
A Novel Cascade Model for End-to-End Aspect-Based Social Comment Sentiment Analysis



Abstract
:1. Introduction
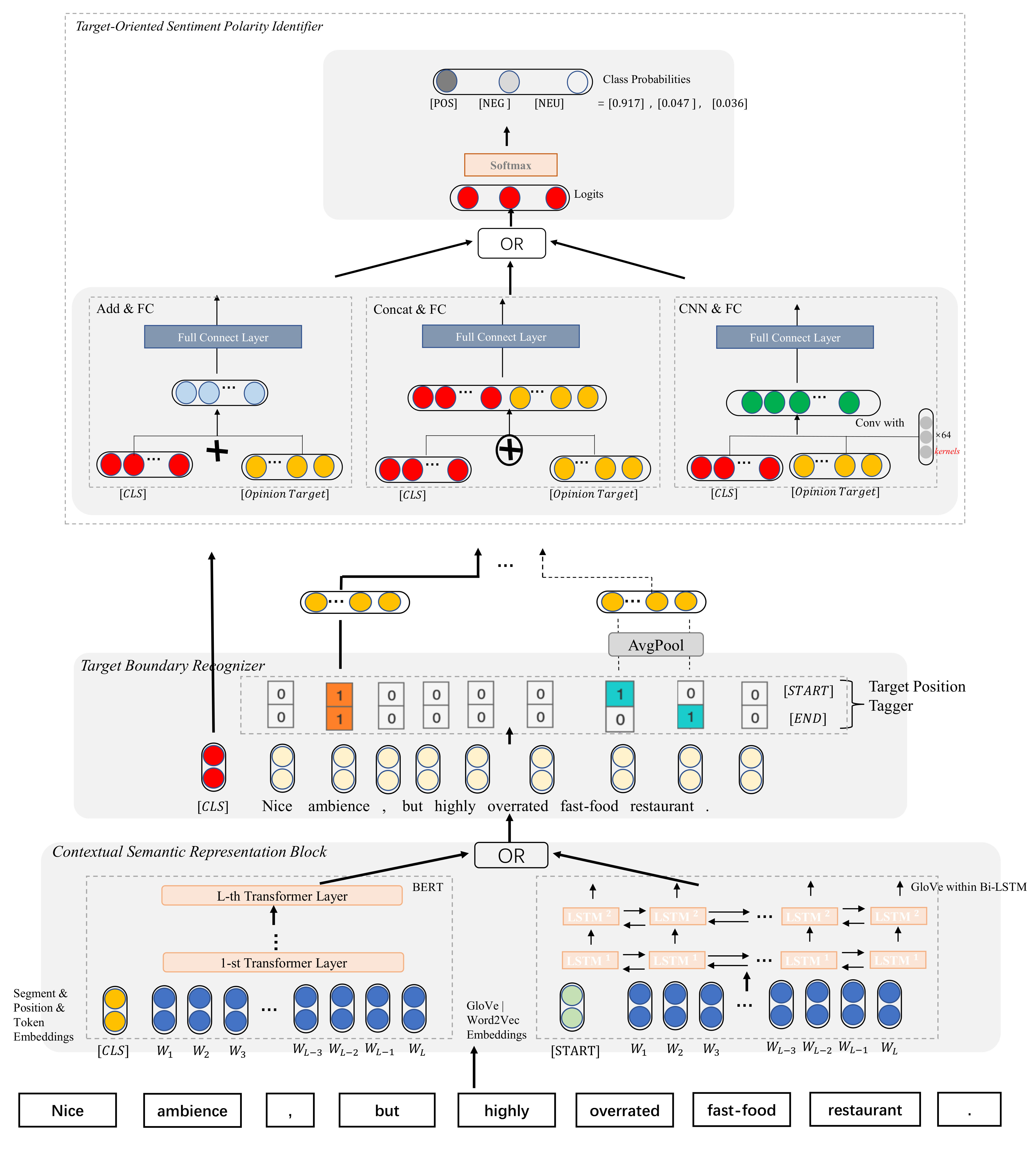
- We go deep into the complete aspect-based sentiment analysis task, and formulate it as the sequence tagging problem of the opinion-target extraction sub-task (OTE) and the multi-label identification problem for the target-oriented sentiment analysis sub-task (TSA). To be specific, we introduce a novel ABSA approach named CasNSA, which is composed of three main sub-modules: contextual semantic representation module, target boundary recognizer and sentiment polarity identifier.
