Figure 1.
The eight types of shots considered.
Figure 1.
The eight types of shots considered.
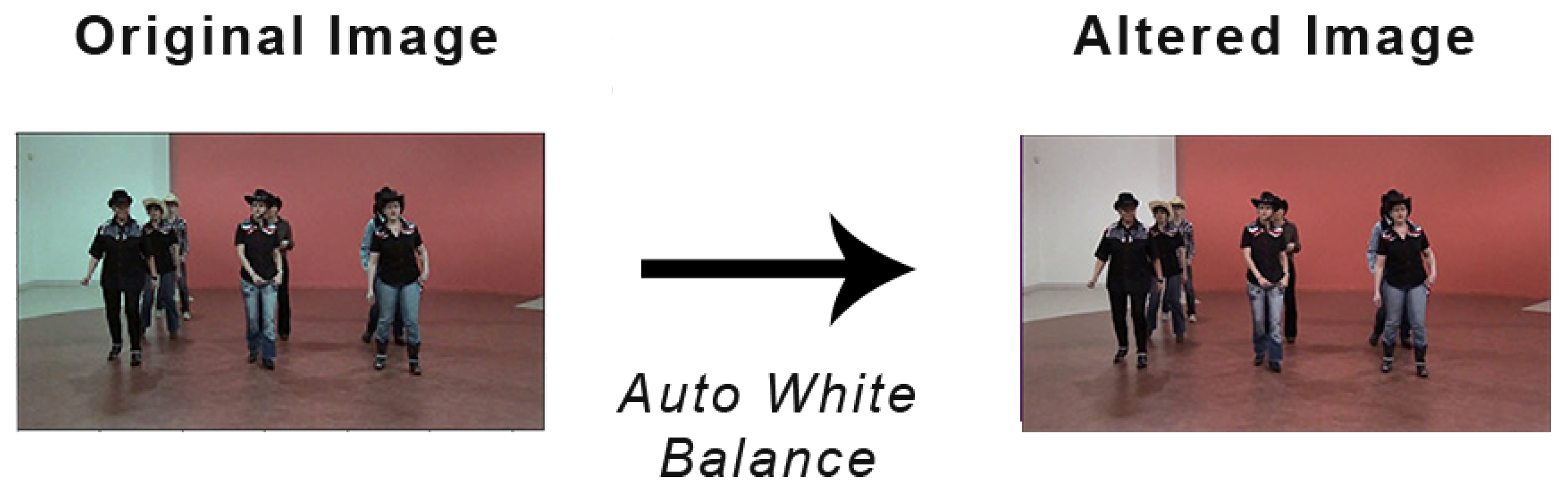
Figure 2.
Example of an image before and after white balance.
Figure 2.
Example of an image before and after white balance.
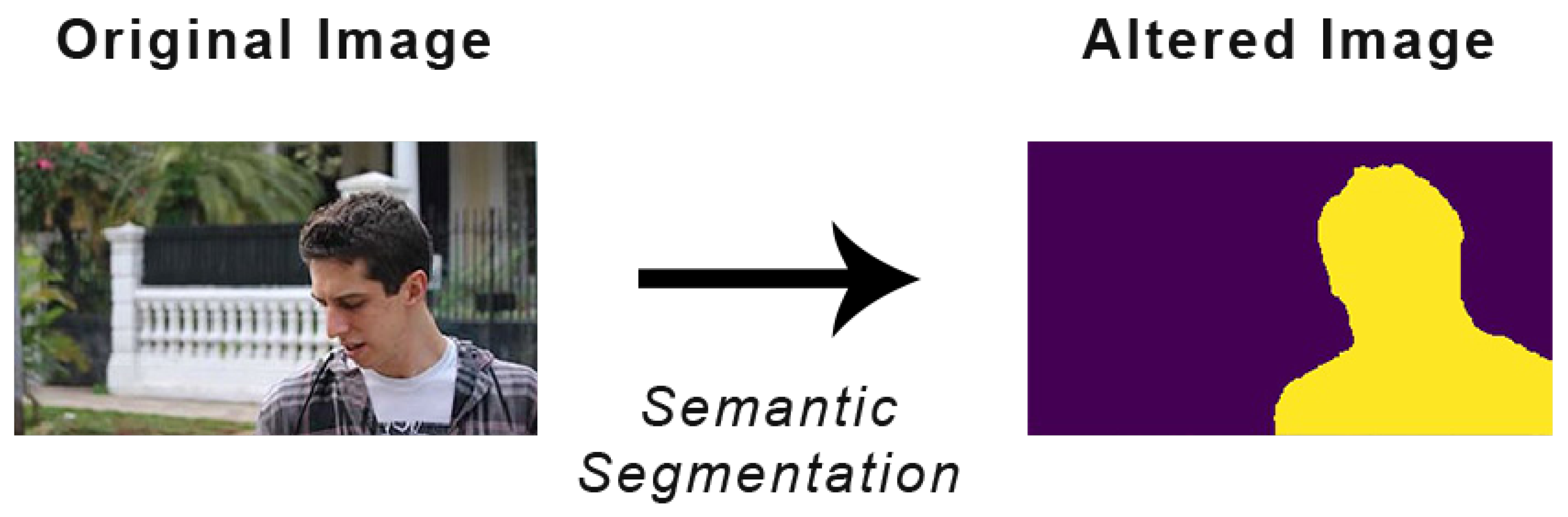
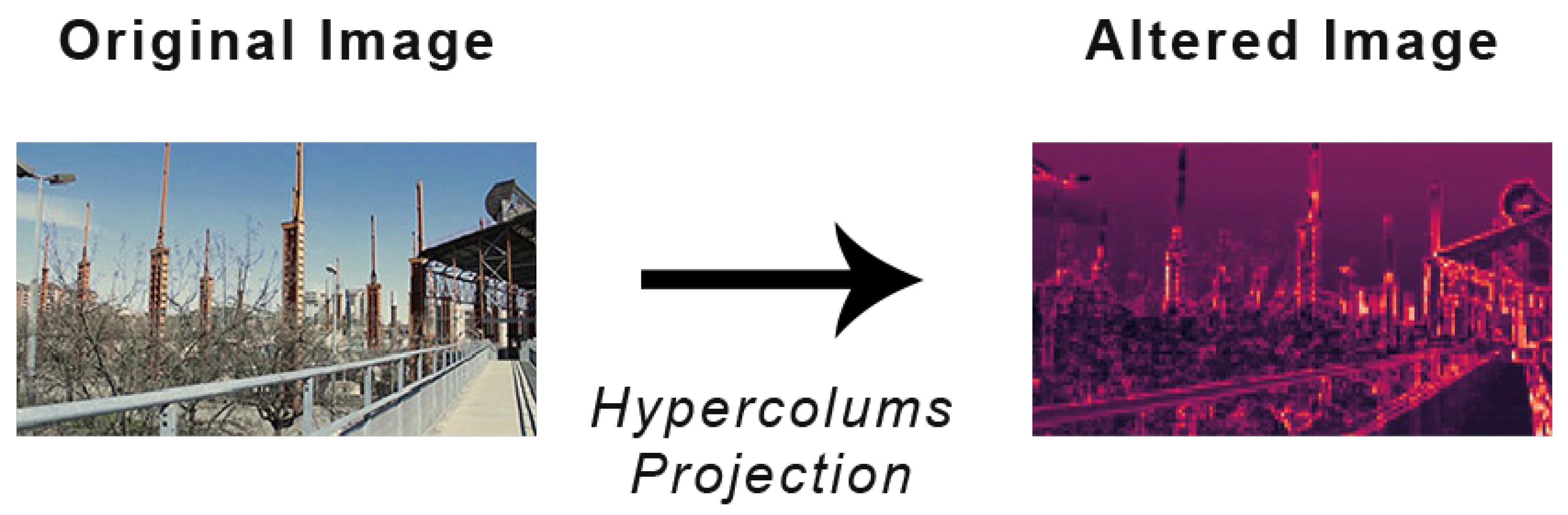
