1. Introduction
Generating trajectories for 3D objects is a fundamental problem in areas of robotics, image processing, and others. There are few mathematical algorithms for the interpolation of points that use vector calculus, quaternions, dual-quaternions, and linear algebra. Geometric algebra is a powerful mathematical framework for solving problems using basic geometry entities (circles, points, spheres, planes, and lines), and can represent Euclidean geometry, quaternions, and dual-quaternions. For this reason, it can be used for interpolating geometric entities for applications in medical robotics, graphic engineering, robotics, and aeronautics.
In screw theory, Chasles’ theorem states that a general displacement can be represented using a screw motion (cylindrical helix). Screw theory is widely used in mechanics and robotics and linear interpolation is the simple manner for interpolation; however, screw theory allows many other forms of interpolation, such as Bézier curves [
1] or three-point quadratic. The pure rotation interpolation reduces exactly to the rotor or quaternionic SO(3) Lie group interpolation. In this paper, we propose the Study quadratic interpolation using the motor algebra for the SE(3) Lie group; a sub-algebra of the conformal geometric algebra.
This work focuses on the reformulation of the quadric Study interpolation method in conformal geometric algebra. The work shows that the speed up of the quadratic interpolation using GPU improves the algorithm’s performance significantly. These results are not surprising, since the replacement of matrices with geometric algebra formulations are known to be superior in numerical stability and performance; also, using GPU hardware is generally faster than CPUs.
The contribution of this work is as follows:
Formulation of the quadratic interpolation algorithm using motors of conformal geometric algebra as 8D vectors in the Study manifold;
Speeding up the quadratic interpolation algorithm using GPU;
Comparison of fast quadratic interpolation GPU versus CPU;
The interpolation of the motion of geometric objects in conformal geometric algebra;
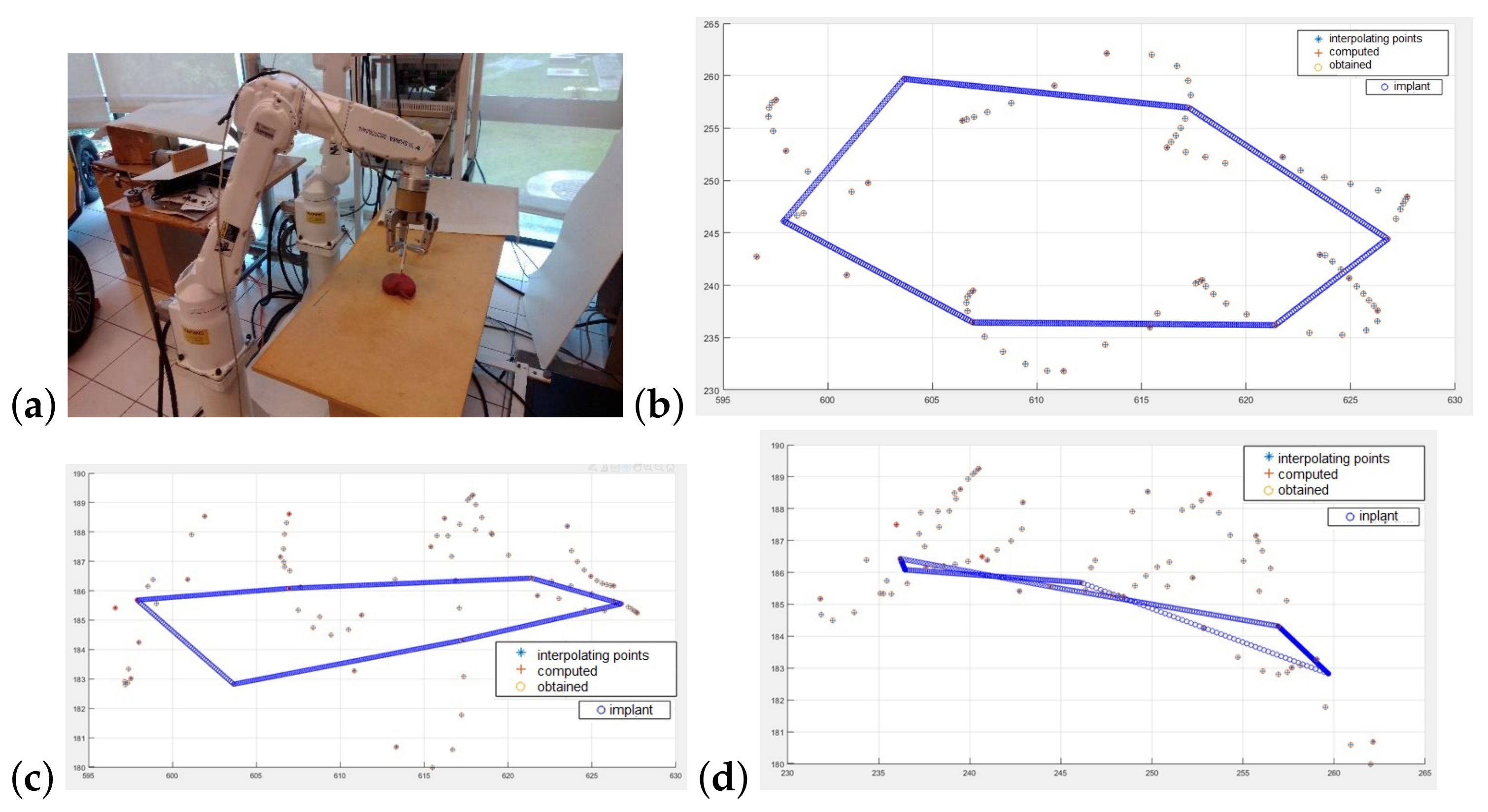
Application of the interpolation algorithm in kidney surgery.
