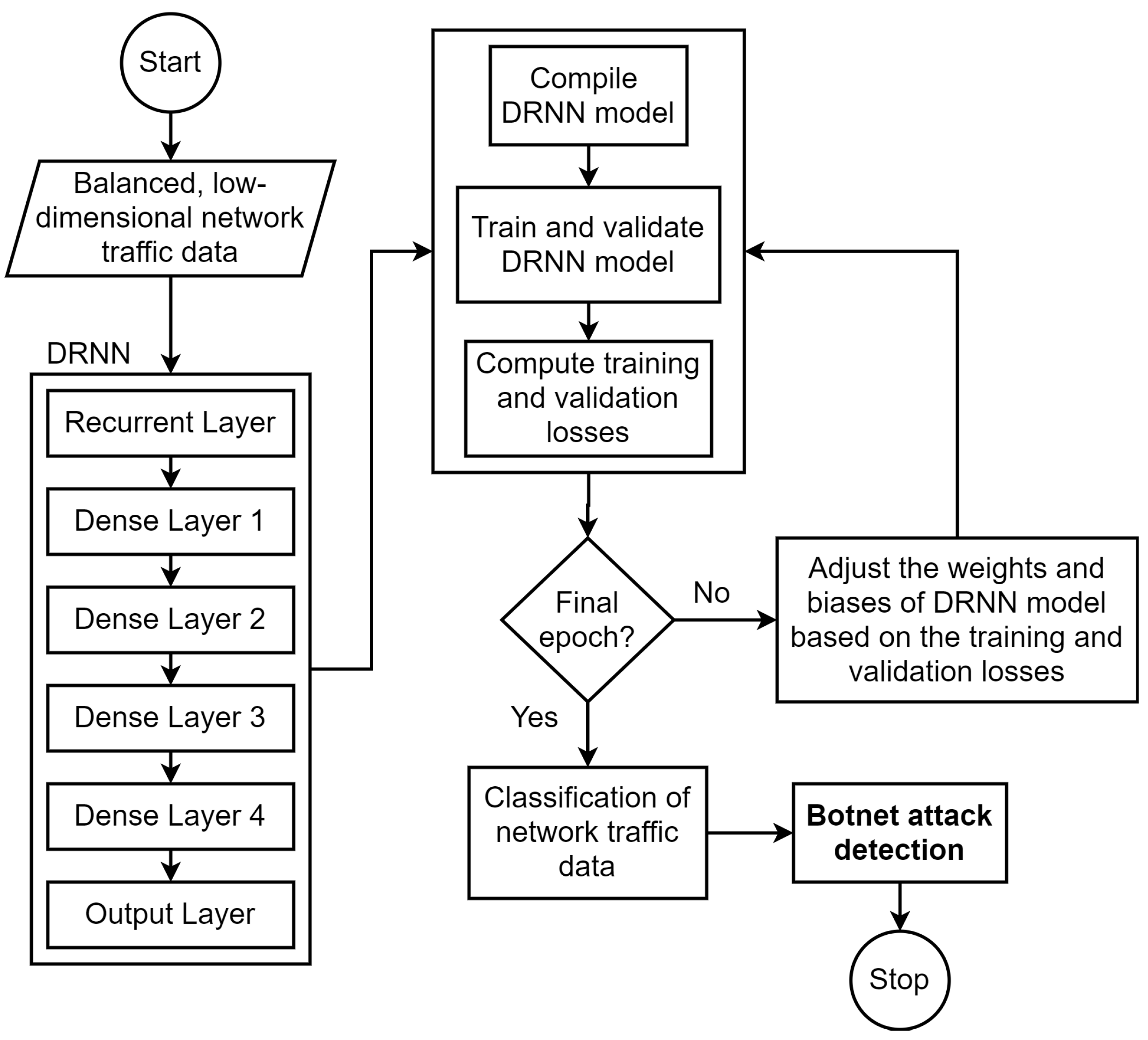
3.3. Deep Recurrent Neural Network
Given a low-dimensional network traffic feature set, , and a corresponding ground truth label vector, , the goal of DRNN is to learn the function that determines the output target whenever the input data sequences are presented. First, a new hidden state vector, , is produced at each time step implementing an activation function on the previous hidden state, , and the current input, .
