1. Introduction
The timely availability of multimedia content to a user is as important as the availability of intelligence in a war. In digital marketing, video covers 80% [
1] of material. According to Cisco [
2], 82% of total Internet traffic is videos. Moreover, a single HD television that is connected to the Internet will generate, on average, an equivalent amount of traffic to that generated by an entire family. This problem escalates when it comes to Ultra-High-Definition (UHD) devices, as they require double the HD video bit-rate. Cisco estimates that by 2023, 66% of televisions will be UHD. Therefore, an efficient algorithm is required that can reduce the size of multimedia content. Compression algorithms reduce the size of videos but maintain the same subjective video quality.
For this work, we will use the High-Efficiency Video Coding (HEVC) [
3] compression standard. This standard, also known as H.265, reduces the bit-rate requirement by 50% and delivers the same subjective quality [
4]. This bit-rate reduction is achieved by using big block sizes to compress smooth regions of the video, and small block sizes to compress textured regions. Moreover, the content of each block is predicted by using neighboring pixels. These neighboring pixels are projected onto the area of the current block in 35 different ways to achieve best prediction. These 35 projections are known as intra modes in HEVC.
HEVC can efficiently compress UHD content, and all issues related to UHD can be solved, but HEVC is not applicable to real-time applications. The complexity of HEVC has increased as compared to its previous standard, H.264. The complexity of HEVC increases as it tries all the block sizes and intra modes to predict the best tradeoff between rate and distortion, known as the RD cost. HEVC test model software, HM [
5], first partitions the image into
-size blocks known as Coding Units (CUs) and the best intra mode is selected by applying all 35 intra modes. Then, this
CU is partitioned into 4 CUs of equal size, and the same intra mode procedure is repeated on them. This CU partitioning and intra-mode selection process is repeated until the CU size reaches 8, which is the smallest CU in HEVC. This brute-force characteristic of HEVC makes it unfit for real-time application.
To reduce the complexity of HEVC, a fast intra-mode [
6] decision-making task will be carried out in this article. There are 35 intra modes, and one of them is the best; therefore, a mechanism is needed that facilitates early intra-mode decision. Out of these 35 modes, 33 are angular modes that project neighboring pixels in 33 different ways onto the current CU. The remaining two modes are used to predict the smooth regions present in the image.
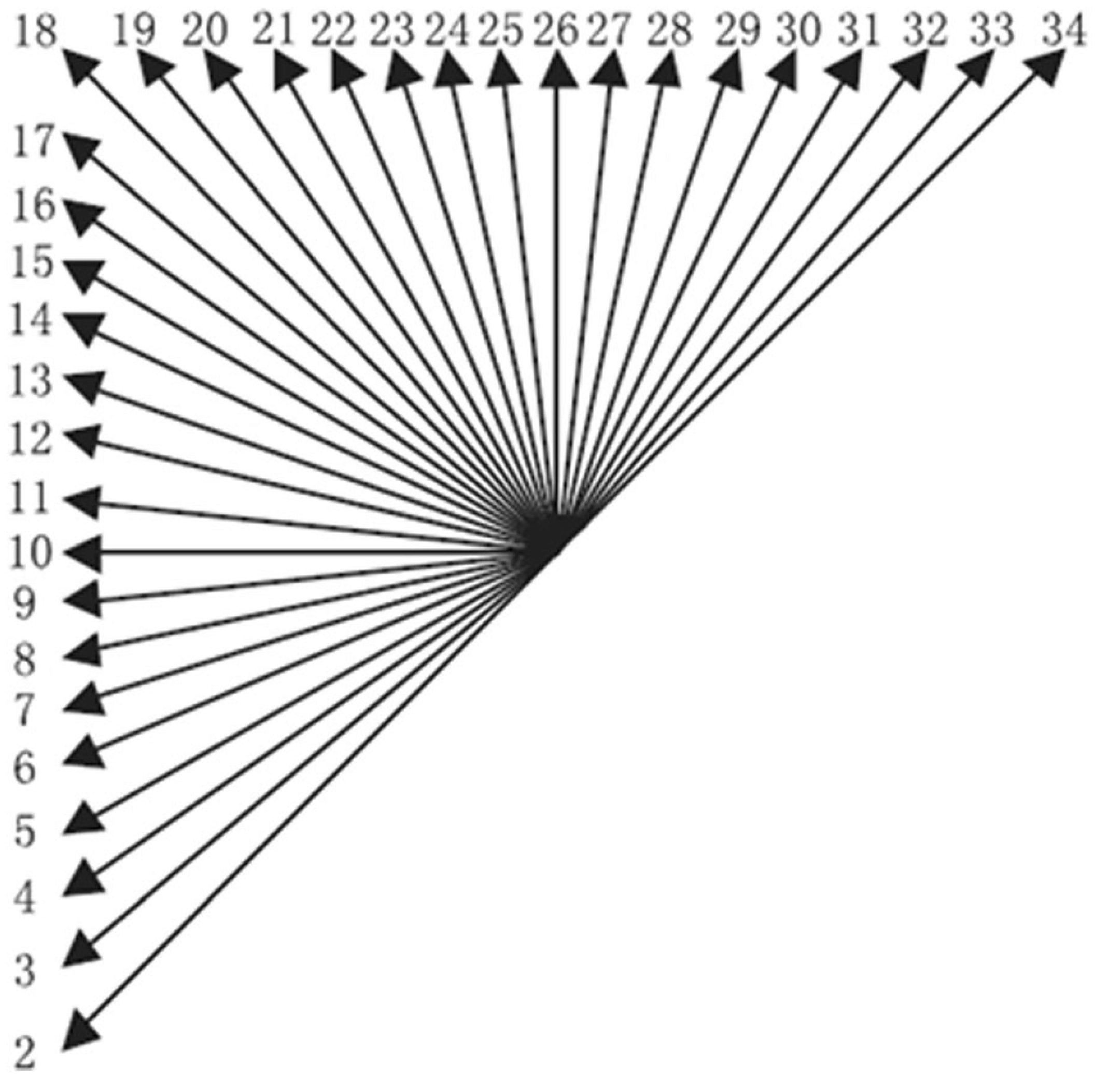
Figure 1 [
7] shows the directions of the 33 angular modes. The RMD module of the HM software shortlists up to 8 intra modes for the current block by using the Hadamard cost. The number of intra modes depends on the size of the block. The RMD module shortlists {8, 8, 3, 3, 3} intra modes for block size ∈ {
,
,
,
,
}, respectively. Then, the RDO module of the HEVC computes the RD cost for these intra modes (shortlisted by RMD) and selects 1 intra mode.
