1. Introduction
With the plethora of cloud services in the marketplace, the selection of a trustworthy cloud service is often a difficult task for a consumer. The service offerings from different cloud service providers (CSP) claim to meet the highest quality of service (QoS), confirming service level agreement (SLA), and regularity compliance, namely, General Data Protection Regulation (GDPR) [
1] and Safe Harbor [
2]. In such cases, how a cloud service user (CSU) can get an assurance that a CSP actually complies with the SLA and takes into consideration the user preferences.
Trust plays an important role in establishing a dependable relationship between a CSP and CSU. To date, numerous trust computation models have been proposed in the literature wherein the trustworthiness of a cloud service is assessed on various dimensions, namely, service quality, user feedback, competence, integrity, benevolence, honesty, capability, etc. [
3,
4]. However, the existing models have a number of limitations, as discussed below.
First, trust computation is based on a single source of evidence, i.e., QoS, expert opinion, or user feedback. Second, trust computation is carried out by CSPs themselves, which raises concerns over the transparency of the process. The CSPs might not take into consideration the negative user feedback or blacklist such users. Third, in trust computation models based on subjective logic [
5,
6,
7,
8], the weights are assigned by the experts, which in some cases might not be accurate as human judgements are often prone to error. Fourth, the credibility of user feedback is not evaluated, meaning that in some cases, CSUs may behave maliciously and report false feedback regarding their quality of experience (QoE). CSUs can carry out collusion and Sybil attacks to slander/self-promote cloud services. Therefore, the trust computed in such cases could be misleading and inaccurate.
1.1. Motivation
Considering the limitations of existing approaches, in this paper, we propose a novel trust computation framework (TCF) for cloud services. In our proposed TCF, the trust of a cloud service is computed by fusing evidence from monitored QoS and user feedback. The multi-faceted trust assessment guarantees that several factors are considered in trust computation. As discussed above, the trust in a cloud service is computed by the aggregation of QoS evidence and user feedback. To make it clearer, we introduce two notions of trust, namely, objective and subjective. From here onwards, trust computed from QoS would be referred to as objective trust, whereas the trust computed from user feedback would be referred to as subjective trust.
For the objective trust computation, we employ the random forest regression model. Machine learning models, specifically regression and classification, have already been used for solving various computational problems. Likewise, we believe regression models could be employed to predict the trust in a cloud service based on a number of features related to the service quality. Another advantage of regression models is that weight allocation is automatic and eliminates the need for an expert opinion or manual weight inputs.
Moreover, the trust computation process is entrusted to a trusted third party, namely a broker. The trust appraisal by the broker ensures that the trust process is transparent and preserves the privacy of user feedback. Additionally, our proposed TCF includes several modules for user feedback credibility assessment, which subsequently prevents malicious behaviour, namely collusion and Sybil attacks. Computing the credibility of user feedback can help in not only preventing collusion and Sybil attacks but also adjusting the trust of affected cloud services. Besides that, we have observed that very few studies take into consideration feedback credibility and multi-dimensional feedback criteria for subjective trust. The multi-dimensional QoS and QoE evidences enable a precise and accurate trust assessment, which subsequently helps the CSPs to better tailor and/or personalize the cloud services as per the user’s requirements.
1.2. Contribution
Following are our main contributions. First, a novel TCF for precise and accurate trust computation of cloud services is proposed. Second, a feedback credibility assessment model that protects against collusion and Sybil attacks is proposed.
The rest of this paper is organized as follows. The related work is discussed in
Section 2. Our proposed TCF is elaborated upon in
Section 3. The experimental results of the proposed TCF are presented in
Section 4. The conclusion and future work are discussed in
Section 5.
2. Background and Related Work
In this section, we will first present a brief overview of the trust models. Next, we will review recent trust models proposed for cloud services. We will also discuss the trust models proposed for fog computing. We will then describe the models based on machine learning as it seems to be a robust approach for predicting trust.
The trust computation models are categorized based on the type of evidence, parameters, and the methodology used for aggregating the evidence. The evidence can be subjective, for example, the feedback of cloud service users, and it can be objective, where the QoS is evaluated by monitoring the various service parameters. The depth and breadth of the literature on trust models is immense, and various studies have based their trust computation on different parameters; for example, some use resource availability, hardware specifications, task success ratio, and other use competence, security, privacy, and trustworthiness. Some studies compute trust solely based on one type of evidence, QoS parameters or user feedback.
When it comes to trust computation models, there are two main types, (1) subjective trust and (2) objective trust. Subjective trust is quantified based on the direct interactions between the trustor and trustee. As mentioned above, subjective trust is computed based on user feedback, reviews, and ratings. The experts in certain fields often use their personal experience to evaluate the interactions between systems and users. Objective trust is computed based on the evidence gathered from multiple sources, similar to a reputation-based approach. The evidence for objective trust computation is gathered by deploying real-time monitoring tools. The evidence can be aggregated in two ways, subjective logic [
5] and real-time adaptive trust computation [
9,
10]. The main difference between the two approaches is the manner in which weights are assigned; in the former, they are assigned manually and/or based on personal preferences, and in the latter, they are assigned using the maximizing deviation method [
10], information entropy [
9], and regression [
11,
12,
13]. Besides these, some studies employ both subjective and objective trust to evaluate the trustworthiness of systems [
6,
10,
14,
15]. Such a hybrid approach avoids the system/user bias and guarantees that trust is computed based on different types of collective evidence. Therefore, our review of the literature is also based on the aforementioned trust computation approaches, and for each study we cite, we will describe the evidence, parameters, and trust aggregation method, objective, subjective, and hybrid.