- While many methods attempt to model sub-tasks’ correlations, including machine learning methods and deep learning methods, our method attempts to address the ABSA task by the neural network construction. To the best of our knowledge, the unique modeling mechanism is proposed to handle the ABSA task for the first time. Based on our formulated deduction for the complete ABSA task, we employ the specific opinion-target context representation provided by the OTE into the TSA procedure, which can further constrain and guide the sentiment polarity analysis, thus achieving better performance for the complete end-to-end ABSA task.
- The further empirical comparison result confirms the effectiveness and rationality of our model CasNSA. We first consider the interactive relations modeling between opinion target determining and target-specific sentiment identification. Furthermore, the ablation study also proves that the transformer-based BERT is more efficient in contrast with traditional pre-trained embedding methods (e.g., Word2Vec and GloVe).
2. Related Works
2.1. Separate Approaches
2.2. Pipeline Approaches
2.3. Unified Approaches
3. The CasNSA Framework: Architecture Details
3.1. Task Preliminaries
3.2. Explicit Task Modelling
3.3. Contextual Semantic Representation Block
- Scheme 1: As is illustrated in the bottom right of Figure 1, we first use the 300 dimension GloVe [30] to initialize word embeddings. In the model training and reference time, we add an extra marker ’[START]’ before the start index of the inputs to generate the sentence-level feature vector. Then the embedding operation queries each word’s corresponding embedding and conducts the transfer process . To prevent the vanishing-gradient problem [50] existing in RNNs, we choose the two-layer Bi-LSTM as the basic encoder in which the Bi-LSTM hidden size is set to 200. Existing works [12] have demonstrated a better learning capability than the original LSTM. Compared with vanilla recurrent neural network LSTM, bidirectional-LSTM is the same as LSTM in the mechanical aspect, but Bi-LSTM allows the reversed information flow in which the inputs can be fed from the end index to the beginning index. Finally, the encoder layer provides a forward hidden state and a backward hidden state . We list the LSTM feature propagation’s relevant formulations as follows:The variables and in the above equations are the input, forget and output gate’s activation vectors, respectively. The three gated states and are calculated through a series of complex operations. The updated new memory of LSTM corresponds to the matrix multiplication of the input token feature and the updating matrix and . The remained old memory of LSTM corresponds to the matrix multiplication of the last hidden state and the forgotten matrix and . Finally, LSTM converts the logical value into a prob-value between 0 and 1 through an activation function . Furthermore, ∘ is the cell state vector, and and are the sigmoid and hyperbolic tangent functions.After the information flows through LSTM, we concatenate the forward and backward and obtain the combined features where the j-th hidden state , then the obtained hidden state sequence H is used by the other two downstream tasks, OTE and TBR.
- Scheme 2: For the sake of the disadvantage that the traditional fixed embedding layer (e.g., Word2Vec, and GloVe) only provides a single context-independent representation, as is illustrated in the bottom left of Figure 1, our CSR module further adopts pre-train Transformer BERT [28] during our experiments. Here, we briefly introduce BERT. Bidirectional encoder representations from Transformers, or BERT, is a revolutionary self-supervised pre-train technique that learns to predict intentionally hidden (masked) sections of text. Crucially, the representations learned by BERT have been shown to generalize well to downstream tasks. When BERT was first released in 2018, it achieved state-of-the-art results on many NLP benchmarks. Specifically, BERT is composed of a stack of N () identical Transformer blocks. We denote the Transformer block as , in which N represents the BERT’s depth.Firstly, we pack the sequence of vector inputs as , where the is the initialized BERT embedding vector of the i-th token of the sentence. Then the transformer blocks refine the token-level semantic representation layer by layer. Taking the j-th transformer blocks step as an example, the BERT hidden features are calculated through Equation (9):where the denotes the j-th BERT feature representations and the denotes the {j−1}-th BERT feature representations. Finally, we regard as the contextualized representations of the input sentence, and our CasNSA’s other key components (OTE and TBR) use them for the further downstream model-reasoning step.
