
DGG: A Novel Framework for Crowd Gathering Detection


Abstract
:1. Introduction
- DGG, a novel framework is proposed to solve the crowd gathering detection problem, which tries to find the gathering action in complex environments with the help of the inner feature of the crowd.
- The DCFG and the GAD are proposed as the global and local crowd gathering feature extractors, which are used to detect the candidate frame and the gathering area in a video frame.
- To detect the gathering action, the GJ is designed to analyze the statistical feature of the crowd and it can obtain a stable pattern for gathering action. This statistical pattern can be used to find the crowd gathering action in a complex scene.
2. Related Work
2.1. The Image Processing-Based Methods
2.2. The Deep-Learning-Based Methods
3. Overview of the DGG
4. The Details of the Proposed DGG
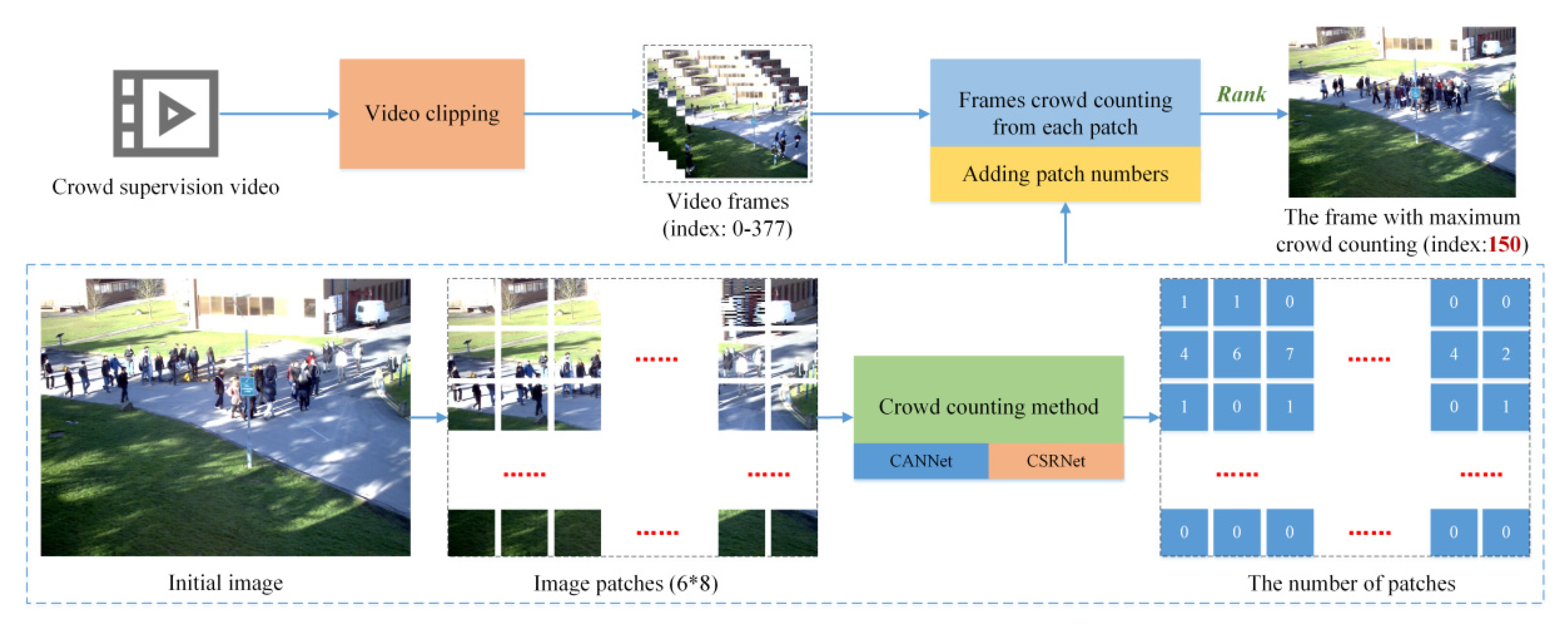
4.1. The Detecting Candidate Frame of Gathering (DCFG)
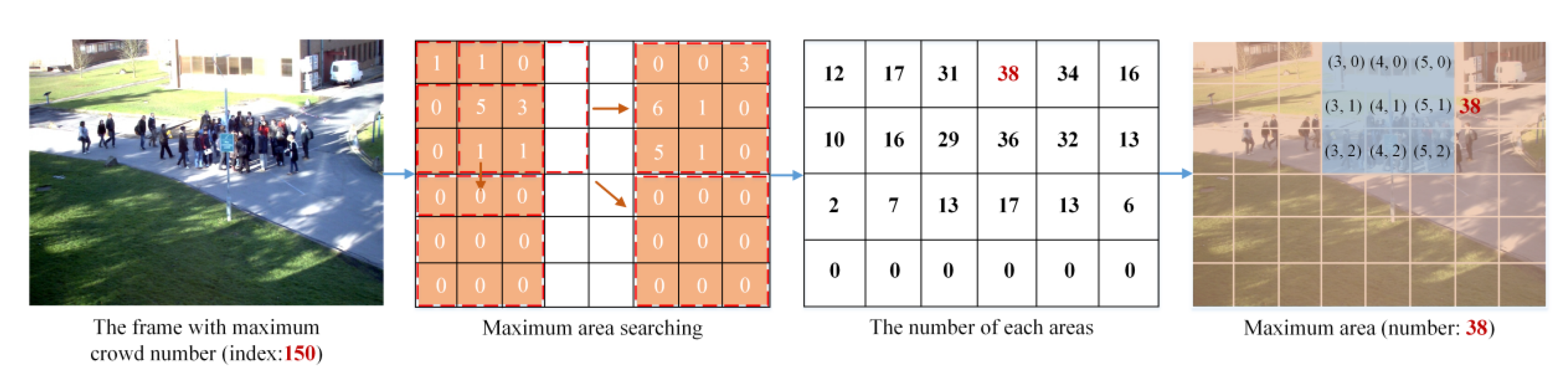
4.2. The Gathering Area Detection (GAD)
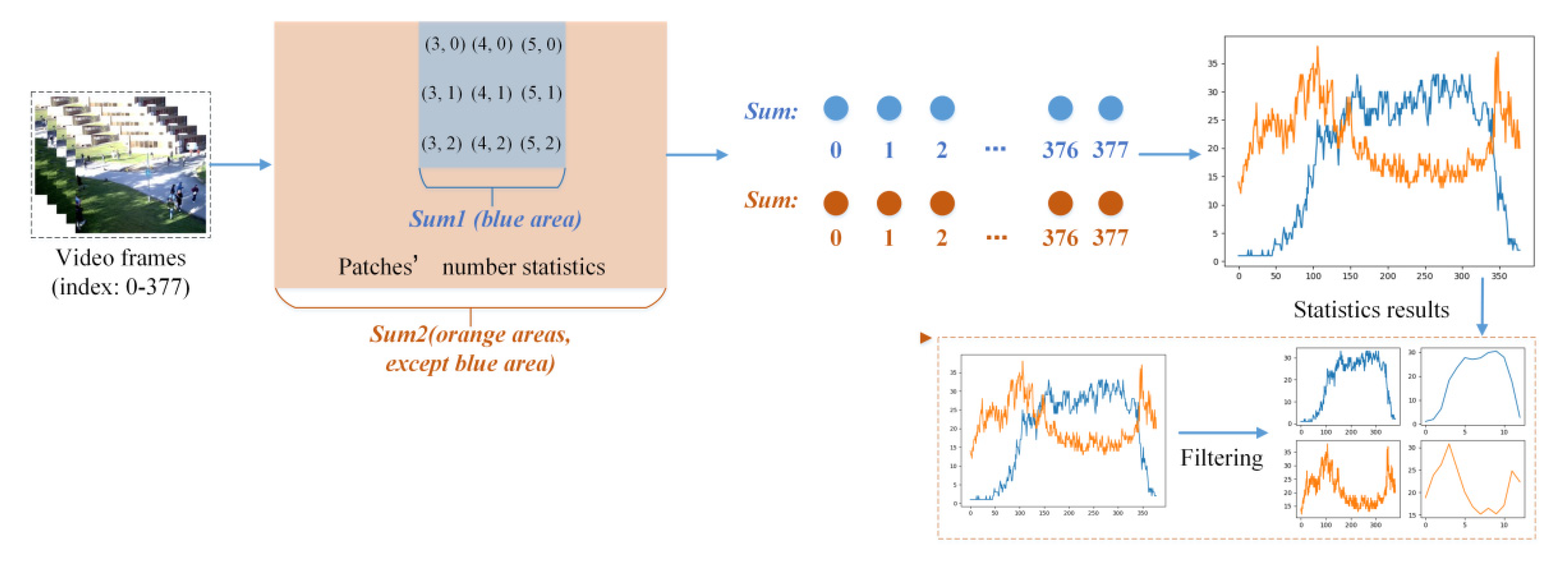
4.3. The Gathering Judgement (GJ)
5. Experiments
5.1. The Dataset for Evaluation
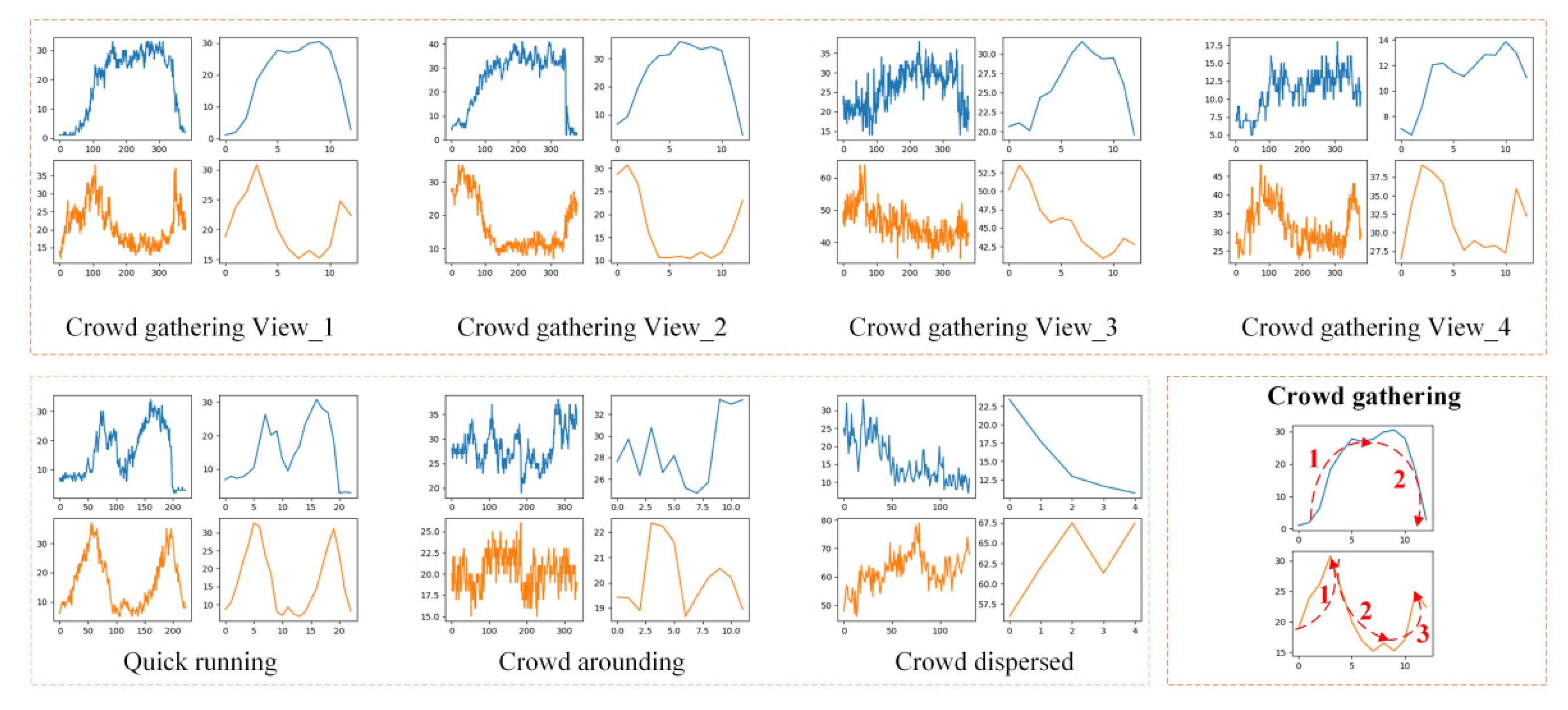
5.2. The Results of the Abnormal Action Statistical Analyses
5.3. The Performances of the Proposed Method
5.4. Ablation Studies and Extreme Conditions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Swathi, H.Y.; Shivakumar, G.; Mohana, H.S. Crowd behavior analysis: A survey. In Proceedings of the 2017 International Conference on Recent Advances in Electronics and Communication Technology (ICRAECT), Bangalore, India, 16–17 March 2017; pp. 169–178. [Google Scholar]
- Li, T.; Chang, H.; Wang, M.; Ni, B.; Hong, R.; Yan, S. Crowded scene analysis: A survey. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 367–386. [Google Scholar] [CrossRef] [Green Version]
- Hsu, W.; Wang, Y.; Lin, C. Abnormal crowd event detection based on outlier in time series. In Proceedings of the 2014 International Conference on Machine Learning and Cybernetics (ICMLC), Lanzhou, China, 13–16 July 2014; pp. 359–363. [Google Scholar]