Figure 3.
Example of an image alterated for the Hypercolumns Dataset.
Figure 3.
Example of an image alterated for the Hypercolumns Dataset.
Figure 4.
Example of an image alterated for the Stylized Dataset.
Figure 4.
Example of an image alterated for the Stylized Dataset.
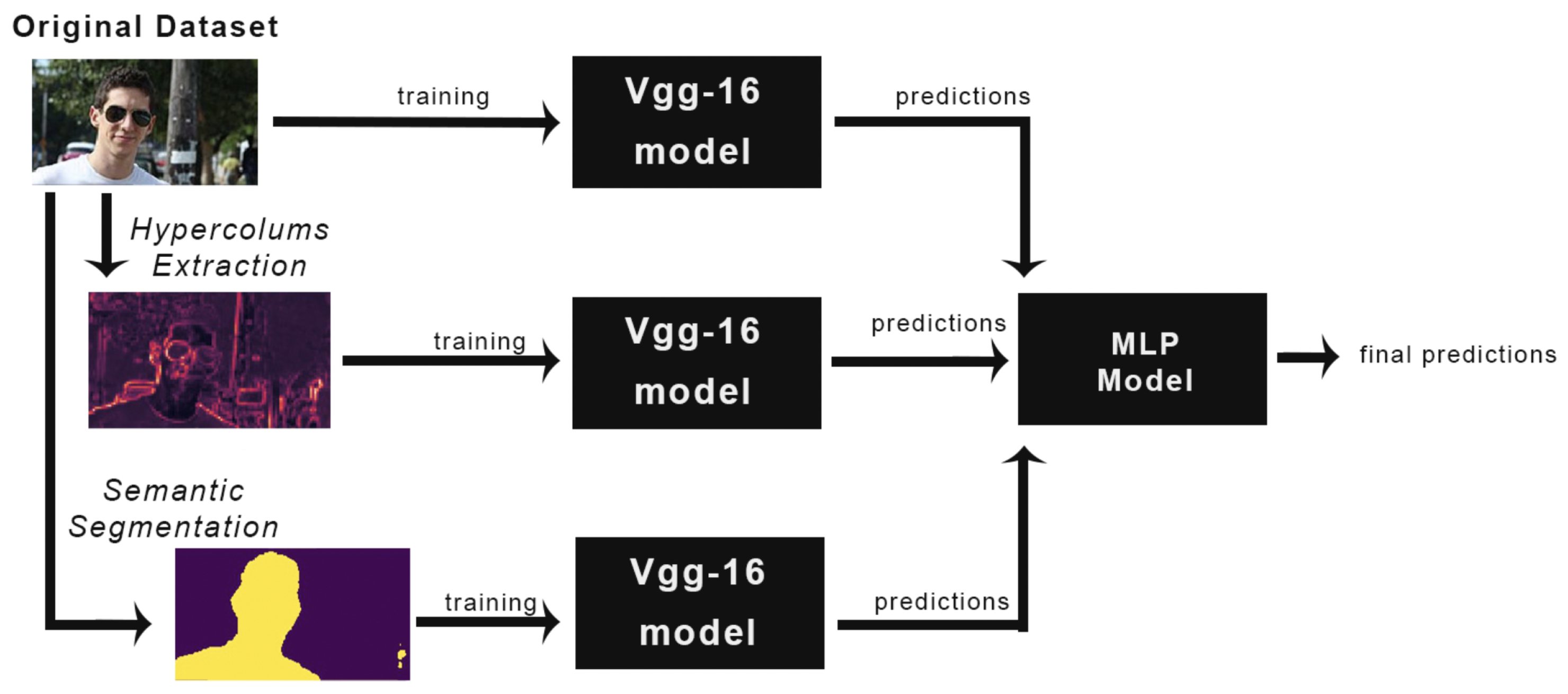
Figure 5.