The proposed work is inspired by Optimal Stopping Theory (OST) and Classical Secretary Problem (CSP)-based models, and applied the German Tanks Problem (GTP) [
8] algorithm to perform a fast intra-mode decision. The GTP algorithm is a statistical model just like OST and CSP, but is based on a true story. The GTP was created during World War II (WW2) to predict the number of tanks that the Germans had. This algorithm, GTP, not only predicted the number of tanks with great accuracy, but also discarded the claims made by intelligence. This victory over British and American intelligence gave GTP unique importance and significance. Moreover, the formulation of GTP is very simple. Therefore, this article applies GTP to predict the intra mode for the current CU. The proposed GTP-based algorithm outperformed existing algorithms. The main contributions of proposed algorithm include:
- (i)
Being the first algorithm to use GTP for early intra-mode decisions.
- (ii)
Having not only a strong foundation, but also computational efficiency.
- (iii)
Providing a satisfactory tradeoff between rate and distortion, and performing better than many existing algorithms.
This article is structured as follows: related works, motivation, the proposed model, and results are presented in
Section 2,
Section 3,
Section 4 and
Section 5, respectively. After that, the article is concluded in
Section 6.
2. Related Works
The literature is full of fast algorithms. One reason for intra-mode popularity is that it is a very challenging area because one mode must be selected from 35 modes. Therefore, the probability of selecting the correct option is only 0.02%.
In [
9], 30% of the encoding time is saved by a classical secretary problem-based algorithm. This work evaluates a minimum of two modes to compute the stopping point. In [
10], the pixel values of the left and above block are used to decide the planar mode. This results in a 14% time reduction in the encoding process. Zhu et al. in [
11] saved 16.1% of the encoding time. In this work, the Hadamard transform is used instead of DCT.
The author of [
12] saved 28% of the time by proposing a model that performs intra-mode selection in an iterative process. In each iteration, a few intra modes are selected from the available pool (i.e., 35 modes). In [
13], a 60% time-saving is achieved. This work tries a sub-set of modes. Ying in [
14] saved 38% of the time by proposing a model that uses RD as a stopping point. Zhang in [
15] saved 38% of the time by proposing a model that consisted of three phases. In [
16], a model is proposed that uses the complexity of the block to form three groups. Yeh in [
17] computes an RD cost using co-located information. Then, this RD cost is used to compute the stopping point.
In [
18], the RDOQ module was customized. This work used the coefficients of the transform to predict RD cost. Around 63% of the time was saved in this work. Zhang in [
19] performed intra prediction using the gradient of the block. In [
20], Hu saved 55% of the time by proposing a regression-based algorithm. Tariq in [
21] saved 35% of the time by proposing a model based on stopping theory.
In [
22], Kuanar saved 45% of the time by proposing a model based on CNN. Huang in [
23] performed optimization of intra modes. According to Huang, this model can be used for early decisions of CU and PU. The time-saving was around 66% on average. The author of [
24] saved 58% of the time by proposing a model based on random forest. In [
25], 52%of the time was saved. This work selected an angular mode for the block by using the output of the planar mode applied on the same block.
Tian in [
26] saved 20.45% of the time. This work used a deviation among pixels of the block to find the intra mode for the block. In [
27], Gwon saved 31.54% of the time by proposing a model that used a classifier. The Hadamard cost was used as a feature in this classifier. In [
28], uncertainty-based model was proposed for fast intra-mode decision. The main contribution of this work was that it incorporates uncertainty of the real world into the algorithm. Therefore, it dynamically adjusts itself to various situations. In [
29], Munagala enhanced the holoentropy of HEVC. As a result, the PSNR is approved compared to the original HEVC. Improvement to PSNR is directly related to improvement in the subjective quality of the content. Therefore, this algorithm gives a realistic experience to the user. Liu, in [
30], proposed a method that accurately predicted features from video sequences. This method helped overcome stability and quantity issues of feature-matching techniques. More features mean more information and, hence, such an algorithm gives a more accurate prediction. However, more features mean more computation. Therefore, features should only be used that efficiently represent the original data. Bahce, in [
31], proposed a 3D-SPECK method for the encoding of geometry videos. Jridi in [
32,
33] proposed an architecture for Discrete Cosine Transform (DCT) to reduce the complexity of HEVC. This work approximates DCT better than the existing architectures. Tariq, in [
34,
35,
36,
37], used statistical models to make early decisions about the intra mode.
The proposed work, in comparison to the state-of-the-art works presented above, computes the probability of each intra mode. These probabilities are then passed to the GTP algorithm to estimate the stopping point. Moreover, GTP is modified to perform early estimation by using only k options such that k ≤ N, where N is the total number of options.
3. Motivation
First, we present the ’German Tanks Problem’ (GTP) algorithm here; otherwise, it will be difficult to know the importance of GTP and why it is being selected to perform early intra-mode decision. Statistically, GTP has great importance because it is based on a true story. In World War II (WW2), the Allies wanted to know how many tanks the Germans had. Such information was of great importance because it could affect the outcome of the war. Therefore, the British and the Americans asked statistical intelligence to estimate the number of tanks the German had. The statisticians had one key piece of information, which was the serial numbers on the captured tanks. This was enough for statisticians to make an estimate of the total number of tanks that had been produced up to any given moment.
