
Few-Shot Image Classification: Current Status and Research Trends


Abstract
:1. Introduction
2. Definition and Datasets
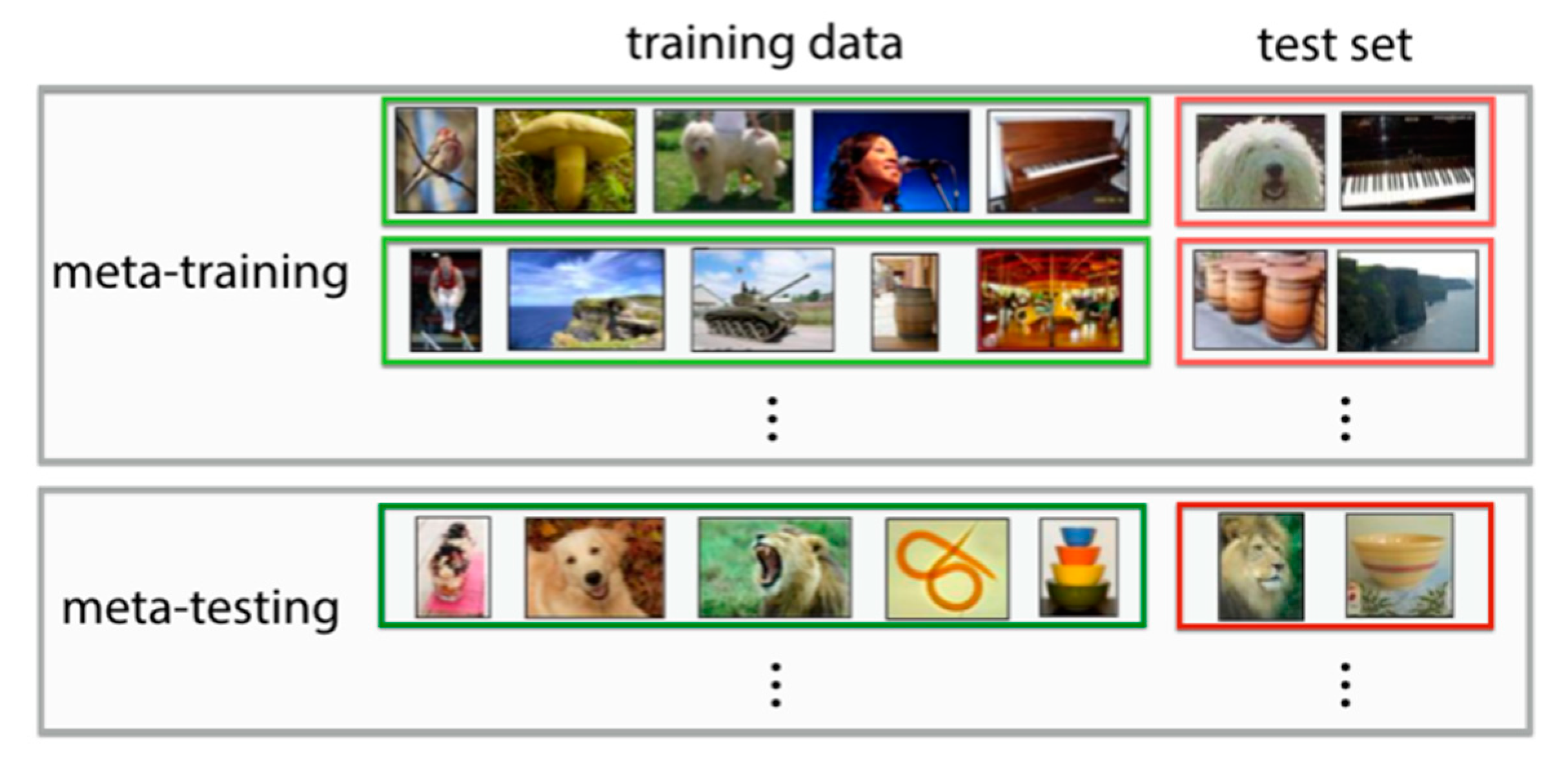
2.1. Few-Shot Image Classification Definition
2.2. Datasets
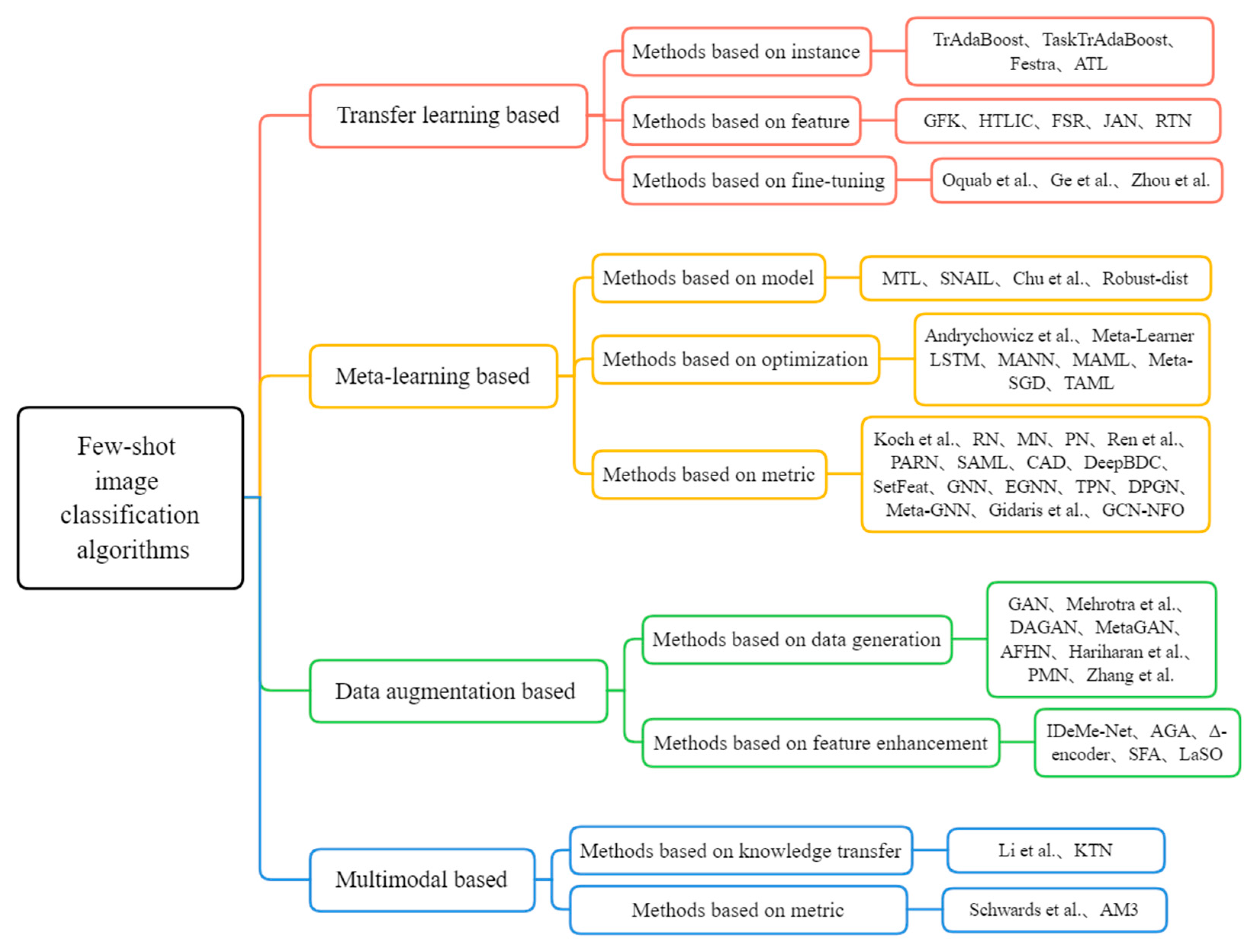
3. Few-Shot Image Classification Algorithms
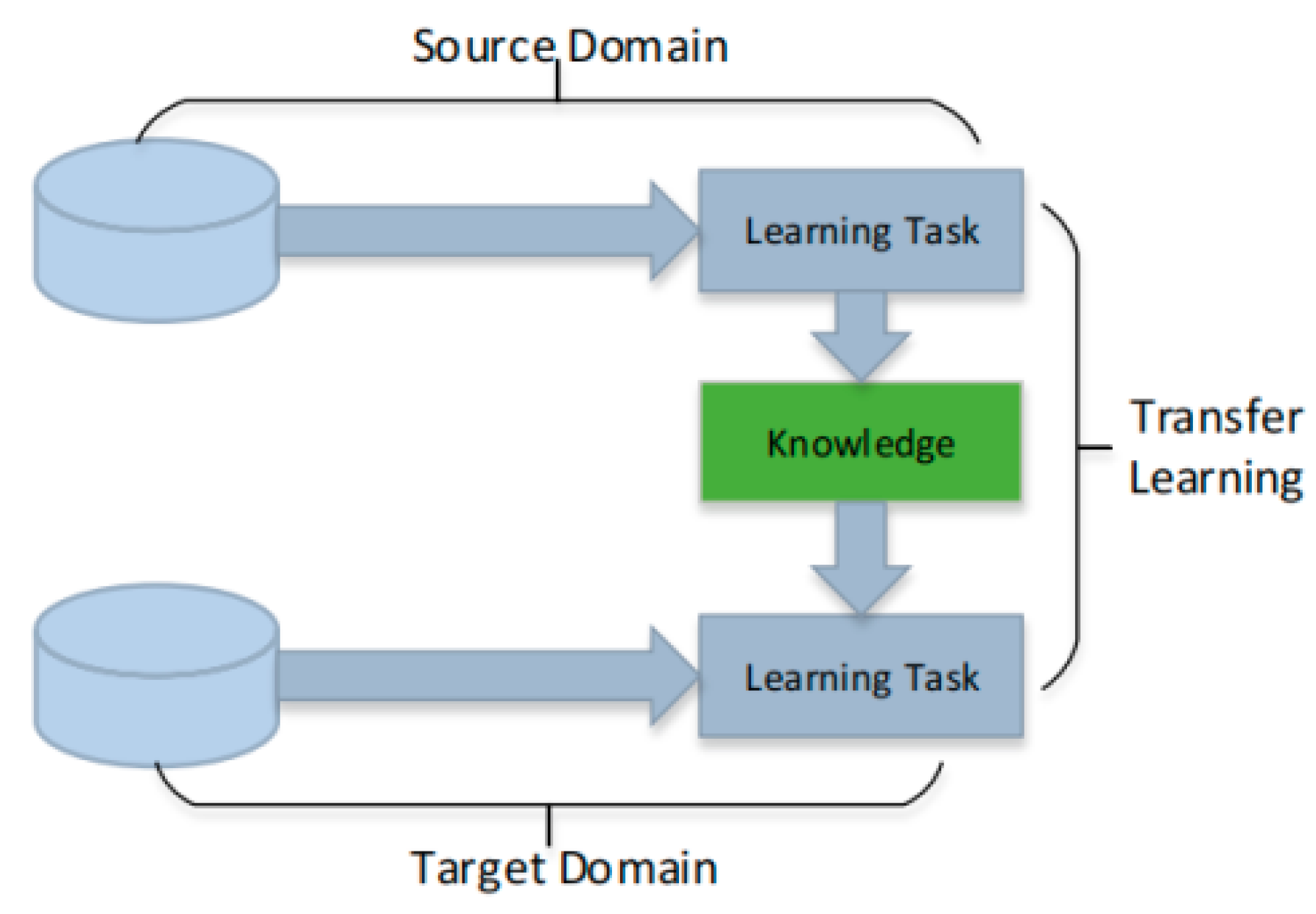
3.1. Transfer Learning-Based Methods
3.1.1. Instance-Based Methods
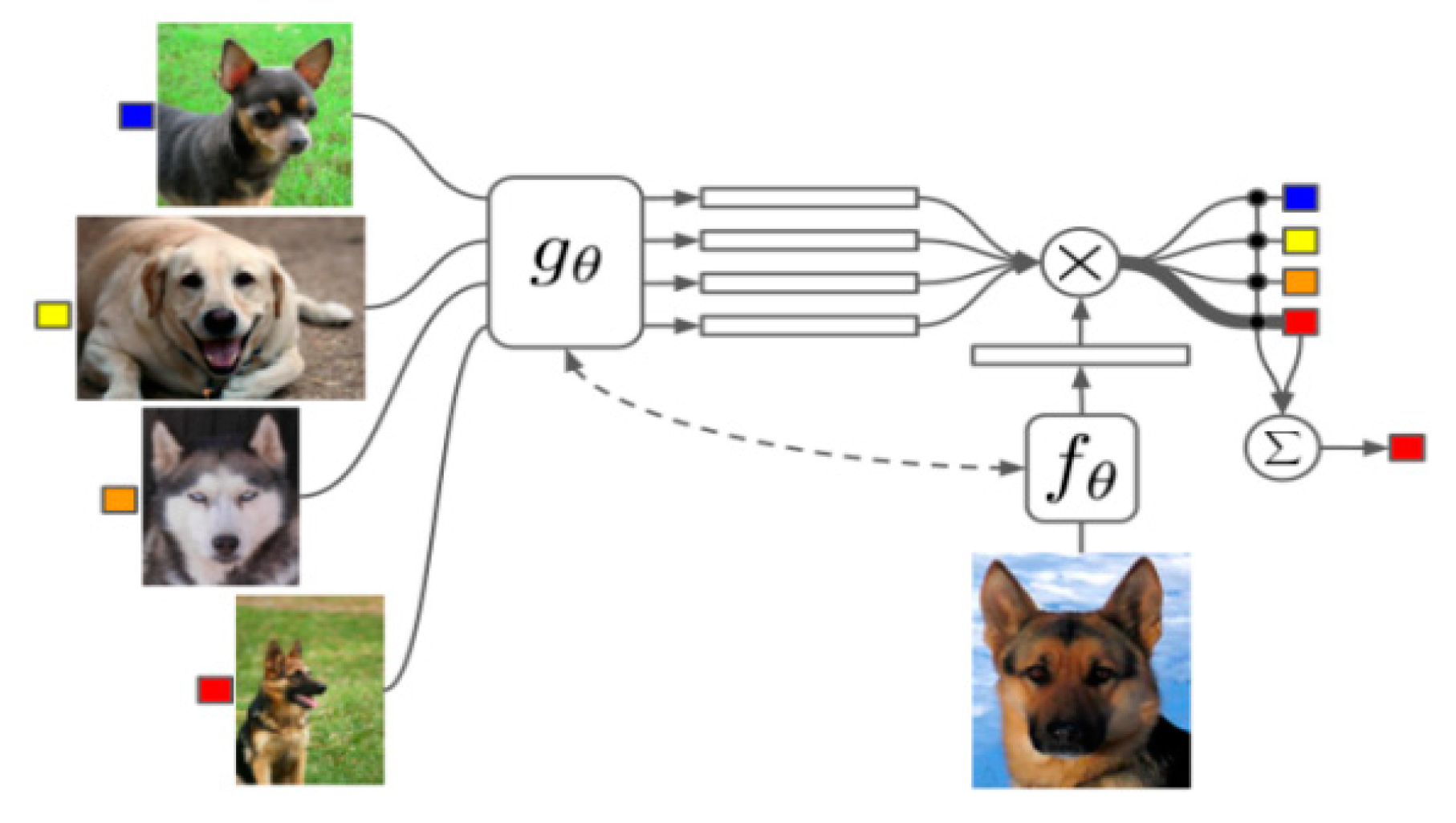