Recently, Manel et al. [
16] proposed a trust model for cloud service selection. The model is based on a Naive Bayes probabilistic classifier and uses the correlation among QoS parameters to predict missing ratings. This work only used objective evidence and do not consider the user feedback in service selection. The QoS evidence alone is not enough to assess the trustworthiness of cloud services, as it can be fabricated by the providers and necessitate employing user’s QoE ratings in trust computation. Balcao et al. [
17] propose a trust assessment framework for cloud providers. This is an interesting work that employs multi-dimensional evidence about governance, transparency, information security, and QoS parameters to compute the trust. It also considers the user feedback but does not evaluate its credibility before incorporating it into the trust model. Another limitation of this work is rather simplistic formal modelling based on arithmetic and geometric means. Such models cannot capture the recentness of the evidence and will use all available data in the computation, and can produce inaccurate results regarding the performance and trustworthiness of CSPs. In addition to that, it is not clear how the consumers can rate crude qualitative dimensions of governance, transparency, and security, as usually naive users do not have access to tools that are required to assess these. Ahmed et al. [
18] propose an objective trust computation model for the selection of dependable service from a federation of cloud services. The assessment is based on QoS parameters consisting of node profile, reliability, and competency. This model neither considers user feedback nor provides any attack resiliency.
Golnaz et al. [
19] propose a subjective trust model that employs user feedback to assess the trustworthiness of CSPs. In comparison to other studies [
20,
21] that also incorporate feedback, this work proposes some components that can improve the quality of user feedback by addressing the data sparsity and invalidity problems. A key limitation of this study is the inconsideration of objective evidence. Doa et al. [
22] conducts a study to compare existing trust models, analytical hierarchy process (AHP), fuzzy analytical hierarchy process (FAHP), fuzzy technique for order preference by similarity to ideal solution (FTOPSIS), multi-criteria decision-making (MCDM), and the technique for order preference by similarity to ideal solution (TOPSIS). These models are compared via ratings gathered on performance, agility, finance, security, and usability criteria using a hybrid fuzzy logic method and multi-criteria decision-making techniques. The comparison is based on QoS evidence gathered from the Cloud Analyst application, which is part of the widely used CloudSim simulator. This study also does not take into consideration user feedback. Chen et al. [
23] propose a hierarchical trust model for IoT services. The consumers report their first-hand experience and recommendations, which are later used in computing subjective trust by incorporating the social relationships between IoT devices. This model provides some security against malicious attackers. Compared to other studies, this work does not consider the objective evidence in trust computation.
Among several parameters that are used to compute trust, competence and trustworthiness are the most important ones. The work in [
15] approximates the risk of interactions with new and/or unknown cloud service providers based on these two parameters. Trustworthiness is evaluated on the basis of the direct interactions with the vendors and their established reputation. In other words, it is a subjective evaluation. For competence, the service level agreements (SLAs) are assessed for transparency in outlining the quality of service (QoS) parameters and the relevant terms and conditions. The study in [
24] proposes a trust computation model that uses both subjective and objective evidence to compute the trust for cloud services. The work in [
6] devises a hybrid model to evaluate the trustworthiness of cloud services. The objective trust is quantified based on the real-time parameter measurements, whereas the subjective trust is quantified on the basis of prior direct experiences and the recommendations of others if first-hand evidence cannot be acquired. The study in [
25] devised a service ranking algorithm for helping the system designers and users to select highly rated cloud services.
The work in [
7] uses only one source of objective evidence to compute the trust based on subjective logic. It completely disregards user feedback. In contrast to the above study, the work in [
8] evaluates the trustworthiness of the web services based on user preferences. The trust is computed using subjective logic and considers the credibility of the user ratings as sometimes malicious users can give false feedback to decrease/increase the trust. A major limitation of this work is the inconsideration of QoS parameters, making it unsuitable for cloud services. Another work that evaluates the credibility of user feedback feeding it into computation, is proposed in [
21]. The reputation-based trust model is based on the subjective trust that is computed by taking feedback on multiple dimensions, namely, usability, accessibility, availability, price, customer service, etc. Additionally, a feedback credibility model is proposed to protect cloud services against malicious behaviour (e.g., collusion or Sybil attacks) from its users. The collusion attacks are detected by quantifying the number of feedbacks given by a CSU and subsequently lowering the impact of multiple feedback ratings by the feedback density parameter. This approach is not a viable solution for real-world cloud services, as only a certain amount of feedback can be considered in a trust computation while the rest is discarded. Besides that, a major limitation of this work [
21] is that trust is computed from user feedback only. However, it is evident that both direct evidence and user feedback should be considered in assessing the trustworthiness of cloud services. The real-time evaluation of QoS parameters can give actual insights into service quality.
