
A Two-Stage GAN for High-Resolution Retinal Image Generation and Segmentation

 ,
,  ,
,  ,
,
Abstract
:1. Introduction
2. Related Work
2.1. Synthetic Image Generation
2.2. Image-to-Image Translation
2.3. Retinal Image Synthesis
2.4. Retinal Vessel Segmentation
3. Materials and Methods
3.1. The Benchmark Datasets
- DRIVE dataset—The DRIVE dataset [16] includes 40 retinal fundus images of size (20 images for training and 20 for test). The images were collected by a screening program for diabetic retinopathy in the Netherlands. Among the 40 photographs, 33 showed no diabetic retinopathy, while 7 showed mild early diabetic retinopathy. The segmentation ground-truth was provided both for the training and the test sets.
- CHASE_DB1 dataset—The CHASE_DB1 dataset [17] is composed by 28 fundus images of size , corresponding to the left and right eyes of 14 children. Each image is annotated by two independent human experts. An officially defined split between training and test is not provided for this dataset. In our experiments, we adopted the same strategy as [64,65], selecting the first 20 images for training and the remaining 8 for testing.
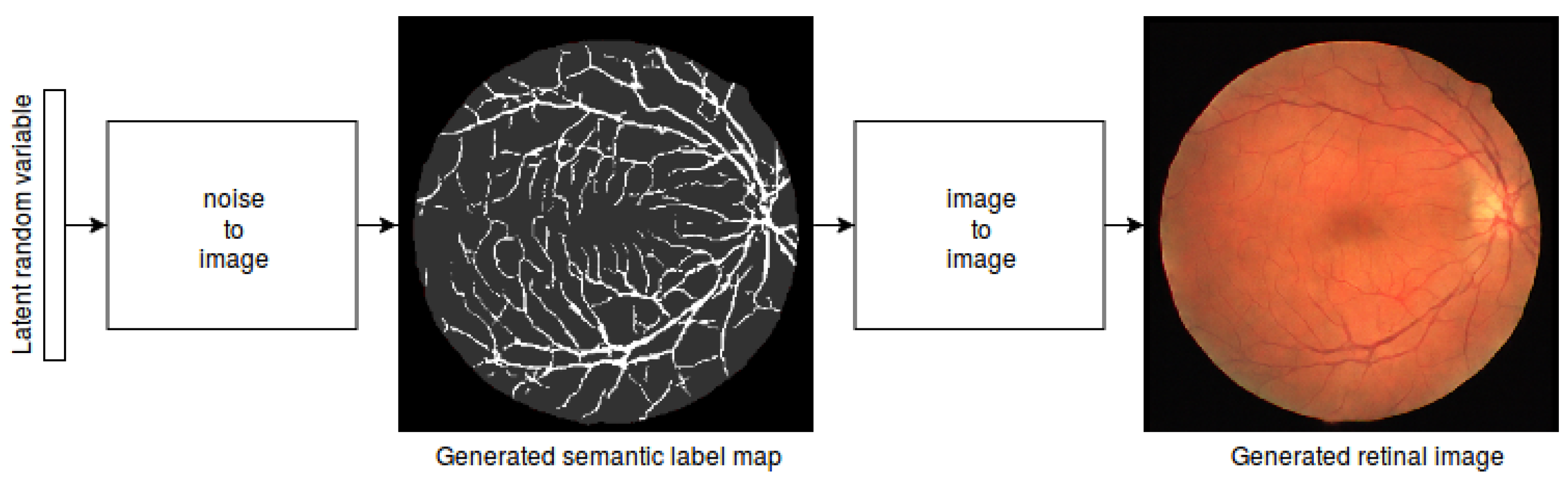
3.2. Vasculature Generation
3.3. Translating Vessel Maps into Retinal Images
3.4. The SMANet Architecture
3.5. Training Details
4. Results and Discussion
- SYNTH—the segmentation network was trained using only the 10,000 generated synthetic images;
- REAL—only real data were used to train the semantic segmentation network;
- SYNTH + REAL—synthetic data were used to pre-train the semantic segmentation network and real data were employed for fine-tuning.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Patton, N.; Aslam, T.M.; MacGillivray, T.; Deary, I.J.; Dhillon, B.; Eikelboom, R.H.; Yogesan, K.; Constable, I.J. Retinal image analysis: Concepts, applications and potential. Prog. Retin. Eye Res. 2006, 25, 99–127. [Google Scholar] [CrossRef] [PubMed]
- Fraz, M.; Remagnino, P.; Hoppe, A.; Uyyanonvara, B.; Rudnicka, A.; Owen, C.; Barman, S. Blood vessel segmentation methodologies in retinal images—A survey. Comput. Methods Programs Biomed. 2012, 108, 407–433. [Google Scholar] [CrossRef]
- Patil, D.D.; Manza, R.R. Design new algorithm for early detection of primary open angle glaucoma using retinal Optic Cup to Disc Ratio. In Proceedings of the 2016 International Conference on Electrical, Electronics, and Optimization Techniques (ICEEOT), Chennai, India, 3–5 March 2016; pp. 148–151. [Google Scholar]
- Bowling, B. Kanski’s Clinical Ophthalmology: A Systematic Approach; Saunders Ltd.: Philadelphia, PA, USA, 2015. [Google Scholar]
- Abràmoff, M.D.; Garvin, M.K.; Sonka, M. Retinal imaging and image analysis. IEEE Rev. Biomed. Eng. 2010, 3, 169–208. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Cheron, G.; Laptev, I.; Schmid, C. P-CNN: Pose-Based CNN Features for Action Recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Huynh, T.C. Vision-based autonomous bolt-looseness detection method for splice connections: Design, lab-scale evaluation, and field application. Autom. Constr. 2021, 124, 103591. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of GANs for Improved Quality, Stability, and Variation. arXiv 2018, arXiv:1710.10196. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Staal, J.; Abràmoff, M.D.; Niemeijer, M.; Viergever, M.A.; van Ginneken, B. Ridge-based vessel segmentation in color images of the retina. IEEE Trans. Med. Imaging 2004, 23, 501–509. [Google Scholar] [CrossRef]