3.4. Target Boundary Recognizer
3.5. Sentiment Polarity Identifier
3.6. Training Objective of Target and Sentiment Joint Extractor
4. Experimental Results
4.1. Datasets and Evaluation Metrics
4.2. Parameter Settings
4.3. Compared Models
- LSTM-CRF [54] is a standard sequence tagging framework, which is constructed through the LSTM and CRF decoding layer.
- BERT-LSTM-CRF [55] Different from the above LSTM-CRF model, BERT-LSTM-CRF is a competitive model which employs pre-trained language model BERT rather than the pre-trained word embeddings to learn the character-level word representations.
- E2E-TBSA [17] E2E-TBSA is a novel framework which involves two stacked LSTMs for performing the OTE and TBR sub-tasks, respectively. Meanwhile, it utilizes a unified tagging scheme to formulate ABSA as a sequence tagging problem.
- RACL[19] RACL is a relation-aware collaborative learning framework with multi-task learning and relation propagation techniques. RACL is one of the two RACL implementations which outperforms many state-of-the-art pipeline baselines and unified baselines for the E2E-ABSA task.
- ABSA-DeBERTa [37] ABSA-DeBERTa is a simple downstream fine-tuning model using BERT with disentangled attention for aspect-based sentiment analysis. ABSA-DeBERTa’s disentangled attention mechanism incorporates complex dependencies between aspects and sentiments words and thus obtains state-of-the-art results on benchmark datasets.
4.4. Overall Comparison Results
4.5. Case Study
5. Conclusions and Perspectives
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| NLP | Natural Language Processing–An AI research area |
| E2E-ABSA | End-to-End Aspect-Based Sentiment Analysis–a specific NLP research task |
| BERT | Bidirectional Encoder Representations from Transformers–pre-trained language model |
| SOTA | State-Of-the-Art–obtain the best performance until now |
References
- Jalil, Z.; Abbasi, A.; Javed, A.R.; Badruddin, K.M.; Abul Hasanat, M.H.; Malik, K.M.; Saudagar, A.K.J. COVID-19 Related Sentiment Analysis Using State-of-the-Art Machine Learning and Deep Learning Techniques. Digital Public Health 2022, 9, 812735. [Google Scholar] [CrossRef]
- Khan, M.U.; Javed, A.R.; Ihsan, M. A novel category detection of social media reviews in the restaurant industry. Multimed. Syst. 2020, 1–14. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, Y. Attention Modeling for Targeted Sentiment. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; pp. 572–577. [Google Scholar]
- Zhou, J.; Huang, J.X.; Chen, Q.; Hu, Q.V.; Wang, T.; He, L. Deep Learning for Aspect-Level Sentiment Classification: Survey, Vision, and Challenges. IEEE Access 2019, 7, 78454–78483. [Google Scholar] [CrossRef]
- Liu, B. Sentiment analysis and opinion mining. Synth. Lect. Hum. Lang. Technol 2012, 5, 1–167. [Google Scholar] [CrossRef] [Green Version]
- Jacobs, G.; Véronique, H. Fine-grained implicit sentiment in financial news: Uncovering hidden bulls and bears. Electronics 2021, 10, 2554. [Google Scholar] [CrossRef]
- Li, X.; Bing, L.D.; Li, P.J.; Lam, W.; Yang, Z.M. Aspect term extraction with history attention and selective transformation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, LA, USA, 2–7 February 2018; pp. 4194–4200. [Google Scholar]