- Yang, D.; Liu, C.; Liao, W.; Ruan, S. Crowd gathering and commotion detection based on the stillness and motion model. Multimed. Tools Appl. 2020, 79, 19435–19449. [Google Scholar] [CrossRef]
- Liu, C.; Liao, W.; Ruan, S. Crowd gathering detection based on the foreground stillness model. IEICE Trans. Inf. Syst. 2018, 101, 1968–1971. [Google Scholar] [CrossRef] [Green Version]
- Alqaysi, H.; Sasi, S. Detection of abnormal behavior in dynamic crowded gatherings. In Proceedings of the 2013 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 23–25 October 2013; pp. 1–6. [Google Scholar]
- Sang, H.; Chen, Y.; He, D. Crowd gathering and running behavior detection based on overall features. J. Optoelectron. Laser. 2016, 27, 52–60. [Google Scholar]
- Xiong, G.; Wu, X.; Chen, Y.; Ou, Y. Abnormal crowd behavior detection based on the energy model. In Proceedings of the 2011 IEEE International Conference on Information and Automation (ICIA), Shenzhen, China, 6–8 June 2011; pp. 495–500. [Google Scholar]
- Xiong, G.; Cheng, J.; Wu, X.; Chen, Y.; Ou, Y.; Xu, Y. An energy model approach to people counting for abnormal crowd behavior detection. Neurocomputing 2012, 83, 121–135. [Google Scholar] [CrossRef]
- Moria, K.; Albu, A.; Wu, K. Computer vision-based detection of violent individual actions witnessed by crowds. In Proceedings of the 2016 Conference on Computer and Robot Vision (CRV), Victoria, BC, Canada, 1–3 June 2016; pp. 303–310. [Google Scholar]
- Liu, S.; Xue, H.; Xu, C.; Fang, K. Abnormal behavior detection based on the motion-changed rules. In Proceedings of the 2020 IEEE International Conference on Signal Processing (ICSP), Beijing, China, 6–9 December 2020; pp. 146–149. [Google Scholar]
- Chondro, P.; Liu, C.; Chen, C.; Ruan, S. Detecting abnormal massive crowd flows: Characterizing fleeing en masse by analyzing the acceleration of object vectors. IEEE Consum. Electron. Mag. 2019, 8, 32–37. [Google Scholar] [CrossRef]
- Fradi, H.; Dugelay, J. Spatial and temporal variations of feature tracks for crowd behavior analysis. J. Multimodal User Interfaces 2016, 10, 307–317. [Google Scholar] [CrossRef]