Methodology Overview.
Figure 5.
Methodology Overview.
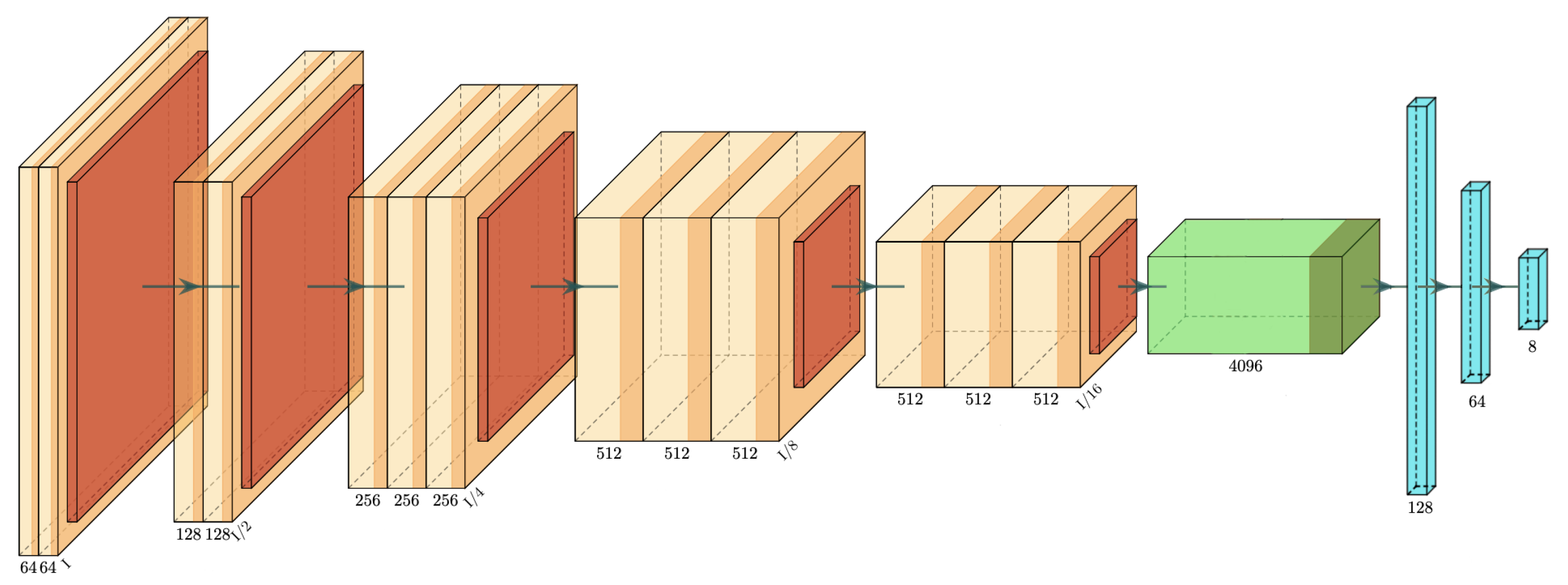
Figure 6.
VGG-16 structure: the orange blocks represent the convolutional layers, the red ones are the pooling layers. The green block represents the flatten layer. Finally the blue blocks represents the fully connected layers.
Figure 6.
VGG-16 structure: the orange blocks represent the convolutional layers, the red ones are the pooling layers. The green block represents the flatten layer. Finally the blue blocks represents the fully connected layers.
Table 1.
Datasets’ description.
Table 1.
Datasets’ description.
| Name | Short Name | N Sample | N Sample | Alterations | Example |
|---|
| | | Train | Test | | |
|---|
| Original | OD | 7318 | 3164 | Auto | Figure 2 |
| Dataset | | | | White-Balance | |
| Stylyzed | SD | 7318 | 3164 | Semantic | Figure 3 |
| Dataset | | | | Segmentation | |
| Hypercolums | HD | 7318 | 3164 | Hypercolumn | Figure 4 |
| Dataset | | | | Projection | |
Table 2.
Confusion Matrix of a VGG-16 trained on the Original Dataset.
Table 2.