A point estimate in sample statistics is used to estimate a population. In this case, the statisticians were trying to estimate the maximum tank serial number based on the sample of tanks. Suppose we have a sample of serial numbers of tanks
S as follows:
One can compute many types of sample statistics for this
S. For example, one can find the
mean,
mean + 1SD (SD: Standard Deviation),
mean + 2SD,
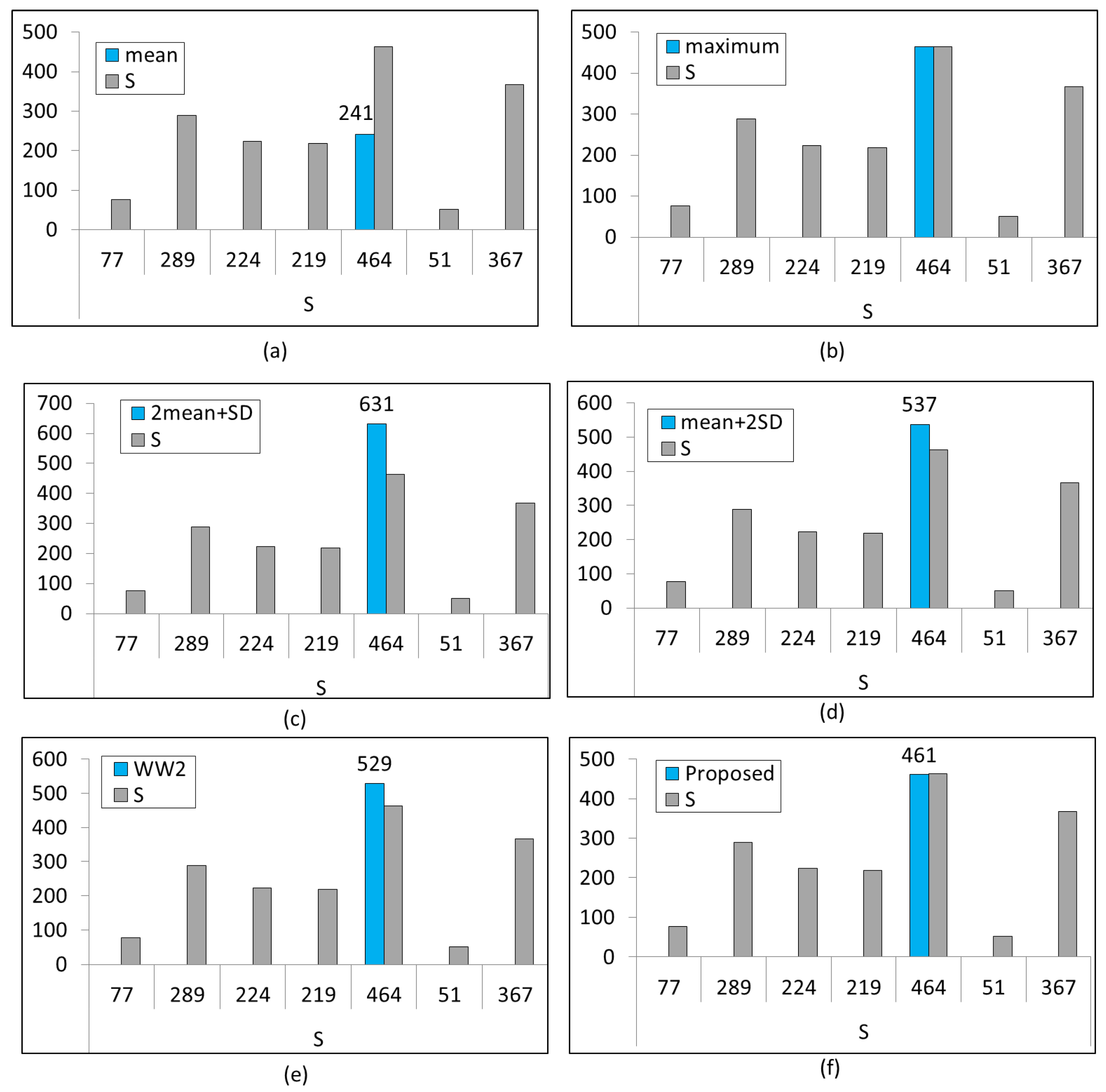
max + min, etc. To find out which of these statistics is best, we must perform some simulations and the best of them will be centered at 500. Now we look at some statistics and plot them on the graph to see how they perform.
Figure 2 presents graphs of well-known statistics. The blue line in these graphs represents the population obtained from the statistics and the gray bars are the samples (
S) that we have. The first statistic is the
mean, as shown in
Figure 2a.
Figure 2a shows that this statistic estimates half the population. In
Figure 2b, the
maximum is used and it predicts close to maximum only. Similarly,
Figure 2c,d show the graphs of
‘2 times the mean + 1 standard deviation (SD)’ and
‘1 mean + 2 SD’, respectively. The correct number of tanks the German had was 500, and now we see how statisticians estimated this number.
The statisticians used (
2) in WW2 to estimate the population, where
m is the maximum serial number and
k is the total number of tanks captured. This estimate takes the population maximum and multiplies it by a number that is slightly greater than 1, i.e.,
(Sample Size +1)/Sample Size. The rest of the story of WW2 regarding GTP is that the statisticians at that time reported that the Germans had 529 tanks, but the standard intelligence estimate was 1400 tanks. After the war, the Allies captured the German production records, which showed that the true number of tanks produced was 545, almost exactly what the statisticians had calculated. The most famous form of (
2) is obtained by simplifying it as follows:
This is also known as
minimum-variance unbiased estimator. The most important feature of this estimator is that it predicts a single value for a set of values,
N. Now, we solve the same problem by applying the optimal stopping theory concept. The main task is to estimate the value as soon as possible, where the serial numbers are shown one at a time. Moreover, these serial numbers are sorted in ascending order. We slightly modified (
3) into (
4) and its output is given in
Table 1.
In (
4),
k is the number of elements seen so far,
m is the highest value (serial number) among the seen elements,
is the sum of all the serial numbers of the
k elements seen so far. The working of (
4) is explained with the help of an example; suppose a person has 3 cars in total and they have serial numbers on them. Equation (
4) is applied to this situation and the result is presented in
Table 1. Let us compute the first row of
Table 1. The first row of
Table 1 shows that the decision maker has seen one car, so
k = 1,
m = 1 because the serial number on this car is the highest serial number observed so far, and
= 1, as the sum of serial number of seen element(s) is one. Therefore,
= 2 ( 1 + 1/1). Then we see another car (2nd row of
Table 1) with serial number 2, hence,
k = 2,
m = 2,
= 3 and
= 3.5 (2 + 3/2). It is interesting to see that the number 3 is estimated after seeing only two elements.