- Jaechoon, J.; Gyeongmin, K.; Kinam, P. Sentiment-target word pair extraction model using statistical analysis of sentence structures. Electronics 2021, 10, 3187. [Google Scholar] [CrossRef]
- Xu, H.; Liu, B.; Shu, L.; Yu, P.S. Double embeddings and cnn-based sequence labelling for aspect extraction. In Proceedings of the The 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 592–598. [Google Scholar]
- Fan, Z.F.; Wu, Z.; Dai, X.Y.; Huang, S.; Chen, J. Target-oriented opinion words extraction with target-fused neural sequence labelling. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 29 April–19 May 2019; pp. 2509–2518. [Google Scholar]
- Hazarika, D.; Poria, S.; Vij, P.; Krishnamurthy, G.; Cambria, E.; Zimmermann, R. modelling inter-aspect dependencies for aspect-based sentiment analysis. In Proceedings of the 16th Annual Conference of the North American Chapter of the Association for Computational Linguistics, New Orleans, LA, USA, 1–6 June 2019; pp. 266–270. [Google Scholar]
- Ma, Y.; Peng, H.; Cambria, E. Targeted aspect-based sentiment analysis via embedding commonsense knowledge into an attentive lstm. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2019; pp. 5876–5883. [Google Scholar]
- Wang, S.; Mazumder, S.; Liu, B.; Zhou, M.; Chang, Y. Target-sensitive memory networks for aspect sentiment classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 957–967. [Google Scholar]
- Li, Z.; Wei, Y.; Zhang, Y.; Xiang, Z.; Li, X. Exploiting coarse-to-fine task transfer for aspect-level sentiment classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27–31 January 2019; pp. 4253–4260. [Google Scholar]
- Ma, D.H.; Li, S.J.; Zhang, X.D.; Wang, H.F. Interactive attention networks for aspect-level sentiment classification. In Proceedings of the International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 4068–4074. [Google Scholar]
- Hu, M.H.; Peng, Y.X.; Huang, Z.; Li, D.S.; Lv, Y.W. Open-domain targeted sentiment analysis via span-based extraction and classification. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 537–546. [Google Scholar]
- Li, X.; Bing, L.; Li, P.; Lam, W. A unified model for opinion target extraction and target sentiment prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27–31 January 2019; pp. 6714–6721. [Google Scholar]
- Li, X.; Bing, L.; Lam, W.; Shi, B. Transformation networks for target-oriented sentiment classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 946–956. [Google Scholar]
- Chen, Z.; Qian, T. Relation-aware collaborative learning for unified aspect-based sentiment analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3685–3694. [Google Scholar]
- Li, X.; Bing, L.; Zhang, W.; Lam, W. Exploiting BERT for end-to-end aspect-based sentiment analysis. In Proceedings of the 5th Workshop on Noisy User-generated Text (W-NUT 2019), Hong Kong, China, 4 November 2019; pp. 34–41. [Google Scholar]
- Sun, C.; Huang, L.Y.; Qiu, X.P. utilising BERT for aspect-based sentiment analysis via constructing auxiliary sentence. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 29 April–19 May 2019; pp. 380–385. [Google Scholar]
- Huang, B.X.; Carley, K.M. Syntax-aware aspect level sentiment classification with graph attention networks. arXiv 2019, arXiv:1909.02606. [Google Scholar]
- Zhang, M.; Zhang, Y.; Vo, D.T. Neural networks for open domain targeted sentiment. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 612–621. [Google Scholar]
