2.2. Dynamically Updated-Auto-Regressive Integrated Moving Average
After data pre-processing, it is necessary to predict the subsequent time-step of the historical data. To improve the accuracy of the data prediction, the DU-ARIMA method is proposed. DU-ARIMA is an improved auto-regressive integrated moving average (ARIMA) designed to improve the prediction accuracy of ARIMA [
28]. The DU-ARIMA(
p,
d,
q) model can be expressed as
where
is the current time-series,
is the random interference of the time-series, and
is the delay operator. For a time-series,
,
, ⋯,
, for random interference,
,
, ⋯,
.
.
,
p is the order of the auto-regressive model,
q is the order of the moving average model, and
d is the order of the difference.
The essence of DU-ARIMA model is the combination of the difference operation and dynamic updated-auto-regressive moving average (DU-ARMA) models. This means that any non-stationary series is stationary after one or more difference operations. Therefore, when using the DU-ARIMA model to predict the non-stationary sequence, firstly, the non-stationary sequence is transformed into a stationary sequence after a difference operation. Secondly, the DU-ARMA model is used to predict the stationary sequence. Finally, the non-stationary sequence-prediction value can be obtained by recovering the difference operation.
We let
, where
. After applying the above difference operation, Equation (
1) can be transformed into the auto-regressive moving average (ARMA) model without considering the condition that
can be dynamically updated, which is expressed as
According to the stationarity and reversibility of the ARMA model, the ARMA process has both the infinite moving average representation
, and the infinite auto-regressive representation
. For the infinite moving average representation, the time-series
can be represented by a linear function of random interference terms, see Equation (
3). Then, the true value of the subsequent
l time-steps of the time-series can be expressed by Equation (
4).
Since
,
,⋯,
cannot be obtained,
can only be estimated by the linear combination of
,
,
,⋯, denoted by
, which is recorded as Equation (
5). From this, the prediction error value of the ARMA model’s infinite moving average representation can be obtained, see Equation (
6) for details. Equation (
7) is the variance of the prediction error for the ARMA model’s infinite moving average representation.
Only when
, is the value of the prediction error the smallest. At this time,
,
and
can be expressed by Equations (8)–(10), respectively.
For the dynamic updated-infinite moving average representation, considering the fact that the condition
can be dynamically updated to obtain (
also can be obtained by difference operation),
is known. The estimated value of the subsequent
l time-steps after the dynamic update can be expressed by Equation (
11). The prediction error value after the dynamic update is shown in Equation (
12). Equation (
13) is the variance of the prediction error for the dynamic updated-infinite moving average representation.
It is clear that the variance of the prediction error for a dynamic updated-infinite moving average representation Equation (
13) is smaller than that of an ARMA’s infinite moving average representation (Equation (
10) by
.
The infinite auto-regressive representation
can be also expressed as
or
It can be seen from Equation (
15) that the essence of infinite auto-regressive representation is to predict
by the known historical data,
,
,
,⋯. It is easy to draw the conclusions that: if the predicted time-step
l is longer, the more unknown data there will be, and the lower the accuracy of data prediction will be. However, for the dynamic updated-infinite auto-regressive representation, it can continuously obtain new monitoring data,
,
,⋯, based on the original historical data
,
,
,⋯. This means that the number of unknown data is reduced, which can improve the prediction accuracy of
. The variance of the prediction error for a dynamic updated-infinite auto-regressive representation is smaller than that of an infinite auto-regressive representation by
(similar to the variance of the prediction error for a dynamic updated-infinite moving average representation, see
Appendix A for details).
The DU-ARMA model can be seen as a combination of the dynamic updated-infinite moving average representation and the dynamic updated-infinite auto-regressive representation, so the variance of the prediction error of the DU-ARMA model is smaller than that of the ARMA model. According to the difference relationship between DU-ARMA and DU-ARIMA, the DU-ARIMA model obtained after the recovery difference operation can predict the non-stationary sequence, and the variance of the prediction error of DU-ARIMA model is also smaller than that of the ARIMA model. The essence of the DU-ARIMA model is to input the current monitoring data into the ARIMA model in real time to realize the dynamic update of historical data. The term “dynamic updated” in DU-ARIMA means that the user can access the real value of the current time-step to update the model before predicting the next time-step. Therefore, DU-ARIMA can effectively improve the accuracy of data prediction. The quality of the DU-ARIMA prediction result can be measured by the root mean square error (RMSE). The smaller the RMSE value, the better the DU-ARIMA prediction result.
2.3. Multiple Isolation Forest
For the difficulty of obtaining degradation malfunction samples, the multiple isolation forest (M-iForest) model is selected to predict the degradation malfunction of historical monitoring data and predicted data. To know what M-iForest is, it is necessary to start with isolation forest. Isolation forest is an effective unsupervised outlier detection model [
29]. Its main idea is that outliers are few and different.