Confusion Matrix of a VGG-16 trained on the Original Dataset.
| | | | | Predicted Labels | | | | | |
|---|
| | | LS | MS | FF | AS | HF | HT | CU | ECU |
| True | Long Shot (LS) | 301 | 61 | 7 | 2 | 6 | 13 | 7 | 10 |
| | Medium Shot (MS) | 29 | 255 | 57 | 13 | 12 | 11 | 1 | 3 |
| | Full Figure (FF) | 1 | 27 | 252 | 26 | 4 | 8 | 2 | 4 |
| Label | American Shot (AS) | 0 | 5 | 26 | 192 | 52 | 7 | 0 | 0 |
| | Half Figure (HF) | 0 | 3 | 3 | 54 | 256 | 73 | 2 | 2 |
| | Half Torso (HT) | 0 | 6 | 4 | 1 | 28 | 435 | 27 | 2 |
| | Close Up (CU) | 0 | 2 | 1 | 2 | 1 | 108 | 376 | 29 |
| | Extreme Close Up (ECU) | 0 | 1 | 1 | 0 | 1 | 3 | 66 | 283 |
Table 3.
Confusion Matrix of the VGG-16 trained on Stylized Dataset.
Table 3.
Confusion Matrix of the VGG-16 trained on Stylized Dataset.
| | | | | Predicted Labels | | | | | |
|---|
| | | LS | MS | FF | AS | HF | HT | CU | ECU |
| True | Long Shot (LS) | 331 | 49 | 3 | 2 | 0 | 11 | 8 | 3 |
| | Medium Shot (MS) | 41 | 254 | 52 | 10 | 7 | 7 | 9 | 1 |
| | Full Figure (FF) | 13 | 37 | 221 | 31 | 6 | 11 | 3 | 2 |
| Label | American Shot (AS) | 3 | 9 | 16 | 187 | 55 | 6 | 6 | 0 |
| | Half Figure (HF) | 11 | 9 | 4 | 37 | 255 | 62 | 11 | 4 |
| | Half Torso (HT) | 13 | 9 | 4 | 3 | 46 | 341 | 83 | 4 |
| | Close Up (CU) | 10 | 10 | 2 | 9 | 5 | 73 | 356 | 54 |
| | Extreme Close Up (ECU) | 5 | 3 | 1 | 2 | 1 | 10 | 82 | 251 |
Table 4.
Confusion Matrix of a VGG-16 trained on the Hyper Dataset.
Table 4.
Confusion Matrix of a VGG-16 trained on the Hyper Dataset.
| | | | | Predicted Labels | | | | | |
|---|
| | | LS | MS | FF | AS | HF | HT | CU | ECU |
| True | Long Shot (LS) | 312 | 63 | 20 | 0 | 7 | 1 | 2 | 2 |
| | Medium Shot (MS) | 48 | 251 | 56 | 11 | 11 | 0 | 2 | 2 |
| | Full Figure (FF) | 8 | 43 | 238 | 12 | 16 | 1 | 2 | 4 |
| Label | American Shot (AS) | 3 | 15 | 49 | 142 | 67 | 3 | 2 | 1 |
| | Half Figure (HF) | 2 | 15 | 20 | 38 | 277 | 34 | 1 | 6 |
| | Half Torso (HT) | 8 | 7 | 20 | 5 | 92 | 235 | 44 | 2 |
| | Close Up (CU) | 8 | 9 | 9 | 1 | 5 | 68 | 375 | 44 |
| | Extreme Close Up (ECU) | 5 | 0 | 1 | 1 | 3 | 5 | 61 | 279 |
Table 5.
Confusion Matrix of the MLP as fourth classifier.
Table 5.
Confusion Matrix of the MLP as fourth classifier.
| | | | | Predicted Labels | | | | | |
|---|
| | | LS | MS | FF | AS | HF | HT | CU | ECU |
| True | Long Shot (LS) | 320 | 67 | 3 | 1 | 4 | 6 | 4 | 2 |
| | Medium Shot (MS) | 30 | 294 | 36 | 9 | 7 | 3 | 1 | 1 |
| | Full Figure (FF) | 4 | 36 | 247 | 23 | 4 | 4 | 2 | 4 |
| Label | American Shot (AS) | 0 | 7 | 18 | 194 | 57 | 5 | 1 | 0 |
| | Half Figure (HF) | 0 | 6 | 3 | 44 | 291 | 44 | 2 | 3 |
| | Half Torso (HT) | 2 | 6 | 6 | 0 | 51 | 402 | 36 | 0 |
| | Close Up (CU) | 1 | 6 | 1 | 1 | 3 | 75 | 409 | 23 |
| | Extreme Close Up (ECU) | 1 | 0 | 0 | 0 | 3 | 3 | 66 | 282 |
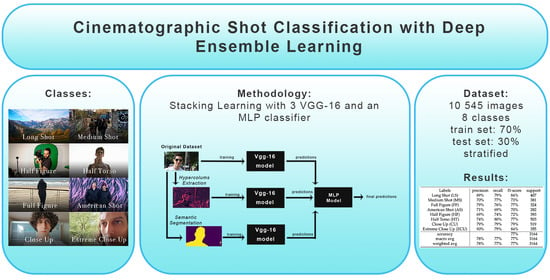
Table 6.
Precision recall and f1-score of the MLP as fourth classifier.
Table 6.