- Phule, S.; Sawant, S. Abnormal activities detection for security purpose unattainded bag and crowding detection by using image processing. In Proceedings of the 2017 International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 15–16 June 2017; pp. 1069–1073. [Google Scholar]
- Liao, H.; Xiang, J.; Sun, W.; Feng, Q.; Dai, J. An abnormal event recognition in crowd scene. In Proceedings of the 2011 International Conference on Image and Graphics (ICIG), Anhui, China, 12–15 August 2011; pp. 731–736. [Google Scholar]
- Xie, S.; Zhang, X.; Cai, J. Video crowd detection and abnormal behavior model detection based on machine learning method. Neural Comput. Appl. 2018, 31, 175–184. [Google Scholar] [CrossRef]
- Zhao, H.; Min, W.; Xu, J.; Han, Q.; Wang, Q.; Yang, Z.; Zhou, L. SPACE: Finding key-speaker in complex multi-person scenes. IEEE Trans. Emerg. Topics Comput. 2021. [Google Scholar] [CrossRef]
- Zhao, H.; Min, W.; Xu, J.; Wang, Q.; Zou, Y.; Fu, Q. Scene-adaptive crowd counting method based on meta learning with dual-input network DMNet. Front. Comput. Sci. 2021. [Google Scholar] [CrossRef]
- Wang, Q.; Min, W.; Han, Q.; Liu, Q.; Zha, C.; Zhao, H.; Wei, Z. Inter-domain adaptation label for data augmentation in vehicle re-identification. IEEE Trans. Multimed. 2021. [Google Scholar] [CrossRef]
- Tay, N.; Tee, C.; Ong, T.; Teh, P. Abnormal behavior recognition using CNN-LSTM with attention mechanism. In Proceedings of the 2019 International Conference on Electrical, Control and Instrumentation Engineering (ICECIE), Kuala Lumpur, Malaysia, 25–25 November 2019; pp. 1–5. [Google Scholar]
- Cao, B.; Xia, H.; Liu, Z. A video abnormal behavior recognition algorithm based on deep learning. In Proceedings of the 2021 Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 18–20 June 2021; pp. 755–759. [Google Scholar]
- Bai, L.; Wu, C.; Xie, F.; Wang, Y. Crowd density detection method based on crowd gathering mode and multi-column convolutional neural network. Image Vis. Comput. 2021, 105, 104084. [Google Scholar] [CrossRef]
- Gupta, T.; Nunavath, V.; Roy, S. CrowdVAS-net: A deep-CNN based framework to detect abnormal crowd-motion behavior in videos for predicting crowd disaster. In Proceedings of the 2019 international conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 2877–2882. [Google Scholar]