3.1.2. Feature-Based Methods
3.1.3. Fine-Tuning-Based Methods
3.2. Meta-Learning-Based Methods
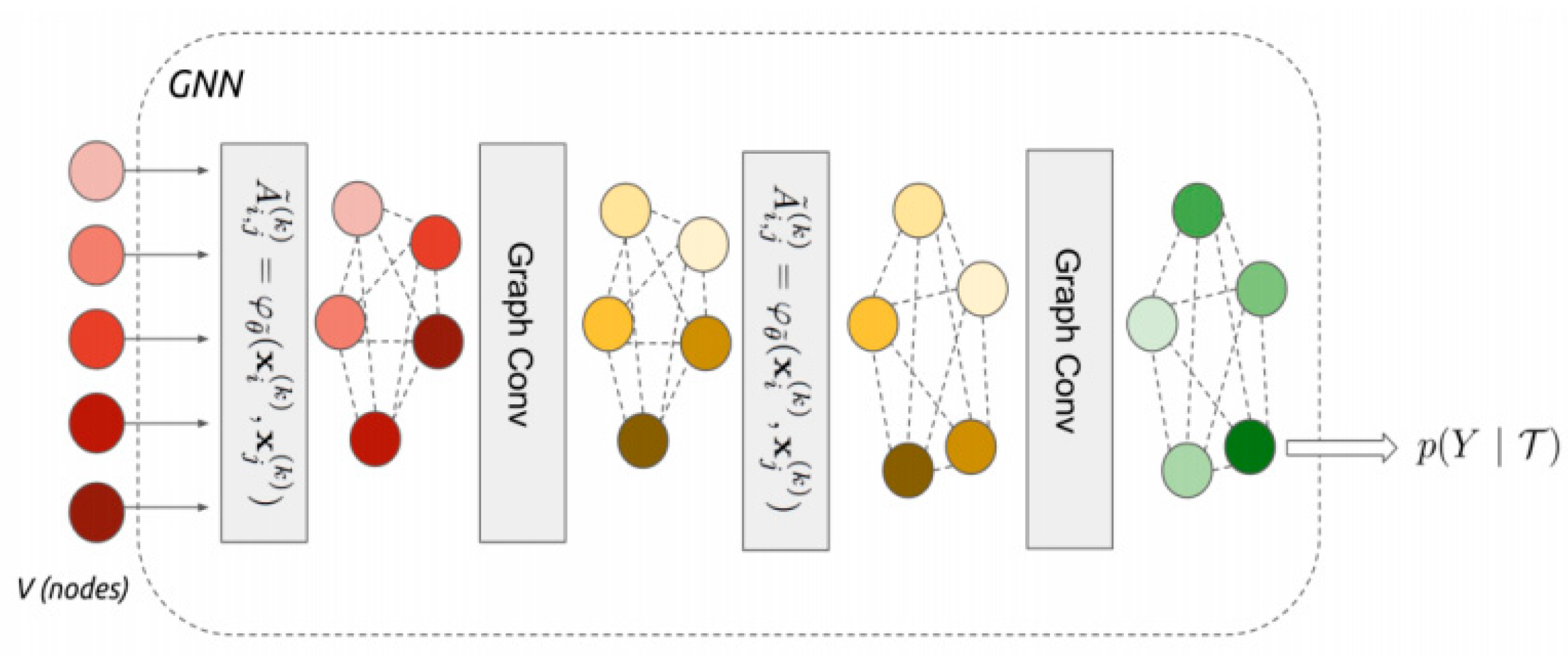
3.2.1. Model-Based Methods
3.2.2. Optimization-Based Methods
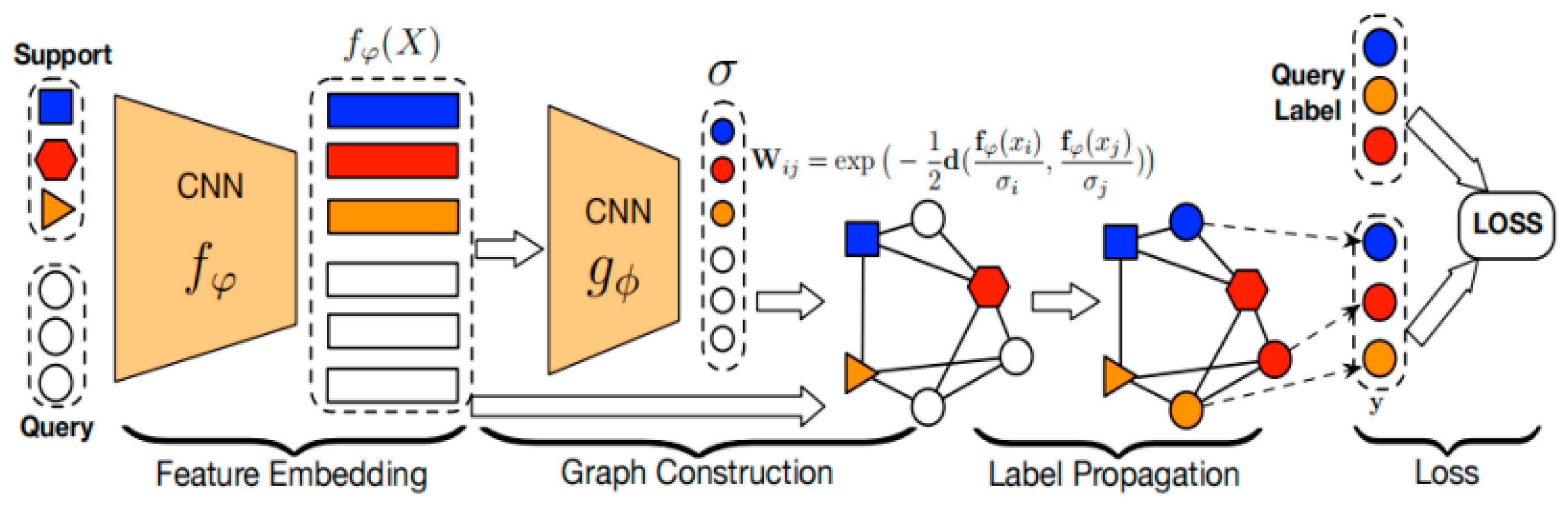
3.2.3. Metric-Based Methods
3.3. Data Augmentation-Based Methods
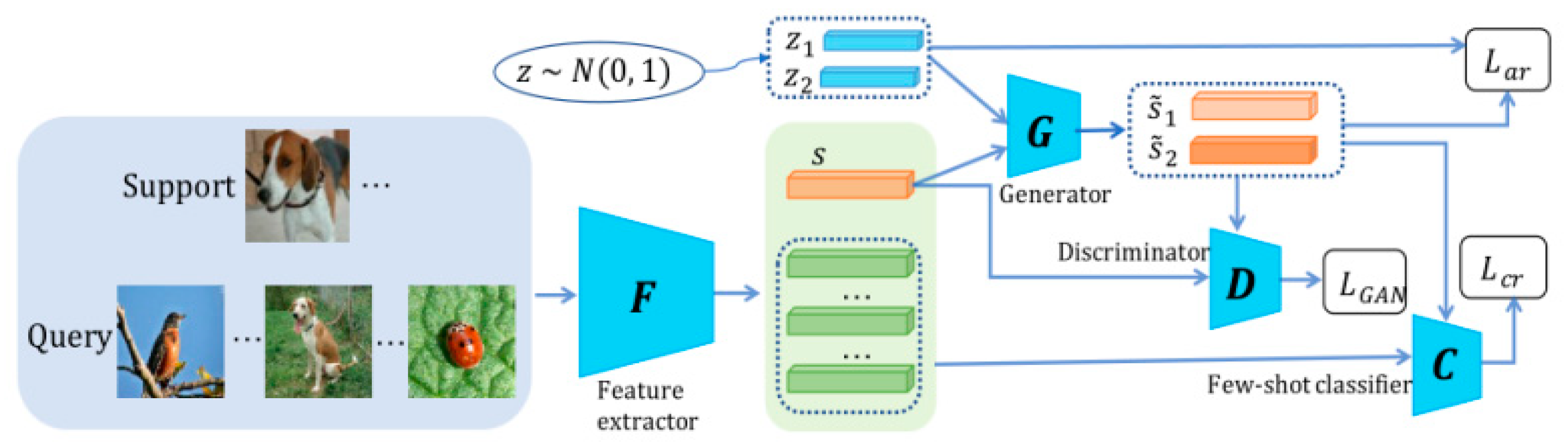
3.3.1. Data Generation-Based Methods
3.3.2. Feature Enhancement-Based Methods
3.4. Multimodal-Based Methods
3.4.1. Knowledge Transfer-Based Methods
3.4.2. Metric-Based Methods
3.5. Comparison of Different Learning Paradigms
4. Comparison of Different FSIC Algorithms
4.1. Quantitative Comparison of FSIC Algorithms
4.1.1. Comparison of Performance on Benchmark Datasets
- The few-shot image classification algorithms have a high classification accuracy on the Omniglot dataset, while their performance on the miniImageNet dataset is relatively poor.