Let us see another example of the proposed formulation by applying it to the data given in (
1), and its results are shown in
Table 2. In
Table 2,
k is the number of elements,
S is the serial number of the tank that is currently captured,
is the summation of serial numbers up to
k, and
is the output of the proposed fast estimation. It is interesting to note that the value 461 is achieved by the 5th element. It is not accurate, but it is the best possible estimate made by looking at the minimum number of elements.
4. Proposed Algorithm
In this section, we will propose a fast intra-mode estimation technique using GTP. It is already shown in the previous section that it is possible to estimate an early value. Therefore, GTP concept will be extended in this section to estimate the intra mode early for the current CU.
4.1. Hadamard Cost vs. Probability
The RMD module of HEVC shortlists
N number of modes for the current CU by applying the Hadamard cost. Then, the RDO module performs operations on each of these
N modes to obtain the RD (Rate Distortion) cost to find the optimal intra mode. The RDO module evaluates all these
N modes, because it is possible that the RD cost of the first intra mode can be large and the RD cost of the
Nth intra mode can be small. Therefore, we used the probabilities for the intra modes that are shortlisted by the RMD module. These probabilities are pre-computed and saved in a 2D matrix of size 35 × 35 because there are 35 modes. This matrix is shown in
Figure 3. To obtain this matrix, we initialize this 2D matrix with zeros. Then we encode any video and when a mode is selected for the current block (e.g.,
j) and the neighboring mode is
m, then we increment the value at
mth column and
jth row. This will give us the count matrix but it can be converted to probability by dividing it by the sum of all the values in this row
j. After that, if the intra mode
J is shortlisted by the RMD module for the current block, and by using this 2D matrix (given in
Figure 3), we can compute its probability. The small spikes in
Figure 3 mean that these modes have less probability to be selected, and big spikes in
Figure 3 mean that these modes have high probability of selection. In this work, we obtained this matrix using a
BasketballDrill video sequence because it contains fast and medium motion.
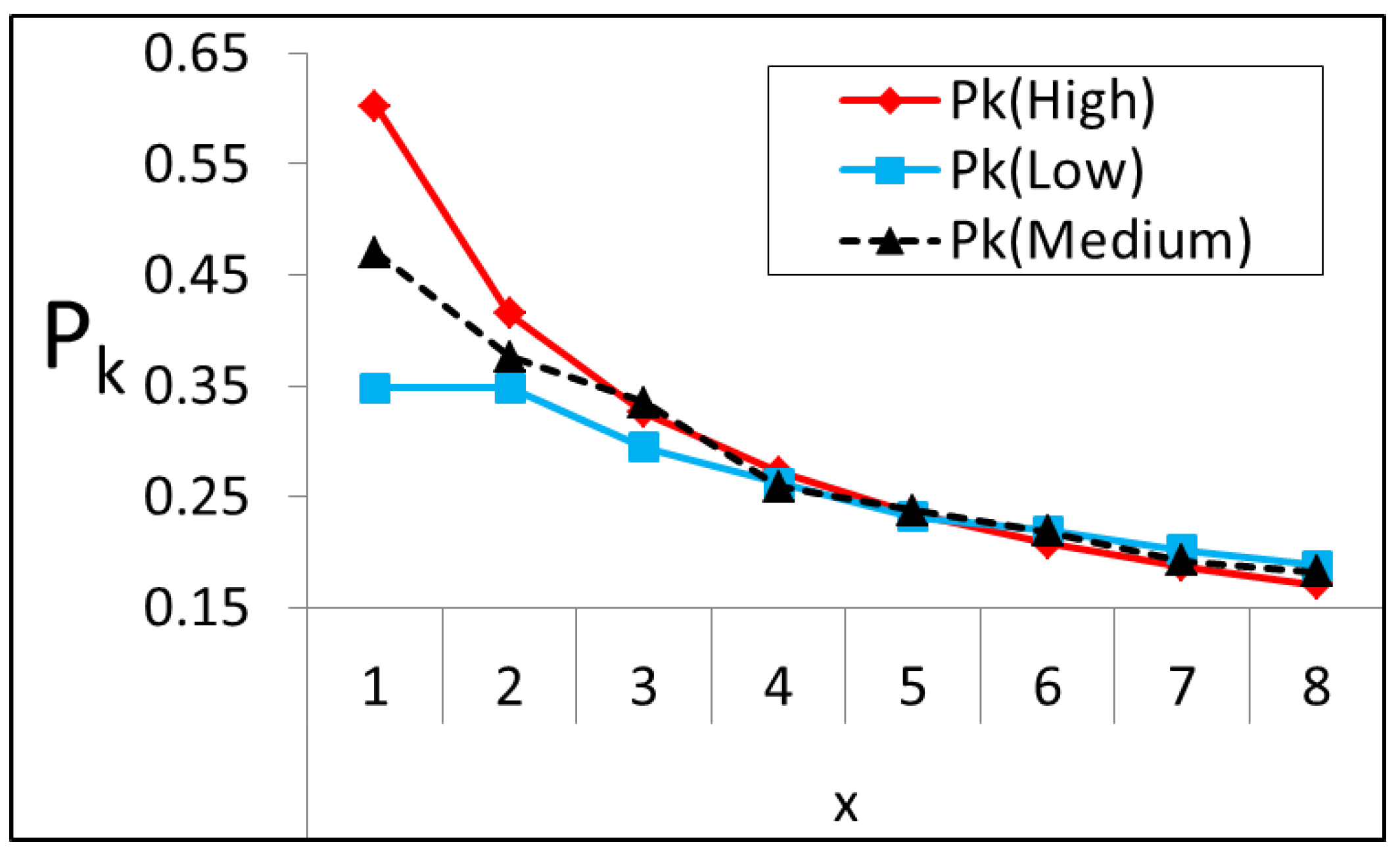
To construct a model and to perform simulations, three sets of values are selected from
Figure 3 that are termed as ‘high’, ‘medium’, and ‘low’. The ‘high’, ‘medium’, and ‘low’ sets are obtained from different regions of this 2D matrix. The ‘high’ values are taken from a high peak region that indicates huge values, ‘medium’ values are taken from medium size peak and similarly, and ‘low’ values are taken from a flat region of a 2D matrix. The values in the ‘high’ set are: {0.30, 0.18, 0.12, 0.10, 0.08, 0.07, 0.06, 0.05 }; The values in the ‘medium’ set are: { 0.24, 0.17, 0.15, 0.10, 0.09, 0.08, 0.07, 0.06 }; The values in the ‘low’ set are: { 0.17, 0.17, 0.13, 0.11, 0.09, 0.09, 0.08, 0.07 }. The proposed early estimation, (
4), is applied to these sets and their visual output is shown in
Figure 4. In
Figure 4, the values are decreasing because the ‘high’, ‘medium’ and ‘low’ sets are arranged in descending order.