Next, we discuss trust models that use fog computing as the trust computation entity. The study in [
26] proposes a trust model for vehicular ad hoc networks (VANETS). The dependability and reliability of such systems highly rely on data integrity such that messages are not modified when they are transmitted from one vehicle to another. This work uses experience and plausibility as trust parameters to compute the trust using fuzzy logic. Evaluating the trustworthiness of entities in multi-hop sensor networks is essential to guarantee the dependability of the system. The work in [
27] designs a hierarchical trust model for evaluating the performance of the sensor devices, edge devices, and service providers. The trust is computed at the fog layer to ensure the trust ratings are accessible in real-time with no and/or negligible delay and latency. Recently, the work in [
13] proposes a trust management system to compute the trust for different entities in a fog-based cyber-physical system (CPS). This is an objective trust computation model wherein the final trust in fog nodes is computed by combining the evidence gathered from IoT devices and a fog monitoring node. The credibility of evidence coming from CPS devices is evaluated to guarantee the inputs are secure and have not been modified by malicious adversaries. Next, we discuss the machine learning-based trust models.
Since machine learning is widely being used for classification and prediction problems, some the recent studies have employed it to predict the trust of cloud services based on a number of features. The work in [
12] uses multiple linear regression (MLR) to predict the trust of sensor networks wherein the cloud provides the backend services. Likewise, in [
11], logistic regression is used to compute the trust in MANETS.
Discussion
Now we draw on some conclusions from our review of the related studies.
Table 1 presents a comparison of state-of-the-art trust models for cloud services. The
Type column defines the type of trust model, the
Evidence column lists the evidence used, the
Aggregation Method column describes the method used to combine/fuse the evidence, and the
Security Measures column describes the countermeasures against attacks. It is believed that a multi-dimensional assessment of cloud services is essential to achieve better insights into QoS and QoE. It can be observed that, except ours, only two more studies [
17,
24] use objective and subjective evidence for evaluating the trustworthiness of cloud services.
Incorporating user feedback in trust computation provides insights into the service quality experienced by CSUs, but, at the same time, it also provides an opportunity to adversaries to exploit it to change (increase/decrease) the trust of CSPs. The identification of malicious feedback is vital to prevent malicious behaviour (i.e., Sybil and collusion attacks) of CSUs and subsequently computing a precise and accurate trust of cloud services. From
Table 1, only five studies, including ours [
11,
19,
21,
27], have some mechanism to address the security issues in user feedback. Interestingly, all of these studies are either based on objective or subjective assessment, and none of them fuses multiple sources of evidence like this study. Furthermore, adaptive trust evaluation approaches are better than subjective logic as they do not require weight inputs from experts. It is better to adopt a data-driven approach to compute the trust and derive the weights based on the features gathered from objective evidence, QoS parameters in this case. Machine learning algorithms such as multiple linear regression and random forest regression can be used for trust prediction.
Considering the limitations of existing studies, we propose a new TCF in which we evaluate cloud services on multi-dimensional criteria and apply a credibility model to countermeasure the malicious behaviour of cloud users. We predict the objective trust of cloud services by using a random forest regression model.
3. Proposed Trust Computation Framework
Now, we introduce our proposed framework that enables the broker to precisely and accurately compute the trust of cloud services.
Figure 1 illustrates the proposed TCF. There are three types of entities, namely, cloud services, CSUs, and a broker. Infrastructure as a service (IaaS), platform as a service (PaaS), and software as a service (SaaS) are three popular cloud services. Moreover, nowadays, some special and/or dedicated services (i.e., security, trust) are also offered by CSPs. Since the cloud services are offered by CSPs, the trust of a service reflects the QoS provided by the CSP. From here onwards, the terms cloud service and CSP are used interchangeably. Brokers assist CSUs in finding services matching their requirements, which are offered by various CSPs. Moreover, brokers are also responsible for trust computation and management. Each CSP is required to register its services with the broker.
Trust gained by a cloud service reflects its performance based on directly monitored QoS evidence and user feedback. To be more specific, the trust score of a cloud service is the aggregation of trust computed from the evidence gathered by the broker and CSUs. The broker monitors the QoS parameters and computes the objective trust. The CSUs also provide feedback regarding their experience with the CSP. The feedback is subsequently sent to the broker, which computes subjective trust on behalf of CSUs. The various QoS parameters and feedback factors incorporated in trust computation are listed in
Table 2. It is underlined that for all types of trust, namely, objective, subjective, and final trust of cloud services, trust lies in the range of
. It is represented as a fraction. The proposed TCF consists of eight submodules, namely:
Preference Manager
Service Matching
SLA Manager
Credibility Assessment
QoS Monitoring
Objective Trust
Subjective Trust
Trust Computation
The details of each of these modules are given below.
3.1. Preference Manager
This module handles the user preferences on the basis of their service requirements. Service specifications, i.e., processing, computational, and storage, for an IaaS can be defined in the form of requirements, whereas the security, privacy, and legal aspects can be covered in preferences.