- The accuracy of the 5-way 5-shot task in the two datasets is higher than that of the 5-way 1-shot task, which shows that the more training data in the sample category, the more features the model can learn, which is conducive to improving the classification accuracy.
- On the Omniglot dataset, the accuracy of the selected algorithms is more than 98%, and the experimental results are slightly different; on the miniImageNet dataset, the experimental results of different algorithms differ greatly. The accuracy of the 5-way 1-shot task is mostly about 50%. The classification result of the GCN-NFO method with the best performance is about 55% higher than that of the Meta-Learner LSTM method. The classification accuracy of the 5-way 5-shot task is mostly about 65%. Among them, the GCN-NFO method, which has the best classification effect, improves by about 43% compared to the worst-performing MN method, indicating that the existing few-shot image classification algorithm can still make a great improvement on the miniImageNet dataset.
4.1.2. Comparison of Performance on Application Dataset
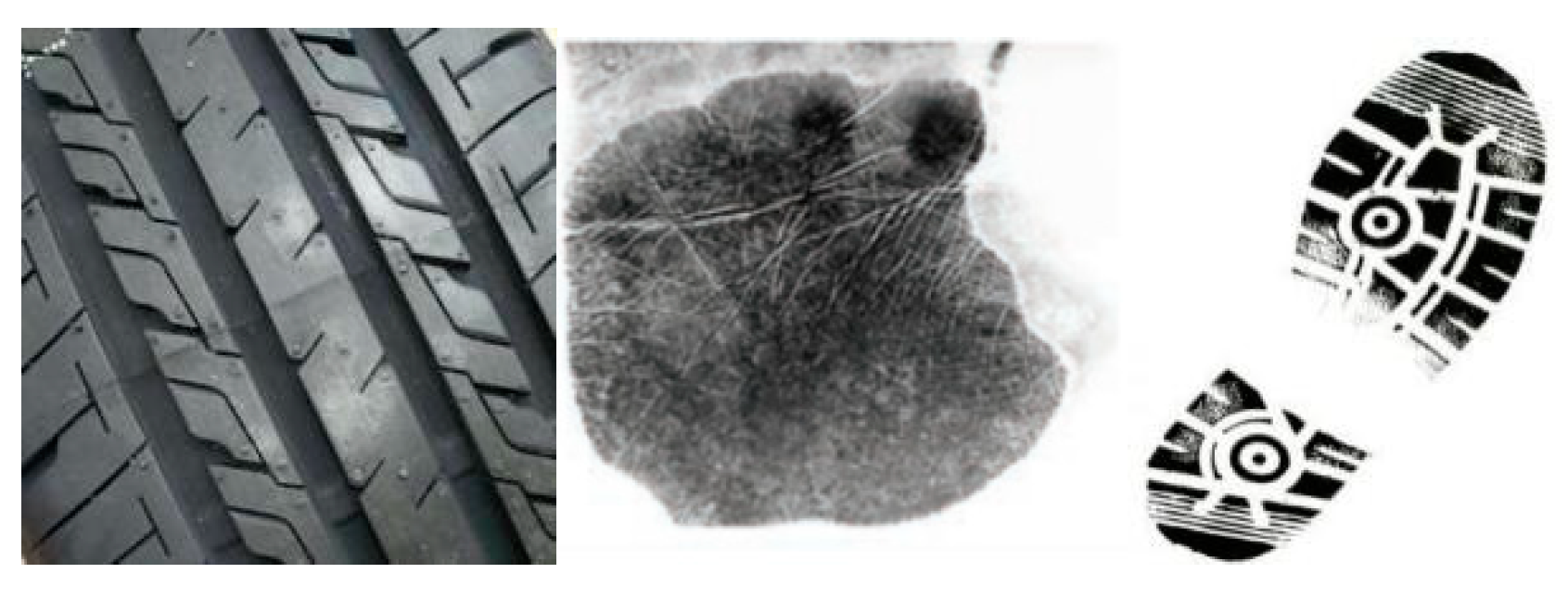
- The experimental results of various few-shot image classification algorithms on the CIIP-TPID dataset are relatively good, better than those on the miniImageNet dataset, but lower than those on the Omniglot dataset. The reason is that the miniImageNet dataset has a wide variety of image samples and complex content; the Omniglot dataset is composed of different handwritten character images with a single background and simple content; while the CIIP-TPID dataset consists of different types of tire pattern images and includes indentation images on different carriers. Its image background is slightly richer and the content is relatively simple.
- The results of different methods on the mixed dataset are relatively low. This is because the mixed data contains two kinds of data: surface pattern image and indentation pattern image. The samples in each category are relatively complex with characteristics of large intra-class differences and small inter-class differences, which bring difficulties to the classification task.
- GNN and GCN-NFO have the highest accuracy in the 5-way 1-shot task, indicating that the metric learning method based on the graph neural network is more suitable for the study of tire pattern image classification.
- The GCN-NFO method achieves the best classification effect on different sub-datasets. This is because GCN-NFO makes full use of the image features of the special data samples to improve the network performance. In the next step, we will compare more algorithms and try to conduct more in-depth research on datasets in other fields.
4.2. Qualitative Comparison of FSIC Algorithms
5. Applications of Few-Shot Image Classification
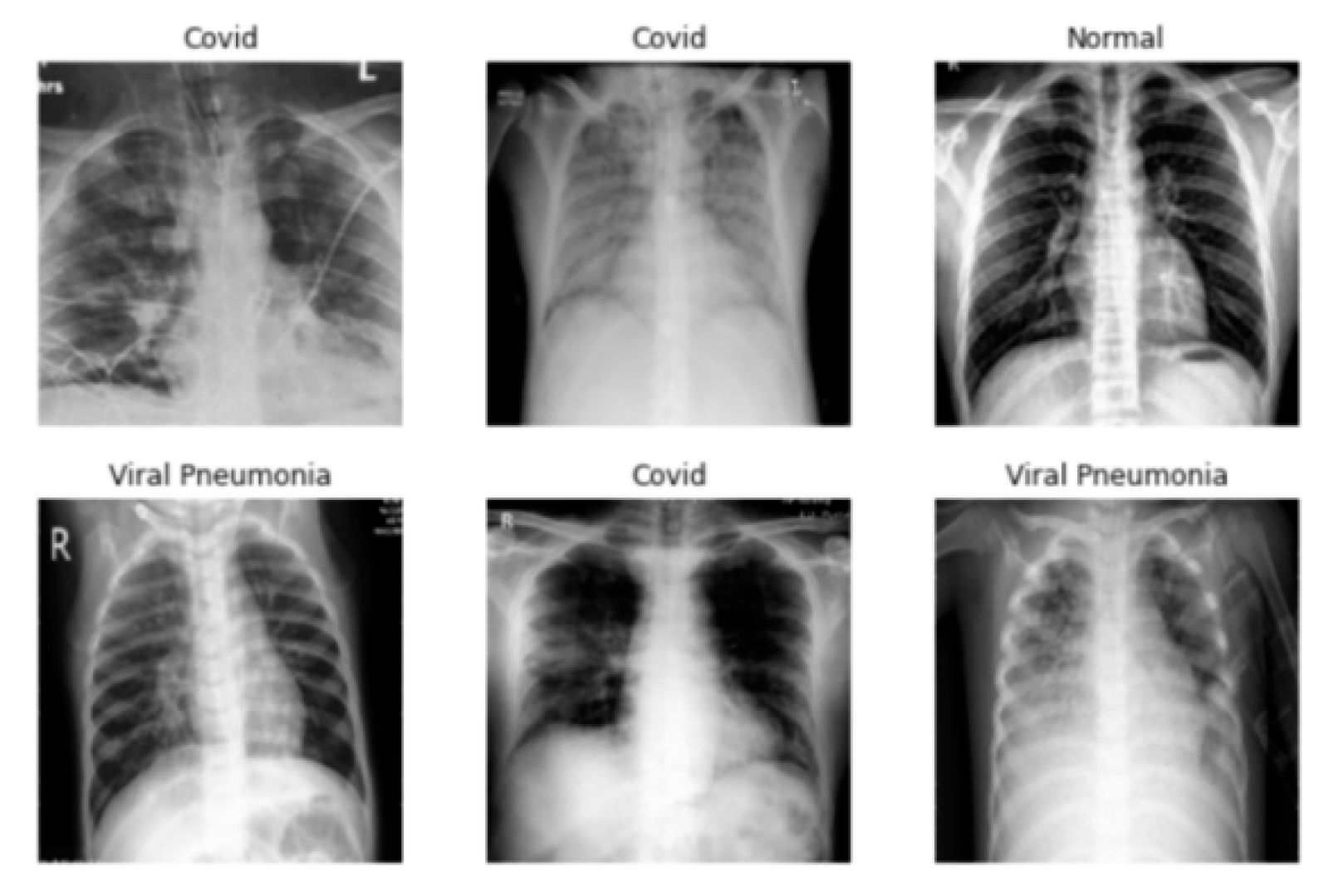
5.1. Medical Field
- There are subtle differences in medical images, which usually lead to certain recognition errors and make the model learn unnecessary features, and finally affect the classification results.