Figure 4 ‘high’ case gives higher values for early elements and gives very small values for the last elements. This indicates that the last elements have very little chance of being the optimal element. Where the ‘low’ case is concerned, the
assigns values to the last elements such that they are greater than the ‘high’ case. This is a very interesting factor of the proposed model, assigning large values to the last elements of the ‘low’ case even though the values in the ‘low’ set are smaller than the values present in the ‘high’ case. The ‘low’ values do not descend very fast like the ‘high’ case because the probability is very low, and this indicates there is no clear information about the best element. Similarly, the ‘medium’ case in
Figure 4 represents the intermediate case where the
values for this case are lower than ’high’ but greater than ‘low’ values.
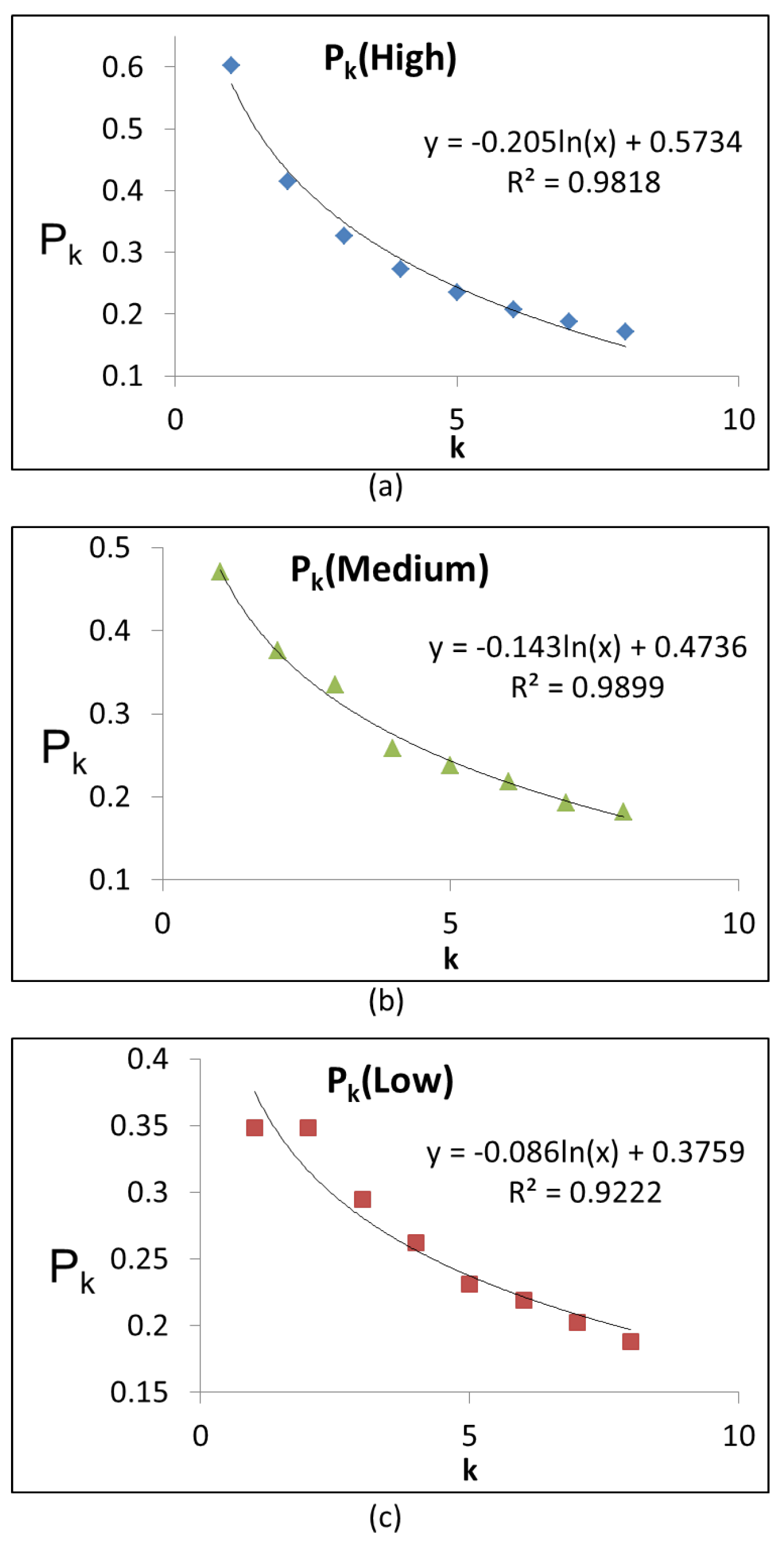
4.2. Trend of Proposed Early Estimator
The trend of
for ‘high’, ‘medium’ and ‘low’ values are shown in
Figure 5.
Figure 5 shows that these values follow the natural-log trend (
). The correlation coefficient (
R) is also shown in
Figure 5. This
R is obtained using Microsoft Excel. Moreover, according to Wikipedia, GTP can also be written using a Bayesian formulation as follows:
Therefore, we can say that the proposed early estimation (i.e., (
4)) is aligned with GTP, because it follows a natural-log (
) trend.