- Xu, Y.; Lu, L.; Xu, Z.; He, J.; Zhou, J.; Zhang, C. Dual-channel CNN for efficient abnormal behavior identification through crowd feature engineering. Mach. Vis. Appl. 2019, 30, 945–958. [Google Scholar] [CrossRef] [Green Version]
- Gao, Z.; Wang, Y.; Liu, X.; Li, T.; Li, B.; He, J. On the analysis of multi-point crowd gathering in designated areas. In Proceedings of the 2019 International Conference on Intelligent Computing, Automation and Systems (ICICAS), Chongqing, China, 6–8 December 2019; pp. 344–349. [Google Scholar]
- Zhao, R.; Liu, Q.; Li, C.; Dong, D.; Hu, Q.; Ma, Y. Fuzzy neural network based scenario features extraction and mapping model for crowd evacuation stability analysis. In Proceedings of the 2018 International Seminar on Computer Science and Engineering Technology (SCSET), Shanghai, China, 17–19 December 2018; p. 032022. [Google Scholar]
- Liu, S.; Xie, K. Research on crowd gathering risk identification based on cell sensor and face recognition. In Proceedings of the 2015 International Conference on Industrial Informatics-Computing Technology, Intelligent Technology, Industrial Information Integration, Wuhan, China, 3–4 December 2015; pp. 201–204. [Google Scholar]
- Zhao, M.; Zhang, C.; Zhang, J.; Porikli, F.; Ni, B.; Zhang, W. Scale-aware crowd counting via depth-embedded convolutional neural networks. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3651–3662. [Google Scholar] [CrossRef]
- Sam, D.; Peri, S.; Sundararaman, M.; Kamath, A.; Radhakrishnan, V. Locate, size and count: Accurately resolving people in dense crowds via detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2739–2751. [Google Scholar]
- Wu, X.; Zheng, Y.; Ye, H.; Hu, W.; Ma, T.; Yang, J.; He, L. Counting crowds with varying densities via adaptive scenario discovery framework. Neurocomputing 2020, 397, 127–138. [Google Scholar] [CrossRef]
- Zheng, H.; Lin, Z.; Cen, J.; Wu, Z.; Zhao, Y. Cross-line pedestrian counting based on spatially-consistent Two-stage local crowd density estimation and accumulation. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 787–799. [Google Scholar] [CrossRef]