- Most medical images are 2D images, which cannot truly reflect the 3D structure information of the human body. This will lead to the loss of certain effective information in the process of collecting images, and finally, result in inaccurate classification results.
- Analysis of medical images alone is not enough to accurately judge the disease but requires collaboration with multimodal technologies. Although the current few-shot image classification has made good achievements in the medical field, there is still a lot of research space in the future.
5.2. Public Security Field
5.3. Commercial Field
6. Research Trend of Few-Shot Image Classification
6.1. Build Suitable Datasets for Practical Applications
6.2. Neural Architecture Search
6.3. Interpretability of Neural Networks
6.4. Multimodal Few-Shot Image Classification
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Csurka, G.; Dance, C.R.; Fan, L.; Willamowski, J.; Bray, C. Visual Categorization with Bags of Keypoints. In Proceedings of the Conference and Workshop on European Conference on Computer Vision, Prague, Czech Republic, 11–14 May 2004. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar]
- Ahonen, T.; Hadid, A.; Pietikainen, M. Face description with local binary patterns: Application to face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 2037–2041. [Google Scholar] [CrossRef] [PubMed]
- Yang, C. Plant leaf recognition by integrating shape and texture features. Pattern Recognit. 2021, 112, 107809. [Google Scholar] [CrossRef]
- Al-Saffar, A.A.M.; Tao, H.; Talab, M.A. Review of deep convolution neural network in image classification. In Proceedings of the 2017 International Conference on Radar, Antenna, Microwave, Electronics, and Telecommunications (ICRAMET), Jakarta, Indonesia, 23–24 October 2017; pp. 26–31. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Munkhdalai, T.; Yu, H. Meta networks. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 2554–2563. [Google Scholar]
- Zhang, X.; Sung, F.; Qiang, Y.; Yang, Y.; Hospedales, T.M. Deep comparison: Relation columns for few-shot learning. arXiv 2018, arXiv:1811.07100. [Google Scholar]
- Liu, L.; Zhou, T.; Long, G.; Jiang, J.; Yao, L.; Zhang, C. Prototype Propagation Networks (PPN) for Weakly-supervised Few-shot Learning on Category Graph. arXiv 2019, arXiv:1905.04042. Available online: http://arxiv.org/abs/1905.04042 (accessed on 2 June 2019).
- Fei-Fei, L.; Fergus, R.; Perona, P. One-shot learning of object categories. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 594–611. [Google Scholar] [CrossRef] [Green Version]
- Fink, M. Object classification from a single example utilizing class relevance metrics. Adv. Neural Inf. Process. Syst. 2005, 17, 449–456. [Google Scholar]
- Fe-Fei, L.; Fergus; Perona. A Bayesian approach to unsupervised one-shot learning of object categories. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; Volume 2, pp. 1134–1141. [Google Scholar] [CrossRef] [Green Version]
- Qiao, S.; Liu, C.; Yuille, A.L. Few-shot image recognition by predicting parameters from activations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7229–7238. [Google Scholar]
- Shaban, A.; Bansal, S.; Liu, Z.; Essa, I.; Boots, B. One-shot learning for semantic segmentation. arXiv 2017, arXiv:1709.03410. [Google Scholar]
- Liu, B.; Yu, X.; Yu, A.; Zhang, P.; Wan, G.; Wang, R. Deep few-shot learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2290–2304. [Google Scholar] [CrossRef]
- Ashrafi, I.; Mohammad, M.; Mauree, A.S.; Habibullah, K.M. Attention guided relation network for few-shot image classification. In Proceedings of the 2019 7th International Conference on Computer and Communications Management, Bangkok, Thailand, 27–29 July 2019; pp. 177–180. [Google Scholar]
- Gui, L.; Wang, Y.-X.; Hebert, M. Few-shot hash learning for image retrieval. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 1228–1237. [Google Scholar] [CrossRef]
- Singh, R.; Bharti, V.; Purohit, V.; Kumar, A.; Singh, A.K.; Singh, S.K. MetaMed: Few-shot medical image classification using gradient-based meta-learning. Pattern Recognit. 2021, 120, 108111. [Google Scholar] [CrossRef]
- Yu, Y.; Bian, N. An Intrusion Detection Method Using Few-Shot Learning. IEEE Access 2020, 8, 49730–49740. [Google Scholar] [CrossRef]
- Zhao, K.; Jin, X.; Wang, Y. Survey on few-shot learning. J. Softw. 2021, 32, 349–369. [Google Scholar]
- Wang, Y.; Yao, Q.; Kwok, J.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. arXiv 2020, arXiv:1904.05046. Available online: http://arxiv.org/abs/1904.05046 (accessed on 13 May 2019). [CrossRef]
- Liu, Y.; Lei, Y.; Fan, J.; Wang, F.; Gong, Y.; Tian, Q. Survey on image classification technology based on few-shot learning. Acta Autom. Sin. 2021, 47, 297–315. (In Chinese) [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching networks for one shot learning. arXiv 2017, arXiv:1606.04080. Available online: http://arxiv.org/abs/1606.04080 (accessed on 29 December 2017).
- Lake, B.M.; Salakhutdinov, R.; Tenenbaum, J.B. Human-level concept learning through probabilistic program induction. Science 2015, 350, 1332–1338. [Google Scholar] [CrossRef] [Green Version]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Ren, M.; Triantafillou, E.; Ravi, S.; Snell, J.; Swersky, K.; Tenenbaum, J.B.; Larochelle, H.; Zemel, R.S. Meta-learning for semi-supervised few-shot classification. arXiv 2018, arXiv:1803.00676. Available online: http://arxiv.org/abs/1803.00676 (accessed on 30 April 2018).
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Koda, T. An Introduction to the Geometry of Homogeneous Spaces. In Proceedings of the 13th International Workshop on Differential Geometry and Related Fields, Taejon, Korea, 5–7 November 2009; pp. 121–144. [Google Scholar]
- Welinder, P.; Branson, S.; Mita, T.; Wah, C.; Schroff, F.; Belongie, S.; Perona, P. Caltech-UCSD Birds 200; CNS-TR-2010–001; California Institute of Technology: Pasadena, CA, USA, 2010. [Google Scholar]
- CIIP-TPID (Center for Image and Information Processing-Tread Pattern Image Datasets). Xi’an University of Posts and Telecommunications. 2019. Available online: http://www.xuptciip.com.cn/show.html?database-lthhhw (accessed on 1 September 2019).
- The 1st ACM International Conference on Multimedia in Asia (ACM Multimedia Asia). 2019. Available online: http://www.acmmmasia.org/2019/multimedia-grand-challenges.html (accessed on 17 December 2019).