Unlike Feedforward Neural Network (FNN), RNN has a hidden state which helps to model temporal dynamics of input data. RNN learns the temporal dynamics of a mini-batch of highly imbalanced network traffic features,
, by transforming the input data and initial hidden state,
, with trainable parameters as stated in Equation (
13):
where
is the new hidden state when RNN is trained with the
mini-batch;
and
are the weights used for linear transformation of
and
respectively; and
is the bias. RNN layer output is further processed based on Equations (
14)–(
20) to produce DRNN layer output. Complete information about DRNN is presented in Algorithm 2.
| Algorithm 2: DRNN Algorithm |
![Electronics 10 01104 i002]() |
The hidden states of the four dense hidden layers are obtained by Equation (
14):
where
;
is the hidden state of
hidden layer;
;
is the weight used for linear transformation of previous hidden state,
;
is the bias of
hidden layer; and
is a Rectified Linear Unit (ReLU) activation function given by Equation (
15):
If a is a negative value, the function returns 0; but the same a is returned when it is a positive value.
The hidden state of the fourth dense layer,
, is transformed by the dense output layer as stated in Equation (
16):
where
n is the sample size of mini-batch of
and
;
is the batch size and
;
is the weight used for linear transformation of
;
is the bias of dense output layer; and
is the activation function of dense output layer.
In multi-class classification scenario,
is a softmax function given by Equation (
17):
where
is the number of classes in
. while the difference between
and
is measured by categorical cross-entropy loss function
in Equation (
18):
The performance of DRNN was validated with a different previously unknown highly imbalanced network traffic data,
, and its corresponding ground-truth labels,
. Training loss and validation loss are minimized in mini-batches over
u epochs using an efficient first-order stochastic gradient descent algorithm named Adam in [
55]. Trainable parameters of densely-connected DL model are represented by Equation (