3.2. Service Matching
Initially, the CSPs register all their services with the broker. The service matching module takes service requirements as an input from the preference manager and performs the resource matching on the available cloud services. The resource matching is performed on the basis of a well-defined criterion. For service selection, the broker checks the trust of services that have matched the user requirements and selects the one with the highest trust value.
3.3. SLA Manager
Once the CSU selects a particular cloud service, it will negotiate the SLA details with the CSP provider. An SLA contract is signed between the CSU and CSP based on a number of required service quality attributes. The SLA guarantees a minimum expected level of service quality between the CSUs and CSPs.
3.4. QoS Monitoring
This module monitors the QoS parameters of CSP by pulling in the run-time service statistics. Our choice of parameters is motivated by [
13], but they have used it for fog nodes. Since the cloud services are like large-scale fog nodes, it was rational for us to use the same parameters as them. The broker monitors four kinds of parameters (see
Table 2), namely (1) service specification, (2) average resource usage, (3) average response time, and (4) average task success ratio. The service specification profile includes CPU frequency, memory size, hard disk capacity, and energy consumption. The average resource usage information consists of the current CPU utilisation rate, current memory utilisation rate, current hard disk utilisation rate and current bandwidth utilisation rate. The broker stores the QoS data in a monitoring database and later uses it for objective trust computation.
3.5. Objective Trust Computation
Once the service quality is monitored by the broker, the next task is the objective trust computation. For
, the broker acquires/quantifies eight different QoS parameters listed in
Table 2, at discrete time instances
. For evaluating the service quality, the objective trust prediction is modelled as a random forest regression problem. The monitored QoS parameters (check
Table 2) are the input features.
at time is predicted using a random forest regression model established using available training samples that include input feature sets and labelled output of . The random forest regression is a type of supervised learning model that learns from the training sample data (including ground truths in the output samples). The random forest regression model makes predictions by combining the predictive outputs of several decision tree models.
Let us suppose if there are
n number of decision tree models, each denoted by
, then the regression model is formalized using Equation (
1):
where
is the weight assigned to each decision tree (with
and
) and
x is the input data.
r is the weighted sum of base model outputs (i.e., equal to the mean if the weights are 1/m for all decision trees). Each decision tree is trained on a subsample of the data.
The next task is to select the best feature from the high-dimensional QoS features to split the data. The first step in this process is optimisation, wherein a single feature is randomly selected and optimized at each node in a decision tree. The above process is repeated until all features have been optimized. Once the best feature is found from the previous step, the dataset is split and passed to the two child nodes in the decision tree.
If
, it denotes
q trusted cloud services.
denotes the trust level of a cloud service,
, at a given time
t.
is predicted based on the QoS measurements pulled by a broker at that time instance. The objective trust
of
over a time period (i.e., one hour or one day) is computed using Equation (
2):
where
is the weight assigned to each
with
and
.
is a time-decay-based weight computation function, and gives more weight to recent interactions, as shown in Equation (
3).
3.6. Subjective Trust Computation
The subjective trust
of a cloud service
is computed as follows:
where
is the feedback for
pth cloud service.
3.7. Feedback Credibility Assessment
In our proposed TCF, subjective trust is computed in two steps. In the first step, multi-dimensional feedback (
Table 2) is taken from CSUs. While in the second step, the credibility of the feedback is evaluated, and the resulting feedback is employed to compute subjective trust. The user feedback can be subject to various malicious attacks, namely, Sybil, collusion, and on-off. Considering the possible risks, it is essential to verify the credibility of user feedback. Accordingly, a trust credibility evaluation module is designed to prevent and mitigate collusion and Sybil attacks.
3.7.1. Sybil Attacks Prevention
In order to prevent Sybil attacks, all CSUs are required to register with the broker based on a unique set of credentials i.e., username, personal details, address, etc. The CSUs can register after signing the SLA with CSP. Only authenticated CSUs can give feedback. The broker maintains a database in which it stores the hashes of credentials that belong to the CSUs. During the registration process, the credentials are hashed and aggregated.
Let be a secure cryptographic hash function such as SHA3. Let be a set of user credentials. The broker calculates and compares it with the existing user records already stored in the CSU database. If a match is found, the broker will generate a warning that CSU is already registered; otherwise, it will register the new record.
3.7.2. Collusion Attacks
A collusion attack occurs when a user sends multiple false feedbacks to increase/decrease the trust of a cloud service. Such attacks can occur strategically and occasionally. In strategic collusion attacks, a number of compromised CSUs collaborate to report false feedback. While in occasional attacks, the CSUs can periodically change the feedback behaviour. Sometimes they give high feedback, while at other times, they give low feedback. The attackers adopt such different behaviours in order to remain undetected and still be able to change the trust.
The prevention of collusion attacks is not trivial. It might be possible that some CSUs give malicious feedback (i.e., very high and very low) to push the trust closer to either zero or one. For example, if users give very high feedback (i.e., [0.7–1]), it can result in a value closer to one. Likewise, with lower feedback in a range of [0.1–0.3], the trust can decrease to 0. Now the problem is one cannot be certain about the malicious behaviour; at times low and high values can be given by legitimate CSUs who did not experience a good quality of service or otherwise. The users can give good/bad feedback based on their experience. However, a collaborative effort by some CSUs to push trust in one direction or the other can be taken into consideration to adjust the subjective trust in cloud services.