- IEEE International Conference on Multimedia and Expo (ICME) 2021, Grand Challenges. Available online: https://2021.ieeeicme.org/conf_challenges (accessed on 8 July 2021).
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Dai, W.; Yang, Q.; Xue, G.; Yu, Y. Boosting for transfer learning. In Proceedings of the 24th International Conference on Machine Learning, Corvallis, OR, USA, 20–24 June 2007; pp. 193–200. [Google Scholar]
- Yao, Y.; Doretto, G. Boosting for transfer learning with multiple sources. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1855–1862. [Google Scholar] [CrossRef]
- Li, N.; Hao, H.; Gu, Q.; Wang, D.; Hu, X. A transfer learning method for automatic identification of sandstone microscopic images. Comput. Geosci. 2017, 103, 111–121. [Google Scholar] [CrossRef]
- Liu, W.; Chang, X.; Yan, Y.; Yang, Y.; Hauptmann, A.G. Few-shot text and image classification via analogical transfer learning. ACM Trans. Intell. Syst. Technol. 2018, 9, 1–20. [Google Scholar] [CrossRef]
- Gong, B.; Shi, Y.; Sha, F.; Grauman, K. Geodesic flow kernel for unsupervised domain adaptation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2066–2073. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Y.; Chen, Y.; Lu, Z.; Pan, S.J.; Xue, G.R.; Yu, Y.; Yang, Q. Heterogeneous transfer learning for image classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Palo Alto, CA, USA, 11–14 October 2011. [Google Scholar]
- Feuz, K.D.; Cook, D.J. Transfer learning across feature-rich heterogeneous feature spaces via feature-space remapping (FSR). ACM Trans. Intell. Syst. Technol. 2015, 6, 1–27. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Deep transfer learning with joint adaptation networks. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 2208–2217. [Google Scholar]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Unsupervised domain adaptation with residual transfer networks. arXiv 2017, arXiv:1602.04433. Available online: http://arxiv.org/abs/1602.04433 (accessed on 16 February 2017).
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Learning and transferring mid-level image representations using convolutional neural networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1717–1724. [Google Scholar] [CrossRef] [Green Version]
- Ge, W.; Yu, Y. Borrowing treasures from the wealthy: Deep transfer learning through selective joint fine-tuning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 10–19. [Google Scholar] [CrossRef] [Green Version]
- Zhou, L.; Cui, P.; Jia, X.; Yang, S.; Tian, Q. Learning to select base classes for few-shot classification. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4623–4632. [Google Scholar] [CrossRef]
- Sun, Q.; Liu, Y.; Chua, T.; Schiele, B. Meta-transfer learning for few-shot learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 403–412. [Google Scholar] [CrossRef] [Green Version]
- Mishra, N.; Rohaninejad, M.; Chen, X.; Abbeel, P. A Simple Neural Attentive Meta-Learner. arXiv 2018, arXiv:1707.03141. Available online: http://arxiv.org/abs/1707.03141 (accessed on 25 February 2018).
- Chu, W.-H.; Li, Y.-J.; Chang, J.-C.; Wang, Y.-C.F. Spot and learn: A maximum-entropy patch sampler for few-shot image classification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6244–6253. [Google Scholar] [CrossRef]
- Dvornik, N.; Mairal, J.; Schmid, C. Diversity with cooperation: Ensemble methods for few-shot classification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3722–3730. [Google Scholar] [CrossRef] [Green Version]
- Andrychowicz, M.; Denil, M.; Gomez, S.; Hoffman, M.W.; Pfau, D.; Schaul, T.; Shillingford, B.; de Freitas, N. Learning to learn by gradient descent by gradient descent. Adv. Neural Inf. Process. Syst. 2016, 29, 3981–3989. [Google Scholar]
- Ravi, S.; Larochelle, H. Optimization as a model for few-shot learning. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Santoro, A.; Bartunov, S.; Botvinick, M.; Wierstra, D.; Lillicrap, T. Meta-learning with memory-augmented neural networks. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1842–1850. [Google Scholar]
- Graves, A.; Wayne, G.; Danihelka, I. Neural turing machines. arXiv 2014, arXiv:1410.5401. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 1156–1168. [Google Scholar]
- Li, Z.; Zhou, F.; Chen, F.; Li, H. Meta-SGD: Learning to learn quickly for few-shot learning. arXiv 2017, arXiv:1707.09835. Available online: http://arxiv.org/abs/1707.09835 (accessed on 28 September 2017).
- Jamal, M.A.; Qi, G.-J. Task agnostic meta-learning for few-shot learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11711–11719. [Google Scholar] [CrossRef] [Green Version]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the Conference and Workshop on the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.S.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar] [CrossRef] [Green Version]
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical networks for few-shot learning. arXiv 2017, arXiv:1703.05175. Available online: http://arxiv.org/abs/1703.05175 (accessed on 19 June 2017).
- Wu, Z.; Li, Y.; Guo, L.; Jia, K. PARN: Position-aware relation networks for few-shot learning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6658–6666. [Google Scholar] [CrossRef] [Green Version]
- Hao, F.; He, F.; Cheng, J.; Wang, L.; Cao, J.; Tao, D. Collect and select: Semantic alignment metric learning for few-shot learning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8459–8468. [Google Scholar] [CrossRef]
- Chikontwe, P.; Kim, S.; Park, S.H. CAD: Co-Adapting Discriminative Features for Improved Few-Shot Classification. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022. [Google Scholar]
- Xie, J.; Long, F.; Lv, J.; Wang, Q.; Li, P. Joint Distribution Matters: Deep Brownian Distance Covariance for Few-Shot Classification. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022. [Google Scholar]
- Afrasiyabi, A.; Larochelle, H.; Lalonde, J.F.; Gagné, C. Matching Feature Sets for Few-Shot Image Classification. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022. [Google Scholar]
- Garcia, V.; Bruna, J. Few-shot learning with graph neural networks. arXiv 2018, arXiv:1711.04043. Available online: http://arxiv.org/abs/1711.04043 (accessed on 20 February 2018).
- Kim, J.; Kim, T.; Kim, S.; Yoo, C.D. Edge-labeling graph neural network for few-shot learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11–20. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Lee, J.; Park, M.; Kim, S.; Yang, E.; Hwang, S.J.; Yang, Y. Learning to propagate labels: Transductive propagation network for few-shot learning. arXiv 2019, arXiv:1805.10002. Available online: http://arxiv.org/abs/1805.10002 (accessed on 8 February 2019).