This paper is organized as follows:
Section 2 reports on related work,
Section 3 gives a brief introduction to geometric algebra, with special emphasis on conformal geometric algebra.
Section 4 describe the rigid motion and similitude group interpolation methods.
Section 5 explains the interpolation algorithm using the Study Quadric Manifod.
Section 6 describes the speeding up the algorithms using a GPU accelerator.
Section 7 shows the experimental results.
Section 8 shows an example of interpolation of motion in surgery. Finally,
Section 9 presents our conclusions and future work.
2. Related Work
Due to the easy representation of complex problems in robotics and image processing, several works have been proposed to accelerate geometric algebra operations. Most related techniques for accelerating geometric algebra algorithms are based on speeding up basic operations (inner, outer and geometric product, etc.) with FPGA Co-processors [
2,
3,
4,
5] and GPU parallelization [
6,
7].
More complex architectures have been developed for applications on computational vision. In [
8], the authors present an algorithm of Clifford convolution and Clifford Fourier transforms for color edge detection, and an alternative algorithm based on rotor edge detection is proposed in [
9]. Gerardo Soria-García et al. introduce an FPGA implementation of a Conformal Geometric Algebra Voting Scheme for Geometric Entities Extraction, such as lines and circles on images of edges [
10].
A GPU implementation for a conformal geometric algebra interpolation application based on GPU is presented in [
11]. The algorithm presented in this work is a modification using motors of the dual-quaternion method to interpolate rotation, translation, and dilation of geometric entities such as points, lines, circles,
, planes, and spheres.
Recently, the following authors have produced highly optimized code for GA algorithms: D. Hildenbrand developed the GAALOP code generator for GA algorithms with optimized output on various CPUs and GPUs [
6,
12]; and Ahmed Eid’ developed the geometric algebra package GMac [
13,
14,
15].
In our work, we focus on the direct implementation of the Study quadric interpolation optimizing the source code for a better execution in the GPU, that is, we reduce the complexity of our source code in order to suit to a computation via the GPU. If a user wants, on top of that, to use code generators like GAALOP or GMac, it would of course reduce the complexity even more.
3. Geometric Algebra
In an
n-dimensional real vector space
, we can introduce an orthonormal basis of vectors
,
for
. This leads to a basis for the entire geometric algebra:
The Geometric Algebra (GA) of the real n-dimensional quadratic vector space is denoted as . In the case of the notation , () denotes the GA of where correspond to the number of basis vectors which square in GA to 1, −1 or 0; that is, , , and , respectively. When a unit vector squares to 0, it is seen as a null vector as in the motor algebra or the point at the origin or at infinity which squares to zero.
In the cases when , or for simplicity, we denote , respectively. If only , we denote .
Definition 1. The geometric product of two vectors a and b is written as and it is expressed as a sum of its symmetric and antisymmetric parts: is a graded linear space:
where the elements of
are referred to as (homogeneous) multivectors of grad
k for
. In the following, for short, elements of
are called vectors. Thus, any
can be uniquely decomposed into a sum
where
.
Furthermore,
is a
-graded algebra in the following sense:
where
Then,
(resp.
) is called the even (resp. the odd) part pf
. Note that, due to Equation (
4),
is a subalgebra of
. Later in this paper, the even subalgebra of
will be denoted by
.