4.3. Early Mode Decision Using Early Estimator
In HEVC, the first element given by the RMD module is selected 60% of the time, but there is no clue as to which are those 60% cases out of a total of 100%. That is why probabilities of these modes are used to extract some extra information about these modes that might help us make the early decision. Therefore, we need a stopping mechanism that performs early termination when these probabilities are high, and delay the early termination when these probabilities are low.
Figure 5 clearly illustrates that the values are smooth and can be modeled using the natural log. Moreover, the drop in these values is also dependent upon the probabilities of these elements (see
Figure 4), and this makes early estimation both dynamic and flexible. Therefore, an efficient early intra-mode decision can be performed using:
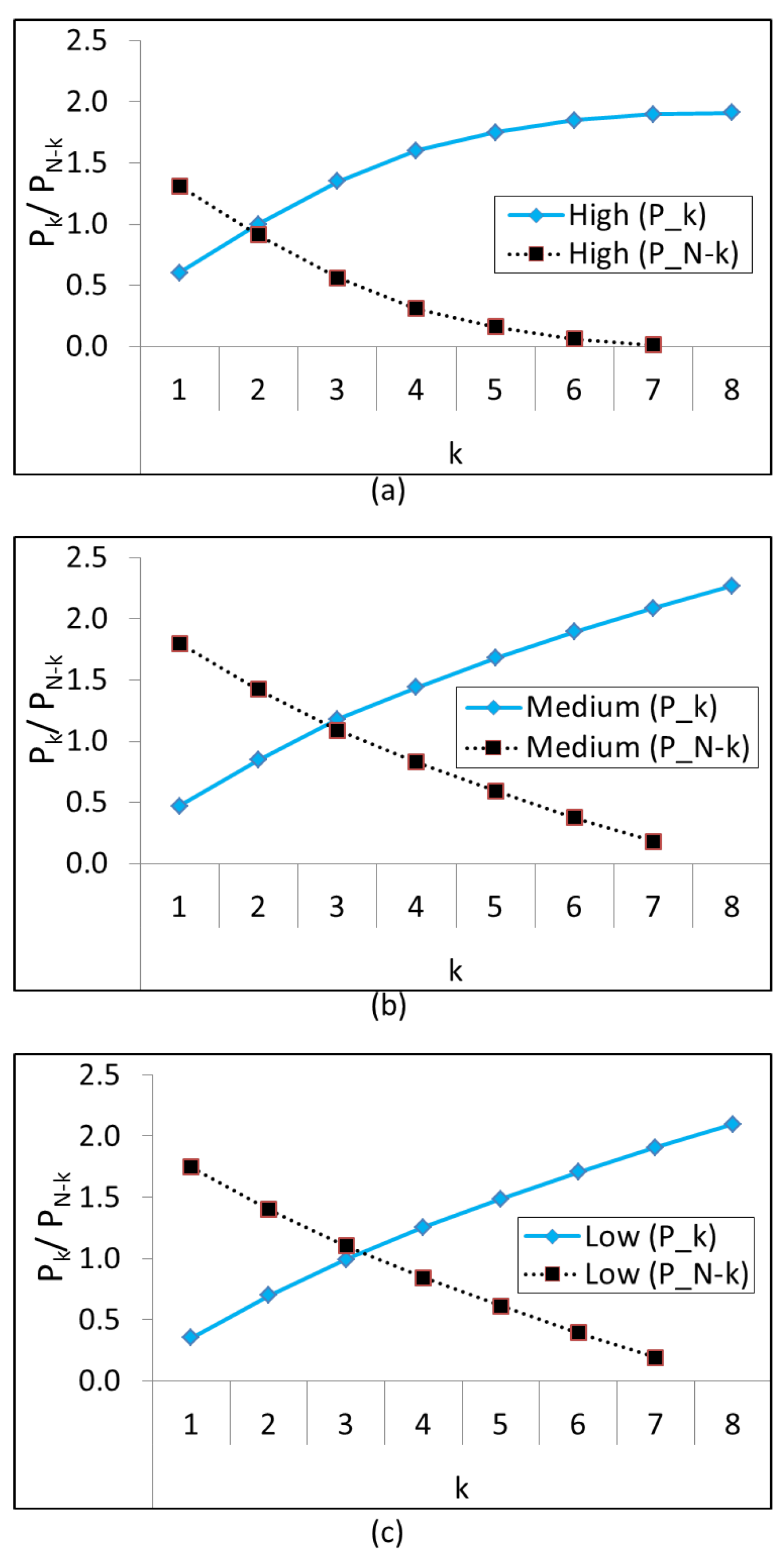
This model evaluates elements from a sequential list one at a time and checks the above early-decision condition. At any element k, if becomes greater than the remaining elements, i.e., , then this early termination is performed. It all depends upon the movement of k for different cases. For example, for ’high’ case, this k will be among the early elements of the list and for ’low’ case, this k will be among the later elements of the list.
The visual outputs of the proposed model (
6) for three cases (‘high’, ‘medium’ and ‘low’) are shown in
Figure 6. The movement of
k is clearly visible for different cases. For ’high’ case,
k has moved before the 2nd element and for ‘low’ case, this
k has moved after the 3rd element, therefore making the model dynamic and flexible.
These examples show that the proposed algorithm handles various situations efficiently and dynamically, adjusting itself according to the elements. Moreover, the formulation of this early termination model is very simple and, as a result, it requires less computation.