Considering these constraints, we consider time as an important factor for collusion attack prevention. The rate of change of subjective trust is analysed by comparing the trust in consecutive time instances. Moreover, the collaborative effort to change trust is also handled by reducing its impact accordingly. Precisely, the collusion is detected by “subjective trust variance” and “volume collusion” parameters. Next, we discuss each of these parameters in detail.
3.7.3. Subjective Trust Variance
The subjective trust variance
measures the change in trust during consecutive time instances and subsequently compares it with a predefined tolerance threshold
. If the difference
in two time instances is greater than
, then the subjective trust in the current time instance is adjusted.
3.7.4. Volume Collusion
This parameter quantifies how many CSUs are collaborating to change the subjective trust in a given time instance. The impact of feedback given by a significant number of collaborating users is further reduced using Equation (
6).
where
m is the number of collaborating CSUs that are giving similar kinds of feedback.
denotes the total number of the feedback given to a cloud service
(i.e., feedback volume), and
is subjective variance. The aggregated subjective trust is considered credible if volume collusion is higher.
3.7.5. Feedback Credibility
The broker improves the accuracy of trust computation by computing the credibility of false feedback using Equation (
7). The credibility is computed in two cases. The first case of credibility is based on volume collusion
that detects the change in trust due to a significant number of malicious CSUs. In the second case, credibility is computed by considering the subjective variance
that quantifies the change in trust during consecutive time instances.
where
p is the minimum percentage of CSUs, which is assumed to affect the subjective trust. Next, the subjective trust in a recent time instance is adjusted using Equation (
8).
3.8. Trust Computation
Having presented the objective and subjective modules, the next step is to compute the final trust
using Equation (
9).
where
is the weight of
, and
is the weight of
. If
in Equation (
9), then only objective trust
is used in computing
, and if
, then
is computed based on subjective evidence alone. As can be observed that both
and
play a role in evaluating the trustworthiness of the cloud services; it is better to assign them either equal weights or decide their proportion based on the number and recentness of the evidence. A few studies maintain that
should be assigned a high weight. Since objective evidence indicates the real performance of the cloud services based on the resources they have and how well they completed each task. On the contrary, if the amount of feedback from CSUs is higher, then
should get a high value.
4. Experimental Results and Analysis
In this section, we present the results of our proposed TCF. We begin by stating the objectives of our experiments. Following this, we discuss the testbed and dataset used for computing the trust of cloud services. Next, we present the experiments that were set up to evaluate the proposed framework. Experiment 1 illustrates that trust results in a legitimate environment wherein all users are honest. Experiment 2 demonstrates the effectiveness of adding a credibility assessment module in the subjective trust computation. Experiment 3 presents the comparative analysis results. All these results together demonstrate the advantage of aggregating two sources of evidence to compute trust and also underline how important it is to evaluate the credibility of user feedback as it can impact the trust accuracy if left unverified.
4.1. Experimental Objectives
The first objective of the experimental evaluation is to underline the effectiveness of the multi-factor trust assessment of cloud services. The second objective is to analyse the robustness of the proposed TCF in preventing the malicious behaviour of CSUs. Collusion attacks are designed in different configurations of a hostile strategic environment whereby the CSUs are collaborating to change the trust of cloud services. Moreover, the third objective is to perform a comparative analysis of the final trust
computed from our TCF with the one computed from an existing study [
10], wherein the increasing number of positive feedback from CSUs can increase the overall trust degree. The major limitation of [
10] is the inability to prevent attacks on user feedback, namely, Sybil and collusion.
4.2. Testbed
Here, we describe the setup of our experimental testbed. As discussed in
Section 3, the broker is responsible for efficient resource matching and trust computation. The broker maintains a database of CSUs and CSPs. In our experimental prototype, the broker is simulated by creating a web-based interface where different CSPs register by specifying the types of services (i.e., IaaS, PaaS, SaaS, etc.) they offer, as specified in
Table 3. At the backend, the broker interface is connected with the Greencloud simulator [
28]. The broker takes the service requirements as input and searches the registered CSPs, and subsequently returns the matching resources along with their trust values. The values of different parameters used in our experiments are listed in
Table 4.
4.2.1. Objective Trust Parameters
In order to compute
, the broker requires direct QoS evidence to compute
, and user feedback to compute
.
is computed by monitoring QoS-based evidence gathered from the Greencloud simulator. Each data centre represents a CSP in our case. User requirements for 113 cloud services (
Table 2) are defined and later simulated to measure the QoS parameters. We measured the CPU frequency, memory, hard disk capacity, andenergy consumption and, later on, computed the current CPU, memory, and disk utilisation. We also quantified the average response time and task success ratio for each cloud service. The user requirements were scaled over time to reflect the increasing load on the cloud services.