The dimension of is . The multivector basis of has bases for scalars, bivectors, trivectors and k-vectors. A k-blade is either the identity element 1 of (when k = 0 or, when k> 0), it is defined as the wedge product . A linear combination of k-vectors is called a homogeneous multivector.
Consider two homogeneous multivectors
and
of grades
r and
s, respectively. The geometric product of
and
can be written as:
Multivector computing involving inner products is easier if one employs the next equality for the generalized inner product of two blades
, and
:
For
, use the following equation:
and for
From these equations, we can see that the inner product is not commutative for general multivectors.
3.1. Conformal Geometric Algebra
In Conformal Geometric Algebra (CGA), the Euclidean vector space is represented in . The space for has an orthonormal vector basis given by with the properties , , , .
The
null basis (origin and point at infinity) is defined as:
These null vectors satisfy the relations and .
Let
be the Minkowski plane. The unit Euclidean pseudo-scalar is
, and the conformal pseudoscalar
is used for computing the inverse and duals of multivectors. Given a nonsingular
k-vector
, the dual and its inverse are, respectively,
where
stands for the reversion of
A and
its magnitude.
3.2. Points, Lines, Planes, and Spheres
The representation of a 3D Euclidean point
x, y, z
in the geometric algebra
is given by:
According to Equation (
7), given two conformal points
and
, their difference in Euclidean space can be computed as follows:
and, consequently, the following equality:
is fulfilled as well.
The line is formulated as a form in the Inner Product Null Space (IPNS) as follows:
where
n (bivector) is the orientation and the vector
m is the moment of the line.
The plane is formulated as a form in IPNS
where the
n (bivector) for the plane orientation and
d is the distance from origin orthogonal to the plane.
The sphere is formulated as a form in IPNS:
A point is a sphere with zero radius. Considering the dual equation for the sphere, we can write the constraint for a point lying on a sphere:
The sphere can be directly computed by the wedge of four conformal points in the Outer Product Null Space (OPNS):
Replacing any of these points with the point at infinity, we obtain the OPNS plane equation:
Similar to Equation (
20), the OPNS line equation can be formulated as a circle passing through the point at infinity:
see in
Table 1 the summary of the IPNS and OPNS geometric objects.
3.3. Rigid Transformations
In CGA many of the transformations can be formulated in terms of successive reflections between planes.
3.3.1. Reflection
The equation of a point
x reflected with respect to a plane
is:
3.3.2. Translation
The transformation of geometric entity
O formulated as two successive reflections w.r.t. the parallel planes
and
is given by:
where
,
d is the distance of translation, and
n is the direction of translation.
3.3.3. Rotation
Similarly, we can formulate a rotation as the product of two reflections between non-parallel planes
and
which cross the origin.
The geometric product of the unit normal vectors of these planes
and
yields the equation for the rotor:
where the unit bivector
, and the angle
is twice the angle between
and
.
3.3.4. Screw Motion
The operator for screw motion or motor
M is a composition of a translator
T and a rotor
R, both w.r.t. to an arbitrary axis
L. The equation for a motor is as follows:
where the screw line is
;
n and
m stand for the orientation and momentum of the screw line and the dual angle
. Finally, the motor transformation for any object
reads
4. Rigid Motion and Similitude Group Interpolation
This section presents the motor interpolation. We will use this technique when we interpolate geometric objects like points, lines, planes, circles and spheres.
This is a generalization of the well known Spherical Linear Interpolation (SLERP) method [
16] Given
and
two motors representing the initial and final pose of a rigid body respectively, the Motor Spherical Linear Interpolation function (MSLERP) is defined as follows
with
. The underlying kinematic concept of the screw motion was explained in previous sections. A kinematic explanation of this interpolation method was given by [
16,
17]. Since
represents the finite screw motion between the initial and final pose of the rigid body, specifically the product:
defines a screw motion of a dual angle
along the screw axis
. In this equation,
and
t stand for the rotation angle and the translation bivector, respectively.