Precision recall and f1-score of the MLP as fourth classifier.
| Labels | Precision | Recall | f1-Score | Support |
|---|
| Long Shot (LS) | 89% | 79% | 84% | 407 |
| Medium Shot (MS) | 70% | 77% | 73% | 381 |
| Full Figure (FF) | 79% | 76% | 77% | 324 |
| American Shot (AS) | 71% | 69% | 70% | 282 |
| Half Figure (HF) | 69% | 74% | 72% | 393 |
| Half Torso (HT) | 74% | 80% | 77% | 503 |
| Close Up (CU) | 79% | 79% | 79% | 519 |
| Extreme Close Up (ECU) | 90% | 79% | 84% | 355 |
| accuracy | | | 77% | 3164 |
| macro avg | 78% | 77% | 77% | 3164 |
| weighted avg | 78% | 77% | 77% | 3164 |
Table 7.
Comparison with VGG-16 and ResNet-50.
Table 7.
Comparison with VGG-16 and ResNet-50.
| | | | | Predicted Labels | | | | | |
|---|
| Model | | | f1 | Score | per | Class | | | Accuracy |
| | LS | MS | FF | AS | HF | HT | CU | ECU | |
| VGG-16 0 | 82% | 69% | 75% | 67% | 68% | 75% | 75% | 82% | 74.26% |
| VGG-16 1 | 86% | 69% | 77% | 69% | 69% | 71% | 79% | 83% | 76.55% |
| VGG-16 2 | 85% | 70% | 77% | 72% | 72% | 76% | 76% | 85% | 76.74% |
| VGG-16 3 | 85% | 72% | 71% | 62% | 69% | 74% | 77% | 80% | 74.68% |
| ResNet-50 1 | 78% | 62% | 61% | 52% | 68% | 74% | 71% | 83% | 69.15% |
| Us | 84% | 73% | 77% | 70% | 72% | 77% | 79% | 84% | 77.09% |
Table 8.
Confusion Matrix of a VGG-16 trained on the augmented Original Dataset with the flip on the y-axis, i.e., Scenario 1.
Table 8.
Confusion Matrix of a VGG-16 trained on the augmented Original Dataset with the flip on the y-axis, i.e., Scenario 1.
| | | | | Predicted Labels | | | | | |
|---|
| | | LS | MS | FF | AS | HF | HT | CU | ECU |
| True | Long Shot (LS) | 375 | 14 | 3 | 0 | 2 | 2 | 4 | 7 |
| | Medium Shot (MS) | 71 | 224 | 56 | 10 | 8 | 6 | 1 | 5 |
| | Full Figure (FF) | 7 | 22 | 253 | 24 | 4 | 5 | 2 | 7 |
| Label | American Shot (AS) | 3 | 5 | 19 | 200 | 52 | 1 | 1 | 1 |
| | Half Figure (HF) | 2 | 4 | 1 | 57 | 291 | 31 | 5 | 2 |
| | Half Torso (HT) | 5 | 1 | 5 | 6 | 70 | 353 | 58 | 5 |
| | Close Up (CU) | 3 | 1 | 0 | 0 | 0 | 47 | 416 | 52 |
| | Extreme Close Up (ECU) | 0 | 1 | 0 | 0 | 0 | 0 | 44 | 310 |
Table 9.
Precision recall and f1-score of a VGG-16 trained on the augmented Original Dataset with the flip on the y-axis, i.e., Scenario 1.
Table 9.
Precision recall and f1-score of a VGG-16 trained on the augmented Original Dataset with the flip on the y-axis, i.e., Scenario 1.
| Labels | Precision | Recall | f1-Score | Support |
|---|
| Long Shot (LS) | 80% | 92% | 86% | 407 |
| Medium Shot (MS) | 82% | 59% | 69% | 381 |
| Full Figure (FF) | 75% | 78% | 77% | 324 |
| American Shot (AS) | 67% | 71% | 69% | 282 |
| Half Figure (HF) | 68% | 74% | 71% | 393 |
| Half Torso (HT) | 79% | 70% | 74% | 503 |
| Close Up (CU) | 78% | 80% | 79% | 519 |
| Extreme Close Up (ECU) | 80% | 87% | 83% | 355 |
| accuracy | | | 77% | 3164 |
| macro avg | 76% | 76% | 76% | 3164 |
| weighted avg | 77% | 77% | 76% | 3164 |
Table 10.
Confusion Matrix of a VGG-16 trained on the augmented Original Dataset with the flip on the y-axis and zoom range = 0.1, i.e., Scenario 2.
Table 10.
Confusion Matrix of a VGG-16 trained on the augmented Original Dataset with the flip on the y-axis and zoom range = 0.1, i.e., Scenario 2.
| | | | | Predicted Labels | | | | | |
|---|
| | | LS | MS | FF | AS | HF | HT | CU | ECU |
| True | Long Shot (LS) | 349 | 51 | 3 | 1 | 1 | 0 | 2 | 0 |
| | Medium Shot (MS) | 41 | 272 | 51 | 7 | 3 | 7 | 0 | 0 |
| | Full Figure (FF) | 2 | 36 | 262 | 13 | 4 | 4 | 2 | 1 |
| Label | American Shot (AS) | 2 | 7 | 25 | 201 | 43 | 3 | 0 | 1 |
| | Half Figure (HF) | 4 | 8 | 9 | 51 | 278 | 41 | 1 | 1 |
| | Half Torso (HT) | 5 | 9 | 5 | 3 | 50 | 408 | 23 | 0 |
| | Close Up (CU) | 6 | 5 | 2 | 3 | 3 | 97 | 361 | 42 |
| | Extreme Close Up (ECU) | 3 | 3 | 0 | 0 | 1 | 4 | 47 | 297 |
Table 11.