- Fraz, M.M.; Remagnino, P.; Hoppe, A.; Uyyanonvara, B.; Rudnicka, A.R.; Owen, C.G.; Barman, S. An Ensemble Classification-Based Approach Applied to Retinal Blood Vessel Segmentation. IEEE Trans. Biomed. Eng. 2012, 59, 2538–2548. [Google Scholar] [CrossRef]
- Bonechi, S.; Bianchini, M.; Scarselli, F.; Andreini, P. Weak supervision for generating pixel–level annotations in scene text segmentation. Pattern Recognit. Lett. 2020, 138, 1–7. [Google Scholar] [CrossRef]
- Sekou, T.B.; Hidane, M.; Olivier, J.; Cardot, H. From Patch to Image Segmentation using Fully Convolutional Networks—Application to Retinal Images. arXiv 2019, arXiv:1904.03892. [Google Scholar]
- Richter, S.R.; Vineet, V.; Roth, S.; Koltun, V. Playing for data: Ground truth from computer games. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 102–118. [Google Scholar]
- Ros, G.; Sellart, L.; Materzynska, J.; Vazquez, D.; Lopez, A.M. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3234–3243. [Google Scholar]
- Hodan, T.; Vineet, V.; Gal, R.; Shalev, E.; Hanzelka, J.; Connell, T.; Urbina, P.; Sinha, S.N.; Guenter, B. Photorealistic Image Synthesis for Object Instance Detection. arXiv 2019, arXiv:1902.03334. [Google Scholar]
- Collins, D.L.; Zijdenbos, A.P.; Kollokian, V.; Sled, J.G.; Kabani, N.J.; Holmes, C.J.; Evans, A.C. Design and construction of a realistic digital brain phantom. IEEE Trans. Med. Imaging 1998, 17, 463–468. [Google Scholar] [CrossRef]
- Andreini, P.; Bonechi, S.; Bianchini, M.; Mecocci, A.; Scarselli, F. A Deep Learning Approach to Bacterial Colony Segmentation. In Proceedings of the International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; pp. 522–533. [Google Scholar]
- Andreini, P.; Bonechi, S.; Bianchini, M.; Mecocci, A.; Scarselli, F. Image generation by GAN and style transfer for agar plate image segmentation. Comput. Methods Programs Biomed. 2020, 184, 105268. [Google Scholar] [CrossRef] [PubMed]
- Kugelman, J.; Alonso-Caneiro, D.; Read, S.A.; Vincent, S.J.; Chen, F.K.; Collins, M.J. Data augmentation for patch-based OCT chorio-retinal segmentation using generative adversarial networks. Neural Comput. Appl. 2021, 33, 7393–7408. [Google Scholar] [CrossRef]
- Waheed, A.; Goyal, M.; Gupta, D.; Khanna, A.; Al-Turjman, F.; Pinheiro, P.R. Covidgan: Data augmentation using auxiliary classifier gan for improved covid-19 detection. IEEE Access 2020, 8, 91916–91923. [Google Scholar] [CrossRef] [PubMed]
- Shin, H.C.; Tenenholtz, N.A.; Rogers, J.K.; Schwarz, C.G.; Senjem, M.L.; Gunter, J.L.; Andriole, K.P.; Michalski, M. Medical Image Synthesis for Data Augmentation and Anonymization using Generative Adversarial Networks. In Proceedings of the International Workshop on Simulation and Synthesis in Medical Imaging, Granada, Spain, 16 September 2018. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Pathak, D.; Krähenbühl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context Encoders: Feature Learning by Inpainting. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. A neural algorithm of artistic style. arXiv 2015, arXiv:1508.06576. [Google Scholar] [CrossRef]
- Liu, M.Y.; Breuel, T.; Kautz, J. Unsupervised Image-to-Image Translation Networks. arXiv 2017, arXiv:1703.00848. [Google Scholar]
- Liu, M.Y.; Tuzel, O. Coupled Generative Adversarial Networks. In Advances in Neural Information Processing Systems 29; Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2016; pp. 469–477. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. DualGAN: Unsupervised Dual Learning for Image-to-Image Translation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2868–2876. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Chen, Q.; Koltun, V. Photographic Image Synthesis with Cascaded Refinement Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1520–1529. [Google Scholar]