In
Section 3.5, we discussed that the random forest regression model is used to predict
. The random forest regression model is a supervised machine learning algorithm, so it needs labelled outputs for training and testing. However, the Greencloud [
28] simulator that we have used to create cloud services and gather their QoS parameters does not give us a trust value. Therefore, our next task was to find a way to generate the trust labels for simulated cloud services based on how well they performed and how many tasks they successfully completed. We have compared the obtained QoS parameters with the values stored in SLA contracts. We have used “task success ratio” as the key feature to compute the
trust value, meaning that it gets a high value if the average task success ratio is high, and the QoS parameter values match with the SLA contract and vice versa. This work followed the well-established standards of labelling the ground truths (in both training and testing data) [
13,
16,
21] based on prior domain information during the data preparation stages. The domain information includes the values of the input feature set compared with the predefined SLA values to check how much they vary from the guaranteed service quality, the verification that the cloud service has successfully completed a given task, and how long it took. In other words, the label
is generated based on the node profile, average resource consumption, and performance features. This experimental analysis used a software program that checked both of these conditions and generated the labels. It is noted that the task success ratio is an important parameter in generating the labels because if the values of other input features are in conformance with the SLA but the cloud service is completing half of its tasks, then it cannot be considered trustworthy. These steps were closely followed according to the benchmarking references. Additionally, this experiment did not use the task success ratio as a feature of the regression as it was already used in generating the labels. Once the ground truths in training and testing data are available, the purpose of the regression or machine learning model is to identify the unknown function/relationship between the input and output within the training samples. Once a regression or machine learning model is established, another dataset is used to test the model’s fitness and usefulness.
Train-Test Split: It is underlined that in the random forest regression experiment, 70% of the records are used for training, whereas 30% are used for testing. Next, we partitioned the generated dataset into a train–test split and then rigorously trained the random forest regression model.
Selection of Appropriate Regression Model: As we know, several machine learning models, namely, multiple linear regression, support vector machine, random forest regression, and neural networks, can be used for prediction. We have compared the prediction accuracy of these models and found that the random forest regression model outperforms the others (in consideration of robustness as well). After intensive training of all the regression models, we tested them with the remaining 30% of the data samples. The classification error rate for the neural networks was quite high, and that of the support vector regression was reasonable but showed signs of overfitting. As per our expectations, the random forest regression model correctly classified the trust labels with a 98% accuracy against the ground-truth trust label values available in the testing sample data. Note the testing sample data are different from the training sample data to validate the model. We believe the random forest regression achieved good accuracy and robust modelling due to its non-linear regulated model and, therefore, is well suited for these tasks. The error rate for multiple linear regression on the testing data was a bit high, 11%. The error rate for support vector regression on the testing data was 13%. The lowest error rate of the random forest regression model made it easy for us to select it for objective trust prediction of cloud services.