19):
For each epoch, Adam optimizer,
, updates
to minimize
L as stated in Equation (
20):
where
is the new set of trainable parameters;
is the learning rate (
); and
and
are the exponential decay rates (
and
respectively).
4. Simulation and Performance Evaluation
In this section, we implement and evaluate the effectiveness of DRNN, S-DRNN, and LS-DRNN models with the Bot-IoT data set [
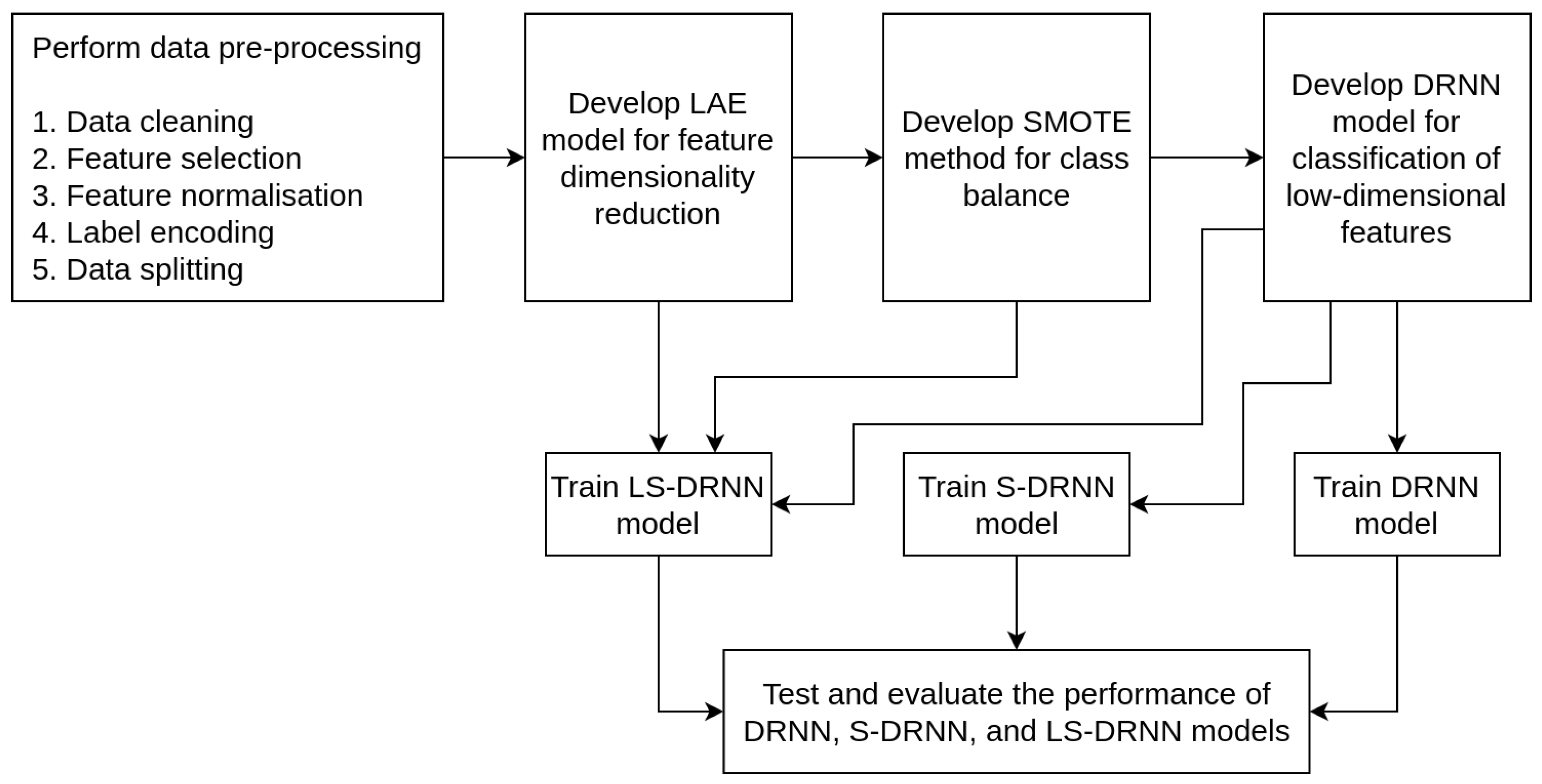
11]. The research methodology involves data pre-processing, model development, and model evaluation, as shown in
Figure 1.
Bot-IoT data set [
11] contains the information about the features of 477 benign network traffic samples that were generated by five IoT scenarios, namely: a weather station, a smart fridge, motion-activated lights, a remote-controlled garage door, and a smart thermostat. Furthermore, the data set contains the features and the corresponding labels of 3,668,045 malicious network traffic samples that represent different botnet attack scenarios including DDoS, DoS, reconnaissance, and data theft. All the network traffic samples in the Bot-IoT dataset were grouped into 10 attack classes and a benign class namely: DDoS-HTTP (DDH), DDoS-TCP (DDT), DDoS-UDP (DDU), DoS-HTTP (DH), DoS-TCP (DT), DoS-UDP (DU), normal, OS Fingerprinting (OSF), Service Scanning (SS), Data Exfiltration (DE), and Key Logging (KL).
Data pre-processing stage involved input feature selection, label encoding, input feature normalization and random data splitting as described in [
10]. The sample distribution of the BoT-IoT data set for training, validation and testing in
Table 2 shows that the network traffic data is highly imbalanced across the 11 classes. All the 37 network traffic features have continuous values; and these values were scaled to a range of
using min-max transformation given by Equation (
21):
where
and
are the minimum and maximum values of
X respectively. Data pre-processing operations were implemented using Numpy, Pandas and Scikit-learn libraries developed for Python programming language.