If isolation forest alone is used to predict the degradation malfunction, there are two main processes. Firstly, the historical monitoring data and predicted data are randomly sampled to construct an isolation binary tree. Secondly, the malfunction score of each data point is obtained through the isolation forest established by the isolation binary tree. The specific process is shown in part 1 inside the dashed box of
Figure 2. To solve the problems of swamping (normal samples are recognized as outliers) and masking (too many outliers to cover up the existence of abnormality) caused by too much data, multiple isolation binary trees are constructed by random sub-sampling. However, the formation of binary trees is random, which makes it unreliable for a single isolation binary tree to find outliers using shorter paths. Therefore, multiple isolation binary trees are formed into an isolation forest to improve reliability. For any sample,
x, the malfunction score can be calculated using Equations (16)–(18), where
is the malfunction score,
is the average value of the sample
x path length
in a set of isolation trees,
is the average path length of the unsuccessful search in the isolation binary tree for the given
n samples,
is the number of harmonics, and
is Euler’s constant. The calculated malfunction score, s, is in the range of [0, 1]. If s is closer to 1, it means that the sample is more likely to be a degradation malfunction sample. Conversely, if s is closer to 0, it indicates that the sample is more likely to be a normal sample.
To further improve the reliability and stability of isolation forest, an M-iForest model is proposed, which aims to construct many isolation forests to ensure the stability of the malfunction prediction and evaluate the model, as shown in
Figure 2 for a whole model. The generalizability and stability of the model can be evaluated by the area under curve (AUC). The model will obtain multiple AUC values, because of the construction of multiple rounds of isolation forests. If the average of AUC is closer to 1, the better the model effect and the stronger the generalization ability, while the smaller the variance of AUC, the better the stability of the model.
















{kind=link}
{kind=link}
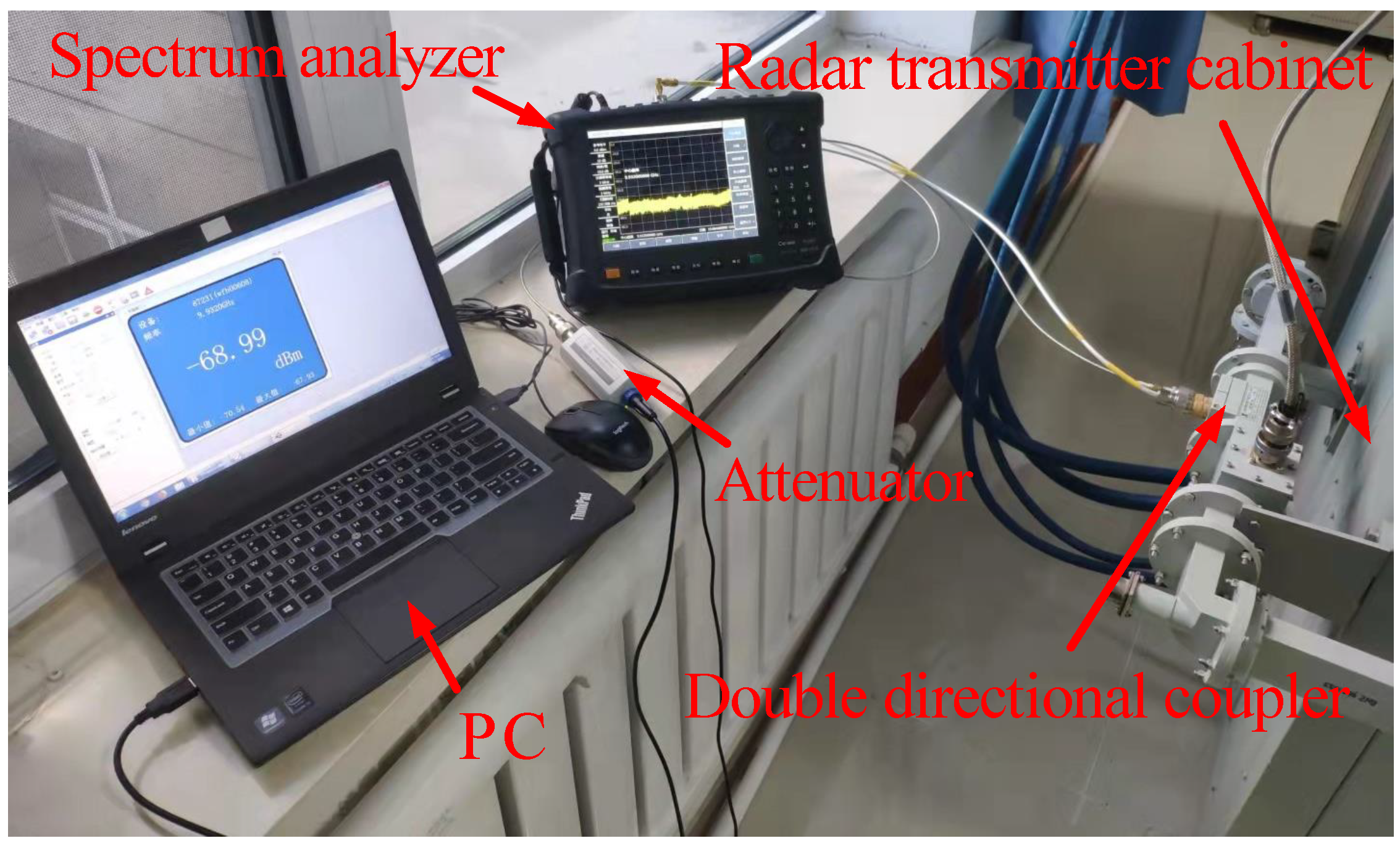{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}