- Sagar, M.; Bullivant, D.P.; Mallinson, G.D.; Hunter, P.J. A virtual environment and model of the eye for surgical simulation. In Proceedings of the 21st Annual Conference on Computer Graphics and Interactive Techniques (SIGGRAPH), Orlando, FL, USA, 24–29 July 1994. [Google Scholar]
- Fiorini, S.; Biasi, M.D.; Ballerini, L.; Trucco, E.; Ruggeri, A. Automatic Generation of Synthetic Retinal Fundus Images. In Smart Tools and Apps for Graphics—Eurographics Italian Chapter Conference; Giachetti, A., Ed.; The Eurographics Association: Cagliari, Italy, 2014. [Google Scholar] [CrossRef]
- Menti, E.; Bonaldi, L.; Ballerini, L.; Ruggeri, A.; Trucco, E. Automatic Generation of Synthetic Retinal Fundus Images: Vascular Network. In Simulation and Synthesis in Medical Imaging; Tsaftaris, S.A., Gooya, A., Frangi, A.F., Prince, J.L., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 167–176. [Google Scholar]
- Costa, P.; Galdran, A.; Meyer, M.I.; Abramoff, M.D.; Niemeijer, M.; Mendonça, A.M.; Campilho, A. Towards adversarial retinal image synthesis. arXiv 2017, arXiv:1701.08974. [Google Scholar]
- Zhao, H.; Li, H.; Maurer-Stroh, S.; Cheng, L. Synthesizing retinal and neuronal images with generative adversarial nets. Med. Image Anal. 2018, 49, 14–26. [Google Scholar] [CrossRef] [PubMed]
- Costa, P.; Galdran, A.; Meyer, M.I.; Niemeijer, M.; Abràmoff, M.; Mendonça, A.M.; Campilho, A. End-to-End Adversarial Retinal Image Synthesis. IEEE Trans. Med. Imaging 2018, 37, 781–791. [Google Scholar] [CrossRef] [PubMed]
- Beers, A.; Brown, J.M.; Chang, K.; Campbell, J.P.; Ostmo, S.; Chiang, M.F.; Kalpathy-Cramer, J. High-resolution medical image synthesis using progressively grown generative adversarial networks. arXiv 2018, arXiv:1805.03144. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015. [Google Scholar]
- Liu, I.; Sun, Y. Recursive tracking of vascular networks in angiograms based on the detection-deletion scheme. IEEE Trans. Med. Imaging 1993, 12, 334–341. [Google Scholar] [CrossRef]
- Yin, Y.; Adel, M.; Bourennane, S. Retinal vessel segmentation using a probabilistic tracking method. Pattern Recognit. 2012, 45, 1235–1244. [Google Scholar] [CrossRef]
- Hoover, A.D.; Kouznetsova, V.; Goldbaum, M. Locating blood vessels in retinal images by piecewise threshold probing of a matched filter response. IEEE Trans. Med. Imaging 2000, 19, 203–210. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Roychowdhury, S.; Koozekanani, D.D.; Parhi, K.K. Iterative Vessel Segmentation of Fundus Images. IEEE Trans. Biomed. Eng. 2015, 62, 1738–1749. [Google Scholar] [CrossRef]
- Neto, L.C.; Ramalho, G.L.; Neto, J.F.R.; Veras, R.M.; Medeiros, F.N. An unsupervised coarse-to-fine algorithm for blood vessel segmentation in fundus images. Expert Syst. Appl. 2017, 78, 182–192. [Google Scholar] [CrossRef]
- Zhao, Y.; Rada, L.; Chen, K.; Harding, S.P.; Zheng, Y. Automated Vessel Segmentation Using Infinite Perimeter Active Contour Model with Hybrid Region Information with Application to Retinal Images. IEEE Trans. Med. Imaging 2015, 34, 1797–1807. [Google Scholar] [CrossRef] [Green Version]
- Khan, K.B.; Siddique, M.S.; Ahmad, M.; Mazzara, M. A hybrid unsupervised approach for retinal vessel segmentation. BioMed Res. Int. 2020, 2020, 8365783. [Google Scholar] [CrossRef]