Figure 2,
Figure 3 and
Figure 4 show the overview of the implementation of LAE, SMOTE, and DRNN methods, respectively. The classification performance of ML/DL model depends on the quality of the training data and the choice of the right network topology. Therefore, we performed extensive experimentation with different recurrent layer, dense layer, activation function, batch size, and epochs to determine the most suitable DRNN architecture. The optimal DRNN structure shown in
Figure 4 has a single recurrent layer, four dense layers, and an output layer. There were 100 neurons each in the recurrent layer and the four dense layers. On the other hand, the number of neurons in the output layer depends on the number of classes in the training set. Hence, the number of neurons in the output layer was set to 11. ReLU activation function was used in the recurrent and dense layers, while softmax activation function was employed in the output layer. DRNN, S-DRNN, and LS-DRNN models were trained using mini-batch stochastic gradient descent algorithm [
55], and we used a batch size of 64. These models were trained and validated for a period of 20 epochs using categorical cross-entropy loss function. Data processing were performed using open-source frameworks and libraries such as Pandas (
https://pandas.pydata.org/), Numpy (
https://numpy.org/), Sklearn (
https://scikit-learn.org/stable/), and Imblearn (
https://pypi.org/project/imblearn/). Model training, validation and testing were implemented using TensorFlow (
https://www.tensorflow.org/) and Keras (
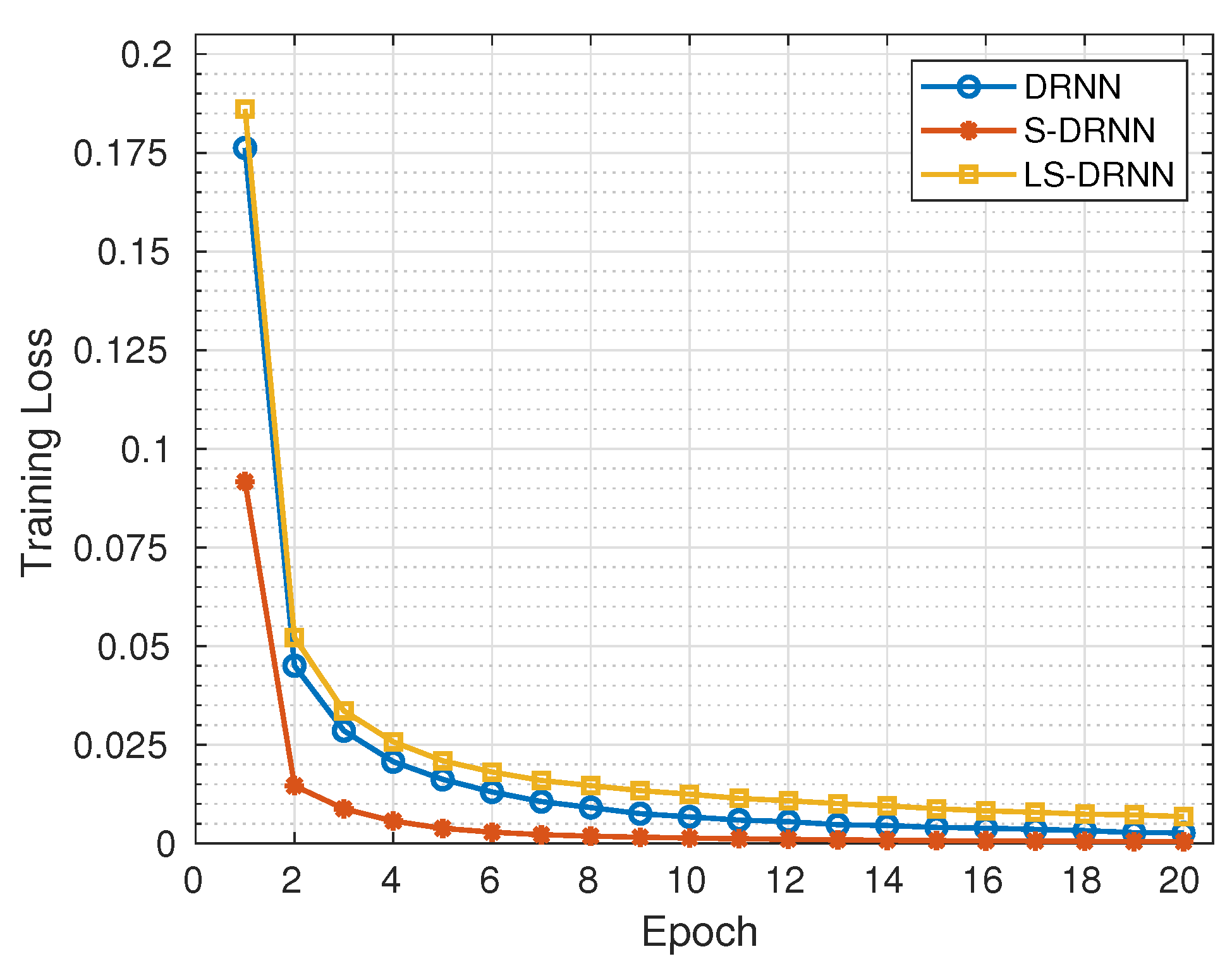
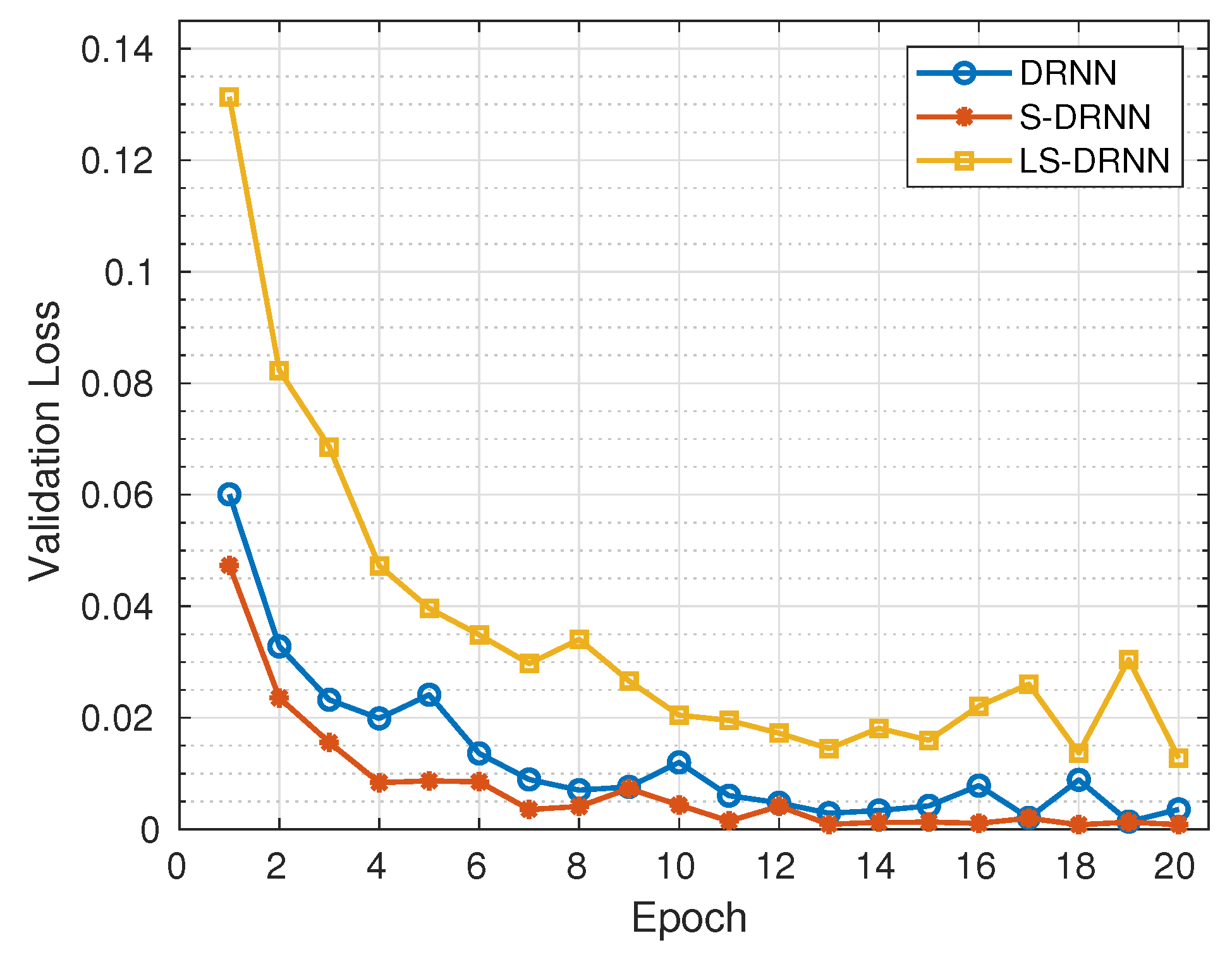
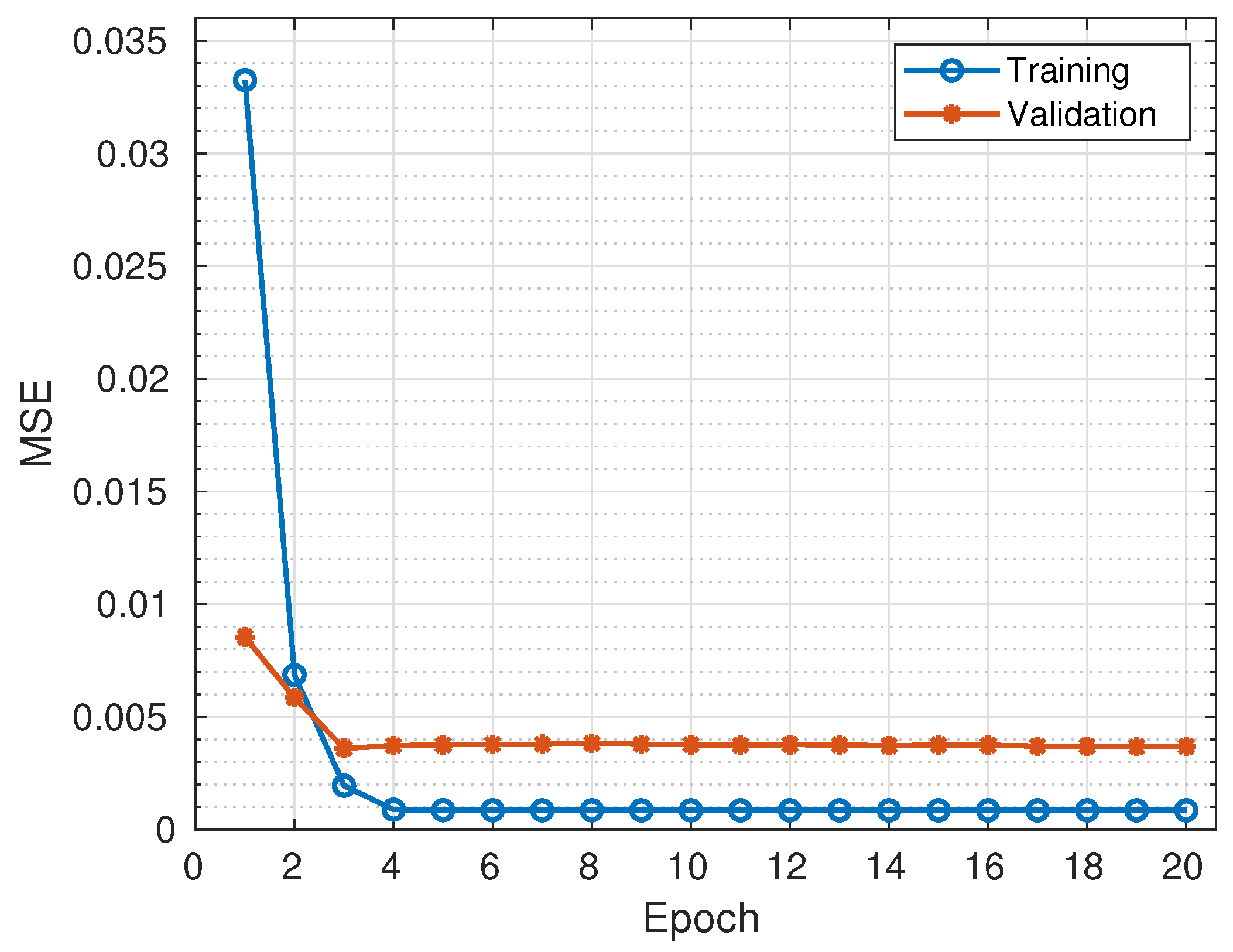
https://keras.io/) frameworks developed for Python programming running on Ubuntu 16.04 LTS workstation with the following specifications: RAM (32 GB), processor (Intel Core i7-9700K CPU @ 3.60 GHz × 8), Graphics (GeForce RTX 2080 Ti/PXCIe/SSE2) and OS type (64-bit). The data sizes of the features in the training sets are analysed to determine the amount of storage space required for DL in memory-constrained IoT devices. Then, training losses and validation losses are analysed to evaluate the robustness of DL models against under-fitting and