- Yang, L.; Li, L.; Zhang, Z.; Zhou, X.; Zhou, E.; Liu, Y. DPGN: Distribution propagation graph network for few-shot learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13387–13396. [Google Scholar] [CrossRef]
- Sankar, A.; Zhang, X.; Chang, K.C.-C. Meta-GNN: Metagraph neural network for semi-supervised learning in attributed heterogeneous information networks. In Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Vancouver, BC, Canada, 27–30 August 2019; pp. 137–144. [Google Scholar] [CrossRef]
- Gidaris, S.; Komodakis, N. Generating Classification Weights with GNN Denoising Autoencoders for Few-Shot Learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 21–30. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Lei, Y.; Rashid, S.F. Graph convolution network with node feature optimization using cross attention for few-shot learning. In Proceedings of the 2nd ACM International Conference on Multimedia in Asia, Singapore, 7–9 March 2021; pp. 1–7. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Conference and Workshop on Neural Information Processing Systems, Vancouver, BC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Mehrotra, A.; Dukkipati, A. Generative adversarial residual pairwise networks for one shot learning. arXiv 2017, arXiv:1703.08033. [Google Scholar]
- Antoniou, A.; Storkey, A.; Edwards, H. Data augmentation generative adversarial networks. arXiv 2018, arXiv:1711.04340. [Google Scholar]
- Zhang, R.; Che, T.; Ghahramani, Z.; Bengio, Y.; Song, Y. MetaGAN: An adversarial approach to few-shot learning. In Proceedings of the 32nd Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Li, K.; Zhang, Y.; Li, K.; Fu, Y. Adversarial feature hallucination networks for few-shot learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13467–13476. [Google Scholar] [CrossRef]
- Hariharan, B.; Girshick, R. Low-shot visual recognition by shrinking and hallucinating features. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3037–3046. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Girshick, R.; Hebert, M.; Hariharan, B. Low-shot learning from imaginary data. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7278–7286. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Zhang, J.; Koniusz, P. Few-shot learning via saliency-guided hallucination of samples. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2765–2774. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Fu, Y.; Wang, Y.-X.; Ma, L.; Liu, W.; Hebert, M. Image deformation meta-networks for one-shot learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8672–8681. [Google Scholar] [CrossRef] [Green Version]
- Dixit, M.; Kwitt, R.; Niethammer, M.; Vasconcelos, N. AGA: Attribute-guided augmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3328–3336. [Google Scholar] [CrossRef] [Green Version]
- Schwartz, E.; Karlinsky, L.; Shtok, J.; Harary, S.; Marder, M.; Kumar, A.; Feris, R.; Giryes, R.; Bronstein, A. Delta-encoder: An effective sample synthesis method for few-shot object recognition. arXiv 2018, arXiv:1806.04734. [Google Scholar]
- Chen, Z.; Fu, Y.; Zhang, Y.; Jiang, Y.G.; Xue, X.; Sigal, L. Semantic feature augmentation in few-shot learning. arXiv 2018, arXiv:1804.05298. [Google Scholar]
- Alfassy, A.; Karlinsky, L.; Aides, A.; Shtok, J.; Harary, S.; Feris, R.; Giryes, R.; Bronstein, A.M. LaSO: Label-set operations networks for multi-label few-shot learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 6541–6550. [Google Scholar] [CrossRef] [Green Version]
- Gao, J.; Li, P.; Chen, Z.; Zhang, J. A survey on deep learning for multimodal data fusion. Neural Comput. 2020, 32, 829–864. [Google Scholar] [CrossRef]
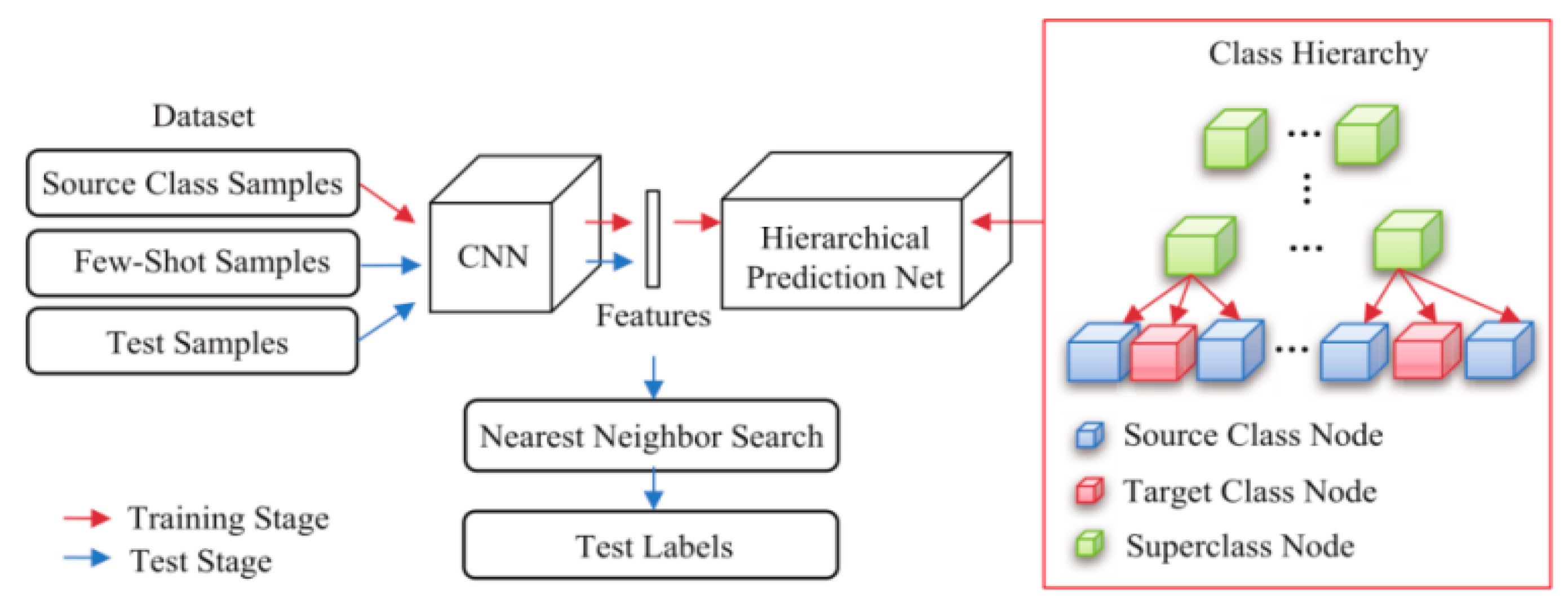
- Li, A.; Luo, T.; Lu, Z.; Xiang, T.; Wang, L. Large-scale few-shot learning: Knowledge transfer with class hierarchy. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7205–7213. [Google Scholar] [CrossRef]
- Peng, Z.; Li, Z.; Zhang, J.; Li, Y.; Qi, G.-J.; Tang, J. Few-shot image recognition with knowledge transfer. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 441–449. [Google Scholar] [CrossRef]
- Schwartz, E.; Karlinsky, L.; Feris, R.; Giryes, R.; Bronstein, A.M. Baby steps towards few-shot learning with multiple semantics. arXiv 2020, arXiv:1906.01905. [Google Scholar]
- Xing, C.; Rostamzadeh, N.; Oreshkin, B.N.; Pinheiro, P.O. Adaptive Cross-Modal Few-Shot Learning. Adv. Neural Inf. Process. Syst. 2019, 32, 4847–4857. [Google Scholar]
- Shang, H.; Sun, Z.; Yang, W.; Fu, X.; Zheng, H.; Chang, J.; Huang, J. Leveraging other datasets for medical imaging classification: Evaluation of transfer, multi-task and semi-supervised learning. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Cham, Switzerland, 2019; pp. 431–439. [Google Scholar]
- Cai, A.; Hu, W.; Zheng, J. Few-Shot Learning for Medical Image Classification. In Proceedings of the International Conference on Artificial Neural Networks, Bratislava, Slovakia, 15–18 September 2020; Springer: Cham, Switzerland, 2020; pp. 441–452. [Google Scholar]
- Chen, X.; Yao, L.; Zhou, T.; Dong, J.; Zhang, Y. Momentum contrastive learning for few-shot covid-19 diagnosis from chest ct images. Pattern Recognit. 2021, 113, 107826. [Google Scholar] [CrossRef]
- Jadon, S. COVID-19 detection from scarce chest X-ray image data using few-shot deep learning approach. In Medical Imaging 2021: Imaging Informatics for Healthcare, Research, and Applications; International Society for Optics and Photonics: Bellingham, WA, USA, 2021. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, S.; Wang, F.; Ling, N. Tread pattern image classification using convolutional neural network based on transfer learning. In Proceedings of the 2018 IEEE International Workshop on Signal Processing Systems, Cape Town, South Africa, 21–24 October 2018; pp. 300–305. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, S.; Li, D.X.; Fan, J.L.; Liu, W. An effective tread pattern image classification algorithm based on transfer learning. In Proceedings of the 3rd International Conference on Multimedia Systems and Signal Processing, Shenzhen, China, 28–30 April 2018; pp. 51–55. [Google Scholar] [CrossRef]
- Shao, H.; Zhong, D. Few-shot palmprint recognition via graph neural networks. Electron. Lett. 2019, 55, 890–892. [Google Scholar] [CrossRef]
- Xu, C.; Sun, Y.; Li, G.; Yuan, H. Few-shot retail product image classification based on deep metric learning. J. Chongqing Univ. Technol. 2020, 34, 209–216. (In Chinese) [Google Scholar]
- Lu, J.; Xie, X.; Li, W. Improved clothing image recognition model based on residual network. Comput. Eng. Appl. 2020, 56, 206–211. [Google Scholar]