The Motor Linear Blending interpolation method (MLB) is defined as follows:
This procedure can be extended to the interpolation involving several poses:
These weights are assumed to be convex, namely
and
. One can choose weights that are made coincident with the coefficients of the classical Lagrange’s interpolating polynomials
Note that Algorithm 1 uses the resulting bivector
B (se(3) Lie algebra) to compute the motor (SE(3) Lie group). To interpolate geometric objects
O in the conformal geometric algebra framework, represented in IPNS, as points in Equation (
12), lines in Equation (
15), planes in Equation (
16) and spheres in Equation (
16), we represent the objects using an IPNS representation and apply the blending interpolated motor
and for spheres a Dilator
as well,
| Algorithm 1 MIB: Motor Iterative Blending. |
procedure (MIB) ()
|
5. Interpolation Algorithm Using the Study Quadric Manifold
According Gfrerrer [
18], one can formulate an interpolation algorithm using the Study’s kinematics mapping.This maps Euclidean rigid transformations into homogeneous points which in turn belong to the Study quadric
(projective space
)
where
is the special Lie group for 3D Euclidean rigid transformations,
represents any Euclidean rigid transformation and the vector
X containing homogeneous coordinates
. Note that the motor algebra
is a sub-algebra of the 3D conformal geometric algebra
, thus the interpolation uses motors, depending upon which algebra is used one can use
I for motors of
or
for motors of
which both square to zero and are acting similarly to the isotropic operator of the dual quaternions, which use
, which squares to zero as well.
Given the set
containing three homogeneous points
, that is, these points lie on a manifold
, which is embedded in the projective space
(
). The interpolation curve is generated by interpolating the given homogeneous points
which satisfy the set
computed as follows
This equation represents a discretization of the curve into N points. i.e., intermediate points are computed.
The interpolation polynomials
,
, and
are formulated as follows
where
t,
,
, and
are interpolation values between 0 and 1.
t represents the segment of curve where the point is calculated,
,
and
are values that represent the section of curve where interpolated and control points meet. The algorithm checks the number of elements in X, if there is only one point, this is returned as the solution, otherwise, X is used to get intermediate control points via Equation (
38) and saved in M. For N control points, we obtain
interpolation points.
The Study-quadric bilinear form is given by the following matrix
,
If one wishes to interpolate more points, the above-explained interpolation equation can be extended and adapted as De Casteljau’s algorithm [
19]. This is shown in Algorithm 2.
This algorithm calculates a homogeneous point for the given set
that contains the control points (
) and the interpolation values (
) and the Study quadric bilinear matrix
. Here
are interpolation variables.
t is the position interval variable and allows us to determine the position within the curve of the interpolation point, the value
t goes from 0 to 1. To calculate all the points of the curve, all the values of
t are traversed.
are values that indicate at which point the interpolation points, in the functions that came in the Klawiter library [