Precision recall and f1-score of a VGG-16 trained on the augmented Original Dataset with the flip on the y-axis and zoom range = 0.1, i.e., Scenario 2.
Table 11.
Precision recall and f1-score of a VGG-16 trained on the augmented Original Dataset with the flip on the y-axis and zoom range = 0.1, i.e., Scenario 2.
| Labels | Precision | Recall | f1-Score | Support |
|---|
| Long Shot (LS) | 85% | 86% | 85% | 407 |
| Medium Shot (MS) | 70% | 71% | 70% | 381 |
| Full Figure (FF) | 73% | 81% | 77% | 324 |
| American Shot (AS) | 72% | 71% | 72% | 282 |
| Half Figure (HF) | 73% | 71% | 72% | 393 |
| Half Torso (HT) | 72% | 81% | 76% | 503 |
| Close Up (CU) | 83% | 70% | 76% | 519 |
| Extreme Close Up (ECU) | 87% | 84% | 85% | 355 |
| accuracy | | | 77% | 3164 |
| macro avg | 77% | 77% | 77% | 3164 |
| weighted avg | 77% | 77% | 77% | 3164 |
Table 12.
Confusion Matrix of a VGG-16 trained on the augmented Original Dataset with the flip on the y-axis and zoom range = 0.3, i.e., Scenario 3.
Table 12.
Confusion Matrix of a VGG-16 trained on the augmented Original Dataset with the flip on the y-axis and zoom range = 0.3, i.e., Scenario 3.
| | | | | Predicted Labels | | | | | |
|---|
| | | LS | MS | FF | AS | HF | HT | CU | ECU |
| True | Long Shot (LS) | 353 | 29 | 3 | 4 | 5 | 3 | 8 | 2 |
| | Medium Shot (MS) | 37 | 266 | 55 | 9 | 10 | 3 | 1 | 0 |
| | Full Figure (FF) | 3 | 41 | 235 | 31 | 7 | 3 | 3 | 1 |
| Label | American Shot (AS) | 1 | 5 | 10 | 216 | 49 | 0 | 1 | 0 |
| | Half Figure (HF) | 1 | 1 | 2 | 66 | 288 | 32 | 3 | 0 |
| | Half Torso (HT) | 1 | 2 | 4 | 2 | 75 | 371 | 48 | 0 |
| | Close Up (CU) | 2 | 1 | 0 | 0 | 4 | 77 | 429 | 6 |
| | Extreme Close Up (ECU) | 1 | 1 | 0 | 1 | 0 | 5 | 126 | 221 |
Table 13.
Precision recall and f1-score of a VGG-16 trained on the augmented Original Dataset with the flip on the y-axis and zoom range = 0.3, i.e., Scenario 3.
Table 13.
Precision recall and f1-score of a VGG-16 trained on the augmented Original Dataset with the flip on the y-axis and zoom range = 0.3, i.e., Scenario 3.
| Labels | Precision | Recall | f1-Score | Support |
|---|
| Long Shot (LS) | 88% | 87% | 88% | 407 |
| Medium Shot (MS) | 77% | 70% | 73% | 381 |
| Full Figure (FF) | 76% | 73% | 74% | 324 |
| American Shot (AS) | 66% | 77% | 71% | 282 |
| Half Figure (HF) | 66% | 73% | 69% | 393 |
| Half Torso (HT) | 75% | 74% | 74% | 503 |
| Close Up (CU) | 69% | 83% | 75% | 519 |
| Extreme Close Up (ECU) | 96% | 62% | 76% | 355 |
| accuracy | | | 75% | 3164 |
| macro avg | 77% | 75% | 75% | 3164 |
| weighted avg | 77% | 75% | 75% | 3164 |
Table 14.
Confusion Matrix of a Resnet-50 trained on OD plus flip on the y-axis.
Table 14.
Confusion Matrix of a Resnet-50 trained on OD plus flip on the y-axis.
| | | | | Predicted Labels | | | | | |
|---|
| | | LS | MS | FF | AS | HF | HT | CU | ECU |
| True | Long Shot (LS) | 275 | 118 | 6 | 0 | 2 | 3 | 2 | 1 |
| | Medium Shot (MS) | 20 | 236 | 33 | 1 | 0 | 0 | 1 | 0 |
| | Full Figure (FF) | 2 | 89 | 218 | 5 | 5 | 3 | 1 | 1 |
| Label | American Shot (AS) | 1 | 38 | 90 | 115 | 36 | 2 | 0 | 0 |
| | Half Figure (HF) | 1 | 36 | 16 | 36 | 257 | 45 | 1 | 1 |
| | Half Torso (HT) | 1 | 27 | 13 | 1 | 53 | 390 | 18 | 0 |
| | Close Up (CU) | 0 | 23 | 6 | 3 | 7 | 109 | 317 | 54 |
| | Extreme Close Up (ECU) | 2 | 10 | 6 | 0 | 2 | 5 | 40 | 290 |
Table 15.
Precision recall and f1-score of a ResNet50 trained on the OD plus the flip on the y-axis.
Table 15.