over-fitting, respectively. Lastly, the accuracy, precision, recall, F1 score, FPR, Negative Predictive Value (NPV), Balanced accuracy (BACC), Geometric Mean (GM), and Matthews Correlation Coefficient (MCC) of DL models are analysed to evaluate their classification performance. The time required to train DL models with the network traffic samples in the training sets and the time required to test the models with the network traffic samples in the testing sets is analysed to evaluate their training speed and detection speed, respectively.
6. Conclusions
In this paper, we developed a memory-efficient DL method, named LS-DRNN, to detect botnet attacks in IoT networks. This method exploited the combined benefits of an unsupervised DL method (LAE), a sampling method (SMOTE), and a supervised DL method (DRNN) for efficient performance. The effectiveness of the LS-DRNN method was evaluated with the highly imbalanced network traffic features and their corresponding labels in the Bot-IoT dataset. First, the LAE method reduced the dimensionality of the network traffic features to minimise the memory space required for the storage of training data in IoT back-end server or cloud platform. Then, SMOTE method generated a total of 4,612,442 synthetic network traffic samples to achieve class balance across the 11 classes. Lastly, DRNN performed a multi-class classification of balanced, low-dimensional network traffic features to identify botnet attacks in IoT networks.
The results of our experiments showed that the dimensionality of the network traffic features reduced from 37 to 10. Consequently, the memory space required for the storage of training data reduced by . Furthermore, the LS-DRNN model achieved high classification performance in the minority classes. Compared to the DRNN model, the overall precision, recall, F1 score, BACC, GM, and MCC of the LS-DRNN model increased by , , , , , and , respectively. Furthermore, the LS-DRNN model demonstrated better classification performance and faster detection speed than state-of-the-art ML and DL models. Therefore, the findings of this study validate the effectiveness of the LS-DRNN model for efficient botnet attack detection in IoT networks.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}