19], the values
, are proposed so that the interpolated points correspond to the initial control point, the mid-control point and the endpoint, respectively. These are fixed for each curve, only
t is what can change when calculating a point within a specific curve. In the algorithm, the triple of the set of points will be selected as follows:
for
.
The algorithm checks the number of elements in
. If there is only one point, this is returned as the solution. Otherwise,
is used to obtain intermediate control points via Equation (
38) and saved in
.
is used to call the algorithm recursively until we get only one interpolation point and return it.
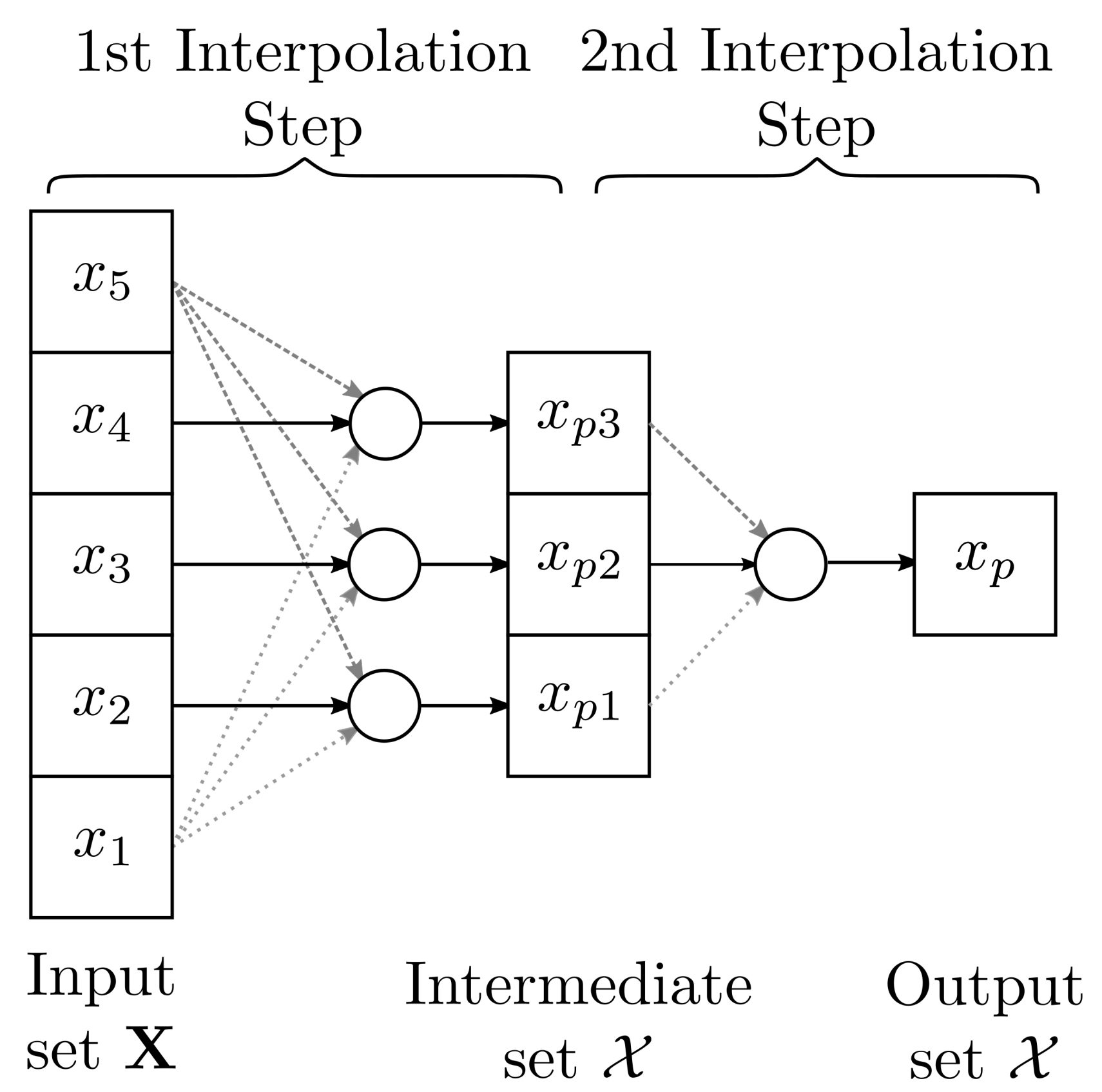
Figure 1 shows the algorithm interpolation for five control points. See that, in each interpolation step, for N control points, we get
interpolation points and
repeats are required. Since in the last step, Equation (
38) required three points, an odd number of control points is needed. \
![Electronics 11 01527 i001]()
Figure 1.
Interpolation of five control points with Algorithm 2.
Figure 1.
Interpolation of five control points with Algorithm 2.
Where
is the set of control homogeneous points (
) that describe the discrete curve trajectory,
is the quadric matrix,
,
, and
are global constant values, in this case, 0,
and 1 respectively. As is seen in the algorithm, it is required that the array X has an odd number of homogeneous points to get an interpolation curve. Note that the solution is in fact a rational motion utilizing an interpolating spline which in turn involves rational sub-spline motions, see [
1].
In general, the Study quadric interpolation algorithm uses homogeneous points represented by dual-quaternions or by homogenous matrices. As we know, motors are isomorphic to dual-quaternions and a motor can be represented as a homogeneous point as well. This motor represented as a vector
lies on the Study Manifold (see
Table 2). In this regard, we propose a modified interpolation algorithm. For that, the homogeneous points are replaced by motors and matrix operations are substituted with GA operations.
Since the matrix multiplications in (
38) with the form
, the result of which is a constant value expressed as:
Changing the homogeneous points with their respective motor representations in CGA and analyzing the motor multiplication, is shown that the coefficient of the blade
(
) from the motor multiplication
is the double value of (
41). This coefficient (
) can be extracted from any motor using the partial derivative:
or via the inner product with the
and
:
Using GA, Equation (
38) is reformulated for a motor based interpolation algorithm. It uses three control motors as follows:
In the same manner as in Algorithm 2, for more control points, Equation (
44) can be rewritten using the De Casteljau’s algorithm as described in Algorithm 3. This algorithm calculates one motor for the set
of control motors (
) and the interpolation constants (
t,
,
,
). Similar to Algorithm 2, the interpolation function is called recursively with the calculated motors from the last step as an input until we get only one motor. Since the last step needs three motors to calculate the last one,
must contain an odd number of motors.
![Electronics 11 01527 i002]()















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}