- Wu, L.; Li, M. Applying a probabilistic network method to solve business-related few-shot classification problems. Complexity 2021, 2021, 6633906. [Google Scholar] [CrossRef]
- Luo, J.; Wu, J. A survey on fine-grained image categorization using deep convolutional features. Acta Autom. Sin. 2017, 43, 1306–1318. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural Architecture Search with Reinforcement Learning. arXiv 2017, arXiv:1611.01578. [Google Scholar]
- Huang, M.; Huang, Z.; Li, C.; Chen, X.; Xu, H.; Li, Z.; Liang, X. Arch-Graph: Acyclic Architecture Relation Predictor for Task-Transferable Neural Architecture Search. arXiv 2022, arXiv:2204.05941. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8697–8710. [Google Scholar] [CrossRef] [Green Version]
- Real, E.; Aggarwal, A.; Huang, Y.; Le, Q.V. Aging evolution for image classifier architecture search. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Xue, Z.; Duan, L.; Li, W.; Chen, L.; Luo, J. Region Comparison Network for Interpretable Few-shot Image Classification. arXiv 2020, arXiv:2009.03558. [Google Scholar]
- Huang, Z.; Li, Y. Interpretable and accurate fine-grained recognition via region grouping. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8659–8669. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef] [Green Version]
- Furuta, R.; Inoue, N.; Yamasaki, T. PixelRL: Fully Convolutional Network with Reinforcement Learning for Image Processing. IEEE Trans. Multimed. 2020, 22, 1704–1719. [Google Scholar] [CrossRef] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types | Datasets | Source | Categories | Images | Examples |
|---|---|---|---|---|---|
| Simple image datasets | Omniglot | New York University | 1623 | 32,460 |  |
| MNIST | New York University | 10 | 70,000 |  | |
| Complex image datasets | miniImageNet | Google DeepMind team | 100 | 60,000 |  |
| tieredImageNet | University of Toronto | 608 | 779,165 |  | |
| CIFAR-100 | University of Toronto | 100 | 60,000 |  | |
| Caltech101 | California Institute of Technology | 101 | 9146 |  | |
| Special image datasets | CUB-200 | California Institute of Technology | 200 | 6033 |  |
| CIIP-TPID | Xi’an University of Posts and Telecommunications | 69 | 11,040 |  |
| Method | Characteristic | Advantage | Disadvantage |
|---|---|---|---|
| Transfer Learning | Transfer of the useful prior knowledge | Alleviate of overfitting | Negative transfer |
| Meta-Learning | Usage of prior knowledge to guide the learning of new tasks | Excellent performance | Complex model |
| Data Augmentation | Usage of auxiliary information to expand sample data | Prevention of overfitting | Poor generalization ability |
| Multimodal | Usage of the information of auxiliary modalities to classify images | Better feature representation | Hard to train and calculate |
| 5-Way Accuracy (%) | ||||
|---|---|---|---|---|
| Algorithm | Omniglot | miniImageNet | ||
| 1-Shot | 5-Shot | 1-Shot | 5-Shot | |
| MTL [46] | - | - | 61.20 ± 1.80 | 75.50 ± 0.80 |
| SNAIL [47] | 99.07 ± 0.16 | 99.78 ± 0.09 | 55.71 ± 0.99 | 68.88 ± 0.92 |
| Meta-Learner LSTM [51] | - | - | 43.44 ± 0.77 | 60.60 ± 0.71 |
| MAML [54] | 98.7 ± 0.4 | 99.9 ± 0.1 | 48.70 ± 1.84 | 63.11 ± 0.92 |
| Meta-SGD [55] | 99.53 ± 0.26 | 99.93 ± 0.09 | 50.47 ± 1.87 | 64.03 ± 0.94 |
| TAML [56] | 99.5 ± 0.3 | 99.81 ± 0.1 | 51.73 ± 1.88 | 66.05 ± 0.85 |
| RN [58] | 99.6 ± 0.2 | 99.8 ± 0.1 | 50.44 ± 0.82 | 65.32 ± 0.70 |
| MN [59] | 98.1 | 98.9 | 43.56 ± 0.84 | 55.31 ± 0.73 |
| PN [60] | 98.8 | 99.7 | 49.42 ± 0.78 | 68.20 ± 0.66 |
| GNN [67] | 99.2 | 99.7 | 50.33 ± 0.36 | 66.41 ± 0.63 |
| EGNN [68] | 99.7 | 99.7 | 62.3 | 76.37 |
| TPN [69] | 99.2 | 99.4 | 55.51 | 69.86 |
| GCN-NFO [73] | 99.87 | 99.96 | 98.57 | 98.58 |
| MetaGAN [77] | 99.67 ± 0.18 | 99.86 ± 0.11 | 52.71 ± 0.64 | 68.63 ± 0.67 |
| PMN [80] | - | - | 57.6 | 71.9 |
| IDeMe-Net [82] | - | - | 59.14 ± 0.86 | 74.63 ± 0.74 |
| ∆-encoder [84] | - | - | 59.9 | 69.7 |
| AM3 [91] | - | - | 65.30 ± 0.49 | 78.10 ± 0.36 |
| Algorithm | Datasets | 5-Way Accuracy (%) | |
|---|---|---|---|
| 1-Shot | 5-Shot | ||
| Meta Networks [9] | Surface | 53.46 | 78.42 |
| Indentation | 66.13 | 80.45 | |
| Mix | 42.80 | 63.53 | |
| MAML [54] | Surface | 67.09 | 85.55 |
| Indentation | 77.66 | 87.32 | |
| Mix | 46.03 | 64.00 | |
| RN [58] | Surface | 63.97 | 81.60 |
| Indentation | 73.71 | 84.54 | |
| Mix | 48.21 | 65.20 | |
| GNN [67] | Surface | 77.46 | 89.52 |
| Indentation | 77.76 | 92.00 | |
| Mix | 58.04 | 79.98 | |
| GCN-NFO [73] | Surface | 89.12 | 94.04 |
| Indentation | 95.84 | 88.14 | |
| Mix | 99.62 | 88.20 | |
| SFA [85] | Surface | 72.71 | 91.03 |
| Indentation | 76.42 | 91.76 | |
| Mix | 51.84 | 81.02 | |
| Category | Method | Advantage | Disadvantage |
|---|---|---|---|
| Transfer Learning | Instance-based | Easy to implement | Data distribution is often different |
| Feature-based | Good feature selection and transformation | Prone to overfitting | |
| Fine-tuning-based | Alleviate overfitting | The number of iterations should be less | |
| Meta-Learning | Model-based | Strong generalization | Complex model and extensive calculations |
| Optimization-based | Make models learn new tasks quickly | Extensive calculations and high memory consumption | |
| Metric-based | Easy to calculate | Weak interpretability and high memory consumption | |
| Data Augmentation | Data generation-based | Increase sample numbers | Cannot completely solve overfitting |
| Feature enhancement-based | Increase feature numbers | Easy to be disturbed by noise | |
| Multimodal | Knowledge transfer-based | Learn better feature representation | Easy to be disturbed by noise during the fusion process |
| Metric-based | Simple calculation and high accuracy | Weak interpretability and high memory consumption |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Zhang, H.; Zhang, W.; Lu, G.; Tian, Q.; Ling, N. Few-Shot Image Classification: Current Status and Research Trends. Electronics 2022, 11, 1752. https://doi.org/10.3390/electronics11111752
Liu Y, Zhang H, Zhang W, Lu G, Tian Q, Ling N. Few-Shot Image Classification: Current Status and Research Trends. Electronics. 2022; 11(11):1752. https://doi.org/10.3390/electronics11111752
Chicago/Turabian StyleLiu, Ying, Hengchang Zhang, Weidong Zhang, Guojun Lu, Qi Tian, and Nam Ling. 2022. "Few-Shot Image Classification: Current Status and Research Trends" Electronics 11, no. 11: 1752. https://doi.org/10.3390/electronics11111752
APA StyleLiu, Y., Zhang, H., Zhang, W., Lu, G., Tian, Q., & Ling, N. (2022). Few-Shot Image Classification: Current Status and Research Trends. Electronics, 11(11), 1752. https://doi.org/10.3390/electronics11111752