- Liu, B.; Gu, L.; Lu, F. Unsupervised ensemble strategy for retinal vessel segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; pp. 111–119. [Google Scholar]
- Khawaja, A.; Khan, T.M.; Khan, M.A.; Nawaz, S.J. A multi-scale directional line detector for retinal vessel segmentation. Sensors 2019, 19, 4949. [Google Scholar] [CrossRef] [Green Version]
- Shah, S.A.A.; Shahzad, A.; Khan, M.A.; Lu, C.K.; Tang, T.B. Unsupervised method for retinal vessel segmentation based on gabor wavelet and multiscale line detector. IEEE Access 2019, 7, 167221–167228. [Google Scholar] [CrossRef]
- Niemeijer, M.; Staal, J.; van Ginneken, B.; Loog, M.; Abramoff, M.D. Comparative study of retinal vessel segmentation methods on a new publicly available database. In Proceedings of the Medical Imaging 2004: Image Processing, San Diego, CA, USA, 16–19 February 2004; Volume 5370, pp. 2672–2680. [Google Scholar] [CrossRef]
- Soares, J.V.B.; Leandro, J.J.G.; Cesar, R.M.; Jelinek, H.F.; Cree, M.J. Retinal vessel segmentation using the 2-D Gabor wavelet and supervised classification. IEEE Trans. Med. Imaging 2006, 25, 1214–1222. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Toptaş, B.; Hanbay, D. Retinal blood vessel segmentation using pixel-based feature vector. Biomed. Signal Process. Control 2021, 70, 103053. [Google Scholar] [CrossRef]
- Liskowski, P.; Krawiec, K. Segmenting Retinal Blood Vessels with Deep Neural Networks. IEEE Trans. Med. Imaging 2016, 35, 2369–2380. [Google Scholar] [CrossRef] [PubMed]
- Hajabdollahi, M.; Esfandiarpoor, R.; Najarian, K.; Karimi, N.; Samavi, S.; Reza-Soroushmeh, S. Low complexity convolutional neural network for vessel segmentation in portable retinal diagnostic devices. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 2785–2789. [Google Scholar]
- Jiang, Z.; Zhang, H.; Wang, Y.; Ko, S.B. Retinal blood vessel segmentation using fully convolutional network with transfer learning. Comput. Med. Imaging Graph. 2018, 68, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Dasgupta, A.; Singh, S. A fully convolutional neural network based structured prediction approach towards the retinal vessel segmentation. In Proceedings of the 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017), Melbourne, Australia, 18–21 April 2017; pp. 248–251. [Google Scholar] [CrossRef] [Green Version]
- Feng, Z.; Yang, J.; Yao, L. Patch-based fully convolutional neural network with skip connections for retinal blood vessel segmentation. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 1742–1746. [Google Scholar]
- Li, Q.; Feng, B.; Xie, L.; Liang, P.; Zhang, H.; Wang, T. A Cross-Modality Learning Approach for Vessel Segmentation in Retinal Images. IEEE Trans. Med. Imaging 2016, 35, 109–118. [Google Scholar] [CrossRef] [PubMed]
- Yan, Z.; Yang, X.; Cheng, K.T.T. Joint Segment-Level and Pixel-Wise Losses for Deep Learning Based Retinal Vessel Segmentation. IEEE Trans. Biomed. Eng. 2018, 65, 1912–1923. [Google Scholar] [CrossRef] [PubMed]
- Xie, S.; Tu, Z. Holistically-Nested Edge Detection. Int. J. Comput. Vis. 2017, 125, 3–18. [Google Scholar] [CrossRef]
- Fu, H.; Xu, Y.; Wong, D.W.K.; Liu, J. Retinal vessel segmentation via deep learning network and fully-connected conditional random fields. In Proceedings of the 2016 IEEE 13th International Symposium on Biomedical Imaging (ISBI), Prague, Czech Republic, 13–16 April 2016; pp. 698–701. [Google Scholar]
- Liu, S.; Deng, W. Very deep convolutional neural network based image classification using small training sample size. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 730–734. [Google Scholar] [CrossRef]