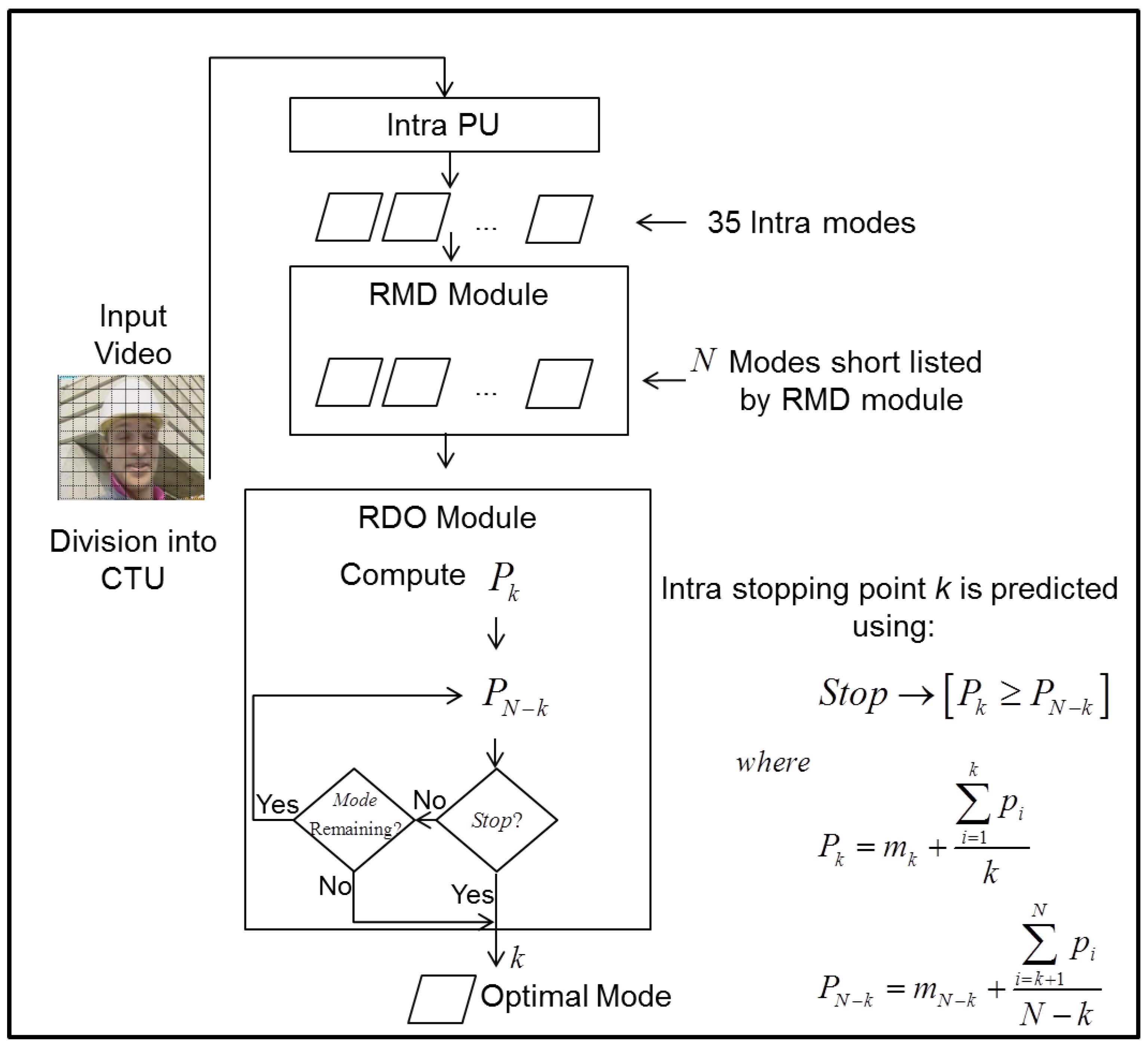
The flowchart of the proposed algorithm is shown in
Figure 7. The changes made to the RDO module are shown in the RDO box. For each CU, the RMD module evaluates 35 intra modes and shortlists up to
N modes. Then, the proposed algorithm evaluates these intra modes given by the RMD module one by one until it finds the termination point, i.e., the point found using (
6).
5. Experimental Results
Experimentation and comparison will be covered in this section. A slight change to the proposed model will be made to further improve the time-saving of the proposed model, but it will be presented in a separate table.
The proposed model is implemented in the recent HM version of HEVC i.e., 16.9. This HM software is downloadable from [
5]. The HEVC dataset [
38] contains various classes which include various videos. All these videos are coded using the "All Intra Main" configuration. This configuration is usually selected for intra-mode decision algorithms. In this configuration, all the CUs are intra-coded. Moreover, videos are encoded using 4 QPs (22, 27, 32, 37) to make comparison with the existing algorithms. The performance of the proposed algorithm is evaluated using BD-PSNR, time-saving, and BD-BR as recommended in [
39]. Time-saving is computed using:
Experiments are conducted on a machine with 8 GB Ram, Intel i5 processor with computing power of 2.30 GHz and 64-bit operating system. First HM16.9 is executed to encode each test sequence five times and the mean of its time-saving is noted. Then, the proposed model is executed five times to encode the same sequences, and mean of time-saving is noted for comparison.
5.1. Encoding Results of Proposed Model
The compression results of the proposed model are presented in
Table 3. In
Table 3,
P,
R and
T stands for BD-PSNR, BD-BR, and time-saving, respectively.
Table 3 shows that the proposed model saves 24% of the encoding time and costs 1.79% more bit-rate (BD-BR). The
T column in
Table 3 shows that there is some uniformity among the test video sequences. The maximum time-saving of the proposed model is 26.25 and the minimum time-saving is 21.45. Where BD-BR is concerned, the maximum BD-BR cost of the proposed model is 2.88 for the ‘Kimono’ test video and minimum BD-BR cost is 0.99 for the ‘SlideShow’ test video sequence.
To further improve the time-saving of the proposed model given in (
6), its
m term is removed to further reduce the complexity of the model. This resulted in a model given in (
8).
The encoding results of (
8) are given in
Table 4.
Table 4 shows that the time-saving is increased to 26.88%, and BD-BR increased to 1.97%. This is the maximum time-saving achieved with this model as we have tried two versions of GTP.