4.2.2. Subjective Trust Parameters
For subjective trust computation, we have used the “Cloud Armor Trust Feedback” dataset [
21]. This dataset contains 10,000+ feedbacks given by nearly 7000 consumers to 113 real-world cloud services. The feedback is based on multi-dimensional QoE parameters. The personal details of consumers are anonymized. As this dataset contains feedback for 113 cloud services, we have simulated the same number of services. The simulation parameters are listed in
Table 4.
4.3. Experiment 1—Legitimate Environment
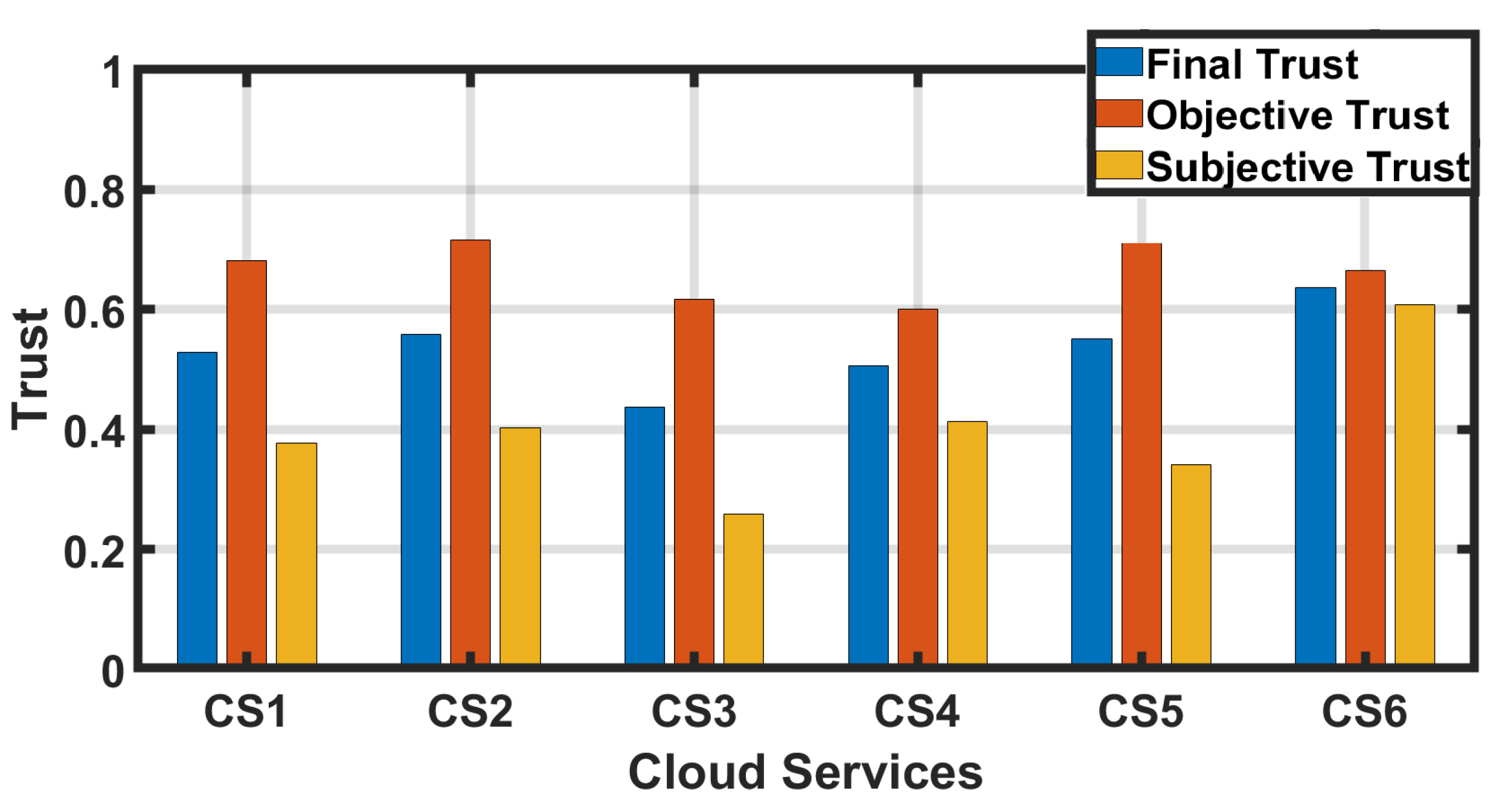
Figure 2 illustrates the trust of six cloud services in a legitimate environment when all entities are honest. The subjective trust, objective trust, and final trust are plotted in
Figure 2. The notation
denotes the
i-th cloud service. The subjective trust is computed using Equation (
4). It can be observed that the
for the first cloud service,
, is 0.37,
is 0.40,
is 0.26,
is 0.41,
is 0.34, and
is 0.60. The objective trust is computed using Equation (
2). Likewise, the objective trust
of six cloud services
to
is 0.68, 0.71, 0.62, 0.60, 0.75, and 0.66 respectively. The final trust
of cloud services is computed based on Equation (
9). In the legitimate environment, both objective and subjective trust are assigned the same weight, i.e.,
in (
9). A a result, the final trust of
is 0.52,
is 0.56,
is 0.43,
is 0.50,
is 0.55, and
is 0.63. To differentiate the trustworthy and untrustworthy services, an appropriate threshold is selected based on all available sample training data (that represents the ground truth) and other available information to minimise the false classifications. In this experiment, a threshold value of 0.5 was selected based on the available information and used to demonstrate how trustworthy services and untrustworthy services are differentiated. A cloud service with a final trust
is considered trustworthy in this case. Based on the selected threshold, all services except
are considered trustworthy. A change in threshold can change such outcomes, and the threshold must be selected based on all available information to minimise the risk of false classification.
4.4. Experiment 2—Malicious Environment
In this experiment, we will analyse the robustness of the credibility assessment module in countering the malicious behaviour of compromised CSUs. Sybil attacks are prevented by registering CSUs with unique credentials and only considering their feedback in subjective trust computation. However, for collusion attacks, five attacking scenarios are considered, whereby a percentage of the feedback given to a cloud service is assumed to be coming from malicious adversaries or compromised users. In the following, the notation is used to denote the ith attacking scenario. Scenario is designed by assuming all CSUs are honest, meaning that there is no false/fabricated feedback. In the subsequent scenarios, the percentage of malicious feedback is slightly increased. For instance, in , 25% of the feedback is considered to be coming from malicious CSUs. Similarly, in , 50% of the feedback is assumed to be fabricated. The fourth scenario, , contains 75% malicious feedback. Lastly, in , all feedback is assumed to be given by malicious CSUs. In all of the collusion scenarios, the CSUs can send feedback with high values, i.e., in the range of [0.8–1], or they can send feedback with low values, i.e., between 0.05 and 0.2.
We have designed the attacking scenarios in a manner such that the credibility of user feedback can be evaluated in different configurations of hostile environments. Following this,
is computed in two cases. In the first case, the trust computation is based on the credibility model presented in
Section 3.7. In the second case, trust is computed without a credibility evaluation. In other words, the aim of computing trust in the above-mentioned two cases is to demonstrate that our TCF can accurately compute trust by discounting the impact of malicious feedback using the proposed credibility assessment module.