- Yang, B.; Zhan, W.; Wang, N.; Liu, X.; Lv, J. Counting crowds using a scale-distribution-aware network and adaptive human-shaped kernel. Neurocomputing 2020, 390, 207–216. [Google Scholar] [CrossRef]
- Zou, Z.; Cheng, Y.; Qu, X.; Ji, S.; Guo, X.; Zhou, P. Attend to count crowd counting with adaptive capacity multi-scale CNNs. Neurocomputing 2019, 367, 75–83. [Google Scholar] [CrossRef] [Green Version]
- Jiang, S.; Lu, X.; Lei, Y.; Liu, L. Mask-aware networks for crowd counting. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3119–3129. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Wen, Q.; Chen, H.; Liu, W.; He, S. Crowd counting via cross-stage refinement Networks. IEEE Trans. Image Process 2020, 29, 6800–6812. [Google Scholar] [CrossRef]
- Liu, W.; Salzmann, M.; Fua, P. Context-aware crowd counting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5094–5103. [Google Scholar]
- Li, Y.; Zhang, X.; Chen, D. CSRNet: Dilated convolutional neural networks for understanding the highly congested scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1091–1100. [Google Scholar]
- Ferryman, J.; Shahrokni, A. PETS2009: Dataset and challenge. In Proceedings of the 12th IEEE International Workshop on Performance Evaluation of Tracking and Surveillance (W PETS), Snowbird, UT, USA, 7–9 December 2009; pp. 1–6. [Google Scholar]
- Guan, Y.; Hu, W.; Hu, X. Abnormal behavior recognition using 3D-CNN combined with LSTM. Multimed. Tools Appl. 2021, 80, 18787–18801. [Google Scholar] [CrossRef]
- Xu, F.; Rao, Y.; Wang, Q. An unsupervised abnormal crowd behavior detection algorithm. In Proceedings of the 2017 International Conference on Security, Pattern Analysis, and Cybernetics (SPAC), Shenzhen, China, 15–17 December 2017; pp. 219–223. [Google Scholar]
- Gu, X.; Cui, J.; Zhu, Q. Abnormal crowd behavior detection by using the particle entropy. Optik 2014, 125, 3428–3433. [Google Scholar] [CrossRef]
- Zhang, Q.; Nie, Y.; Zheng, W. Dual illumination estimation for robust exposure correction. Comput. Graph. 2019, 38, 243–252. [Google Scholar] [CrossRef] [Green Version]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-light image enhancement via illumination map estimation. IEEE Trans. Image Process 2017, 26, 982–993. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Inner-Feature of Crowd | Fitting in Complex Scenes | Robustness |