- Ma, D.; Li, S.; Wang, H. Joint learning for targeted sentiment analysis. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4737–4742. [Google Scholar]
- Wei, Z.P.; Su, J.L.; Wang, Y.; Tian, Y.; Chang, Y. A novel cascade binary tagging framework for relational triple extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 1476–1488. [Google Scholar]
- Yu, B.W.; Zhang, Z.Y.; Shu, X.B.; Liu, T.W.; Wang, Y.B.; Wang, B.; Li, S.J. Joint extraction of entities and relations based on a novel decomposition strategy. In Proceedings of the European Conference on Artificial Intelligence, Santiago de Compostela, Spain, 29 August–8 September 2020; pp. 2282–2289. [Google Scholar]
- Yu, J.F.; Jiang, J. Adapting bert for target-oriented multimodal sentiment classification. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 5408–5414. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 29 April–19 May 2019; pp. 4171–4186. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Twenty-seventh Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global vectors for word representation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Pontiki, M.; Galanis, D.; Pavlopoulos, J.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S. SemEval-2014 task 4: Aspect based sentiment analysis. SemEval 2014, 27–35. [Google Scholar]
- Pontiki, M.; Galanis, D.; Pavlopoulos, J.; Papageorgiou, H.; Manandhar, S.; Androutsopoulos, I. SemEval-2015 Task 12: Aspect Based Sentiment Analysis. SemEval. 2015, pp. 486–495. Available online: https://alt.qcri.org/semeval2015/task12/# (accessed on 1 June 2022).
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S.; AL-Smadi, M.; Zhao, B.Q. SemEval-2016 task 5: Aspect based sentiment analysis. SemEval 2016, 19–30. [Google Scholar]
- Andres, L.F.; Coromoto, C.Y.; Nabhan, H.M. Sentiment analysis in twitter based on knowledge graph and deep learning classification. Electronics 2022, 10, 2739–2756. [Google Scholar]
- Song, Y.W.; Wang, J.H.; Jiang, T.; Liu, Z.Y.; Rao, Y.H. Attentional encoder network for targeted sentiment classification. arXiv 2019, arXiv:1902.09314. [Google Scholar]
- Li, X.L.; Li, Z.Y.; Tian, Y.H. Sentimental Knowledge Graph Analysis of the COVID-19 Pandemic Based on the Official Account of Chinese Universities. Electronics 2021, 10, 2921. [Google Scholar] [CrossRef]
- Yadav, R.K.; Jiao, L.; Granmo, O.-C.; Goodwin, M. Human-Level Interpretable Learning for Aspect-Based Sentiment Analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021; pp. 14203–14212. [Google Scholar]
- Granmo, O.-C. The Tsetlin Machine—A Game The oretic Bandit Driven Approach to Optimal Pattern Recognition with Propositional Logic. arXiv 2018, arXiv:abs/1804.01508. [Google Scholar]
- Wang, W.Y.; Pan Sinno, J.; Dahlmeier, D.; Xiao, X.K. Coupled multi-layer attentions for co-extraction of aspect and opinion terms. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2019; pp. 3316–3322. [Google Scholar]
- Chen, Z.; Qian, T.Y. Transfer capsule network for aspect level sentiment classification. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 547–556. [Google Scholar]
- Li, H.; Lu, W. Learning latent sentiment scopes for entity-level sentiment analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2019; pp. 3482–3489. [Google Scholar]