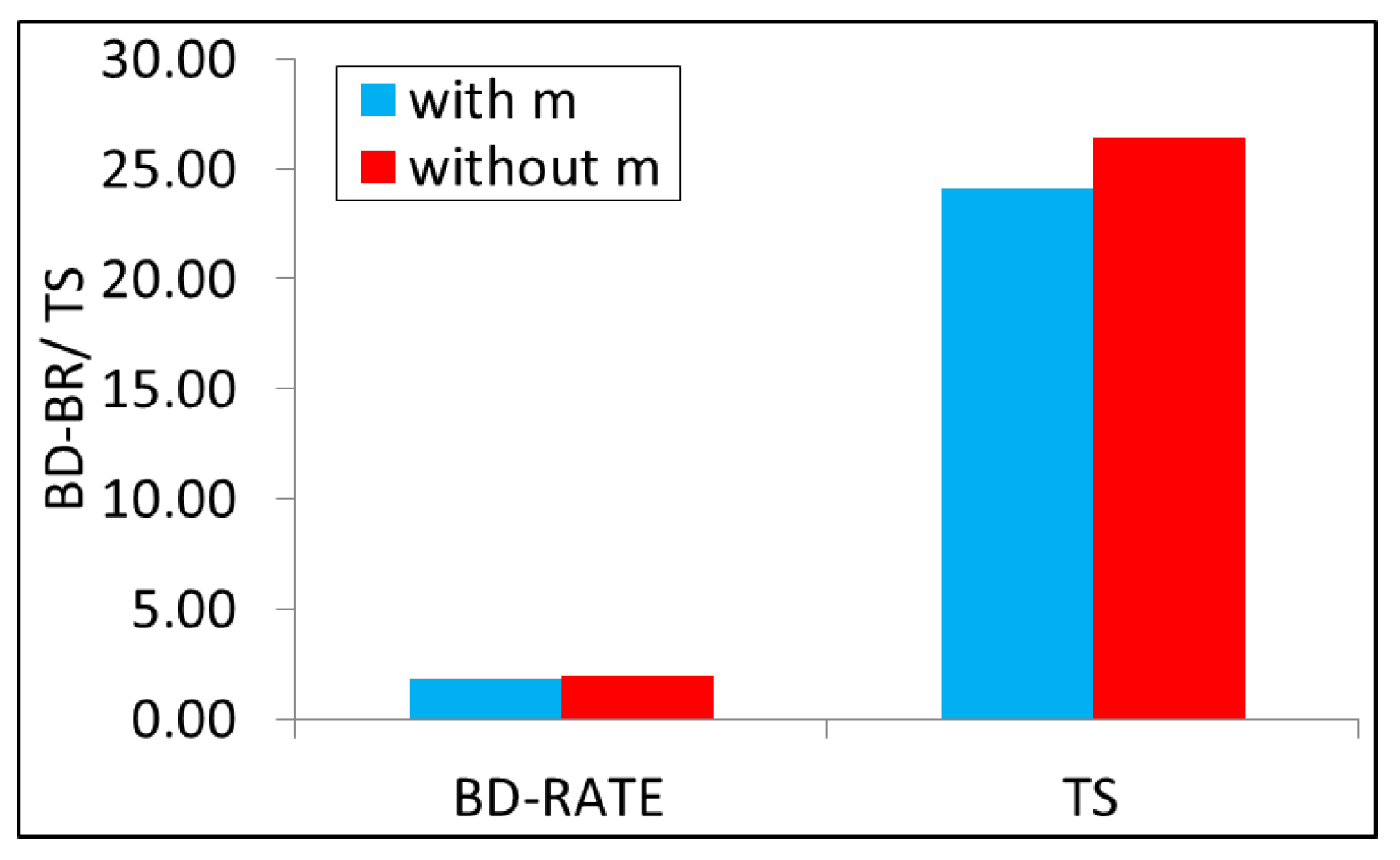
The comparison of both the variations of the proposed models is given in
Figure 8.
Figure 8 shows that if the time-saving is the need for the time, then one should prefer the model given in (
8). Otherwise, one can use the model (
6) to save the bit-rate overhead.
The subjective quality of the proposed algorithms is shown in
Figure 9. By subjective, we mean the reconstruction quality of the video after compression. The reconstructions of the proposed models with and without
terms are shown in
Figure 9a,b, respectively.
Figure 9 shows that there is not much subjective difference between the two variations. Even if we zoom the text present in the image, there is not much difference. Therefore, we can say that the overall quality of the proposed model(s) is satisfactory.
5.2. Proposed Model vs Existing Algorithms
To make a fair comparison with the existing algorithms, the proposed model is placed in
Table 5 along with three latest and state-of-the-art fast intra-mode decision algorithms. The term
Proposed in
Table 5 represents the proposed algorithm. The “-” in
Table 5 means that the author of that algorithm did not mention the result of this test video sequence. Please note that some authors have reported huge time-saving, but that does not fall in fast intra mode decision as they combined fast CU, fast PU, and fast intra mode in a single algorithm. Moreover, the maximum possible time-saving achievable using intra mode decision is 40% [
40]. The fast intra mode decision cannot be compared with a fast CU size decision because the intra mode decision is very different. The probability of selecting the right intra mode is only 0.02 (1/35). Hence, the intra-mode decision is very different and difficult.
Table 5 summarizes three pure intra-mode decision algorithms that include [
41,
42,
43]. Moreover, their years of publication are also mentioned in parentheses “()”. The algorithm presented in [
41] saves 15% of the time, [
42] saves 22% of the time, and [
43] saves 26.75% of the time. The proposed algorithm saves 26.88% of the time, which is very close to [
43]’s time, but the methodology of the proposed work is unique, as this is the first article to employ GTP for fast intra-mode estimation. Moreover, the proposed algorithm is implemented in the latest HM version, i.e., 16.9, and each new version has some sort of optimization. Therefore, we can conclude that the proposed algorithm gives satisfactory results.
5.3. Analysis of Proposed Model
The proposed algorithm makes early terminations at different elements (intra modes) for different CUs. Sometimes, it will select the early element and sometimes it will select the latter element. The proposed model makes the early termination decision using (
8) and if this condition is not successful then HEVC normal working continues. Therefore, the time consumed in decision-making will be the time consumed by (
8). The time consumed by (
8) for full search is
seconds on average.
Finally, we conducted an experiment that is presented in
Table 6.
Table 6 shows that around 52.11% of the modes are skipped by the proposed algorithm. This percentage is obtained with the help of two variables; one variable (e.g.,
T) notes the number of modes shortlisted for the current block and another variable (e.g.,
S) records how many modes were remaining when early termination took place. Finally, the percentage is obtained by computing
.
Table 6 presents this percentage for each QP, separately.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}