Before discussing the results, it is noted that the tolerance threshold is assigned a value of 0.05. This is the minimum value of subjective trust variance that can be tolerated. Any value greater than in consecutive time instances could significantly affect the trust results. It is, therefore, essential to fix a minimum value to the tolerance threshold. The trust model, by default, considers the influence of data outliers to ensure the most information-rich model is constructed with the controlled loss of some outlier data. In reality, some trustworthy feedback may be eliminated alongside the other untrustworthy feedback (as outliers) in credit assessment. This is the case of measured tolerance. As the bulk of information that separates trustworthy feedback from untrustworthy feedback is available in the clustered core regions in the data space, the contribution of a few outliers may be negligent or can be tolerated in trust modelling. If the inclusion or negligence of the outlier data points will impact the trust model, they should not be discarded.
Figure 3a illustrates the trust results of cloud service
computed without considering the credibility, i.e., the first case of collusion. In this case, CSUs are sending high feedback in all attacking scenarios.
has 994 feedbacks. Therefore, in
, the original feedback as found in the dataset is considered. In
, there are 249 high feedback values, while the rest of them are original. Likewise, in
,
, and
, there are 497, 746, and 949 high feedback values, respectively.
It is noted that the objective trust
is not changing. Therefore, the results of subjective
and final trust
are presented. It can be observed that
is increasing with an increasing percentage of high feedback. It has increased from 0.34 in
to 0.9 in
. As a result, the final trust
has also increased in each attacking scenario. Comparing
Figure 2 and
Figure 3a, it can be analysed that
is increasing in each attacking scenario. Overall, it has increased from 0.51 in
to 0.79 in
.
In a similar fashion, we have computed the trust of
with low feedback in all attacking scenarios.
Figure 3b illustrates the subjective and final trust values. It can be observed that
is decreasing in each attacking scenario. In
, it is 0.34, in
, it is 0.28, and in
, it has further decreased to 0.22. In
,
is 0.17, and, lastly, in
, it reached the lowest value of 0.12. The change in subjective trust is also affecting the final trust, which has decreased from 0.51 in
to 0.40 in
. These experiments underline that the final trust in cloud services can be significantly increased/decreased if the credibility assessment is not carried out. Collusion attacks can dramatically change the trust of cloud services; for example, consider
, which has become highly trustworthy or untrustworthy with high and low feedback.
In the second case of collusion attacks, trust is computed based on the credibility model presented in
Section 3.7. As in each attacking scenario, a significant percentage of the feedback is malicious. Therefore, the credibility assessment is based on the feedback volume collusion
parameter. It quantifies the change in subjective trust introduced by a number of collaborative CSUs. Next,
in a recent time instance is adjusted based on the credibility value calculated using Equation (
8). The final trust
of cloud services is computed using Equation (
9). Nonetheless, in the case of a credibility assessment,
is assigned a different value in each attacking scenario.
is quantified based on the percentage of attacking scenarios multiplied by 0.5.
Table 5 lists the
values in five attacking scenarios.
Figure 4a shows the trust results of
in the case of high feedback. It can be observed that the credibility assessment model successfully prevented the malicious CSUs from dramatically increasing the trust results. Comparing the trust with the first case,
Figure 3a, it can be observed that in
,
computed with the credibility assessment is 0.32, and without it, it is 0.47. Similarly, in
,
, with credibility it is 0.43, and without it, it is 0.61. Similar patterns can be observed in the other attacking scenarios,
and
. Moreover, due to the credibility assessment, the final trust
of
is also not changing dramatically. It remained between 0.51 and 0.68 in the five attacking scenarios.
4.5. Experiment 3—Comparative Analysis
In the third experiment, we compare the results of our proposed TCF with [
10], in which the subjective trust in a cloud service increases with the increasing number of positive feedback
and activity degree
. The higher number of positive feedback increases the weight of
(i.e., Equation (16) in [
10]), which eventually increases the overall trust degree (OTD). For comparison and completeness, we first computed the subjective and final trust based on the models presented in [
10] and later compared them with the results obtained from our proposed TCF.
Figure 5a shows the results of
computed based on [
10].
has an activity degree
, as it has taken up 805 jobs. Feedback greater than >
is considered to be positive, and ≤
is negative. For
, the number of positive feedback
, for
, it is 552. Likewise, in the cases of
,
, and
,
is 694, 845, and 994, respectively. We can observe that the final trust of the cloud service
increases from 0.45 to 0.99 with the increasing number of positive feedback.
However, it is very likely that this cloud service has been affected by collusion and/or Sybil attacks. It is, therefore, essential that a trust computation model must be robust in not only detecting these attacks but also mitigating their impact. This is where the feedback credibility assessment plays its role, and we claim that our proposed approach protects against both collusion and Sybil attacks. To show the effectiveness of the credibility model, we have computed the final trust of cloud service
by taking into consideration all attacking scenarios, i.e.,
,
,
,
, and
.
Figure 5b shows the subjective and final trust of
computed based on the credibility model. The difference between the two graphs, i.e.,
Figure 5a,b, is quite promising. The subjective trust
does not change dramatically with high feedback and remained between 0.34 and 0.62 in various scenarios.
also did not change much and remained between 0.51 and 0.68.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}