Precision recall and f1-score of a ResNet50 trained on the OD plus the flip on the y-axis.
| Labels | Precision | Recall | f1-Score | Support |
|---|
| Long Shot (LS) | 91% | 68% | 78% | 407 |
| Medium Shot (MS) | 49% | 86% | 62% | 381 |
| Full Figure (FF) | 56% | 67% | 61% | 324 |
| American Shot (AS) | 72% | 41% | 52% | 282 |
| Half Figure (HF) | 71% | 65% | 68% | 393 |
| Half Torso (HT) | 70% | 78% | 74% | 503 |
| Close Up (CU) | 83% | 61% | 71% | 519 |
| Extreme Close Up (ECU) | 84% | 82% | 83% | 355 |
| accuracy | | | 69% | 3164 |
| macro avg | 72% | 68% | 68% | 3164 |
| weighted avg | 73% | 69% | 69% | 3164 |
Table 16.
Comparison with Variation of the Stacking Learning Technique.
Table 16.
Comparison with Variation of the Stacking Learning Technique.
| Model | | | f1 | Score | per | Class | | | Accuracy |
|---|
| | | LS | MS | FF | AS | HF | HT | CU | ECU |
| Random Forest | 65% | 70% | 76% | 71% | 72% | 76% | 79% | 83% | 72.56% |
| as meta-learner | | | | | | | | | |
| Us: MLP | 84% | 73% | 77% | 70% | 72% | 77% | 79% | 84% | 77.09% |
| as meta-learner | | | | | | | | | |
| Cerberus | 83% | 71% | 68% | 66% | 63% | 75% | 73% | 83% | 73.32% |
Table 17.
Confusion Matrix of random forest trained on predictions.
Table 17.
Confusion Matrix of random forest trained on predictions.
| | | | | Predicted Labels | | | | | |
|---|
| | | LS | MS | FF | AS | HF | HT | CU | ECU |
| True | Long Shot (LS) | 375 | 30 | 1 | 0 | 1 | 0 | 0 | 0 |
| | Medium Shot (MS) | 106 | 244 | 29 | 0 | 1 | 0 | 0 | 1 |
| | Full Figure (FF) | 53 | 25 | 224 | 15 | 3 | 3 | 0 | 1 |
| Label | American Shot (AS) | 49 | 2 | 11 | 177 | 42 | 0 | 0 | 1 |
| | Half Figure (HF) | 54 | 4 | 2 | 26 | 271 | 34 | 1 | 1 |
| | Half Torso (HT) | 48 | 5 | 2 | 1 | 46 | 359 | 42 | 0 |
| | Close Up (CU) | 36 | 3 | 0 | 1 | 0 | 49 | 403 | 27 |
| | Extreme Close Up (ECU) | 25 | 0 | 0 | 0 | 0 | 0 | 55 | 275 |
Table 18.
Precision recall and f1-score of a random forest on the predictions of the three vgg-16.
Table 18.
Precision recall and f1-score of a random forest on the predictions of the three vgg-16.
| Labels | Precision | Recall | f1-Score | Support |
|---|
| Long Shot (LS) | 50% | 92% | 65% | 407 |
| Medium Shot (MS) | 78% | 64% | 70% | 381 |
| Full Figure (FF) | 83% | 69% | 76% | 324 |
| American Shot (AS) | 80% | 63% | 71% | 282 |
| Half Figure (HF) | 74% | 69% | 72% | 393 |
| Half Torso (HT) | 81% | 71% | 76% | 503 |
| Close Up (CU) | 80% | 78% | 79% | 519 |
| Extreme Close Up (ECU) | 90% | 77% | 83% | 355 |
| accuracy | | | 74% | 3164 |
| macro avg | 77% | 73% | 74% | 3164 |
| weighted avg | 77% | 74% | 74% | 3164 |
Table 19.
Confusion Matrix of the cerberus model VGG-16 trained on the three Datasets.
Table 19.
Confusion Matrix of the cerberus model VGG-16 trained on the three Datasets.
| | | LS | MS | FF | AS | HF | HT | CU | ECU |
|---|
| True | Long Shot (LS) | 317 | 80 | 6 | 1 | 2 | 1 | 0 | 0 |
| | Medium Shot (MS) | 27 | 304 | 35 | 6 | 5 | 3 | 0 | 1 |
| | Full Figure (FF) | 4 | 54 | 212 | 38 | 6 | 7 | 2 | 1 |
| Label | American Shot (AS) | 0 | 11 | 29 | 203 | 37 | 2 | 0 | 0 |
| | Half Figure (HF) | 2 | 6 | 7 | 79 | 221 | 75 | 2 | 1 |
| | Half Torso (HT) | 1 | 12 | 8 | 4 | 36 | 418 | 23 | 1 |
| | Close Up (CU) | 4 | 10 | 4 | 6 | 3 | 107 | 337 | 48 |
| | Extreme Close Up (ECU) | 1 | 4 | 2 | 0 | 0 | 4 | 36 | 308 |
Table 20.
Precision recall and f1-score of the Cerberus model trained on the three datasets.
Table 20.