- He, R.D.; Lee, W.S.; Ng, H.T.; Dahlmeier, D. An interactive multi-task learning network for end-to-end aspect-based sentiment analysis. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 504–515. [Google Scholar]
- Mitchell, M.; Aguilar, J.; Wilson, T.; Van Durme, B. Open domain targeted sentiment. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1643–1654. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F. Conditional random fields: Probabilistic models for segmenting and labelling sequence data. In Proceedings of the 18th International Conference on Machine Learning, Freiburg, Germany, 12 September 2001; pp. 282–289. [Google Scholar]
- Silva, E.H.; Marcacini, R.M. Aspect-based sentiment analysis using BERT with Disentangled Attention. In Proceedings of the 8th ICML Workshop on Automated Machine Learning (AutoML 2021), Virual Event, 23–24 July 2021. [Google Scholar]
- Locatello, F.; Bauer, S.; Lucic, M.; Raetsch, G.; Gelly, S.; Scholkopf, B.; Bachem, O. Challenging common assumptions in the unsupervised learning of disentangled representations. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 4114–4124. [Google Scholar]
- He, P.; Liu, X.; Gao, J.; Chen, W. DeBERTa: Decoding-enhanced BERT with Disentangled Attention. arXiv 2020, arXiv:abs/2006.03654. [Google Scholar]
- Deng, J. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Catelli, R.; Serena, P.; Massimo, E. Lexicon-Based vs. Bert-Based Sentiment Analysis: A comparative study in Italian. Electronics 2022, 11, 374. [Google Scholar] [CrossRef]
- Roodschild, M.; Sardiñas, J.G.; Will, A. A new approach for the vanishing gradient problem on sigmoid activation. Prog. Artif. Intell. 2020, 9, 351–360. [Google Scholar] [CrossRef]
- Tao, Q.; Luo, X.; Wang, H.; Xu, R. Enhancing Relation Extraction Using Syntactic Indicators and Sentential Contexts. In Proceedings of the IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; pp. 1574–1580. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 515–526. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. In Proceedings of the 15th Annual Conference of the North American Chapter of the Association for Computational Linguistics, San Diego, CA, USA, 12–16 June 2016; pp. 260–270. [Google Scholar]
- Liu, L.; Shang, J.; Xu, F.; Ren, X.; Gui, H.; Peng, J.; Han, J. Empower sequence labeling with task-aware neural language model. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Shen, T.; Zhou, T.; Long, G.; Jiang, J.; Pan, S.; Zhang, C. Disan: Directional self-attention network for rnn/cnn-free language understanding. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]

{kind=link}
| Input | Nice | Ambience | , | But | Highly | Overrated | Fast-Food | Restaurant | . |
|---|---|---|---|---|---|---|---|---|---|
| Discrete | O | S | O | O | O | O | B | E | O |
| O | POS | O | O | O | O | NEG | NEG | O | |
| Integrated | O | S-POS | O | O | O | O | B-NEG | E-NEG | O |
| Sentence | The | Reason | I | Choose | Apple | MacBook | Is | Their | Designs | And | User | Experiences |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 |
| Dataset | # POS | # NEG | # NEU | Train | Dev | Test | Total |
|---|---|---|---|---|---|---|---|
| SemEval2014 | 4226 | 1986 | 1442 | 5477 | 608 | 1600 | 7685 |
| SemEval2015 | 1241 | 445 | 70 | 1183 | 685 | 130 | 1998 |
| SemEval2016 | 1712 | 565 | 101 | 1799 | 200 | 676 | 2675 |
| 698 | 271 | 2254 | 1903 | 220 | 234 | 2357 |