- Mo, J.; Zhang, L. Multi-level deep supervised networks for retinal vessel segmentation. Int. J. Comput. Assist. Radiol. Surg. 2017, 12, 2181–2193. [Google Scholar] [CrossRef] [PubMed]
- Maninis, K.; Pont-Tuset, J.; Arbeláez, P.; Gool, L.V. Deep Retinal Image Understanding. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Athens, Greece, 17–21 October 2016. [Google Scholar]
- Oliveira, A.; Pereira, S.; Silva, C.A. Retinal vessel segmentation based on Fully Convolutional Neural Networks. Expert Syst. Appl. 2018, 112, 229–242. [Google Scholar] [CrossRef] [Green Version]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved Training of Wasserstein GANs. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; pp. 5769–5779. [Google Scholar]
- Serra, J. Image Analysis and Mathematical Morphology; Academic Press, Inc.: Orlando, FL, USA, 1983. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Papandreou, G.; Kokkinos, I.; Savalle, P.A. Untangling local and global deformations in deep convolutional networks for image classification and sliding window detection. arXiv 2014, arXiv:1412.0296. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Shmelkov, K.; Schmid, C.; Alahari, K. How Good Is My GAN? In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Gen. Vessels | Max Res. | Samples |
|---|---|---|---|
| [41] | No | 614 | |
| [42] | No | 10–20 | |
| [43] | Yes | 634 | |
| [44] | Yes | 5550 | |
| Our | Yes | 20 |
| Methods | AUC | Acc |
|---|---|---|
| SYNTH | 98.5% | 96.88% |
| REAL | 98.48% | 96.87% |
| SYNTH + REAL | 98.65% | 96.9% |
| Methods | AUC | Acc |
|---|---|---|
| SYNTH | 98.64% | 97.49% |
| REAL | 98.82% | 97.5% |
| SYNTH + REAL | 99.16% | 97.72% |
| Methods | AUC | Acc |
|---|---|---|
| SYNTH | 93.49% | 91.01% |
| REAL | 98.48% | 96.87% |
| SYNTH + REAL | 98.57% | 96.88% |
| Methods | AUC | Acc |
|---|---|---|
| SYNTH | 66.96% | 92.62% |
| REAL | 98.82% | 97.5% |
| SYNTH + REAL | 98.87% | 97.65% |
| Methods | AUC | Acc |
|---|---|---|
| One-Step (S) | 93.49% | 91.01% |
| Two-Step (S) | 98.5% | 96.88% |
| One-Step (S + R) | 98.57% | 96.88% |
| Two-Step (S + R) | 98.65% | 96.90% |
| Methods | AUC | Acc |
|---|---|---|
| One-Step (S) | 66.96% | 92.62% |
| Two-Step (S) | 98.64% | 97.49% |
| One-Step (S + R) | 98.87% | 97.65% |
| Two-Step (S + R) | 99.16% | 97.72% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Andreini, P.; Ciano, G.; Bonechi, S.; Graziani, C.; Lachi, V.; Mecocci, A.; Sodi, A.; Scarselli, F.; Bianchini, M. A Two-Stage GAN for High-Resolution Retinal Image Generation and Segmentation. Electronics 2022, 11, 60. https://doi.org/10.3390/electronics11010060
Andreini P, Ciano G, Bonechi S, Graziani C, Lachi V, Mecocci A, Sodi A, Scarselli F, Bianchini M. A Two-Stage GAN for High-Resolution Retinal Image Generation and Segmentation. Electronics. 2022; 11(1):60. https://doi.org/10.3390/electronics11010060
Chicago/Turabian StyleAndreini, Paolo, Giorgio Ciano, Simone Bonechi, Caterina Graziani, Veronica Lachi, Alessandro Mecocci, Andrea Sodi, Franco Scarselli, and Monica Bianchini. 2022. "A Two-Stage GAN for High-Resolution Retinal Image Generation and Segmentation" Electronics 11, no. 1: 60. https://doi.org/10.3390/electronics11010060
APA StyleAndreini, P., Ciano, G., Bonechi, S., Graziani, C., Lachi, V., Mecocci, A., Sodi, A., Scarselli, F., & Bianchini, M. (2022). A Two-Stage GAN for High-Resolution Retinal Image Generation and Segmentation. Electronics, 11(1), 60. https://doi.org/10.3390/electronics11010060