Precision recall and f1-score of the Cerberus model trained on the three datasets.
| Labels | Precision | Recall | f1-Score | Support |
|---|
| Long Shot (LS) | 89% | 78% | 83% | 407 |
| Medium Shot (MS) | 63% | 80% | 71% | 381 |
| Full Figure (FF) | 70% | 65% | 68% | 324 |
| American Shot (AS) | 60% | 72% | 66% | 282 |
| Half Figure (HF) | 71% | 56% | 63% | 393 |
| Half Torso (HT) | 68% | 83% | 75% | 503 |
| Close Up (CU) | 84% | 65% | 73% | 519 |
| Extreme Close Up (ECU) | 86% | 87% | 86% | 355 |
| accuracy | | | 73% | 3164 |
| macro avg | 74% | 73% | 73% | 3164 |
| weighted avg | 75% | 73% | 73% | 3164 |
Table 21.
f1-score per class and accuracy of different architectures.
Table 21.
f1-score per class and accuracy of different architectures.
| | | | | Models’ f1-Score per Class | | | | |
|---|
| Models | Ovgg-16 | Ovgg | Ovgg | Ovgg | MLP | Cerberus | ResNet | Random |
| | | aug1 | aug2 | aug3 | | | 50 | Forest |
| Classes | | | | | | | | |
| LS | 82% | 86% | 85% | 85% | 84% | 83% | 78% | 65% |
| MS | 69% | 69% | 70% | 72% | 73% | 71% | 62% | 70% |
| FF | 75% | 77% | 77% | 71% | 77% | 68% | 61% | 76% |
| AS | 67% | 69% | 72% | 62% | 70% | 66% | 52% | 71% |
| HF | 68% | 71% | 72% | 69% | 72% | 63% | 68% | 72% |
| HT | 75% | 74% | 76% | 74% | 77% | 75% | 74% | 76% |
| CU | 75% | 79% | 76% | 77% | 79% | 73% | 71% | 79% |
| ECU | 82% | 83% | 85% | 80% | 84% | 86% | 83% | 83% |
| Acc | 74.27% | 76.55% | 76.74% | 74.68% | 77.09% | 73.32% | 69.15% | 72.56% |
Table 22.
Precision recall and f1-score of our methodology on a subset of the Cinescale Dataset.
Table 22.
Precision recall and f1-score of our methodology on a subset of the Cinescale Dataset.
| Labels | Precision | Recall | f1-Score | Support |
|---|
| Long Shot (LS) | 81% | 66% | 73% | 345 |
| Medium Shot (MS) | 91% | 96% | 93% | 4345 |
| Close Up (CU) | 79% | 65% | 71% | 863 |
| accuracy | | | 89% | 5553 |
| macro avg | 84% | 75% | 79% | 5553 |
| weighted avg | 89% | 89% | 89% | 5553 |
Table 23.
Confusion Matrix of our methodology on a subset of the Cinescale dataset.
Table 23.
Confusion Matrix of our methodology on a subset of the Cinescale dataset.
| | | Predicted Labels | | |
|---|
| | | LS | MS | CU |
| True | Long Shot (LS) | 226 | 111 | 8 |
| | Medium Shot (MS) | 141 | 4175 | 47 |
| Labels | Close Up (CU) | 5 | 295 | 563 |
Table 24.
Precision recall and f1-score of a mlp as fourth classifier trained on the predictions of three VGG-16 trained on each dataset with data augmentation techniques.
Table 24.
Precision recall and f1-score of a mlp as fourth classifier trained on the predictions of three VGG-16 trained on each dataset with data augmentation techniques.
| Labels | Precision | Recall | f1-Score | Support |
|---|
| Long Shot (LS) | 87% | 85% | 86% | 407 |
| Medium Shot (MS) | 72% | 76% | 74% | 381 |
| Full Figure (FF) | 76% | 81% | 79% | 324 |
| American Shot (AS) | 76% | 73% | 75% | 282 |
| Half Figure (HF) | 71% | 73% | 72% | 393 |
| Half Torso (HT) | 77% | 75% | 76% | 503 |
| Close Up (CU) | 76% | 80% | 78% | 519 |
| Extreme Close Up (ECU) | 91% | 81% | 86% | 355 |
| accuracy | | | 78% | 3164 |
| macro avg | 78% | 78% | 78% | 3164 |
| weighted avg | 78% | 78% | 78% | 3164 |
Table 25.
Confusion matrix of a mlp as fourth classifier trained on the predictions of three VGG-16 trained on each dataset with data augmentation techniques.
Table 25.
Confusion matrix of a mlp as fourth classifier trained on the predictions of three VGG-16 trained on each dataset with data augmentation techniques.
| | | | | Predicted Labels | | | | | |
|---|
| | | LS | MS | FF | AS | HF | HT | CU | ECU |
| True | Long Shot (LS) | 346 | 50 | 4 | 0 | 2 | 0 | 3 | 2 |
| | Medium Shot (MS) | 35 | 289 | 46 | 6 | 2 | 3 | 0 | 0 |
| | Full Figure (FF) | 4 | 35 | 263 | 11 | 6 | 2 | 3 | 0 |
| Label | American Shot (AS) | 2 | 6 | 22 | 206 | 43 | 0 | 3 | 0 |
| | Half Figure (HF) | 1 | 7 | 7 | 46 | 287 | 37 | 8 | 0 |
| | Half Torso (HT) | 6 | 9 | 3 | 1 | 57 | 375 | 52 | 0 |
| | Close Up (CU) | 2 | 4 | 1 | 0 | 6 | 64 | 414 | 28 |
| | Extreme Close Up (ECU) | 0 | 1 | 0 | 0 | 2 | 3 | 60 | 289 |











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}