| Models | SemEval2014 | SemEval2015 | SemEval2016 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Prec | Rec | F1-val | Prec | Rec | F1-val | Prec | Rec | F1-val | Prec | Rec | F1-val | |
| LSTM-CRF | 58.66 | 51.26 | 54.71 | 60.74 | 49.77 | 54.71 | 53.71 | 50.27 | 51.91 | 53.74 | 42.21 | 47.26 |
| BERT-LSTM-CRF | 53.31 | 59.40 | 56.19 | 59.39 | 52.94 | 55.98 | 57.55 | 50.39 | 53.73 | 43.52 | 52.01 | 47.35 |
| E2E-TBSA | 69.83 | 56.76 | 61.62 | 63.60 | 52.27 | 57.38 | 58.96 | 51.41 | 54.92 | 53.08 | 43.56 | 48.01 |
| BERT+SAN | 71.32 | 61.05 | 65.79 | - | - | - | 60.75 | 50.24 | 55.00 | - | - | - |
| RACL | 77.24 | 59.06 | 66.94 | 69.90 | 53.03 | 60.31 | 59.28 | 52.56 | 55.72 | 52.37 | 46.75 | 49.40 |
| ABSA-DeBERTa | 81.57 | 64.74 | 72.19 | 92.68 | 63.24 | 75.18 | 94.07 | 69.27 | 79.79 | 71.56 | 53.69 | 61.35 |
| GloVe-CasNSA-sba | 66.79 | 61.18 | 63.86 | 63.15 | 55.20 | 58.91 | 57.52 | 50.15 | 53.58 | 52.33 | 45.52 | 48.69 |
| GloVe-CasNSA-svc | 69.21 | 62.55 | 65.71 | 65.28 | 54.74 | 59.55 | 59.56 | 49.76 | 54.22 | 53.17 | 44.96 | 48.72 |
| GloVe-CasNSA-cnn | 68.47 | 61.72 | 64.92 | 64.74 | 54.64 | 59.26 | 60.08 | 49.14 | 54.06 | 52.60 | 44.80 | 48.39 |
| Bert-CasNSA-sba | 70.66 | 62.43 | 66.29 | 65.37 | 57.35 | 61.10 | 62.23 | 51.12 | 56.13 | 54.76 | 45.56 | 49.74 |
| Bert-CasNSA-svc | 71.29 | 65.24 | 68.13 | 67.38 | 56.95 | 61.73 | 62.17 | 51.61 | 56.40 | 56.93 | 44.65 | 50.05 |
| Bert-CasNSA-cnn | 70.48 | 65.60 | 67.95 | 66.82 | 58.65 | 62.34 | 61.48 | 51.37 | 55.97 | 55.62 | 45.06 | 49.79 |
| S1 | Sentence 1: The [teas]pos are great and all the [sweets]pos are homemade. | |||||
| S2 | Sentence 2: [Sushi]pos so fresh that it crunches in your mouth. | |||||
| S3 | The [performance]pos seems quite good, and [built-in applications]pos like [iPhoto]pos work great with my phone and camera. | |||||
| Sentence | PIPELINE | CasNSAGloVe | CasNSABERT | |||
| OTE | TBR | OTE | TBR | OTE | TBR | |
| S | teas (✓) | POS (✓) | teas (✓) | POS (✓) | teas (✓) | POS (✓) |
| None (✗) | None (✗) | sweets (✓) | POS (✓) | sweets (✓) | POS (✓) | |
| S | Sushi (✓) | NEU (✗) | Sushi (✓) | POS (✓) | Sushi (✓) | POS (✓) |
| S | performance (✓) | POS (✓) | performance (✓) | POS (✓) | performance (✓) | POS (✓) |
| None (✗) | None (✗) | built-in applications (✓) | POS (✓) | built-in applications (✓) | POS (✓) | |
| iPhoto (✓) | None (✗) | iPhoto (✓) | None (✗) | iPhoto (✓) | POS (✓) | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, H.; Huang, S.; Jin, W.; Shan, Y.; Yu, H. A Novel Cascade Model for End-to-End Aspect-Based Social Comment Sentiment Analysis. Electronics 2022, 11, 1810. https://doi.org/10.3390/electronics11121810
Ding H, Huang S, Jin W, Shan Y, Yu H. A Novel Cascade Model for End-to-End Aspect-Based Social Comment Sentiment Analysis. Electronics. 2022; 11(12):1810. https://doi.org/10.3390/electronics11121810
Chicago/Turabian StyleDing, Hengbing, Shan Huang, Weiqiang Jin, Yuan Shan, and Hang Yu. 2022. "A Novel Cascade Model for End-to-End Aspect-Based Social Comment Sentiment Analysis" Electronics 11, no. 12: 1810. https://doi.org/10.3390/electronics11121810
APA StyleDing, H., Huang, S., Jin, W., Shan, Y., & Yu, H. (2022). A Novel Cascade Model for End-to-End Aspect-Based Social Comment Sentiment Analysis. Electronics, 11(12), 1810. https://doi.org/10.3390/electronics11121810