|---|---|---|---|
| [4] | √ | × | × |
| [5] | √ | × | × |
| [11] | √ | √ | × |
| [13] | × | √ | × |
| [21] | × | √ | √ |
| [23] | × | × | √ |
| [24] | × | √ | × |
| [25] | × | √ | √ |
| DGG | √ | √ | √ |
| View | TP | TN | FP | FN | TPR | FPR | ACC | Recall | Precision | F1 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 213 | 154 | 5 | 6 | 97.26% | 3.14% | 97.09% | 97.26% | 97.71% | 97.48% |
| 2 | 216 | 151 | 4 | 7 | 96.86% | 2.58% | 97.09% | 96.86% | 98.18% | 97.52% |
| 3 | 214 | 140 | 16 | 8 | 96.40% | 10.26% | 93.65% | 96.40% | 93.04% | 94.69% |
| 4 | 200 | 151 | 0 | 27 | 88.11% | 0 | 92.86% | 88.11% | 1 | 93.68% |
| ACC | |||||
|---|---|---|---|---|---|
| Methods | View 1 | View 2 | View 3 | View 4 | Average |
| [40] | 84.39% | 82.28% | 68.79% | \ | 78.49% |
| [41] | 82.01% | \ | 77.78% | \ | 79.90% |
| [5] | 89.92% | 91.24% | 87.79% | 85.67% | 88.66% |
| [4] | 93.90% | 94.16% | 88.33% | 87.80% | 91.05% |
| Ours | 97.09% | 97.09% | 93.65% | 92.86% | 95.17% |
| Methods | View 1 | View 2 | View 3 | View 4 |
|---|---|---|---|---|
| DGG-CSRNet | 93.92% | 95.24% | 91.27% | 88.62% |
| DGG-CANNet | 97.09% | 97.09% | 93.65% | 92.86% |
| Methods | Average |
|---|---|
| DGG-Darkness | 72.75% |
| DGG-Illumination-improved | 83.33% |
| DGG-Normal-Illumination | 97.09% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, J.; Zhao, H.; Min, W.; Zou, Y.; Fu, Q. DGG: A Novel Framework for Crowd Gathering Detection. Electronics 2022, 11, 31. https://doi.org/10.3390/electronics11010031
Xu J, Zhao H, Min W, Zou Y, Fu Q. DGG: A Novel Framework for Crowd Gathering Detection. Electronics. 2022; 11(1):31. https://doi.org/10.3390/electronics11010031
Chicago/Turabian StyleXu, Jianqiang, Haoyu Zhao, Weidong Min, Yi Zou, and Qiyan Fu. 2022. "DGG: A Novel Framework for Crowd Gathering Detection" Electronics 11, no. 1: 31. https://doi.org/10.3390/electronics11010031
APA StyleXu, J., Zhao, H., Min, W., Zou, Y., & Fu, Q. (2022). DGG: A Novel Framework for Crowd Gathering Detection. Electronics, 11(1), 31. https://doi.org/10.3390/electronics11010031